introduction to data science with hadoop
TRANSCRIPT

1 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
IntroducAon to Data Science with Hadoop
Glynn Durham, Senior Instructor, Cloudera [email protected]

2 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
I will cover:
Hadoop, Hadoop ecosystem HDFS MapReduce Sqoop Flume Hive Pig Mahout Machine learning Data science using Hadoop
Terms
with a few extras:
YARN HBase Impala Oozie data products

3 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Hadoop is:
a plaLorm for big data
several Apache SoNware FoundaOon (ASF) projects
free open source soNware
Major parts:
Hadoop Core
Hadoop ecosystem
Hadoop

4 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Hadoop Core Main Features: File System and Batch Programming

5 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Hadoop Core consists of:
HDFS – (Hadoop Distributed File System), for storage
MapReduce – for batch programming
Hadoop Core

6 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
HDFS Writes

7 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
HDFS Reads

8 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
HDFS is good at: – storing enormous files – storing a lot of data reliably – throughput on sequenAal writes – throughput on sequenAal reads of a file or part of a file
HDFS is not good at: – high speed random reads of parts of a file
HDFS cannot: – update any part of a file once wri>en* – * but you can always write a new file, and/or delete, move, and rename files and directories
HDFS Strengths and Weaknesses

9 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
MapReduce: Programming with Simple FuncAons

10 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
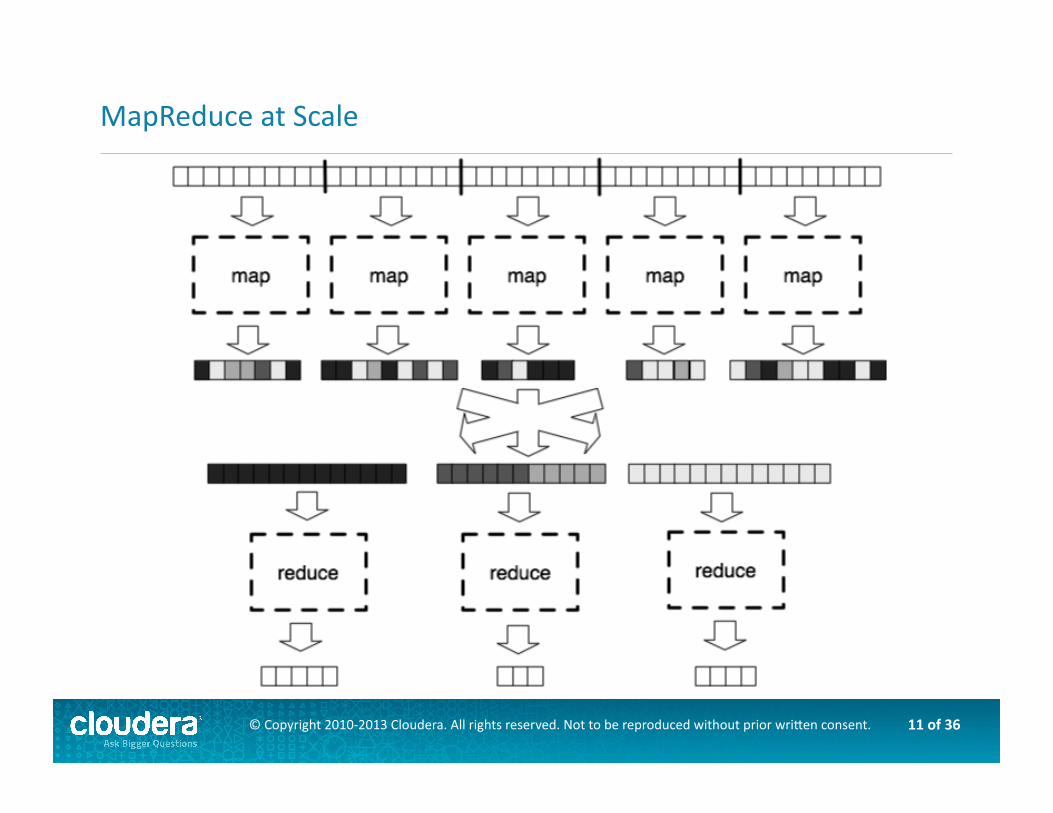
MapReduce Chains
11 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
MapReduce at Scale

12 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
MapReduce in Hadoop

13 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
MapReduce is good at: – processing enormous amounts of data – scaling out as you add more machines – conAnuing to compleAon, even when some machines die
MapReduce is not good at: – running any algorithm you can think up – algorithms that require shared state overall* – * but maybe you can get clever with your algorithm design
MapReduce cannot: – run in real Ame: MapReduce jobs are batch jobs
MapReduce Strengths and Weaknesses

14 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Detour: YARN, Yet Another Resource NegoAator—near future

15 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
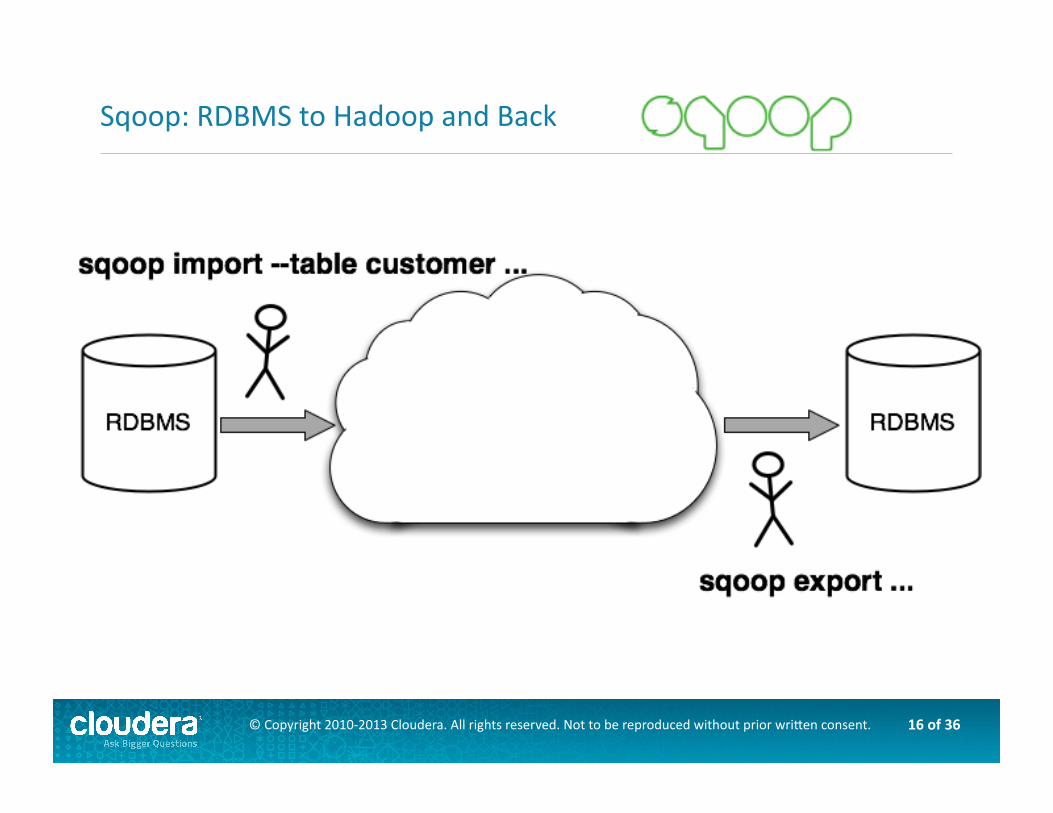
The Hadoop Ecosystem consists of other projects that round out Hadoop Core to make it a useful pla\orm: – Sqoop, for RDBMS integraAon – Flume, for event ingesAon – Hive, for "SQL"-‐like high-‐level programming – Pig, another high-‐level programming paradigm – Mahout, a Java library for machine learning in Hadoop
Plus: – HBase, a "NoSQL" database system – Oozie, a workflow manager for Hadoop acAons – ....
Hadoop Ecosystem
16 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Sqoop: RDBMS to Hadoop and Back

17 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Flume: IngesAng ConAnuing Event Data

18 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Detour: General File Input/Output

19 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Java MapReduce API
MapReduce revisited: How to write MapReduce programs?
• The most expressive technique possible
• The most work, by far
• (Can be easier with Hadoop Streaming: a way to use streaming programming such as shell scripOng or Python)

20 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Hive: MapReduce as "SQL"
• Familiar language and programming paradigm
• Provides interface to many SQL-‐compliant tools

21 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Detour: Impala, High Speed AnalyAcs in Hadoop
• 5 to 30 Omes faster then Hive queries (someOmes 100's of Omes faster!)
• Cloudera exclusive offering, but Apache licensed, so it's free and open source

22 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Impala Does Not Use MapReduce

23 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Detour: HBase, A NoSQL Database System

24 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
HBase is a NoSQL database system: – programmers create and use database tables – high volume, high performance access to individual cells – much weaker query language than SQL – lacks ACID-‐compliant transacAons
HBase is not strictly needed to do "data science" – a resource hog; competes with analyAcal programs – ogen deployed on its own separate cluster – may be part of your organizaAon's data storage and delivery, so you may need to get or put data into an HBase system* – * (or other NoSQL system)
Detour: A bit more about HBase

25 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Pig: Another Language for MapReduce

26 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Mahout is:
a collecOon of algorithms, mainly focused on "the three C's" of machine learning
wriden in Java
largely implemented over Hadoop MapReduce
invocable from the command line
extensible, with the Java API
Mahout is not:
a turnkey soluOon for doing machine learning
always user-‐friendly
Mahout: Machine Learning in MapReduce

27 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
"The three C's" of machine learning:
ClassificaOon Clustering
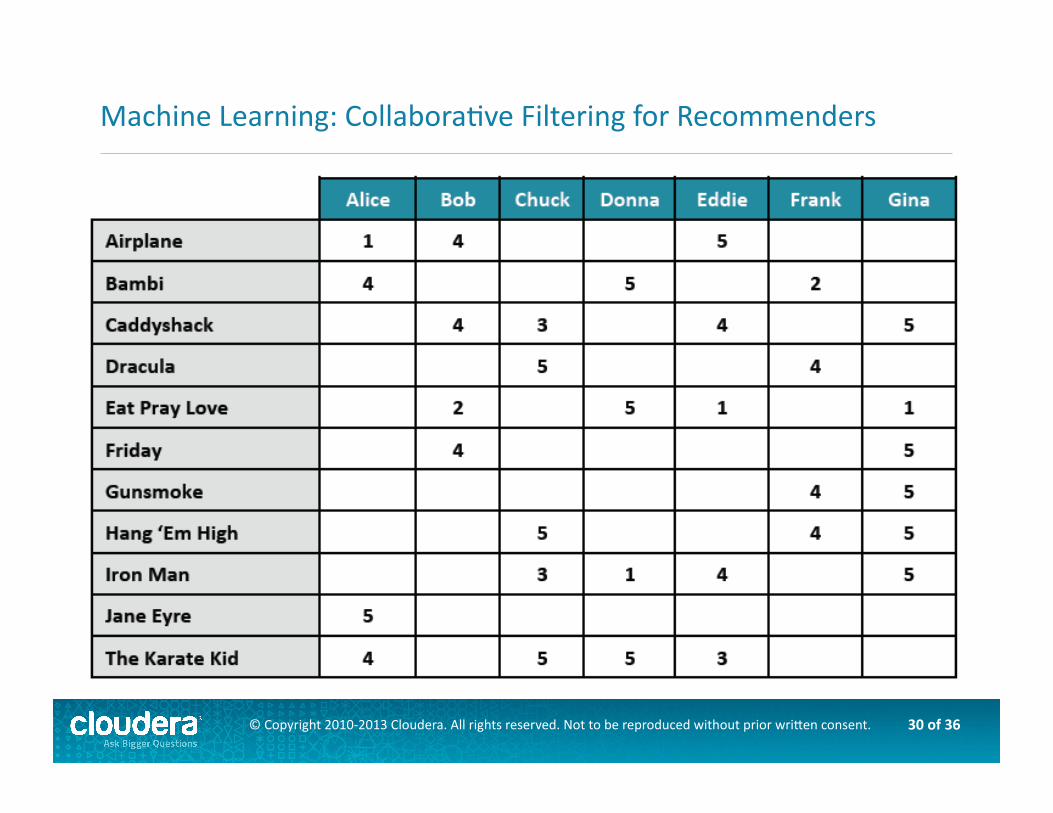
CollaboraOve filtering (recommenders)
Machine Learning

28 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Supervised Machine Learning: ClassificaAon

29 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Machine Learning: Clustering
30 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Machine Learning: CollaboraAve Filtering for Recommenders

31 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Simple Enterprise Deployment: Hadoop as ETL Appliance

32 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Simple workflow within Hadoop:
1. Clear out staging directory in HDFS
2. Sqoop import from OLTP tables
3. Hive (or Pig) script to transform data
4. Sqoop export to data warehouse
Detour: Oozie, Workflow within Hadoop

33 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Hadoop: The Bigger Picture

34 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
A data scienOst will:
1. IdenOfy internal and external data for potenOal use (general data wrangling tools).
2. Help build ingesOon pipelines to obtain data for use (Flume, Sqoop, other).
3. Examine, clean, and anonymize ingested data (Hive, Impala, Pig, Hadoop Streaming).
4. Shape data into useful formats (Hive, Pig).
5. Explore data sets to gain understanding of problems, trends, reality (Impala, Hive, Pig, staOsOcal programming).
6. Build predicOve models using staOsOcal programming, machine learning (Mahout).
7. Contribute to data products: products in the organizaOon that are built in large part from the data itself (Mahout, Sqoop export, general file export).
8. Conduct experiments with data products, quanOfying benefits and/or tradeoffs of system changes (Flume, Sqoop, staOsOcal tests).
9. Communicate results and insights to stakeholders (visualizaOon*).
Data Science with Hadoop

35 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
VisualizaAon: Needs VisualizaAon Sogware

36 of 36 © Copyright 2010-‐2013 Cloudera. All rights reserved. Not to be reproduced without prior wri>en consent.
Thank you! QuesAons? ContribuAons?
Glynn Durham, Senior Instructor, Cloudera [email protected]