ján kmeťko - nosql a distribuované databázy – pohľad zhora na konzistentnosť výkon a...
TRANSCRIPT

Ján Kmeťko


Deklarovaný výkon nie je vždy reálnym obrazom (napr. môže platiť len pre špeciálny testovací prípad, alebo len pre percento reálnych situácii)
Univerzálna lineárna škálovateľnosť je mýtus

1. Výkon DB je obmedzovaný fyzicky vlastnosťami existujúcich algoritmov a dostupného HW
2. Výkon DB je znižovaný vnútornou neefektívnosťou databázy
3. Výkon je znižovaný použitím neoptimálnych algoritmov, alebo neoptimálneho HW

Rýchlosť procesora Prístup na pamäťové médium
◦ Latencia◦ Náhodný prístup – frekvencia◦ Sekvenčný prístup – rýchlosť zápisu vs. čítania◦ Linearita adresného priestoru◦ Trvalosť
Komunikácia cez sieť◦ Latencia◦ Priepustnosť
Spoľahlivosť
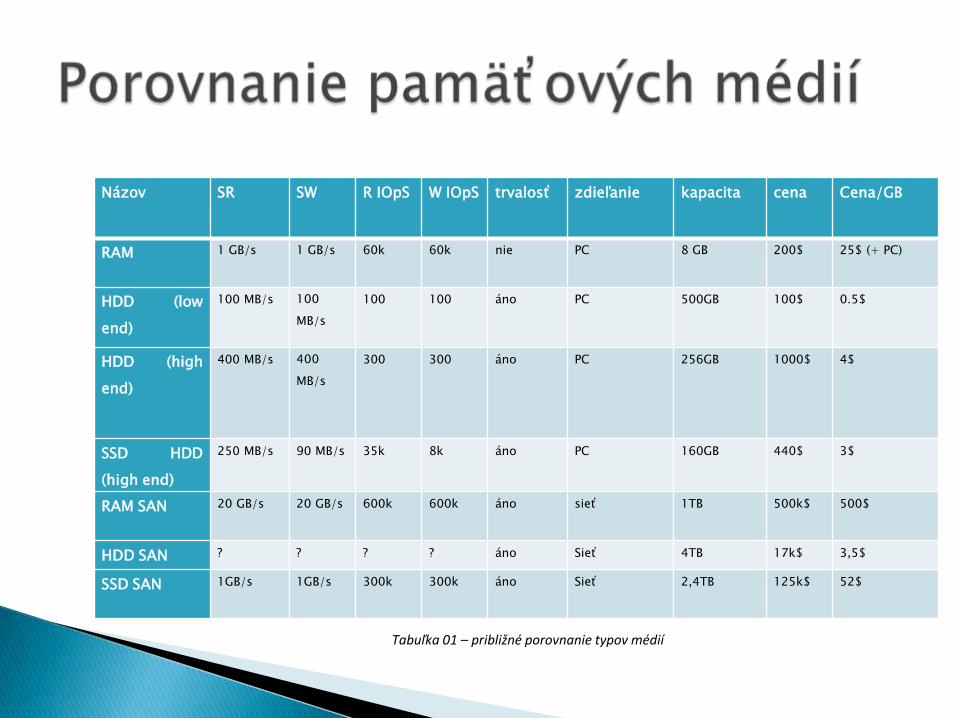
Názov SR SW R IOpS W IOpS trvalosť zdieľanie kapacita cena Cena/GB
RAM 1 GB/s 1 GB/s 60k 60k nie PC 8 GB 200$ 25$ (+ PC)
HDD (low
end)
100 MB/s 100
MB/s
100 100 áno PC 500GB 100$ 0.5$
HDD (high
end)
400 MB/s 400
MB/s
300 300 áno PC 256GB 1000$ 4$
SSD HDD
(high end)
250 MB/s 90 MB/s 35k 8k áno PC 160GB 440$ 3$
RAM SAN 20 GB/s 20 GB/s 600k 600k áno sieť 1TB 500k$ 500$
HDD SAN ? ? ? ? áno Sieť 4TB 17k$ 3,5$
SSD SAN 1GB/s 1GB/s 300k 300k áno Sieť 2,4TB 125k$ 52$
Tabuľka 01 – približné porovnanie typov médií

Vyhľadávanie polením intervalu (dáta musia byť zoradené) – O(log 2 N) – náhodné čítanie
Vyhľadávanie linárne – O(N) – sekvenčné čítanie
Cena úpravy indexov pri zápise a zmene dát
Cena tranzakčnosti (čakanie na zámky vs. reštart transakcie)
Distribuované DB◦ Cena distribuovaných tranzakcií
◦ Úprava synchrónnych replík na viacerých uzloch
◦ Náročnejšia concurrency control pri distribuovaných DB


Zníženie transaction isolation levelu Eventuálna konzistentnosť
◦ Asynchróne menená/invalidovaná cache◦ Čítanie asynchrónnej repliky (alebo
materializovaného view)◦ Vlastné riešenia „šírenia dát“◦ Konzistentné prečítanie minulosti
Slabá trvalosť Prečítanie uzamknutých, alebo
modifikovaných dát Komutatívne operácie (inkrement)
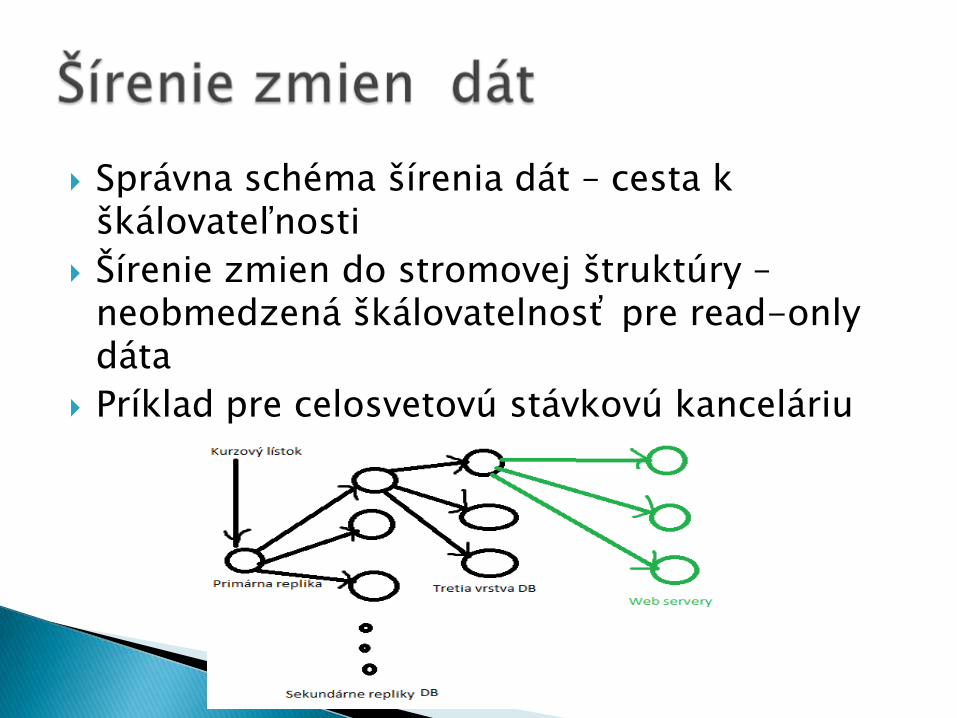
Správna schéma šírenia dát – cesta k škálovateľnosti
Šírenie zmien do stromovej štruktúry –neobmedzená škálovatelnosť pre read-onlydáta
Príklad pre celosvetovú stávkovú kanceláriu

Nemajú úplnú replikáciu
Primárne repliky rozdistribuované na viacero uzlov
Neexistuje pevný a dopredu daný kľúč rozloženia dát na uzly

Obmedzenia CAP teorémy
Kde sú dáta ktoré hľadám?!
Distribuované concurrency control
Distribuované transakcie a commit
Predefinovanie ACID podmienok
Problém N na M stavov

Konzistentnosť (Consistency)
Dostupnosť (Availability)
Odolnosť voči rozdrobeniu siete (Partitiontolerance)
Nemôžeme mať všetky tri – príklad
Môžeme mať ale rozumnú mieru všetkých
CA / AP / CP systémy
Potrebujeme skutočne P?

Statická tabuľka umiestnení
Distribuovaná hash tabuľka
Dynamická tabuľka umiestnení
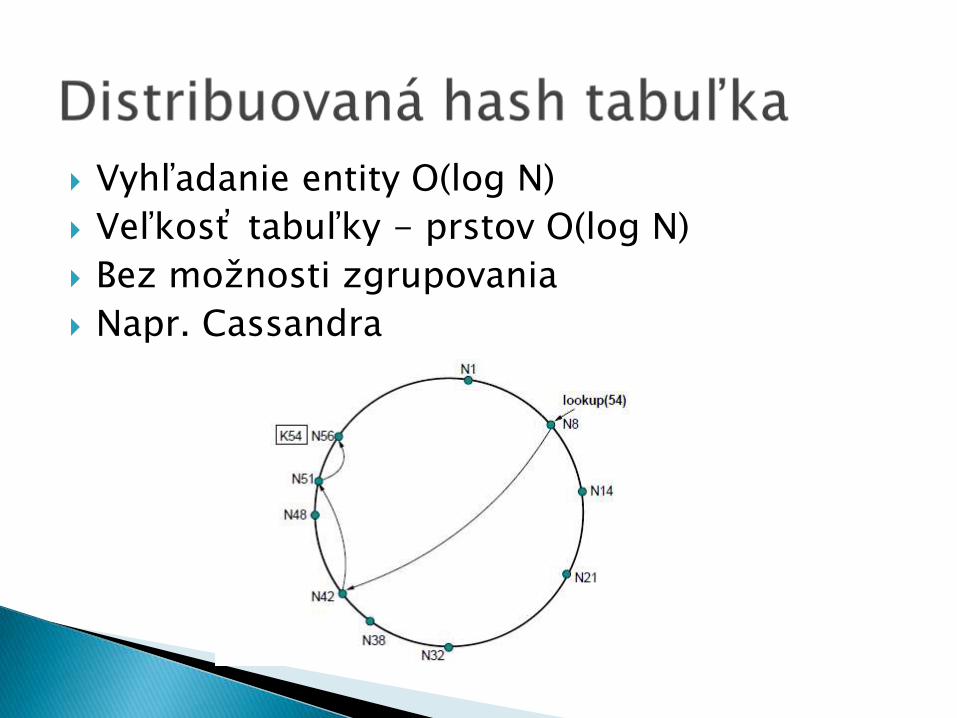
Vyhľadanie entity O(log N)
Veľkosť tabuľky - prstov O(log N)
Bez možnosti zgrupovania
Napr. Cassandra

Vyhľadanie entity - O(1)
Veľkosť tabuľky – O(N), (N/X) X – veľkosť partície
Zgrupovanie entít podľa primárneho usporiadania
Možnosť viacvrstvovej tabuľky
Napr. HBase, Google BigTable

Dvojfázové zamykanie (two phase locking)
Zoradené časové značky (timestamp ordering)
Konflikty – čakanie / reštart tranzakcie
Concurrency Control in Distributed Database Systems - PHILIP A. BERNSTEIN

Problém konsenzu◦ Komunikácia môže zlyhať v ktoromkoľvek okamihu
Dvojfázové potvrdenie◦ Náchylné na zlyhanie koordinátora
Trojfázové potvrdenie
Paxos potvrdenie◦ Odolnosť voči (N - 1)/2 zlyhaniam
◦ Náročnosť N(F + 3) / 3 správ

Dostupnosť ◦ (1 - P^n) nedostupnosti všetkých potrebných replík
Trvalosť◦ (1 – p^n) straty všetkých synchrónnych replík. P je
pravdepodobnosť zlyhania uzla za čas potrebný na vytvorenie novej repliky
Konzistentnosť (CAP)◦ Okno nekonzistentnosti / perióda zmeny
Network partition – izolácia uzla / racku / datacenta◦ Závisí od sieťovej infraštruktúry
Konzistentnosť (ACID)◦ Naruší len chyba, nesprávna kombináia algoritmov, alebo
failover na asynchrónnu/neaktuálnu repliku

Eventuálna konzistentnosť◦ Push asynchrónna replikácia zmien
◦ Pop asynchrónna replikácia zmien
One-site transakcie
Harwest a yield◦ Výsledky len z % dát

Zložitejšie algoritmy Odolnosť voči výpadku uzlov a komunikácie Problém N^M stavov Viac možností optimalizácie Testovanie Zmena schémy dát Update verzie systému za behu
Odhad: 10 – 100 krát náročnejšia implementácia, ako single node relačnej DB

Priestor na Vaše otázky