mikro-kursus i statistik 1. del - person.hst.aau.dk · 24-11-2002 mikrokursus i biostatistik 3...
TRANSCRIPT

24-11-2002 Mikrokursus i biostatistik 1
Mikro-kursus i statistik1. del

24-11-2002 Mikrokursus i biostatistik 2
Hvad er statistik?
Det systematiske studium af tilfældighedernes spil
!Dyrkes af biostatistikere
Anvendes som redskab til vurdering af troværdighed af indsamlede data.
!Af epidemiologer!Af klinikere (fx jordemødre)!Og af mange andre…..
Ikke bare et redskab for sundhedsvidenskab, men også for andre videnskaber, der gør brug af kvantitativ metode.

24-11-2002 Mikrokursus i biostatistik 3
Hvorfor er der brug for statistik?
Data/observationer er underlagt tilfældig variation.
Behov for at kvantificere*, hvor meget skyldes tilfældig oghvor meget skyldes systematisk (=ikke tilfældig) variation.
Behov for at resumere mange enkelte observationer i noglefå tal. Det vil sige beskrive de centrale tendenser.
*beskrive med tal…

24-11-2002 Mikrokursus i biostatistik 4
Forskellige typer statistik
Deskriptiv statistik, hvor vi beskriver vores datasætUdregning af middelværdi (=gennemsnit) i datasættet
Analytisk statistik, hvor vi prøver at kvantificere den tilfældig variation, som vores datasæt er underlagt.
- ’Vi analyserer variationen i datasættet’.Hvor sikker kan du være på, at den middelværdi, du har målt, repræsenterer den virkelige middelværdi.

24-11-2002 Mikrokursus i biostatistik 5
Forskellig brug af statistikSamfundsvidenskab:! Bruger oftest kun deskriptiv statistik! Den fastsatte værdi står alene
Opinionsundersøgelser, spørgeskemaundersøgelser28% ønsker mulighed for frit valg af forløsningsmetode!
Naturvidenskab:! Man går som hovedregel videre:! Den fastsatte værdi bruges til at komme med et gæt på den
tilsvarende, men ukendte, værdi i populationen.Den gennemsnitlige fødselsvægt for maj måned i Nordjyllands Amt brugt som gæt på den gennemsnitlige fødselsvægt i Danmark.
! Når vores fundne værdi anvendes som gæt, kaldes den et estimat.
! - og den ukendte, sande værdi, vi ønsker at sige noget om, kaldesen parameter
• Husk: Kun ’Vor Herre’ kender den eksakte værdi på en parameter.

24-11-2002 Mikrokursus i biostatistik 6
Hyppigt anvendte deskriptive mål:! Middelværdi, fx fødselsvægt! Forskel i middelværdi, fx fødselsvægt rygere/ikke
rygere! Prævalens: Hvor mange har en givet sygdom /
karakeristikum på et givet tidspunkt?Hyppigheden af gravide rygere i 1. trimester.
! Incidens: Hvor mange får en givet sygdom / karakteristikum indenfor en fastsat periode?
Nye tilfælde af rubella i Nordjylland pr år! Relativ risiko eller odds ratio: Sammenligning af to
risici (fx 2 odds eller 2 incidenser).Hvor meget større er din risiko for at få en episiotomi, hvis du bor på Sjælland i forhold til, hvis du bor i Jylland?
Deskriptiv statistik
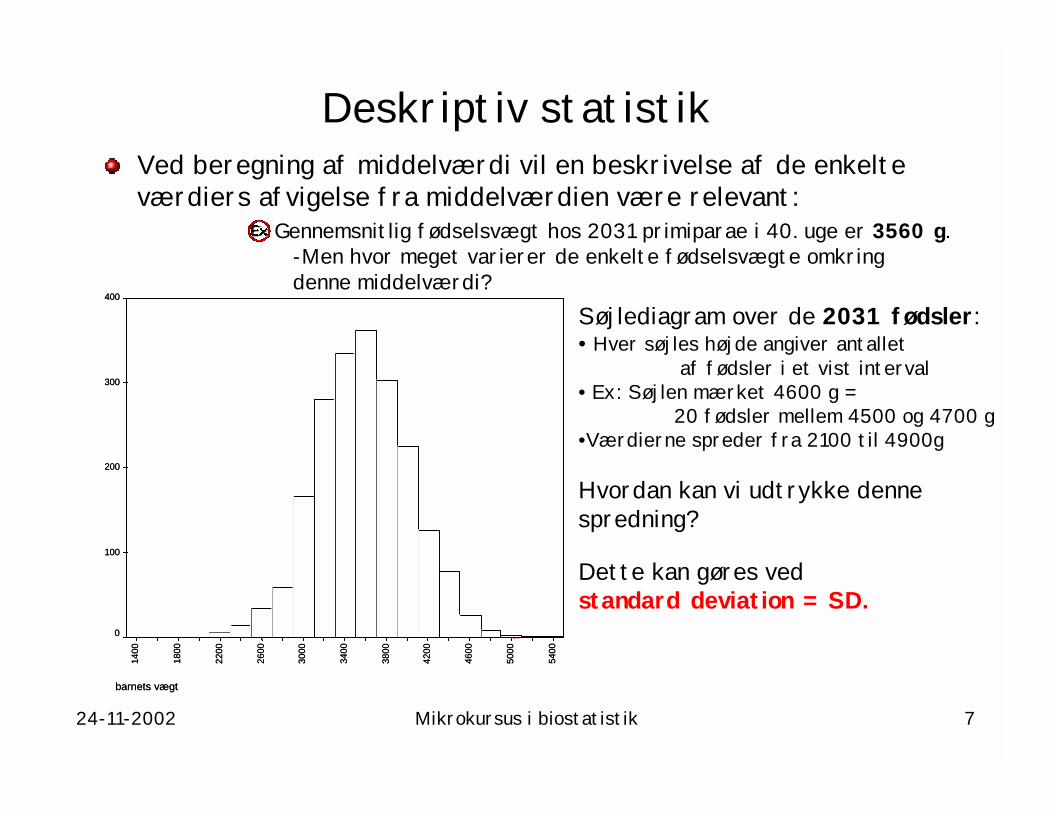
24-11-2002 Mikrokursus i biostatistik 7
Ved beregning af middelværdi vil en beskrivelse af de enkelte værdiers afvigelse fra middelværdien være relevant:
Gennemsnitlig fødselsvægt hos 2031 primiparae i 40. uge er 3560 g. -Men hvor meget varierer de enkelte fødselsvægte omkring denne middelværdi?
Deskriptiv statistik
Søjlediagram over de 2031 fødsler:• Hver søjles højde angiver antallet
af fødsler i et vist interval• Ex: Søjlen mærket 4600 g =
20 fødsler mellem 4500 og 4700 g•Værdierne spreder fra 2100 til 4900g
Hvordan kan vi udtrykke denne spredning?
Dette kan gøres ved standard deviation = SD.
barnets vægt
5400
5000
4600
4200
3800
3400
3000
2600
2200
1800
1400
400
300
200
100
0
barnets vægt
5400
5000
4600
4200
3800
3400
3000
2600
2200
1800
1400
400
300
200
100
0

24-11-2002 Mikrokursus i biostatistik 8
Hvad er Standard Deviation (SD)SD udregnes ved en formel, som I ikke skal bekymre jer om. Men forestil
jer alligevel:
! Observationerne varierer fra middelværdien 3560g i forskellig grad:fx 3210g afviger med -350g, 2780g med –780g, 4410g med 850g osv.
! Disse afvigelser (= deviations) gøres op for samtlige observationer.
! Herefter kvadreres de (ex –3502, –7802, 8502 osv), så de alle bliver positive
! Så lægges de sammen (ex –3502 + –7802 + 8502 osv).
! Til slut divideres den samlede sum med antallet af observationer.
! Nu har man variansen.
! derefter Standard deviation = kvadratroden af variansen.
! Standard deviation = SD

24-11-2002 Mikrokursus i biostatistik 9
Normalfordelte dataHvis vi ser på vores stikprøve af fødselsvægte, er fordelingen flot klokkeformet og symmetrisk.En sådan fordeling af data kaldes en normalfordelingDen følger en kurve, som kan beskrives ved en formel, hvori middelværdi og spredning indgår. Formlen er skrækkeligt indviklet…Men vhja. formlen kan man beskrive, hvordan data er fordelt.
barnets vægt
5400
5000
4600
4200
3800
3400
3000
2600
2200
1800
1400
400
300
200
100
0
barnets vægt
5400
5000
4600
4200
3800
3400
3000
2600
2200
1800
1400
400
300
200
100
0

24-11-2002 Mikrokursus i biostatistik 10
68.3% = ca. 2/3Middelværdi = M (gennemsnit)Standarddeviation = SD (spredning)
M – 1 SD M + 1 SDM
Middelværdien +/- 1 SDomfatter 2/3 af samtligeobservationer.
Fordeling af data i en normalfordeling
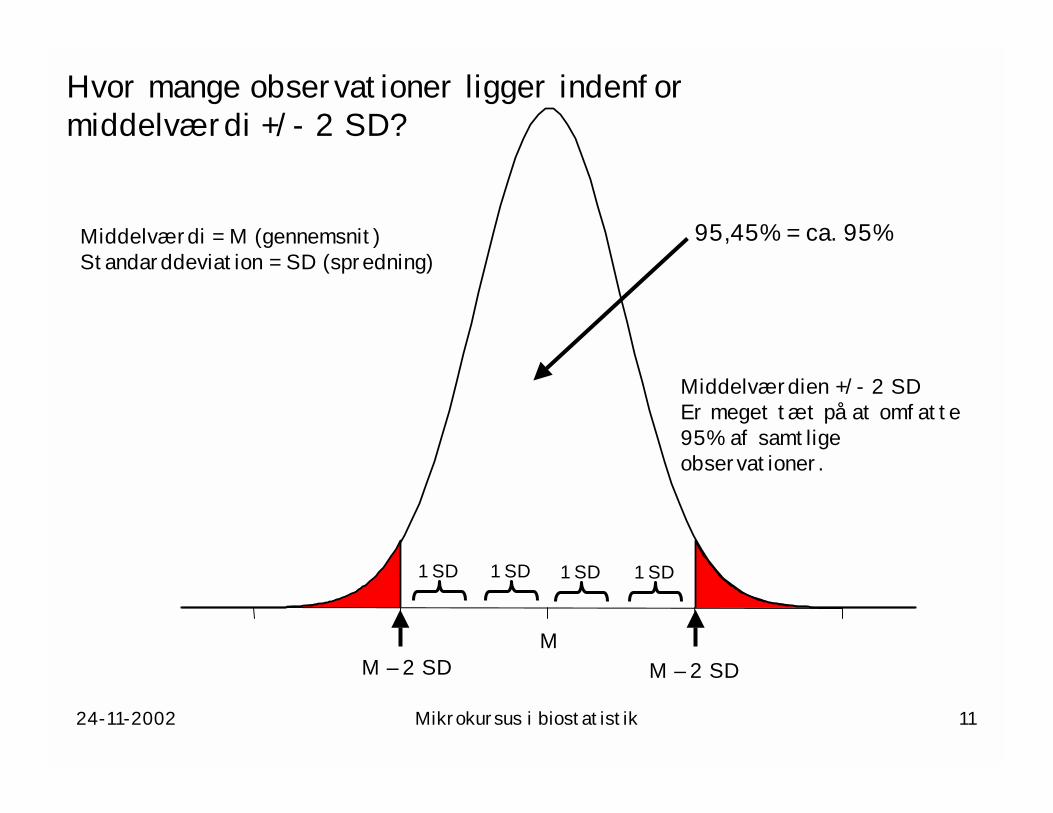
24-11-2002 Mikrokursus i biostatistik 11
Hvor mange observationer ligger indenformiddelværdi +/- 2 SD?
Middelværdi = M (gennemsnit)Standarddeviation = SD (spredning)
M – 2 SDM
M – 2 SD
1 SD 1 SD 1 SD 1 SD
95,45% = ca. 95%
Middelværdien +/- 2 SDEr meget tæt på at omfatte95% af samtligeobservationer.
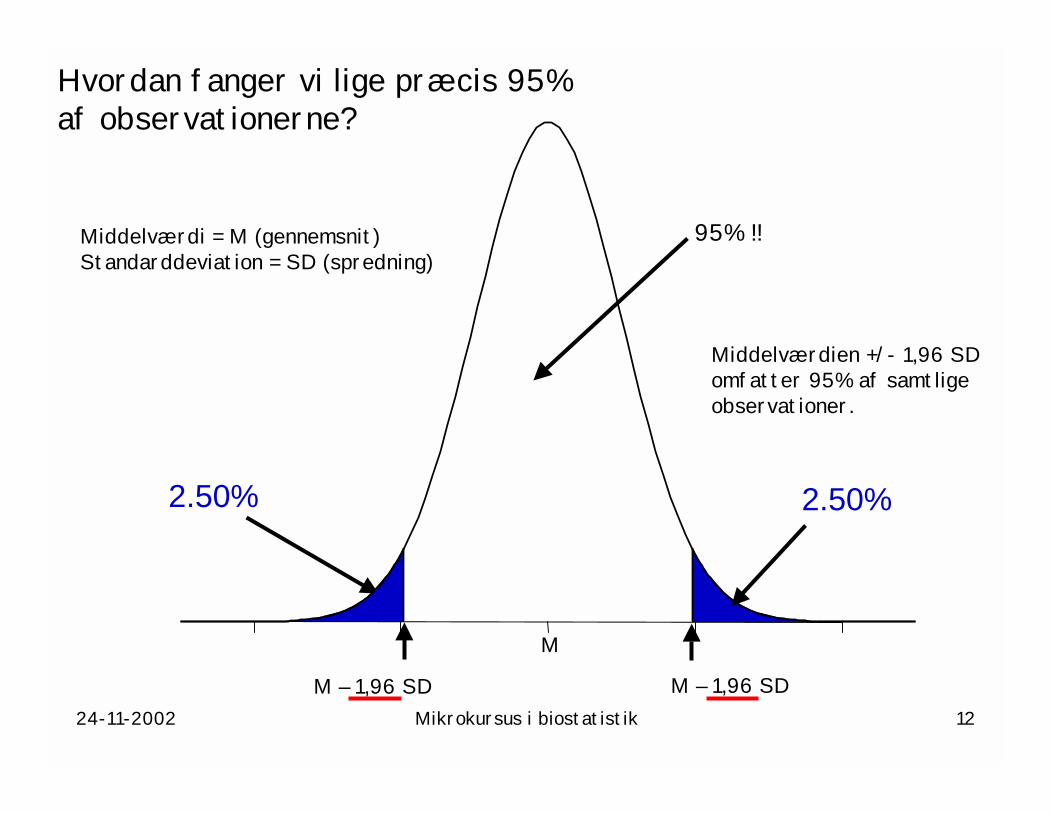
24-11-2002 Mikrokursus i biostatistik 12
2.50% 2.50%
Hvordan fanger vi lige præcis 95%af observationerne?
Middelværdi = M (gennemsnit)Standarddeviation = SD (spredning)
95% !!
M – 1,96 SD
M
M – 1,96 SD
Middelværdien +/- 1,96 SDomfatter 95% af samtligeobservationer.

24-11-2002 Mikrokursus i biostatistik 13
SD kan også udregnes for andre fordelinger, fx en rektangulær
fordeling, men giver så ikke samme mening som for en normalfordeling!
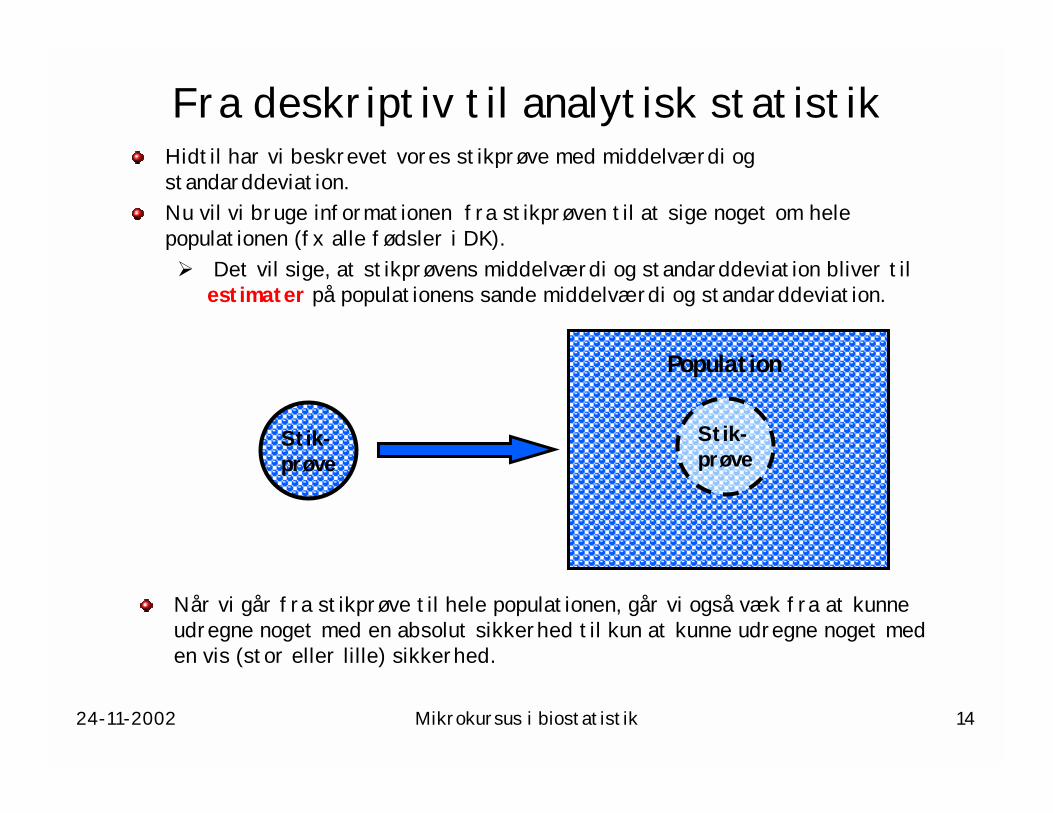
24-11-2002 Mikrokursus i biostatistik 14
Fra deskriptiv til analytisk statistikHidtil har vi beskrevet vores stikprøve med middelværdi og standarddeviation.Nu vil vi bruge informationen fra stikprøven til at sige noget om hele populationen (fx alle fødsler i DK).! Det vil sige, at stikprøvens middelværdi og standarddeviation bliver til
estimater på populationens sande middelværdi og standarddeviation.
Stik-prøve
Stik-prøve
Population
Når vi går fra stikprøve til hele populationen, går vi også væk fra at kunne udregne noget med en absolut sikkerhed til kun at kunne udregne noget med en vis (stor eller lille) sikkerhed.

24-11-2002 Mikrokursus i biostatistik 15
Hvorfor analytisk statistik?Naturvidenskabelig seriøsitet er synonymt med inddragelse af statistisk usikkerhed ved vurdering af resultatet….
Ved publicering af en fundet forskel vil der blive afkrævet oplysninger om:! Hvor stor kan man regne med, at den fundne
forskel er?
! Hvor sikker kan man være på, at den fundne forskel er sand?

24-11-2002 Mikrokursus i biostatistik 16
Forskellige typer analytisk statistik
Mål for usikkerhed på estimatet! ’Estimate’ betyder egentlig noget i retning af bedste gæt.! Ved hjælp af statistik prøver man at kvantificere, hvor sikkert dette bedste
gæt er i forhold til at sige noget om den tilsvarende parameter, dvs. den sande værdi (som ingen reelt kender).
Konfidensintervaller: gennemsnitlig fødselsvægt 3570g (95% CI: 3310g – 3830g).
Hypotesetestning! Man prøver at vurdere om en funden forskel mellem to grupper er tilfældig
eller sand. P-værdi: Fordoblet risiko for makrosomi ved diabetes (p = 0,02).
Lad os starte med konfidensintervallerne…
24-11-2002 Mikrokursus i biostatistik 17
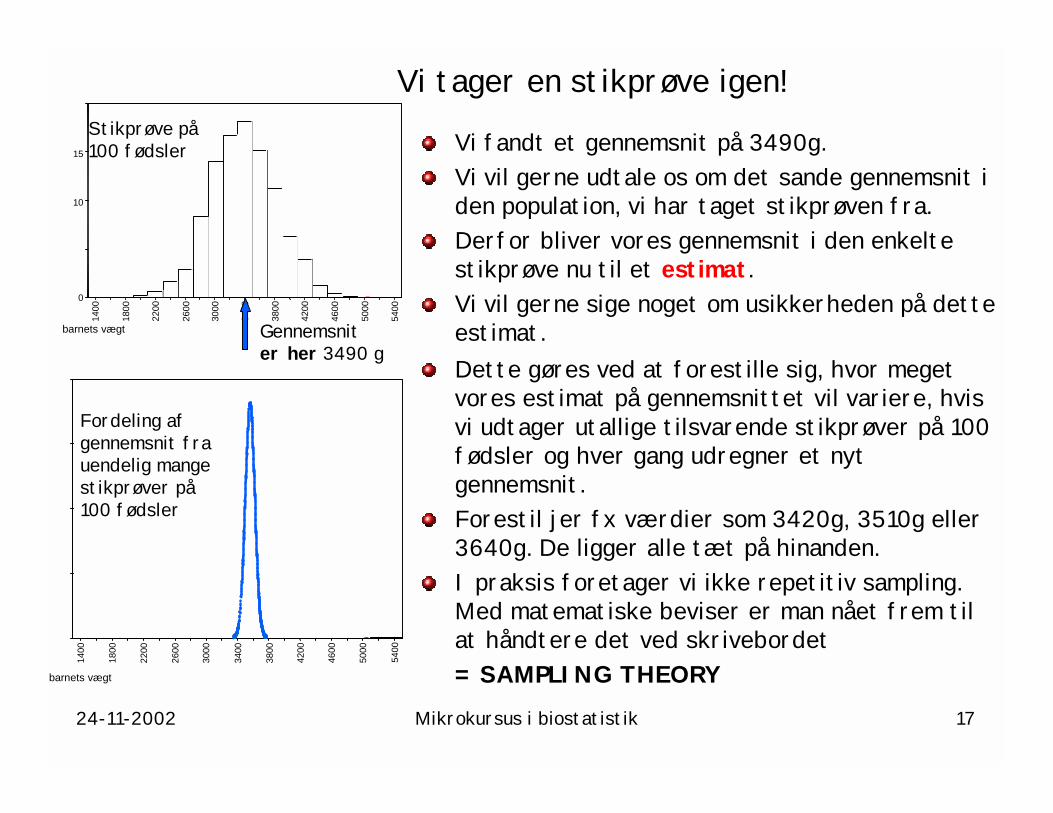
Vi tager en stikprøve igen!
Vi fandt et gennemsnit på 3490g.Vi vil gerne udtale os om det sande gennemsnit i den population, vi har taget stikprøven fra.Derfor bliver vores gennemsnit i den enkelte stikprøve nu til et estimat.Vi vil gerne sige noget om usikkerheden på dette estimat.barnets vægt
5400
5000
4600
4200
3800
3400
3000
2600
2200
1800
1400
15
10
0
Stikprøve på100 fødsler
Gennemsniter her 3490 g
barnets vægt
5400
5000
4600
4200
3800
3400
3000
2600
2200
1800
1400
Fordeling af gennemsnit fra uendelig mange stikprøver på 100 fødsler
Dette gøres ved at forestille sig, hvor meget vores estimat på gennemsnittet vil variere, hvis vi udtager utallige tilsvarende stikprøver på 100 fødsler og hver gang udregner et nyt gennemsnit.Forestil jer fx værdier som 3420g, 3510g eller 3640g. De ligger alle tæt på hinanden.I praksis foretager vi ikke repetitiv sampling. Med matematiske beviser er man nået frem til at håndtere det ved skrivebordet = SAMPLING THEORY

24-11-2002 Mikrokursus i biostatistik 18
Lad os se nærmere på fordelingen af alle vores stikprøvers middelværdi!
• Den vigtigste erkendelse i SAMPLING THEORY er, at denne fordeling er normalfordelt, hvis stikprøverne blot er rimeligt store (80-100) – dvs. også selv om fordelingen i populationen IKKE er normalfordelt.
Figuren illustrerer, hvordan alledisse stikprøver på 100 fødslermed hvert sit gennemsnit harbidraget til fordelingen
Gennemsnitlig fødselsvægti et sample på 100 fødsler
Man skal forestille sig, at hver stikprøves gennemsnit har en afvigelse (samplingsfejl) fra det sande, men ukendte gennemsnit.

24-11-2002 Mikrokursus i biostatistik 19
STANDARD ERROR er et mål for samplingsfejl!
Fra tidligere ved vi, at en normalfordeling beskrives ved en standard deviation- således også for den normalfordeling, som estimaterne (vore
bedste gæt) udgør ved uendelig mange samplinger.
Standard deviationen på estimaterne ved uendelige mange samplinger = Den sande STANDARD ERROR (SE).

24-11-2002 Mikrokursus i biostatistik 20
Tilbage til estimatet på middelværdien på fødselsvægten!
SM – 1,96 sSESand middelværdi (SM)
Kender vi ikke! SM + 1,96 sSE
2,5%2,5%
Estimaterne danner en normalfordeling omkring den sande, ukendte middelværdi (SM).
Der hører til den sande middelværdi en sand Standard Error (sSE), som I kan se på x-aksen.
Hver kugle repræsenterer 1% af es-timaterne, så der er 100 kugler i alt.
95% af estimaterne/kuglerne vil ligge indenforsand middelværdi +/- 1,96 sSE
1 sSE 1 sSE1 sSE1 sSE

24-11-2002 Mikrokursus i biostatistik 21
SM – 1,96 sSESand middelværdi (SM)
Kender vi ikke! SM + 1,96 sSE
2,5%2,5%
Estimaterne danner en normalfordeling omkring den sande, ukendte middelværdi (SM).
Der hører til den sande middelværdi en sand Standard Error (sSE), som I kan se på x-aksen.
Hver kugle repræsenterer 1% af es-timaterne, så der er 100 kugler i alt.
95% af estimaterne/kuglerne vil ligge indenforsand middelværdi +/- 1,96 sSE
For hver kugle/estimat kan duudregne en estimeret Standard error (SE) ved denne formel:
Hvad skal vi bruge den til????
nSDSE =
1 sSE 1 sSE1 sSE1 sSE

24-11-2002 Mikrokursus i biostatistik 22
Vi skal bruge Standard Error (SE) til at udregneet 95% konfidensinterval!
Et 95% konfidensinterval udregnes ved formlen:Estimatet på middelværdi +/- 1,96 SE
Gennemsnit på fødselsvægt i et sample på 100 fødsler = 3510gSD = 450g
SE = 45g3510g +/- 1,96 x 45 = 3510 +/- 87g= 3423g til 3597g = 95% konfidensinterval
nSDSE =
Men hvad fortæller et 95% konfidensinterval os?

24-11-2002 Mikrokursus i biostatistik 23
SM – 1,96 sSESand middelværdi (SM)
Kender vi ikke! SM + 1,96 sSE
2,5%2,5%
95% af estimaterneville ligge her
1
32
95% KONFIDENSINTERVAL:
Estimatet på middelværdi +/-1,96 SE svarer til det interval, hvor det i 95% af tilfældene vil gælde, at den sande værdi er indeholdt.
Der er altså en risiko på 5% for, at vi sidder med et interval, der har ramt ved siden af den sande middelværdi.
Det kan illustreres ved, at vi forestiller os, at vi udregneret konfidensinterval for allevores kugler.
Hvordan det?
24-11-2002 Mikrokursus i biostatistik 24
SM – 1,96 sSESand middelværdi (SM)
Kender vi ikke! SM + 1,96 sSE
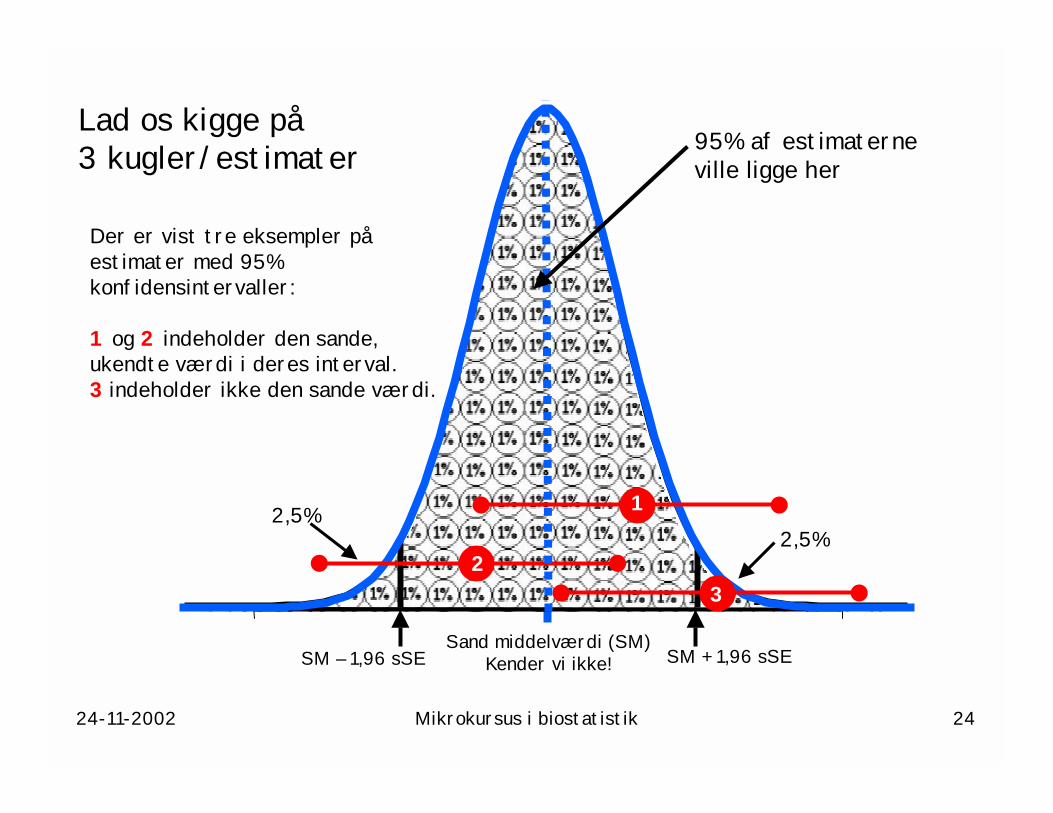
Lad os kigge på 3 kugler/estimater
2,5%2,5%
Der er vist tre eksempler på estimater med 95% konfidensintervaller:
1 og 2 indeholder den sande,ukendte værdi i deres interval.3 indeholder ikke den sande værdi.
1
32
95% af estimaterneville ligge her

24-11-2002 Mikrokursus i biostatistik 25
SM – 1,96 sSESand middelværdi (SM)
Kender vi ikke! SM + 1,96 sSE
Lad os kigge på 3 kugler/estimater
2,5%2,5%
Der er vist tre eksempler på estimater med 95% konfidensintervaller:
1 og 2 indeholder den sande,ukendte værdi i deres interval.3 indeholder ikke den sande værdi.
Det kan indses, at de kugler/estimater, der ligger indenfor den sande middelværdi +/- 1,96sSEogså vil have konfidensintervaller, derindeholder den sande, men ukendtemiddelværdi.Det er i alt 95% af kuglerne/estimaterne
Ved 5% af kuglerne rammerkonfidensintervallerne vedsiden af den sande middel-værdi.
1
32
24-11-2002 Mikrokursus i biostatistik 26
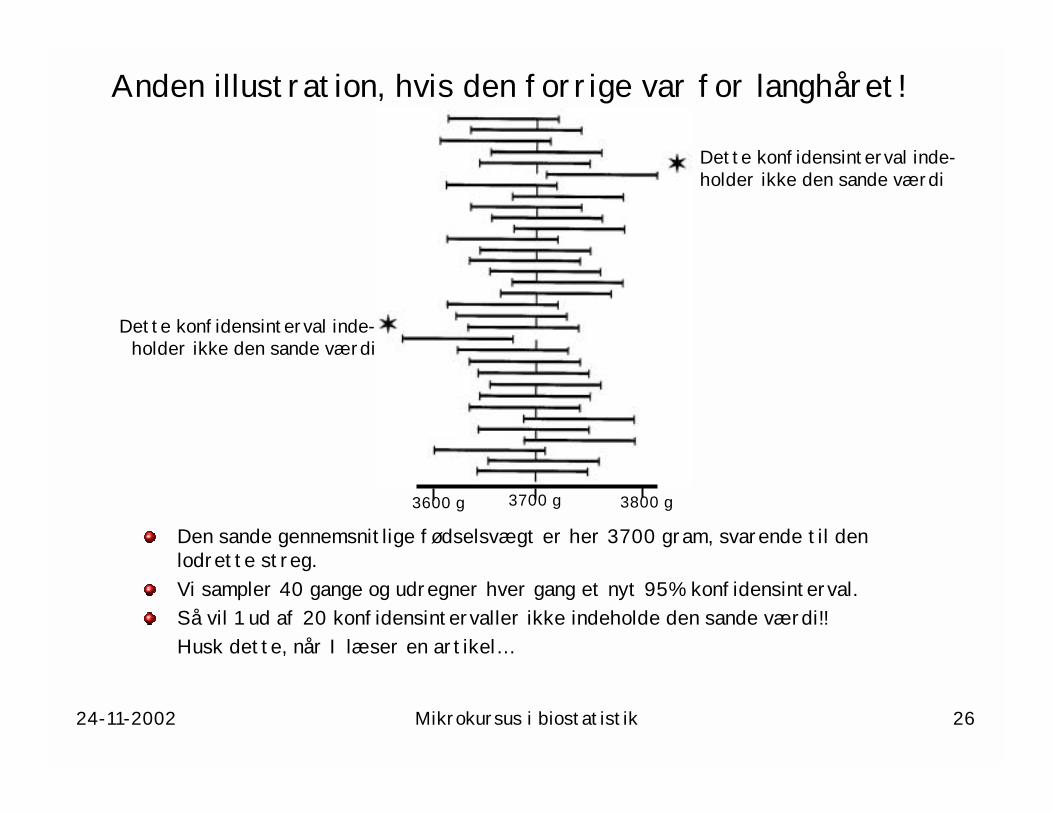
Anden illustration, hvis den forrige var for langhåret!
Den sande gennemsnitlige fødselsvægt er her 3700 gram, svarende til den lodrette streg.Vi sampler 40 gange og udregner hver gang et nyt 95% konfidensinterval.Så vil 1 ud af 20 konfidensintervaller ikke indeholde den sande værdi!!Husk dette, når I læser en artikel…
Dette konfidensinterval inde-holder ikke den sande værdi
Dette konfidensinterval inde-holder ikke den sande værdi
3700 g3600 g 3800 g
24-11-2002 Mikrokursus i biostatistik 27
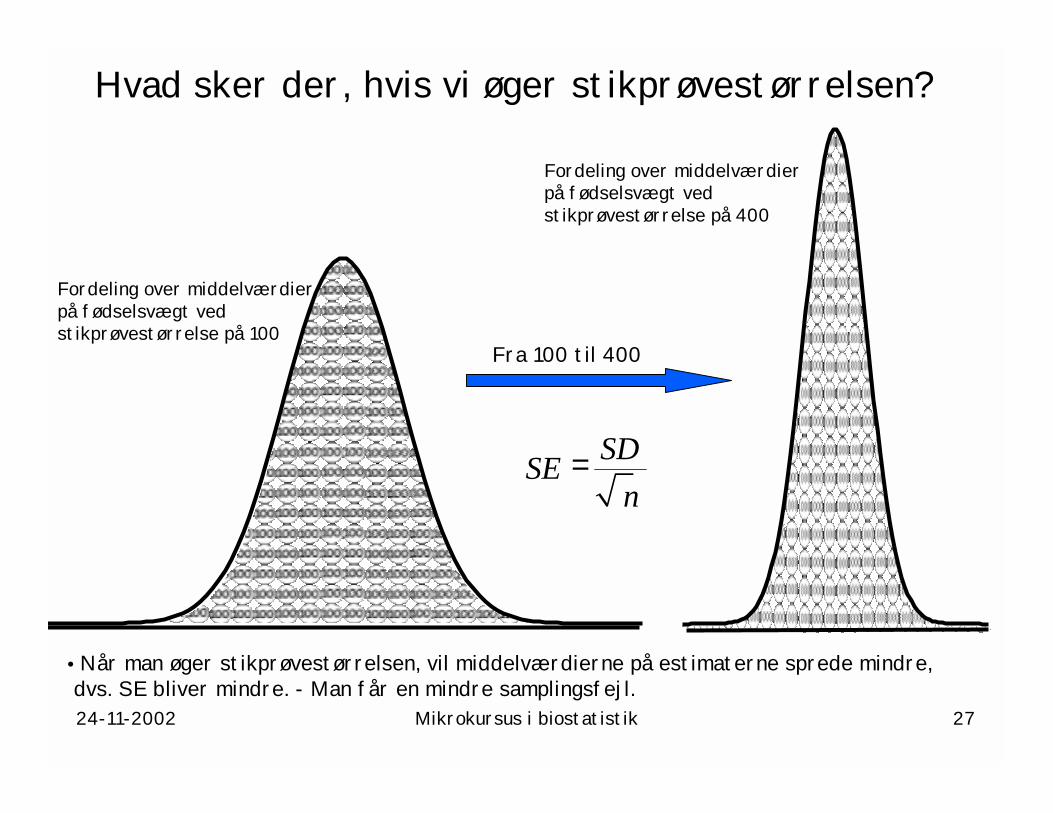
Hvad sker der, hvis vi øger stikprøvestørrelsen?
Fra 100 til 400
• Når man øger stikprøvestørrelsen, vil middelværdierne på estimaterne sprede mindre,dvs. SE bliver mindre. - Man får en mindre samplingsfejl.
Fordeling over middelværdierpå fødselsvægt ved stikprøvestørrelse på 100
Fordeling over middelværdierpå fødselsvægt ved stikprøvestørrelse på 400
nSDSE =

24-11-2002 Mikrokursus i biostatistik 28
OPSUMMERING, KONFIDENSINTERVALLER
Vi er nødt til at regne med, at vores resultat er påvirket af tilfældigheder.Denne usikkerhed prøver vi at udtrykke ved at opgive resultatet som et interval.Et bredt konfidensinterval indikerer lav præcision, medens et smalt konfidensinterval indikerer høj præcision.Et 95% konfidensinterval (sikkerhedsinterval) udtrykker det interval, hvor om det gælder:! At gentages dataindsamlingen 100 gange, hvor der hver gang
beregnes et nyt konfidensinterval, vil dette interval i 95 ud af de 100 gange indeholde den sande, men ukendte, værdi.
! Det vil sige man kan regne med, at 1 ud af 20 konfidensintervaller er misvisende, det vil sige indeholder ikke den sande, men ukendte, værdi.

24-11-2002 Mikrokursus i biostatistik 29
Hvad er sandsynligheden for,at mani et 95% konfidensintervalhar ramt den sande værdi?
Forestil jer en cowboy med bind for øjnene. Han har 100 af de der lassoer med sten i enden(konfidensintervaller) at kaste efter en hest (=sandheden).
Vi ved, at ud fra tilfældighedsprincippet vil 95 af lassoerne ramme hesten, medens 5 vil rammeved siden af.
Når han kaster den første lasso, er der 95% sandsynlighed for at han vil ramme.
Dette er at ligestille med vores beregning af et konfidensinterval på et estimat i vores stik-prøve: Vi kaster altid kun den første lasso, de andre eksisterer kun matematisk. Vi kan der-for tillade os at sige, at der er 95% sandsyn-lighed for, at vi rammer den sande værdi.
O,96SE1SE
O,96SE
1SE
Nærbillede af lassoen
”Sandheden”

24-11-2002 Mikrokursus i biostatistik 30
16%
1 sSE1 sSE
16%
Sand middelværdi (SM)Kender vi ikke!
Hvad fortæller et konfidensinterval på +/- 1 Standard Error?De røde kugler repræsenterer estimater, der nu er påhæftet korte konfidensintervaller på +/- 1 SE (68% konfidensinterval)
De kugler/estimater, der ligger indenforden sande middelværdi +/- 1 SE vil også i konfidensintervaller på +/1 SE indeholdeden sande, men ukendte middelværdi.Det er i alt 68% af kuglerne/estimaterne
Ved 32% af kuglerne rammerde korte konfidensintervaller ved siden af den sande middel-værdi.
Konklusion: At gentages dataindsamlingen 100 gange, hvor der hver gang beregnes et nyt 68% konfidensinterval, vil dette interval i 68 ud af de 100 gange indeholde den sande, men ukendte, værdi.

24-11-2002 Mikrokursus i biostatistik 31
”Sandheden”
Hvad er sandsynligheden for,at man i et konfidensinterval på +/- 1 SEhar ramt den sande værdi?
Forestil jer igen en cowboy med 100 lassoer, som nu er blevet kortet ned til +/- 1 Standard Error. Han kaster igen efter hesten (=sandheden) oghar stadigvæk bind for øjnene.
Vi ved, at ud fra tilfældighedsprincippet vil 68af lassoerne ramme hesten, medens 32 vilramme ved siden af.
Når han kaster den første lasso, er der 68% sandsynlighed for at han vil ramme.
Dette er at ligestille med vores beregning af et konfidensinterval på et estimat i vores stik-prøve: Vi kaster altid kun den første lasso, de andre eksisterer kun matematisk. Der er derfor 68% sandsynlighed for, at vi rammer den sande værdi med dette afkortede konfidensinterval.
1SE 1SE
Nærbillede af lassoen

24-11-2002 Mikrokursus i biostatistik 32
Kan vi komme tættere på, hvor vi har den sande værdi i et 95% konfidensinterval?
Sandsynligheden for at ramme den sande værdi med en +/-1,96 SE-lasso var 95%.Sandsynligheden for at ramme den sande værdi med en +/- 1 SE-lasso var 68%.Hvor stor er sandsynligheden for, at den sande værdi ligger i de yderste SE’er i 2 SE-lassoen?
O,96SE
1SE
O,96SE
1SE
Nærbillede af lassoenInderste 2 SE
Yderste 2 SE
Vi skillerden ad!
•Alle 4 SE = ca. 95%
•Inderste 2 SE = 68%
•Yderste 2 SE = 95% - 68% = 27%
Sandsynligheden for at den sande værdi ligger i de to yderste SE= 27%.Hvor meget højere er sandsynligheden for, at den sande værdi ligger i de inderste 2 SE i forhold til sandsynligheden for, at den ligger i de to yderste SE?= 68 % / 27% = 2,5 gange højere.Altså er sandsynligheden for, at den sande værdi ligger i de inderste 2 SE over dobbelt så stor som sandsynligheden for, at den ligger i de to yderste SE.HUSK DET NÅR I VURDERER ET KONFIDENSINTERVAL!! Sandsynlig-heden er ikke ens overalt i intervallet, men højest i nærheden af jeres punktestimat. – Den er faktisk normalfordelt omkring jeres punktestimat…