online entity resolution using an oracle (論文紹介)
TRANSCRIPT

Online Entity Resolution Using an OracleDonatella Firmani, Barna Saha, Divesh Srivastava
In VLDB'16
論文紹介
2017/06/29
東京大学 大坂直人
1

論文情報
Online Entity Resolution Using an Oracle. In VLDB'16
① Donatella Firmani (University of Rome Tor Vergata)
② Barna Saha (UMass Amherst)
③ Divesh Srivastava (AT&T Labs Research)
▶ SIGMOD'17 Network Data Analyticsでkeynote
▶ https://sites.google.com/site/networkdataanalytics2017/ の
Repairing Noisy Graphs
ちょっと違う問題を & まだ発展途上っぽそう❔
2

Entity resolution (ER) [Fellegi-Sunter. '69]
▶与えられたレコード集合から同一実体を指すレコード達を特定する古典的問題
A.k.a. record linkage, deduplication
▶重複が生じる原因
場所 (同一場所の別名)、
画像 (同一人物の別写真)、…
3
Kennedy Airport, NY
John F. Kennedy
Memorial Airport
Kennedy Memorial
Airport, WI
John F. Kennedy
Memorial Plaza
John F. Kennedy
International Airport
JFK Airport

Hybrid human-machine approach[Wang-Kraska-Franklin-Feng. VLDB'12]
😢計算機だけだと厳しい 😃プラス人間だと楽勝
▶オラクル=クラウドソーシングと考える
質問「XとYは同一実体を指してます?」
▶目標:オラクル質問回数を抑え、ER完遂
▶課題:良さの指標、ナイスなアルゴリズム、
4
http://stevenwhang.com/QuestionSelectionSlides.pdf (p.5&p.7) より引用

この論文の貢献
オンラインER戦略の指標としてprogressive recallを導入▶ 意味:同一レコードを早く多く特定したいオフラインER戦略の指標=ただのオラクル質問回数
オンラインER戦略のアルゴリズム▶ Progressive recall最大化を目指す
解析の為のグラフモデル&戦略の理論的解析▶ クラスタリングから辺重みを生成するedge noiseモデル既存モデル上の解析は実挙動と隔たり
実験評価▶ 既存手法より良い progressive recall vs. 質問回数
5

▶ラベル有完全グラフ 𝐶 = 𝑉, 𝐸+ ∪ 𝐸−
頂点=レコード、辺=レコード間の関係
+:レコード対は同じ実体
-:レコード対は異なる実体
▶仮定:𝐸+は推移的
▶ (𝑉, 𝐸+)は互いに素なクリーク𝑘個∴ 𝑘つの実体がある
問題定式化
クラスタリングのグラフ表現
6

問題定式化
やりたいこと
7
入力レコード集合𝑉、辺確率𝑝 𝑥, 𝑦
𝑝 𝑥, 𝑦 ≒ Pr 𝑥と𝑦は同じ実体
出力𝑉のクラスタリング
𝐶 = 𝑉, 𝐸+ ∪ 𝐸−
現実的にはレコードの特徴から𝑝を計算
現実的な意味はただの重み
戦略𝑠実行
0.2
0.8

問題定式化
戦略 (1/2)
各辺のラベルを暴いていく
手段1:オラクルに質問
𝐪𝐮𝐞𝐫𝐲 𝑥, 𝑦 says " 𝑥, 𝑦 ∈ 𝐸+" OR " 𝑥, 𝑦 ∈ 𝐸−"
𝑇+・𝑇−:返答が+・-の辺集合
現実のオラクル=クラウドソーシング
▶間違えないと仮定※実際は間違えうるが、既存の解決法が有る
▶質問回数は少ないと良い※自明には 𝑉
2回 …多すぎ
8
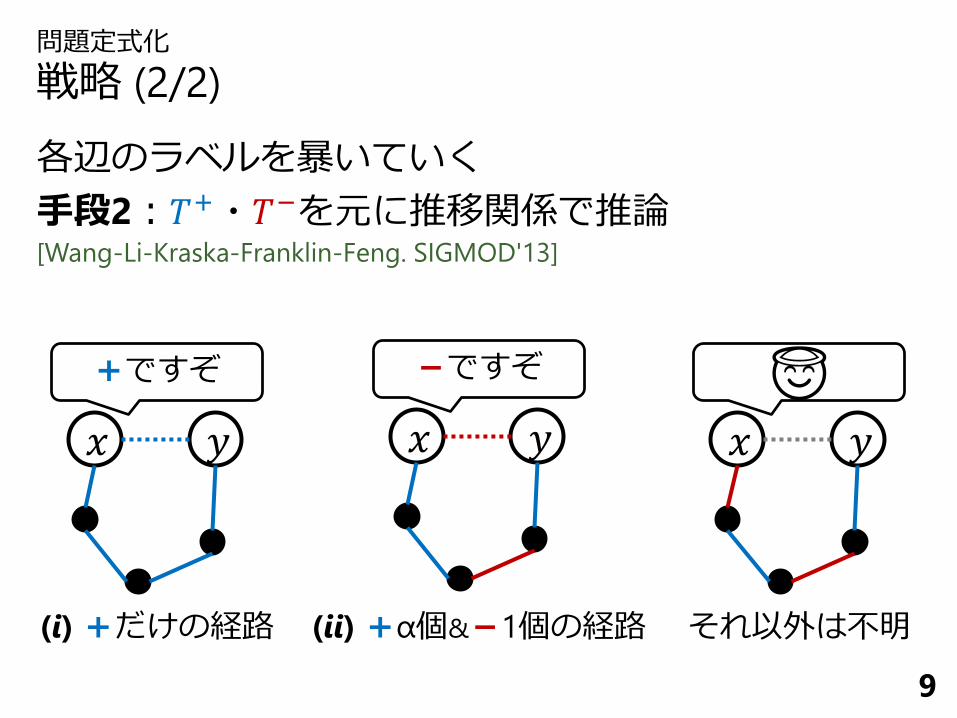
問題定式化
戦略 (2/2)
各辺のラベルを暴いていく
手段2:𝑇+・𝑇−を元に推移関係で推論[Wang-Li-Kraska-Franklin-Feng. SIGMOD'13]
9
𝑥 𝑦
+ですぞ
𝑥 𝑦
-ですぞ
(i)+だけの経路 (ii)+α個&-1個の経路
𝑥 𝑦
😇
それ以外は不明

戦略の例
10
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論
𝑎, 𝑏, 𝑐 , 𝑑, 𝑒 , 𝑓 の3クラスタ⇧本当は知らない
※辺確率𝑝は書いてません

戦略の例
11
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
とりあえず質問した
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論

戦略の例
12
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
(i)で推論
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論

戦略の例
13
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論

戦略の例
14
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
ここ+(ii)で𝑎, 𝑏, 𝑐 × 𝑑, 𝑒 に張る
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論

戦略の例
15
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
𝑎, 𝑏, 𝑐 × 𝑓 に張る
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論
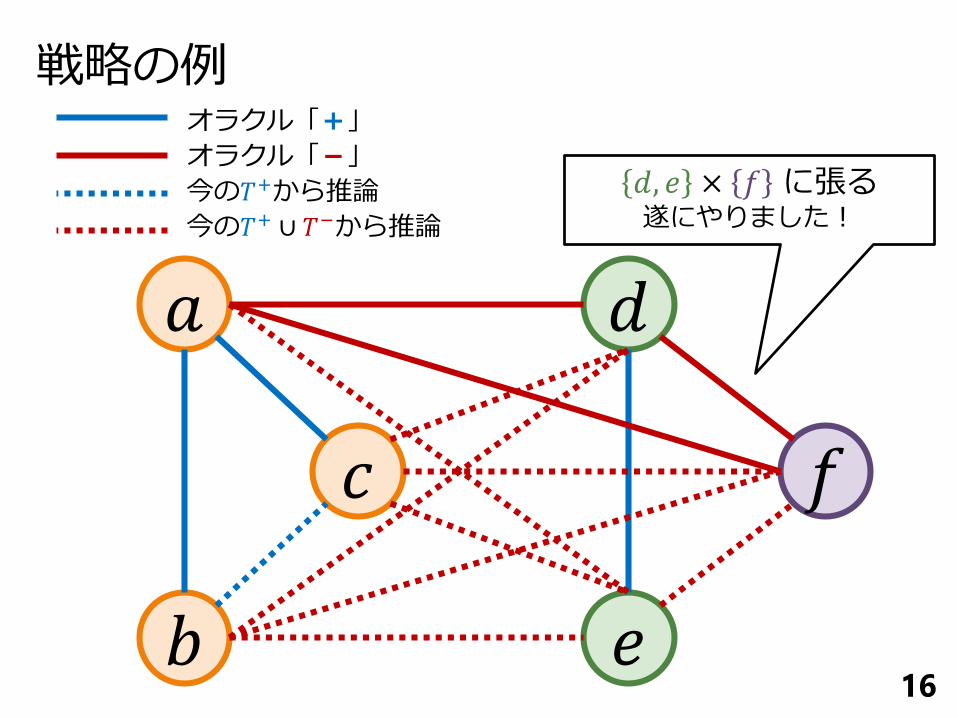
戦略の例
16
𝑎 𝑑
𝑏 𝑒
𝑐 𝑓
𝑑, 𝑒 × 𝑓 に張る遂にやりました!
オラクル「+」
オラクル「-」
今の𝑇+から推論
今の𝑇+ ∪ 𝑇−から推論

問題定式化
オラクル質問回数の下限
推移関係を最大限活用した場合
▶ (𝐸+の特定に必要な質問回数) = 𝑉 − 𝑘
▶ (𝐸+ ∪ 𝐸−の特定に必要な質問回数) = 𝑉 − 𝑘 + 𝑘2
▶ 𝑉 = 12レコード
▶𝑘 = 4クラスタ
17
本当は4×2辺ある

問題定式化
戦略の良さを測る指標の設計指針
▶既存の指標
min (𝐸+ ∪ 𝐸−の完全特定までの質問回数)
▶この研究の設定:オンライン
➔途中でも多くラベル(特に+)を特定して欲しい[Papenbrock-Heise-Naumann. TKDE'15]
[Whang, Marmaros, Garcia-Molina. TKDE'13]
18
[Wang-Li-Kraska-Franklin-Feng. SIGMOD'13][Vesdapunt-Bellare-Dalvi. VLDB'14] 等
似たことをしてるが解析無し

問題定式化
Recall:特定した𝐸+の辺の割合
recall 𝑡 =|𝐸𝑇
+|
|𝐸+|, recall+ 𝑡 =
𝐸𝑇++
|𝐸+|▶𝑇:最初の𝑡個の返答
▶𝑇+:最初の𝑡個の+の返答 (-の返答は無視)
▶𝐸𝑇+・𝐸𝑇+
+ : 𝑇・𝑇+から推論した𝐸+の辺の集合
返答列:+++-++-++-+…
▶気づき:頂点対の質問順は影響しない
19
recall 7 = recall+ 5

問題定式化
Progressive recall:オンラインっぽく
➔ recall(𝑡)の area under the recall-questions curve
precall 𝑡 = ∑1≤𝑡′≤𝑡
recall 𝑡′
precall+ 𝑡 = ∑1≤𝑡′≤𝑡
recall+ 𝑡′
▶気づき:頂点対の質問順が重要※過去の研究でもそれらしい指標はある
benefit = precall 𝑡𝑟∗ , benefit+ = precall+(𝑡𝑟
∗)
▶ 𝑡𝑟∗ = 𝑉 − 𝑘:𝐸+を特定するまでの最低質問回数※論文中は正規化したものを考えている
20

問題定式化
定義
結局、最大化したいもの(= benefit+)は何ですか?
NP困難[Vesdapunt-Bellare-Dalvi. VLDB'14]の問題より難しいと主張
21
入力:レコード集合 𝑉、𝐶のオラクル、辺確率𝑝(𝑢, 𝑣)出力:benefit+を最大化する戦略𝑠
∑1≤𝑡′≤ 𝑉 −𝑘
(𝑡′質問目で特定した+辺数)⋅ ( 𝑉 − 𝑘 + 1 − 𝑡′)先に特定した辺に重み

提案戦略
理想的な戦略
benefit+を上げるには…
+辺を早く多く特定したい
-辺は後回しが良い 実際どうでも良い
𝐸+ ∪ 𝐸−を知っている前提で
最適な―recall 𝑡 の上限を達成する―戦略
𝑐1, 𝑐2, … , 𝑐𝑘:𝑘個のクラスタ in サイズの降順
22
for each 𝑖 = 1 to 𝑘𝑐𝑖中の頂点対をある経路に沿って𝐪𝐮𝐞𝐫𝐲(⋅,⋅)(質問回数 = 𝑐𝑖 − 1)
𝐸−中の辺を適当に尋ねる (質問回数 = 𝑘2
)

提案戦略
論文中にあるが省略する話
𝐪𝐮𝐞𝐫𝐲 𝑥, 𝑦 の具体的な実装
▶辺 𝑥, 𝑦 のラベル+ OR -が分かる
▶返答を𝑇 = 𝑇+ ∪ 𝑇−に保持
▶𝑇で推論可能なラベルを自動的に更新
複数同時質問
▶実験も有
戦略の計算時間
▶例:質問する辺の選択にかかる時間
23

提案戦略
戦略一覧
24
名前近似比
𝑬+ ∪ 𝑬−特定までの質問回数
近似比𝐛𝐞𝐧𝐞𝐟𝐢𝐭+
𝑠𝐰𝐚𝐧𝐠[Wang+ SIGMOD'13]
𝑂 log2 𝑉 Ω 𝑉
𝑠𝐯𝐬𝐞𝐝[Vesdapunt+ VLDB'14]
𝑂 log2 𝑉 Ω |𝑉|
Edge ordering
𝑠𝐞𝐝𝐠𝐞―
最適❔強い仮定
Hybrid ordering
𝑠𝐡𝐲𝐛𝐫𝐢𝐝―
最適❔強い仮定
この論文中で証明クラスタリングのモデルだけ話します
説明します

提案戦略
質問の良さ:期待クラスタサイズ
頂点の期待クラスタサイズ
▶𝑝s 𝑥 = ∑𝑦∈𝑉∖𝑥 𝑝 𝑥, 𝑦
▶ 𝑥を含むクラスタのサイズをGUESSしたい気分
𝑝s 𝑥 = 𝑝 𝑥, 𝑦1 + 𝑝 𝑥, 𝑦2 + 𝑝 𝑥, 𝑦3
25
𝑥
𝑦2
𝑦3
𝑦1
この辺りは無視

提案戦略
① 𝑠𝐰𝐚𝐧𝐠 [Wang-Li-Kraska-Franklin-Feng. SIGMOD'13]
気持ち
▶+になりそうな頂点対から質問する
26
for each 𝑥, 𝑦 in 辺確率𝑝の降順if 𝑥, 𝑦 のラベルが現情報から推論不可
𝐪𝐮𝐞𝐫𝐲 𝑥, 𝑦

提案戦略
② 𝑠𝐯𝐬𝐞𝐝 [Vesdapunt-Bellare-Dalvi. VLDB'14]
気持ち
▶大きそうなクラスタを含む頂点から伸ばす
27
𝑃 ← ∅for each 𝑥 in 期待クラスタサイズ𝑝sの降順
for each 𝑦 ∈ 𝑃 in 𝑝 𝑥, 𝑦 の降順if 𝑥, 𝑦 のラベルが現時点の情報から推論不可
𝐪𝐮𝐞𝐫𝐲 𝑥, 𝑦𝑥, 𝑦 ∈ 𝐸+ならループを抜ける
𝑃 ← 𝑃 ∪ 𝑥
𝑥𝑃 𝑥𝑃′
𝑥′

提案戦略
質問の良さ:辺のbenefit
辺のbenefit = (recallの期待増分)
𝑏e 𝑥, 𝑦 = 𝑐𝑇 𝑥 ⋅ 𝑐𝑇 𝑦 ⋅ 𝑝 𝑥, 𝑦
𝑐𝑇 𝑥 : (現在の返答𝑇から推論した) 𝑥を含むクラスタ
28
2 3 0.46
もし 𝑥, 𝑦 ∈ 𝐸+ と分かれば、6辺増える
𝑦𝑥0.46

頂点のbenefit = (recallの期待増分)
𝑏v 𝑥, 𝑃 = max𝑐∶cluster, 𝑐≠ 𝑥 , 𝑐⊆𝑃
𝑏vc 𝑥, 𝑐
𝑏vc 𝑥, 𝑐 = ∑𝑦∈𝑐 𝑝 𝑥, 𝑦
提案戦略
質問の良さ:頂点のbenefit
29𝑥
𝑦1𝑦2 𝑧1
𝑧2
𝑧3
無視される
𝑃
𝑏vc(𝑥, {𝑧1, 𝑧2, 𝑧3})= 𝑝 𝑥, 𝑧1 + 𝑝 𝑥, 𝑧2 + 𝑝(𝑥, 𝑧3)
𝑏vc(𝑥, {𝑦1, 𝑦2}) = 𝑝 𝑥, 𝑦1 + 𝑝(𝑥, 𝑦2)

提案戦略
③ Edge ordering 𝑠𝐞𝐝𝐠𝐞 𝑤
▶Progressive recallを上げたいので、
▶高benefit辺から選ぶと良さそう
▶パラメータ𝑤大➔低確率辺も考慮
▶※𝑠𝐞𝐝𝐠𝐞 1 = 𝑠𝐰𝐚𝐧𝐠
30
while 全ラベルが未特定𝑊 ←辺確率top-𝑤の辺
𝑥, 𝑦 ← argmax𝑥′,𝑦′ ∈𝑊
𝑏e 𝑥′, 𝑦′
𝐪𝐮𝐞𝐫𝐲(𝑥, 𝑦)↑これがbenefit

提案戦略
④ Hybrid ordering 𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤, 𝜏, 𝜃
▶頂点𝑥を選ぶ基準:期待クラスタサイズ𝑝sと𝑏v▶辺 𝑥, 𝑦 を選ぶ基準:𝑏vc
31
while 𝑃 ≠ 𝑉𝑊 ← 𝑝sがtop-𝑤の点集合
𝑥 ← argmax𝑥′∈𝑊
𝑏v(𝑥′, 𝑃)
for each 𝑦 ∈ 𝑃 in 𝑏vc 𝑥, 𝑦を含むクラスタ の降順
𝐪𝐮𝐞𝐫𝐲(𝑥, 𝑦)if 𝑥, 𝑦 が+ OR 𝜏辺見た OR 𝑏vc 𝑥, 𝑦を含むクラスタ ≤ 𝜃
break
𝑃 ← 𝑃 ∪ {𝑥}𝑠𝐞𝐝𝐠𝐞 𝑤 実行
※𝑠𝐡𝐲𝐛𝐫𝐢𝐝 1, 𝑉 , 0 = 𝑠𝐯𝐞𝐬𝐝, 𝑠𝐡𝐲𝐛𝐫𝐢𝐝 1,0, 𝑉 = 𝑠𝐰𝐚𝐧𝐠

提案戦略
解析の為のクラスタリングモデル (雰囲気)
既存研究のモデル [Vesdapunt-Bellare-Dalvi. VLDB'14]
▶ 辺確率がfixed、クラスタリングがrandom
Edge noise model (本研究)
▶ クラスタリングがfixed、辺確率がrandom
32

提案戦略
解析の為のクラスタリングモデル (雰囲気)
既存研究のモデル [Vesdapunt-Bellare-Dalvi. VLDB'14]
▶ 辺確率がfixed、クラスタリングがrandom
① Uncertain graph 𝒢 = 𝑉, 𝐸, 𝑝 を一つ決める
② 𝐺 ∼ 𝒢 を生成 条件:𝐺がクラスタリング
▶期待質問回数を解析 …𝑝の設定で変な例を容易に作れる
Edge noise model (本研究)
▶ クラスタリングがfixed、辺確率がrandom
33

提案戦略
解析の為のクラスタリングモデル (雰囲気)
既存研究のモデル [Vesdapunt-Bellare-Dalvi. VLDB'14]
▶ 辺確率がfixed、クラスタリングがrandom
Edge noise model (本研究)
▶ クラスタリングがfixed、辺確率がrandom
①クラスタリング 𝐶 = (𝑉, 𝐸+ ∪ 𝐸−)を一つ決める
②各辺確率𝑝 𝑥, 𝑦 を生成:
②-1 パラメータ生成 𝜂𝑥,𝑦 ∼ 𝒟𝑥,𝑦 (何らかの分布)
②-2 𝑝 𝑥, 𝑦 = ൝1 − 𝜂𝑥,𝑦 𝑥, 𝑦 ∈ 𝐸+
𝜂𝑥,𝑦 𝑥, 𝑦 ∈ 𝐸−
34「𝐸+ ∪ 𝐸−が推論容易な𝑝になりやすい」を解析

実験
データセット:説明
cora (参考文献)
▶属性:題目、著者、場所、日付、ページ
skew (架空の病院の患者、Febrlで生成)
▶属性:名前、電話番号、誕生日、住所
sqrtn (架空の病院の患者、Febrlで生成)
▶属性:名前、電話番号、誕生日、住所
prod (製品)
▶abt.comの製品1,081個+buy.comの製品1,092個
▶属性:名前、価格
dblp (計算機科学の参考文献)
▶属性:❔
35
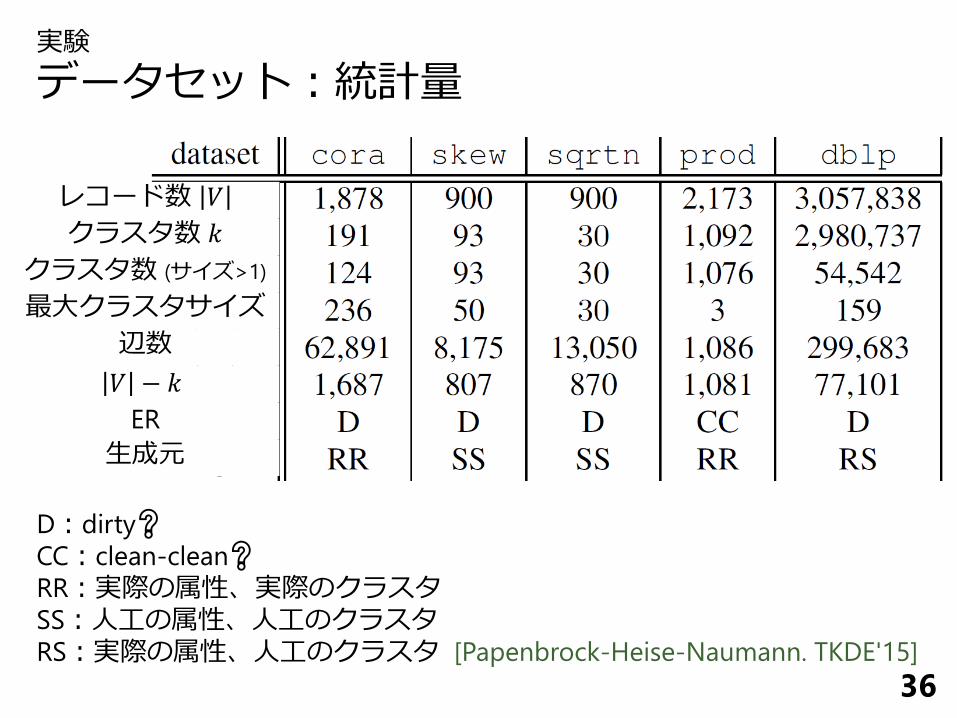
実験
データセット:統計量
36
レコード数 𝑉
クラスタ数 𝑘
クラスタ数 (サイズ>1)
最大クラスタサイズ
辺数
𝑉 − 𝑘
ER
生成元
D:dirty❔
CC:clean-clean❔
RR:実際の属性、実際のクラスタSS:人工の属性、人工のクラスタRS:実際の属性、人工のクラスタ [Papenbrock-Heise-Naumann. TKDE'15]

実験
データセット:クラスタの構造
緑➔高類似度
37
cora少数の巨大クラスタ
𝑉 − 𝑘 ≪ 𝐸+
prod推移関係はほぼ無意味
𝑉 − 𝑘 ≈ |𝐸+|

実験
データセット:クラスタの構造
▶ skew
▶大きさlog 𝑉 ×𝑉
log 𝑉個と
▶大きさ 𝑉 × 𝑉 個と
▶大きさ𝑉
log 𝑉× log 𝑉 個
▶ sqrtn
▶ピッタリ大きさ |𝑉| × 𝑉 個
▶dblp
▶100-5.4×10-6 % はシングルトン
38

実験
データセット:辺確率の生成 (概要)
各レコード対の類似度を計算
▶cora, dblp : Jaro–Winkler distance
▶ skew, sqrtn : 0 OR 1 簡単そう❔
▶prod : Jaccard
[Whang, Lofgren, Garcia-Molina. VLDB'13]に従い類似度-確率のマッピングを計算
39

実験
評価:𝑠𝐞𝐝𝐠𝐞 の質問数 vs. recall
𝑠𝐞𝐝𝐠𝐞 𝑤 = 1 , 𝑠𝐞𝐝𝐠𝐞 𝑤 = 𝑉 , ⇦提案手法
𝑠𝐯𝐞𝐬𝐝, 𝑠𝐰𝐚𝐧𝐠, 𝑠𝐩𝐚𝐩𝐞 [Papenbrock-Heise-Naumann. TKDE'15]
+:recallの上限
40
benefit=⇩までのarea under curve
何とも言えない𝑉 − 𝑘 = 1,687までは順調

実験
評価:𝑠𝐞𝐝𝐠𝐞 の質問数 vs. recall
𝑠𝐞𝐝𝐠𝐞 𝑤 = 1 , 𝑠𝐞𝐝𝐠𝐞 𝑤 = 𝑉 ,
𝑠𝐯𝐞𝐬𝐝, 𝑠𝐰𝐚𝐧𝐠, 𝑠𝐩𝐚𝐩𝐞 [Papenbrock-Heise-Naumann. TKDE'15]
+:recallの上限
41
𝑠𝐞𝐝𝐠𝐞 𝑤 = 𝑉 が良い
benefit=⇩までのarea under curve

実験
評価:𝑠𝐞𝐝𝐠𝐞 の質問数 vs. recall
𝑠𝐞𝐝𝐠𝐞 𝑤 = 1 , 𝑠𝐞𝐝𝐠𝐞 𝑤 = 𝑉 ,
𝑠𝐯𝐞𝐬𝐝, 𝑠𝐰𝐚𝐧𝐠, 𝑠𝐩𝐚𝐩𝐞
+:recallの上限
42
= 質問回数
𝑠𝐞𝐝𝐠𝐞 𝑤 = 𝑉 が良い 𝑠𝐞𝐝𝐠𝐞 𝑤 = 1 が良いただの辺確率順

実験
評価:𝑠𝐡𝐲𝐛𝐫𝐢𝐝 の質問数 vs. recall
𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 1 , 𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 𝑉 (𝜃 = 0.3, 𝜏 = log |𝑉|)
𝑠𝐯𝐞𝐬𝐝, 𝑠𝐰𝐚𝐧𝐠, 𝑠𝐩𝐚𝐩𝐞
+:recallの上限
43
何とも言えない𝑉 − 𝑘 = 1,687までは順調
𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 𝑉 が良い

実験
評価:𝑠𝐡𝐲𝐛𝐫𝐢𝐝 の質問数 vs. recall
𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 1 , 𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 𝑉 (𝜃 = 0.3, 𝜏 = log |𝑉|)
𝑠𝐯𝐞𝐬𝐝, 𝑠𝐰𝐚𝐧𝐠, 𝑠𝐩𝐚𝐩𝐞
+:recallの上限
44𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 𝑉 が良い 𝑠𝐡𝐲𝐛𝐫𝐢𝐝 𝑤 = 1 が良い

実験
可視化: 𝑐1 − 1 = 235質問で特定した辺(cora)
45
小クラスタばかり
最大クラスタ重視
2番目
大体最大クラスタ

まとめ
▶オンラインentity resolution戦略の問題定式化・アルゴリズム提案・実験評価
▶Progressive recall最大化
▶クラスタリングの新しいモデル下での解析
▶ Future work:誤りを含むオラクル
▶感想
▶質問回数の下限= 𝑉 − 𝑘 + 𝑘2が大変なので、
誤差を含んだ出力も許すと良さそう?
46