mapreduce 簡單介紹與練習
TRANSCRIPT

MAP REDUCEhttps://goo.gl/dSsBqp
May 21, 2015

巨量資料
■ Google處理Web■ 20+ billion web pages x 20KB = 400+ TB■ 單台電腦讀取硬碟速度 30-35 MB/sec。需 4個月讀取整個 web
■ 200 * 2TB硬碟來儲存

巨量資料
■ 分散式計算、分散式儲存■ 2011年時 Google有 1M台機器

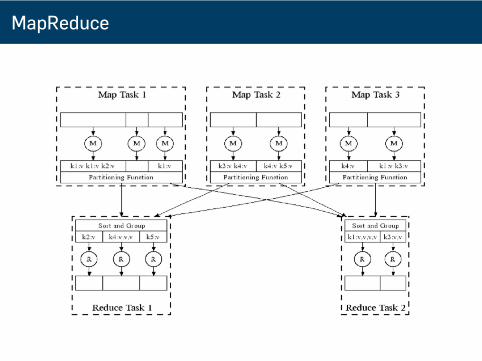
MapReduce
■ 挑戰■ 如何分散計算、分散資料?■ 撰寫分散式/平行程式很困難?
■ MapReduce解決上述問題■ Google所設計的運算與資料處理模型■ 簡單且優雅的運用在大資料處理,撰寫平行程式不再困難
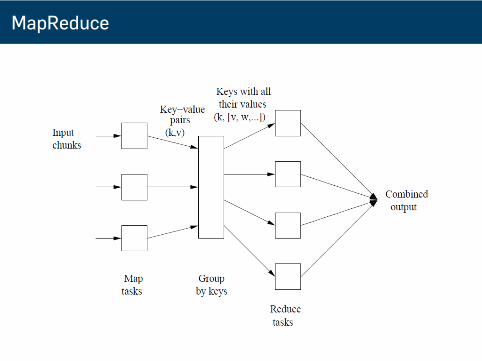
MapReduce

範例: Word Count
1 $ cat data | tr -sc 'A-Za-z' '\n' | sort | uniq -c2 ...3 645 and4 2 animation5 3 annotations6 3 answers7 1 anticipated8 19 any9 2 anymore
10 2 anything11 39 apos12 ...
6

範例: Word Count
1 $ cat data2 ...3 On January 2, 1985, Zaman Akil sent the Academy of Sciences a short summary of a longer work.4 At his request, the Perpetual Secretary of the Academy, Prof. Paul Germain, sent the letter to several members of the Academy, including myself.5 I was the only one who agreed to discuss it with the author.6 ...
7

Map
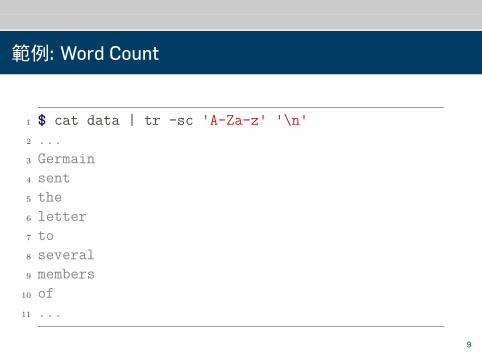
範例: Word Count
1 $ cat data | tr -sc 'A-Za-z' '\n'2 ...3 Germain4 sent5 the6 letter7 to8 several9 members
10 of11 ...
9
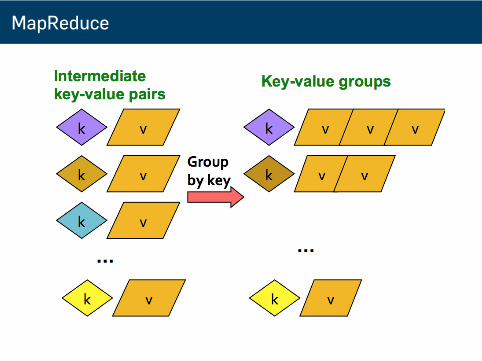
MapReduce

範例: Word Count
1 $ cat data | tr -sc 'A-Za-z' '\n' | sort2 ...3 Also4 Also5 Also6 Although7 Although8 America9 American
10 American11 Among12 An13 An14 ...
11

MapReduce
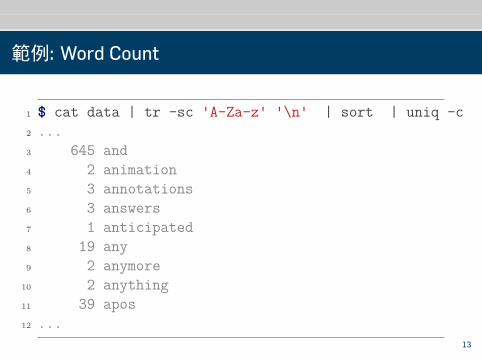
範例: Word Count
1 $ cat data | tr -sc 'A-Za-z' '\n' | sort | uniq -c2 ...3 645 and4 2 animation5 3 annotations6 3 answers7 1 anticipated8 19 any9 2 anymore
10 2 anything11 39 apos12 ...
13

WordCount Functions
1 def map(key, value):2 # key: NA; value: a line of input text3 for word in value:4 emit(word, 1)5 def reduce(key, values):6 # key: word; values: an iterator over counts7 result = 08 for count in values:9 result += count
10 emit(key, result)
14
MapReduce

MapReduce Implementations
■ Hadoop■ 1999 Doug Cutting開發搜尋引擎開放軟體 ApacheLucent, Nutch
■ 2004 Google揭露搜尋引擎的作法: MapReduce +Google分散式檔案系統
■ 2004 Doug Cutting開發 Hadoop以配合 Lucent,Nutch(Yahoo贊助)

MapReduce Implementations
■ Spark■ Designed for performance■ APIs for Scala, Java, and Python
■ Disco: MapReduce framework for Python■ MapReduce-MPI: for distributed-memory parallelmachines on top of standard MPI message passing
■ Meguro: a simple Javascript Map/Reduce framework■ bashreduce : mapreduce in a bash script■ localmapreduce
Hadoop Distributions & Services
Apache page of Distributions
■ Amazon Web Services■ Apache Bigtop■ Cascading■ Cloudera■ Datameer■ Hortonworks■ IBM InfoSphere BigInsights■ MapR Technologies■ Syncsort■ Tresata■ ...

Hadoop Streaming
■ 使用 stdin, stdout做資料的傳遞。類似 shell上的pipeline。
■ 可用任何可在 shell上執行的指令作為mapper或reducer。亦即可用任何語言做mapreduce計算。
Mapper
■ Input: 檔案整行作為 value(預設)■ Output: 第一個 tab以前為 key,其後為 value
Reducer
■ Input: 第一個 tab以前為 key,其後為 value。相同key的行會連續出現。
■ Output: 整行印出(預設)

實際動手跑 (lmr)
下載
■ ngramcount.py: https://goo.gl/wZ41MH■ localmapreduce: https://goo.gl/8UlChs■ citeseerx.40000: https://goo.gl/RmbfYm
Mac環境準備
■ 安裝 Homebrew http://brew.sh/■ 安裝 GNU parallel
brew install parallel
20

實際手動跑 (lmr)
■ 使用 pipe測試 ngramcount.py1 $ head -100 citeseerx.40000 | ./ngramcount.py -m | \2 > sort -k1,1 -t$'\t' | ./ngramcount.py -r | less
■ 使用 lmr(localmapreduce)分散執行1 $ pv citeseerx.40000 | \2 > lmr 300k 20 './ngramcount.py -m' './ngramcount.py -r' out3 $ ls out4 reducer-00 reducer-02 reducer-04 reducer-06 reducer-08 reducer-10 reducer-12 reducer-14 reducer-16 reducer-185 reducer-01 reducer-03 reducer-05 reducer-07 reducer-09 reducer-11 reducer-13 reducer-15 reducer-17 reducer-196 $ less out/*
21

Ngram Count I
1 #!/usr/bin/env python2 # -*- coding: utf-8 -*-3 from __future__ import unicode_literals, print_function456 def ngrams(words):7 for length in range(1, 5 + 1):8 for ngram in zip(*(words[i:] for i in range(length))):9 yield ngram
101112 def mapper(line):13 # from nltk.tokenize import word_tokenize14 # words = word_tokenize(line.lower())15 import re16 words = re.findall(r'[a-z]+', line.lower())17 for ngram in ngrams(words):
22

Ngram Count II
18 yield ' '.join(ngram), 1192021 def reducer(key, values):22 count = sum(int(v) for v in values)23 yield key, count242526 def do_mapper(files):27 import fileinput28 for line in fileinput.input(files):29 for key, value in mapper(line):30 print('{}\t{}'.format(key, value))313233 def line_to_keyvalue(line):34 key, value = line.decode('utf8').split('\t', 1)35 return key, value36
23

Ngram Count III
3738 def do_reducer(files):39 import fileinput40 from itertools import groupby, imap41 keyvalues = imap(line_to_keyvalue, fileinput.input(files))42 for key, grouped_keyvalues in groupby(keyvalues,43 key=lambda x: x[0]):44 values = (v for k, v in grouped_keyvalues)45 for key, value in reducer(key, values):46 print('{}\t{}'.format(key, value))474849 def argparser():50 import argparse51 parser = argparse.ArgumentParser(description='N-gram counter')52 mode_group = parser.add_mutually_exclusive_group(required=True)53 mode_group.add_argument(54 '-r', '--reducer', action='store_true', help='reducer mode')55 mode_group.add_argument(
24

Ngram Count IV
56 '-m', '--mapper', action='store_true', help='mapper mode')57 parser.add_argument('files', metavar='FILE', type=str, nargs='*',58 help='input files')59 return parser.parse_args()6061 if __name__ == '__main__':6263 args = argparser()64 if args.mapper:65 do_mapper(args.files)66 elif args.reducer:67 do_reducer(args.files)
25

修改練習
修改 ngramcount.py
■ 只產生 1-2grams■ 只保留 count > 5的 n-grams

練習:語言搜尋引擎
■ 建立一搜尋引擎用於搜尋英文詞語用法。■ 可輔助英語學習與文章寫作。
搜尋例子
■ adj. beach: 即代表搜尋 beach前面出現過的形容詞。■ play * role: 搜尋 play與 role中間最常出現的字詞組合。
■ go ?to home: go與 home之間是否要放 to。■ go * movie: go與 role中間最常出現的字詞組合。■ kill the _: 最常被 kill的東西是。

用 Google查英文

用 Google查英文

語法設計
語法 說明_ 單一任意字詞* 零到多個任意字詞?term term可有可無term1 | term2 term1或 term2adj. det. n. v. prep.形容詞、冠詞、名詞、動詞、介繫詞
搜尋例子
■ adj. beach: 即代表搜尋 beach前面出現過的形容詞。■ play * role: 搜尋 play與 role中間最常出現的字詞組合。
■ go ?to home: go與 home之間是否要放 to。■ go * movie: go與 role中間最常出現的字詞組合。■ kill the _: 最常被 kill的東西是。

語言搜尋引擎
■ 目標:完成語法第一項 _■ 任意位置置入 _■ 最長 4-gram
Query範例
■ play _ _ role■ kill the _■ a _ beach
■ 輸入資料:citeseerx的許多句子■ 輸出結果:
■ key: 所有會有結果的 query■ value: 符合 query的前 100名 ngram與 count。

語言搜尋引擎 -輸出
■ key: 所有會有結果的 query■ value: 符合 query的前 100名 ngram與 count。
輸出範例
Key Ngrams Countsa _ beach a sandy beach 486
a private beach 416a beautiful beach 314a small beach 175...
kill the _ kill the people 189kill the other 174kill the process 163kill the enemy 160...

隨堂練習
目標
■ 依MapReduce架構,設計每階段mapper, reduce的輸入輸出來完成 Lab 12
■ 在紙寫撰寫簡單輸入、輸出的 key-value範例表達概念即可
小提示
■ 可有 1至多個map, reduce流程■ 考慮mapper的輸入資料切割影響■ mapper輸入為 value或 key-value,輸出為 key-value■ reducer輸入為 grouped key-values,輸出為key-value

Bi-gram Count
Bi-gram Count Mapper範例
Input(value) Output(key => value)C D C D C D => 2
D C => 1B C D A B C => 1
C D => 1D A => 1
C D A B C D => 1D A => 1A B => 1
Reducer範例
Input(key => value) Output(key => value)A B => 1 A B => 1B C => 1 B C => 1C D => 2 C D => 4C D => 1C D => 1D A => 1 D A => 2D A => 1D C => 2 C C => 2

語言搜尋引擎
Mapper範例
Input(value) Output(key => value)A B C 200 A B C => A B C 200
_ B C => A B C 200A _ C => A B C 200A B _ => A B C 200_ _ C => A B C 200_ B _ => A B C 200A _ _ => A B C 200
A D C 300 _ D C => A D C 300A _ C => A D C 300...
A E C 100 _ E C => A E C 100A _ C => A E C 100...

語言搜尋引擎
Reducer範例
Input(value) Output(key => value)A _ C => A B C 200 A _ C => A D C 300,A _ C => A D C 300 A B C 200,A _ C => A E C 100 A E C 100A B _ => A B C 200 A B _ => A B C 200A D _ => A D C 300 A D _ => A D C 300A E _ => A E C 100 A E _ => A E C 100A _ _ => A B C 200 A _ _ => A D C 300,A _ _ => A D C 300 A B C 200,A _ _ => A E C 100 A E C 100_ B C => A B C 200 _ B C => A B C 200_ D C => A D C 300 _ D C => A D C 300_ E C => A E C 100 _ E C => A E C 100... ...

回家作業
需完成六支程式
■ 產生 ngram count的mapper, reducer■ 產生 query result的mapper, reducer■ 將 query result轉為 database(試試 python內建的 shelve或 sqlite3套件)
■ Database介面程式,讓使用者輸入 query,即時取得result
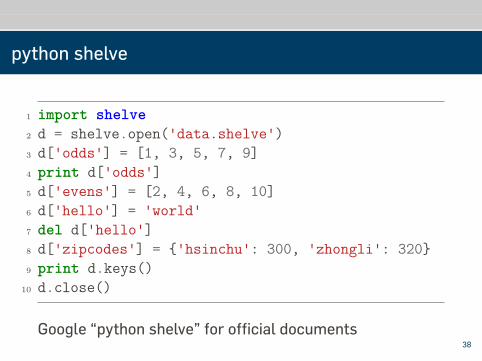
python shelve
1 import shelve2 d = shelve.open('data.shelve')3 d['odds'] = [1, 3, 5, 7, 9]4 print d['odds']5 d['evens'] = [2, 4, 6, 8, 10]6 d['hello'] = 'world'7 del d['hello']8 d['zipcodes'] = {'hsinchu': 300, 'zhongli': 320}9 print d.keys()
10 d.close()
Google “python shelve” for official documents38