knihovny 2020: praktické využití principů sémantického webu (projekt dáme práci)
TRANSCRIPT

Praktické využití principů sémantického webuPředstavení projektu Dáme práci
Knihovny 2020: služby a technologie, 9. 12. 2015
Jakub Fialae-mail: [email protected]
Tajemník a lektor Studia nových médiíÚstav informačních studia a knihovnictvíFilozofická fakulta Univerzity Karlovy v Praze

Růst informací a způsoby jejich zpracování
V posledních dvaceti letech jsme v oblasti zpracování informací (a to nejen na internetu) svědky prudkého a často překotného růstu jejich objemu.
Tento růst je dán především technickým a ekonomickým "snížením prahu" nutného k publikaci informace v různém mediálním prostředí.
Nejdramatičtější nárůst v tomto kontextu vidíme především v oblasti WWW, kde technologická epocha označovaná jako Web 2.0 proměnila de facto všechny účastníky komunikace na webu v producenty, a zásadně tak zvětšila objem dostupných informací.
Souběžně s tímto procesem se rozvíjejí i techniky zpracování informací.

Růst informací a způsoby jejich zpracování
První jsou přístupy spojené s tradicí statistického zpracování dat (řadíme sem i nejrůznější formy data miningu, strojové učení atd.).
Druhým přístupem jsou potom techniky spojené s využíváním lidmi vytvořených ontologií, které jsou aplikovány do prostředí internetu polo-automaticky. Tento směr především ústí do oblasti nazývané sémantický web.
Statistické metody se nezajímají často o význam informace.
Sémantické techniky se především orientují na přímé využití sémantické znalosti vnořené kupříkladu do mikroformátu pro zpracování strojem.
Zjednodušeně řečeno, statistické metody se snaží vyextrahovat vzorce z chování systémů; jejich výstupy se však nesnaží napodobit lidské chápání. Oproti tomu sémantické technologie se snaží v podstatě aplikovat znalosti o lidské sémantice na strojově zpracovatelnou oblast.

Růst informací a způsoby jejich zpracování
Běžný uživatel webu se přímo nesetkává ani s jednou z technologií, přesto ale mají na jeho pohyb v tomto prostředí velký vliv. Rozhodují totiž o snadnosti dohledatelnosti informací, které uživatel na webu publikuje.
Výsledky zpracování dat pomocí statistických metod může producent informací ovlivnit jen velmi málo, byť i toto málo stojí za celou jednou obchodní oblastí na internetu nazývanou Search Engine Optimization.
Lépe je na tom tvůrce obsahu v oblasti sémantického zpracování: zde sice nemůže přímo ovlivnit pořadí výsledků ve vyhledávačích, ale může ovlivnit podobu zobrazení a kvalitu zpracování. Cestou k tomu je využití různých forem sémantických mikroformátů a mikrodat, které dnes vyhledávače (ale také sociální sítě jako Facebook) podporují.

Praktický příklad (adresa sídla firmy)
Studia nových médií FF UKU kříže 8, Praha 5 - Jinonice15800 Prague, Czech Republic

V jednoduché podobě HTML
<h3>Studia nových médií FF UK</h3 ><p class="adresa">Studia nových médií FF UK<br>U kříže 8, Praha 5 - Jinonice<br>15800 Prague, Czech Republic<br></p>

<div class="vcard"><div class="fn org">Studia nových médií FF UK</div><div class="adr"><div class="street-address">U kříže 8</div><span class="locality">Praha 5 - Jinonice</span><span class="country-name">Czech Republic</span></div></div>
<h3>Studia nových médií FF UK</h3 ><p class="adresa">Studia nových médií FF UK<br>U kříže 8, Praha 5 - Jinonice<br>15800 Prague, Czech Republic<br></p>
Při zápisu v HTML avšak stroj, který přijde na stránku, nebude vědět vůbec nic o tom, o jaký obsah se jedná. Pomoci mu můžete, pokud využijete například mikroformát hCard.
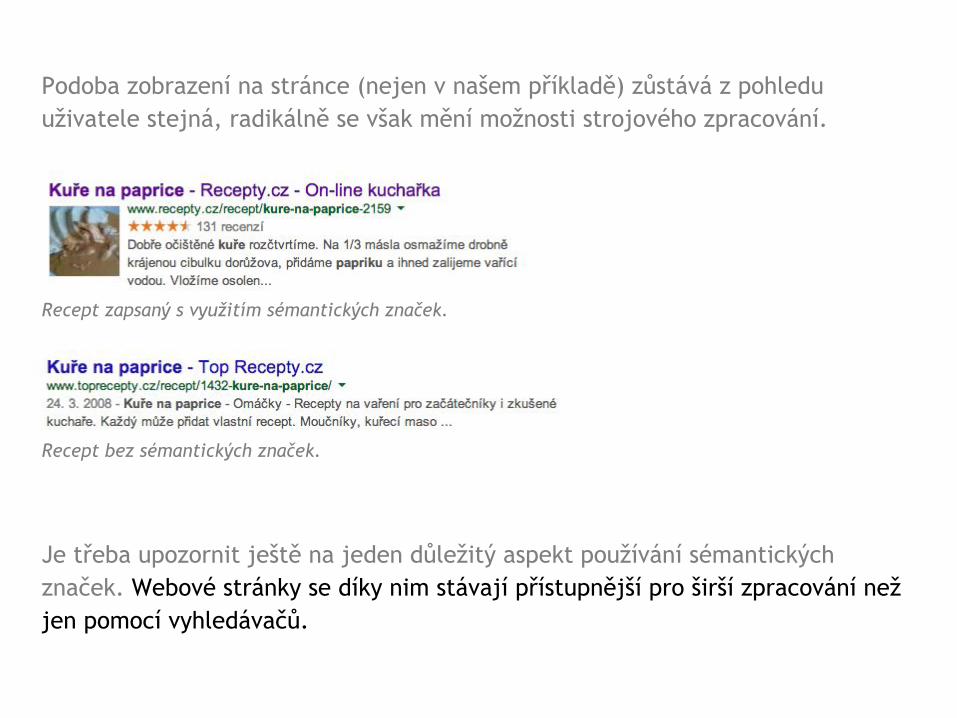
Podoba zobrazení na stránce (nejen v našem příkladě) zůstává z pohledu uživatele stejná, radikálně se však mění možnosti strojového zpracování.
Recept zapsaný s využitím sémantických značek.
Recept bez sémantických značek.
Je třeba upozornit ještě na jeden důležitý aspekt používání sémantických značek. Webové stránky se díky nim stávají přístupnější pro širší zpracování než jen pomocí vyhledávačů.

"Dáme práci" jako aplikace principů sémantického webuPlný název projektu zní Využití mezinárodních zkušeností s business ontologiemi pro návrh a vývoj platformy propojení nezaměstnaných s poskytovali přímých nabídek práce prostřednictvím hyperlokálních služeb.
Řešitelem projektu byla Univerzita Karlova prostřednictvím pracoviště Studia nových médií na FF UK. Projekt byl financován z Evropského sociálního fondu prostřednictvím Operačního programu Lidské zdroje a zaměstnanost a ze státního rozpočtu České republiky.
Jádrem projektu byl návrh a vývoj platformy propojení nezaměstnaných s poskytovateli přímých nabídek práce prostřednictvím hyperlokálních služeb. V praxi nešlo jen o vytvoření specifikace mikrodat použitelných pro webové nabídky práce, ale také o přenesení způsobů jak takové specifikace vytvářet a navržení a vytvoření softwarové infrastruktury pro ni. Webová služba www.damepraci.cz pak demonstruje možnosti, které platforma nabízí.

"Dáme práci" jako aplikace principů sémantického webuCílem projektu není (a nikdy nebylo) konkurovat komerčním subjektům, ale naopak vstoupit do míst, která nejsou pro většinu z nich lukrativní.
Považovali jsme za užitečné přispět technologickým řešením postaveným na principech sémantického webu, které by využívalo jeho hlavní výhody: jednoduchost implementace a snadnost zpracování na straně poskytovatele informací (a zaměstnání), a zároveň poskytovalo nekomerční platformu, která by se vyhnula problémům tradičních řešení (tj. zejména uzavření dat), jež mají své důvody, v konečném důsledku však přinášejí zpomalení toku informací na trhu práce.

Projekt byl příležitostí vyzkoušet si v praxi i několik postupů při tvorbě ontologií pro sémantické projekty.

Postup analýzy dat a vznik datového modelu
Začali jsme rozhovory s doménovými experty. Byli mezi nimi jak nezaměstnaní, tak odborní garanti projektu z Katedry sociální práce na FF UK, stejně jako zástupci zaměstnavatelů.
Z rozhovorů jsme extrahovali často se opakující struktury v požadavcích potenciálních zaměstnavatelů, stejně jako uchazečů o práci. Zvláštní pozornost jsme věnovali otázce priorit při popisu zaměstnance, popisu práce i při rozhodování se o nabídce práce.
Získané informace jsme konfrontovali s daty nabídek práce samotných (dataset čítal více než 1000 inzerátů), v analýze jsme postupovali jak kvalitativní, tak kvantitativní metodou.
Při kvalitativní části jsme ručně označovali inzeráty podle přítomnosti atributů jako je plat, typ úvazků, vzdělání apod. Pro kvantitativní část jsme si vytvořili jednoduchý nástroj nazvaný Corpus Viewer, který kvantifikoval souvýskyt slov, a umožnil tak exaktně potvrdit některé hypotézy nad českými daty.
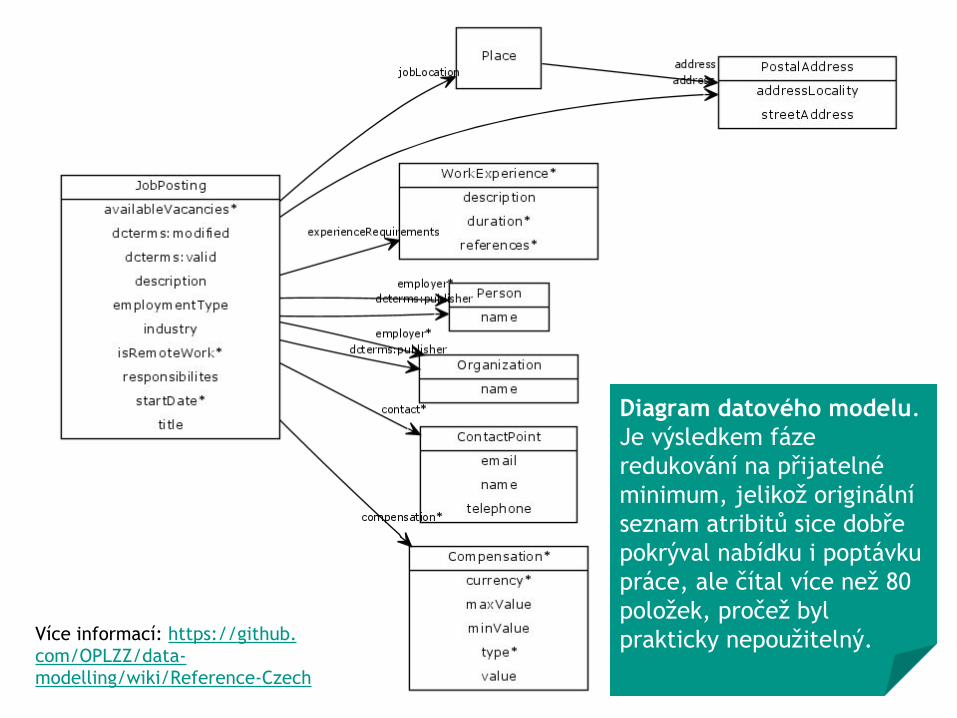
Diagram datového modelu.Je výsledkem fáze redukování na přijatelné minimum, jelikož originální seznam atribitů sice dobře pokrýval nabídku i poptávku práce, ale čítal více než 80 položek, pročež byl prakticky nepoužitelný.Více informací: https://github.
com/OPLZZ/data-modelling/wiki/Reference-Czech

S finálním datovým modelem nastal problém: jakou cestou se vydat pro specifikaci mikrodat?

Specifikace mikrodat
Na jednu stranu bylo možné vytvořit zcela nové značky, které by přesně vyhovovaly potřebám našeho projektu – tím bychom ale prudce snížili jejich šanci na uplatnění. Anebo jsme mohli využít pro popis kombinaci stávajících značek, které jsou podporovány světovými vyhledávači a jsou k dispozici na stránkách www.schema.org.
Zvolili jsme variantu co nejdéle postupovat podle dostupných specifikací a nové navrhovat jen v nutných případech. Díky tomu je specifikace mikrodat pro náš datový model z 80 % kompatibilní s mikrodaty již přijatými.
Podrobné zdroje k prostudování
Úvod k zápisu strukturovaných dat do webových stránek pomocí RDFa
Recept na vyznačení nabídky práce pomocí RDFa

Ukázka značení sémantickými značkami (RDFa)Vyznačení nabídek práce na webu pomocí sémantických značek (v našem případě RDFa) zajistí čitelnost pro stroje a nijak neovlivní jejich podobu pro návštěvníky stránek. RDFa (druh sémantického značení) je způsob, jak říci stroji, co určitá informace na webu znamená.
Přidání značek do HTML kódu stránky zajistí, že pracovní inzerát bude strukturovaný a aplikace jako je Dáme práci s ním dokáže samostatně pracovat.
Platí zde základní pravidlo, že čím více informací poskytnete (označkujete) strojům k automatizovanému zpracování, tím lépe, avšak i velmi malý vstup představuje významnou kvalitativní změnu.
Zdroj obrázku.

Krok č. 1 (bez toho to nebude fungovat)
Aby bylo možné pracovní inzeráty rozpoznat a nabízet je lidem používající aplikaci, je nezbytně nutné přidat následující dvě podbarvené značky. Označení jazyka je vhodné, ale není nezbytné.
krok příklad
Do elementu <html> přidejte atribut vocab="http://schema.org/"
<html vocab="http://schema.org/">
Do elementu <html> přidejte označení jazyka webové stránky pomocí atributu lang="cs", pokud je stránka v češtině.
<html vocab="http://schema.org/" lang="cs">
Do elementu <body> přidejte atribut typeof="JobPosting".
<body typeof="JobPosting">

Kterýkoliv z dalších kroků týkající se popisu inzerátu v elementu <body> lze přeskočit. Toto jsou příklady těch nejčastějších.
Uvnitř elementu <body> popište nabídku práce.
Element obsahující text názvu pracovní pozice označte atributem property="title".
<h1 property="title">skladník</h1>
Element obsahující textový popis pracovní pozice označte atributem property="description".
<p property="description">Společnost ACME s.r.o. hledá nové zaměstnance na pozici Skladník/ce - Řidič/ka VZV v lokalitě Ostrava.</p>
Datum nástupu do práce označte atributem property="startDate". Strojově čitelnou verzi data zapište jako hodnotu atributu content ve tvaru RRRR-MM-DD.
Datum nástupu: <span property="startDate"
content="2013-04-01">1. dubna 2014</span>
Typ pracovního úvazku lze popsat atributem property="employmentType".
Úvazek: <span property="employmentType">plný
úvazek</span>

Uvnitř elementu <body> vyznačte adresu pracoviště.
Část stránky obsahující adresu pracoviště zabalte do elementu označeného atributem rel="jobLocation".
<div rel="jobLocation">
…</div>
Uvnitř tohoto elementu popište ulici a číslo popisné v elementu s atributem property="streetAddress".
<p property="streetAddress">Místecká 126</p>
Obec, v níž se pracoviště nachází, označte atributem property="addressLocality".
<p property="addressLocality">Ostrava</p>
Uvnitř elementu <body> vyznačte údaje, jak je možné kontaktovat zaměstnavatele.
Část stránky s kontaktními údaji zabalte do elementu s atributem rel="contact".
<div rel="contact">
…</div>
Uvnitř tohoto elementu označte jméno kontaktní osoby pomocí atributu property="name".
<p property="name">Jan Hluchý</p>
Pokud je kontaktním údajem telefonní číslo, označte ho atributem property="telephone".
<span property="telephone">420 123 456
789</span>
Emailovou adresu můžete označit pomocí atributu property="email".
<span property="email">jan.hluchy@acme.
cz</span>

Sémantické značení na webu je užitečné
Obsah svého webu můžete díky sémantickým značkám šířit snadno a zdarma k těm, kdo vás hledají / koho hledáte.
Pokud vás toto téma zajímá a chcete vědět, jakým dalším způsobem mohou být pro vás sémantické značky na webu užitečné (a to zdaleka ne jen v oblasti pracovních nabídek), doporučuji příspěvek Jindřicha Mynarze a Josefa Petráka s názvem Advertising throught structured data on the Web, který je součástí sborníku (s. 228) z mezinárodní konference Semantic Web in Business.
Značkuji, tedy jsem.
Zdroj obrázku.

Výstupy, o kterých jsme doposud hovořili, nejsou primárně určeny pro cílovou skupinu uchazečů.
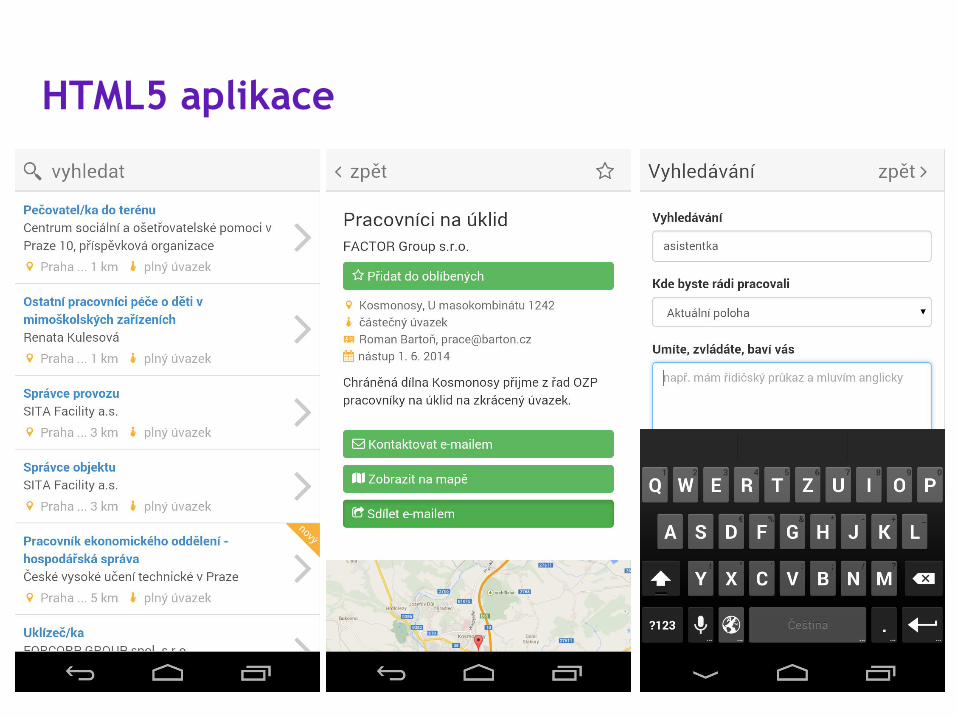
Té je totiž určena HTML5 aplikace, která běží na doméně www.damepraci.cz.

HTML5 aplikace
Již v začátku projektu jsme se rozhodli pro vytvoření HTML5 aplikace, která bude moci fungovat nejen na webu, ale také jako aplikace pro mobilní telefony (na platformě Android i iOS). Volba responsivního designu navíc zajistila, že aplikace vypadá v zásadě vždy stejně, bez ohledu na zařízení, na němž je využívána. Mění se jen počet na první pohled viditelných obrazovek.
Pro design byly zvoleny velké dotykové plochy, které na webu vyhovují starším uživatelům a zároveň v prostředí mobilní aplikace působí přirozeně.
Pokud jde o neochotu skupiny 50+ sdílet osobní informace, rozhodli jsme, že po uživatelích služby nebudeme vyžadovat registraci. Informace, které nám o sobě napíší lidé při vyhledávání, budeme ukládat na klientské straně a vždy znovu posílat. V praxi tak na naší straně neexistuje žádná informace o identitě uživatele.
HTML5 aplikace

Uplatnitelnost v praxi a další výhledy
Určitou inspirací pro náš projekt byly hyperlokální nabídky mikroprací známé z USA. Ty v podstatě umožňují zadávat drobné, sousedské práce ve větších městech. Mezi takové práce patří kupříkladu odvoz nákupu, sklizení ovoce či větší úklid v domě.
Služby jako TaskRabbit nabídkou mikroprací pomáhají nejen lidem bez práce alespoň k nějakému výdělku, ale také jim pomáhají udržovat sociální kontakt, což je pro dlouhodobě nezaměstnané nesmírně důležité. Bohužel česká právní úprava není v tomto ohledu příliš jednoznačná, a tak se lidé do mikroprací příliš nepouštějí, aby se nedopustili neoprávněného podnikání. Navíc je tento druh příjmu limitován maximální částkou 30.000 Kč ročně.
Z dlouhodobého pohledu je ale zřejmě tato situace neudržitelná a je velmi pravděpodobné, že dojde k uvolnění trhu v této oblasti i u nás. Aplikace Dáme práci s takovou variantou počítá a je na ni připravena.

Uplatnitelnost v praxi a další výhledy
Přestože samotná aplikace byla z hlediska projektu pilotáží, a prakticky má pouze demonstrovat funkčnost celého vyvinutého originálního řešení, jenž je díky otevřeným licencím, kterými jsou všechny jeho součásti opatřeny, snadno přenositelné např. do jiné země (ať už v rámci EU nebo i za jejími hranicemi).
HTML5 aplikaci stále provozujeme a snažíme se, alespoň v rámci svých omezených možností, i o její rozvoj a další zpřístupnění.
V roce 2016 bychom rádi spustili možnost snadno aplikaci embedovat do vlastních webových stránek, aby instituce jako jsou knihovny či neziskové organizace mohly efektivním způsobem zpřístupnit svým klientům tento druh služeb, aniž by se o provoz museli starat nebo s ním měli nějaké náklady.

Děkuji za pozornost.http://uisk.ff.cuni.cz/
http://novamedia.ff.cuni.cz/
http://damepraci.cz/
http://damepraci.eu/
https://github.com/OPLZZ/
http://schema.org/
Zdroj obrázku.