my talk on hadoop stack operations engineering at ospcon
TRANSCRIPT

Наdoop на службе федерального налогового ведомства страны
Александр Чистяков, ФКУ “Налог-Сервис”,главный специалист

Я пришел с миром!
● Меня зовут Саша
● Я работаю в Федеральном Казенном
Учреждении “Налог-Сервис”
на должности главного специалиста
● Я занимаюсь эксплуатацией
Hadoop-кластера Федеральной
Налоговой Службы

Вы?
● Работаете с большими данными?
● Работаете с очень большими данными?
● Работаете с очень-очень большими
данными
● Кстати, как отличить просто большие
данные от очень больших данных?

Сразу достанем и измерим
● Похвастаюсь:
● У меня МНОГО RPS*
* совершенно
бесполезных

Начнем с начала
● Ни одна крутая история не начинается
со слов “мы сидели и пили кофе”
● Эта история началась со слов
“все плохо”
● Повторенных не один раз

Насколько все было плохо?
● Полстойки BigData-решения от компании Cisco

Насколько все было плохо?
● Полстойки BigData-решения от компании Cisco
● RedHat Enterprise Linux 6

Насколько все было плохо?
● Полстойки BigData-решения от компании Cisco
● RedHat Enterprise Linux 6
● Установленный “дистрибутив” Hadoop от компании
Cloudera (на тот момент – 5.2)

Насколько все было плохо?
● Полстойки BigData-решения от компании Cisco
● RedHat Enterprise Linux 6
● Установленный “дистрибутив” Hadoop от компании
Cloudera (на тот момент – 5.2)
● Разработчики с полным доступом к продакшну

Насколько все было плохо?
● Полстойки BigData-решения от компании Cisco
● RedHat Enterprise Linux 6
● Установленный “дистрибутив” Hadoop от компании
Cloudera (на тот момент – 5.2)
● Разработчики с полным доступом к продакшну
● Два приложения: Java/YARN/HBase и
Scala/Spark/HBase/Parquet

Кстати, зачем все это нужно?
● Система контроля НДС – сравнение налоговых
деклараций контрагентов

Кстати, зачем все это нужно?
● Система контроля НДС – сравнение налоговых
деклараций контрагентов
● ^ когда никого нет на кластере

Кстати, зачем все это нужно?
● Система контроля НДС – сравнение налоговых
деклараций контрагентов
● ^ когда никого нет на кластере
● Визуализация несоответствий и работа с ними

Кстати, зачем все это нужно?
● Система контроля НДС – сравнение налоговых
деклараций контрагентов
● ^ когда никого нет на кластере
● Визуализация несоответствий и работа с ними
● Обработка интерактивных запросов от налоговых
инспекторов

Кстати, зачем все это нужно?
● Система контроля НДС – сравнение налоговых
деклараций контрагентов
● ^ когда никого нет на кластере
● Визуализация несоответствий и работа с ними
● Обработка интерактивных запросов от налоговых
инспекторов
● ^ в рабочее время (когда на кластере есть
пользователи)

Подготовьте мышь к опыту
● Ценности DevOps это:
● C – Culture
● A – Automation
● M – Measurement
● S – Sharing

C — Culture
● Петербург – культурная столица Российской
Федерации
● В петербургском филиале ФКУ
“Налог-Сервис” принято обращаться друг к
другу по имени-отчеству

A — Automation
● A – Ansible*
* отстирывает в два раза лучше Вашего
моющего средства!

Б — Безопасность
● Внутренняя сеть ФКУ не подключена к
интернету
● Нельзя просто так взять и внести или
вынести файлы*
* но если очень хочется...

Рабочее место специалиста
● Плюсы: можно нормально
выспаться
● Минусы: нет

Первые шаги
● А – Автоматизация (Ansible)
● Первый проект, в котором я делал ad hoc команды
● ansible all -a "command" --sudo --user ansible

Первые шаги
● А – Автоматизация (Ansible)
● Первый проект, в котором я делал ad hoc команды
● ansible all -a "command" --sudo --user ansible
● Тем не менее: описание в виде playbooks/roles
● Прямое переиспользование уже накопленного
материала практически невозможно из-за
особенностей Cloudera

Особенности Cloudera
● Управление через веб-интерфейс (!)
● Параметры хранятся в СУБД PostgreSQL (!!)
● Где-то (?) есть шаблоны для генерации конфигурации

Особенности Cloudera
● Управление через веб-интерфейс (!)
● Параметры хранятся в СУБД PostgreSQL (!!)
● Где-то (?) есть шаблоны для генерации конфигурации
● Сервисами управляет supervisord
● Конфигурационные файлы supervisord генерируются
при каждом рестарте кластера заново в новом
каталоге с новым уникальным именем (!!!)

Это безумие? Это Cloudera!
● Веб-интерфейс не управляет некоторыми параметрами
● Значения вида -Xmx2048m не поддерживаются из-за
буквы m (только значения в байтах)
● Как быть, если нужно задать значение более 4-х
гигабайт (в Int такое не поместится)?

Это безумие? Это Cloudera!
● Веб-интерфейс не управляет некоторыми параметрами
● Значения вида -Xmx2048m не поддерживаются из-за
буквы m (только значения в байтах)
● Как быть, если нужно задать значение более 4-х
гигабайт (в Int такое не поместится)?
● ^ Зачем такое может быть нужно честному человеку?

Укрощение строптивой
● Описали текущую конфигурацию при помощи Ansible
● Выключили веб-интерфейс

Укрощение строптивой
● Описали текущую конфигурацию при помощи Ansible
● Выключили веб-интерфейс
● Получили набор удивительных проблем при
рестарте узла: сервис Cloudera удаляет всю
конфигурацию supervisord
● Решили это переносом конфигурации в неизвестный
сервису каталог

M — Measurement
● Church of Metrics
● В первую же неделю работы мы пронесли в закрытый
контур ФНС LXC-контейнер с Grafana и
Graphite/Whisper
● Обычно, увидев интерфейс Grafana, люди теряют волю
и становятся адептами нашей церкви
● Так и вышло

П — Проблемы
● 100% утилизация системного HDD на машине с контейнером
Grafana/Graphite/Whisper
● Постоянные жалобы разработчиков, которые теперь
умеют смотреть на графики (научили на свою голову)

П — Проблемы
● 100% утилизация системного HDD на машине с контейнером
Grafana/Graphite/Whisper
● Постоянные жалобы разработчиков, которые теперь
умеют смотреть на графики (научили на свою голову)
● Как ни странно, жалобы имели под собой основу –
одна из нод HBase не успевала записывать на
системный диск логи

Р — Решения
● O – OpenTSDB (time series database)
● Работает как сервис поверх HBase
● А у нас уже есть HDFS и HBase

О — Опять проблемы
● O – OpenTSDB (time series database)
● Работает как сервис поверх HBase
● А у нас уже есть HDFS и Hbase
● Интерфейс рисования графиков в Grafana для
интеграции с OpenTSDB нравится далеко не всем
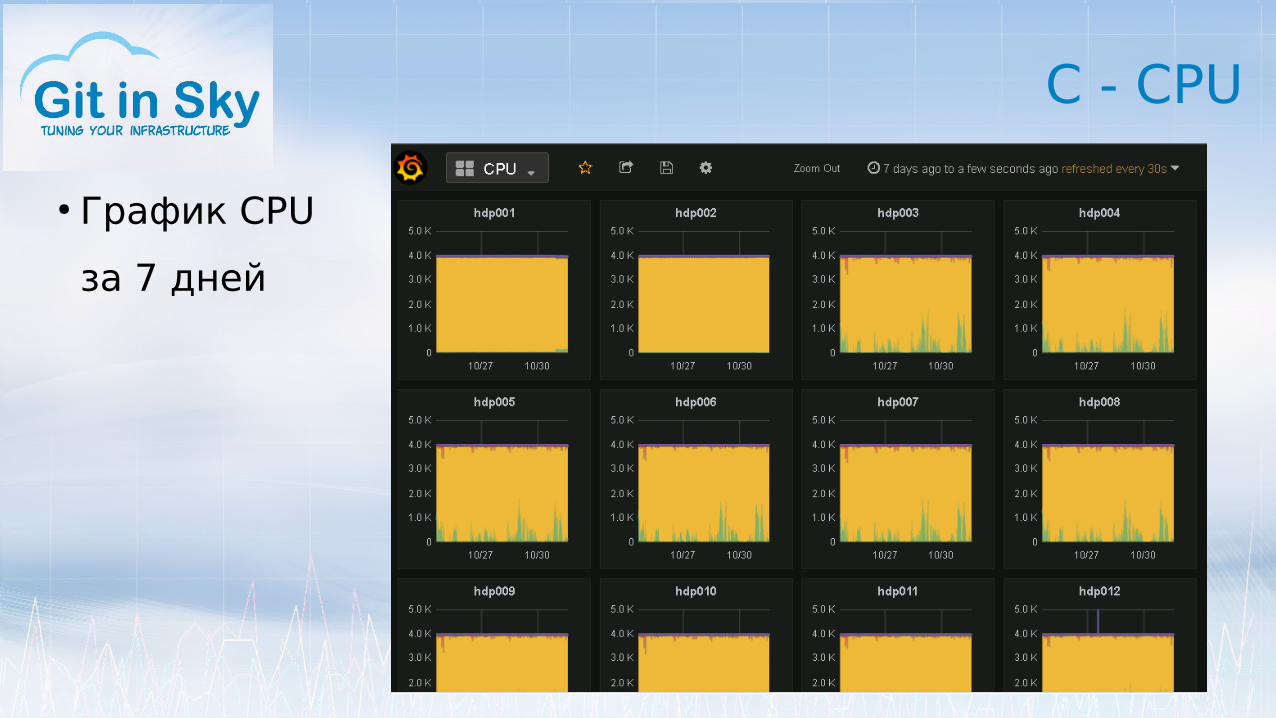
C - CPU
● График CPU
за 7 дней

Н - Недогруз
● График CPU
за 12 часов
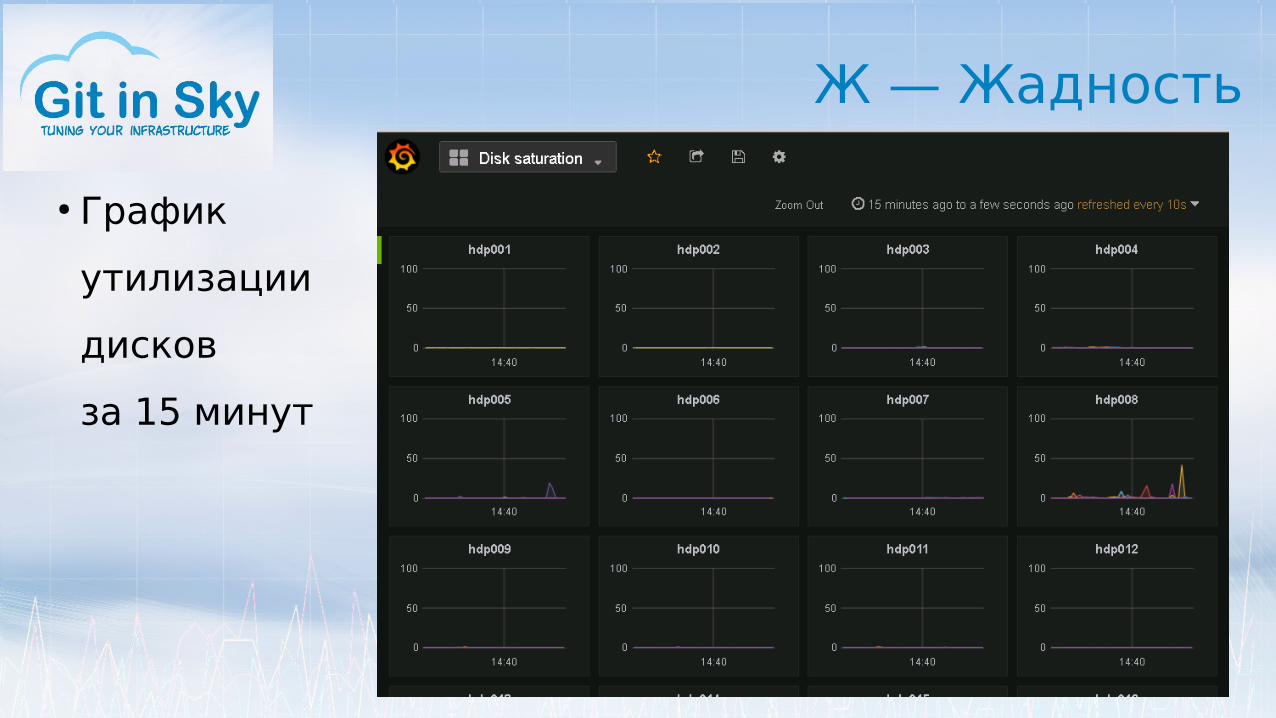
Ж — Жадность
● График
утилизации
дисков
за 15 минут
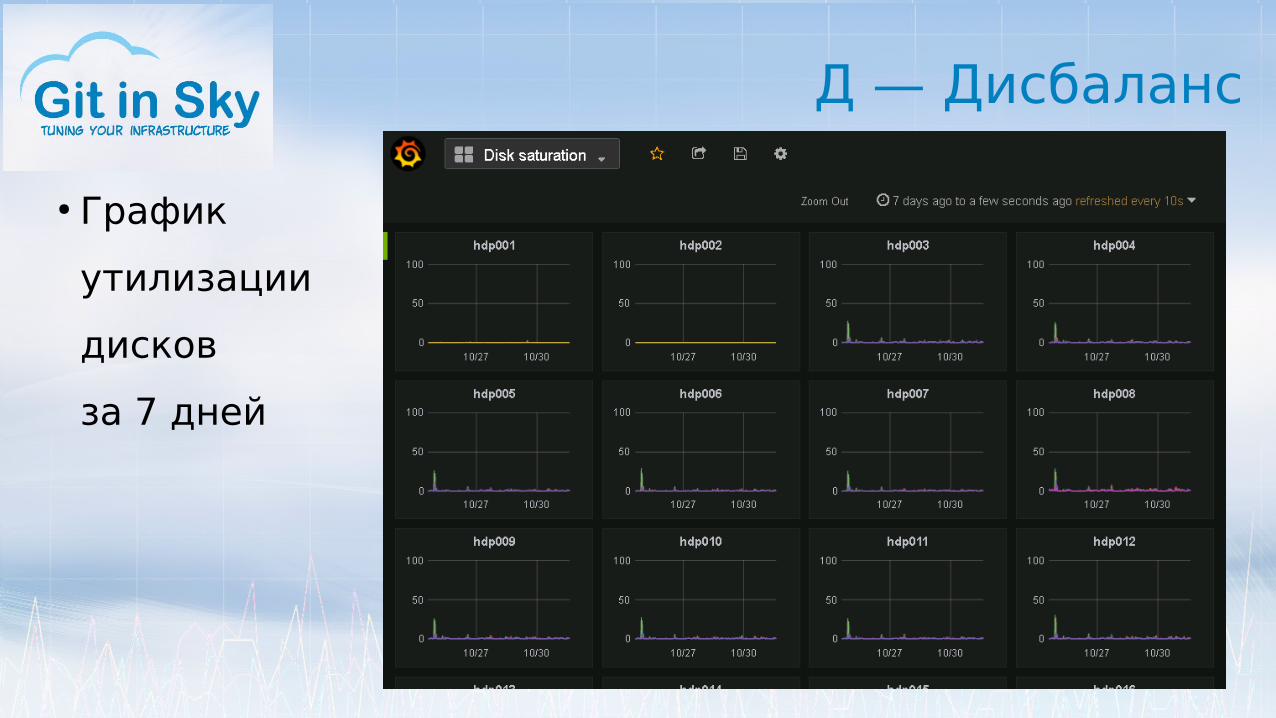
Д — Дисбаланс
● График
утилизации
дисков
за 7 дней
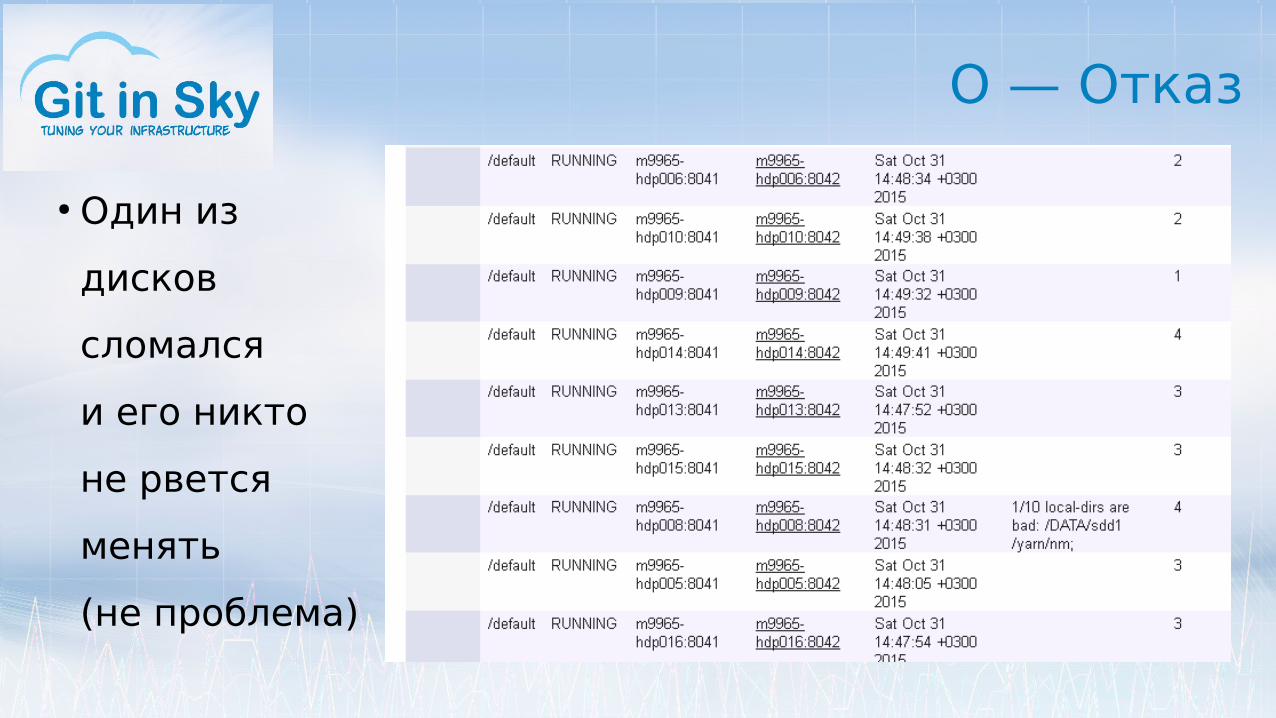
О — Отказ
● Один из
дисков
сломался
и его никто
не рвется
менять
(не проблема)

Д — Другой отказ
● supervisord в Cloudera так настроен, что после трех
попыток выключает сервис
● Однажды у нас выключились 11 из 14 region серверов
в HBase
● Кластер работал БЕЗ ПОТЕРИ
ПРОИЗВОДИТЕЛЬНОСТИ

Д — Другой отказ
● supervisord в Cloudera так настроен, что после трех
попыток выключает сервис
● Однажды у нас выключились 11 из 14 region серверов
в HBase
● Кластер работал БЕЗ ПОТЕРИ
ПРОИЗВОДИТЕЛЬНОСТИ
● ^ Помните слайд про “недогруз”?
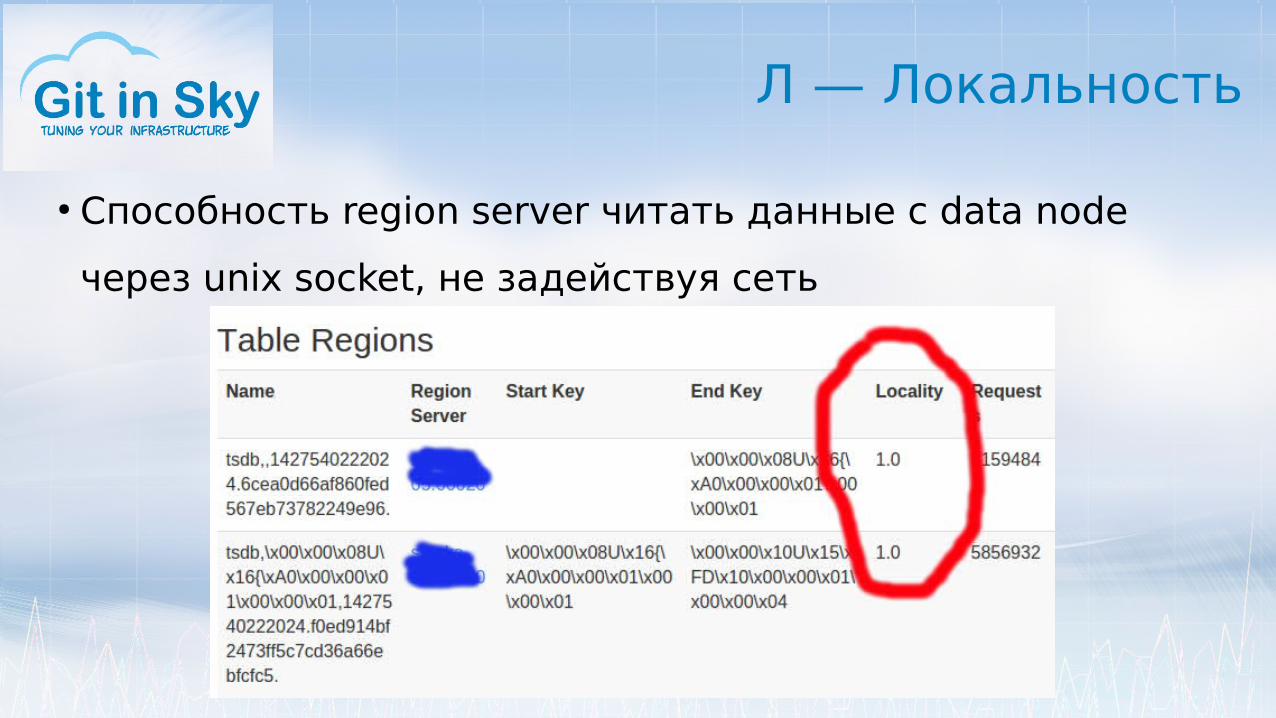
Л — Локальность
● Способность region server читать данные с data node
через unix socket, не задействуя сеть

Л — Локальность
● Была 0 на всех region servers
● На HDFS data nodes зарегистрированы по FQDN
● На HBase region servers зарегистрированы по short
names
● Несовпадение имен – region servers не распознают
локальность и не могут использовать unix socket

Л — Локальность
● Семь бед – один restart всех data nodes
● После рестарта регистрируются по коротким именам
● Делаем major compaction всех таблиц – локальность
становится почти 100%

Л — Локальность
● Семь бед – один restart всех data nodes
● После рестарта регистрируются по коротким именам
● Делаем major compaction всех таблиц – локальность
становится почти 100%
● И НИКАКОГО ПРИРОСТА ПРОИЗВОДИТЕЛЬНОСТИ!

Б — Безысходность
● S - Sampling
● kill -QUIT pid
● Скрипт на bash для сэмплинга заданных контейнеров
● Анализ полученных логов вручную
● Слишком частые обращения к HBase metadata
● ^ удалось быстро исправить

Б — Безысходность
● S - Sampling
● kill -QUIT pid
● Скрипт на bash для сэмплинга заданных контейнеров
● Анализ полученных логов вручную
● Слишком частые обращения к HBase metadata
● ^ удалось быстро исправить
● На этом хорошие новости кончились – далее в сэмплах
видим код счета в приложении

К — Качество
● Размер кластера не так важен
● Критически важна способность алгоритма
параллелиться

D — Docker
● Новая модная технология
● Которую мы любим и умеем
● К сожалению, стандартная сеть в Docker не позволяет
развернуть YARN
● Использование OpenVSwitch (который зависает в
предсказуемые, к счастью, моменты)
● Сильная фрустрация всех участников, отказ от Docker

S — Sharing
● Три интенсивные тренировочные сессии
● Несколько часов обучающего видео
● План создания видеотренингов и практических работ
на ближайшие полгода
● Как показала практика – в рамках интенсивных трех-
и пятидневных сессий запомнить нужный объем
информации невозможно

Выводы
● Работа в федеральном проекте:
● а) позволяет посетить новые места
● б) позволяет познакомиться с новыми
интересными людьми

Спасибо за внимание!
● Пожалуйста, ваши вопросы!
● С вами был Александр Чистяков
● http://gitinsky.com
● Кстати, мы делаем митапы в Петербурге:
● http://meetup.com/Docker-Spb, http://meetup.com/Ansible-Spb,
http://meetup.com/DevOps-40