modelowanie i analiza danych przestrzennych w sejsmologii...
TRANSCRIPT

Modelowanie i Analiza Danych Przestrzennychw Sejsmologii i Sejsmometrii
Andrzej LeśniakKatedra Geoinformatyki i Informatyki StosowanejAkademia Górniczo-Hutnicza w Krakowie
Wykład 1
Procesy punktowe
Zestaw danych punktowych to obraz obiektów / wydarzeń wraz z ich lokalizacją w
regionie badania.
Punkty mogą reprezentować drzewa, gniazda zwierząt, epicentra trzęsień Ziemi,
lokalizacje przestępstw, miejsca zamieszkania określonej grupy osób,
położenie nowych przypadków grypy, rozkład galaktyk, itp.
Punkty mogą być usytuowane na powierzchni dwuwymiarowej (2D) lub na powierzchni
Ziemi bądź w 3D, itd. Mogą być również punktami w czasoprzestrzeni (np. epicentrum
trzęsienia Ziemi o określonym miejscu i czasie powstania).
2

Kiedy dane można traktować jako proces punktowy?
Rozkład obiektów może być traktowany jako proces punktowy jeśli ich rozkład jest
przypadkowy (lokalizacje punktów, liczba punktów, są losowe) i rozkład jest
obserwacją lub "odpowiedź" układu. Realizacja procesu punktu jest
nieuporządkowanym zestawem punktów, więc punkty nie mają określonego porządku
(chyba że istnieją markery bądź znaczniki – np. czas, do nich dołączone).
Przykład Płytka krzemowa jest sprawdzane pod kątem wad na powierzchni kryształu i
lokalizacje wszystkie wady są rejestrowane.
Rozkład wad może być analizowany w dwóch wymiarach jako proces punktowy, przy
założeniu, że wady są punktowe. Jesteśmy zainteresowani intensywność wad, rozstaw
między wadami itp
Przykład Wstrząsów wtórne trzęsienia Ziemi w Japonii są wykrywane, a ich szerokość,
długość i czas wystąpienia są rejestrowane.
Może to być analizowane jako czasoprzestrzenny proces punktowy (gdzie przestrzeń
jest dwuwymiarowy lub jest powierzchni Ziemi). Jeżeli czasy występowanie są
ignorowane, to staje się przestrzennym procesem punktowym.
Procesy punktowe
3
4
Sejsmiczność Europy – Rozkład epicentrów wstrząsów w okresie 2010 roku

Przykład
Rekina biały (samica Lydia)
został „wzbogacony” o nadajnik
satelitarny. W ciągu
kilku tygodni jego lokalizacja
jest zgłaszana raz na dobę. Te
punkty są nanoszone na mapę.
Położenia mogą być traktowane
jako realizacja
czasoprzestrzennego procesu
punktowego. Proces ten budują
pojedyncze punkty w
izolowanych punktach
czasowych. Te dane powinny
być traktowane jako bardzo
rzadko spróbkowana realizacja
ciągłego toru i analizowane przy
użyciu innych metod [które,
niestety, są stosunkowo słabo
rozwinięty] .
Procesy punktowe
5
Przykład Rozmieszczenie drobnych
przestępstw, które miały miejsce w
ubiegłym tygodniu rozmieszczone
na mapie Chicago.
Obraz może być analizowany jako
realizacja procesu punktowego.
Jesteśmy zainteresowani
intensywnością (skłonność do
wystąpienia zbrodni), wszelkimi
zmianami przestrzennymi w
intensywności, klastrami
przestępstw itp. Jedną kwestią
dyskusyjną jest czy zapisane
przestępstwa mogą zdarzyć się w
dowolnym miejscu przestrzeni
dwuwymiarowej, czy są one w
rzeczywistości ograniczone do
miejsc na ulicach (tworząc w ten
sposób proces punktowy na sieci
jednowymiarowej).
Procesy punktowe
6

Sformułowanie ścisłe:
Zakładamy, że proces punktowy X (w tzw. „modelu standardowym”) rozciąga się w
całej przestrzeni 2D lecz jest obserwowany w skończonym oknie W. Wewnątrz okna
obserwowane są dane których kolejność jest nieistotna:
( ) 0,,,, 21 ≥∈= nWxxxx inKx
Okno W jest ustalone i znane (!). Naszym celem jest znalezienie zależności
pomiędzy obiektami obserwowanymi w oknie W.
Położenie okna jest istotne ponieważ
zakładamy, że znane są wszystkie
miejsca, gdzie są ulokowane badane
obiekty jak również miejsca gdzie ich na
pewno nie ma.
W analizie współzmiennych procesów
musimy mianowicie brać pod uwagę
położenia obiektów obu procesów w
punktach o różnej lokalizacji
przestrzennej.
Procesy punktowe
7
Intensywność
Kiedy analizujemy dane liczbowe, często zaczynamy od obliczenia wartości średniej z
próby. Analogicznie do średniej lub przewidywanej wartości zmiennej losowej dla
procesu punktowego mówimy o intensywności.
Intensywność (ang. intensity) to średnia gęstość punktów (oczekiwana liczba
punktów na jednostkę powierzchni). Intensywność może być stała (jednorodna) lub
może się zmieniać w zależności od lokalizacji (intensywność niejednorodna).
Procesy punktowe – intensywność procesu
8

Jeśli proces punktowy X jest jednorodny to dla każdego podregionu B przestrzeni
dwuwymiarowej oczekiwana liczba punktów w B jest proporcjonalna do pola
powierzchni B:
Współczynnik proporcjonalności λ jest nazywany intensywnością.
( )( ) ( )BareaBN ⋅=∩ λXE
Należy rozróżnić rozkład o intensywności jedno- i niejednorodnej od zależności
(statystycznej) między punktami w przestrzeni. Możemy powiedzieć, że punkty są
rozłożone niezależnie od siebie (przypadkowo) lub regularnie bądź w klastrach.
Procesy punktowe – intensywność procesu
9
Jeśli wiemy, że proces punktowy jest jednorodny, to empiryczna gęstość punktów,
( )( )Warea
xn=λ
jest nieobciążonym estymatorem prawdziwej intensywności λ.
Na ogół, intensywność procesu punktowego zmienia się w zależności od miejsca.
Załóżmy, że spodziewana liczba punktów w małym regionie o obszarze du wokół
lokalizacji u jest równa . W tym wypadku jest funkcją intensywności procesu
spełniającą równanie:
duλ ( )uλ
( )( ) ( )duuBNB
∫=∩ λXE
dla każdego podobszaru B.
Procesy punktowe – intensywność procesu
10

W niektórych wypadkach obserwujemy osobliwe zgrupowaną intensywność (np
epicentrum trzęsień Ziemi zagęszczone wzdłuż linii uskoku) tak, że funkcja
intensywności nie istnieje. Możemy wówczas posługiwać się „miernikiem
intensywności” o postaci:
( ) ( )( )BNB ∩=Λ XE
zakładając, że wartość oczekiwana jest skończona dla 2
R⊂B
Jeśli podejrzewamy, że intensywność nie jest jednorodna, funkcja intensywność
lub miernik intensywności można oszacować nieparametrycznymi technikami
takimi jak szacowanie lokalne (obliczenia w kwadratach) bądź użycie funkcji
jądrowych.
W pierwszej z metod dzielimy obszar na równe podobszary
w kształcie kwadratów i zliczamy obiekty które znalazły się w każdym podobszarze:
Jest to nieobciążony estymator miernika intensywności
nBBBB K,,, 321
( ) nkBXnn kk ,,1 K=∩=( )
kBΛ
Procesy punktowe – intensywność procesu
11
Jądrowy estymator funkcji intensywności jest z kolei równy:
gdzie jest dowolną funkcją jądrową (dowolną funkcją gęstości
prawdopodobieństwa) zaś
( ) ( ) ( )∑=
−=n
k
ixuueu1
~κλ
( ) ( )dvvuueX
∫ −=−
κ1
( ) ( ) ( ) ( )dvvvuueuX
λκλ ∫ −=*
( )uκ
jest funkcją korygującą efekt obciążenia estymatora efektami związanymi z
brzegiem. Oczywiście jest nieobciążonym estymatorem uśrednionej wersji
estymatora intensywności danej wzorem:
( )uλ~
Wybór konkretnego jądra wygładzania (funkcji gęstości) zawsze wiąże się z
kompromisem między wielkością obciążenia i wariancji.
Procesy punktowe – intensywność procesu
12

Procesy punktowe – jądrowy estymator uśredniający
W wypadku obliczeń przedstawionych w ramach bieżącego wykładu używana
będzie kwadratowa funkcja jądrowa:
( ) ( ) ( )
−∈−=
reszta
udlauu
0
1,113 22
πκ
gdzie dla u=(x,y) :
222yxu +=
( ) ( )∑
=
−=
n
k
i
h
xu
h
ueu
12
~κλ
Jeśli chcemy sterować szerokością
f. jądrowej wzór na funkcję
intensywności będzie miał postać:
dla małych h wygładzenie będzie mniejsze (będą występować impulsy) dla dużych h
wygładzenie (rozmycie) będzie większe13
Estymacja funkcji intensywności procesu
punktowego odbywa się poprzez zliczanie
obiektów w podobszarach.
Wynik będzie w sposób istotny zależał od
wielkości obszarów.
Nie ma jednoznacznej odpowiedzi jaka
powinna być gęstość aby wynik estymacji był
wiarygodny.
Procesy punktowe – intensywność procesu
14
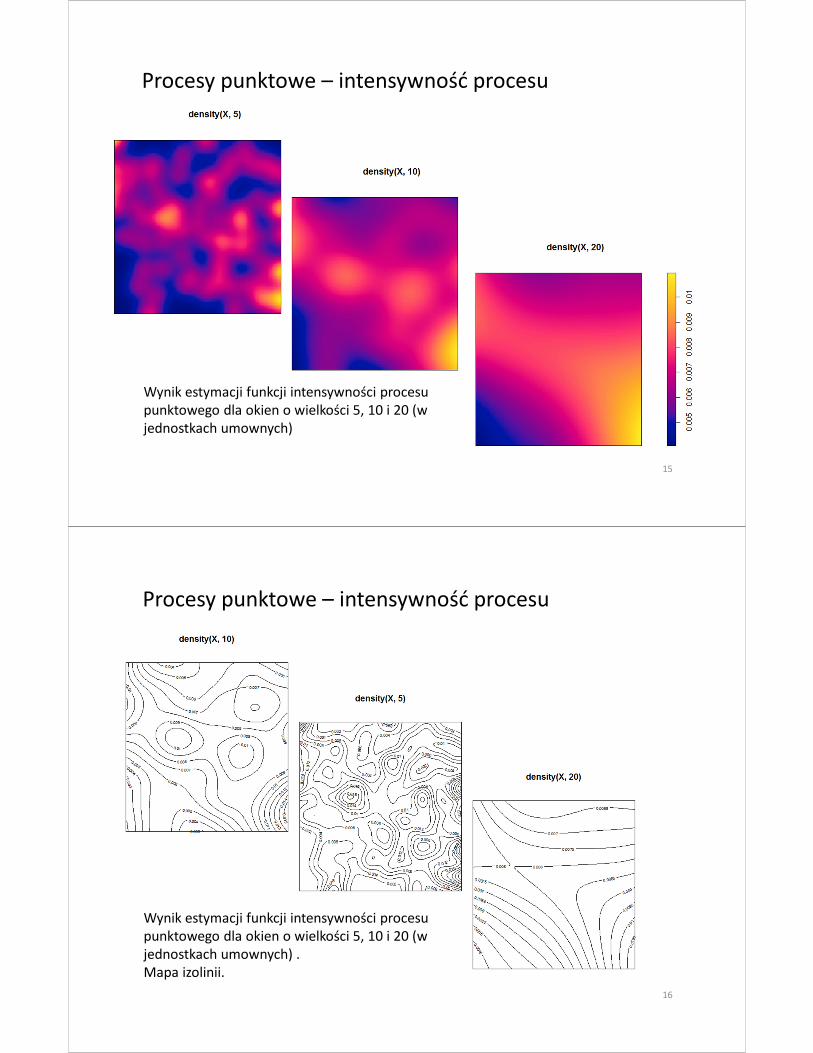
Wynik estymacji funkcji intensywności procesu
punktowego dla okien o wielkości 5, 10 i 20 (w
jednostkach umownych)
Procesy punktowe – intensywność procesu
15
Wynik estymacji funkcji intensywności procesu
punktowego dla okien o wielkości 5, 10 i 20 (w
jednostkach umownych) .
Mapa izolinii.
Procesy punktowe – intensywność procesu
16

Przykład analizy procesu punktowego – występowanie drzewa Beilschmiedia w lesie
tropikalnym
Procesy punktowe – intensywność procesu
17
Procesy punktowe – intensywność procesu
18
Intensywność procesu (kolor) wykreślona z użyciem funkcji jądrowych o założonej
szerokości.

Procesy punktowe – intensywność procesu
19
Inny sposób prezentacji – w 3D, bez kolorów
0.002
0.002
0.0
02
0.004
0.0
04 0.006
0.006
0.0
06 0
.008
0.008
0.0
08 0.01
0.01
0.012
0.012
0.012
0.0
14
0.014
0.014
0.0
16
0.016
0.018
Procesy punktowe – intensywność procesu
20
Inny sposób prezentacji – mapa izolinii w 2D, bez kolorów

Często chcemy wiedzieć, czy funkcja intensywności dla pewnego rozkładu obiektów
(punktów) zależy od wartości innej zmiennej (tzw. zmiennej towarzyszącej).
Dla przykładu, czy intensywność rozkładu punktów bei (drzewa w tropikalnym lesie
deszczowym) pozostaje w jakiejkolwiek relacji z wysokością nad poziom morza bądź
np. z nachyleniem stoków. Interesujące jest ustalenie czy drzewa wolą rosnąć na
stromym czy na płaskim terenie oraz czy wolą konkretnej wysokości n.p.m. ?
Procesy punktowe – intensywność procesu
21
Nachylenie
Wysokość n.p.m.
Obiekty (drzewa) poddawane zliczaniu
Procesy punktowe – intensywność procesu
22

W metodzie liczenia w kwadratach , de facto każdy wybór kształtu do obliczeń jest
dopuszczalny. Z teoretycznego punktu widzenia nie muszą to być prostokąty o równej
powierzchni i możemy te regiony w dowolny sposób kształtować.
Szacowanie tego typu jest bardziej przydatne, jeśli wybieramy kształt obszarów w
sposób jaki nam najbardziej odpowiada. Możemy na przykład dobrać kształty
obszarów w których będziemy prowadzić zliczanie tak, by odzwierciedlały one kształty
na obrazie stowarzyszonym.
Dla tropikalnych lasów deszczowych, możemy na przykład podzielić obszar badań na
kilka podregionów związanych z wielkością nachylenia terenu.
W zamieszczonym poniżej przykładzie dzielimy mapę gradientu (wielkości nachylenia
stoków) na cztery obszary o równej powierzchni – 4 kwantyle (!) – każdy zawierający
teren o podobnym nachyleniu.
0% 25% 50% 75% 100%
0.00086633 0.03997179 0.06202988 0.11295320 0.32847670
min max
Następnie dokonujemy zliczenia obiektów w każdym obszarze.
Procesy punktowe – intensywność procesu
23
Granice wartości dla kwantyli
nachylenia terenu (arctg kąta
nachylenia)
Wniosek:
Drzewa preferują
obszary o największym
nachyleniu.
Procesy punktowe – intensywność procesu
24

Załóżmy, że intensywność procesu punktowego jest funkcją współzmiennej wielkości
Z. Dla dowolnej wartości argumentu u (położenie – współrzędne geograficzne), niech
będzie intensywnością procesu punktowego zaś Z(u) będzie wartością
współzmiennej. Następnie zakładamy że zależność ma postać:
( )uλ
( ) ( )( )uZu ρλ =
gdzie jest to funkcją, którą chcemy znaleźć mówiącą nam, jak intensywność
punktów zależy od wartości współzmiennych.
Wygładzanie z użyciem funkcji jądrowych może być stosowane w celu oszacowania
poszukiwanej funkcji za pomocą metod rozkładu względnego lub ryzyka względnego.
( )Kρ
Obok przedstawiono zależność
intensywności występowania
drzew od wielkości nachylenia
terenu.
Na płaskim terenie (slope <0.05 )
prawdopodobieństwo znalezienia
drzew jest niewielkie.
Procesy punktowe – intensywność procesu
25
( ) ( )( )uslopeu ρλ =
W analizach przestrzennych istotnym zagadnieniem jest wzajemne położenie różnych
obiektów, np. obiektów punktowych lub obiektów liniowych. Można np. zapytać jaka
jest odległość obiektów punktowych od najbliższego obiektu liniowego.
Konkretnie – punktami zaznaczono położenie zwiększonej mineralizacji miedzi zaś
liniami prostymi lineamenty geologiczne (głównie pokrywające się z uskokami).
Geneza złóż miedzi wiąże występowanie tych złóż z bliskim sąsiedztwem uskoków.
Procesy punktowe – analiza położeń
26

Analiza związku występowania rud miedzi z siecią uskoków wymaga stworzenia mapy będącej
funkcją współrzędnej przestrzennej u(x,y). Niech mapą tą będzie mapa Z(u) odległości dowolnego
punktu u od najbliższego uskoku.
Obok przedstawiono wykres gęstość
występowania okruszcowania miedzią w
zależności od odległości od uskoku.
Procesy punktowe – analiza położeń
27
Modele Poissona
Zajmiemy się analizą rozkładu punktów w obszarze X. Poziomem odniesienia dla dalszych
analiz będzie całkowicie losowy rozkład tych punktów posiadający stałą intensywność λ.
Będziemy mówić, że punkty z przestrzeni X są jednorodnym procesem Poissona o intensywności λ
jeśli:- Liczba punktów w każdym wybranym podregionie B jest zmienną losową o rozkładzie Poissona
- Wartość oczekiwana tej liczby punktów jest równa
- Jeśli B1 i B2 są rozłącznymi podobszarami X to i są niezależnymi z.los.
- Jeśli to punkty te są niezależne i jednorodnie rozmieszczone w B.
( )BXN ∩
( )[ ] ( )BpoleBXN ⋅=∩ λE
( )2BXN ∩( )1BXN ∩
( ) nBXN =∩
28

Rozkład Poissona –definicja w statystyce klasycznej
( )!
,k
ekf
k λλλ
−
=
Rozkład Poissona – jednowymiarowy - prawdopodobieństwo szeregu wydarzeń mających miejsce w
określonym czasie (przestrzeni, powierzchni…), gdy te wydarzenia występują ze znaną średnią
częstotliwością i czas wystąpienia konkretnego zjawiska jest niezależny od czasu jaki upłynął od
zajścia poprzedniego zjawiska.
Dla stałej częstotliwości (intensywności) λ, prawdopodobieństwo,
wystąpienia dokładnie k zjawisk, gdzie k jest nieujemną liczbą
całkowitą, k = 0, 1, 2, ...) jest równe
k
f(k
,λ)
29
Test zgodności χ2 – prezentacja procedury
Jest to test nieparametryczny weryfikujący hipotezę dotyczącą rodzaju rozkładu
badanej cechy w populacji nie precyzując parametrów tego rozkładu. Statystyka jaką
tu stosujemy ma rozkład asymptotyczny χ2. Weryfikujemy hipotezę H0: dystrybuantą
badanej cechy jest F0(x), dla zmiennej ciągłej, skokowej bądź dyskretnej.
Procedura:
1. Tworzymy szereg rozdzielczy
2. Dzielimy go na k klas z których każda zawiera kolejno ni próbek i=1...k,
3. Obliczamy z rozkładu hipotetycznego teoretyczną liczebność
poszczególnych prób w tych samych k klasach ti=npi i=1...k,
4. Jeżeli hipoteza H0 jest prawdziwa to pomierzone liczebności w klasach są zbliżone
do teoretycznych; miarą rozbieżności jest wartość:
która asymptotycznie ma rozkład chi – kwadrat o k-1 stopniach swobody.
5. Na poziomie istotności α zbiorem krytycznym jest przedział Q = [h1- α,∞) gdzie
h1- α jest kwantylem rzędu 1 - α rozkładu chi-kwadrat o k-1 stopniach
swobody czyli dla �2(�1,�2,…,��) ≥ h1- α hipotezę odrzucamy, a dla
�2(�1,�2,…,��) < h1- α nie ma podstaw do odrzucenia hipotezy
∑=
=k
i
inn1
∑=
=k
i
inpn1
( )∑
=
−=
k
i i
ii
np
npn
1
2
2χ
30

Planar point pattern: 86 points window: rectangle = [0, 153] x [0, 95] feet
31
Test χ2 Pearsona
W poszczególnych podobszarach
podano wartości – zliczoną,
oczekiwaną i rezyduum
(odchyłkę) Pearsona.
Chi-squared test of CSR using quadrat counts Pearson X2 statistic data: nzchop X2 = 5.0769, df = 5, p-value = 0.8131Wartość X2 jest równa wartości
statystyki testowej χ2.
Wartość „p-value” to liczba
określająca na jakim minimalnym
poziomie istotności podejmowana
jest decyzja o odrzuceniu hipotezy
testowej H0 dla obserwowanych
danych.
Wartość p-value = 0.8131 oznacza, że
jeżeli odrzucimy hipotezę H0 o tym że
rozkład jest rozkładem Poissona to
prawdopodobieństwo, że jest to błąd
wynosi 0.8131 (czyli prawie pewność).
Wobec tego, w tym wypadku, brak
podstaw do odrzucenia hipotezy o
niejednorodności rozkładu punktów. 32

Test Kołmogorowa - Smirnowa
Weryfikujemy następującą hipotezę H0: Dystrybuantą badanej cechy jest F0(x),
gdzie x jest zmienną typu ciągłego (w naszym przypadku np. współrzędną X lub Y
punktu, lub innym typem pola ciągłego).
Test przebiega następująco:
1. Wyniki n-elementowej próby (np. współrzędne X punktów) układamy w szereg
rozdzielczy i tworzymy dystrybuantę empiryczną Fn(x)
2. Dla tych samych wartości x obliczamy dystrybuantę teoretyczną F0(x)
3. Obliczamy wartość statystyki λ Kołmogorowa :
4. Jej obszar krytyczny jest prawostronny, gdyż duże wartości λ świadczą przeciw
hipotezie H0.
Obszar krytyczny jest postaci: gdzie są
krytycznymi wartościami statystyki
podanymi dla określonych α i n z tablic statystycznych.
5. Porównujemy wartość empiryczną statystyki z obszarem krytycznym Q.
Jeśli należy do obszaru krytycznego to hipotezę H0 odrzucamy, jeśli nie to
nie ma podstaw do jej odrzucenia.
( ) ( )xFxFD nx
n 0sup −=
{ }αnnn DDDQ ≥= : αnD
nD
nD
nD
33
Test Kołmogorowa-Smirnowa
Jako wartości do testu można używać dowolnego
rastru, funkcji dwóch zmiennych bądź na przykład
współrzędnych X bądź Y (jak w tym przypadku) .
Wynik testu dla poprzednio analizowanych danych
wskazuje na brak przesłanek do odrzucenia
hipotezy o jednorodnym rozkładzie punktów w
badanym obszarze.
Porównanie testów �2 Pearsona i Kołmogorowa-
Smirnowa:
1.Dla małego n i gdy cecha ma charakter ciągły
stosujemy test K-S
2.W przypadku podziału na klasy o tym samym
prawdopodobieństwie dla badanej cechy o
rozkładzie ciągłym test Kołmogorowa wymaga
mniej licznej próby przy tej samej mocy
3. Jeżeli rozkład badanej cechy jest skokowy, to
stosujemy test �2 Pearsona
34

test K-S dla współzmiennej
Chi-squared test of CSR using quadrat counts Pearson X2 statistic data: bei X2 = 661.84, df = 3, p-value < 2.2e-16
Spatial Kolmogorov-Smirnov test of CSR in two dimensions data: covariate ‘Z’ evaluated at points of ‘bei’
and transformed to uniform distribution under CSR D = 0.19481, p-value < 2.2e-16
Analizowane poprzednio rozmieszczenie drzew w lesie tropikalnym w zależności od stopnia nachylenia stoku
może być przetestowane zarówno testem chi_kw jak i K-S. Testujemy, czy rozkład jest jednorodny przy podziale
na obszary o różnym nachyleniu stoku.
35