오픈소스 검색엔진을 활용한 데이터 분석logstash elasticsearch kibana x-pack custom...
TRANSCRIPT

Elastic Stack을 이용한 데이터 분석
오픈소스 검색엔진을 활용한 데이터 분석
김종민
Tech Evangelist @Elastic
2017.10.26

Elastic?

Elastic?
• Elasticsearch 라는 검색엔진을 개발한 회사입니다. – (ELK Stack 으로 더 잘 알려져 있습니다.)
• 검색엔진은 우리 주변 여기저기에 있습니다.
• 요즘은 검색엔진이 데이터 분석에도 쓰입니다.

Elastic Stack 100% open source

Elasticsearch Heart of the Elastic Stack
Distributed, Scalable High-availability Multi-tenancy
Developer Friendly Real-time, Full-text Search Aggregations

Kibana
Visualize and analyze Geospatial Customize and
Share Reports
Graph Exploration UX to secure and manage the Elastic Stack
Build Custom Apps

Beats
Ship data from the source Ship and centralize
in Elasticsearch Ship to Logstash for transf
ormation and parsing
Ship to Elastic Cloud Libbeat: API framework to build custom beats
30+ community Beats

Logstash
Ingest data of all shapes, sizes, and sources
Parse and dynamically
transform data
Transport data
to any output
Secure and encrypt data inputs
Build your own pipeline More than 200+ plugins
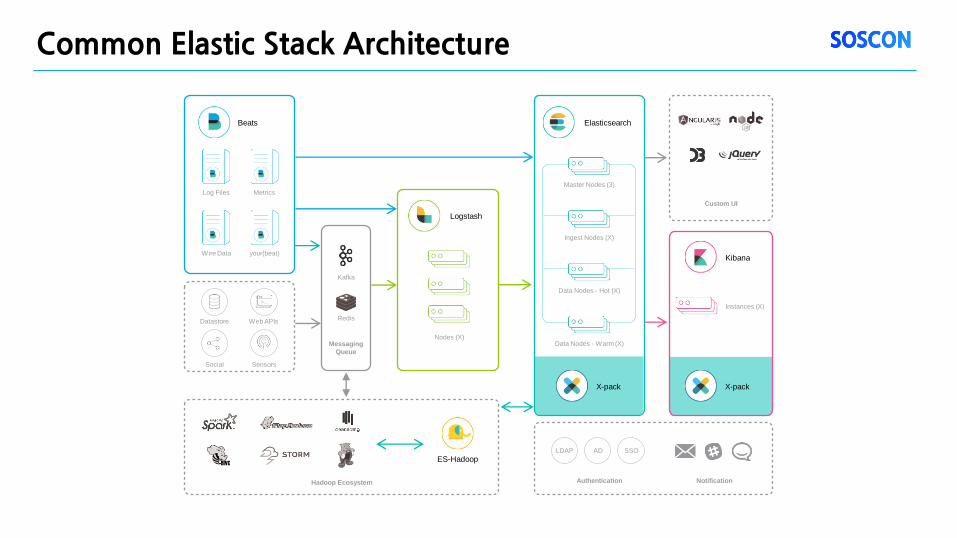
Common Elastic Stack Architecture
Beats
Log Files Metrics
Wire Data your(beat)
Datastore
Social
Web APIs
Sensors
Kafka
Redis
Messaging
Queue
Nodes (X)
Hadoop Ecosystem
Logstash
Elasticsearch
Kibana
X-pack
Custom UI
Authentication Notification
X-pack
ES-Hadoop LDAP AD SSO
Instances (X)
Master Nodes (3)
Ingest Nodes (X)
Data Nodes - Hot (X)
Data Nodes - Warm (X)

아파치 루씬 (Apache Lucene)
• Created by - Doug Cutting • Written in – Java • Apache Solr, Elasticsearch

열을 기준으로 인덱스를 만듭니다. 책의 맨 앞에 있는 제목 리스트와 같습니다.
RDBMS 에서는 데이터를 테이블 형태로 저장합니다.
DOC TEXT
1 The quick brown fox jumps over the lazy dog
2 Fast jumping rabbits
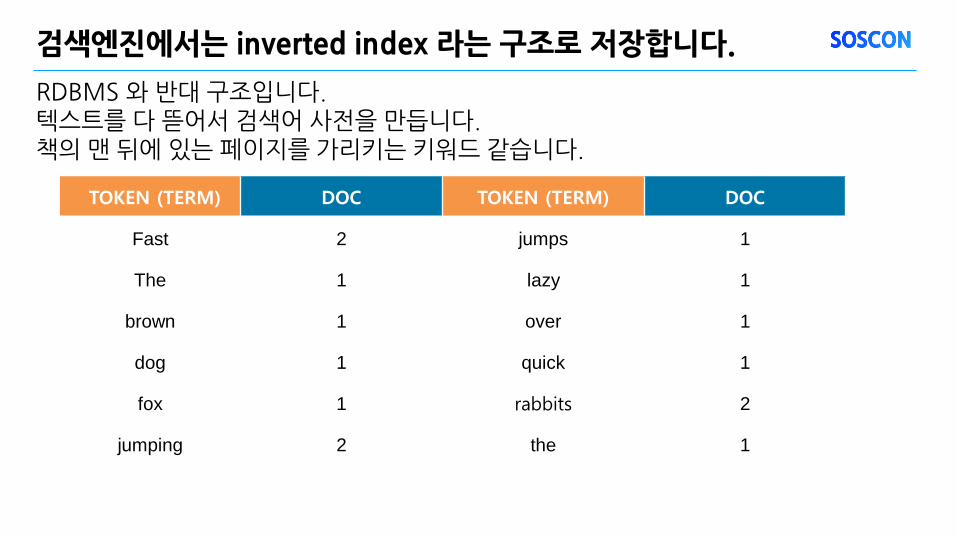
RDBMS 와 반대 구조입니다. 텍스트를 다 뜯어서 검색어 사전을 만듭니다. 책의 맨 뒤에 있는 페이지를 가리키는 키워드 같습니다.
검색엔진에서는 inverted index 라는 구조로 저장합니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
Fast 2 jumps 1
The 1 lazy 1
brown 1 over 1
dog 1 quick 1
fox 1 rabbits 2
jumping 2 the 1

TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazi 1
dog 1 over 1
fast 1 , 2 quick 1 , 2
fox 1 rabbit 2
jump 1 , 2
텍스트를 저장할 때 몇가지 처리 과정을 거칩니다.
실제로는 이렇게 저장됩니다.

대소문자를 변환합니다.
텍스트 처리
TOKEN (TERM) DOC TOKEN (TERM) DOC
Fast fast 2 jumps 1
The the 1 lazy 1
brown 1 over 1
dog 1 quick 1
fox 1 rabbits 2
jumping 2 the 1

토큰을 (보통 ascii 순서로) 재 정렬합니다.
텍스트 처리
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazy 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbits 2
jumping 2 the 1
jumps 1 the 1

불용어(stopwords, 검색어로서의 가치가 없는 단어들) 를 제거합니다. a, an, are, at, be, but, by, do, for, i, no, the, to … 등등
텍스트 처리
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazy 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbits 2
jumping 2 the 1
jumps 1 the 1
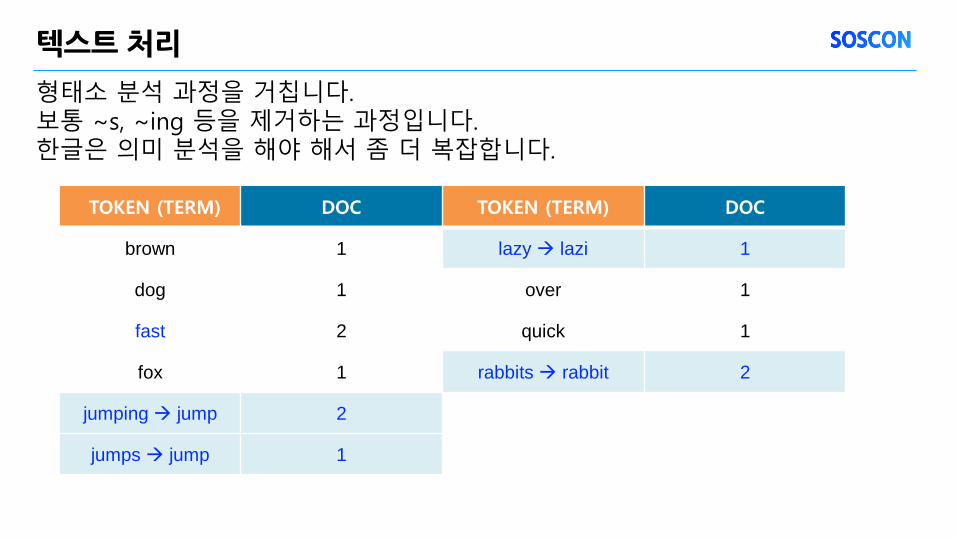
형태소 분석 과정을 거칩니다. 보통 ~s, ~ing 등을 제거하는 과정입니다. 한글은 의미 분석을 해야 해서 좀 더 복잡합니다.
텍스트 처리
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazy lazi 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbits rabbit 2
jumping jump 2
jumps jump 1
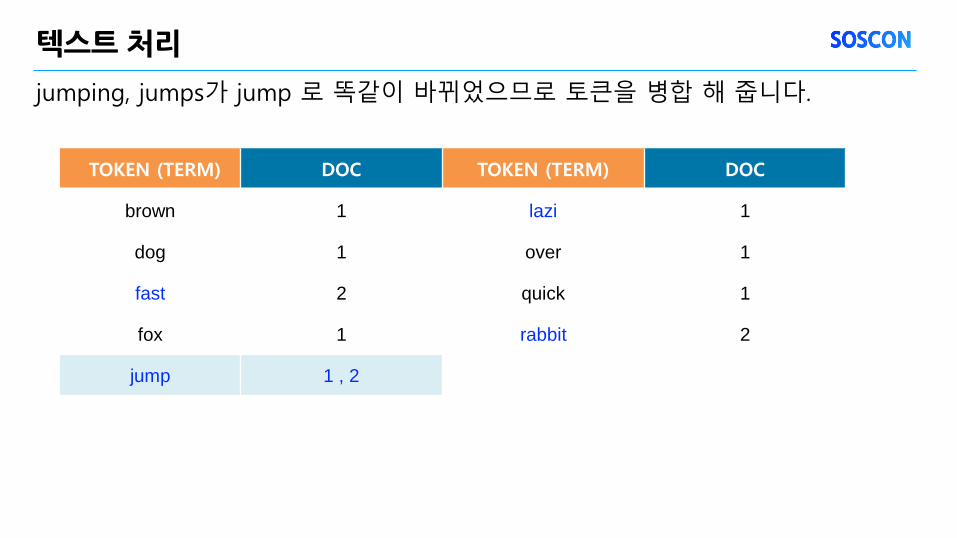
jumping, jumps가 jump 로 똑같이 바뀌었으므로 토큰을 병합 해 줍니다.
텍스트 처리
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazi 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbit 2
jump 1 , 2

동의어를 처리합니다.
텍스트 처리
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazi 1
dog 1 over 1
fast 1 , 2 quick 1 , 2
fox 1 rabbit 2
jump 1 , 2
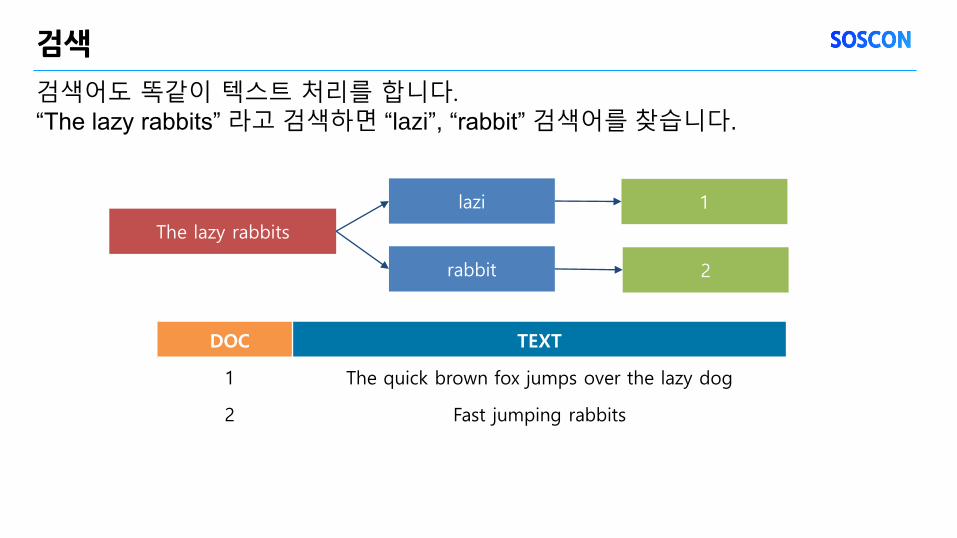
검색어도 똑같이 텍스트 처리를 합니다. “The lazy rabbits” 라고 검색하면 “lazi”, “rabbit” 검색어를 찾습니다.
검색
The lazy rabbits
lazi
rabbit
1
DOC TEXT
1 The quick brown fox jumps over the lazy dog
2 Fast jumping rabbits
2

검색엔진과 RDBMS 비교
RDBMS 검색엔진
데이터 저장 방식 정규화 역정규화
전문(Full Text) 검색 속도 느림 빠름
의미 검색 불가능 가능
Join 가능 불가능
수정 / 삭제 빠름 느림
RDBMS 는 쿼리 시점, 검색엔진은 색인 시점이 중요합니다.

Elasticsearch 클러스터링
1 0 2
3 4
노드 (Node)
Elasticsearch 실행 프로세스
샤드 (Shard)
루씬 검색 쓰레드
Inverted Index는 한번 생성되면 변경이 불가능하기 때문에 Elasticsearch는 클러스터링을 위해 데이터를 샤드라는 단위로 분리해서 저장합니다.

Elasticsearch 클러스터링
노드를 여러개 실행시키면 같은 클러스터로 묶입니다.
1 0 2
3 4
Elasticsearch
클러스터(Cluster)

Elasticsearch 클러스터링
샤드들은 각각의 노드들에 분배되어 저장됩니다.
2 0 1 4 3

Elasticsearch 클러스터링
무결성과 가용성을 위해 샤드의 복제본을 만듭니다. 같은 내용의 복제본과 샤드는 서로 다른 노드에 저장됩니다.
2 0 3 4 1 0 4 1 3 2
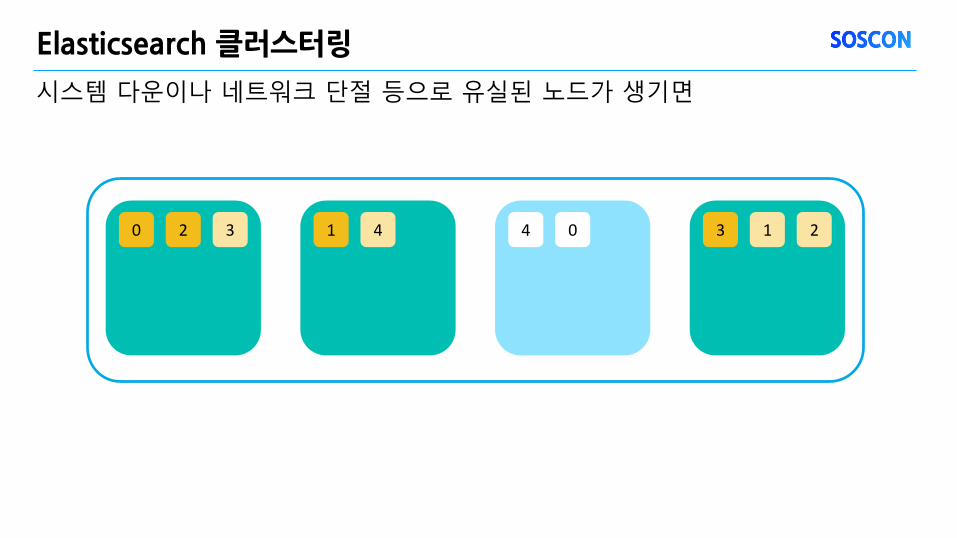
Elasticsearch 클러스터링
시스템 다운이나 네트워크 단절 등으로 유실된 노드가 생기면
2 0 3 4 1 0 4 1 3 2

Elasticsearch 클러스터링
복제본이 사라진 샤드들은 다른 살아있는 노드로 샤드 복제를 시작합니다.
2 0 3 4 1 0 4 1 3 2
4
0

Elasticsearch 클러스터링
노드의 수가 줄어들어도 샤드의 수는 변함 없이 무결성을 유지합니다.
2 0 3 4 1 1 3 2
4
0

Aggregation
Elasticsearch 에서는 검색 뿐 아니라 Aggregation 기능을 이용한 데이터 집계가 가능합니다.
Search
aggregation hits
(docs)

Web Log - 데이터 분석
207.241.237.228 - - [08/Aug/2017:22:22:23 +0000] "GET /blog/tags/defcon HTTP/1.0" 200 24142 "http://www.semicomplete.com/blog/tags/C" "Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot)"

Web Log - 데이터 분석
Logstash를 통해 다음과 같이 파싱이 가능합니다.

Web Log - 데이터 분석
Logstash를 통해 다음과 같이 파싱이 가능합니다.

Web Log - 데이터 분석
다음과 같은 형식의 데이터들의 처리가 가능합니다.
텍스트
위치정보
키워드
숫자

공격에 주로 사용되는 키워드 들의 검색. (admin, wp-admin, php 등)
Web Log - 데이터 검색

접속 오류 데이터들을 검색. (response:404)
Web Log - 데이터 검색

데이터를 복합해서 검색 ("admin" AND response:200)
Web Log - 데이터 검색

Elasticsearch 의 Aggergation 기능을 이용해서 데이터 집계가 가능합니다.
Web Log - 데이터 집계
• 분석된 텍스트 데이터 • 키워드 데이터 • 수치 (Metric) 데이터




Ecommerce Data
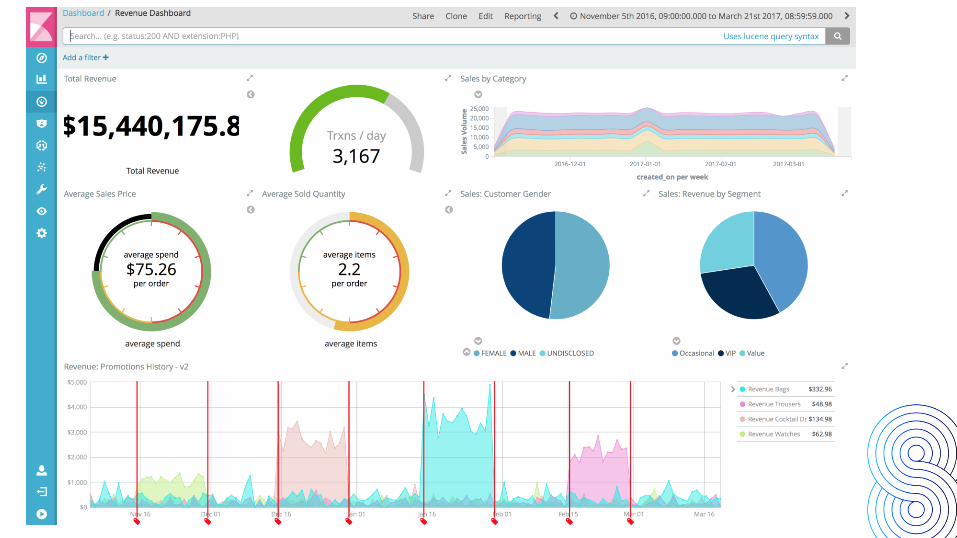




Log : data + timestamp
Elasticsearch + Kibana
• 시계열 데이터를 이용해서 다양한 시각화 도구를 만듭니다. • 시각화 도구를 한눈에 볼 수 있도록 대시보드를 만들고 검색 쿼리와 기간을 활용해서 데이
터 간의 연관성을 파악합니다. • 파악한 연관성을 바탕으로 앞으로의 목적 달성을 위한 근거 자료로 활용합니다.

Copyright ⓒ 2017 SAMSUNG ELECTRONICS. ALL RIGHTS RESERVED
감사합니다 Elastic 부스에서 더 많은 데모들을 시연중이니
많이 들러주세요.