ing. josé díaz chow
DESCRIPTION
ARQUITECTURA DE MÁQUINAS COMPUTADORAS III. UNI-FEC. Unidad 1 : PARALELISMO Y MEJORA DEL RENDIMIENTO. Ing. José Díaz Chow. U1.2. ¿ Qué hemos abordado ?. Evaluación de la computadora : ¿Para qué ? ¿ Qué ? ¿ Cómo ? Métricas de evaluación Técnicas de Evaluación Rendimiento - PowerPoint PPT PresentationTRANSCRIPT

Ing. José Díaz Chow
ARQUITECTURA DE MÁQUINAS
COMPUTADORAS IIIUNI-FEC
Unidad 1: PARALELISMO Y MEJORA DEL RENDIMIENTO
U1.2

¿Qué hemos abordado? Evaluación de la computadora: ¿Para qué?
¿Qué? ¿Cómo?
Métricas de evaluación Técnicas de Evaluación Rendimiento Tiempo de ejecución Ley de Amdahl Benchmarks (medición)

1.2. Reducción del Tiempo de Ejecución
¡ Queremos mejorar el Rendimiento de la Computadora !
Rendimiento es el inverso del tiempo de ejecución:
Así que, si reduzco el tiempo de ejecución, incremento el rendimiento.

¿Cómo reducir el tiempo de ejecución? Factores que determinan t:
Reducir uno o más factores sin que incrementen otros permitiría reducir t: ¿ De qué depende ? ¿Cómo reducirlo? ¿ De qué depende el? ¿Cómo reducirlo? ¿ De qué depende ? ¿Cómo reducirlo?

Reducción del período (t) El t de reloj debe ser lo suficientemente
ancho para que se completen todas las microoperaciones de control del paso de control más tardado.
Para reducir t es requerido, por tanto, que las operaciones de control sean más rápidas (para que no se tenga que incrementar el CPI).
Depende del avance de la tecnología en los procesos de fabricación de sistemas digitales.

Reducción del número de Instrucciones (N) Depende de la arquitectura. Arquitecturas con instrucciones complejas
permiten realizar operaciones con menos instrucciones que otras con instrucciones más simples: Operaciones integradas: CMP + Jx (2 inst.) vs BRx (1
inst.: Salta si se cumple la condición x) Múltiples modos: LOAD Rf, Rs(d) + ADD Rd, Rf, Rg (2
inst. Arq R3) vs ADD Rs(d), Rf (1 inst. Arq R2) Dependencia de instrucciones complejas con
mProgramación tiende a t mayor. ¡No rinde buenos frutos!

Reducción de ciclos por instrucción (CPI) Depende de la arquitectura: ¡Cantidad de
operaciones que se pueden realizar en un ciclo de reloj!
Arquitecturas con instrucciones complejas obligan a altos CPIs
Arquitecturas con instrucciones simples pueden reducir CPI. Meta a aspirar: CPI =1
Proyecto RISC lo demostró. ¡Mejor apuesta para el arquitecto!

Mejorando nuestra arquitectura X (R2) Reducir modos para simplificar la UC:
Arquitectura R3: Transferencia de M R: LOAD, y RM: STORE.
Usan modo Índice. Operaciones OP: Solo registros o inmediatos. Move R1, R2 Add R2, R1, R0; ¡R0 siempre vale
0! Bus común Conexiones directas: más rápido. Uso de más registros en un Banco de
Registros: 2 puertos de lectura y 1 de escritura simultáneos

1.3. Mejoras al sistema de memoria
Sistema de Memoria
Despues del CPU, el sistema de memoria es el más usado.
¡Eliminar los WMFC!
Mejorar el desempeño del sistema de Memoria.

Mejorando el desempeño de M ¿Cuáles son los factores de desempeño de la
Memoria? Latencia: Tiempo de acceso, tiempo de ciclo.
Depende de la tecnología de fabricación. Productividad: Velocidad de transferencia.
Ancho del Bus Solapamiento: memorias entrelazadas.
Disponibilidad: Detección y corrección de errores Capacidad: Memoria Virtual
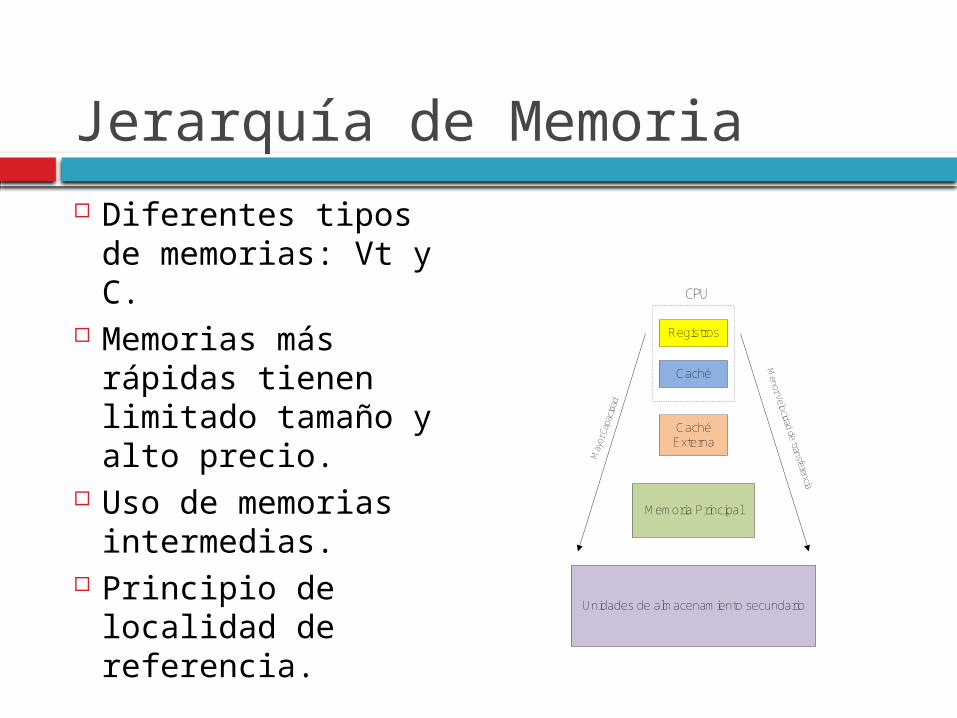
Jerarquía de Memoria Diferentes tipos de
memorias: Vt y C. Memorias más
rápidas tienen limitado tamaño y alto precio.
Uso de memorias intermedias.
Principio de localidad de referencia.
Registros
Caché
CPU
Caché Externa
Memoria Principal
Unidades de almacenamiento secundarioM
ayor
Cap
acid
ad
Menor Velocidad de transferencia

1.4. Mejoras al sistema de E/S
Sistema de Entrada - Salida
Comunicación con el exterior Leer Programas y Datos Entregar resultados de procesamiento.
Diferentes dispositivos de E/S Entrada Salida Memoria de largo plazo
Diferentes tecnologías y velocidades
Mejorar el desempeño del sistema de Entrada / Salida.

Mejorando el desempeño de E/S Diferentes dispositivos con diferentes
métodos de transferencia de datos y velocidades
¿Cuáles son los factores de desempeño del sistema de E/S?
Latencia: Tiempo de respuesta. Depende de la tecnología de fabricación.
Productividad: Velocidad de transferencia. Frecuencia Ancho del Bus
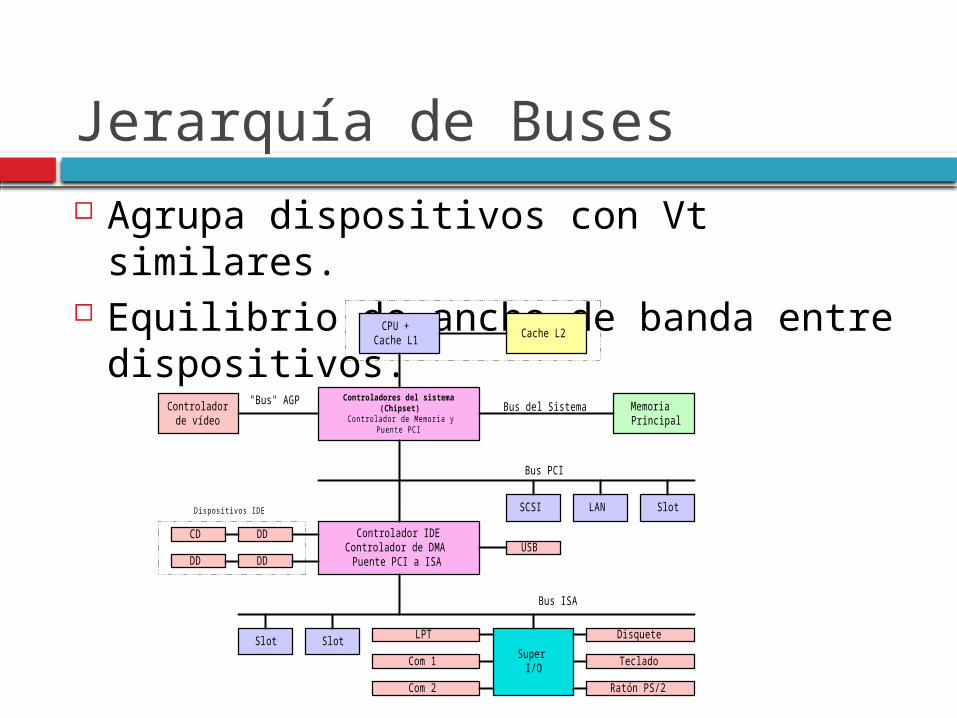
Jerarquía de Buses Agrupa dispositivos con Vt similares. Equilibrio de ancho de banda entre
dispositivos. CPU +Cache L1
Cache L2
Controladorde vídeo
Controladores del sistema(Chipset)
Controlador de Memoria yPuente PCI
MemoriaPrincipal
Controlador IDEControlador de DMA
Puente PCI a ISA
SCSI LAN Slot
USBDD
DD
CD
DD
Dispositivos IDE
Slot SlotSuper
I/O
Disquete
Com 1
Com 2 Ratón PS/2
Teclado
LPT
Bus ISA
Bus PCI
Bus del Sistema"Bus" AGP

ADM y Procesadores de E/S
Agiliza las transferencias de dispositivos de E/S a M y viceversa.
Emplea un procesador auxiliar dedicado. Solapa la ejecución de instrucciones con
las operaciones de E/S Diversos esquemas de acuerdo a las
velocidades de los dispositivos
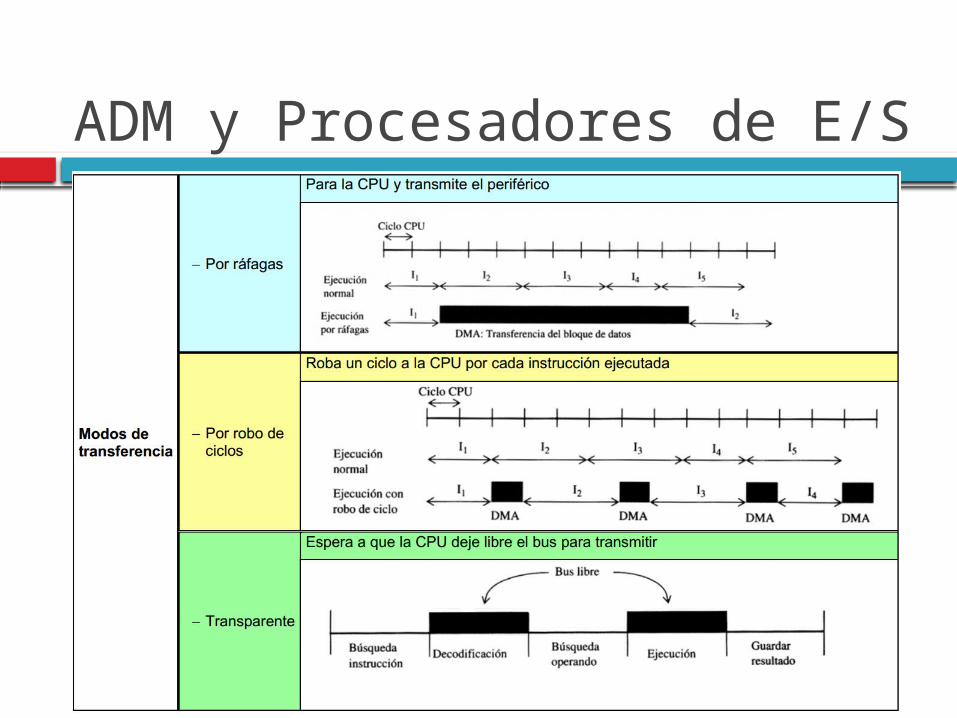
ADM y Procesadores de E/S

1.5. Introducción al Paralelismo
Paralelismo ¿Y si aún con todas estas mejoras, no logramos el rendimiento deseado?
Por Amdahl: CPU es el más apropiado de mejorar
¿Se puede? Si solo hago una tarea, con un
amigo, ¡puedo hacer dos!

Requerimientos de mayor desempeño Concurrencia (datos compartidos). Capacidad de atención a múltiples
usuarios y tareas. Procesamiento de datos de información
de conocimiento Inteligencia. Tecnología de producción de hardware
más poder a menor costo Ejecutor más rápido vs más ejecutores.

Procesamiento Paralelo
Forma de procesamiento que explota ejecución de sucesos concurrentes. Simultaneidad Multiplicidad
Solapamiento de ejecución de múltiples tareas.
Multiplicidad de ejecutores en una o varias tareas.

Tipos de Paralelismo
• Temporal: El paralelismo que involucra solapamiento se denomina temporal porque permite la ejecución concurrente de sucesos sobre los mismos recursos en intervalos intercalados de tiempo.
• Espacial: El paralelismo que permite
simultaneidad real sobre múltiples recursos al mismo tiempo se denomina paralelismo espacial.

Nivel de Paralelismo Grano Grueso
Tarea Programa
Grano Fino Instrucción Aritmético o de Bits

Técnicas de mejora y paralelismo Multiprogramación y Tiempo
compartido: técnica software (temporal): Sistema Operativo.
Solapamiento de las operaciones CPU y E/S: DMA e IOPs. Espacial.
Jerarquización y equilibrio de ancho de banda: Jerarquía de Memoria y de Buses: agilización y redundancia de datos. Espacial.

Técnicas de mejora y paralelismo Solapamiento de la ejecución: Ciclo de
instrucción solapado. Adelanta etapas del ciclo. Pre-Fetch y Pipelining. Temporal.
Multiplicidad de unidades ejecutoras: Sistemas superescalares. Espacial.
Sistemas paralelos: Paralelismo de datos y de código: SIMD y MIMD. Espacial

1.6. Clasificación de arquitecturas paralelas
Taxonomías
Diferentes sistemas de clasificación.
Más comunes: Flynn: Basado en cardinalidad
(s,m) de flujo de instrucciones y datos.
Feng: Basado en tipo de transferencia o procesamiento (s,p) y cantidad de bits involucrados (b,w).
Händler: Modelo matemático basado en métricas. Categoría es tupla de valores
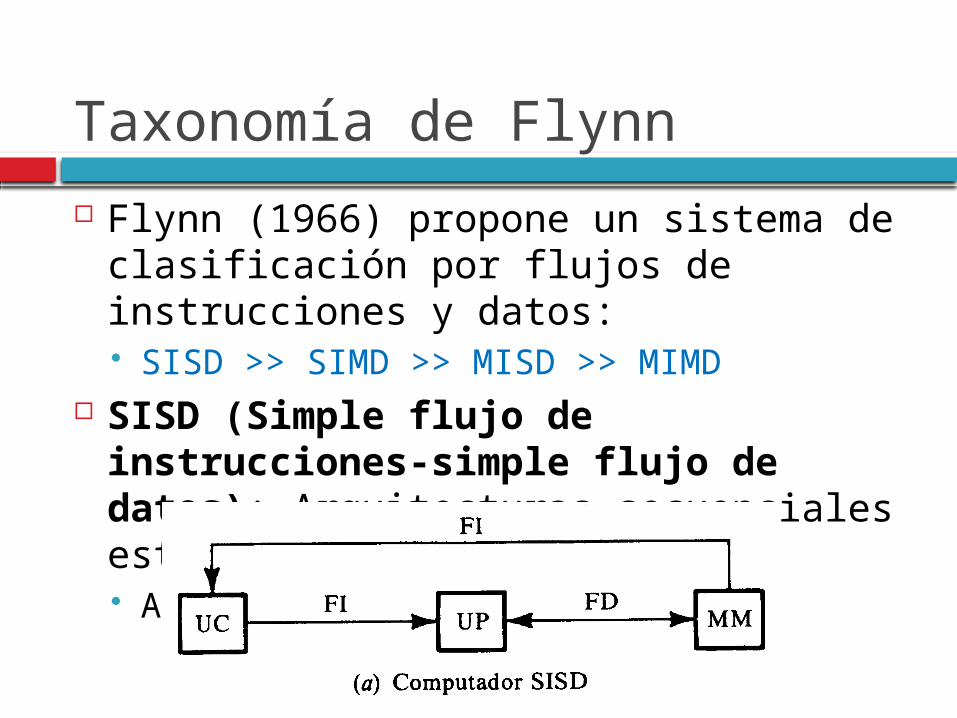
Taxonomía de Flynn
Flynn (1966) propone un sistema de clasificación por flujos de instrucciones y datos: SISD >> SIMD >> MISD >> MIMD
SISD (Simple flujo de instrucciones-simple flujo de datos): Arquitecturas secuenciales estándares Arquitectura Von Neumann.
Taxonomía de Flynn
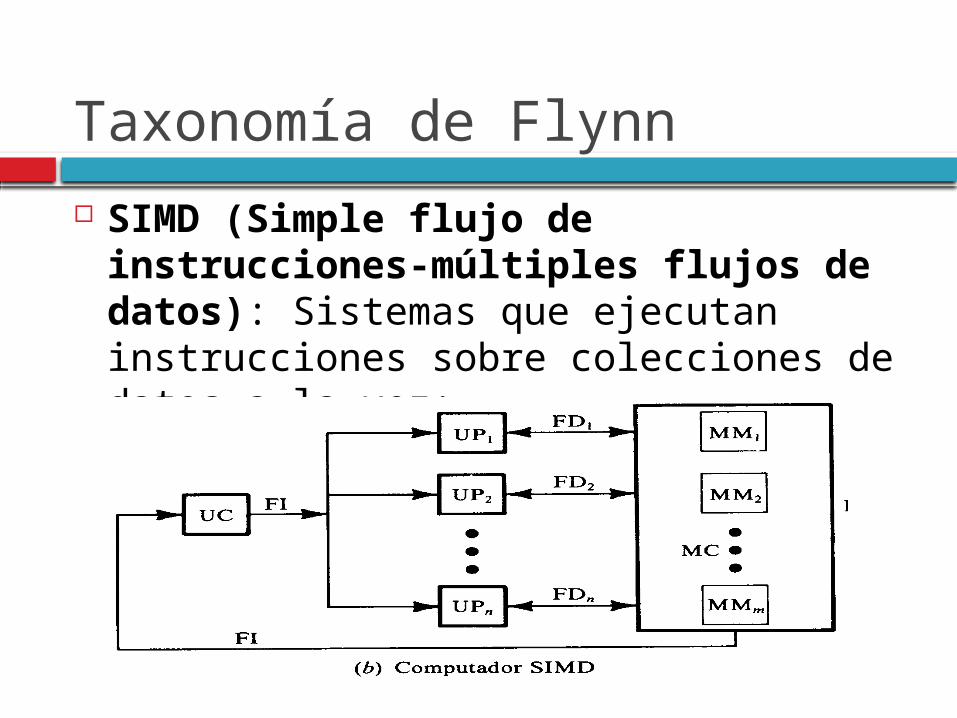
SIMD (Simple flujo de instrucciones-múltiples flujos de datos): Sistemas que ejecutan instrucciones sobre colecciones de datos a la vez: Cálculo vectorial y matricial.

Taxonomía de Flynn
MISD ( Múltiples flujos de instrucciones-simple flujo de datos): Arquitecturas no viables en el paradigma actual. Arquitecturas de flujo de datos. No aplicación real.
Taxonomía de Flynn
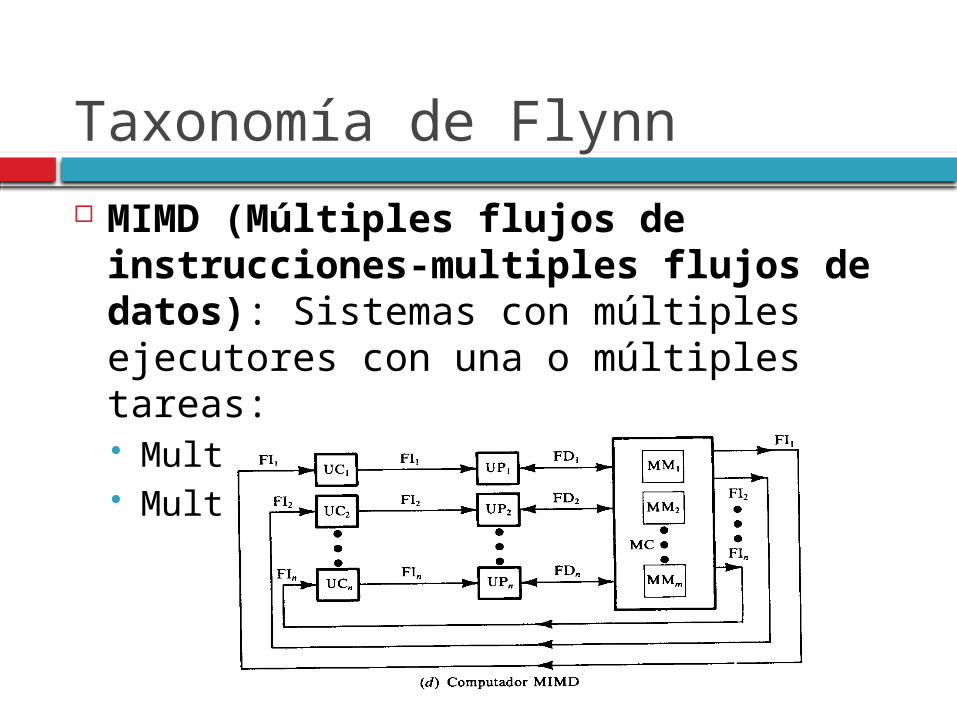
MIMD (Múltiples flujos de instrucciones-multiples flujos de datos): Sistemas con múltiples ejecutores con una o múltiples tareas: Multiprocesadores Multicomputadores
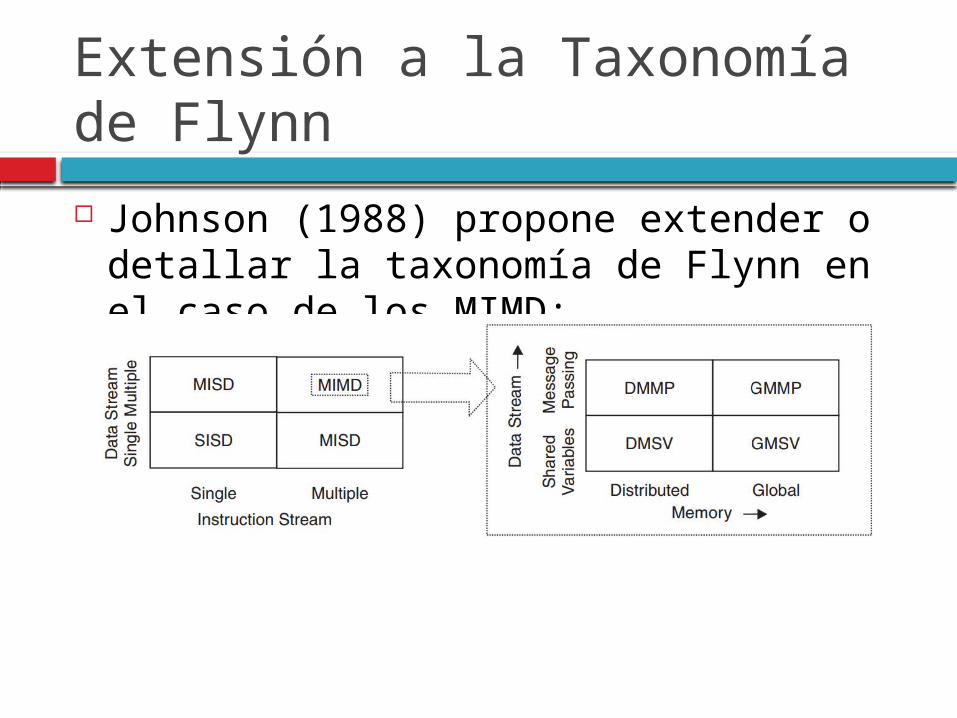
Extensión a la Taxonomía de Flynn Johnson (1988) propone extender o
detallar la taxonomía de Flynn en el caso de los MIMD:

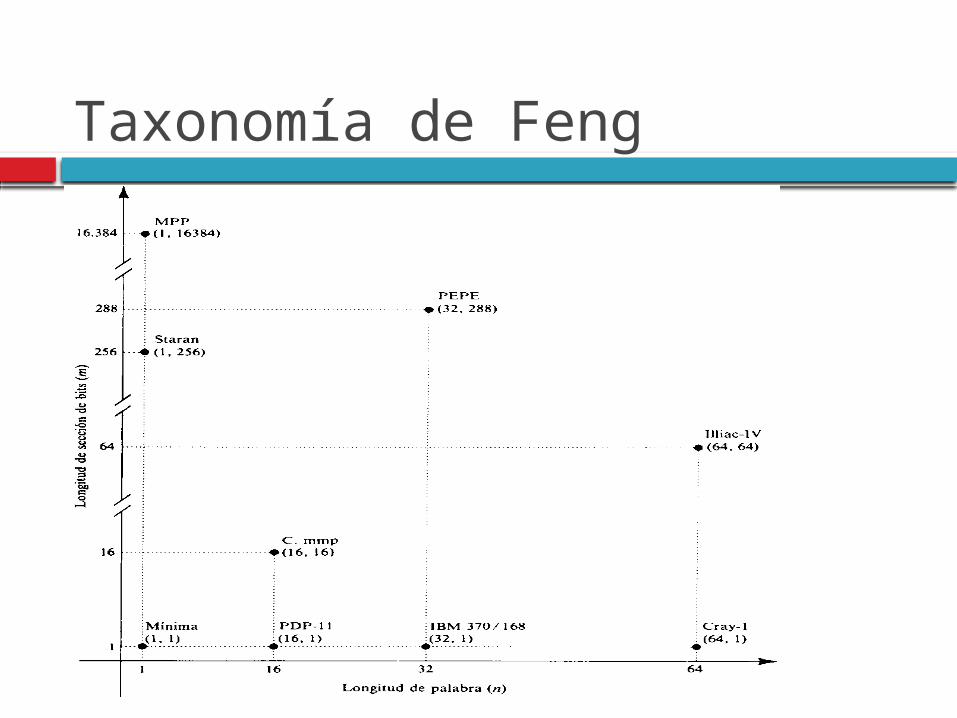
Taxonomía de Feng Tse-yun-Feng, sugiere el grado de paralelismo
como criterio de clasificación: Máximo grado de paralelismo ( P ) = número máximo de
dígitos binarios que pueden ser
procesados en una unidad de tiempo
Grado medio de paralelismo ( Pm ) y tasa de utilización ( g ) de un sistema en T ciclos:Donde Pi es el No. de bits que puede ser
procesados en el i-esimo ciclo del procesador, para T ciclos.
Tasa de utilización en T ciclos

Taxonomía de Feng Se puede clasificar a la computadoras de
acuerdo a este criterio como:
Palabra-serie y bit-serie (PSBS). m=n=1. Procesamiento totalmente serial.
Palabra-paralelo y bit-serie (PPBS). m>1, n=1, procesamiento por sección de bits (procesa m palabras 1 bit cada vez).
Palabra-serie y bit-paralelo (PSBP). n>1, m=1, procesamiento por sección de palabra (procesa una palabra de n bits a la vez), computadoras actuales.
Palabra-paralelo y bit-paralelo (PPBP). n>1, m>1, procesamiento totalmente paralelo (se procesa una matriz de n*m bits a la vez), multiprocesadores y multicomputadoras (cluster´s).
Taxonomía de Feng

Taxonomía de Händler Wolfgang Händler: Esquema basado en encauzamiento
del procesamiento en tres niveles “top-down”: UCP (Unidad Central de procesamiento) UAL (Unidad Aritmética Lógica) El circuito a nivel Bit (CNB)
Un sistema computador (C )puede caracterizarse por una triada:
C = < K x K’, D x D’, W x W’ > donde:
K = Es el número procesadoresK’ = Número de procesadores que puede encauzarse (pipelined)D = Es el número de ALU bajo el control de un CPUD’ = Número de ALU´s que pueden ser encauzadas (pipelined)W = Longitud de palabra de una UAL o un Elemento de Proceso (EP)W’ = El número de segmentos en pipeline en todas las ALU´s o EP´s

Taxonomía de Händler Por ejemplo para la Cray-1:
Es un procesador de 64-bit no segmentado, superescalar
Cuenta con12 unidades de proceso o ALUs, 8 de las cuales pueden trabajar en pipeline.
Diferentes unidades funcionales tienen de 1 a 14 segmentos los cuales pueden trabajas en pipeline.
Por tanto:
CRAY-1 = < 1, 12 x 8, 64 x ( 1~14) >

Otras Taxonomías Otras clasificaciones que se pueden encontrar en
la literatura son: Taxonomía de Shore´s (1973): Basada en la estructura
y el número de unidades funcionales en la computadora. Se divide en 6 categorías o tipos de máquina: Máquina 1 … Máquina 6.
Taxonomía estructural de Hockney y Jesshope´s. Se basa en la notación llamada “Estilo de Notación Estructural Algebraica (ASN)”, es muy compleja. C(Cray-1) = Iv12 [ 12Ep12 - 16M50 ] r; 12Ep = {3Fp64,9B}
Existen otras nomenclatura que pretende ser más descriptiva y se basa en: multiplicidad del procesador, tamaño de grano, topología y control de multiplicidad.
Recomendaciones
U1: Paralelismo y mejora del rendimiento
Recordar consultar el folleto de clase.
Recordar consultar la bibliografía: Hwang Henesy - Patterson