lvths. htlan phuong
TRANSCRIPT

HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG ---------------------------------------
Hoàng Thị Lan Phương
VỀ GIẢI THUẬT K-MEANS SUY RỘNG VÀ THỬ NGHIỆM NHẬP ĐIỂM TIẾNG NÓI TIẾNG VIỆT
Chuyên ngành: Truyền dữ liệu và Mạng máy tính Mã số: 60.48.15
TÓM TẮT LUẬN VĂN THẠC SĨ
HÀ NỘI – 2012

2
Luận văn được hoàn thành tại:
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG
Người hướng dẫn khoa học: PGS. TS. Nguyễn Quang Hoan ………………………
Phản biện 1: ……………………………………………………………………………
Phản biện 2: …………………………………………………………………………..
Luận văn sẽ được bảo vệ trước Hội đồng chấm luận văn thạc sĩ tại Học viện Công
nghệ Bưu chính Viễn thông
Vào lúc: ....... giờ ....... ngày ....... tháng ....... .. năm ...............
Có thể tìm hiểu luận văn tại:
- Thư viện của Học viện Công nghệ Bưu chính Viễn thông

3
MỞ ĐẦU
Giải thuật phân chùm K-Means là một trong những giải thuật được đánh giá cao trong
khai phá dữ liệu (Data Mining). Nó được áp dụng trong các bài toán thực tế như trong lĩnh
vực nhận dạng mẫu, phân tích phân loại, xử lý ảnh...
Tuy nhiên, giải thuật K-Means cũng có nhũng hạn chế nhất định khi tập dữ liệu đầu
vào và số chiều của chúng là lớn. Từ đó, đã có những đề xuất nhằm tăng tính hiệu quả của
giải thuật K-Means, được gọi là K-Means suy rộng.
Trong phạm vi của đề tài tập chỉ trung nghiên cứu giải thuật K-Means, các vấn đề liên
quan và những cải tiến của nó trong giải thuật K-Means suy rộng. Từ đó ứng dụng cho dữ
liệu trong nhận dạng tiếng nói. Luận văn không có tham vọng giải quyết toàn bộ vấn đề
nhận dạng tiếng nói mà chỉ đưa ra cách tiếp cận mới trên cơ sở cải tiến những hạn chế của
giải thuật K-Means kinh điển là sử dụng cây KD-tree và giải thuật lọc trong nhận dạng tín
hiệu. Từ đó áp dụng để nhập điểm môn học bằng tiếng nói tiếng việt, cụ thể các điểm từ 0
đến 10.
Kết quả nghiên cứu và thực hiện nội dung đề tài được thể hiện trong luận văn với các
nội dung chính sau: Ngoài phần Mở đầu và Kết luận, các nội dung chính được chia làm 4
chương:
Chương 1: Giới thiệu giải thuật K-Means
Chương 2: Giải thuật K-Means suy rộng
Chương 3: Ứng dụng giải thuật K-Means suy rộng cho nhận dạng dữ liệu tiếng
nói tiếng việt
Chương 4: Phân tích, thiết kế, cài đặt hệ thống thử nghiệm

4
Chương 1 - GIỚI THIỆU GIẢI THUẬT K-MEANS Thuật toán K-Means clustering là một trong những giải thuật học không giám sát
thông dụng nhất trong phân nhóm dữ liệu. Với mục tiêu chia tập gồm n đối tượng của cơ sở
dữ liệu thành k vùng (k n nguyên, dương) sao cho các đối tượng trong cùng một vùng có
khoảng cách bé còn các đối tượng khác vùng thì có khoảng cách lớn hơn nhiều.
Về nguyên lý, có n đối tượng, mỗi đối tượng có m thuộc tính, ta phân chia được các
đối tượng thành k nhóm dựa trên các thuộc tính của đối tượng bằng việc áp dụng thuật toán
này.
Giải thuật K-Means phân nhóm dữ liệu dựa trên khoảng cách Euclidean nhỏ nhất giữa
đối tượng đến phần tử trung tâm của các nhóm.
Phần tử trung tâm của nhóm được xác định bằng giá trị trung bình các phần tử trong
nhóm.
1.1. Các khái niệm
1.1.1. Khoảng cách Euclidean Ta giả sử:
ai=(xi1, xi2,... xim) - đối tượng thứ i cần phân phân loại, (i=1..n)
cj=(xj1, xj2,... xjm) - phần tử trung tâm nhóm j (j=1..k)
Khoảng cách Euclidean từ đối tượng ai đến cj (phần tử trung tâm nhóm j) được tính
toán dựa trên công thức:
m
1s
2jsisji )xx(δ ( 1.2)
Trong đó:
ji - khoảng cách Euclidean từ ai đến cj
xis - thuộc tính thứ s của đối tượng ai
xjs - thuộc tính thứ s của phần tử trung tâm cj
1.1.2. Phần tử trung tâm
k phần tử trung tâm (k nhóm) ban đầu được chọn ngẫu nhiên, sau mỗi lần nhóm các đối
tượng vào các nhóm, phần tử trung tâm được tính toán lại.
Clusteri = {a1, a2 .... at} – Nhóm thứ i i=1..k, k số số nhóm cần phân chùm ; j= 1..m, m số thuộc tính

5
t - số phần tử hiện có của nhóm thứ I; xsj - thuộc tính thứ j của phần tử s s=1..t
cij - toạ độ thứ j của phần tử trung tâm nhóm i; t
xc
t
ssj
ij
1
1.2. Giải thuật K-Means
Đầu tiên, ta xác định số lượng K nhóm và giả thiết trọng tâm hay tâm của những nhóm
này.
Thuật toán k means thực hiện như sau :
- Khởi tạo k phần tử trung tâm một cách ngẫu nhiên .
- Thực hiện ba bước cơ bản sau cho đến khi hội tụ, tức là tất cả các đối tượng được
phân loại và không còn còn sự thay đổi của các đối tượng đến các nhóm:
Bước 1: Xác định khoảng cách Euclidean của các đối tượng đến các phần tử trọng tâm.
Bước 2: Nhóm đối tượng vào cluster dựa khoảng cách nhỏ nhất của đối tượng với các
phần tử trọng tâm.
Bước 3: Tính toán lại phần tử trọng tâm của mỗi nhóm dựa vào các đối tượng của
nhóm.
1.3. Sự hội tụ và độ phức tạp của giải thuật K-Means Nếu số phần tử dữ liệu cần phân nhóm ít hơn số nhóm cần phân thì ta gán mỗi phần tử
dữ liệu là tâm của nhóm, mỗi nhóm sẽ có 1 phần tử. Nếu số lượng phần tử trong dữ liệu mà
lớn hơn số nhóm cần phân, đối với mỗi phần tử, ta tính khoảng cách tới tất cả các tâm và lấy
khoảng cách nhỏ nhất. Phần tử này được coi là thuộc một nhóm nếu khoảng cách từ nó tới
tâm nhóm đó là nhỏ nhất.
Toạ độ trọng tâm của nhóm được điều chỉnh lại dựa trên dữ liệu vừa được cập nhật.
Sau đó ta gán tất cả dữ liệu vào tâm mới này. Quá trình này được lặp lại cho đến khi không
có sự thay đổi dữ liệu tới các nhóm khác. Thuật toán này được chứng minh là hội tụ.
Độ phức tạp của giải thuật K-Means:
Số ô nhớ cần dùng để lưu trữ các đối tượng là O(mn) trong đó m là số đối tượng còn n
là số chiều (hay số thuộc tính) của các đối tượng
Giải thuật K-Means có độ phức tạp theo thời gian của nó là O(nkl), trong đó n là số
lượng các mẫu , k là số nhóm và l là số lượng các vòng lặp tạo ra thuật toán cho đến khi hội

6
tụ. Thường, k và l là cố định và vì vậy thuật toán có độ phức tạp theo thời gian theo đường
thẳng tuyến tính.
1.4. Kết luận chương
Giải thuật K-Means là một trong những giải thuật kinh điển và được ứng dụng nhiều
thuật toán nổi tiếng và được sử dụng nhiều nhất trong hướng tiếp cận phân nhóm phân
hoạch .Tuy nhiên , giải thuật K-Mean cũng có những hạn chế sau:
- Số lượng nhóm k phải được xác định cứng trước và việc xác định không dễ.
- Điều kiện khởi tạo có ảnh hưởng lớn đến kết quả. Điều kiện khởi tạo khác nhau có
thể cho ra kết quả phân nhóm khác nhau. Điều này dẫn đến nó hội tụ tới các điểm
cực tiểu địa phương.
- Không xác định được mức độ ảnh hưởng của thuộc tính đến quá trình tạo nhóm.
- Khi các điểm và số chiều của các điểm trong tập dữ liệu là rất lớn, giải thuật thực
hiện với số lượng lớn các vòng lặp. Điều đó khiến việc thực hiện giải thuật K-
Means là khó khả thi.
Để khắc phục những hạn chế nêu trên, một trong những phương pháp được xem xét là
sử dụng một cấu trúc dữ liệu dạng cây đa chiều, còn gọi là cây KD (KD-Tree) để lưu trữ
một tập hữu hạn các điểm trong không gian d chiều làm tăng hiệu quả xử lý của giải thuật
K-Means.
CHƯƠNG 2 - GIẢI THUẬT K-MEANS SUY RỘNG
Để cải tiến hiệu quả của giải thuật K-Means, có rất nhiều phương pháp được đưa ra
như các phương pháp ngẫu nhiên CLARAN, CLARANS hay các phương pháp nhằm tăng
hiệu quả hoạt động thuật toán với dữ liệu lớn như BDSCAN hay ScaleKM[12].
Trong giải thuật phân nhóm K-Means, ta đưa ra một tập n điểm dữ liệu trong không
gian d chiều Rd và một số k nguyên dương. Vấn đề của giải thuật là phải xác định được một
tập k điểm trong Rd. Trong chương này ta nghiên cứu một sự cải tiến khác của giải thuận K-
Means do Lloy đề xuất (ta gọi là giải thuật K-Means suy rộng). Giải thuật này còn có tên là
giải thuật lọc (Filtering Algorithm). Giải thuật sử dụng cấu trúc dữ liệu chính là cây nhị
phân k chiều (K-Dimensional Tree) – là một cấu trúc dữ liệu phân vùng cho các tập hợp
điểm trong một không gian k chiều. Các điểm dữ liệu cần phân nhóm trong giải thuật K-
Means được đưa vào cấu trúc cây KD-Tree.

7
2.1. Các khái niệm liên quan
2.1.1. Cây KD-Tree Cây KD-Tree được sử dụng trong giải thuật lọc của Lloyd có những đặc điểm sau:
Là một cây nhị phân.
Mỗi nút biểu diễn một tập con các điểm cần phân nhóm, tập con đó gọi là Ô (Cell) và
lưu giữ:
o Siêu chữ nhật (Hyper-Rectangle) nhỏ nhất có thể bao tất cả các điểm trong tập
con.
o Vector tổng của tất cả các điểm trong tập con.
o Số lượng các điểm trong tập con.
Một lá của cây là một Ô chứa nhiều nhất một điểm.
Nút gốc của cây chứa siêu chữ nhật bao tập dữ liệu chứa toàn bộ các điểm cần phân
nhóm.
Mỗi nút trong của cây: Ô được chia thành 2 siêu chữ nhật (tạo ra con trái và con phải
của cây kd) bởi một siêu phẳng chia tách. Có nhiều cách chọn siêu phẳng chia tách.
Ta có thể chia một cách trực giao tới cạnh dài nhất của Ô và đi qua trọng tâm của các
điểm trong Ô. Ở đây ta sử dụng phương pháp chia để tạo ra các siêu chữ nhật có tên
là Sliding-Midpoint.[4,8]
2.1.2. Phương pháp chia tách Sliding-Midpoint Nội dụng của phương pháp được tóm tắt như sau:
Đầu tiên, thực hiện một phép chia điểm giữa bởi một siêu phẳng chia tách đi qua tâm
của Ô và vuông góc với cạnh dài nhất của Ô. Nếu các điểm dữ liệu nằm trên cả 2 phía của
siêu phẳng thì siêu phẳng được duy trì ở đây. Tuy nhiên, nếu tất cả các điểm chỉ nằm trên
cùng một phía của siêu phẳng chia tách thì thực hiện “trượt” mặt phẳng cắt về phía các điểm
cho tới khi gặp điểm dữ liệu đầu tiên .
Trong không gian k chiều, nếu phép chia thực hiện trực giao với toạ độ thứ i, và tất cả
các điểm dữ liệu có toạ độ thứ i mà lớn hơn toạ độ thứ i của mặt phẳng chia thì mặt phẳng
chia được dịch chuyển cho tới khi toạ độ thứ i của nó bằng toạ độ thứ i của nhỏ nhất trong
số các điểm dữ liệu. Gọi điểm đó là p1. Sau đó, điểm p1 sẽ nằm ở một nửa của Ô, tất cả các
điểm dữ liệu còn lại sẽ nằm ở nửa còn lại của Ô. Thực hiện một luật đối xứng nếu tất cả các
điểm trong Ô đều có toạ độ thứ i nhỏ hơn toạ độ thứ i của mặt phằng chia[8].

8
2.2. Giải thuật lọc
Giải thuật của Lloyd dựa trên một quan sát đơn giản là sự thay thế tối ưu cho một tâm
của nhóm chính là trọng tâm (Centroid) của nhóm tương ứng đó. Giả sử, cho một tập Z
chứa k tâm. Với mỗi tâm zZ, gọi V(z) là lân cận của nó, V(z) là tập các điểm dữ liệu mà z
là lân cận gần nhất. Mỗi giai đoạn của giải thuật thực hiện chuyển tất cả các điểm tâm z tới
trọng tâm của tập V(z) và sau đó cập nhật lại V(z) bằng việc tính lại khoảng cách từ mỗi
điểm tới tâm gần nhất của nó. Các bước này lặp lại cho đến khi điều kiện hội tụ đạt được.
Giải thuật sẽ hội tụ tới một điểm là cực tiểu địa phương đối với sai số.
2.3. Độ phức tạp của giải thuật
Nội dung phần này trình bày cách phân tích thời gian tiêu hao trong từng giai đoạn của
giải thuật lọc. Cách phân tích trường hợp xấu nhất theo truyền thống là không còn thích hợp
với trường hợp ở đây, về nguyên tắc, giải thuật có thể gặp phải các đoạn kịch bản mà nó
chuyển thành tìm kiếm mạnh mẽ.
Độ phức tạp thời gian giải thuật Lọc không tăng theo đường thẳng đối với số lượng
các điểm hoặc số lượng các nhóm như trong trường hợp của giải thuật K-Means truyền
thống. Giải thuật này phù hợp đối với số lượng các điểm và các tâm là lớn. Số lượng các
nút được mở rộng trong một vòng lặp K-Means của giải thuật lọc là 0(nk2/2). Với là sự

9
phân tách nhóm. Do vậy, độ phức tạp thời gian của K-Means giảm nhanh khi tăng. Điều
này trái ngược với độ phức tạp 0(nk) của vòng lặp K-Means đơn trong vòng lặp của giải
thuật K-Means truyền thống với mọi cấp độ của sự phân tách.
2.4 Kết luận chương
Trong chương này ta nghiên cứu một sự cải tiến khác của giải thuận K-Means do Lloy
đề xuất (ta gọi là giải thuật K-Means suy rộng). Giải thuật sử dụng cấu trúc dữ liệu chính là
cây nhị phân k chiều (K-Dimensional Tree). Theo nghiên cứu của Jim Z.A Lai và Yi –
Ching Liaw áp dụng giải thuật trên vào việc phân nhóm các mẫu ảnh đã kết luận giải thuật
tăng hiệu quả rõ rệt so với giải thuật K-Means truyền thống, cụ thể thời gian tính toán giảm
được từ 5,9 ->39,8% . Dựa trên việc xem xét này, ta có cơ sở để xem xét việc áp dụng giải
thuật vào bài toán nhận dạng tiếng nói với ứng dụng cụ thể trong nhập điểm môn học, chi
tiết về việc áp dụng của thuật toán được trình bày trong chương 3 và chương 4 tiếp theo.

10
CHƯƠNG 3 - ỨNG DỤNG GIẢI THUẬT K-MEANS SUY RỘNG
CHO NHẬN DẠNG TIẾNG NÓI TIẾNG VIỆT
3.1. Khái quát về tiếng Việt
Tiếng Việt là tiếng đơn âm có ranh giới cố định, mang thanh điệu, có cấu trúc đơn
giản, có âm tiết trùng với hình vị, đơn vị nhỏ nhất có tổ chức mang ý nghĩa ngữ pháp.
Tiếng Việt có 6 thanh điệu là: huyền, sắc, hỏi, ngã, nặng và không dấu. Mỗi thanh đều
có thể tham gia vào việc cấu tạo từ và tạo nghĩa cho từ.
Âm tiết tiếng Việt ở dạng đầy đủ bao gồm 3 thành phần có mức độ độc lập khác nhau
là âm đầu, âm chính và âm cuối. Trong đó nguyên âm và thanh điệu là hạt nhân của âm tiết.
Từ và cụm từ là đơn vị cấu tạo nên câu[3].
3.1.1. Đơn vị cơ bản cho các hệ thống nhận dạng tiếng nói tiếng Việt
Trong tất cả các ngôn ngữ, từ là đơn vị nhỏ nhất của tiếng nói và từ là mục tiêu của các
hệ thống nhận dạng tiếng nói. Ngoài ra, mô hình âm vị và mô hình âm đầu + vần cũng là
đơn vị cơ bản được sử dụng trong các hệ thống nhận dạng tiếng Việt dựa trên cấu tạo các
thành phần trong tiếng Việt. Tuy nhiên trong phạm vi luận văn chỉ tập trung xem xét đơn vị
nhận dạng là từ.
3.1.2. Đặc điểm âm tiết và bài toán nhận dạng
Trong tiếng Việt ranh giới âm tiết trùng với ranh giới hình vị. Đây chính là đặc điểm
quan trọng khi tiến hành trích chọn các đặc trưng của âm tiết.
Tuy nhiên khi chọn mô hình âm tiết cũng gặp một khó khăn rất lớn là số lượng âm tiết
tiếng Việt rất nhiều như vậy hạn chế khả năng nhận dạng của hệ thống.[3]
3.2. Xử lý tiếng nói và đặc trưng của dữ liệu tiếng nói
3.2.1. Các đặc trưng của tiếng nói
Tiếng nói có những đặc trưng cơ bản sau:
Là tín hiệu dạng dao động, thay đổi theo thời gian
Tiếng nói của một từ nhưng do nhiều người nói hoặc một người nói những lần khác
nhau sẽ có tín hiệu khác nhau.

11
Có đoạn tín hiệu tiếng nói xuất hiện chu kỳ cơ bản, gọi là chu kỳ pitch, có đoạn
không xuất hiện chu kỳ tín hiệu có dạng như nhiễu (hình 3.2).
Tần số trong tiếng nói thường được cộng hưởng do cơ chế phát âm của con người.
3.2.2. Các thông số cơ bản của tín hiệu tiếng nói
Tần số cơ bản: tần số cơ bản thường được ký hiệu là F0, còn gọi là Pitch. Đây là thuộc
tính cơ bản nhất của tín hiệu tiếng nói.
Formant: Các đỉnh formant ký hiệu F1, F2, F3,...
3.2.3. Một số cách biểu diễn tín hiệu tiếng nói
Biểu đồ dao động hay dạng sóng – WavForm :
Biểu diễn phổ biến nhất của tín hiệu tiếng nói là biểu đồ dao động, hay là dạng
wavform.
Phổ:
Phổ cho chúng ta hình ảnh về sự phân bố của tần số và biên độ tức thời theo thời gian.
Ảnh phổ :
Là hình thức biểu diễn phổ cả về mặt thời gian.
Trong phạm vi của luận văn thực hiện biểu diễn tín hiệu tiếng nói dưới dạng sóng.
3.2.4. Các vấn đề xử lý tiếng nói
Ở đây ta chỉ xét các vấn đề xử lý tiếng nói trong miền thời gian (Time-Domain). Cụ thể
theo hướng nghiên cứu các phương pháp xử lý trên miền thời gian bao gồm tỷ lệ Zero –
Crossing trung bình, năng lượng. Các phương pháp xử lý trên miền thời gian tỏ ra hiệu quả
bởi vì yêu cầu một khối lượng tính toán đơn giản và cung cấp nhiều thông tin quan trọng để
dự đoán các đặc trưng của tiếng nói.
Các tham số âm học:
Tham số của tín hiệu tiếng nói có thể phân làm hai lớp: tham số âm học và tham số cấu
âm. Trong phạm vi nghiên cứu chỉ xét đến tham số âm học của tín hiệu tiếng nói. Do cấu
trúc phức tạp của tín hiệu tiếng nói cho phép phân các tham số âm học thành nhiều nhóm
tham số đó là:
Phương pháp xác định các tham số bộ lọc:
Vấn đề xác định điểm bắt đầu và điểm kết thúc của tiếng nói trên nền nhiễu cũng là một
trong những vấn đề quan trọng của xử lý tiếng nói. Các kỹ thuật dùng để xác định điểm bắt

12
đầu và điểm kết cuối của tiếng nói có thể dùng để khử những đoạn khó tính toán bằng cách
đánh dấu những phần tương ứng với tiếng nói để đưa vào xử lý.
Việc phân biệt tiếng nói với nền nhiễu là rất quan trọng và không đơn giản. Ngoại trừ
trường hợp ghi âm chất lượng cao, khi đó tỷ lệ tín hiệu trên nhiễu là cao, năng lượng thấp
nhất của tiếng nói cũng vượt qua ngưỡng của nhiễu nền nên việc xác định trở nên đơn giản.
Thuật toán đề cập trong phần này là dựa trên hai phép đo trên miền thời gian: hàm năng
lượng và tỷ lệ Zero-Crossing.
Thuật toán có thể trình bày như sau:
Hàm năng lượng và tỷ lệ Zero-Crossing được tính cho từng đoạn 10ms. Cả hai hàm
trên tính toán trên toàn bộ đoạn ghi với tỷ lệ 100 lần/sec. Giả sử trong 10ms đầu tiên không
có tín hiệu, tỷ lệ Zero-Crossing tương ứng với nhiễu nên gọi là IZTC và ngưỡng năng lượng
gọi là ITL. Tới đoạn tín hiệu tiếp theo, dùng một ngưỡng ITU có giá trị lớn hơn ITL vài lần
để xác định 2 điểm N1 và N2. Như vậy ta đã có hai điểm N1 và N2 đảm bảo rằng nó nằm
trong đoạn có tín hiệu. Bước tiếp theo là tiến hành dịch chuyển N1 và N2 sang hai phía,
đồng thời dùng một ngưỡng IZTC đã được xác định để so sánh tỷ lệ Zero-Crossing, nếu tỷ
lệ Zero-Crossing vượt quá hai lần ngưỡng thì N1, N2 di chuyển về hướng cũ. Cứ tiến hành
cho đến khi năng lượng nhỏ hơn năng lượng ngưỡng và tỷ lệ Zero-Crossing nhỏ hơn Zero-
Crossing ngưỡng.
Cấu trúc file *.wav:
Một trong những cấu trúc đơn giản nhất, cơ bản trong việc lưu trữ dữ liệu âm thanh là tập
tin dạng wav. Tập tin dạng wav là tập tin lưu trữ dữ liệu dạng wavform, dữ liệu khi thu âm
được lưu trữ trực tiếp vào tập tin, nên tốc độ mã và giải mã dữ liệu dạng này rất nhanh.
3.2.5. Tiền xử lý tín hiệu tiếng nói Tín hiệu tiếng nói thu được, trước khi đưa vào trích chọn đặc trưng phải thực hiện tiền
xử lý nhằm hạn chế những sai số do nhiễu gây ra.
Xác định đường mức không
Tiếng nói hay âm thanh là tín hiệu dao động, giả sử các giá trị tín hiệu nhận từ 0 đến
L-1, khi im lặng các tín hiệu này sẽ nhận giá trị là L/2, ví dụ mẫu 8 bít có L=256 thì mức
không là 128, giá trị này là giá trị không. Thực tế khi thu âm, soundcard thực hiện số hoá
âm thanh có thể mức không không là giá trị nói trên. Để xác định đường mức không thực
hiện như sau:

13
Bước 1: Lấy mức thu của soundcard.
Bước 2: Đặt mức thu ở giá trị thấp nhất (tín hiệu thu được là nhỏ nhất).
Bước 3: Thu một đoạn dữ liệu ngắn (khoảng 3 giây).
Bước 4: Tính Histogram H (H[k] là số mẫu có giá trị biên độ k).
Bước 5: Tìm trong dãy H phần tử H[max] có giá trị lớn nhất. Đường mức không chính
là max.
Khi đã xác định được đường mức không, giá trị tín hiệu tiếng nói sẽ dao động xung
quanh đường mức không.
Chuẩn hoá biên độ
Các tín hiệu của cùng một từ khi nói và thu vào máy tính có thể có cường độ (biên độ
tín hiệu so với đường mức không) khác nhau, để thuận tiện cho việc trích rút đặc trưng, một
trong những khâu tiền xử lý là chỉnh biên độ tín hiệu các từ về cùng mức, giá trị lớn nhất
biên độ so với đường mức không là như nhau.
Bước 1: Đặt L=2bitsamp, bitsamp là số bít của một mẫu.
Bước 2: Tính biến độ lớn nhất max so với mức không.
Bước 3: Chuyển giá trị tín hiệu theo mức không
s(n)=s(n)- (Mức không)
Bước 4: Tính hệ số điều chính max.2Lk
Bước 5: Nhân tín hiệu với hệ số k.
s(n)=s(n)*k+ (Mức không)
Chuẩn hoá thời gian
Các tín hiệu của cùng một từ khi nói và thu vào máy tính có thể có tổng số mẫu khác
nhau, để thuận tiện cho việc trích rút và nhận dạng đặc trưng, ta tính toán lại tổng số mẫu
bằng phương pháp chuẩn hoá thời gian. Công việc được thực hiện theo kỹ thuật căn chỉnh
thời gian tuyến tính:
Bước 1: Tính M là tổng số mẫu tín hiệu đầu vào.
Bước 2: Đặt N là tổng số mẫu tín hiệu đầu ra.
Bước 3: Tính giá trị mẫu tín hiệu y(i) ở đầu ra:
NiiNMxiy ,1,*)(
3.3. Ứng dụng giải thuật K-Means cho dữ liệu tiếng nói

14
3.3.1. Mô hình bài toán
Hình: Mô hình bài toán
Yêu cầu bài toán
- Áp dụng giải thuật K-Means suy rộng để phân chùm các khúc dữ liệu tiếng nói
của một người.
- Nhận dạng hữu hạn các âm tiết chữ số {không, một, hai, ba, bốn, năm, sáu, bảy,
tám, chín, mười} của một người phục vụ cho ứng dụng nhập điểm môn học.
Phạm vi bài toán
- Chỉ áp dụng với dữ liệu tiếng nói của một người.
- Số âm tiết là hữu hạn {không, một, hai, ba, bốn, năm, sáu, bảy, tám, chín, mười}
- Yêu cầu dữ liệu đầu vào là tệp dữ liệu dạng file *.wav với tần số lấy mẫu
11025Hz, độ phân giải 8bit, Mono. Được ghi âm ở chế độ bình thường (nhiễu tự
nhiên, không quá lớn).
Kết quả cần đạt được:
Từ kết quả của việc phân chùm các khúc dữ liệu, nhận dạng các âm tiết là các số đếm
từ 0 đến 10 của một người. Kết quả này sau đó được áp dụng vào nhận dạng một chuỗi từ
liên tiếp nhau để nhập điểm môn học.
3.3.2. Phân chùm các khúc dữ liệu tiếng nói
Phân tích tiếng nói nhằm tách ra được các tham số đặc trưng cho các tính chất của tín
hiệu tiếng nói. Các tham số này có thể được ứng dụng trong nhận dạng. Quá trình phân tích
nhằm trích rút ra các đặc trưng số về các dạng như sau:
Năng lượng và độ lớn trung bình thời gian ngắn.
Tỷ lệ Zero-Crossing.
Tần số Pitch.
Dữ liệu đầu vào là các khúc hình sin dữ liệu tiếng nói đã được trích rút từ tệp dữ liệu
*.wav. Mỗi khúc dữ liệu này có p thành phần và ta coi như là một vector p chiều. Các khúc
này có số chiều là khác nhau.

15
Chuẩn hoá dữ liệu đầu vào
Từ kiểm nghiệm thực tế ta thấy các khúc dữ liệu tiếng nói có số chiều thay đổi trong
khoảng từ 90 đến 130. Với xác suất xuất hiện nhiều nhất với số chiều là 95. Vì vậy, chúng ta
sẽ chuẩn hoá số chiều của các khúc dữ liệu là 95 chiều.
Sử dụng giải thuật K-Means để phân chùm các khúc dữ liệu
Giải thuật K-Means sẽ được áp dụng với bộ số liệu là n vector p chiều, số nhóm cần
phân chùm là k.
3.4. Kết luận chương
Nội dung của chương 3 đã trình bày tổng thể các khái niệm liên quan đến đặc trưng
của tiếng nói tiếng việt, các vấn đề liên quan đến tiếng nói và xử lý tiếng nói làm cơ sở
cho xử lý dữ liệu tiếng nói tiếng việt áp dụng trong các ứng dụng nhận dạng/phân mẫu.
Cuối cùng là nội dung về ứng dụng giải thuật K-Means suy rộng cho bài toán nhận dạng
tiếng nói tiếng Việt với số lượng âm hữu hạn áp dụng vào bài toán nhập điểm môn học (
các điểm số từ 0 đến 10). Phần chương trình ứng dụng cụ thể của giải thuật vào bài toán
trên được trình bày tại chương 4.
16
CHƯƠNG 4 - PHÂN TÍCH, THIẾT KẾ, CÀI ĐẶT HỆ THỐNG
Hệ thống thử nghiệm được triển khai và chạy trong môi trường Windows. Hệ quản trị
cơ sở dữ liệu Foxpro Version 7.0. Ngôn ngữ lựa chọn để cài đặt chương trình là Visual
Basic 6.0. Công cụ hỗ trợ DirectX8.0 của Windows.
4.1. Phân tích thiết kế
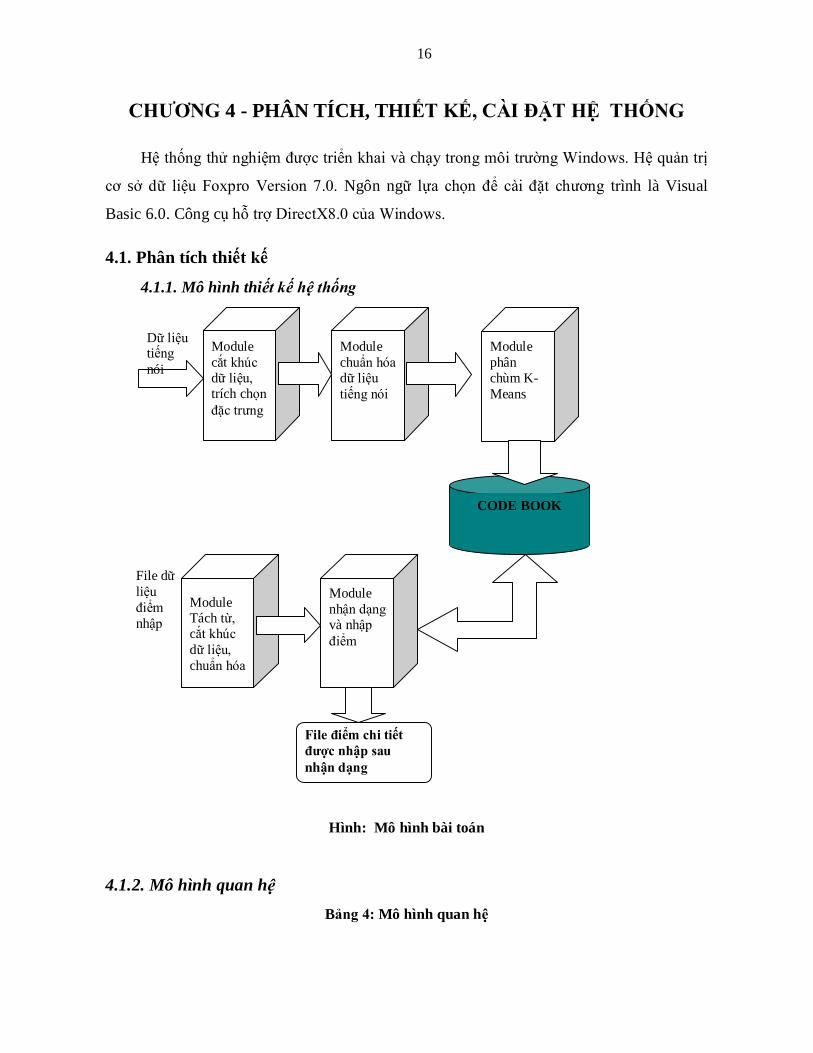
4.1.1. Mô hình thiết kế hệ thống
Hình: Mô hình bài toán
4.1.2. Mô hình quan hệ Bảng 4: Mô hình quan hệ
Dữ liệu tiếng nói
Module cắt khúc dữ liệu, trích chọn đặc trưng
Module chuẩn hóa dữ liệu tiếng nói
Module phân chùm K-Means
CODE BOOK
File dữ liệu điểm nhập
Module Tách từ, cắt khúc dữ liệu, chuẩn hóa
Module nhận dạng và nhập điểm
File điểm chi tiết được nhập sau nhận dạng

17
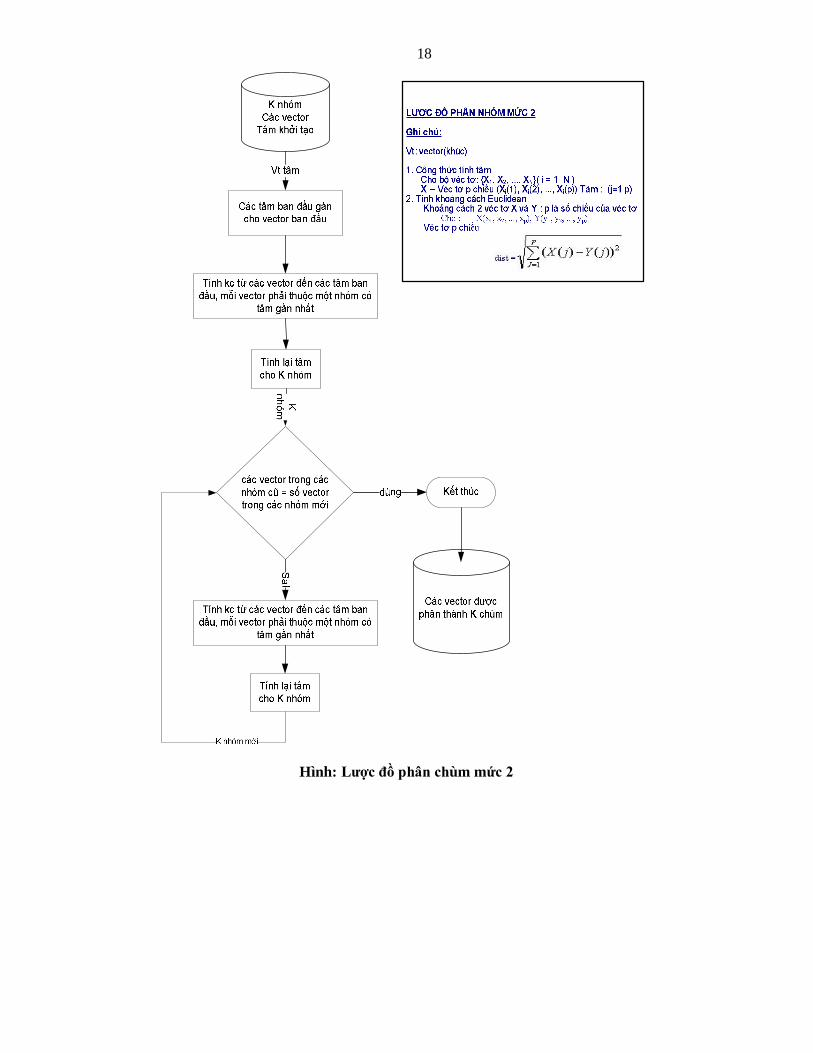
4.1.3. Mô tả thuật toán phân chùm input: Các khúc hình sin.
output: phân thành bao nhiêu chùm và hệ số tương quan.
Lưu đồ thuật toán
18
Hình: Lược đồ phân chùm mức 2
19
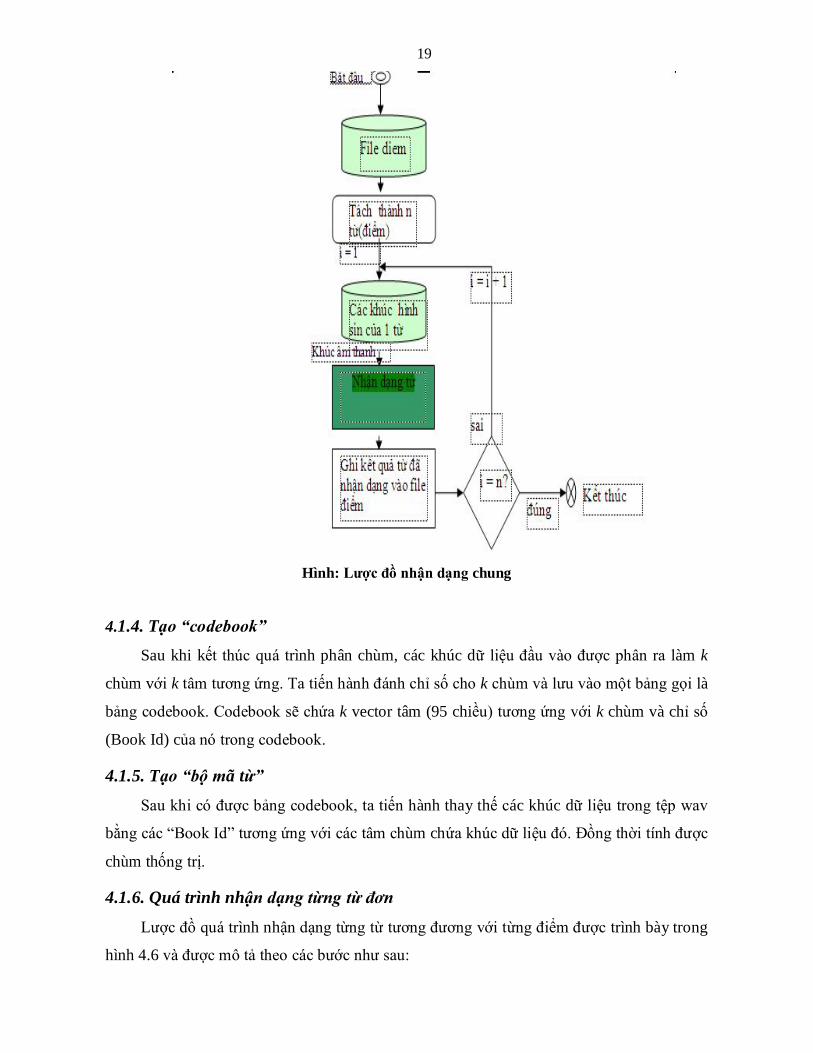
Hình: Lược đồ nhận dạng chung
4.1.4. Tạo “codebook” Sau khi kết thúc quá trình phân chùm, các khúc dữ liệu đầu vào được phân ra làm k
chùm với k tâm tương ứng. Ta tiến hành đánh chỉ số cho k chùm và lưu vào một bảng gọi là
bảng codebook. Codebook sẽ chứa k vector tâm (95 chiều) tương ứng với k chùm và chỉ số
(Book Id) của nó trong codebook.
4.1.5. Tạo “bộ mã từ”
Sau khi có được bảng codebook, ta tiến hành thay thế các khúc dữ liệu trong tệp wav
bằng các “Book Id” tương ứng với các tâm chùm chứa khúc dữ liệu đó. Đồng thời tính được
chùm thống trị.
4.1.6. Quá trình nhận dạng từng từ đơn
Lược đồ quá trình nhận dạng từng từ tương đương với từng điểm được trình bày trong
hình 4.6 và được mô tả theo các bước như sau:

20
B1: chọn tệp *.wav của một điểm cần nhận dạng (cụ thể là một số từ 0 đến 10). Điểm cần
nhận dạng phải được ghi âm với các thông số giống như thông số ghi âm của các từ
mẫu.
B2: Tiến hành cắt khúc; chuẩn hoá số chiều của các khúc dữ liệu của tập cần nhận dạng.
B3: Với mỗi khúc của tập dữ liệu cần nhận dạng, tính hstq của khúc đó với các tâm lưu
trong CodeBook và tìm ra giá trị max. Ta ký hiệu: hstq(i,j) là hstq của khúc thứ i với
tâm có Book Id là j. Khi đó, Ta thay thế khúc thứ i bằng tâm có Book Id là j nếu
hstq(i,j) là lớn nhất. Quá trình này tương đương với việc ta thay thế mỗi khúc dữ liệu
cần nhận dạng bằng một tâm trong codebook “gần” với nó nhất. Sau khi thay thế xong,
ta tìm được các chùm thống trị của từ cần nhận dạng (vd: 6 chùm thống trị).
B4: Tiến hành so sánh và tìm ra từ có trong “bộ từ mã” có số lượng lớn nhất các chùm
thống trị giống với các chùm thống trị của từ cần nhận dạng. Nếu số tỉ lệ chùm thống
trị giống nhau/số chùm thống trị>50% ta có thể kết luận là nhận dạng được từ và tỷ lệ
nhận dạng. Nếu không thi đưa ra kết luận không nhận dạng được từ .
4.1.7. Quá trình nhập dữ liệu điểm và nhận dạng nhiều từ
Lược đồ mô tả chức năng nhập điểm môn học từ dữ liệu bao gồm nhiều từ đơn và
được mô tả theo các bước như sau:
B1: Chọn tệp *.wav bao gồm nhiều điểm của nhiều học sinh cần qua nhận dạng để nhập
điểm . File dữ liệu phải được ghi âm với các thông số giống như thông số ghi âm của
các từ mẫu. Dữ liệu sau đó được tách ra thành từng từ/điểm riêng lẻ và đưa vào nhận
dạng từng từ đơn như quá trình mô tả tại mục 4.1.6.
B2: Chọn file dữ liệu điểm cần nhập điểm môn học tương ứng. Kết quả nhận dạng từ bước
1 được ghi vào file điểm môn học tại bước 2.
4.2. Cài đặt hệ thống và thử nghiệm
4.2.1. Một số module chính Bảng: Một số module chính
STT Thủ tục / Hàm I/O Ý nghĩa
1 Cmdchuanhoa Input: các khúc hình sin Output: các khúc hình sin chuẩn hóa chiều =95, ghi vào csdl
Tiền xử lý các khúc hình sin, chuẩn hóa chiều, ghi vào csdl

21
2 kMeanCluster, Tinhsub
Input: các khúc hình sin đã chuẩn hóa Output: phân K chùm các khúc hình sin
Phân chùm các khúc
3 Hesotuongquansub
Input: K chùm Output: hệ số tương quan các điểm với tâm trong mỗi chùm
Kiểm tra hệ số tương quan
4 Dist() Input: vector(khúc) và tâm Output: khoảng các từ một vector đến tâm
Tính khoảng cách Euclidean
5 distE() Input: vector(khúc) và tâm Output: hệ số tương quan của một vector với tâm
Tính hệ số tương quan của hai điểm
6 Laybiendo Input: vector (khúc) Output: biên độ max của vector(khúc)
Tính biên độ Max của khúc(vector)
7 thaytam95 Input: 1 vector (khúc) Output: thay thế tâm của chùm vào khúc(vector) 95 chiều
Thay một khúc đã phân chùm bằng tâm 95 chiều
8 thaytam_nchieu
Input: 1 vector (khúc) Output: thay thế tâm của chùm vào khúc(vector) với số chiều gốc
Thay một khúc đã phân chùm bằng tâm với số chiều gốc của khúc gốc
9 strim_tang Input: 1 vector (khúc) Output: Tăng số chiều
Tăng số chiều của một khúc
10 strim_giam Input: 1 vector (khúc) Output: Gỉam số chiều
Gỉam số chiều của một khúc
11 Cmdcodebook Input: các tâm sau khi thay thế cho các vector (khúc) Output: mã các tâm và đưa vào codebook
Mã các tâm sau khi thay cho các khúc hinh sin gốc và ghi vào codebook
12 Cmdnhapdiem Input: file âm thanh dữ liệu điểm cần nhập qua nhận dạng Output: kết quả điểm nhập sau nhận dạng
Nhập điểm môn học sau khi nhận dạng từng điểm
4.2.2. Các chức năng chính của chương trình
- Cắt khúc dữ liệu từ tệp dữ liệu dạng *.wav: cho phép cắt khúc 1 hoặc nhiều tệp wav
cùng lúc. Kết quả cắt khúc lưu ở tệp “chunks.txt”.
22
- Phân chùm các khúc dữ liệu từ tệp chunks.txt; chuẩn hoá và phân chùm. Chương
trình cho phép chọn k ban đầu.
- Tạo bảng code book; bộ mã từ .
- Nhập điểm từ file dữ liệu đưa vào.
4.2.3. Giao diện chương trình
Hình . Menu Chính
Hình. Các menu chi tiết chức năng nhập điểm
*. Kết quả đạt được:

23
File âm thanh dữ liệu điểm đưa vào là 4 mẫu bao gồm chuỗi các điểm như sau: 10-
8-6-9 .
Kết dữ liệu nhập điểm sau quá trình nhận dạng là: 10-8-6-9. Trong đó từ số 6 có tỷ
lệ xếp khúc là nhỏ nhất nhưng kết quả nhận dạng vẫn đúng.
Tỷ lệ nhận dạng đúng với dữ liệu nhập điểm cho mẫu đầu tiên là: 100%.
Ngoài ra khi thử với file dữ liệu đưa vào là từng từ đơn, kết quả nhận dạng cũng đạt từ
80%->90%. Dưới đây là kết quả với tập dữ liệu thử là các tập dữ liệu đầu vào nhiều từ
khác:
Bảng 4.4. Một số kết quả nhập điểm theo file
stt Input Output Tỷ lệ
1 File dữ liệu 5 điểm đọc liên tục, giá trị: 1 2 3 7 5
Kết quả điểm sau nhận dạng là: 10 2 3 3 5
60%
2 File dữ liệu 8 điểm đọc liên tục, giá trị như sau: 10 9 9 9 10 10 9 9
Kết quả điểm sau nhận dạng là: 10 9 9 9 10 10 9 9 0
87%
3 File dữ liệu 30 điểm đọc liên tục, giá trị như sau: 1 2 1 2 1 1 2 5 6 7 5 6 7 1 2 1 2 1 1 2 1 2 1 2 1 1 2 5 6 7
Kết quả điểm sau nhận dạng là: 1 2 1 2 1 1 2 2 6 7 2 6 7 1 2 1 2 1 1 2 1 2 1 2 1 1 2 2 6 7
90%
4.3 Kết luận chương
Như vậy, nội dung của chương 4 đã trình bày về thiết kế hệ thống thử nghiệm nhận
dạng tiếng nói. Một số chức năng chính của hệ thống nhằm mô tả cụ thể các bước xử lý và
nhận dạng dữ liệu trong bài toán. Tỷ lệ nhận dạng chính xác của hệ thống có thể đánh giá là
tốt ( 80%->90%). Tuy nhiên với những từ có âm tiết gần giống nhau như một và mười, hai
và năm, ba và bảy thì kết quả nhận dạng có khi bị sai lệch. Do đó những từ này phải được
tiếp tục đào tạo để có đủ một tập các tâm đặc trưng phân biệt với các từ điểm gần giống
khác. Một vấn đề khác ảnh hưởng đến hiệu quả nhận dạng của hệ thống là do tiếng nói được
ghi âm trong môi trường thực nên nhiễu nền khá cao. Định hướng trong thời gian tới, tác giả
sẽ tiếp tục nghiên cứu và cải thiện kết quả thực hiện của hệ thống thử nghiệm trên.
KẾT LUẬN VÀ KIẾN NGHỊ
Luận văn giới thiệu các nội dung về giải thuật K-Means; tìm hiểu giải thuật K-Means
suy rộng và áp dụng thử nghiệm vào ứng dụng nhập điểm số thông qua nhận dạng tiếng nói.

24
Trong chương trình thử nghiệm phân chùm dữ liệu các khúc hình sin có sử dụng giải
thuật phân nhóm K-Means kết hợp giải thuật Lọc, cấu trúc cây KD-tree cho kết quả phân
chùm tốt. Tỷ lệ nhận dạng đúng từ khoảng 80->90%. Việc phát hiện ra chùm thống trị của
mỗi từ và tỷ lệ dãy con dài nhất so với từ mẫu đưa ra khả năng nhận dạng từ (điểm số) đưa
vào.
Nhưng với bộ dữ liệu và số nhóm cần phân chùm lớn thì thời gian thực hiện cũng tăng
theo 0(nk2/2). Với là sự phân tách nhóm. Do vậy, độ phức tạp thời gian của K-Means
giảm nhanh khi tăng, trong đó n là số lượng các mẫu, k là số nhóm.
Do có những hạn chế nhất định về thời gian và kiến thức của bản thân nên hệ thống
thử nghiệm chỉ dừng lại ở việc nhập dữ liệu điểm số với đầu vào là file gồm một hoặc nhiều
điểm cần nhập.
Từ kết quả nghiên cứu, phân tích và thử nghiệm cho thấy khả năng ứng dụng trong
thực tế. Mặc dù các kết quả đạt được trong luận văn không phải là lớn nhưng nó có thể là
một hướng mới trong việc ứng dụng để nhận dạng, mã hoá và tổng hợp tiếng nói. Các
hướng phát triển và định hướng nghiên cứu tiếp theo của luận văn xin được đề xuất như sau:
Mở rộng phạm vi áp dụng của bài toán như có thể nhận dạng và nhập điểm trực tiếp
từ giọng nói của một người theo thời gian thực.
Nghiên cứu mở rộng hướng triển khai, phạm vi áp dụng bài toán vào nhập điểm tự
động qua mạng cho hệ thống quản lý điểm của các trường học, học viện hoặc tự
động nhập điểm qua điện thoại di động.
Tôi rất mong nhận được ý kiến đóng góp từ phía các thầy cô, các bạn để tôi hoàn
thiện hơn nữa kiến thức cho bản thân, phục vụ quá trình học tập, nghiên cứu sau này.

25