mysqlテーブル設計入門
TRANSCRIPT

MySQL⼊門7限目: テーブル設計について
2015/04/30
GMOメディア株式会社 yoku0825schoo WEB-campus

\こんにちは/
yoku0825@GMOメディア株式会社オラクれない-ポスグれない-マイエスキューエる-
家に帰ると妻の夫-せがれの⽗-娘の⽗-
Twitter: @yoku0825Blog: ⽇々の覚書
1/144

アジェンダ
事前知識DDLで使われる⽤語についてざっと説明します-データ型について説明します-
カラム設計デモケースとして掲⽰板⽤のデータモデリングをします-非正規形のテーブルからスタートし、正規形にするまでの考え⽅を学びます
-
インデックス設計インデックスの動作の仕⽅についてトランプの例を⽤いて簡単に解説します
-
先の掲⽰板⽤のデータモデルにインデックスを作成します-
2/144

質問3/144

今のあなたのレベル感を教えてください
SQLもまだいまいち。。1. SQLならほぼわかるけど実務経験ガー2. テーブル設計経験者。でも破綻しちゃって。。3. バリバリサービスでやっててノウハウはあるけど、ちょっと理屈を聞いてみたくなった。
4.
お前にマサカリを投げに来た5.
4/144

1. SQLもまだいまいち。。 の⽅
そんなにたくさんSQLをゴリゴリ書くような授業ではないですので、気楽に最後まで眺めてみてください。暗記すること、憶えなければいけないことは基本何もありません。そういえばこんな話聞いたな…というのが後から⽣きてくる、というのを弊社研修⽣からは⽿にしています :)
SQLが判ればもっと⾯⽩くなると思いますので、SQLが⼿についてきたころに観返してみると違った発⾒があるかも知れません。
-
5/144

2. SQLならほぼわかるけど実務経験ガー の⽅
前半の正規形と設計のプロセスについて、疑問に思ったところはどんどん聞いてください。後半かなりアーキテクチャーに寄りますので、そちらはまた慣れてきたころに観返していただけると幸いです。
6/144

3. テーブル設計経験者。でも破綻しちゃって。。 の⽅
まずは前半で “正規形” について誤解がないかどうか⼀緒に考えましょう。そして、 正規化 した/していない のに何故テーブルが破綻したのかの答え(への⾜掛かり)を後半で探っていきます。
7/144

4. バリバリサービスでやっててノウハウはある⽅
そんなあなたにこの授業の内容をそれっぽい⾔葉で説明すると3NFまで1段階ずつ正規化していきます。-インデックスの使われ⽅(WHERE狙いのキー, ORDER BY狙いのキー)の話をします。
-
JOIN時における内部表と外部表の話とWHERE狙い, ORDER BY狙いの話が絡んできます。
-
楽しんでいただけそうですか︖
8/144

5. お前にマサカリを投げに来た
お⼿柔らかにお願いします。。
9/144

⽤語について
インデックス(主に)データを検索するために使われる ソート済みのデータのサブセット
-
MySQLでは “キー” と “インデックス” は同じもの(特に、セカンダリーキー)を指すことが多いリレーショナルモデル上では “キー” は “候補キー”
-
10/144

⽂字コードについて
sjis悪いことは⾔わないのでやめましょう。バグが多いです。-WindowsのSJISと 互換性がない ので、WindowsのSJISを使いたいのであればcp932を使ってください
-
ujisオススメはしませんがsjisよりはマシです。eucjpmsの⽅がいいです。
-
utf8基本的にオススメですが、4バイト⽂字(絵⽂字)が⼊らないので、utf8mb4にするべきかと思います。
-
latin1暗黙のデフォルト。-⽇本語を⼊れると闇が⾒えます。-
11/144

⽂字列型
CHAR(n), VARCHAR(n)n ⽂字 (not byte)のデータを格納するための型-デフォルトのまま使っていると、⼤⽂字と⼩⽂字を区別 しない (Case Insensitive)
-
現在のMySQLにおいてCHAR型を選ぶメリットはほぼない。迷ったらVARCHAR。
-
データサイズの側⾯でいうと、1⽂字に必要なバイト数は⽂字コードごとに違うので、n⽂字 * 1⽂字あたりのバイト数 + αが1⾏あたりの最⼤サイズになります。
-
12/144

⽂字列型
TEXT, LONGTEXTTEXT型は2^16⽂字くらいまで、LONGTEXT型は2^64⽂字くらいまで。
-
ただしmax̲allowed̲packetがあるので、LONGTEXT型でも2^64⽂字くらいまで全て詰め込むことはできません。
-
バイト型もあるけど、あまり使うことはないPHPとかから使う時はどっちも⽂字列っぽく⾒えるけれど、Javaとかから使うと型が違ってごちゃごちゃする。
-
13/144

数値型
TINYINT, INT, BIGINTそれぞれ1バイト, 4バイト, 8バイトの整数型。-UNSIGNED属性をつけると符号なし整数になって1ビット余計に使える。
-
FLOAT, DOUBLE単精度, 倍精度浮動⼩数点数型。-浮動⼩数点型なので丸め誤差に注意。ほぼ使わない。-
DECIMAL, NUMERIC固定⼩数点数型。演算が伴うときはこれを使うか、100倍してINT型に⼊れるなんてことも。
-
14/144

⽇付時刻型
DATE型3バイトで年⽉⽇-
TIME型3バイトで時分秒、地味に負値も格納できる。-
DATETIME型5.5までは8バイト、5.6からは5バイト。年⽉⽇時分秒まで格納。-5.6以降はTIMESTAMP型よりこちらが推奨されている。-
TIMESTAMP型4バイトでUNIXTIMEを格納して⽇付型として解釈する。-1970/1/1 00:00:00〜2038/1/19 03:14:07-
15/144

その他テーブルの属性
AUTO̲INCREMENT数値型(⼩数点型でもOK)そのカラムにインデックスがある場合にのみ設定可能な属性。
-
⾃動でカウントアップされるDEFAULT属性みたいな感じ。-AUTO̲INCREMENTの次の値は int(そのカラムの最⼤値) + 1-
DEFAULTそのカラムに値が指定されなかった時に、暗黙にこの値を設定する。-CURRENT̲TIMESTAMPの例外を除いてリテラルのみ指定可能で、関数の結果はDEFAULTに指定できない。
-
ストレージエンジン, 圧縮, その他..
16/144

本編
カラム設計のデモケースとして掲⽰板⽤のデータモデリングをします非正規形のテーブルからスタートし、正規形にするまでの考え⽅を⾒ていきます
17/144

⼀番最初に考えること
あなたの 掲⽰板システムに必要なデータは何か︖
18/144

たとえば
掲⽰板にはスレッド単位で話題が上がってそれに対してコメントが付く形-1スレッドの上限コメント数は制限したい-スレッドを⽴てるにはメールアドレスを必須にしたい-
スレッドの⼀覧出⼒機能をつけたいスレの作成順にソートしたい-最終書き込み時刻でソートしたい-スレの書き込み数でもソートしたい-スレッドのタイトルの横にコメント数を表⽰したい-
19/144

考え⽅の順番
まず最初に全部⼊りで考えてみる正規化とか考えずに必要なものを全部テーブルに詰め込んでみる正規化⼿順に沿って5NFまで持っていくもちろん慣れていれば3NFくらいからいきなり書き始められる
20/144
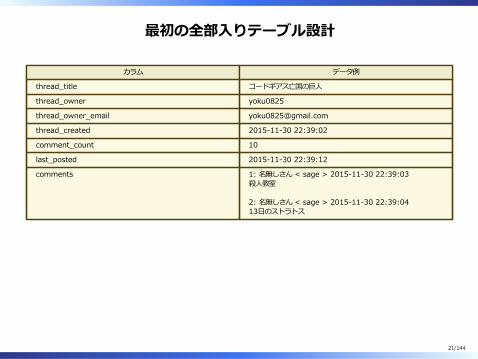
最初の全部⼊りテーブル設計
カラム データ例
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
21/144

参照系クエリー
新しく作成された順にスレッド⼀覧を表⽰するクエリー
SELECT thread_titleFROM bbsORDER BY thread_created DESC
22/144
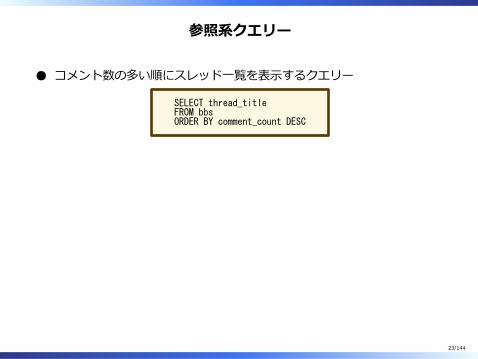
参照系クエリー
コメント数の多い順にスレッド⼀覧を表⽰するクエリー
SELECT thread_titleFROM bbsORDER BY comment_count DESC
23/144
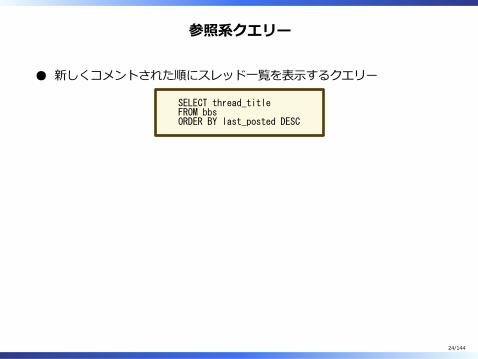
参照系クエリー
新しくコメントされた順にスレッド⼀覧を表⽰するクエリー
SELECT thread_titleFROM bbsORDER BY last_posted DESC
24/144

参照系クエリー
スレッドを詳細表⽰するクエリー
SELECT thread_title, thread_owner, thread_owner_email, thread_created, comment_count, last_posted, commentsFROM bbsWHERE thread_title = 'new_thread'
25/144

SELECTは特に問題なさそうに⾒える︖
26/144
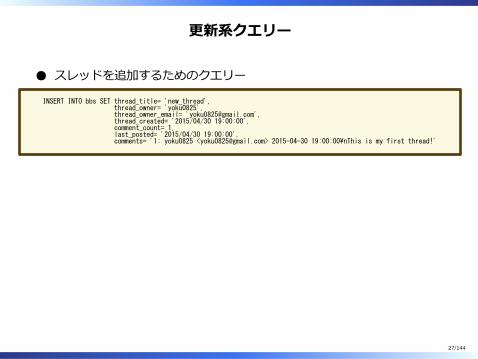
更新系クエリー
スレッドを追加するためのクエリー
INSERT INTO bbs SET thread_title= 'new_thread', thread_owner= 'yoku0825', thread_owner_email= '[email protected]', thread_created= '2015/04/30 19:00:00', comment_count= 1, last_posted= '2015/04/30 19:00:00', comments= '1: yoku0825 <[email protected]> 2015-04-30 19:00:00\nThis is my first thread!'
27/144

更新系クエリー
コメントを追加するクエリー
UPDATE bbs SET comment_count = comment_count + 1, last_posted = NOW(), comments = CONCAT(comments, '\n\n', '2: yoku0825 <[email protected]> 2015-04-30 19:01:00\n2 get!')WHERE thread_title= 'new_thread'
28/144

更新系クエリー
それとも、こう︖
UPDATE bbs SET comment_count = 2, last_posted= '2015-04-30 19:01:00', comments = '1: yoku0825 <[email protected]> 2015-04-30 19:00:01\nThis is my first thread!\n\n
2: yoku0825 <age> 2015-04-30 19:01:00\n2 get!'WHERE thread_title = 'new_thread';
29/144

雲⾏きが怪しくなってきましたね :)
30/144

コメントの削除
どうやる︖アプリ側で⽂字列探査して目的のコメントを削除してUPDATEする(last̲postedもがんばる)
そんなばかな
31/144

第1非正規形
SELECTする分には特に問題なく⾒えるというかとてもシンプルで良いようにすら⾒える
JOINもGROUP BYも出てこない-
更新処理が破綻している⽂字列操作で追加、削除-⽂字列操作はSQL外の範疇になるので、RDBMSの利点をほとんど受けられない
-
32/144

それでも正規化せずに使いますか︖
[No/いいえ]33/144

正規化とは
テーブルを リレーショナルモデルのお作法に基づいた形 に作り変える作業SQLはリレーショナルモデルに基づいた操作を提供する⾔語RDBMSの機能を(フルに)使うためにはSQLを使わなければいけないSQL(だけ)で綺麗に操作するためには正規化が必要
34/144

なんて⾔っててもわかりづらいので実際に正規化してみましょう
35/144

第1正規形
テーブルの中には個々の⾏を⼀意に識別できる候補キーが存在することテーブルの全ての要素は
NULLでないこと宗教問題に近いので、軽く流します
-
アトミックである-アトミックでない場合はアトミックになるように分割する
36/144

全ての⾏は⼀意に識別されなければいけない
カラム データ例
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
このテーブルに格納された⾏を⼀意に識別するものは︖
37/144

thread̲title︖
カラム データ例
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
同じタイトルのスレッドは存在できなくなる。
38/144
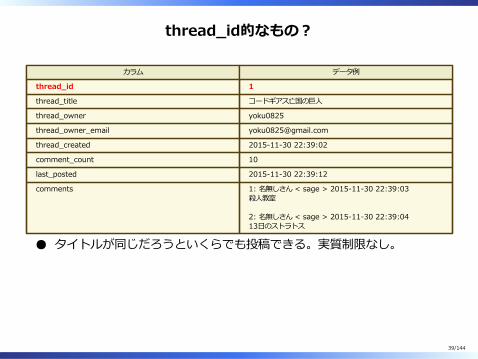
thread̲id的なもの︖
カラム データ例
thread̲id 1
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
タイトルが同じだろうといくらでも投稿できる。実質制限なし。
39/144

PRIMARY KEYを複雑化する︖
カラム データ例
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
タイトル, 作成者, 作成者のメールアドレスまで⼀致したら重複スレッドとして扱う
40/144

どれが正解︖
同じタイトルのスレッドは存在できないタイトルが同じでもいくらでも投稿できるある程度の情報が⼀致したら重複として扱って投稿できない正解はどれでも良くて、これは要件との兼ね合いになる。
41/144

要件を思い出す
掲⽰板にはスレッド単位で話題が上がってそれに対してコメントが付く形-1スレッドの上限コメント数は制限したい-スレッドを⽴てるにはメールアドレスを必須にしたい-
スレッドの⼀覧出⼒機能をつけたいスレの作成順にソートしたい-最終書き込み時刻でソートしたい-スレの書き込み数でもソートしたい-スレッドのタイトルの横にコメント数を表⽰したい-
42/144

スレッドの重複に関する要件はない
でもどれかのプライマリーキーを選ばないと、同じタイトルのスレッドが存在した時に機能が破綻する要件を追加しなければならない
43/144

追加されるであろう要件
重複したスレッドの作成を禁⽌するタイトルが同じなら重複として作成させない => PRIMARY KEY(thread̲title)タイトルよりは複雑だけど重複判定はする => PRIMARY KEY(thread̲title, thread̲owner, thread̲owner̲email)
-
禁⽌しない => PRIMARY KEY(thread̲id)-テーブル設計と要件定義は密接に関わっている
44/144

今回は重複スレッドを禁⽌しない
(thread̲id⽅式)を選んでみる
45/144

第1正規形の話に戻ると
テーブルの中には個々の⾏を⼀意に識別できる候補キーが存在することテーブルの全ての要素は
NULLでないこと宗教問題に近いので、軽く流します
-
アトミックである-アトミックでない場合はアトミックになるように分割する
46/144

テーブルの要素
NULLではないことNOT NULL制約つけましょうテストケースが膨⼤に増えるTRUE, FALSEの2値なら条件網羅テストケースは 2 ^ カラム数TRUE, FALSE, NULLの3値だと条件網羅テストケースは 3 ^ カラム数演算に慣れていないと問題の分析に時間がかかるパッと⾔えますか︖TRUE and NULL => NULLFALSE and NULL => FALSETRUE or NULL => TRUEFALSE or NULL => NULL
-
47/144

テーブルの要素
アトミックであること1つの⾏の1つのカラムに複数の要素を詰め込まない こと。-これからしばらく気持ち悪いテーブル構成が並びますが、正規化の途中ということで⼤目に⾒てください。
-
48/144
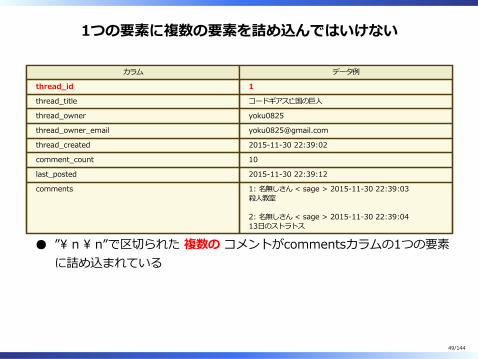
1つの要素に複数の要素を詰め込んではいけない
カラム データ例
thread̲id 1
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
”\ n \ n”で区切られた 複数の コメントがcommentsカラムの1つの要素に詰め込まれている
49/144

⾏を分割して1⾏1コメントになるようにする
カラム データ例1 データ例2
thread̲id 1 1
thread̲title コードギアス亡国の巨⼈ コードギアス亡国の巨⼈
thread̲owner yoku0825 yoku0825
thread̲owner̲email [email protected] [email protected]
thread̲created 2015-11-30 22:39:02 2015-11-30 22:39:02
comment̲count 10 10
last̲posted 2015-11-30 22:39:12 2015-11-30 22:39:12
comments 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
このプライマリーキーだと1スレッドに複数コメントがつけられない。
50/144

プライマリーキーを伸ばす
カラム データ例1 データ例2
thread̲id 1 1
thread̲title コードギアス亡国の巨⼈ コードギアス亡国の巨⼈
thread̲owner yoku0825 yoku0825
thread̲owner̲email [email protected] [email protected]
thread̲created 2015-11-30 22:39:02 2015-11-30 22:39:02
comment̲count 10 10
last̲posted 2015-11-30 22:39:12 2015-11-30 22:39:12
one̲comment 1: 名無しさん < sage > 2015-11-30 22:39:03殺⼈教室
2: 名無しさん < sage > 2015-11-30 22:39:0413⽇のストラトス
これだとプライマリーキーが⼀意に識別するのは “あるスレッドの” “あるコメント”になる意味が変わってしまっているので、本当はこの時点でテーブル分割が望ましい(が、説明のためこの時点では分割せずいきます)
51/144

この段階での参照クエリー
新しく作成された順にスレッド⼀覧を表⽰するクエリー
SELECT thread_id /* アンカータグでリンクを張るのに使う */, thread_titleFROM bbsORDER BY thread_created DESC
スレッドを詳細表⽰するクエリー
SELECT thread_title, thread_owner, thread_owner_email, thread_created, comment_count, last_posted, GROUP_CONCAT(one_comment ORDER BY one_comment ASC SEPARATOR '\n') AS commentsFROM bbsWHERE thread_id = 1 /* スレッド一覧からthread_idをパラメーターでもらう */
GROUP̲CONCATはMySQL独⾃関数なので、アプリ側でループした⽅が良い。
52/144
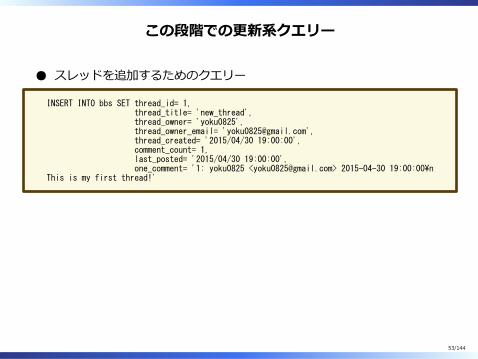
この段階での更新系クエリー
スレッドを追加するためのクエリー
INSERT INTO bbs SET thread_id= 1, thread_title= 'new_thread', thread_owner= 'yoku0825', thread_owner_email= '[email protected]', thread_created= '2015/04/30 19:00:00', comment_count= 1, last_posted= '2015/04/30 19:00:00', one_comment= '1: yoku0825 <[email protected]> 2015-04-30 19:00:00\nThis is my first thread!'
53/144

この段階での更新系クエリー
コメントを追加するクエリー
INSERT INTO bbs SET thread_id= 1, thread_title= 'new_thread', thread_owner= 'yoku0825', thread_owner_email= '[email protected]', thread_created= '2015/04/30 19:00:00', comment_count= 2, last_posted= '2015/04/30 19:01:00', one_comment= '2: yoku0825 <[email protected]> 2015-04-30 19:01:00\n2 get!'
コメントを追加するためだけにスレッドの情報もINSERT⽂に⼊れないといけないの︖
54/144

この段階での更新系クエリー
コメントの削除
DELETEFROM bbsWHERE thread_id= 1 AND one_comment= '2: yoku0825 <[email protected]> 2015-04-30 19:01:00\n2 get!';
WHERE句が不恰好ではあるものの、⼀応SQLでコメントを削除できるようになった。
55/144

これで第1正規形︖
まだ書式によって区切られた複数の意味(コメント番号, コメント主, email, コメント⽇付, コメントの本⽂)が1つの要素に詰め込まれている = アトミックではないとはいえこの時点でコメントの投稿はINSERT, コメントの削除はDELETEで直観的に操作できるようになった
56/144

カラムを分割してアトミックになるようにする
カラム データ例1 データ例2
thread̲id 1 1
thread̲title コードギアス亡国の巨⼈ コードギアス亡国の巨⼈
thread̲owner yoku0825 yoku0825
thread̲owner̲email [email protected] [email protected]
thread̲created 2015-11-30 22:39:02 2015-11-30 22:39:02
comment̲count 10 10
last̲posted 2015-11-30 22:39:12 2015-11-30 22:39:12
comment̲number 1 2
comment̲owner 名無しさん 名無しさん
comment̲owner̲email sage sage
comment̲posted 2015-11-30 22:39:03 2015-11-30 22:39:04
comment̲body 殺⼈教室 13⽇のストラトス
one̲commentの代わりにcomment̲numberをプライマリーキーの⼀部として差し替え。
57/144

変化のあったクエリー
コメントを追加するクエリー
INSERT INTO bbs SET thread_id= 1, thread_title= 'new_thread', thread_owner= 'yoku0825', thread_owner_email= '[email protected]', thread_created= '2015/04/30 19:00:00', comment_count= 2, last_posted= '2015/04/30 19:01:00', comment_number= 2, comment_owner = 'yoku0825', comment_owner_email = '[email protected]', comment_posted = '2015-04-30 19:01:00', comment_body = '2 get!'
コメントの削除
DELETEFROM bbsWHERE thread_id= 1 AND comment_number= 2
58/144

これで第1正規形
レコードが⼀意に識別できる要素にNULLを含まない要素がアトミックである
59/144

第1正規化することで変わったこと
コメントの削除が(SQLで)できるようになったコメントの投稿がシンプルなINSERT⽂にその気になればコメントの内容をUPDATEで編集することもできるコメント追加のINSERTのために、スレッド本体の情報も持たせないといけないの︖スレッドのタイトルが編集できたとしたら、たくさんの⾏を更新しないといけなくない︖
60/144

正規化とは(再掲)
テーブルを リレーショナルモデルのお作法に基づいた形 に作り変える作業SQLはリレーショナルモデルに基づいた操作を提供する⾔語RDBMSの機能を(フルに)使うためにはSQLを使わなければいけないSQL(だけ)で綺麗に操作するためには正規化が必要
61/144

RDBMSの機能
トランザクションによるACID保証制約によるデータの保証集計関数RDBMSの恩恵を しっかり受けるために 正規化するRDBMS の外側 でやるところには正規化という概念はない
62/144

ひとやすみ
63/144

正規形の種類
非正規形 (?)第1正規形第2正規形第3正規形BC正規形第4正規形第5正規形第6正規形
64/144

第2正規形と第3正規形の違いを知っていますか︖ [Yes/No]
65/144

第2正規形と第3正規形の違い
第2正規形プライマリーキーの ⼀部 だけで決まる要素が存在しない-
第3正規形非キー要素から⼀意に決まる要素が存在しない-
どちらも存在する場合はテーブルを分割する
66/144

プライマリーキーの ⼀部 #とは
プライマリーキーが単⼀カラムで構成されている場合、 プライマリーキーの”⼀部” は存在しないので⾃動的に第2正規形(thread̲id, comment̲number)の⼀部から⼀意に決まる値はあるか︖
thread̲idが決まればthread̲title, thread̲owner, thread̲owner̲email, thread̲created, comment̲count, last̲postedが決まる
-
thread̲owner, comment̲ownerが決まればthread̲owner̲email, comment̲owner̲emailも決まるはずだけど、これは プライマリーキーの⼀部ではない のでここでは分割しない
-
67/144

分割
threadテーブルカラム データ例1
thread̲id 1
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲owner̲email [email protected]
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
thread̲idから決まるスレッドごとの属性情報をthreadテーブルとして分離。
68/144

分割
commentテーブルカラム データ例1 データ例2
thread̲id 1 1
comment̲number 1 2
comment̲owner 名無しさん 名無しさん
comment̲owner̲email sage sage
comment̲posted 2015-11-30 22:39:03 2015-11-30 22:39:04
comment̲body 殺⼈教室 13⽇のストラトス
thread̲id, comment̲numberから決まるコメント単位の情報をcommentテーブルに分離。
69/144

参照クエリー
新しく作成された順にスレッド⼀覧を表⽰するクエリー
SELECT thread_id /* アンカータグでリンクを張るのに使う */, thread_titleFROM threadORDER BY thread_created DESC
スレッドを詳細表⽰するクエリー
SELECT thread.thread_title, thread.thread_owner, thread.thread_owner_email, thread.thread_created, thread.comment_count, thread.last_posted, comment.comment_number, comment.comment_owner, comment.comment_owner_email, comment.comment_posted, comment.comment_bodyFROM thread JOIN comment USING (thread_id)WHERE thread.thread_id = 1 /* スレッド一覧からthread_idをパラメーターでもらう */ORDER BY comment.comment_number
70/144

更新クエリー
スレッドを追加するためのクエリー
INSERT INTO thread SET thread_id= 1, thread_title= 'new_thread', thread_owner= 'yoku0825', thread_owner_email= '[email protected]', thread_created= '2015/04/30 19:00:00', comment_count= 1, last_posted= '2015/04/30 19:00:00'
INSERT INTO comment SET thread_id= 1, comment_number= 1, comment_owner= 'yoku0825', comment_owner_email= '[email protected]', comment_posted= '2015/04/30 19:00:00', comment_body= 'This is my first thread!'
71/144
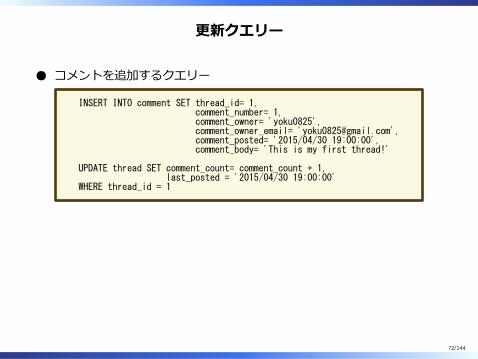
更新クエリー
コメントを追加するクエリー
INSERT INTO comment SET thread_id= 1, comment_number= 1, comment_owner= 'yoku0825', comment_owner_email= '[email protected]', comment_posted= '2015/04/30 19:00:00', comment_body= 'This is my first thread!'
UPDATE thread SET comment_count= comment_count + 1, last_posted = '2015/04/30 19:00:00'WHERE thread_id = 1
72/144

これで第2正規形
プライマリーキーの⼀部から⼀意に決まる値は別のテーブルに分割するその時の”プライマリーキーの⼀部”が分割先テーブルのプライマリーキーになる
-
73/144

第2正規化することで変わったこと
スレッドはスレッド、コメントはコメントで独⽴したテーブルに⼊ったのでコメントを追加するためだけにスレッドの情報を何度も何度もINSERTしなくてよくなった
-
コメントのないスレッドを作ることが出来てしまう-スレッドのタイトルを変えるようなことがあっても、コメントのテーブルには影響を及ぼさない
-
新しいスレッドを作成するために、スレッドの作成と最初のコメントを別々にINSERTする必要がある。
-
新しいコメントを投稿するたびに、スレッドの更新時刻なども更新しないといけない。
-
74/144

第2正規形と第3正規形の違い
第2正規形プライマリーキーの ⼀部 だけで決まる要素が存在しない-
第3正規形非キー要素から⼀意に決まる要素が存在しない-
どちらも存在する場合はテーブルを分割する
75/144

非キー属性から⼀意に決まる #とは
thread̲ownerが決まればthread̲owner̲emailが決まる︖comment̲ownerが決まればcomment̲owner̲emailが決まる︖ここでも要件との兼ね合い(ユーザー登録させるの︖ とか)になってくる決まることにして進めます決まらない場合、これは非キー属性から ⼀意に決まらない ので、分割せずに第3正規形ということになります。
-
76/144

分割
threadテーブルカラム データ例1
thread̲id 1
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
77/144

分割
commentテーブルカラム データ例1 データ例2
thread̲id 1 1
comment̲number 1 2
comment̲owner 名無しさん 名無しさん
comment̲posted 2015-11-30 22:39:03 2015-11-30 22:39:04
comment̲body 殺⼈教室 13⽇のストラトス
78/144


これで第3正規形
プライマリーキー以外のカラムが決まると⾃動的に決まるカラムがあった場合はテーブルを分割するこの時の変数になるカラムが、分割先テーブルのプライマリーキー-
80/144

第3正規化することで変わったこと
スレッドを⽴てたことのない、コメントを投稿したことのないユーザーが存在できるようになった先にユーザー登録をしておかなくてはいけなくなった-
ユーザーがメールアドレスを変更してもスレッドテーブルやコメントテーブルを操作する必要はなくなった
81/144

BC正規形
非キー要素からプライマリーキーの⼀部が⼀意に決まる場合はテーブル分割第2正規化の⽮印が逆になったパターンこの掲⽰板テーブルは第3正規化した時点でBC正規形でもある
82/144

第4正規形, 第5正規形
複合プライマリーキー のみ で構成されたテーブルの分割をするあんまりお目にかからなくて済む(第3正規形を作って、複合プライマリーキーのみのテーブルができることは少ない)このスキーマは第3正規化した時点で第5正規形(複合プライマリーキーだけのテーブルがないから)
83/144

個⼈的テーブル設計まとめ
必要なものを全部洗いだしてから分割していく⽅が楽プライマリーキーに着目して、このテーブルでは”何を主体として扱うのか”-その属性は”どの主体の属性なのか”-でテーブルを振り分ける-
84/144

正規化の話おしまい
ここからこの掲⽰板の話はしばらく忘れます
85/144

だいじなこと
⼀番⼤事なのは 第1正規化カラムの中⾝を関数処理して取り出さないといけないようなものはあらかじめカラムを分けて設計すること関数処理を通すとインデックスが最適な形で使えない-
アトミックでないものを⼊れるなら、検索条件にしたり集計対象にしたりしてはいけない単にDurabilityを保証できるBLOBとして使うのも(オススメしないけど)ありといえばあり
-
常にアプリケーション側でデシリアライズするならJSONとかが⼊っててもいい
-
86/144

ひとやすみ
87/144

都市伝説
MySQLを使うなら 遅くなるから 正規化してはいけない確かに遅くなる ケースも ある(特に、5.5より前の古いバージョン)何故 RDBMSを扱う上で正しい はずの正規化でRDBMSであるMySQLのレスポンスが悪くなるのか︖
MySQLはJOINが遅い︖正規化のプロセスを⾒てきましたけど、この通りに操作していたらプライマリーキーで結合しますよね︖プライマリーキーを使った結合なら ⼤概の場合 ちゃんとした速度で動きますが、NLJなので数百万件に達すると遅くなります。JOINすると遅くなるのは多くの場合 ソート 、きれいにインデックスを使いきれていないケースです。
-
88/144

前提
判りやすく説明するために多少の嘘を含んでいます。MySQLは原則 1つのテーブルにつき同時に1つのインデックスしか使えません。
MySQLはおばかさんだと⾔われる所以。。-他のDBMSは知りませんが、使えるらしいです。-
説明のモデルは5.5がベースです。5.6, 5.7とオプティマイザーはかなりよくなっています。-
89/144

インデックスの設計
インデックスとはソート済みの-ある程度のメタデータを持たせた-データの複製(サブセット)-
データの複製であるため、インデックスだけで必要な情報が集まる場合は、テーブル本体をスキャンしなくても良い(covering index)
-
更新系のDML(INSERT, UPDATE, DELETE)の際には常にオーバーヘッドが加わる
-
テーブル本体の容量とは別に容量を必要とする-
90/144

カーディナリティーとは
そのインデックスに含まれる”取りうる値のバリエーション”の数均等に分散した都道府県のカーディナリティーは47都府なら3
-
⼤きければ⼤きいほど、そのインデックスを使って絞り込んだ時に返ってくる結果セットが⼩さくなることが 期待できる均等に分散しているなら、カーディナリティーが47のインデックスで抽出した場合の期待値は 総レコード件数 / 47ただし、レコードが本当に均等に分散しているとは限らない1億3000万レコードが都道府県カラムを持っていたとしても、東京と島根ではレコード件数に差が出る
-
91/144

インデックスを張っていないカラムでWHEREした時の動作をトランプでたとえてみると
ここに100枚のトランプの束があります何が何枚あるかはわかりません⼊ってない札があるかもしれませんこの中からハートのAを全て⾒つけ出してくださいSQLで書くと、SELECT * FROM card WHERE suite= 'heart' AND
number= 1
92/144

どうやる︖
93/144

こうやる
トランプの⼀番上の札をめくってそれがハートのAかどうか確認してハートのAなら左⼿にとっておいて違ったらテーブルに伏せておいてそれを100枚目まで繰り返す
94/144

これがテーブルスキャン
mysql55> explain SELECT * FROM card WHERE suite= 'heart' AND number= 1;+----+-------------+-------+------+---------------+------+---------+------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+------+---------+------+------+-------------+| 1 | SIMPLE | card | ALL | NULL | NULL | NULL | NULL | 100 | Using where |+----+-------------+-------+------+---------------+------+---------+------+------+-------------+1 row in set (0.02 sec)
type: ALL がテーブルスキャン(=テーブルの先頭から末尾まで全スキャン)を,rows: 100が100⾏フェッチしたことを⽰している
95/144

テーブルスキャン
全ての⾏をフェッチしてWHERE条件にマッチするかどうか判定してマッチしたらバッファに詰めて違ったらスキップしてそれをテーブルの末尾まで繰り返す
テーブルに格納されたデータに応じて線形に負荷が増える
96/144

インデックスを例えると
トランプの束とは別に、こんな表をあらかじめ作っておくイメージ。KEY(suite, number)に相当-
suite number 上から
clover 1 25, 93
clover 2 66
..
heart 1 91, 100
..
この表を⾒ると、上から91枚目と100枚目がハートのAであることがわかるので、あとは上から91枚目, 100枚目をめくって裏を返せばいいだけ。
97/144

実際のインデックス
mysql55> explain SELECT * FROM card WHERE suite= 'heart' AND number= 1;+----+-------------+-------+------+------------------+------------------+---------+-------------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+------------------+------------------+---------+-------------+------+--------------------------+| 1 | SIMPLE | card | ref | idx_suite_number | idx_suite_number | 51 | const,const | 2 | Using where; Using index |+----+-------------+-------+------+------------------+------------------+---------+-------------+------+--------------------------+
type: refがインデックスが使えていることを⽰す(他にもパターンがある)key: idx_suite_numberが使っているインデックスを⽰すkey_len: 51がキーの先頭51バイトを有効利⽤していることを⽰す
varchar(16) * 3bytes(UTF-8) + 2byte(padding) + 1byte(tinyint)
-
rows: 2で、2⾏(含まれているハートのA)だけピンポイントにフェッチしたことを⽰す
98/144

検索条件の⼀部しか満たせないインデックスの場合(suiteのみ)
KEY(suite)に相当する索引だとsuite 上から
clover 10,11,22,24,25,29,35,39,49,52,54,55,61,63,66,68,75,88,93,96,99
diamond 1,2,3,5,6,7,13,16,17,19,21,23,27,46,50,56,58,60,65,71,72,73,76,78,81,82,83,86,87,97
heart 4,8,12,30,33,37,40,44,45,47,51,53,64,84,85,90,91,92,94,98,100
spade 9,14,15,18,20,26,28,31,32,34,36,38,41,42,43,48,57,59,62,67,69,70,74,77,79,80,89,95
上から4, 8, 12, 30, ..枚目を順番にひっくり返し、Aかどうかを確認してバッファに詰める。
99/144

検索条件の⼀部しか満たせないインデックスの場合(suiteのみ)
mysql55> explain SELECT * FROM card WHERE suite= 'heart' AND number= 1;+----+-------------+-------+------+---------------+-----------+---------+-------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+-----------+---------+-------+------+-------------+| 1 | SIMPLE | card | ref | idx_suite | idx_suite | 50 | const | 21 | Using where |+----+-------------+-------+------+---------------+-----------+---------+-------+------+-------------+
さっきと概ね同じだが、rows: 21 なので、21枚ひっくり返した(=⾏をフェッチした)ことが読み取れる。
100/144

検索条件の⼀部しか満たせないインデックスの場合(numberのみ)
KEY(number)に相当する索引だとnumber 上から
1 18,25,26,57,65,82,87,91,93,100
2 7,15,43,66,74,84
3 2,9,13,24,28,30,68,69
4 16,34,40,54,90
5 1,36,51,64,72,78,96
6 3,11,19,27,44,70,92
7 4,12,49,52,59,60,83,88,98
8 17,37,38,42,47,48,62,63,67,79,95,99
9 8,14,21,29,41,56,58,71,73,77,85
10 6,20,23,39,50,81
11 22,35,46,61,86,97
12 10,31,32,33,53,75,80,94
13 5,45,55,76,89
上から18, 25, 26, ..枚目を順番にひっくり返し、ハートかどうかを確認してバッファに詰める。
101/144

検索条件の⼀部しか満たせないインデックスの場合(numberのみ)
mysql55> explain SELECT * FROM card WHERE suite= 'heart' AND number= 1;+----+-------------+-------+------+---------------+------------+---------+-------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+------------+---------+-------+------+-------------+| 1 | SIMPLE | card | ref | idx_number | idx_number | 1 | const | 10 | Using where |+----+-------------+-------+------+---------------+------------+---------+-------+------+-------------+
key_len: 1になっているのは、suiteはUTF-8なvarchar型でサイズが⼤きいのに対し、numberはtinyint型なのでサイズが⼩さいため。rows: 10なので、 どちらか⽚⽅だけしか作れないとしたら 、こっちの⽅が さっきのクエリーに対しては 優秀ということもできる︖
102/144

またトランプに戻る
ここに100枚のトランプの束があります何が何枚あるかはわかりません⼊ってない札があるかもしれませんこの中から全てのハートのカードをKからAまで順番に並べてください。SQLで書くと、SELECT * FROM cards WHERE suite= 'heart' ORDER BY
number DESC;
103/144

どうやる︖
104/144

こうやる
トランプの⼀番上の札をめくってそれがハートかどうか確認してハートのAなら左⼿にとっておいてそれを100枚目まで繰り返したあと左⼿に取っておいたハートだけの束を先頭から1枚ずつ繰って並べ替える
105/144

これがスキャンソート
mysql55> explain SELECT * FROM card WHERE suite= 'heart' ORDER BY number DESC;+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+| 1 | SIMPLE | card | ALL | NULL | NULL | NULL | NULL | 100 | Using where; Using filesort |+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+
Extra: Using filesortが⾏フェッチ後にクイックソートしていることを表す表⽰。
106/144

WHEREもORDER BYもインデックスだけで解決できるパターン
KEY(suite, number)の場合suite number 上から
heart 1 91,100
heart 2 84
heart 3 30
heart 4 40,90
heart 5 51,64
heart 6 44,92
heart 7 4,12,98
heart 8 37,47
heart 9 8,85
heart 12 33,53,94
heart 13 45
⼭の上から45枚目のKを左⼿に詰め、33, 53, 94枚目のQをその上に置きJと10がないのはこの表だけでわかり8, 85枚目の9をその上に置き…というのを繰り返して最後にAを上に置けばいい
107/144

インデックスは ソート済みの データの複製
108/144
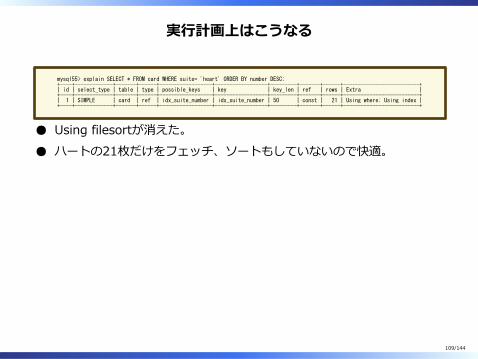
実⾏計画上はこうなる
mysql55> explain SELECT * FROM card WHERE suite= 'heart' ORDER BY number DESC;+----+-------------+-------+------+------------------+------------------+---------+-------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+------------------+------------------+---------+-------+------+--------------------------+| 1 | SIMPLE | card | ref | idx_suite_number | idx_suite_number | 50 | const | 21 | Using where; Using index |+----+-------------+-------+------+------------------+------------------+---------+-------+------+--------------------------+
Using filesortが消えた。ハートの21枚だけをフェッチ、ソートもしていないので快適。
109/144

WHEREのみインデックスで解決できるパターン
KEY(suite)の場合suite 上から
clover 10,11,22,24,25,29,35,39,49,52,54,55,61,63,66,68,75,88,93,96,99
diamond 1,2,3,5,6,7,13,16,17,19,21,23,27,46,50,56,58,60,65,71,72,73,76,78,81,82,83,86,87,97
heart 4,8,12,30,33,37,40,44,45,47,51,53,64,84,85,90,91,92,94,98,100
spade 9,14,15,18,20,26,28,31,32,34,36,38,41,42,43,48,57,59,62,67,69,70,74,77,79,80,89,95
4, 8, 12, 30, ..枚目を左⼿に詰めて全部ハートのカードを取り終わったらハートの束をKから順にAまで並べ替える
110/144

WHEREのみインデックスで解決できるパターン
mysql55> explain SELECT * FROM card WHERE suite= 'heart' ORDER BY number DESC;+----+-------------+-------+------+---------------+-----------+---------+-------+------+-----------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+-----------+---------+-------+------+-----------------------------+| 1 | SIMPLE | card | ref | idx_suite | idx_suite | 50 | const | 21 | Using where; Using filesort |+----+-------------+-------+------+---------------+-----------+---------+-------+------+-----------------------------+
rows: 21で21枚フェッチした(ひっくり返した)ことがわかるUsing filesortされているので、フェッチした21枚をその後並べ替えている。
111/144

ORDER BYのみインデックスで解決できるパターン
KEY(number)の場合number 上から
1 18,25,26,57,65,82,87,91,93,100
2 7,15,43,66,74,84
3 2,9,13,24,28,30,68,69
4 16,34,40,54,90
5 1,36,51,64,72,78,96
6 3,11,19,27,44,70,92
7 4,12,49,52,59,60,83,88,98
8 17,37,38,42,47,48,62,63,67,79,95,99
9 8,14,21,29,41,56,58,71,73,77,85
10 6,20,23,39,50,81
11 22,35,46,61,86,97
12 10,31,32,33,53,75,80,94
13 5,45,55,76,89
5, 45, 55, .. 枚目のKをめくり、ハートだったら左⼿に、そうでなければ机に伏せて、10, 31, 32, 33枚目のQをめくり、ハートだったら左⼿に、そうでなければ机に伏せて…を繰り返してAまでやればおしまい
112/144

ORDER BYのみインデックスで解決できるパターン
mysql55> explain SELECT * FROM card WHERE suite= 'heart' ORDER BY number DESC;+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+| 1 | SIMPLE | card | ALL | NULL | NULL | NULL | NULL | 100 | Using where; Using filesort |+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+
テーブルスキャンになっちゃった(´・ω・`)並べ替えはかっ⾶ばせても、100枚全部フェッチしなきゃいけないなら、セカンダリーキーを使わずに最初からテーブルスキャンした⽅が速いとオプティマイザーが判断。わざわざ表をチェックして開く順番を⾒てから100枚もひっくり返さないといけないのは確かに⾺⿅⾺⿅しい。。
-
113/144

インデックスでソートのみ無効化して⾼速化が⾒込めるケース
mysql55> explain SELECT * FROM card FORCE INDEX(idx_number) WHERE suite= 'heart' ORDER BY number DESC LIMIT 5;+----+-------------+-------+-------+---------------+------------+---------+------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+------------+---------+------+------+-------------+| 1 | SIMPLE | card | index | NULL | idx_number | 1 | NULL | 5 | Using where |+----+-------------+-------+-------+---------------+------------+---------+------+------+-------------+
並べ替えの結果5件だけ戻すような場合。先頭から順番に取っていって、WHERE句にマッチするものが5件あつまった時点で残りの束を⾒る必要がなくなるため、⾏のフェッチ(ひっくり返して中を⾒る)動作はその時点でブレークできる。なのでEXPLAINで⾒ると微妙な感じがするが、件数が多くなれば多くなるほど実感できるほど⾼速化する。5.6以降のオプティマイザーは⾃動で選ぶことがあるが、5.5以前のオプティマイザーはまず間違いなくこの実⾏計画を選んでくれない
LIMIT句はexecutorの範疇で、optimizerを通過した後のステージだから…という。
-
114/144

複合インデックスの弱点
左側のカラムだけ使おうとした場合
mysql55> explain SELECT * FROM card WHERE suite= 'heart';+----+-------------+-------+------+------------------+------------------+---------+-------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+------------------+------------------+---------+-------+------+--------------------------+| 1 | SIMPLE | card | ref | idx_suite_number | idx_suite_number | 50 | const | 21 | Using where; Using index |+----+-------------+-------+------+------------------+------------------+---------+-------+------+--------------------------+
右側のカラムだけ使おうとした場合
mysql55> explain SELECT * FROM card WHERE number = 1;+----+-------------+-------+-------+---------------+------------------+---------+------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+------------------+---------+------+------+--------------------------+| 1 | SIMPLE | card | index | NULL | idx_suite_number | 51 | NULL | 100 | Using where; Using index |+----+-------------+-------+-------+---------------+------------------+---------+------+------+--------------------------+
右側のカラムだけ使おうとしたのはtype: indexでインデックスの全体をスキャンしている。SELECT suite, number, GROUP_CONCAT(seq ORDER BY seq) AS 上から FROM card GROUP BY 1, 2; の結果を⾒ると何となく想像がつくはず。
115/144

よくある「複合インデックスが思った通りに使えないパターン」
OR演算⼦IN演算⼦不等号演算⼦ASC, DESCの混在JOINの結合順序
116/144

JOINのケースに絞って引き続きトランプで
裏⾯が⾚いトランプと 裏⾯が⿊いトランプが何が何枚⼊ってるのか全くわからない状態で100枚ずつの束になっています裏⾯が⾚いトランプの⼭からハートのカードだけを取り出して裏⾯が⿊いトランプの⼭に同じカードが含まれるか確認して両⽅に含まれていることが判ったら、裏⾯が⿊いトランプを机の上に並べて最後にA〜Kの順に並べた上で若い⽅から順番に5枚返すSQLで書くと、SELECT black_card.suite, black_card.number FROM
red_card JOIN black_card USING (suite, number) WHERE red_card.suite= 'heart' ORDER BY black_card.number LIMIT 5
トランプだと物理的な枚数に制約があるので不適だったかもしれない。
-
117/144

どうするか
裏⾯が⾚いトランプの⼭の⼀番上のカードをめくってハートかどうか確認ハートでなければ、次の1枚をめくる-
裏⾯が⿊いトランプの⼭の⼀番上から1枚ずつ順番に裏⾯が⾚いトランプのものと同じカードを探し机に置いておいて最後まで探し終えたら、裏⾯が⾚いトランプの⼭の次のカードをめくって裏⾯が⿊いトランプの⼭の⼀番上から1枚ずつ順番に…これを、裏⾯が⾚いトランプの⼭の最後の1枚まで繰り返したあと、机に置いてある裏⾯が⿊いトランプを並べ替えて、若い⽅から5枚取って返す
118/144

スキャンジョイン
mysql55> explain SELECT black_card.suite, black_card.number FROM red_card JOIN black_card USING (suite, number) WHERE red_card.suite= 'heart' ORDER BY black_card.number LIMIT 5;+----+-------------+------------+------+---------------+------+---------+------+------+----------------------------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+------+---------------+------+---------+------+------+----------------------------------------------+| 1 | SIMPLE | red_card | ALL | NULL | NULL | NULL | NULL | 100 | Using where; Using temporary; Using filesort || 1 | SIMPLE | black_card | ALL | NULL | NULL | NULL | NULL | 100 | Using where; Using join buffer |+----+-------------+------------+------+---------------+------+---------+------+------+----------------------------------------------+
119/144

インデックス︖
WHERE red̲card.suite = ʻheartʼ を解決するためにred_card ADD KEY
idx_suite(suite)
black̲card側のsuite, numberの結合条件を解決するためにblack_card
ADD KEY idx_suite_number(suite, number)
mysql55> explain SELECT black_card.suite, black_card.number FROM red_card JOIN black_card USING (suite, number) WHERE red_card.suite= 'heart' ORDER BY black_card.number LIMIT 5;+----+-------------+------------+------+------------------+------------------+---------+--------------------------+------+----------------------------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+------+------------------+------------------+---------+--------------------------+------+----------------------------------------------+| 1 | SIMPLE | red_card | ref | idx_suite | idx_suite | 50 | const | 17 | Using where; Using temporary; Using filesort || 1 | SIMPLE | black_card | ref | idx_suite_number | idx_suite_number | 51 | const,d1.red_card.number | 1 | Using where; Using index |+----+-------------+------------+------+------------------+------------------+---------+--------------------------+------+----------------------------------------------+
WHERE句のみをインデックスで解決した。ORDER BYに使われているblack̲card.numberもインデックスに含まれているのに、ソートは無効化できていない︖
120/144
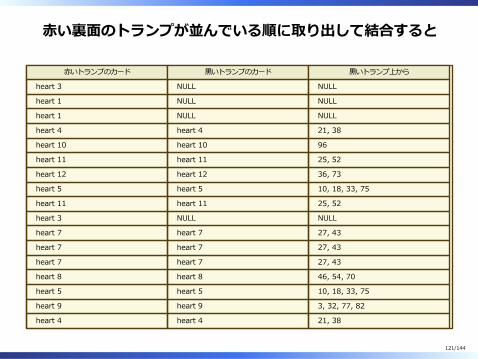
⾚い裏⾯のトランプが並んでいる順に取り出して結合すると
⾚いトランプのカード ⿊いトランプのカード ⿊いトランプ上から
heart 3 NULL NULL
heart 1 NULL NULL
heart 1 NULL NULL
heart 4 heart 4 21, 38
heart 10 heart 10 96
heart 11 heart 11 25, 52
heart 12 heart 12 36, 73
heart 5 heart 5 10, 18, 33, 75
heart 11 heart 11 25, 52
heart 3 NULL NULL
heart 7 heart 7 27, 43
heart 7 heart 7 27, 43
heart 7 heart 7 27, 43
heart 8 heart 8 46, 54, 70
heart 5 heart 5 10, 18, 33, 75
heart 9 heart 9 3, 32, 77, 82
heart 4 heart 4 21, 38
121/144

インデックスで取り出しても、既に並びが崩れている
⾚いトランプのカード ⿊いトランプのカード ⿊いトランプ上から
heart 3 NULL NULL
heart 1 NULL NULL
heart 1 NULL NULL
heart 4 heart 4 21, 38
heart 10 heart 10 96
heart 11 heart 11 25, 52
heart 12 heart 12 36, 73
heart 5 heart 5 10, 18, 33, 75
heart 11 heart 11 25, 52
heart 3 NULL NULL
heart 7 heart 7 27, 43
heart 7 heart 7 27, 43
heart 7 heart 7 27, 43
heart 8 heart 8 46, 54, 70
heart 5 heart 5 10, 18, 33, 75
heart 9 heart 9 3, 32, 77, 82
heart 4 heart 4 21, 38
122/144

ソートが終わってからでないと、”若い⽅から5枚”が判定できないので、結局最後までソートせざ
るをえない。123/144

インデックスでソートまで解決するには
red_card ADD KEY idx_suite_number(suite, number)してやるmysql55> explain SELECT black_card.suite, black_card.number FROM red_card JOIN black_card USING (suite, number) WHERE red_card.suite= 'heart' ORDER BY black_card.number LIMIT 5;+----+-------------+------------+------+----------------------------+------------------+---------+----------------------------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+------+----------------------------+------------------+---------+----------------------------+------+--------------------------+| 1 | SIMPLE | black_card | ref | idx_suite_number | idx_suite_number | 50 | const | 27 | Using where; Using index || 1 | SIMPLE | red_card | ref | idx_suite,idx_suite_number | idx_suite_number | 51 | const,d1.black_card.number | 1 | Using where; Using index |+----+-------------+------------+------+----------------------------+------------------+---------+----------------------------+------+--------------------------+
内部表と外部表が⼊れ替わっているのにお気づきだろうか。red̲card.suite == black̲card.suite なので、ORDER BY black̲card.numberはORDER BY red̲card.numberと等価だと気付いてそれを使っている。
124/144
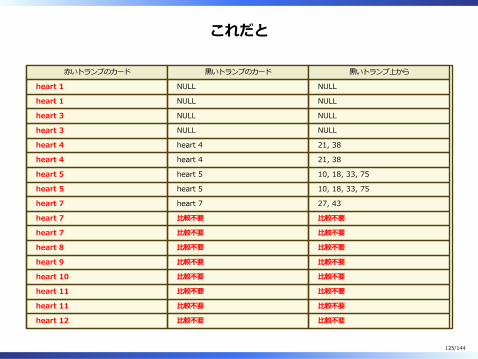
これだと
⾚いトランプのカード ⿊いトランプのカード ⿊いトランプ上から
heart 1 NULL NULL
heart 1 NULL NULL
heart 3 NULL NULL
heart 3 NULL NULL
heart 4 heart 4 21, 38
heart 4 heart 4 21, 38
heart 5 heart 5 10, 18, 33, 75
heart 5 heart 5 10, 18, 33, 75
heart 7 heart 7 27, 43
heart 7 ⽐較不要 ⽐較不要
heart 7 ⽐較不要 ⽐較不要
heart 8 ⽐較不要 ⽐較不要
heart 9 ⽐較不要 ⽐較不要
heart 10 ⽐較不要 ⽐較不要
heart 11 ⽐較不要 ⽐較不要
heart 11 ⽐較不要 ⽐較不要
heart 12 ⽐較不要 ⽐較不要
125/144

⾚いトランプのカードを取り出した時点で既にソートが終わっている
red̲card.idx̲suite̲numberが並んでいる順番にハートだけを抽出してblack̲card.idx̲suite̲numberは”=”演算にだけ使いORDER BY black̲card.numberはORDER BY red̲card.numberと等価で既に並べ替えなのでソートは終わっていると判断してheart 4, heart 4, heart 5, heart 5, heart 7が揃った段階で”若い⽅から5枚”が確定するので、それ以降は⿊いトランプのカードを探す必要がない。
126/144

というのを知っていると、JOINで遅くなるケースはまあまあ納得がいく
そもそもスキャンジョインしているソートまでインデックスだけで解決できていない
17⾏くらい⼤したことないけれど、1000万⾏あったらソートするのはだいぶ骨が折れる。
-
MySQL 5.6でオプティマイザーが賢くなったので、新しいバージョンを使っていればこういう内部動作を気にしなくてもいいかも知れないけれど内部的な動作原理を知っているとどんなインデックスを作ると速くなるか(あるいは、ならないか)が想像しやすい
127/144

取り敢えずの動作としては”まずWHERE句を処理するためのカラム” “次にORDER BY句を処理するためのカラム”の順に並べる
WHERE句を処理するためのカラムにINやANYが⼊っていると、それより後ろに列挙されたぶんが使えなくなるので注意カラムに対して演算を⾏っているとインデックスは効かない更に⾼速化を狙うならselect̲listに⼊っているものを含めてcovering indexを狙うGROUP BYはWHEREのあと、ORDER BYの前に処理されるので、GROUP BY⽤のカラムを追加するなら(WHERE, GROUP BY, ORDER BY)の順番になる。
HAVINGやその後のORDER BYで集計関数の結果カラムを指定していると、それは”演算を⾏っている”のでその部分はインデックスではスキップできない。
-
128/144
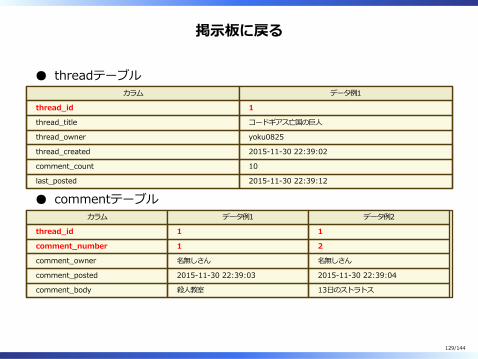
掲⽰板に戻る
threadテーブルカラム データ例1
thread̲id 1
thread̲title コードギアス亡国の巨⼈
thread̲owner yoku0825
thread̲created 2015-11-30 22:39:02
comment̲count 10
last̲posted 2015-11-30 22:39:12
commentテーブルカラム データ例1 データ例2
thread̲id 1 1
comment̲number 1 2
comment̲owner 名無しさん 名無しさん
comment̲posted 2015-11-30 22:39:03 2015-11-30 22:39:04
comment̲body 殺⼈教室 13⽇のストラトス
129/144


参照⽤クエリー
新しく作成された順にスレッド⼀覧を表⽰するクエリー
SELECT thread_id, thread_titleFROM threadORDER BY thread_created DESC
WHEREはないがthread̲createdで逆順ソートしているので、idx̲threadcreated (thread̲created)はあるとクイックソートを⾶ばせる。先頭100件のみ、などとやる時に末尾までソートしなくていいので⾼速化できる。
131/144

参照⽤クエリー
コメント数の多い順にスレッド⼀覧を表⽰するクエリー
SELECT thread_id, thread_titleFROM threadORDER BY comment_count DESC
idx̲commentcount(comment̲count)があった⽅がいい。
132/144
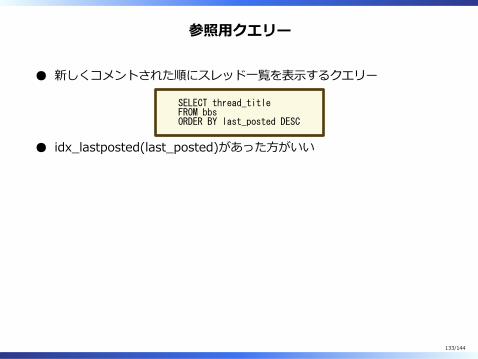
参照⽤クエリー
新しくコメントされた順にスレッド⼀覧を表⽰するクエリー
SELECT thread_titleFROM bbsORDER BY last_posted DESC
idx̲lastposted(last̲posted)があった⽅がいい
133/144

参照⽤クエリー
スレッドを詳細表⽰するクエリー(メタデータを取り出すところ)
SELECT thread.thread_title, thread.thread_owner, user.user_email AS thread_owner_email, thread.thread_created, thread.comment_count, thread.last_postedFROM thread JOIN user ON thread.thread_owner = user.user_nameWHERE thread.thread_id = 1
threadテーブルのthread̲idは既にプライマリーキーなので1つ目のWHERE句はOKuserテーブルのuser̲nameもプライマリーキーなのでOK
134/144

参照⽤クエリー
スレッドを詳細表⽰するクエリー(つづき)
SELECT comment.comment_number, comment.comment_owner, user.user_email AS comment_owner_email, comment.comment_posted, comment.comment_bodyFROM comment JOIN user ON comment.comment_owner = user.user_nameWHERE comment.thread_id = 1ORDER BY comment.comment_number
userテーブルのuser̲nameもプライマリーキーなのでOKcommentテーブルの(thread̲id, comment̲number)はプライマリーキーで順番もこの通りでOK
135/144

他にもたとえば
コメント数の多いユーザー10⼈を抽出するクエリー
SELECT user.user_name, COUNT(*) AS comment_countFROM user JOIN comment ON user.user_name = comment.comment_ownerGROUP BY user.user_nameORDER BY comment_count DESC LIMIT 10
commentテーブルの結合のためにidx̲commentowner(comment̲owner)userテーブルのGROUP BYのためにuser̲nameはプライマリーキーなのでこのままでOKORDER BYのcomment̲countは集計関数の結果カラムなのでソートは避けられない
5.6以降ならばソート⽤の⼀時インデックスを⾃動で作るかも。-
136/144

他にもたとえば
ユーザーの最終コメント時刻を抽出するクエリー
SELECT user.user_name, MAX(comment.comment_posted) AS last_postedFROM user JOIN comment ON user.user_name = comment_comment_ownerGROUP BY user.user_name
どういう風に結合されるのかがイメージできると、idx̲commentowner̲commentposted(comment̲owner, comment̲posted)があった⽅がいい気がしてきませんか︖
137/144

指標的なもの
EXPLAINExtra: Using filesortでORDER BYやGROUP BYがインデックスで解決できていない
-
Extra: Using tempraryでGROUP BYやJOINがインデックスで解決できていない
-
Extra: Using join bufferでスキャンジョイン-
138/144

指標的なもの
SHOW GLOBAL STATUScreated̲tmp̲%tables .. テンポラリーテーブルが作成された(Extra: Using temporaryな)クエリーでカウントアップされる
-
handler̲read% .. 実際に⾏をフェッチしているとカウントアップされる
-
Select̲full̲join, Select̲scan-Sort̲merge̲passes, Sort̲scan-
139/144

指標的なもの
performance̲schemaevents̲statements̲summary̲by̲digestテーブルなど-
140/144

インデックスまとめ
検索が増えれば必要なインデックスも増えるインデックスが増えれば更新性能, ファイルサイズにオーバーヘッドが加わる更新のデメリットに対して参照のメリットは⼗分⼤きい
covering indexで仕留めればクエリーの速度が数百倍になることも珍しくない
-
Disk容量が⾜りているなら、SELECTタイプごとに複合インデックス作った⽅がいい
-
余談: InnoDBは⾏ロックじゃなくてネクストキーロック適切なインデックスがないとロックで死ねる-
MySQLは5.6でオプティマイザーに⼤きな改良が加えられているこれから利⽤なら5.6、可能なら5.7も-MariaDBなら5.3以降を-
141/144

おまけ
thread.comment̲countってcommentから計算できるから消さないといけないんじゃないの︖
“one fact in one place”っていうとそうなんですが-C.J.Dateの本を読んでる限りでは、正規化のプロセスとしてはそこを切り離すのは⾒当たらなかったご存知の⽅いたら本の名前を教えてください。
-
個⼈的には集約関数の結果をソートするのはオーバーヘッドが⼤きいし、threadテーブルから⾒るとcomment̲countは個々のスレッドが持つ “属性” で、たまたま外部で計算したものと値が⼀致するだけ、と考えるようにしている。
-
142/144

おまけ
なんでuserテーブルだけナチュラルキーにしたの︖comment̲numberもナチュラルのつもりです(n番目のコメント、という情報がきちんとコメントを識別する意味を持っている)
thread̲idは完全にサロゲートキーです
-
基本的にナチュラルキーにしたいんですけど、InnoDBのセカンダリーキーのリーフにはPRIMARY KEYの値が格納されるInnoDBのデータ本体はPRIMARY KEYのリーフにぶら下がるInnoDBのチェンジバッファは、セカンダリーキーにしか効かない
-
このあたりの制約から、ある程度以上のボリュームがあったり更新があるのが目に⾒えているものはサロゲートキーを使うことが多いです。
-
143/144

それでは、素敵なMySQLライフを
144/144