introduction to data processing using hadoop and pig
DESCRIPTION
In this talk we make an introduction to data processing with big data and review the basic concepts in MapReduce programming with Hadoop. We also comment about the use of Pig to simplify the development of data processing applicationsYDN Tuesdays are geek meetups organized the first Tuesday of each month by YDN in LondonTRANSCRIPT

introduction to data processing using Hadoop and Pig
ricardo [email protected]
http://twitter.com/phobeo
yahoo ydn tuesdaysLondon, 6th oct 2009

ah! the data!
• NYSE generates 1 Terabyte of data per day
• The LHC in Geneva will produce 15 Petabytes of data per year
• The estimated “digital info” by 2011: 1.8 zettabytes(that is 1,000,000,000,000,000,000,000 = 1021 bytes)
• Think status updates, facebook photos, slashdot comments(individual digital footprints get to Tb/year)
unlicensed img from IBM archivesdata from The Diverse and Exploding Digital Universe, by IDC

“everything counts in large amounts...”
• where do you store a petabyte?
• how do you read it? (remote 10 mb/sec, local 100mb/sec)
• how do you process it?
• and what if something goes wrong?
data from The Diverse and Exploding Digital Universe, by IDC

so, here comes parallel computing!
In pioneer days they used oxen for heavy pulling, and when one ox couldn't budge a log, they didn't try to grow a larger ox. We shouldn't be trying for bigger computers, but for more systems of computers
Grace Hopper

however...
There are 3 rules to follow when parallelizing large code bases.Unfortunately, no one knows what these rules are
Gary R. Montry

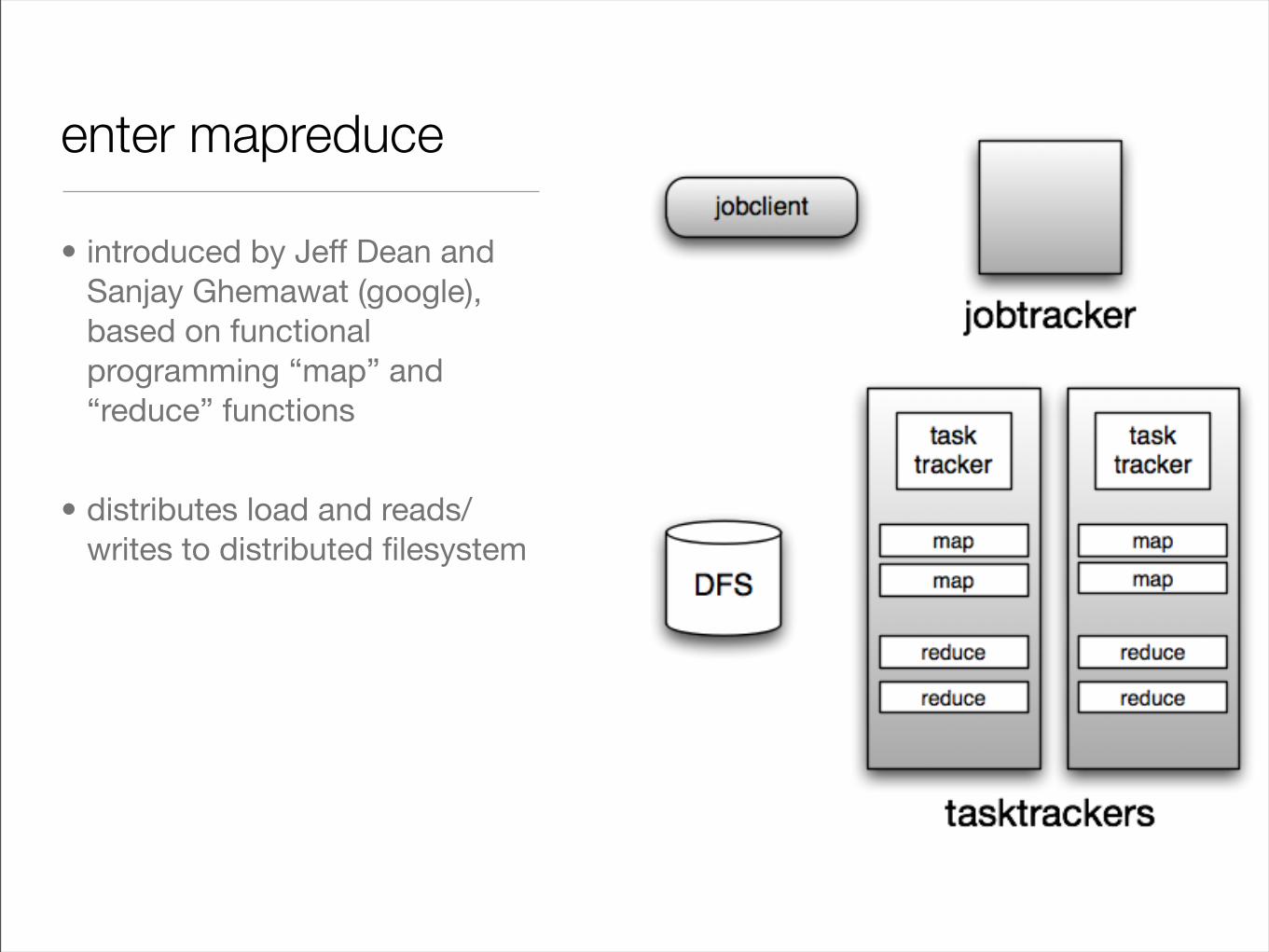
enter mapreduce
• introduced by Jeff Dean and Sanjay Ghemawat (google), based on functional programming “map” and “reduce” functions
• distributes load and reads/writes to distributed filesystem
img courtesy of Janne, http://helmer.sfe.se/
enter mapreduce
• introduced by Jeff Dean and Sanjay Ghemawat (google), based on functional programming “map” and “reduce” functions
• distributes load and reads/writes to distributed filesystem

apache hadoop
• top level apache project since jan 2008
• open source, java-based
• winner of the terabyte sort benchmark
• heavily invested in and used inside Yahoo!

apache hadoop
• top level apache project since jan 2008
• open source, java-based
• winner of the terabyte sort benchmark
• heavily invested in and used inside Yahoo!

hdfs
• designed to store lots of data in a reliable and scalable way
• sequential access and read-focused, with replication

simple mapreduce

simple mapreduce
• note: beware of the single reduce! :)

simple mapreduce

example: simple processing
#!/bin/bash# search maximum temperatures according to NCDC recordsfor year in all/*do echo -ne `basename $year .gz`”\t” gunzip -c $year | \ awk ‘{ temp = substr($0,88,5) + 0; q = substr($0, 93, 1); if(temp != 9999 && q ~ / [01459]/ && temp > max) max = temp; } END { print max }’done

example: simple processing
• data for last 100 years may take in the order of the hour (and non scalable)
• we can express the same in terms of a single map and reduce

example: mapper
public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString(); String year = line.substring(15, 19); int airTemperature; if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs airTemperature = Integer.parseInt(line.substring(88, 92)); } else { airTemperature = Integer.parseInt(line.substring(87, 92)); } String quality = line.substring(92, 93); if (airTemperature != MISSING && quality.matches("[01459]")) { output.collect(new Text(year), new IntWritable(airTemperature)); }}

example: reducer
public class MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int maxValue = Integer.MIN_VALUE; while (values.hasNext()) { maxValue = Math.max(maxValue, values.next().get()); } output.collect(key, new IntWritable(maxValue))
}
}

example: driver
public static void main(String[] args) throws IOException { JobConf conf = new JobConf(MaxTemperature.class); conf.setJobName("Max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(MaxTemperatureMapper.class); conf.setReducerClass(MaxTemperatureReducer.class);
conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class);
JobClient.runJob(conf);}

et voilà!
• our process runs in order of minutes (for 10 nodes) and is almost-linearly scalable(limit being on how splittable input is)

but it may get verbose...
• needs a bit of code to make it work
• chain jobs together(sequences can just use JobClient.runJob() but more complex dependencies need JobControl)
• also, for simple tasks, you can resort to hadoop streaming
unlicensed image from The Matrix, copyright Warner Bros.

pig to the rescue
• makes it simpler to write mapreduce programs
• PigLatin abstracts you from specific details and focus on data processing

simple example, now with pig
-- max_temp.pig: Finds the maximum temperature by year
records = LOAD 'sample.txt' AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND (quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
grouped_records = GROUP filtered_records BY year;
max_temp = FOREACH grouped_records GENERATE group, MAX(filtered_records.temperature)
DUMP max_temp;
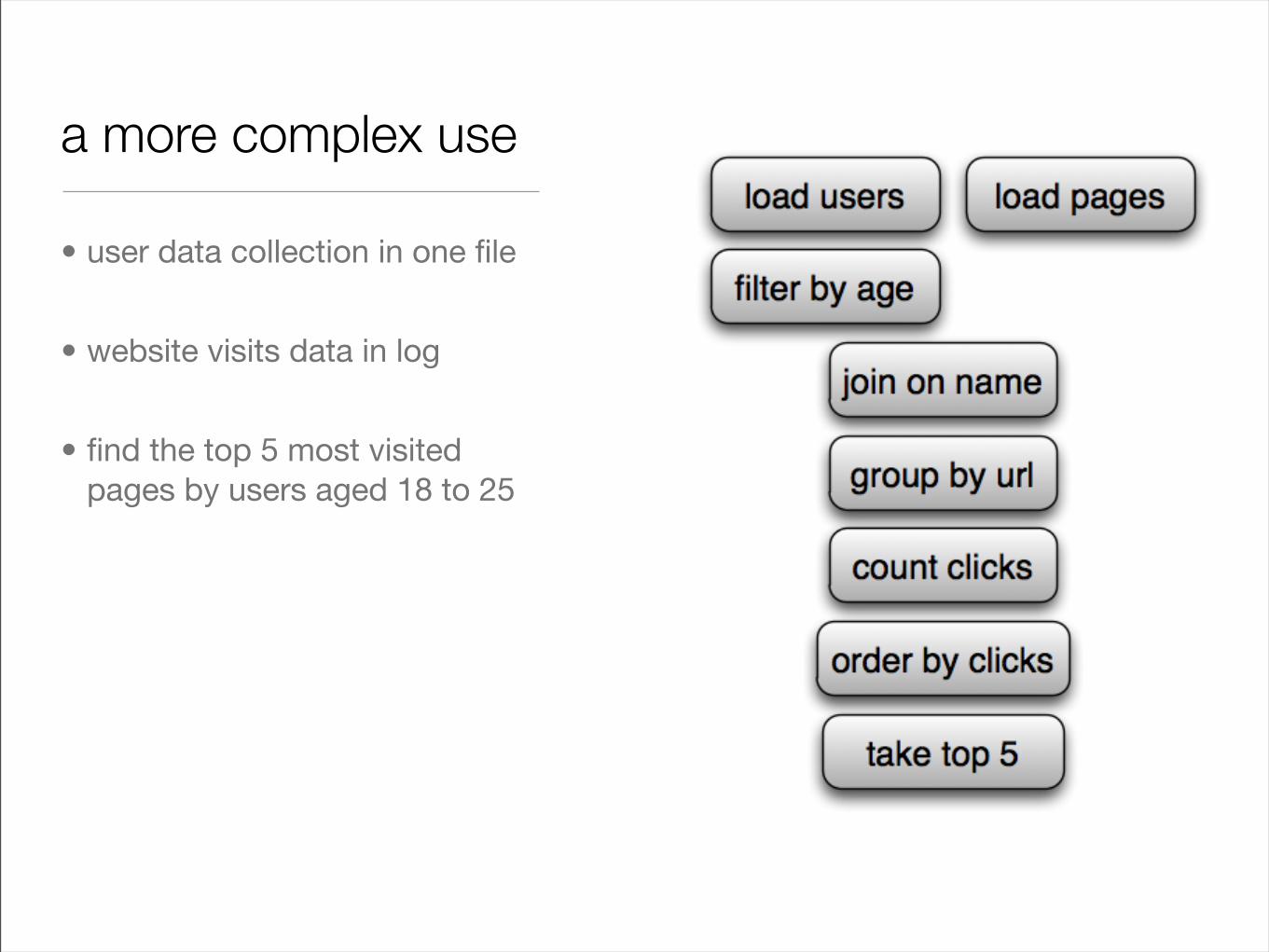
a more complex use
• user data collection in one file
• website visits data in log
• find the top 5 most visited pages by users aged 18 to 25

in mapreduce...

and now with pig...
Users = LOAD ‘users’ AS (name, age);Fltrd = FILTER Users BY age >= 18 AND age <= 25; Pages = LOAD ‘pages’ AS (user, url);Jnd = JOIN Fltrd BY name, Pages BY user;Grpd = GROUP Jnd BY url;Smmd = FOREACH Grpd GENERATE group, COUNT(Jnd) AS clicks;Srtd = ORDER Smmd BY clicks DESC;Top5 = LIMIT Srtd 5;STORE Top5 INTO ‘top5sites’;

lots of constructs for data manipulation
load/store Read/write data from file system
dump Write output to stdout
foreach Apply expression to each record and output one or more records
filter Apply predicate and remove records that do not return true
group/cogroup Collect records with the same key from one or more inputs
join Join two or more inputs based on a key
cross Generates the cartesian product of two or more inputs
order Sort records based on a key
distinct Remove duplicate records
union Merge two data sets
split Split data into 2 or more sets, based on filter conditions
limit Limit the number of records
stream Send all records through a user provided binary

so, what can we use this for?
• log processing and analysis
• user preference tracking / recommendations
• multimedia processing
• ...

example: New York Times
• Needed offline conversion of public domain articles from 1851-1922
• Used Hadoop to convert scanned images to PDF, on 100 Amazon EC2 instances for around 24 hours
• 4 TB of input, 1.5 TB of output
published in 1892. Copyright The New York Times,

coming next: speed dating
• finally, computers are useful!
• Online Dating Advice: Exactly What To Say In A First Messagehttp://bit.ly/MHIST
• The Speed Dating datasethttp://bit.ly/2sOkXm
img by DougSavage - savagechickens.com

after the talk...
• hadoop and pig docs
• our very own step-by-step tutorialhttp://developer.yahoo.com/hadoop/tutorial
• now there’s also books
• http://huguk.org/

and if you get stuck
• http://developer.yahoo.com
• http://hadoop.apache.org
• IRC: #hadoop on irc.freenode.org
img from icanhascheezburger.com
