シリーズml-07 ニューラルネットワークによる非線形回帰
TRANSCRIPT

Ver. 1.0, 2017-08-11
森下功啓
1

2
線形回帰では、式(1)を用いて変数を予測する。
𝑦 = 𝛽0 + 𝛽1𝑥1 + 𝛽2𝑥2 +⋯+ 𝛽𝑛𝑥𝑛 (1)
しかしながら、1次式だけで予測できるものは少ない。sin関数すら予測できない。
そこで、ニューラルネットワークを用いて非線形な回帰問題に対応する方法をこのスライドでは解説しよう。

対応ポイント
• 非線形活性化関数を用いることが肝• 一次関数はいくら足しても一次関数
• 故に、活性化関数は非線形である必要がある
• ∴非線形活性化関数を持つ中間層が必要
• 中間層のユニット数と中間層数は、結果を見ながら調整• 少ないと近似精度が悪い
• 多すぎると過学習を起こしやすい
3
サンプルプログラムのダウンロード
4
1
2
Download: https://github.com/KatsuhiroMorishita/machine_leaning_samples

sin関数の近似
5

6
• 以降のスライドでは、下記のプログラムを使った解説を行います• sin関数を学習するサンプルです

keras_sin.py
• sin関数を学習するプログラム
7

8
モデルの作成
教師データ作成
学習
結合係数の保存など
グラフの表示

9
入力層の次の層(中間層)の活性化関数はsigmoid
この層(入力層)のユニット数は1個
学習係数は0.05
1つの教師データ当たりの学習回数は2000
10個の教師データを使って結合係数を更新する
次の層(中間層)のユニット数は15個
バイアス用のユニットは有効(標準で有効)
誤差関数は二乗平均誤差
学習中に状況を表示するなら1
結合係数の更新回数 = epochs / batch_size

モデルを図にするとこんな感じ
10
中間層(隠れ層)
出力層入力層
𝑥 𝑦
1
1
Unit 0
Unit 15
𝑤0,10
𝑤0,20
𝑤0,11
𝑤1,11
𝑤2,11
𝑤1,150
𝑤1,10
結合係数
Layer 0Layer 1
Layer 2
出力層のユニットの活性化関数は指定されていないので、linear
∴ ℎ 𝑧 = 𝑧
𝑦𝑗1 = sigmoid 𝑧𝑗
1 , 𝑗 ≥1
中間層のユニット𝑗の出力
𝑦 = 𝑦12 = 𝑧1
2

学習回数と誤差
11
Ephch 120 Ephch 240 Ephch 360
Ephch 480 Ephch 600 Ephch 720
Ephch 840 Ephch 960 Ephch 1080
←学習が進むにつ
れ、誤差が小さくなる様子が分かる
学習量が増えると成績が上がるのは人間と同じだ。

より一般的な非線形回帰モデル
12

一般的な非線形回帰への対応
• 活性化関数にsigmoidを利用している場合、入力値xが|x|>6であれば、その点での傾きがほぼ0• 微分しても傾きが0であれば学習できない
• 従って、より広い範囲で使える活性化関数が必要である• → LeakyReLUを使う
• 又は、入力するデータを次元ごとにN(0, 1)に変換する必要がある(概ね、|x|<6となる)
13http://www.procrasist.com/entry/2017/01/12/200000
LeakyReLU

14
• 以降のスライドでは、下記のプログラムを使った解説を行います• 一般的に拡張した非線形回帰用のサンプルです

regression_learning.csv
• 教師データ
15
特徴ベクトル(説明変数)
正解(目的変数)

16
regression_learning.csvで作成した散布図行列重回帰分析では問題になるほどの多重共線性がみられる。

prediction_data.csv
• 未知データ
• 正解が不明なデータです
17
特徴ベクトル(説明変数)

non_linear_regression.py
• 学習を実行するプログラム
• 読み込んだ教師データを自動的に学習データと検証データに分けて、過学習の判定と未知データに対する予測精度の評価ができる
18

19
教師データを読み込む関数
モデルの作成
学習データと検証データに分割
学習データと検証データと特徴ベクトルの次元数(説明変数の数)を変数に格納
p. 1

20
学習
結合係数の保存など
学習データと検証データのlossの変化をグラフとして表示
検証データの正解と予測値とで散布図を作成して表示
p. 2

21
入力層の次の層(中間層)の活性化関数はLeakyReLU
この層(入力層)のユニット数はs-1個(sはデータに合わせて自動で調整される)
学習係数は0.005
次の層(中間層)のユニット数は15個
バイアス用のユニットは有効(標準で有効)
誤差関数は二乗平均誤差
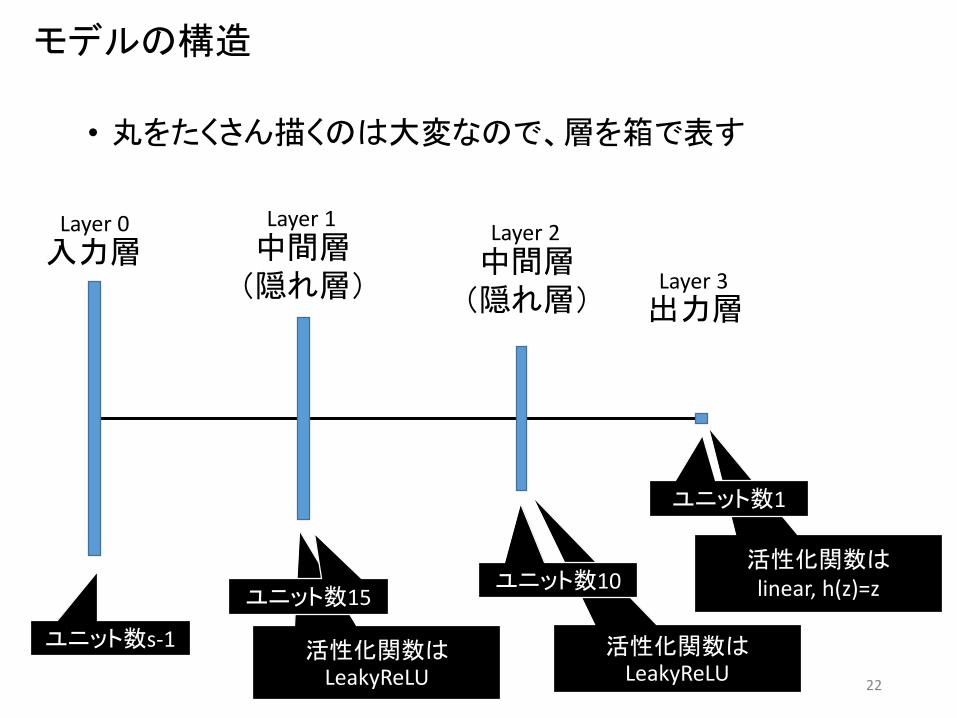
モデルの構造
結合係数の更新回数 = epochs / batch_size
活性化関数はlinear, h(z)=z
活性化関数はLeakyReLU
活性化関数はLeakyReLU
22
• 丸をたくさん描くのは大変なので、層を箱で表す
モデルの構造
ユニット数s-1
ユニット数15ユニット数10
ユニット数1
中間層(隠れ層)
出力層
入力層Layer 0 Layer 1
Layer 3中間層(隠れ層)
Layer 2

non_linear_regression.pyの実行で得られるグラフ
23
epochに対する学習データと検証データのlossの変化
この例では、lossの乖離が見られず、過学習は起こしていないことが分かる。
学習後に表示された、検証データの正解値と予測値の散布図
傾き1.0で直線に分布しているほど予測精度が高いことを示す。
loss(学習データに対するloss)とval_loss(検証データに対するloss)
が乖離していたら過学習
フラットになっているので、学習は十分に収束している

prediction.py
• 正解の不明な未知データを予測する
24

25
2次元配列文字列に変換する関数
モデルと結合係数のロード
予測用のデータを読み込む
予測値を求め、保存
全データが特徴ベクトル(説明変数)なので、スライス範囲は全範囲

prediction.pyを実行することでprediction_result.csvを得る
26
prediction_result.csv
prediction_data.csv
未知データ 正解の予測値

27

28
非線形近似をニューラルネットワーク(NN)で実現するには非線形な活性化関数を持つ中間層を追加するだけという、
なんとも単純なお話でした。
さて、これでNNを使った線形回帰の基本は終了です
次はNNを使って識別問題にトライしてみましょう