learning convolutional neural networks for graphs
TRANSCRIPT

Learning Convolutional Neural Networks for GraphsMathias Niepert, Mohamed Ahmed, Konstantin Kutzkov
秋葉拓哉 (Preferred Networks, Inc.)ICML 2016 読み会 @ ドワンゴセミナールーム, 2016/07/21

⾃⼰紹介
l 名前:秋葉 拓哉
l Twitter, GitHub:@iwiwi
l 経歴:東⼤今井研 (博⼠) → NII (特任助教) → PFN (リサーチャー, 7/1 ⼊社!)
l 今年の戦歴:KDDʼ16, IJCAIʼ16, VLDBʼ16×2, CIKMʼ16×2
仕事内容l これまで:⼤規模グラフのデータマイニング
l PFN:深層学習関係
今⽇は両⽅関係ありそうな論⽂を選んでみました
2

論⽂概要
グラフを CNN に突っ込むがほぼ全て!
課題
l でも、突っ込み⽅が難しい
l 似た構造が似た突っ込まれ⽅をされてほしい
アルゴリズム概要
l 頂点を決まった個数選んで、その近傍を取り出す
l ラベリングによる特徴付けを使って順序を付ける3

背景なぜグラフを NN に突っ込むのが難しいか?

グラフの分類
想定する状況
l グラフが⼤量にある
l 分類をしたい
応⽤例
1. 化学化合物の作⽤を分類する
2. 分⼦(タンパク質)の空間構造から酵素か否かを分類する
3. ⽂や⽂章の構造を分類する本論⽂の実験では 1 と 2 のデータが使われています。
5
[Ralaivola+, 2005, Fig. 2]

グラフの分類の難しさ
そもそも グラフが同⼀か を判定する
ことすら 計算困難!(グラフ同型性判定問題)
6
(wikipediaより)
※ここで計算困難とは多項式時間アルゴリズムが見つかっていないという意味

グラフの分類の難しさ
信号や画像のようなデータと違う難しさ
l ⼊⼒データで使われる頂点番号に意味が無い
l 頂点番号の置換に影響されない特徴を取りたい7

既存研究:グラフカーネル
グラフ同⼠の類似度を測るグラフカーネルが使われてきた
⾊々なグラフカーネルl Shortest-Path Kernell Random Walk Kernell Graphlet Count Kernell Weisfeiler-Lehman Kernel
↑簡単で実際の性能も⾼い&本論⽂でも使うので紹介
8
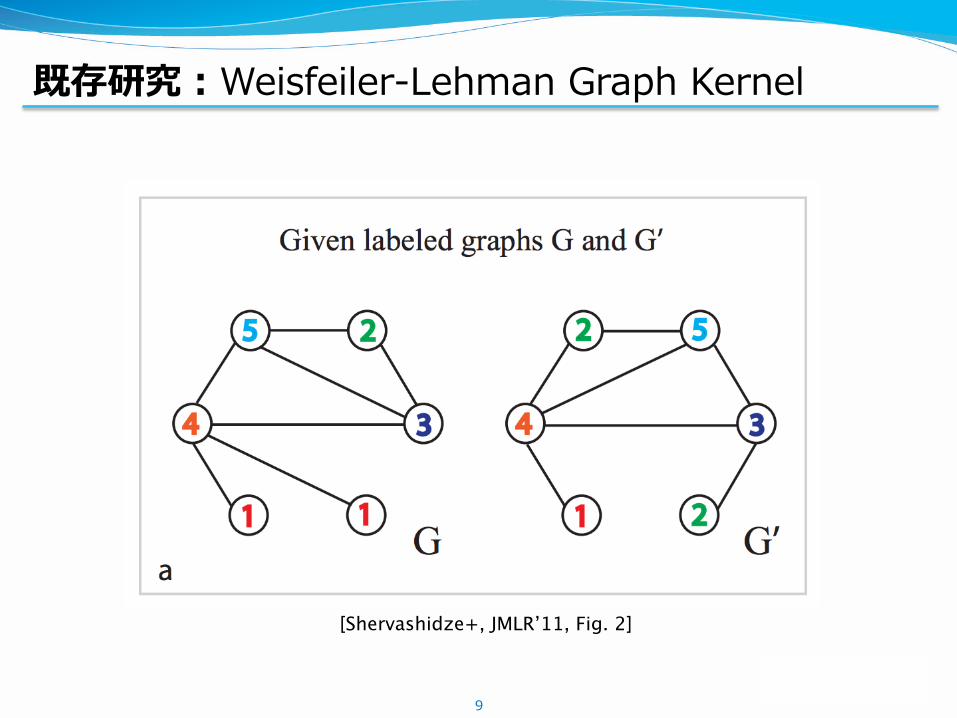
既存研究:Weisfeiler-Lehman Graph Kernel
9
[Shervashidze+, JMLR’11, Fig. 2]
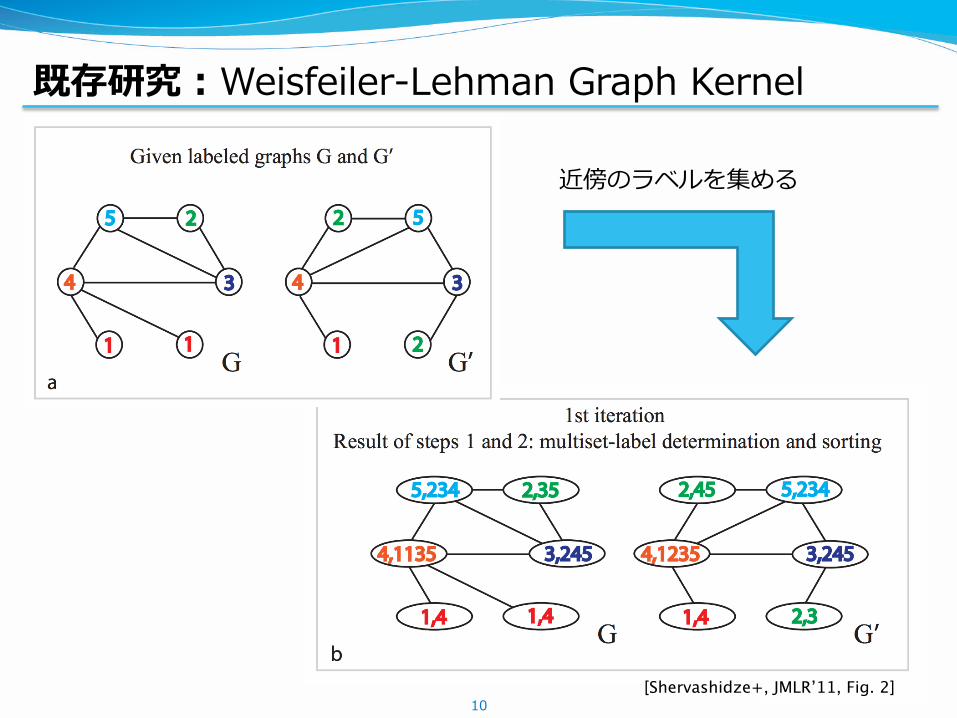
既存研究:Weisfeiler-Lehman Graph Kernel
10[Shervashidze+, JMLR’11, Fig. 2]
近傍のラベルを集める

既存研究:Weisfeiler-Lehman Graph Kernel
11[Shervashidze+, JMLR’11, Fig. 2]
ラベルを振り直す
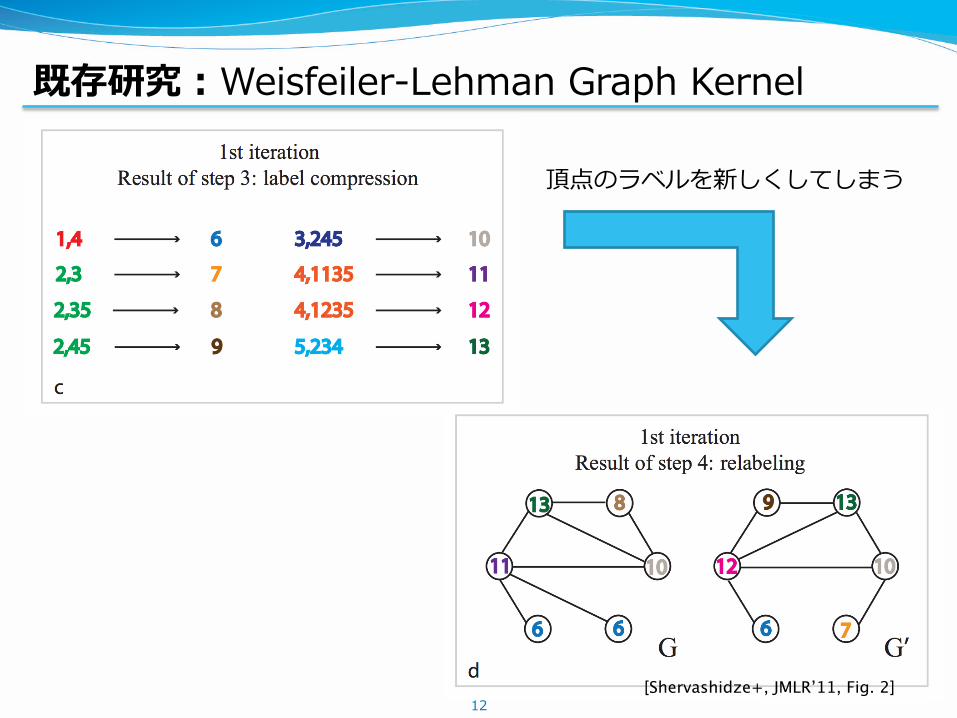
既存研究:Weisfeiler-Lehman Graph Kernel
12[Shervashidze+, JMLR’11, Fig. 2]
頂点のラベルを新しくしてしまう

既存研究:Weisfeiler-Lehman Graph Kernel
13[Shervashidze+, JMLR’11, Fig. 2]
これを繰り返した最終的なグラフ
multisetとみなす

提案⼿法:Patchy-san

アルゴリズム概要
⼊出⼒
l ⼊⼒:頂点のみにラベルのついたグラフ(1つ)
l 出⼒: (w, k, a) のテンソル(→ CNN に突っ込む)
15
CNN
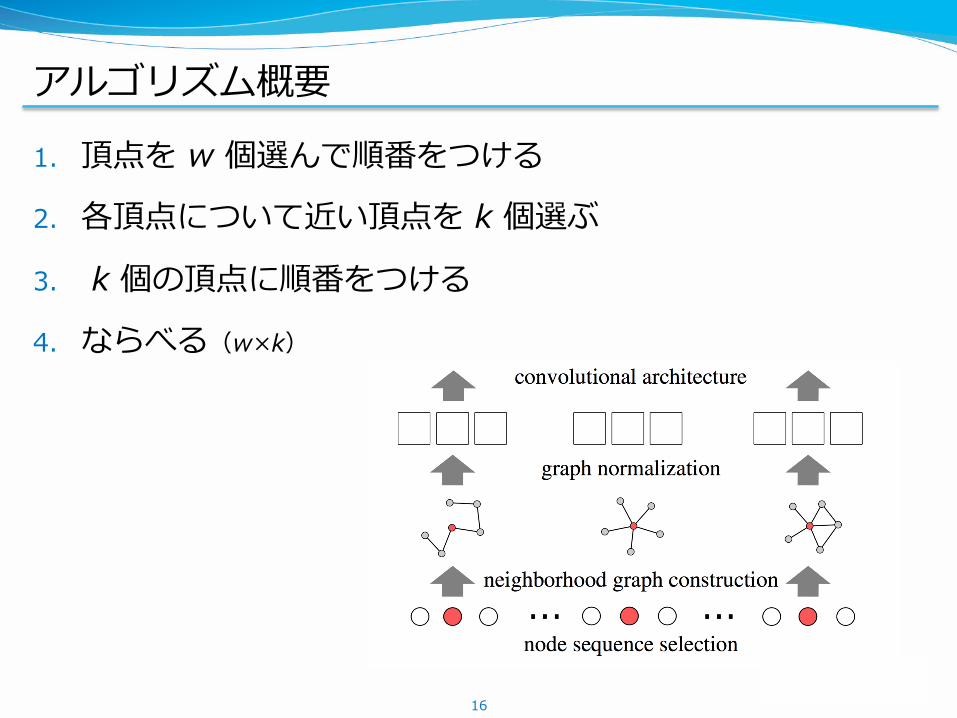
アルゴリズム概要
1. 頂点を w 個選んで順番をつける
2. 各頂点について近い頂点を k 個選ぶ
3. k 個の頂点に順番をつける
4. ならべる(w×k)
16

ステップ1:頂点を w 個選択し順番をつける
Weisfeiler-Lehman (WL) のラベルを使う
1. WL のラベルで頂点をソート
2. ⼩さいやつから順に w 個を選択
同じような近傍構造を持つ頂点をテンソル内の同じような位置に持ってきたい。
少なくとも WL ラベルが同じ頂点は相対的な位置として近い場所に来る。
17
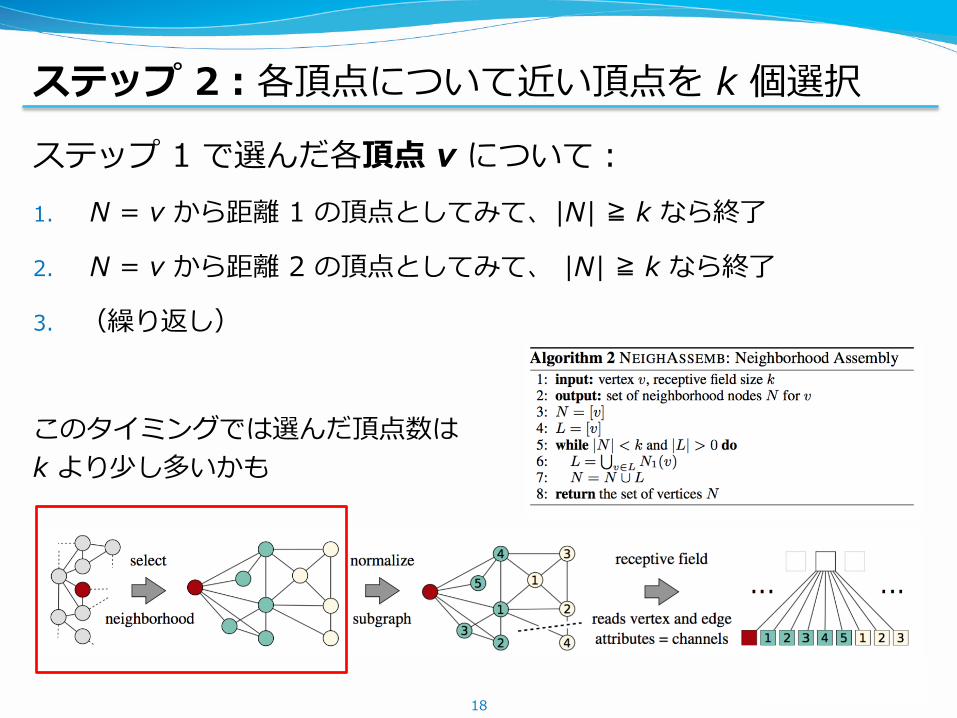
ステップ 2:各頂点について近い頂点を k 個選択
ステップ 1 で選んだ各頂点 v について:1. N = v から距離 1 の頂点としてみて、|N| ≧ k なら終了
2. N = v から距離 2 の頂点としてみて、 |N| ≧ k なら終了
3. (繰り返し)
このタイミングでは選んだ頂点数はk より少し多いかも
18

ステップ 3:k 個の頂点に順番を付ける
頂点 v とその近傍集合 N について:1. まず v からの距離で昇順ソート
2. 同じ距離のものは WL ラベルでソート
3. N が k 個より多ければ top-k だけにする
19

ステップ 4:ならべてテンソルを作るl 縦に w 個の頂点(ステップ 1)を並べる
l 横に k 個の頂点(ステップ 2&3)を並べる
l 各頂点の持つ属性が a 次元のベクトルとする
サイズ (w, k, a) のテンソルの完成!これを CNN に⼊れる!
(実際には 2D のほうが便利なので wk×a の⾏列にしているようだ)
20

アルゴリズム概要(おさらい)
1. 頂点を w 個選んで順番をつける
2. 各頂点について近い頂点を k 個選ぶ
3. k 個の頂点に順番をつける
4. ならべる(w×k)
21

理論的性質
Theorem 4:計算量l このアルゴリズムはほぼ線形時間で動作
Theorem 3:正当性(?)l グリッドグラフに適⽤すると、画像と同じく正⽅形が取られ、
画像に対する CNN と同じ挙動になるという主張だと理解しましたがあまり良くわからないです。証明も省略されている。
22

実験結果

実験設定提案⼿法:Pachy-san + CNNl w = 平均頂点数、k = 5, 10
l 3 層:畳み込み, 畳み込み, 全結合, softmax1層⽬の畳み込みはフィルターが (1×k) でストライドが k → すっぽり各頂点ずつ
l graph-tool, Keras on Theano
既存⼿法:グラフカーネル + SVMl SP (Shortest-Path Kernel), RW (Random Walk Kernel)
GK (Graphlet Count Kernel), WL (Weisfeiler-Lehman Kernel)
l LIB-SVM
データセットl MUTAG, PCT, NCI1, NCI109 …… 化学化合物
l PROTEIN, D&D …… 分⼦(タンパク質)の空間構造
24

実験結果
PSCN:提案⼿法(Pachy-san+CNN)、PSLR:Pachy-san+ロジスティック回帰
雑な要約
l 精度:⾼い(常にそこそこ上位)
l 速度:速い(既存⼿法内で⾼速な WL よりも速い)
25

特徴の可視化
Pachy-san の出⼒を可視化したもの
26

細かいこと・関連研究

細かいこと
l 属性は離散でも連続でもいい– 実はこれはグラフカーネル界隈的には重要
– WL カーネル等のカーネルは離散でしか使えない
– 連続属性向けのカーネルは性能が劣る傾向にあった
l 頂点属性だけでなく辺属性も対応できる
– k 個の頂点の属性を並べる代わりに、隣接⾏列のように k2 個の属性を並べる
– 頂点属性・辺属性を同時に使うこともできる
28
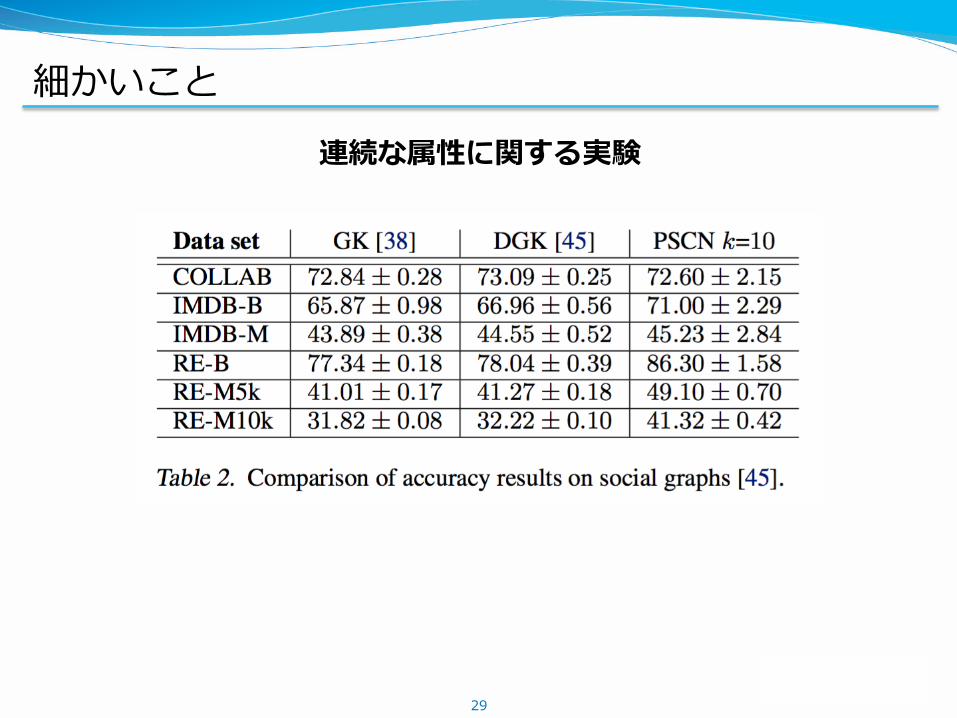
細かいこと
連続な属性に関する実験
29
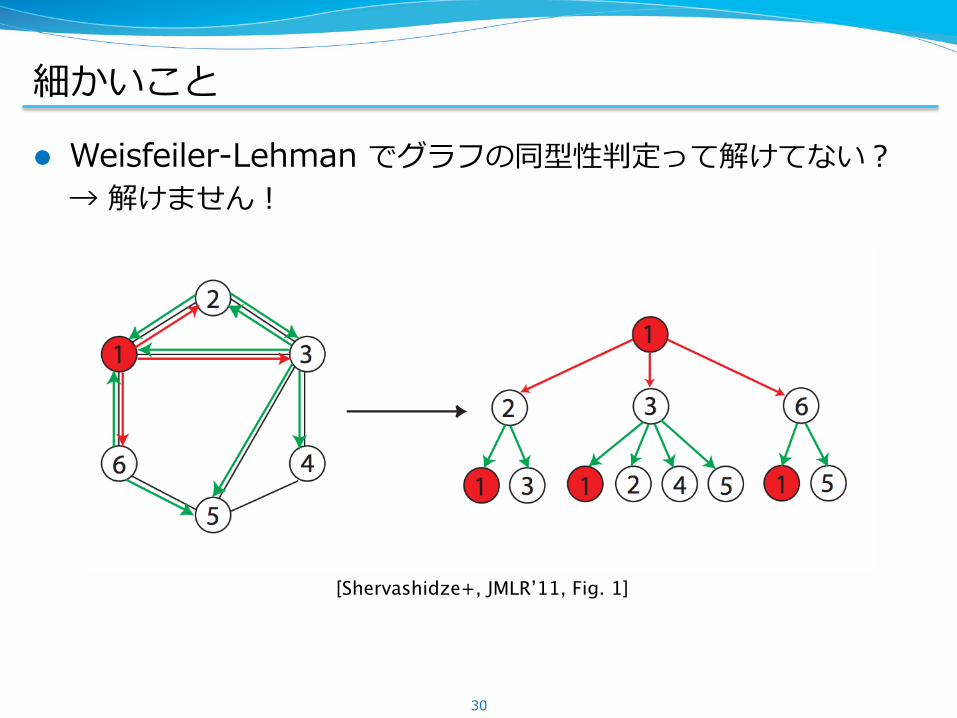
細かいこと
l Weisfeiler-Lehman でグラフの同型性判定って解けてない?→ 解けません!
30
[Shervashidze+, JMLR’11, Fig. 1]

細かいこと
l ラベリングは Weisfeiler-Lehman でなくても良い
– 類似した頂点が類似した値を取るような指標であれば良い
– 次数、中⼼性、PageRank, ......
l 同じラベルになった頂点の tie-breaking には Nauty を使う
– Nauty はグラフ同型性判定関連のツール
31

関連研究l Halting in Random Walk Kernels (NIPSʼ15)
– Random Walk Kernel が理論的に微妙という話
– 阪⼤の杉⼭さん
l DeepWalk: Online Learning of Social Representations (KDDʼ14)
l node2vec: Scalable Feature Learning for Networks (KDDʼ16)
– ソーシャルグラフのような⼤きなグラフが 1 つある状況
– 各頂点の構造的な⽴ち位置を表すベクトルを出⼒する
32

関連研究l Efficient Top-k Shortest-path Distance Queries on Large Networks
by Pruned Landmark Labeling (AAAIʼ15)
– 秋葉、林くん、則さん、岩⽥さん、吉⽥さんの研究(宣伝)
– グラフ上の 2 点間の関係を表現するベクトルを計算
– SVM に突っ込んでグラフの構造を予測
33

まとめ

まとめ
グラフを CNN に突っ込む課題
l 似た構造が似た突っ込まれ⽅になるようにテンソルにする
アルゴリズム
l 既存の特徴付け (Weisfeiler-Lehman) で順序を付けて並べる
実験結果
l ⾼精度かつ⾼速
35

個⼈的な感想l 前処理が多く、Weisfeiler-Lehman ラベリングにかなり頼っている
– 特徴の抽出はできるだけ NN に移譲したいが、グラフはやはり難しい……
– とはいえこれまでのカーネルよりは NN に移譲できているということか
l ラベリングの影響がどの程度なのかかなり気になる
– 著者いわく媒介中⼼性を使ってもほぼ同様だったらしい
– そもそもランダム置換と⽐較してほしい
l とはいえ悪くない精度は出ているし、NN の枠組みの中でグラフも他のデータと統合的に扱えるようになるのはとても良い
36