learning better embeddings for rare words using distributional representations
TRANSCRIPT

Learning Better Embeddings for Rare Words Using Distributional Representations
by YIrina Sergienya, Hinrich Schuze
担当: @Quasi_quant2010
EMNLP2015読み会1
【EMNLP2015読み会】

概要- SGとCBOWを混合させたレアワード分散表現 -
EMNLP2015読み会2
Skip-Gram Negative Sampling(SGNS)は主に頻出語に関する分散表現を構築していた
SGNSがshifted PMIを用いた行列分解であることが分かってきており、次元圧縮により単語の潜在ベクトルを計算
→レアワードは主な計算対象になっていない
本報告は、レアワードに関する分散表現を得る為どの様なモデルを考えればよいかを考察している
Skip-GramとCBOWを混合して表現するほうがよい

先行研究- 単語だけでなく、他ソースを用いた分散表現 -
レアワードは単語のコンテキスト情報が不十分なので、その他情報を用いて、過不足を補っている
形態素:[COLING14] S.Qiu, etc
句構造:[CVSC15] K.Hashimoto, etc
レアワードに関する分散表現を構築する際、先行研究ではCBOWも用いられている
Skip-GramとCBOWは言語現象の近似に、向き不向きがあるらしい
SGとCBOWはどんな現象を近似するのか
EMNLP2015読み会3

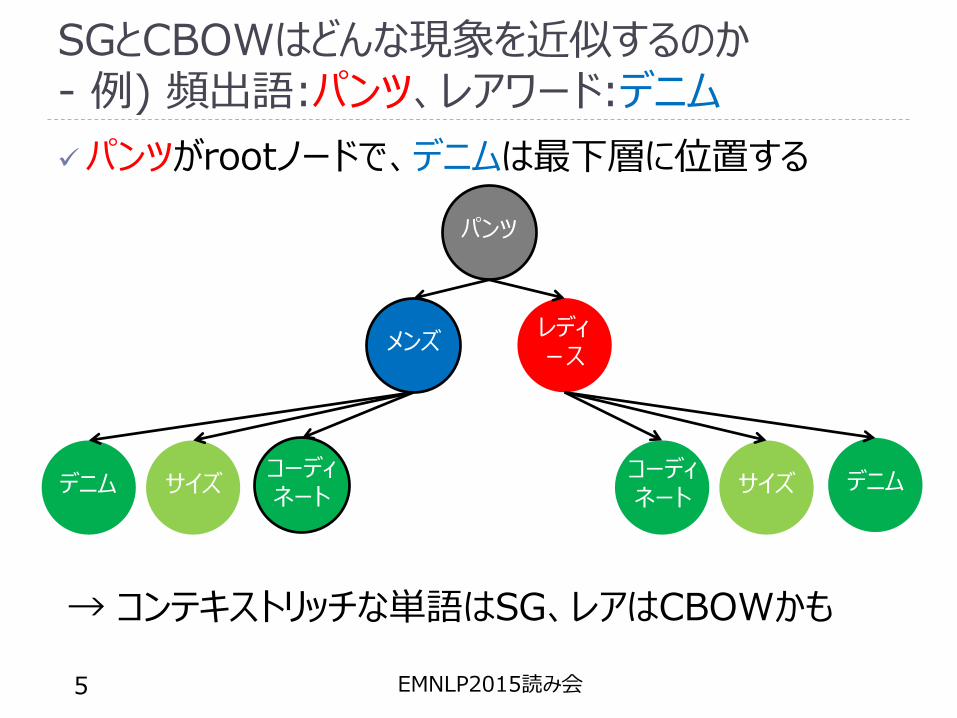
SGとCBOWはどんな現象を近似するのか- 例) 頻出語:パンツ、レアワード:デニム
EMNLP2015読み会4
パンツ
パンツ メンズ パンツ レディース
パンツ メンズ コーディネート パンツ レディース コーディネート
パンツ メンズ コーディネート デニム パンツ レディース コーディネート デニム
パンツ メンズ コーディネート デニム ファッション パンツ レディース コーディネート ジャケット チェック
パンツは多くのコンテキストを持つがデニムは少ない
→ パンツは多くのコンテキストを持つがデニムは少ない
→ パンツは多くの分岐を持つがデニムは少ない
注) dmenuのクエリサジェストから抜粋
SGとCBOWはどんな現象を近似するのか- 例) 頻出語:パンツ、レアワード:デニム
パンツがrootノードで、デニムは最下層に位置する
EMNLP2015読み会5
パンツ
メンズレディ-ス
コーディネート
コーディネート
サイズデニム サイズ デニム
→ コンテキストリッチな単語はSG、レアはCBOWかも

再考 : SGとCBOWはどんな現象を近似するのか- コンテキストリッチな単語はSG、レアはCBOW? -
EMNLP2015読み会6
注) word2vec Parameter Learning
Explainedから抜粋
パンツ
デニム
サイズ
コーディネート
パンツ
デニム
メンズ
コーディネート

モデル- Binary設定でのSGC・BOW混合 -
SeparateはSGとCBOWが完全に独立
頻出語の閾値はΘで制御(freq.words≧Θ)
MixはSGとCBOWを混合
CBOWのコンテキストckはターゲットviと10回以上共起
ck = 1 if (vi, ck) ≧ 10 (otherwise ck = 0)EMNLP2015読み会7
SG
CBOW CBOW
SG
CBOWのインプットベクトルに頻出語を含むか否か
①:Separate ②:Mix

実験設定- レアワード表現獲得のため、コーパスはDownSampling -
コーパス(ukWac, WaCkypedia)
2.4billion tokens, 6million vocabulary
評価データ
有名どころを6つ
Stanford Rare Wordが本報告の目的にあっている
評価値
スピアマン順位相関(人間評価と計算結果)
パラメータ
頻出語・レアワードの表現行列
頻出語の閾値はΘで制御(freq.words≧Θ)
Binary表現以外に、[0,1]でスケーリングしたPMIも計算
1-of-K表現よりスムージングさせる狙い?EMNLP2015読み会8

結果(Binary)- Skip-Gram vs Skip-Gram+CBOW -
Θ(頻出語の閾値)が20以下の場合、概ね SG < SG+CBOW Separate (SGCS) < SG+CBOW Mix(SGCM)
SG < SGCS
レアワードのCBOWを独立に混合した効果
SGCS < SGCM
レアワードのコンテキストに頻出語を含めた効果
EMNLP2015読み会9
注)Table1より抜粋。何れも、5回実験
した平均値

結果(PMI∈[0,1])- Skip-Gram vs Skip-Gram+CBOW -
概ね SG < SG+CBOW Separate (SGCS) < SG+CBOW Mix(SGCM)
SGCM(Binary) < SGCM(PMI)
おそらく1-of-K表現する際、BinaryでなくPMIでスムージングした効果が性能向上に寄与している
Θ∈{10,20,50,100}
レアワード分散表現を計算する場合、頻出語閾値は20が良いEMNLP2015読み会10
注)Table1より抜粋。何れも、5回実験
した平均値

感想- コンテキストリッチな単語はSG、レアはCBOW -
レアワードは単語のコンテキスト情報が不十分なので、良い分散表現を作るため、ターゲットワードと共起するワードを追加することで、コンテキスト情報をリッチにした。
不十分なコンテキスト情報を追加情報で補う流れは共通手法
基礎・追加コンテキストを同時にモデル化するためSG・CBOWを混合
レアワードに関する分散表現構築というより、SG・CBOWがどの様に現象を近似するかという考察をしてみたくなった
EMNLP2015読み会11

参考文献 [S.Qiu] Co-learning of Word Representations and Morpheme
Representations. COLING14
[N.Djuric] Hierarchical Neural Language Models for Joint Representation of Streaming Documents and their Content. WWW15
[K.Hashimoto] Learning Embeddings for Transitive Verb Disambiguation by Implicit Tensor Factorization. CVSC15
[X.Rong] word2vec Parameter Learning Explained. arXiv14
[O.Levy] Improving Distributional Similarity with Lessons Learned from Word Embedding. TACL15
[O.Levy] Neural Word Embedding as Implicit Matrix Factorization. NIPS14
[Y.Li] Word Embedding Revisited: A New Representation Learning and Explicit Matrix Factorization Perspective. IJCAI15
EMNLP2015読み会12