numpy scipyで独立成分分析
DESCRIPTION
TRANSCRIPT

Numpy/Scipyで独立成分分析
2011年8月28日第1回Tokyo.Scipy
@sfchaos

1
目次
1. 自己紹介
2. 独立成分分析
3. Numpy/Scipyを用いた実装
4. まとめ

2
目次
1. 自己紹介
2. 独立成分分析
3. Numpy/Scipyを用いた実装
4. まとめ

3
1.1 プロフィール
� TwitterID: @sfchaos
� 職業:コンサルタント� 金融工学のモデル構築・データ解析
� 最近,大規模データ解析の企画に着手
(Hadoop, Mahout, CEP等)

4
1.2 RとPythonと私
� R歴:4年
� 「Rパッケージガイドブック」(東京図書,2011年4月)執筆.� bigmemoryパッケージ(大規模データの管理・分析)
� RTisean/tseriesChaosパッケージ(非線形(カオス)時系列解析)
� Tokyo.R 翻訳プロジェクト Wiki� Tokyo.Rの方々と各種マニュアルの翻訳

5
� Python歴:薄く1年(Numpy/Scipy歴1ヶ月)
� Rでは大規模データの扱いが大変なので,代替となる手段がないか模索中→ PythonでのHPCに興味があります.
� 今回は,Numpy/Scipyの勉強のために発表させていただきます(独立成分分析自体も初心者).

6
目次
1. 自己紹介
2. 独立成分分析
3. Numpy/Scipyを用いた実装
4. まとめ

7
2.1 独立成分分析の概要
� 未知音源分離問題(Blind Source Separation, BSS). 観測信号から元の信号の成分を取り出す問題.カクテ
ルパーティー効果など.� 脳磁波の解析,音声処理などで使用されている(らし
い).
原信号1
原信号N
観測信号1
観測信号N
原信号i 観測信号i
独立成分分析では,観測信号のみから原信号を推定
重ね合わせ

8
無相関
2.2 無相関性と独立性
� 日常用語では無相関も独立も同じ意味で使われることが多い
� しかし,両者の数学的な定義は異なり,独立⊆無相関
独立
確率変数 x1と x2 が無相関
][][][ 2121 xxxxEEEExxxxEEEExxxxxxxxEEEE =
確率変数 x1と x2 が独立
)()(),( 2211212,1 xpxpxxp =

9
� 原信号がそれぞれ正規分布に従う場合は,「無相関=独立」となり,主成分分析を行えば元信号を取り出せる.
� 主成分分析は,各主成分が正規分布に従うと仮定しており,正規分布に従う変数を線形結合した変数も正規分布に従うことに注意(PRML 第12章,2章).
10
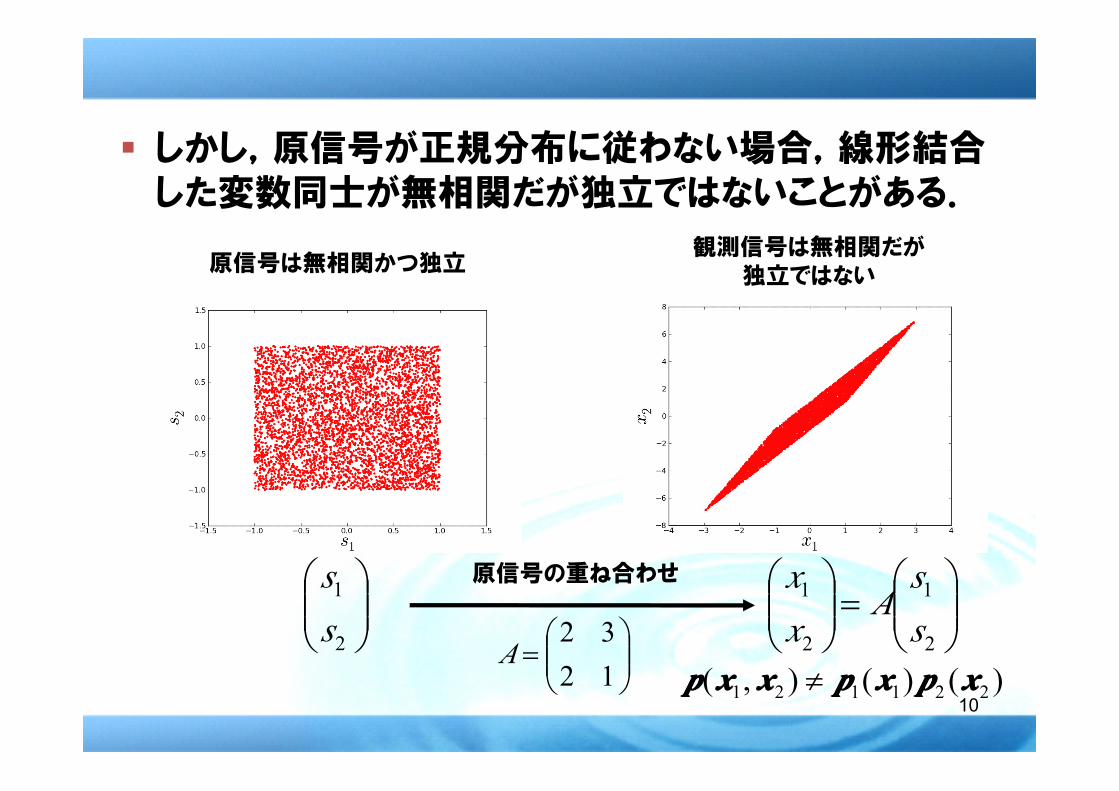
� しかし,原信号が正規分布に従わない場合,線形結合した変数同士が無相関だが独立ではないことがある.
⎟⎟⎠
⎞⎜⎜⎝
⎛
2
1
ss
⎟⎟⎠
⎞⎜⎜⎝
⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛
2
1
2
1
ss
Axx
⎟⎟⎠
⎞⎜⎜⎝
⎛=
1232
A
原信号の重ね合わせ
原信号は無相関かつ独立観測信号は無相関だが
独立ではない
)()(),( 221121 xxxxppppxxxxppppxxxxxxxxpppp ≠
11

12
� このような場合,主成分分析を行っても無相関ではあるが独立ではない原信号が得られてしまう.
無相関だが独立ではない

13
� このような観測信号から,独立な原信号の成分を抽出することが独立成分分析の目的.
観測信号 原信号
⎟⎟⎠
⎞⎜⎜⎝
⎛
2
1
xx
W⎟⎟⎠
⎞⎜⎜⎝
⎛
2
1
xx
W
独立

14
2.3 独立成分の抽出
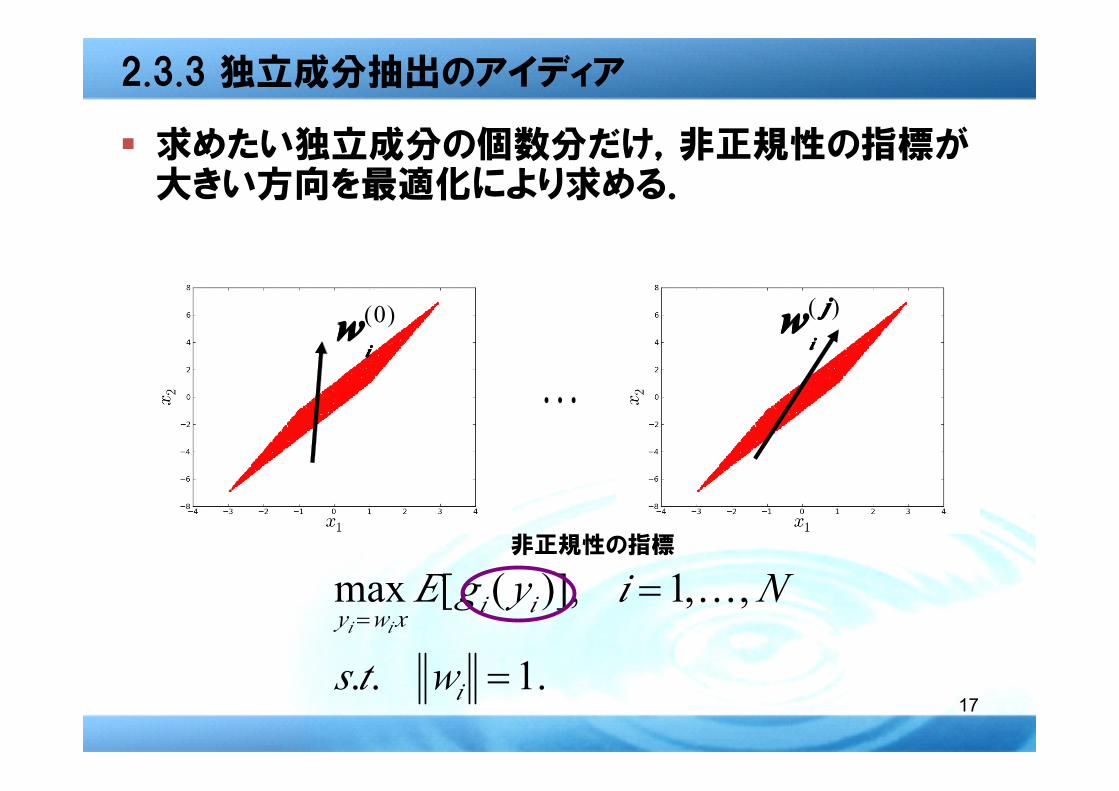
� 目標:この2つの方向を取り出すこと
� 目で見れば一目瞭然だが,機械的に抽出したい
観測信号

15
2.3.1 独立性
� 独立な方向を特徴付ける指標を定義したい.� 実は,分布の非正規性を最大化することが独立成分を
求めることと等価であることが分かっている(きちんとした議論は「詳解独立成分分析」を参照).
� 非正規性を特徴付ける指標はいろいろある.
概要
尖度(の絶対値) � 4次のモーメント
� 正規分布では3次以上のキュムラントはゼロであり,尖度が大きいほど正規分布から離れていることになる
ネゲントロピー � 正規分布は平均と分散が一定の分布の中で最も情報量が大きい(ランダムである)ことに着目
� 正規分布と対象とする分布の情報量の差をネゲントロピーとして定義
� ネゲントロピーが大きい分布ほど正規分布から離れていることになる
他にも,相互情報量などがある.

16
� 尖度(4次のモーメント)
{ } { } { }42232244 ][6][][12][][4][3][)( xExExExExExExEx −+−−=κ
� ネゲントロピー
∫−=−=
yypypyH
yHyHyJ gauss
d)(log)()(
),()()(
ネゲントロピーを計算するためには確率密度関数を近似する必要があるので,後ほど近似関数を導入する.
)(yp :分布の確率密度関数
17
2.3.3 独立成分抽出のアイディア
� 求めたい独立成分の個数分だけ,非正規性の指標が大きい方向を最適化により求める.
.1..
,,1)],([max
=
==
i
iixwy
wts
NiygEii
…
)0(iiii
wwww )( jjjjiiii
wwww
・・・
非正規性の指標

18
� これは,観測信号に対して任意の線形変換を行い,独立な成分を探すという問題であり,自由度が大きいため大変.
?

19
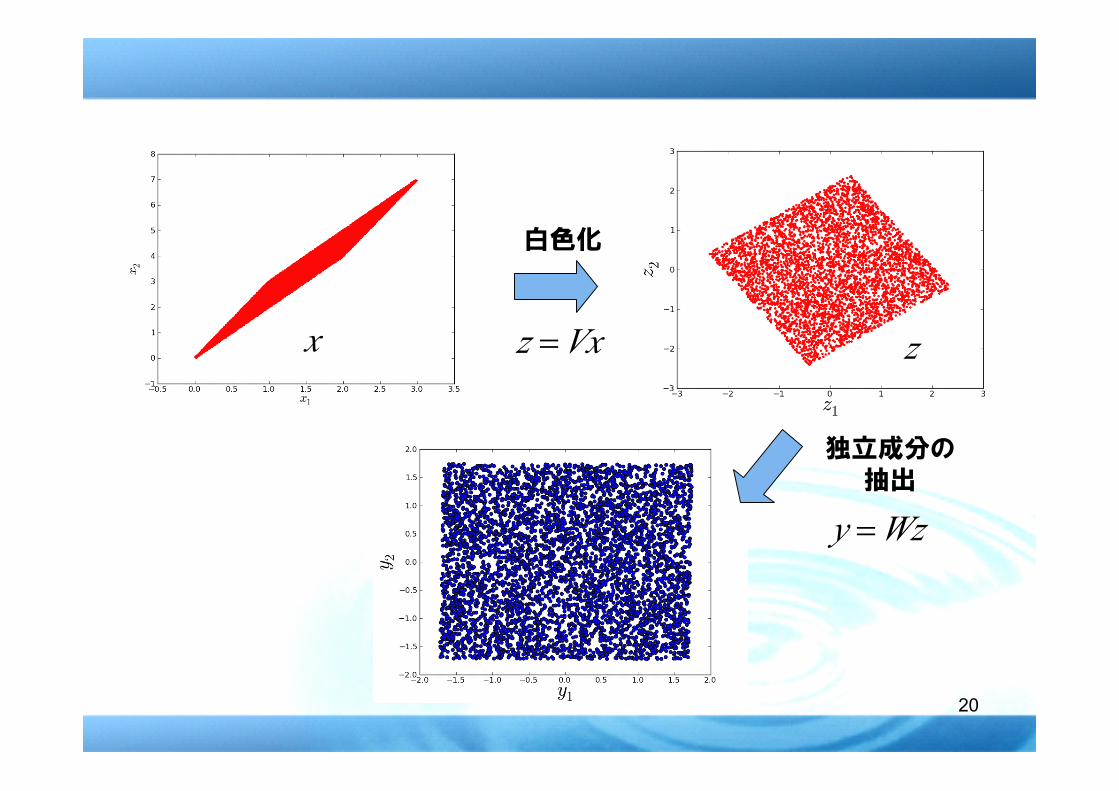
� そこで,独立⊆無相関という関係に着目する.
� 観測信号を無相関にしておけば,独立な成分を探索するためには直交変換だけを対象とすればO.K.
� 主成分分析を用いて,観測信号を直交する成分に変換しておく(白色化,whitening, sphering)
白色化
Vxz =
20
白色化
Vxz =x
Wzy =
z
独立成分の抽出

21
2.4 FastICAアルゴリズム
� 収束が速い(3次収束).� 最適化手法としてNewton法を使用.� 独立性の指標は,ネゲントロピーを使用.
.1..
,,1)],([max
=
==
iiii
iiiiiiiixxxxwwwwyyyy
wwwwttttssss
NNNNiiiiyyyyggggEEEEiiiiiiii
….max
2)]([ =+ iiii
TTTTiiiiiiiiiiii wwwwwwwwyyyyggggEEEE λ

22
上式を微分すると,次の方程式の解を求める問題に帰着する.
.max2
)]([ =+ iiiiTTTTiiiiiiiiiiii wwwwwwwwyyyyggggEEEE λ
.0)]([)( =+= iiiiiiiiiiiiiiiiiiii wwwwyyyyggggxxxxEEEExxxxffff λ
))('())((
))('())((
)('/)(
)()()(
)(
)()()(
)()1(
iiiiTTTTkkkk
iiiikkkkiiii
kkkkiiiiiiii
iiiiTTTTkkkk
iiii
kkkkiiii
kkkkiiiiiiiikkkk
iiii
iiiiiiiikkkkiiii
kkkkiiii
zzzzwwwwggggEEEEwwwwwwwwggggzzzzEEEE
zzzzwwwwggggEEEEwwwwwwwwggggzzzzEEEEwwww
zzzzffffzzzzffffwwwwwwww
−∝
+
+−=
−=+
λ
λ
Newton法を用いて,重みベクトルを求める.
,)(),2/exp()(),tanh()( 33
221 yygyyygayyg =−==
ネゲントロピーは,以下の式で近似することが多い.

23
FastICA
p : 推定する独立成分の個数, m :独立成分のカウンタ(初期値=1)
1.(中心化) データを中心が原点になるように変換する:
2.(白色化) を白色化(主成分分析)して,データ点 を得る:
3. 各独立成分に対するの射影方向 の初期値をランダムに与える.
m=1, 2, ・・・, p に対して以下を行う.
4. 次式に従って を更新する:
5. 次式に従ってを正規直交化する:
6. が収束していない場合は,step.4に戻る.
7. mを1つインクリメントし,の場合はstep.4に戻る.
∑=
−=nnnn
jjjjjjjjiiiiiiii xxxx
nnnnxxxxxxxx
1
' 1
'iiiixxxx
'iiiizzzz
])('[])([ iiiiTTTTpppppppp
TTTTppppiiiipppp zzzzwwwwggggEEEEwwwwwwwwggggzzzzEEEEwwww −←
ppppwwww
ppppwwww
∑
∑−
=
−
=
−
−←
1
1
1
1
)(
)(
pppp
jjjjjjjjpppp
TTTTjjjjpppp
pppp
jjjjjjjjpppp
TTTTjjjjpppp
pppp
wwwwwwwwwwwwwwww
wwwwwwwwwwwwwwwwwwww
ppppwwww

24
目次
1. 自己紹介
2. 独立成分分析
3. Numpy/Scipyを用いた実装
4. まとめ

25
3. Numpy/Scipyを用いた実装
� Pythonには,MDPやscikitsなど独立成分分析を行うパッケージが既にある.
� ここでは,Numpy/Scipyを用いてFastICAアルゴリズムを実装する.

26
3.1 使用するNumpy/Scipyの機能・関数
機能 関数
特異値分解
(主成分分析の中で使用)linalg.svd関数(Numpy linglg)
ベクトルの正規化 linalg.norm関数(Numpy )
乱数生成 random.normal関数(Numpy)
行列演算
乱数生成
� numpy.arrayオブジェクト等を使用して,行列演算,乱数生成等にNumpy, Scipyを使用する.
27
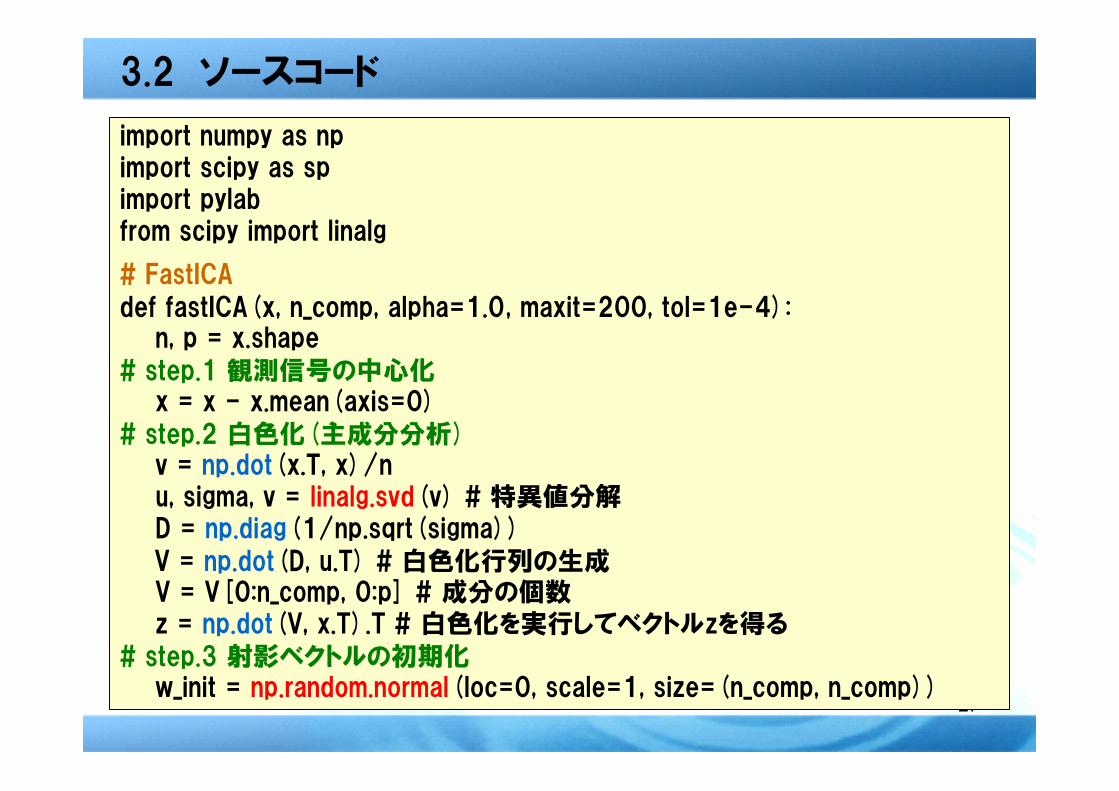
3.2 ソースコード
import numpy as npimport scipy as spimport pylabfrom scipy import linalg
# FastICA
def fastICA(x, n_comp, alpha=1.0, maxit=200, tol=1e-4):n, p = x.shape
# step.1 観測信号の中心化x = x - x.mean(axis=0)
# step.2 白色化(主成分分析)v = np.dot(x.T, x)/nu, sigma, v = linalg.svd(v) # 特異値分解D = np.diag(1/np.sqrt(sigma))
V = np.dot(D, u.T) # 白色化行列の生成V = V[0:n_comp, 0:p] # 成分の個数z = np.dot(V, x.T).T # 白色化を実行してベクトルzを得る
# step.3 射影ベクトルの初期化w_init = np.random.normal(loc=0, scale=1, size=(n_comp, n_comp))

28
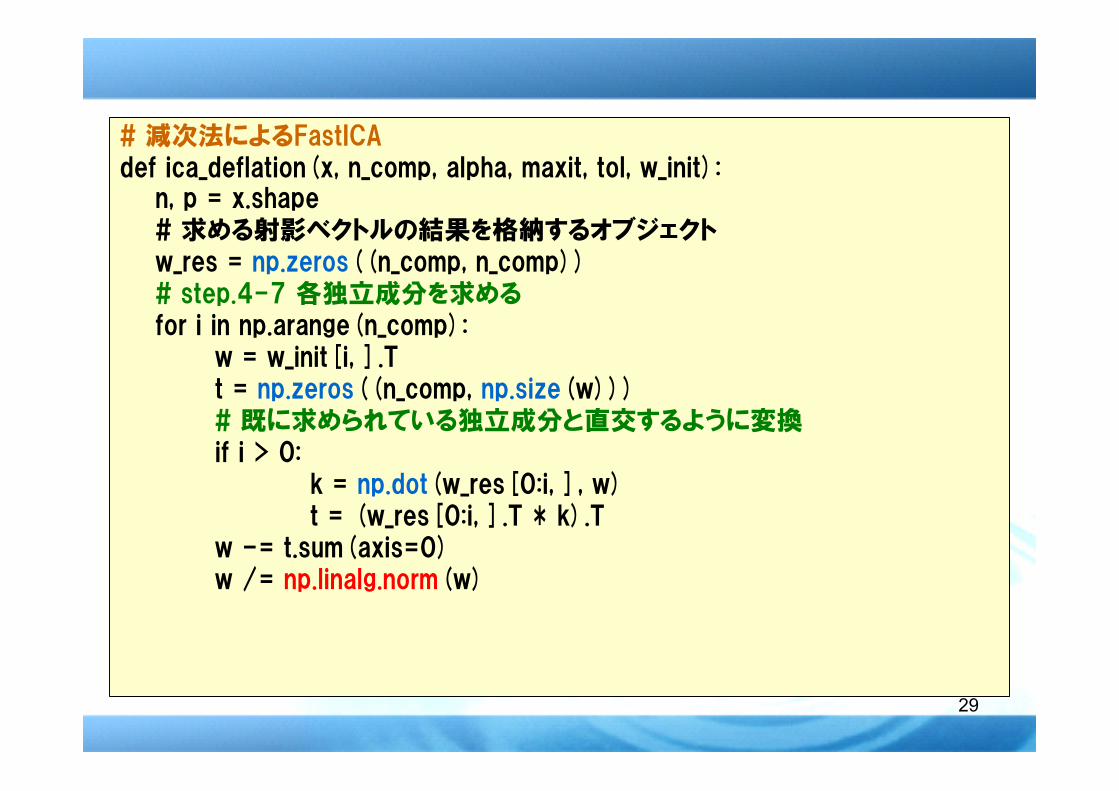
# step.4-7 減次法によるFastICAの実行
w = ica_deflation(z, n_comp, alpha, maxit, tol, w_init)
# 復元信号
s = np.dot(w, z.T).T
pylab.scatter(s[:, 0], s[:, 1])
pylab.xlabel("$y_{1}$", fontsize=30)
pylab.ylabel("$y_{2}$", fontsize=30)
pylab.savefig("../output/scatter_estimated_sources.png")
pylab.show()
pylab.close()
return s
29
# 減次法によるFastICAdef ica_deflation(x, n_comp, alpha, maxit, tol, w_init):
n, p = x.shape# 求める射影ベクトルの結果を格納するオブジェクトw_res = np.zeros((n_comp, n_comp))# step.4-7 各独立成分を求めるfor i in np.arange(n_comp):
w = w_init[i, ].Tt = np.zeros((n_comp, np.size(w)))# 既に求められている独立成分と直交するように変換if i > 0:
k = np.dot(w_res[0:i, ], w)t = (w_res[0:i, ].T * k).T
w -= t.sum(axis=0)w /= np.linalg.norm(w)

30
# 誤差,反復回数カウンタの初期化lim = np.repeat(1000.0, maxit); it = 0# 独立成分の探索while lim[it] > tol and it < maxit:
# step.4 wpの更新wx = np.dot(x, w)gwx = np.tanh(alpha * wx)gwx = np.repeat(gwx, n_comp).reshape(np.size(gwx), n_comp)xgwx = x * gwx v1 = xgwx.mean(axis=0)g_wx = alpha * (1 - (np.tanh(alpha * wx))**2)v2 = np.dot(np.mean(g_wx), w)w1 = v1 - v2it += 1t = np.zeros((n_comp, np.size(w)))# step.5 Gram-Schmidtの正規直交化if i > 0:
k = np.dot(w_res[0:i, ], w1)t = (w_res[0:i, ].T * k).T
w1 -= t.sum(axis=0); w1 /= np.linalg.norm(w1)# step.6 収束判定lim[it] = abs(abs(sum(w1 * w)) - 1.0)w = w1
w_res[i, ] = wreturn w_res

31
3.3 独立成分の方向への収束の確認
w1(4回で収束)
①
④
w2(正規直交化するため,
1回で収束する)
②③
32
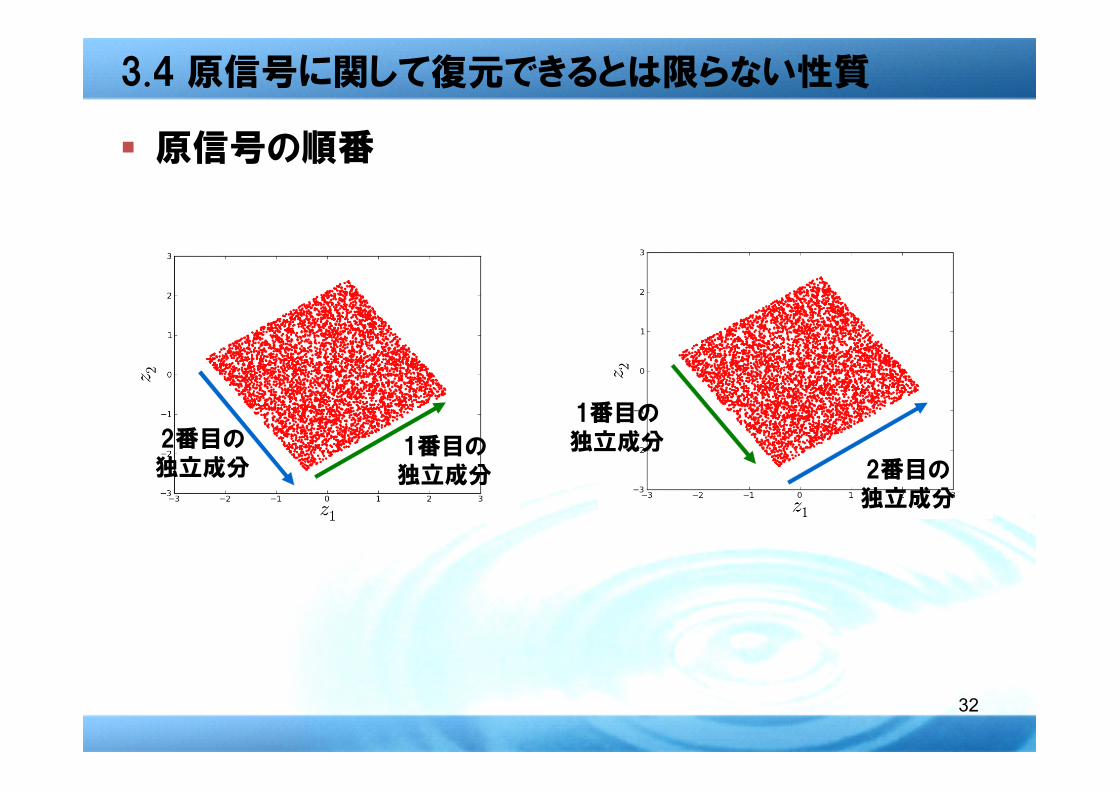
3.4 原信号に関して復元できるとは限らない性質
� 原信号の順番
1番目の独立成分
2番目の独立成分 2番目の
独立成分
1番目の独立成分

33
� 原信号の符号と強度� 正負が逆転する可能性がある.� 射影ベクトルを単位ベクトルとしているため,波形は原信号と
相似形のものが得られ,強度は復元されない可能性がある.
1番目の独立成分
2番目の独立成分
1番目の独立成分
2番目の独立成分
1番目の独立成分
2番目の独立成分
1番目の独立成分
2番目の独立成分

34
目次
1. 自己紹介
2. 独立成分分析
3. Numpy/Scipyを用いた実装
4. まとめ

35
4. まとめ
� 独立成分分析は,観測された信号から独立な原信号の成分を抽出するための多変量解析手法.
� 代表的なアルゴリズムであるFastICAをNumpy/Scipyを使って実装した.
� Rに比べてNumpy/Scipyが勝っている点は・・・
→ これを見つけることが今後の課題

36
参考文献
� 「詳解 独立成分分析」
� 朱鷺の杜 Numpy
� NumPy for R (and S-Plus) users
RユーザがPythonの該当関数を調べるのに便利.
http://mathesaurus.sourceforge.net/r-numpy.html

37
ご清聴ありがとうございました