mysql cluster 新機能解説 7.5 and beyond
TRANSCRIPT

MySQL ClusterMySQL Cluster新機能解説新機能解説7.5 and beyond7.5 and beyond
奥野 幹也Twitter: @nippondanjimikiya (dot) okuno (at) gmail (dot) com
@DBTS-Tokyo 2017

免責事項本プレゼンテーションにおいて示されている見解は、私自身の見解であって、オラクル・コーポレーションの見解を必ずしも反映したものではありません。ご了承ください。

自己紹介
● MySQLサポートエンジニア– 日々のしごと
● トラブルシューティング全般● Q&A回答● パフォーマンスチューニングなど
● ライフワーク– 自由なソフトウェアの普及– 趣味はリカンベントに乗ること
● 最近は執筆と子育ての日々・・・● ブログ
– 漢のコンピュータ道– http://nippondanji.blogspot.com/

MySQL Clusterのネーミングについて

MySQL “NDB” Cluster● マニュアル上での表記が変更
– MySQL Cluster MySQL → NDB Cluster– https://dev.mysql.com/doc/refman/en/mysql-cluster.html
● MySQL InnoDB Cluster との明確化● 製品名としての変更は(今のところ)ナシ
– MySQL Cluster Carrier Grade Edition– https://www.mysql.com/products/cluster/– ややこしや〜
本セッションではMySQL NDB Clusterに統一

MySQL NDB Cluster7.5新機能概要

MySQL NDB Cluster 7.5新機能概要
● MySQL 5.7 との統合● インデックス統計情報の改良● ndbinfoの拡充● バックアップレプリカからの参照● 全データノードへのレプリカ● テーブルの容量制限改善● ndb_restore コマンドの SQL出力
2016年 10月リリース

MySQL 5.7との統合

MySQL 5.7 との統合● MySQLサーバーの最新版
– 2015年 10月リリース– 175を超える新機能搭載
● SQL ノード=NDBストレージエンジンつきMySQLサーバー
– ストレージエンジンを変更するだけで同じ SQLでアクセス可能
– MySQL NDB Clusterでもメリットの享受が可能● MySQL NDB Cluster 7.5 MySQL 5.7→● MySQL NDB Cluster 7.3, 7.4 MySQL 5.6→● MySQL NDB Cluster 7.2 MySQL 5.5→

MySQL 5.7の機能● レプリケーション関連● InnoDB関連● オプティマイザー関連● セキュリティ関連● パフォーマンススキーマ関連● GIS関連● JSON関連● etc etc...

詳解MySQL 5.7止まらぬ進化に乗り遅れないためのテクニカルガイド
● MySQL 5.7の新機能を網羅的に解説– 175 の新機能– WorkLog/Bug Id つき– コンセプト、仕組み、使い方
● 新機能の理解に必要な前提知識– 古いバージョンでも適用可能– アーキテクチャを理解することで本物の理解を

MySQL 5.7 との統合による具体的な
改善点

Records-per-key最適化● オプティマイザが JOINのときに参照する情報● 外部表の 1行に対して、内部表から平均何行がマッチするか
– ストレージエンジンが値を返す– MySQL 5.7においてデータ型が INTから FLOATに変更
● より正確な JOINのコスト見積が可能に● MySQL NDB Cluster 7.5 も FLOATに対応

その他のオプティマイザ関連の新機能
● EXPLAIN FOR CONNECTION● 新しいコストモデル● オプティマイザヒント● ディスクベースのテンポラリテーブルを InnoDB化● UNION ALLがテンポラリテーブル不要に● コストにWHERE句による絞り込みを考慮● GROUP BYの動作を SQL標準準拠に● FROM句のサブクエリでテンポラリテーブルが不要な場合作成しないようにetc etc

パフォーマンススキーマとsysスキーマ
● パフォーマンス・スキーマ– 種々の統計情報を取得– 主にパフォーマンス解析に利用– 情報の種類が多すぎて使いこなすのが難しいのが難点– バージョンが上がるごとに情報の種類が増加
● sysスキーマ– パフォーマンス・スキーマと情報スキーマを横断的にアクセスするビューのコレクション
– パフォーマンス・スキーマよりも直感的に利用可能– MySQL 5.7で追加
● 元々は独立したプロジェクトだった● MySQL 5.6用もあり

MySQL NDB Cluster とは無関係のMySQL 5.7の変更点
● InnoDB全般– SQL ノード上で併用する場合は利点あり– ディスク上のテンポラリテーブルが InnoDBになった点はメリットあり
● レプリケーションのサポートされていない機能– GTID– 準同期レプリケーション– マルチスレッドスレーブ– マルチソースレプリケーション
● MySQL NDB Clusterには無い機能– 空間インデックス– フルテキストインデックス

ndbinfoの拡充

ndbinfo とは● MySQL NDB Cluster用の情報取得ツール● ndbinfoスキーマに各種テーブルがある● データノードからメタデータや統計情報を取得

MySQL NDB Cluster 7.5における改良点
● config_params… パラメーターの説明やデフォルト値、データ型などが追加
● config_values… 現在のパラメーターの設定値を格納。● dict_obj_info... 各種データベースオブジェクトの情報。● table_distribution_status...テーブルの LCP状況等● table_fragments... テーブルごとのフラグメントの状態● table_info...テーブルの各種情報● table_replicas... レプリカの状態

バックアップレプリカからの参照

Read from backup replica● これまではプライマリーレプリカのみ R/W可能● プライマリーレプリカを各データノードに分散させることで、負荷も分散
● MySQL NDB Cluster 7.5より、バックアップレプリカからの参照が可能に
– ただしデフォルトではこれまで通りプライマリーのみにアクセス可能
– テーブル作成時に指定した場合のみ

レプリカの動き
Data node 1 Data node 2
Primary
Secondary Primary
Secondaryデータ同期
データ同期
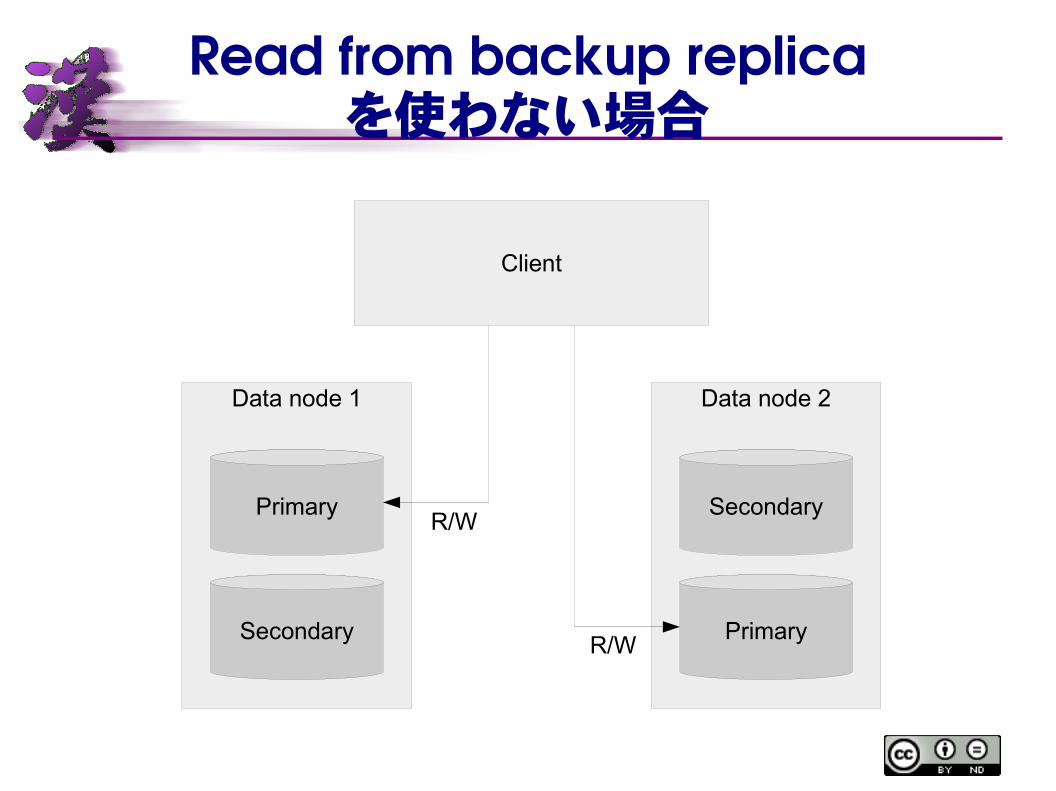
Read from backup replicaを使わない場合
Data node 1 Data node 2
Primary
Secondary Primary
Secondary
Client
R/W
R/W

Read from backup replicaを使った場合
Data node 1 Data node 2
Primary
Secondary Primary
Secondary
Client
R/W
R/W
R
R

全データノードへのレプリカ

通常のテーブルの場合
ノードグループ 1 ノードグループ 2
Data node 1
Data node 2
Data node 3
Data node 4
F1primary
F3backup
F1backup
F3primary
F2backup
F4primary
F2primary
F4backup
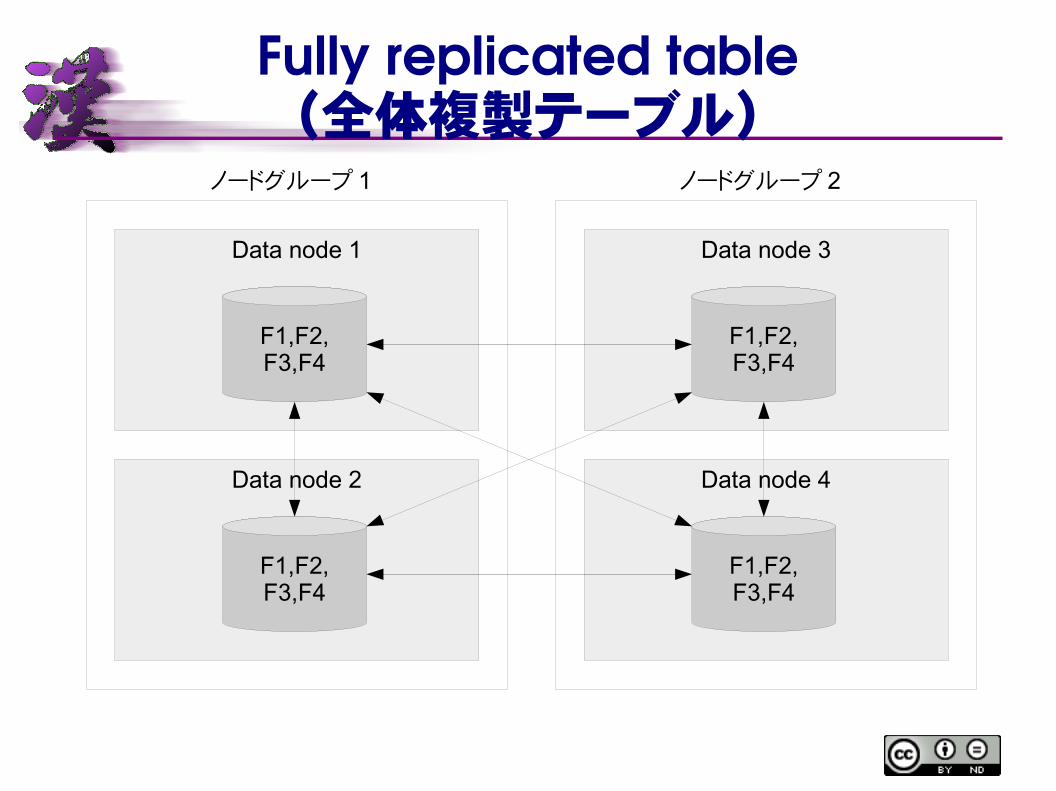
Fully replicated table(全体複製テーブル)
ノードグループ 1 ノードグループ 2
Data node 1
Data node 2
Data node 3
Data node 4
F1,F2,F3,F4
F1,F2,F3,F4
F1,F2,F3,F4
F1,F2,F3,F4

テーブルサイズの制限の改善

テーブルサイズの制限
● MySQL NDB Cluster 7.4 まで– FIXED フォーマット部分はフラグメントあたり 16GB まで– フラグメント数はデータノード数と同じ
● MySQL NDB Cluster 7.5– FIXED フォーマット部分のデータサイズは 128TB まで– ただしデータノードごとのDataMemoryの上限が 1TB
● データノードは 48 ノードなので、実質的な上限は 48TB● レプリカ数2なら 24TB

ndb_restoreコマンドのSQL出力

ndb_restore コマンドのSQL出力
● ndb_restoreは、ネイティブバックアップをリストアするツール
– データノードへクライアントとして接続してリストア– バックアップはメタデータ、データ、ログから構成される– データ部分をCSVで、ログをテキストで出力する機能があった
● MySQL NDB Cluster 7.5において、ログの出力が SQL対応
– InnoDBなど、他のストレージエンジンへのデータ移行に– InnoDBへのレプリケーションのセットアップ

MySQL Cluster7.6DMRの紹介

MySQL Cluster 7.6 DRM登場● MySQL Cluster 7.6 Development Milestone
Release とは?– Release Candidateになる前のバージョン– 機能の追加・削除が予告なく変更される場合有り
● 準備が整った機能から順番に統合される– キャンセルされる場合もあり
● MySQL Cluster 7.6.3 dmr– 2017年 7月 5日リリース
● 正式版ではありません!– https://lists.mysql.com/announce/1185

MySQL NDB Cluster 7.6の(予定された)新機能概要
● ディスク型テーブルの新フォーマット● メモリ割り当て設定の改善● ndbinfoの拡充● CSVデータのインポートツール● 新しいモニタリングツール● LCPのスループット安定化● SPJの改良● システム名の指定

ディスク型テーブルの新フォーマット

ディスク型テーブルの新フォーマット
● ページチェックサムの追加● CREATE TABLE SCHEMA VERSION IDの導入
– DROP/CREATE により、 Table IDが再利用されてしまう– 同じ Table IDを持ったエクステントがCREATE後のテーブルのものだと誤って判定されてしまう
● イニシャルローリングリスタートにより新しいフォーマットへ変更
– 古いフォーマットを持つバージョンにはダウングレードできない

メモリ割り当て設定の改善

IndexMemoryの廃止● DataMemoryから動的に割り当て
– 必要な分だけが割り当てられるように– 無駄がない– 設定がちょっとだけシンプルに
● DataMemoryだけサイジングすればOK

DataMemoryからSharedGlobalMemoryへ
● メモリ割り当て先の変更● DataMemory
– データの格納に関する部分に特化● SharedGlobalMemory
– トランザクション処理に関するメモリはこちらから割り当て– 以前より多く必要になるかも
● 変更されたものの例– レプリケーション用イベントバッファ– ファイルの初期化処理用バッファ– オフラインのインデックス作成用バッファ
etc
storage/ndb/src/kernel/blocks/record_types.hpp

ndbinfoの拡充

ndbinfoに2つのテーブルが追加● config_nodes
– config.ini内で定義されたノードの一覧● processes
– 現在接続中のプロセス(ノード)一覧
ndb_mgm -e SHOWの代わりに使うと便利

CSVデータのインポートツールndb_import

ndb_import● LOAD DATA INFILEのようにCSVデータをテーブルに取り込むツール
● データノードへ直接接続– 高速!– API ノードのひとつとして動作– データノードへの接続数、接続あたりのスレッド数を指定可能
ndb_import -c connectstring db_name table_name.csv

モニタリングツールndb_top
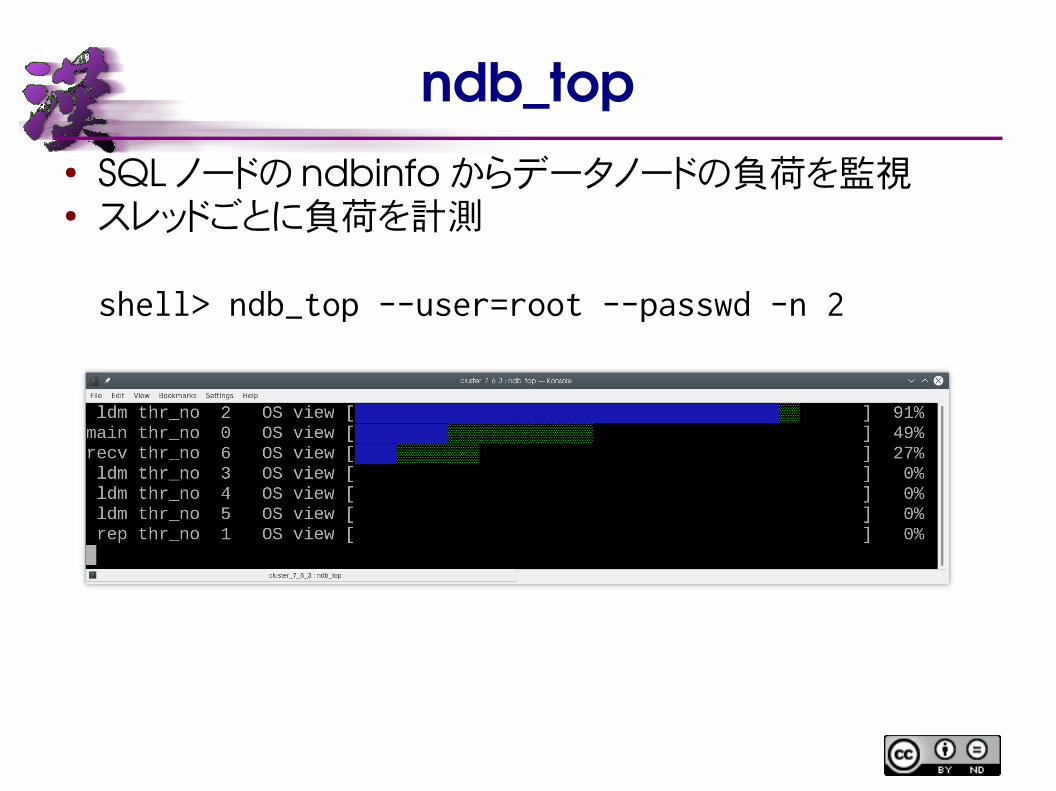
ndb_top● SQL ノードの ndbinfoからデータノードの負荷を監視● スレッドごとに負荷を計測
shell> ndb_top --user=root --passwd -n 2

LCPのスループット安定化

LCP とは● Local checkpointの略● データノードは定期的にDataMemory上のデータを、ファイルへ書き出している
– 全体を順次スキャン– 2世代分のデータがファイルに保存– かなりの I/Oが発生する
● GCP (Global checkpoint )とセットでデータを復元– GCP = Redo logging

LCPのスループット安定化● LCPは I/Oが遅いと自動的にスループットを調整する機能がある
● 7.5までのバージョンでは、 LDMスレッドごとに I/O遅延をモニタリングし、スループットを調整していた
– 他の LDMスレッドはスループットを調整しないかも知れない
– LDM = Local Data Manager● 7.6では I/O遅延のモニタリングをデータノード全体で統一して行うようになった
– より正確にサーバー全体の I/Oの状況を反映するようになった。

SPJの改良

SPJ とは● Select-Project-Joinの略
– 別名 Pushdown Join● データノード上で JOINを実行し、結果を SQL ノードへ返す
– 非常に高速!– データノード・ SQL ノード間のラウンドトリップを省略– 複数のデータノード上で JOINを並列実行

Pushdown Joinが効率化● DBSPJカーネルブロックのシグナル周りの改良
– 余分なシグナルが送信されないように– シグナルフォーマットをコンパクトに
● ロードバランスの改善– LDMスレッド数が、 TCスレッド数で割り切れない場合、DBSPJの負荷に偏りが生じていた
– その場合、DBSPJブロックをラウンドロビンで使うようにすることで、スレッドごとの負荷を平坦化

システム名の指定が可能に

システム名とは
● クラスタを識別するためのタグのようなもの● config.ini内で指定
[System]Name = system_name
● SHOW GLOBAL STATUS LIKE ‘Ndb_system_name’ で参照

まとめ

MySQL “NDB” Clusterは着々と進化中!!
● MySQL NDB Cluster 7.5 、 7.6DMRで着実な進化– 派手な変更は無いが、役立つ新機能が多数
● 機能面– MySQL 5.7 との統合により充実– ndb_top 、 ndb_import などの新しいツール
● 性能面– オプティマイザの改善により、 SQL実行が高速化– LCPスループットの安定– バックアップレプリカらからの参照– DBSPJの改良
● 運用面– ndbinfoによる監視の充実– システム名による識別

宣伝:書籍が出ます!Pro MySQL NDB Cluster
● Pro MySQL NDB Cluster / Apress Media– MySQL NDB Cluster 7.5の解説書– 同僚の Jesper との共著– 英語です。– お値段は $49.99

Q&Aご静聴ありがとうございました。

宣伝:サポートエンジニア募集中!!
● MySQLサポートチームで一緒に働いてみませんか?!● 技術力が物を言うポジションです!
– 技術力に自信のある方、技術を磨きたい方歓迎– L1から L3までの問い合わせをすべて受け持ち
● クエリのチューニングなども行います● オープンソースなのでソースコード見放題!!
– 英語より技術力重視● 普段の業務は日本語オンリーです。● 日本の顧客がターゲットです。
● 上司は海外– やりとりは英語のみ– TOEIC 700程度が目安
● 在宅勤務可能