mysql cluster 7.4で楽しむスケールアウト @db tech showcase 2015/06
TRANSCRIPT

MySQL Cluster 7.4MySQL Cluster 7.4 でで楽しむスケールアウト楽しむスケールアウト
奥野 幹也Twitter: @nippondanjimikiya (dot) okuno (at) gmail (dot) com
@DB Tech Showcase 2015/06

免責事項● 本プレゼンテーションにおいて示されている見解は、私自身の見解であって、オラクル・コーポレーションの見解を必ずしも反映したものではありません。ご了承ください。

自己紹介
● MySQL サポートエンジニア– 日々のしごと
● トラブルシューティング全般● Q&A 回答● パフォーマンスチューニング
など● ライフワーク
– 自由なソフトウェアの普及● オープンソースではない
● ブログ– 漢のコンピュータ道– http://nippondanji.blogspot.com/
今日は個人として参加しています。

MySQL Clusterとは

MySQLの姉妹製品並列分散型データベース
● MySQL のストレージエンジンとして使える。– CREATE TABLE table_name (…) ENGINE=NDB;– トランザクション対応
● 並列分散型のデータベース– データを分散して保存
● シェアードナッシング– 複数のノードで分散処理が可能
● スケールアウト– HA 機能内蔵
● 元々はインメモリデータベース– 後からディスクテーブルが追加– ハイパフォーマンス
● NewSQL = SQL + NoSQL● ディアルライセンス
– コミュニティ版は GPLv2

ノードの種類
● データノード– MySQL Cluster の心臓部– データとトランザクションを司る– HA 機能内蔵
● SQL ノード /API ノード– NDB ストレージエンジンを搭載した MySQL サーバ– NDB API を経由してデータノードへアクセス– アプリケーションが SQL ノードを介さず直接 NDB API を
叩くことも可。( API ノード)● 管理ノード
– クラスターの構成情報を管理– 各種操作の命令を発行
● データノードの起動・停止やバックアップ実行– ログの採取
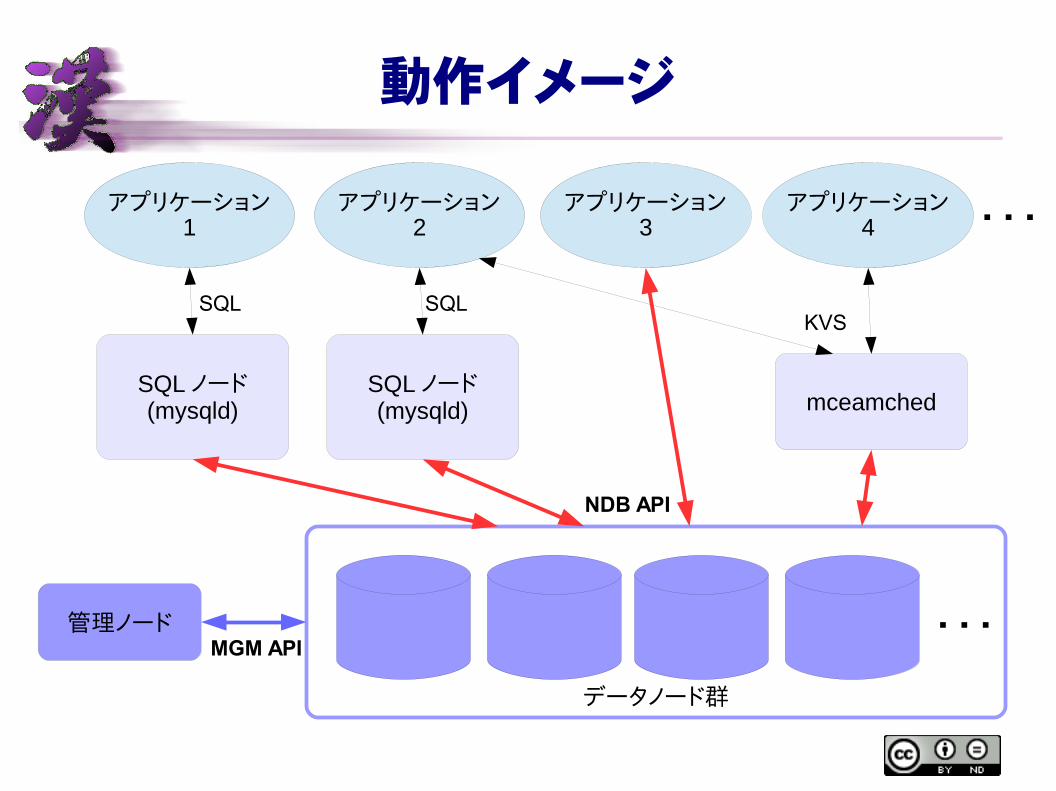
動作イメージ
・・・管理ノード
データノード群
MGM API
SQL ノード(mysqld)
SQL ノード(mysqld)
アプリケーション1
アプリケーション2
アプリケーション3
アプリケーション4 ・・・
mceamched
NDB API
SQL SQLKVS

動作イメージその 2

動作イメージその 3● SBC x 7 で構成し
たデモマシン● BBB x 6● RsapberryPi x 1● ノード構成
– SQL x 2– データ x 4
ポータブルMySQL Cluster!!

現実はデモ環境とは違う
● MySQL Cluster は大規模向けなので、実際にはデータセンター内のラックに収まってるサーバー上で動いてるのが普通です。
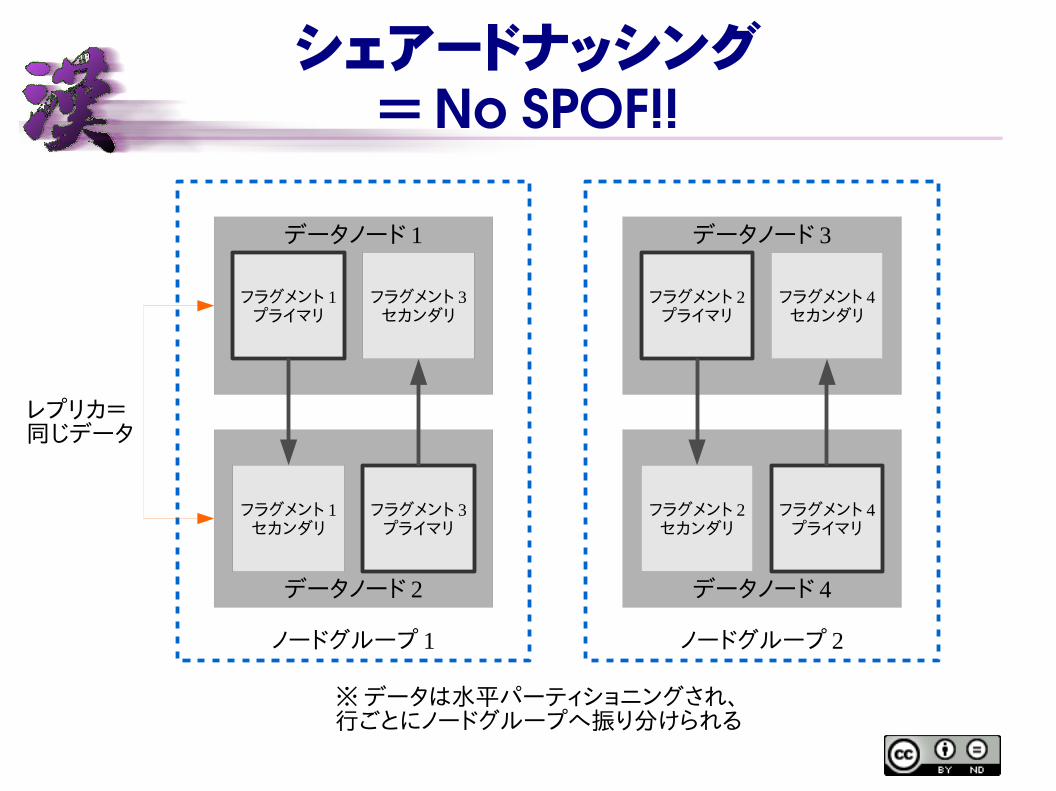
シェアードナッシング=No SPOF!!
ノードグループ 1
データノード 1
データノード 2
フラグメント 1プライマリ
フラグメント 3セカンダリ
フラグメント 1セカンダリ
フラグメント 3プライマリ
ノードグループ 2
データノード 3
データノード 4
フラグメント 2プライマリ
フラグメント 4セカンダリ
フラグメント 2セカンダリ
フラグメント 4プライマリ
※データは水平パーティショニングされ、行ごとにノードグループへ振り分けられる
レプリカ=同じデータ

ノード障害に耐える
ノードグループ 1
データノード 1
データノード 2
dead dead
フラグメント 1プライマリ
フラグメント 3プライマリ
ノードグループ 2
データノード 3
データノード 4
フラグメント 2プライマリ
フラグメント 4セカンダリ
フラグメント 2セカンダリ
フラグメント 4プライマリ
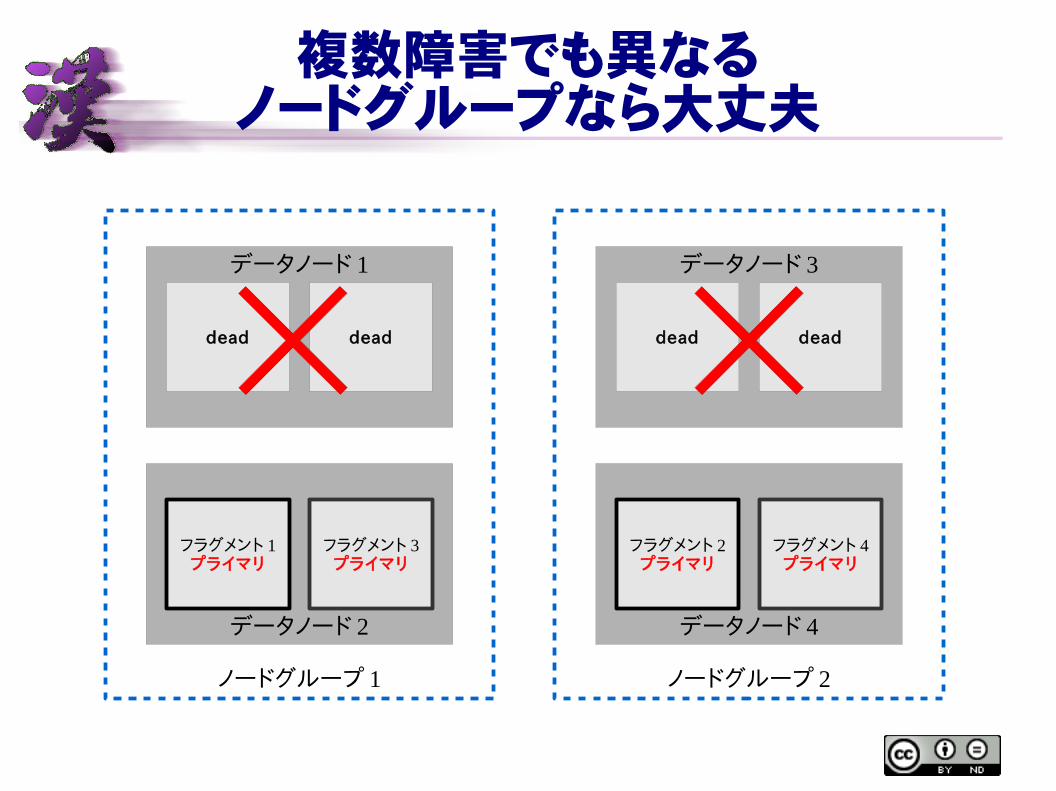
複数障害でも異なるノードグループなら大丈夫
ノードグループ 1
データノード 1
データノード 2
dead dead
フラグメント 1プライマリ
フラグメント 3プライマリ
ノードグループ 2
データノード 3
データノード 4
dead dead
フラグメント 2プライマリ
フラグメント 4プライマリ
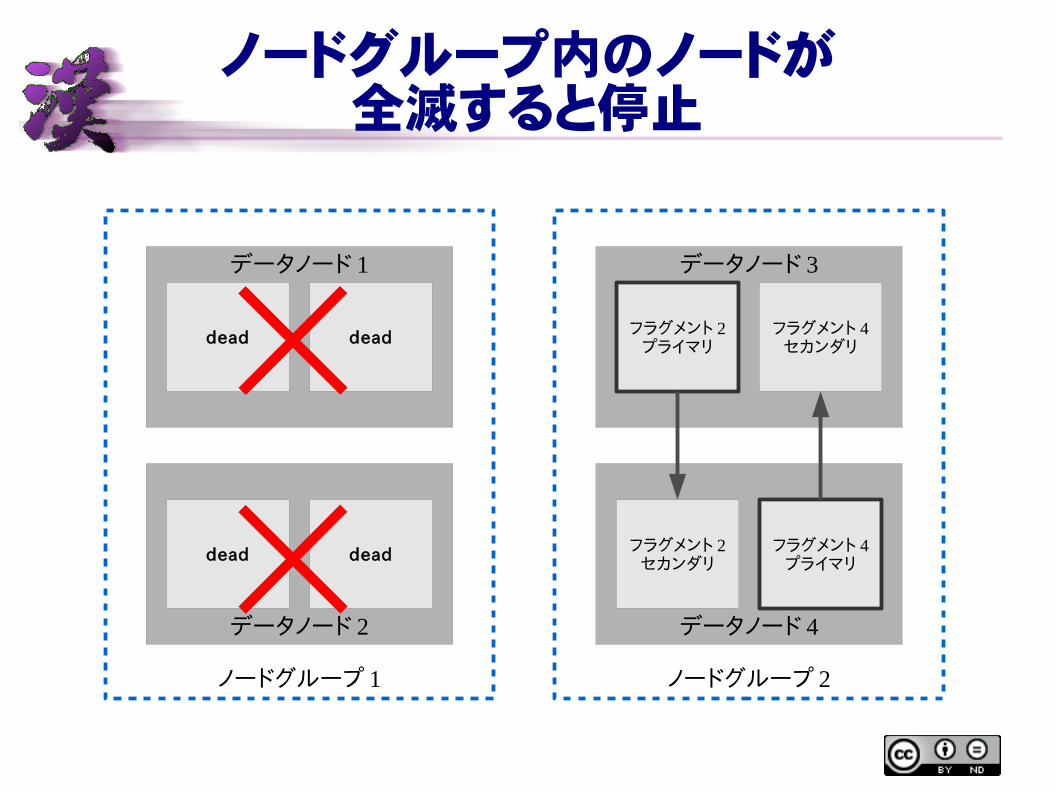
ノードグループ内のノードが全滅すると停止
ノードグループ 1
データノード 1
データノード 2
dead dead
dead dead
ノードグループ 2
データノード 3
データノード 4
フラグメント 2プライマリ
フラグメント 4セカンダリ
フラグメント 2セカンダリ
フラグメント 4プライマリ

MySQL Cluster の
トポロジー

ノード構成の要件
● 全ての種類のノードを含めて最大 255 ノードまで。● データノード
– 最大 48 ノード– HA のためにレプリカ(複製)を構成
● 通常はレプリカ数 2● SQL ノード
– 可用性を考えれば 2 ノード以上● どの SQL ノードからでも同じデータが見える
– 接続を複数消費するモードあり● 管理ノード
– 冗長化してもしなくても良い– アービトレーションとロギング以外に落ちて困ること無し

アービトレーション(調停)
● ネットワークパーティション発生時の解決法– ネットワークパーティションはスプリットブレインとも言う
● ネットワークの問題によって、動作可能な複数のクラスターに分断された状態
● アービトレーターへ最初に到達したほうが動作継続– 負けた方は強制的にシャットダウン
ノードグループ 1
データノード 1
データノード 2
フラグメント 1プライマリ
フラグメント 3プライマリ
フラグメント 1プライマリ
フラグメント 3プライマリ
ノードグループ 2
データノード 3
データノード 4
フラグメント 2プライマリ
フラグメント 4プライマリ
フラグメント 2プライマリ
フラグメント 4プライマリ
アービトレーター
調停依頼
調停依頼
OK
NG
切断

アービトレーターの要件
● アービトレーターになれるノード– デフォルトでは管理ノードがアービトレーター– SQL ノードもアービトレーターになれる– データノードはアービトレーターになれない
● データノードと同じホストで同居不可– もし仮に同居していると・・・
● ホストがこけるとデータノードとアービトレーターが同時にダウン
– ホストのダウンとネットワークの障害は見分けがつかない
– MySQL Cluster は最低でもホスト 3 台から!● データノード x2 ( HA 構成)● SQL ノードはデータノードと同居● 管理ノード=アービトレーター

最小構成
● ホストは 3 台– (データノード+ SQL ノード) x2– 管理ノード x1
データノード
ホスト 1
SQL ノード
データノード
ホスト 2
SQL ノード
ホスト 3
管理ノード
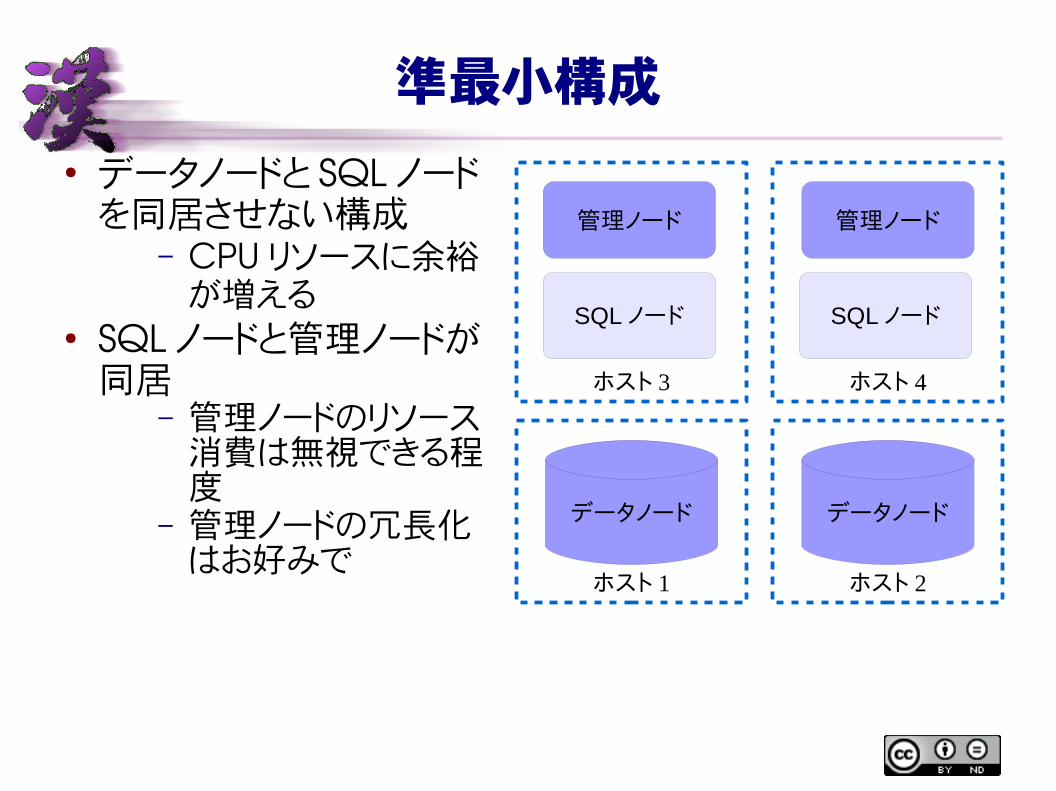
準最小構成
● データノードと SQL ノードを同居させない構成
– CPU リソースに余裕が増える
● SQL ノードと管理ノードが同居
– 管理ノードのリソース消費は無視できる程度
– 管理ノードの冗長化はお好みで
データノード
ホスト 1
SQL ノード
データノード
ホスト 2
SQL ノード
ホスト 3 ホスト 4
管理ノード 管理ノード
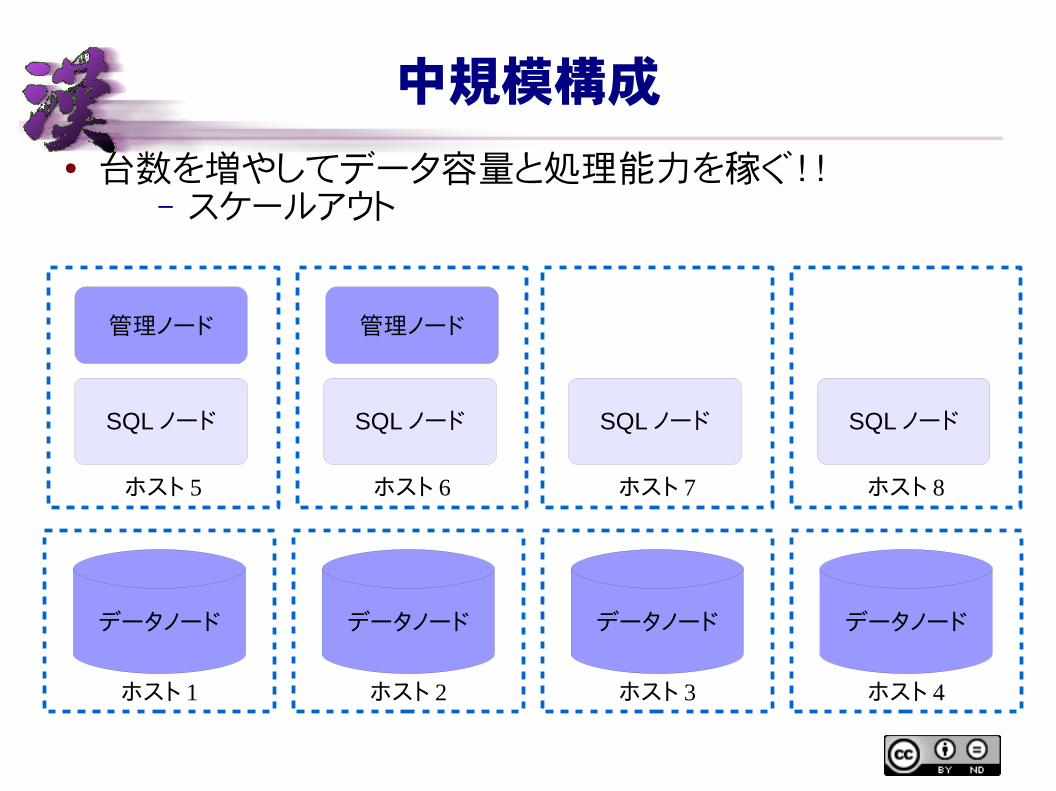
中規模構成
● 台数を増やしてデータ容量と処理能力を稼ぐ!!– スケールアウト
データノード
ホスト 1
SQL ノード
データノード
ホスト 2
SQL ノード
ホスト 5 ホスト 6
管理ノード 管理ノード
データノード
ホスト 3
データノード
ホスト 4
SQL ノード SQL ノード
ホスト 7 ホスト 8

大規模構成
データノード
SQL ノード
管理ノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
データノード
SQL ノード SQL ノード SQL ノード SQL ノード SQL ノード
SQL ノード SQL ノード SQL ノード SQL ノード SQL ノード SQL ノード
SQL ノード SQL ノード SQL ノード SQL ノード SQL ノード SQL ノード
管理ノード

マシン選定時のポイント
● データノード– CPU パワー大、メモリ大– ノードを増やすときの判断基準
● データ容量を稼ぎたい● 同時アクセス数を増やしたい
– ノードを増やすことで処理能力が向上
● SQL ノード– CPU パワー大、メモリ小– ノードを増やすときの判断基準
● CPU パワーが限界● データノードの倍程度
● 管理ノード– CPU パワー小、メモリ小– 可用性のために最大で 2 つ(一つでも問題ではない)– SQL ノードとの同居が多い

データノードによる最適化
● Engine Condition Pushdown– WHERE句の条件をデータノードへ送信– データノード側でデータをフィルタリング– テーブルスキャンなどの大量のデータを扱うクエリが高速
化● Join Pushdown ( SPJ )
– JOIN の条件をデータノードへ送信– データノード側で並列分散 JOIN 実行– SQL ノードは JOIN の結果を受信

アプリケーションとSQL ノードの接続方式
データ
SQL
データ
SQL
Javaアプリケーション
Connector/J
Connector/Jのロードバランスを利用
データ
SQL
データ
SQL
アプリ アプリ
アプリと SQL ノードが同居
データ
SQL
データ
SQL
アプリケーション MySQl Proxy
MySQL Proxyを利用

MySQL Clusterレプリケーション

レプリケーション動作イメージ
データノード群
SQL ノード(バイナリログ生成)通常の
SQLノード
通常のSQLノード通常の
SQL ノードbinloginjectorthread
バイナリログスレーブへ
mceamched
NoSQLによる更新
SQLによる更新更新内容を抽出

レプリケーションの仕組み
● 通常の MySQL サーバーのレプリケーションとほぼ同じ– バイナリログ生成の仕組みが異なる– Binlog Injector Thread がデータノードから更新データ
を受信してまとめる– フォーマットは行ベースのみ
● MySQL Cluster → MySQL Cluster– マスター上のひとつの SQL ノードから、スレーブ上のひと
つの SQL ノードへ– マルチマスター構成も可能
● 競合検出あり● MySQL Cluster → InnoDB
– 1:N 構成が可能

遠隔地レプリケーション
● MySQL Cluster → MySQL Cluster● 主にディザスタリカバリの用途で利用
データ データ
データ データ
SQL SQL SQL
マスター
データ データ
データ データ
SQL SQL SQL
スレーブ
インターネット
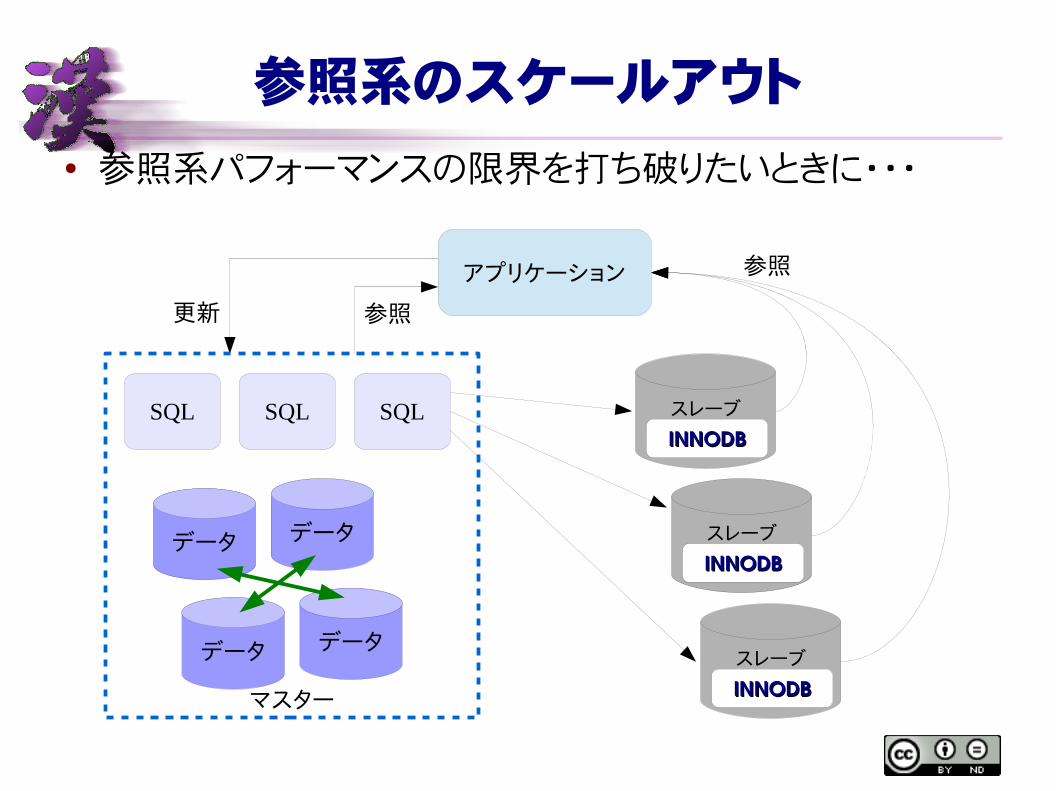
参照系のスケールアウト
スレーブ
INNODBINNODB
スレーブ
INNODBINNODB
スレーブ
INNODBINNODB
更新
参照アプリケーション
データ データ
データ データ
SQL SQL SQL
マスター
参照
● 参照系パフォーマンスの限界を打ち破りたいときに・・・

SQL + NoSQL=
死角無し!!

MySQL ClusterのNoSQL● NDB API
– MySQL Cluster のネイティブ API– 爆速
● ClusterJ/ClusterJPA– Java のラッパー– O/R マッパーっぽい使い方が可能
● memcached– 永続化可能な KVS として
● javascript– Node.js 用に

NoSQL APIを使うことのメリット・デメリット
● メリット– パフォーマンス、パフォーマンス、パフォーマンス!!!
● NDB API>memcached>>>SQL– 永続化可能– SQL と同じデータにアクセスが可能
● SQL と NoSQL のデータ同期不要
● デメリット– クエリの柔軟性に欠ける
● JOIN ができない!!● NDB API は記述が面倒
– memcached はトランザクション非対応● 永続化はできるが API は KVS のもの

組み合わせは自由
● SQL– トランザクション処理
● NoSQL– シンプルな参照・更新– ハイパフォーマンス
● InnoDB によるスケールアウト– 複雑な参照系クエリのスケールアウト– レポーティングやランキング等
● 遠隔地レプリケーション– 万が一のときのために

組み合わせ利用イメージ
INNODBINNODB
INNODBINNODB
INNODBINNODB
アプリケーション群
データ データ
データ データ
SQL SQL SQLmemcache
memcache
データ データ
データ データ
SQL SQLSQL

NoSQLだけの製品と比べた場合のメリット
● データの不整合を起こさないための仕組みがある– リレーショナルモデル– トランザクション– アプリケーションがクラッシュしたときの対処が容易– データの不整合が起きにくい
● MySQL の汎用ツールが使える– SQL 、トリガー、ストアドプロシージャ
● SQL =複雑なクエリを効果的に記述可能– スロークエリログ– レプリケーション
etc● 用途に応じてインターフェイスが使い分けできる
– トランザクションや複雑なクエリは SQL– 単純で速さが重要な処理は NDB API や memcached

MySQL Cluster 7.4登場!!

新機能ダイジェスト
● SQL ノードは MySQL 5.6 ベース– 7.3 と同じ
● パフォーマンスの大幅な向上● レプリケーションにおける競合検出の強化● フラグメントの監視● データノード再起動の高速化と進捗のモニタリング
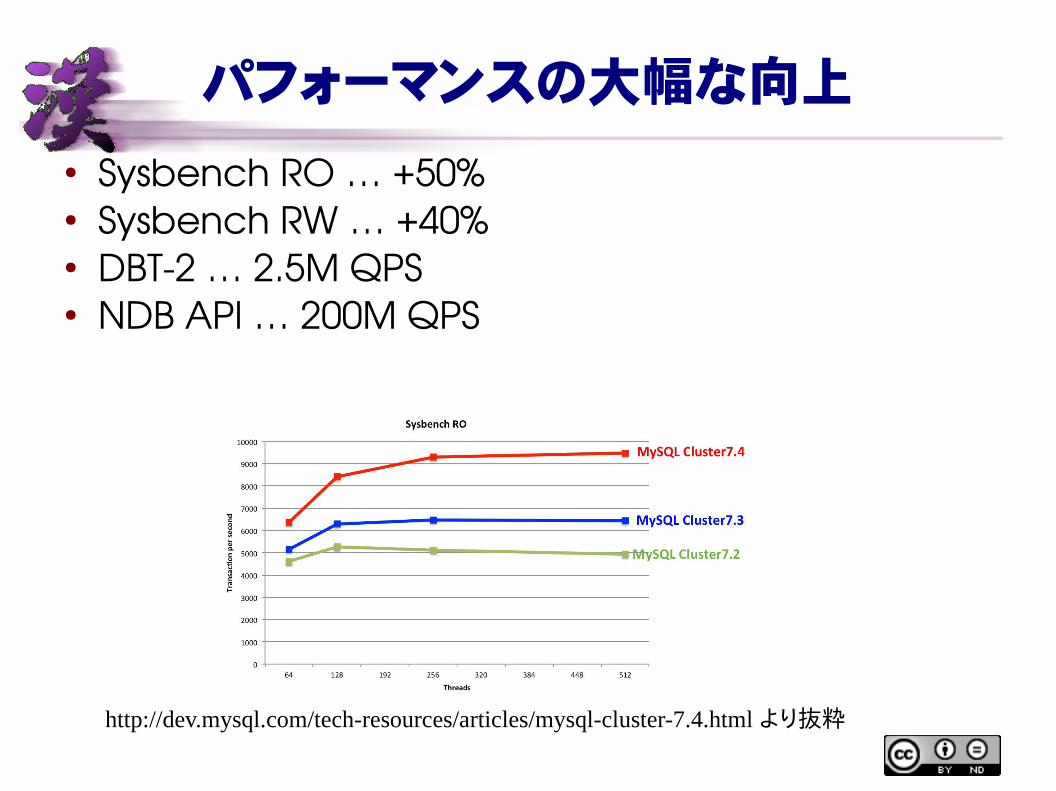
パフォーマンスの大幅な向上
● Sysbench RO … +50%● Sysbench RW … +40%● DBT2 … 2.5M QPS● NDB API … 200M QPS
http://dev.mysql.com/tech-resources/articles/mysql-cluster-7.4.html より抜粋

レプリケーションにおける競合検出の強化
● 競合検出時に採取する情報が拡充– 以前のバージョン:主キーの値のみ– 7.4 :任意のカラムのデータ
● 新しい競合検出方式が追加– マスター・マスター構成において、プライマリのロールを指定可能に
● 参照系処理の不整合を検出可能に

フラグメントごとの監視
● メモリ使用量– どのテーブルあるいはフラグメントがメモリをたくさん消費
しているか– ndbinfo.memory_per_fragment
● オペレーション– どのテーブルあるいはフラグメントにアクセスが集中して
いるか● 操作の種類ごとのアクセス統計が明確に● アクセスの偏りを調査可能
– ndbinfo.operations_per_fragment

データノード再起動高速化
● 7.3 と比べて 5倍高速!!– メモリ初期化処理の並列化– LCP の並列度向上
● 再起動の進捗を取得– ndbinfo.restart_info– ノードを再起動すると、現在のステータスと、それぞれの
フェーズでどれだけ時間がかかったかが分かる。mysql> select * from restart_info\G*************************** 1. row *************************** node_id: 1 node_restart_status: Restart completed node_restart_status_int: 19 secs_to_complete_node_failure: 0 secs_to_allocate_node_id: 2 secs_to_include_in_heartbeat_protocol: 1
〜中略〜 secs_wait_lcp_for_restart: 2 secs_wait_subscription_handover: 6 total_restart_secs: 141 row in set (0.00 sec)

まとめ
● MySQL Cluster の特徴– シェアードナッシングアーキテクチャー– 高可用性– スケールアウト– SQL + NoSQL
● 7.3 から 7.4 へは正常進化– 大きな機能追加はなし– パフォーマンスが大きく向上
● 200M QPS!!– 運用の利便性が向上
● 再起動の高速化● モニタリングの強化● レプリケーション競合検出の強化

宣伝:書籍紹介その 1● MySQL Cluster 構築・運用バイブル
– 第 1章 MySQL Cluster のコンセプト– 第 2章 インストール– 第 3章 基本操作– 第 4章 MySQL Cluster を用いた開発– 第 5章 NoSQL としての MySQL Cluster– 第 6章 パフォーマンス– 第 7章 Cluster レプリケーション– 第 8章 MySQL Cluster の監視– 第 9章 メンテナンス– 第 10章 典型的なトラブルと対処法

宣伝:書籍紹介その 2● 理論から学ぶ データベース実践入門
– どうやってリレーショナルデータベースを使いこなすか!● リレーショナルモデル基礎編
– SQL とリレーショナルモデル– 述語論理とリレーショナルモデル– 正規化 1: 関数従属性– 正規化 2: 結合従属性– 直交性– ドメインの設計
etc● アプリケーション開発実践編
– 履歴– グラフ– インデックスの設計– ウェブアプリケーションのためのデータ構造
etc
基礎の基礎からよくある間違いを指摘しつつ応用まで

Q&Aご静聴ありがとうございました。