openmp/openaccによる マルチコア・メニィコア...
TRANSCRIPT

第109回 お試しアカウント付き並列プログラミング講習会
OpenMP/OpenACCによるマルチコア・メニィコア並列プログラミング入門
東京大学情報基盤センター
担当:星野哲也, 中島研吾hoshino @ cc.u-tokyo.ac.jpnakajima @ cc.u-tokyo.ac.jp
(内容に関するご質問はこちらまで)
1

実習用プログラムのダウンロードn Reedbush へログイン
n $ ssh -Y reedbush.cc.u-tokyo.ac.jp –l txxxxx
n module のロードn $ module load pgi/18.7 #ログインしなおす度に必要です!
n ワークディレクトリに移動n $ cdw
n OpenACC_samples のコピーn $ cp /lustre/gt00/share/OpenMP_OpenACC.tar.gz .n $ tar zxvf OpenMP_OpenACC.tar.gz
2
u自宅で学習したい人へu PGIcompilerの無償版をダウンロードしましょう ->PGIの代理店(SofTekさん)のページ https://www.softek.co.jp/SPG/Pgi/pgi_community.html
u本実習のプログラムは以下 ->http://nkl.cc.u-tokyo.ac.jp/seminars/multicore/

GPU入門
3

What’s GPU ?n Graphics Processing Unitn もともと PC の3D描画専用の装置n パソコンの部品として量産されてる。= 非常に安価
4
GPU
Computer Graphics
3D Game
http://www.nvidia.co.jp

GPUコンピューティングn GPUはグラフィックスやゲームの画像計算のために進化を続けてい
る。n CPUがコア数が2-12個程度に対し、GPUは1000以上のコアがある。n GPUを一般のアプリケーションの高速化に利用することを「GPUコ
ンピューティング」「GPGPU (General Purpose computation on GPU)」などという。
n 2007年にNVIDIA社のCUDA言語がリリースされて大きく発展n ここ数年、ディープラーニング(深層学習)、機械学習、AI(人工
知能)などでも注目を浴びている。
5

GPUの特徴n なぜGPUが使われるのか?
ü 性能高いü NVIDIA P100 (Reedbush-H) 5,304 GFlopsü Intel Xeon Phi (Oakforest-PACS) 3,046.4 GFLops
ü 消費電力低いü スパコンに搭載されている
n コンピュータに取り付ける増設ボードü 単体では動作できず、CPUからの指令が必要。ü CPUとGPUはメモリが異なるため、メモリ間のデータ移動もプログ
ラミングする必要がある。n 多数の小さなコア(1000以上)を搭載。これを有効に活用す
るため「並列計算」が必須。ü CPUは大きなコア:分岐予測、パイプライン処理などできる。逐次
処理が得意。ü GPUは小さなコア:CPUの持つ機能がほとんどないか、全くない。
6

NVIDIA Tesla P100
n 56 SMs, 3584 CUDAコア, 16 GByte
7Tesla P100 whitepaper より

並列計算n 実行時間 T の逐次処理のプログラムを p 台の計算機で並列計算することで、実行時間を T / p にする。
n 実際にできるかどうかは、処理内容(アルゴリズム)による。アルゴリズムによって難易度は異なる。ü 並列化できないアルゴリズム、通信のオーバーヘッドü 部分的にでも並列化できないアルゴリズムがあると、どれだけ並列数を上げても、その時間は短縮されない。
n 並列処理(計算)の種類ü 「タスク並列」と「データ並列」
8
T/p
p台
T

タスク並列n タスク(仕事)を分割することで並列化する。n タスク並列の例:カレーを作る
ü 仕事1:野菜を切るü 仕事2:肉を切るü 仕事3:水を沸騰させるü 仕事4:野菜と肉を入れて煮込むü 仕事5:カレーのルウを入れる
n 並列化
9
仕事1
仕事2
仕事3
仕事4 仕事5
時間
GPUは苦手

データ並列n データを分割することで並列化する。
ü データは異なるが計算の手続きは同じ。n データ並列の例:手分けをして算数ドリルを解く
ü 数字だけ異なるが計算の手続きは同じ。
10
GPUの並列計算はこれが原則。
2 + 1 = 12 – 88 = 34 + 3 = 2 + 4 = 3 + 19 = - 20 + 29 = 1 + 2 = 99 – 72 = 4 - 6 = 4 + 10 = -3 + 2 = 2 + 10 = 5 + 3 = 1 + 10 = -10 – 10 = 3 – 11 = -2 + 10 = 1 + 13 = 2 + 1 = 12 – 34 = 1 + 2 = 0 + 0 = 1 -10 = 45 + 19 =

GPUでの計算の流れ
n 計算はOSのあるCPUから始まるn 物理的に独立のデバイスメモリとデータのやり取り必須
11
CPU
メインメモリ
GPU
~200GB/s ~1,000GB/s
~32GB/s
デバイスメモリ
バス (PCIeなど)
OSが動いている OSは存在しない
2.計算を行う
1.必要なデータを送る
3.計算結果を返す
~20GB/s
ノードの外へ

GPUプログラミングでの注意点(1)
n CPUメモリとGPUメモリが独立ü 従ってCPUとGPUのメモリ間でデータのやりとりが必要になるが、CPUとGPUの間のデータ転送性能は相対的に遅い
ü 特にOpenACCでは、これを意識する必要があるn 高い性能を得るには、スレッド数 >> コア数(P100 では
3584)ü 数万から数百万スレッド程度ü メモリアクセスによる暇な時間(ストール)を、他のスレッドが埋めることができる
ü Intel CPU では Hyperthread に相当。ただしこちらは物理コア x 212
これらはプログラミング言語が CUDA かOpenACCに関わらず、GPUプログラミングでは考慮する必要がある。

GPUプログラミングでの注意点(2)n スレッド間での異なる処理(分岐)は避ける
ü 連続した32スレッド(Warp と呼ぶ)が同じ命令を実行ü Warp内で分岐先が異なると、全ての分岐先を実行し、真になる条件の処理のみ採用
ü branch divergence, divergent branch などという。
13
...
...if (奇数番スレッド) {
処理 A;
} else {
処理 B;
}......
スレッド

GPUプログラミングでの注意点(3)n 同じWarp内のスレッド(連続するスレッド)は近いメモリアドレスへアクセスすると効率的ü コアレスドアクセス(coalesced access)と呼ぶü メモリアクセスは128 Byte 単位で行われる。128 Byte に収まれば1回のアクセス、超えれば128 Byte アクセスをその分繰り返す。
128 byte x 1回のメモリアクセス
128 byte x 2回のメモリアクセス
14
128 160 192 224 256Address
0 3116Thread
... ...15
128 160 192 224 256Address
0 3116Thread
... ...15

OPENACC入門
15

GPUコンピューティングの方法n ライブラリの利用(CUFFT, CUBLAS など)
ü GPU用ライブラリを呼ぶだけで、すぐに利用できる。ü ライブラリ以外の部分は高速化されない。
n 指示文ベース(OpenACC)ü 指示文(ディレクティブ)を挿入するだけである程度高速化。
ü 既存のソースコードを活用できる。
n プログラミング言語(CUDA、OpenCLなど)ü GPUの性能を最大限に活用。ü プログラミングにはGPGPU用言語を使用する必要あり。
16
簡単
難しい

OpenACCn OpenACCとは
ü 新しいアクセラレータ用プログラミングインターフェースü OpenMP のようなディレクティブ(指示文)・ベースü C 言語/C++, Fortran に対応ü 2011年秋に OpenACC1.0、最新は 2.5ü コンパイラ:[商用]PGI, Cray,[フリー]GCC(PGIは無料版あり)ü WEBサイト:http://www.openacc.org/
n 指示文ベースの利点ü 指示文:コンパイラへのヒントü アプリケーションの開発や移植が比較的簡単ü ホスト(CPU)用コード、複数のアクセラレータ用コードを単一コードとして記述。メンテナンスが容易。高生産性。
17
C言語#pragma acc directive-name [clause, …]{
// C code}
Fortran!$acc directive-name [clause, …]
! Fortran code!$acc end directive-name

逐次、OpenMP、OpenACCの実行イメージ
18
int main(){
...
#pragma acc ...for (i=0; i<n; i++) {
...
}
...
}
1スレッド OpenMP
CPU
OpenACC
CPU CPUデバイス(GPU)

はじめてのOpenACCコード
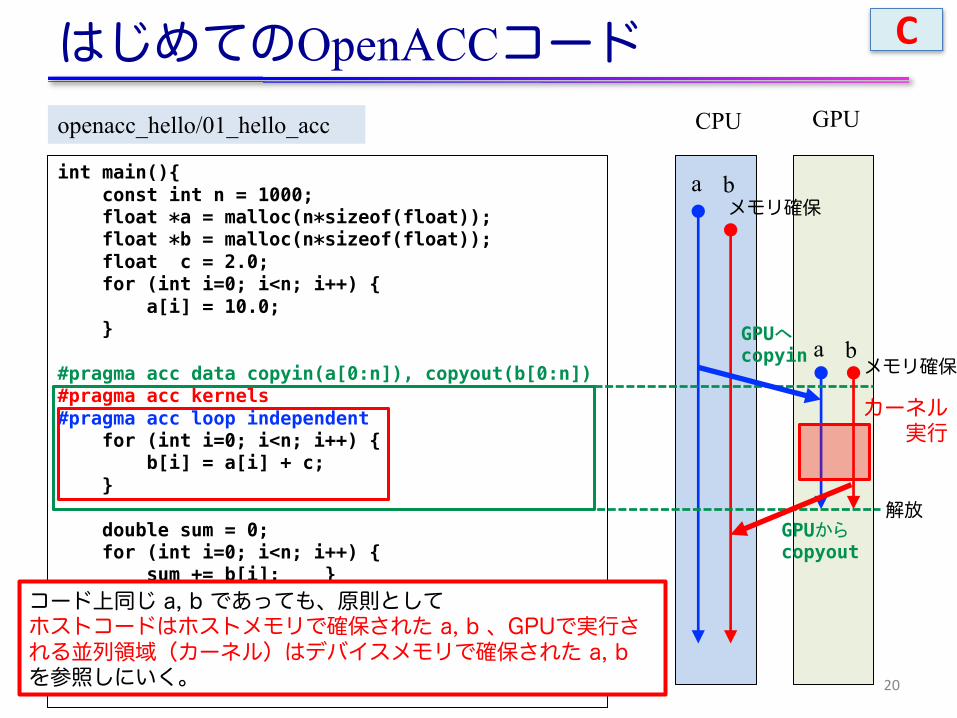
19
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
#pragma acc data copyin(a[0:n]), copyout(b[0:n])#pragma acc kernels#pragma acc loop independent
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}
double sum = 0;for (int i=0; i<n; i++) {
sum += b[i];}fprintf(stdout, "%f¥n", sum/n);free(a); free(b);return 0;
}
CPU GPU
a b
a bGPUへcopyin
GPUからcopyout
カーネル実行
メモリ確保
メモリ確保
解放
openacc_hello/01_hello_acc
C
はじめてのOpenACCコード
20
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
#pragma acc data copyin(a[0:n]), copyout(b[0:n])#pragma acc kernels#pragma acc loop independent
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}
double sum = 0;for (int i=0; i<n; i++) {
sum += b[i]; }fprintf(stdout, "%f¥n", sum/n);
free(a); free(b);return 0;
}
CPU GPU
a b
a bGPUへcopyin
GPUからcopyout
カーネル実行
メモリ確保
メモリ確保
解放
openacc_hello/01_hello_acc
コード上同じ a, b であっても、原則としてホストコードはホストメモリで確保された a, b 、GPUで実行される並列領域(カーネル)はデバイスメモリで確保された a, bを参照しにいく。
C

はじめてのOpenACCコード
21
program mainimplicit none! 変数宣言allocate(a(n),b(n))c = 2.0
do i = 1, na(i) = 10.0
end do!$acc data copyin(a) copyout(b)!$acc kernels!$acc loop independentdo i = 1, n
b(i) = a(i) + cend do
!$acc end kernels!$acc end datasum = 0.d0do i = 1, n
sum = sum + b(i)end doprint *, sum/ndeallocate(a,b)
end program main
CPU GPU
a b
a bGPUへcopyin
GPUからcopyout
カーネル実行
メモリ確保
メモリ確保
解放
openacc_hello/01_hello_acc
F

OpenACCの主な指示文n 並列領域指定指示文
ü kernels, parallel
n データ管理・移動指示文ü data, enter data, exit data, update
n 並列処理の指定ü loop
n その他ü host_data, atomic, routine, declare
赤字:この講習会で扱うもの
22

OpenACC によるアクセラレータでの実行n kernels 指示文
ü 指定された領域がアクセラレータで実行されるカーネルへü 一般には、それぞれのループが別々のカーネルへコンパイル
ü 同様な指示文として、領域内が一つのカーネルとして生成される parallel 指示文もある
23
int main() {
#pragma acc kernels{
for (int i=0; i<n; i++) {A;
}
for (int i=0; i<n; i++) {B;
}}
}
kernel 1
kernel 2
program main
!$ acc kernels
do i = 1, nA;
end do
do i = 1, nB;
end do !$acc end kernels
}

CPUコードのOpenACC化
24
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}
double sum = 0;for (int i=0; i<n; i++) {
sum += b[i];}fprintf(stdout, "%f¥n", sum/n);free(a); free(b);return 0;
}
openacc_hello/01_hello_acc
n ループのOpenACC 化ü 並列化したいループにkernels,
loop 指示文を追加
C

CPUコードのOpenACC化
25
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
#pragma acc kernels#pragma acc loop independentfor (int i=0; i<n; i++) {
b[i] = a[i] + c;}
double sum = 0;for (int i=0; i<n; i++) {
sum += b[i];}fprintf(stdout, "%f¥n", sum/n);free(a); free(b);return 0;
}
openacc_hello/01_hello_acc
n ループのOpenACC 化ü 並列化したいループにkernels,
loop 指示文を追加
C

CPUコードのOpenACC化
26
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
#pragma acc kernels#pragma acc loop independent
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}
double sum = 0;for (int i=0; i<n; i++) {
sum += b[i];}fprintf(stdout, "%f¥n", sum/n);free(a); free(b);return 0;
}
openacc_hello/01_hello_acc
n ループのOpenACC 化ü 並列化したいループにkernels,
loop 指示文を追加
カーネルとしてコンパイルされ、GPU上で実行される配列の1要素が1スレッドで処理されるイメージ
C

CPUコードのOpenACC化
27
openacc_hello/01_hello_acc
n ループのOpenACC 化ü 並列化したいループにkernels,
loop 指示文を追加
F
program mainimplicit none! 変数宣言allocate(a(n),b(n))c = 2.0
do i = 1, na(i) = 10.0
end do
!$acc kernels!$acc loop independentdo i = 1, n
b(i) = a(i) + cend do
!$acc end kernels
sum = 0.d0do i = 1, n
sum = sum + b(i)end doprint *, sum/ndeallocate(a,b)
end program main
Fortranも同じ

OpenACCのデフォルトの変数の扱いn スカラ変数
ü firstprivate または privateü OpenMP では shared
ü ホストからデバイスへコピーが渡され初期化。ホストに戻せない。
n 配列ü sharedü デバイスメモリに動的に確保され、スレッド間で共有。ü デバイスからホストへコピーすることが可能。
n kernels 構文に差し掛かると、ü OpenACCコンパイラは実行に必要なデータを自動で転送する。ü 配列はデバイスメモリに確保され、shared になる。ü 構文に差し掛かるたびに転送を行う。data 指示文で制御できる。
28

データ管理・移動n data 指示文
ü デバイス(GPU)メモリの確保と解放、ホスト(CPU)とデバイス(GPU)間のデータ転送を制御kernels指示文では、データ転送は自動的に行われる。data指示文でこれを制御することで、不要な転送を避け、性能向上できる
ü CUDA で言うところの cudaMalloc, cudaMemcpy に相当
29
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
#pragma acc data copyin(a[0:n]), copyout(b[0:n])#pragma acc kernels#pragma acc loop independent
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}
openacc_hello/01_hello_acc
変数 cはスカラ変数のため、自動的にデバイスへコピーされ、プライベート変数となる。
C

データ管理・移動n data 指示文
ü デバイス(GPU)メモリの確保と解放、ホスト(CPU)とデバイス(GPU)間のデータ転送を制御kernels指示文では、データ転送は自動的に行われる。data指示文でこれを制御することで、不要な転送を避け、性能向上できる
ü CUDA で言うところの cudaMalloc, cudaMemcpy に相当
30
program mainimplicit noneinteger,parameter :: n = 1000real(KIND=4),allocatable,dimension(:) :: a,breal(KIND=4) :: cinteger :: ireal(KIND=8) :: sumallocate(a(n),b(n))c = 2.0do i = 1, n
a(i) = 10.0end do
!$acc data copyin(a) copyout(b)!$acc kernels!$acc loop independent
do i = 1, nb(i) = a(i) + c
end do!$acc end kernels!$acc end data
openacc_hello/01_hello_acc
Fortranでは配列サイズ情報が変数に付随するため(lbound,ubound,sizeなどの組み込み関数をサポートしている)、基本的にサイズを書く必要がない。
F

data 指示文の指示節n copy
ü allocate, memcpy(H->D), memcpy(D->H), deallocaten copyin
ü allocate, memcpy(H->D), deallocateü 解放前にホストへデータをコピーしない
n copyoutü allocate, memcpy(D->H), deallocateü 確保後にホストからデータをコピーしない
n createü allocate, deallocateü コピーしない
n presentü 何もしない。既にデバイス上で確保済みであることを伝える。
n copy/copyin/copyout/create は既にデバイス上確保されているデータに対しては何もしない。present として振る舞う。(OpenACC2.5以降)
31

enter data, exit data 指示文n data 指示文はブロックに対してしか適用できない
ü ファイルをまたがったり、goto 文があったりすると記述できない!n enter data と exit data はペアで data 指示文の代わり
ü enter data では copyout は使えないので create, exit data ではcopyinは使えないので delete 32
#pragma acc data copyin(a[0:n]) ¥ copyout(b[0:n])
{goto hoge;
}hoge:
!$acc data copyin(a), copyout(b)
goto 1000
!$acc end data1000
#pragma acc enter data ¥copyin(a[0:n]) create(b[0:n])
{goto hoge:
}hoge:#pragma acc exit data ¥delete(a[0:n]) copyout(b[0:n])
!$acc enter data !$acc& copyin(a) create(b)
goto 1000
1000!$acc exit data !$acc& delete(a) copyout(b)
NG NG
OK NG

データの移動範囲の指定n ホストとデバイス間でコピーする範囲を指定
n 部分配列の転送が可能n Fortran と C言語で指定方法が異なるので注意
n 二次元配列A転送する例n Fortran: 下限と上限を指定
n C言語: 始点とサイズを指定
33
!$acc data copy(A(lower1:upper1, lower2:upper2) )...!$acc end data
#pragma acc data copy(A[begin1:length1][begin2:length2])...

並列処理の指定
34
int main(){const int n = 1000;float *a = malloc(n*sizeof(float));float *b = malloc(n*sizeof(float));float c = 2.0;for (int i=0; i<n; i++) {
a[i] = 10.0;}
#pragma acc data copyin(a[0:n]), copyout(b[0:n])#pragma acc kernels#pragma acc loop independent
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}
double sum = 0;for (int i=0; i<n; i++) {
sum += b[i];}fprintf(stdout, "%f¥n", sum/n);free(a); free(b);return 0;
}
CPU GPU
a b
a bGPUへcopyin
GPUからcopyout
カーネル実行
メモリ確保
メモリ確保
解放
openacc_hello/01_hello_acc
loop指示文
C
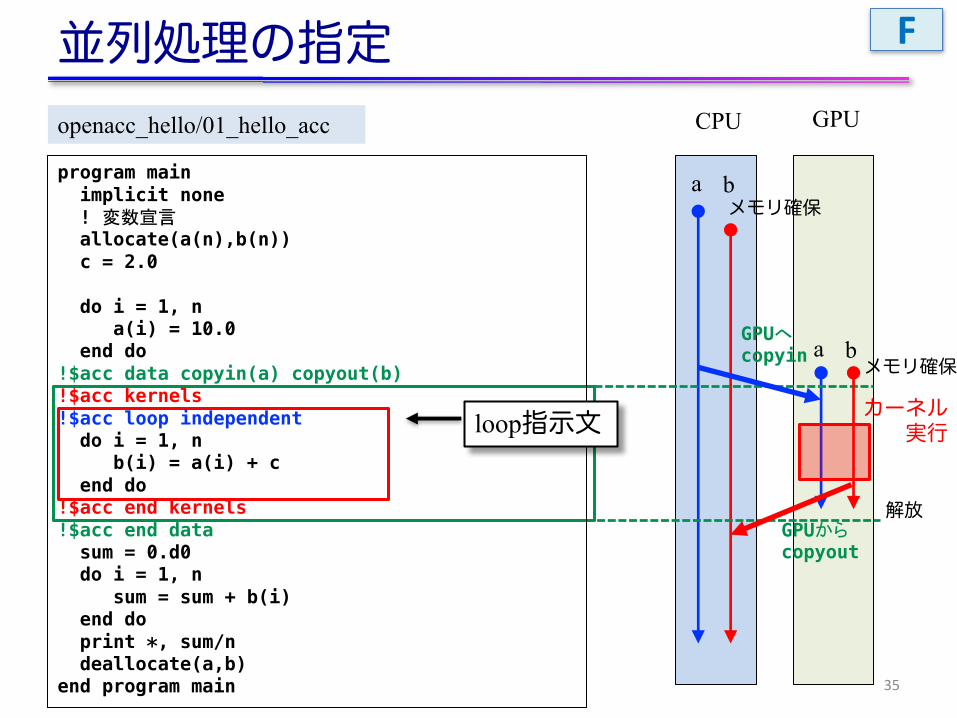
並列処理の指定
35
CPU GPU
a b
a bGPUへcopyin
GPUからcopyout
カーネル実行
メモリ確保
メモリ確保
解放
openacc_hello/01_hello_acc
F
program mainimplicit none! 変数宣言allocate(a(n),b(n))c = 2.0
do i = 1, na(i) = 10.0
end do!$acc data copyin(a) copyout(b)!$acc kernels!$acc loop independentdo i = 1, n
b(i) = a(i) + cend do
!$acc end kernels!$acc end datasum = 0.d0do i = 1, n
sum = sum + b(i)end doprint *, sum/ndeallocate(a,b)
end program main
loop指示文

並列処理の指定:loop 指示文n loop 指示文
ü ループマッピングのパラメータの調整(CUDAのスレッドブロック数を指定)
gang, worker, vector を用いて指定する。大まかに以下のように考えると良い。
- gang: CUDA の thread block 数の指定- vector: CUDA の block 内の threads 数の指定
ü ループがデータ独立であることを指定 (independent clause)データ独立でないと並列化できない。C言語ではコンパイラがしばしばデータ独立であることを判断できないので、その場合はこれを指定。
ü リダクション処理 (reduction clause)ü 逐次処理 (seq clause)
36

データの独立性n independent 指示節により指定
ü ループがデータ独立であることを明示するü コンパイラが並列化できないと判断したときに使用する
37
#pragma acc kernels#pragma acc loop independent
for (int i=0; i<n; i++) {b[i] = a[i] + c;
}並列化可能(データ独立)なので、independent を指定(コンパイラは並列化可能とは判断してくれなかった)
// これは正しくない
#pragma acc kernels#pragma acc loop independent
for (int i=1; i<n; i++) {d[i] = d[i-1];
}
n データ独立でない(並列化可能でない)例

参考:OpenACC 化とCUDA化の比較
38
// CUDA
__global__void calc_kernel(int n, const float *a, const float *b, float c, float *d){
const int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {d[i] = a[i] + c*b[i];
}}
void calc(int n, const float *a, const float *b, float c, float *d){
dim3 threads(128);dim3 blocks((n + threads.x - 1) / threads.x);
calc_kernel<<<blocks, threads>>>(n, a, b, c, d);cudaThreadSynchronize();
}
int main(){
...
float *a_d, *b_d, *d_d;cudaMalloc(&a_d, n*sizeof(float));cudaMalloc(&b_d, n*sizeof(float));cudaMalloc(&d_d, n*sizeof(float));
cudaMemcpy(a_d, a, n*sizeof(float), cudaMemcpyDefault);cudaMemcpy(b_d, b, n*sizeof(float), cudaMemcpyDefault);cudaMemcpy(d_d, d, n*sizeof(float), cudaMemcpyDefault);
calc(n, a_d, b_d, c, d_d);
cudaMemcpy(d, d_d, n*sizeof(float), cudaMemcpyDefault);...
}
// OpenACC
void calc(int n, const float *a, const float *b, float c, float *d){#pragma acc kernels present(a, b, d)#pragma acc loop independent
for (int i=0; i<n; i++) {d[i] = a[i] + c*b[i];
}}
int main(){
...#pragma acc data copyin(a[0:n], b[0:n]) copyout(d[0:n])
{calc(n, a, b, c, d);
}...
}
ü kernels 指示文でGPUでの実行領域を指定。
ü loop 指示文で並列処理の最適化。ü data 指示文でデータ転送を制御。
kernels 指示文でデータ転送を自動的に行うこともできる。
kernel

OpenACCコードのコンパイルn PGIコンパイラによるコンパイル
ü ReedbushではOpenACCはPGIコンパイラで利用できます。
-acc: OpenACCコードであることを指示-Minfo=accel:
OpenACC指示文からGPUコードが生成できたかどうか等のメッセージを出力する。このメッセージがOpenACC化では大きなヒントになる。
-ta=tesla,cc60: ターゲット・アーキテクチャの指定。NVIDIA GPU Teslaをターゲットとし、compute capability 6.0 (cc60) のコードを生成する。
n Makefileでコンパイル講習会のサンプルコードには Makefile がついているので、コンパイルするためには、単純に下記を実行すれば良い。
39
$ module load pgi/18.7$ pgcc -O3 -acc -Minfo=accel -ta=tesla,cc60 -c main.c
$ module load pgi/18.7$ make

簡単なOpenACCコードn サンプルコード: openacc_basic/
ü OpenACC指示文 kernels, data, loop を利用したコードü 計算内容は簡単な四則演算
ü ソースコード
40
openacc_basic/01_original CPUコード。
openacc_basic/02_kernels OpenACCコード。上にkernels指示文のみ追加。
openacc_basic/03_kernels_copy OpenACCコード。上にcopy指示節追加。
openacc_basic/04_loop OpenACCコード。上にloop指示文を追加。
openacc_basic/05_data OpenACCコード。上にdata指示文を明示的に追加。
openacc_basic/06_present OpenACCコード。上でpresent指示節を使用。
openacc_basic/07_reduction OpenACCコード。上にreduction指示節を使用。
for (unsigned int j=0; j<ny; j++) {for (unsigned int i=0; i<nx; i++) {
const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}}
Cdo j = 1,ny
do i = 1,nxc(i,j) = a(i,j) + b(i,j)
end doend do
F

配列のインデックス計算n サンプルコード: openacc_basic/
ü OpenACC指示文 kernels, data, loop を利用したコードü 計算内容は簡単な四則演算
41
void calc(unsigned int nx, unsigned int ny, const float *a, const float *b, float *c){for (unsigned int j=0; j<ny; j++) {
for (unsigned int i=0; i<nx; i++) {const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}}
}
ny
nx
j
i
ix = j*nx + i
C

配列のインデックス計算n サンプルコード: openacc_basic/
ü OpenACC指示文 kernels, data, loop を利用したコードü 計算内容は簡単な四則演算
42
subroutine calc(nx, ny, a, b, c)implicit noneinteger,intent(in) :: nx,nyreal(KIND=4),dimension(:,:),intent(in) :: a,breal(KIND=4),dimension(:,:),intent(out) :: cinteger :: i,j
do j = 1,nydo i = 1,nx
c(i,j) = a(i,j) + b(i,j)end do
end do
end subroutine calc
F
Fortran版では多次元配列を利用

簡単なOpenACC: CPUコードn CPUコードのコンパイルと実行
ü 配列の平均値と実行時間が出力されています。
n 計算内容ü 配列 a、b、cをそれぞれ 1.0, 2.0, 0.0 で初期化ü calc関数内で c += a *b を nt(=1000)回実行。ü この実行時間を測定
43
$ cd openacc_basic/01_original$ make$ qsub ./run.sh$ cat run.sh.o??????mean = 3000.00Time = 19.886 [sec]
答えは常に3000.0
? の数字はジョブごとに変わります。
openacc_basic/01_original

簡単なOpenACC: kernels 指示文(1)n 02_kernelsコード: calc関数
ü CPUコードにkernels 指示文の追加
44
void calc(unsigned int nx, unsigned int ny, const float *a, const float *b, float *c){const unsigned int n = nx * ny;
#pragma acc kernels for (unsigned int j=0; j<ny; j++) {
for (unsigned int i=0; i<nx; i++) {const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}}
}
openacc_basic/02_kernels
CF
subroutine calc(nx, ny, a, b, c)implicit noneinteger,intent(in) :: nx,nyreal(KIND=4),dimension(:,:),intent(in) :: a,breal(KIND=4),dimension(:,:),intent(out) :: cinteger :: i,j!$acc kernelsdo j = 1,ny
do i = 1,nxc(i,j) = a(i,j) + b(i,j)
end doend do!$acc end kernels
end subroutine calc
OpenACCコンパイラは配列 (a,b,c)を shared変数として自動で転送してくれるはずだが…
C
F

簡単なOpenACC: kernels 指示文(2)n コンパイル
45
$ makepgcc -O3 -acc -Minfo=accel -ta=tesla,cc60 -c main.cPGC-S-0155-Compiler failed to translate accelerator region (see -Minfo messages): Could not find allocated-variable index for symbol (main.c: 13)calc:
14, Complex loop carried dependence of a->,c->,b-> prevents parallelizationAccelerator serial kernel generatedAccelerator kernel generatedGenerating Tesla code14, #pragma acc loop seq15, #pragma acc loop seq
15, Accelerator restriction: size of the GPU copy of c,b,a is unknownComplex loop carried dependence of a->,c->,b-> prevents parallelization
PGC-F-0704-Compilation aborted due to previous errors. (main.c)PGC/x86-64 Linux 18.4-0: compilation abortedmake: *** [main.o] Error 2
C
データサイズがわからずコンパイルエラーC言語では配列サイズの指定がほぼ必須!
$ makepgfortran -O3 -mp -acc -ta=tesla,cc60 -Minfo=accel -c main.f90calc:
13, Generating implicit copyin(b(:nx,:ny))Generating implicit copyout(c(:nx,:ny))Generating implicit copyin(a(:nx,:ny))
14, Loop is parallelizable15, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code14, !$acc loop gang, vector(4) ! blockidx%y threadidx%y15, !$acc loop gang, vector(32) ! blockidx%x threadidx%x
F
C
Fデータサイズを検知して自動転送Fotranではサイズ情報が配列に付随するため

簡単なOpenACC: kernels 指示文(3)n 03_kernels_copyコード: calc関数
ü 配列サイズを明示的に指定
ü kernels 指示文では data 指示文が使えるü 上の場合は、copy を指定
ü カーネル前後でGPUとCPU間のメモリ転送が行われる。
46
void calc(unsigned int nx, unsigned int ny, const float *a, const float *b, float *c){const unsigned int n = nx * ny;
#pragma acc kernels copy(a[0:n], b[0:n], c[0:n])for (unsigned int j=0; j<ny; j++) {
for (unsigned int i=0; i<nx; i++) {const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}}
}
openacc_basic/03_kernels_copy
allocate, H -> D
D->H, deallocate
C

簡単なOpenACC: kernels 指示文(4)n 03_kernels_copyコード:初期化
ü CPUコードにkernels 指示文の追加
47
int main(int argc, char *argv[]){...#pragma acc kernels copyout(b[0:n], c[0:n])
{for (unsigned int i=0; i<n; i++) {
b[i] = b0;}for (unsigned int i=0; i<n; i++) {
c[i] = 0.0;}
}
...}
b0 はスカラ変数のため自動的に各スレッドへコピーが渡される。
openacc_basic/03_kernels_copy
C
program main...!$acc kernels copyout(b,c)
do j = 1,nydo i = 1,nx
b(i,j) = b0end do
end do
c(:,:) = 0.0!$acc end kernels...end program
C F
Fortranの配列代入形式も使える
F

簡単なOpenACC: kernels 指示文(5)n コンパイル
ü データの独立性がコンパイラにはわからず、並列化されない。
48
$ makepgcc -O3 -acc -Minfo=accel -ta=tesla,cc60 -c main.ccalc:
13, Generating copy(a[:n],c[:n],b[:n])14, Complex loop carried dependence of a-> prevents parallelization
Loop carried dependence due to exposed use of c[:n] prevents parallelizationComplex loop carried dependence of c->,b-> prevents parallelizationAccelerator scalar kernel generatedAccelerator kernel generatedGenerating Tesla code14, #pragma acc loop seq15, #pragma acc loop seq
15, Complex loop carried dependence of a->,c->,b-> prevents parallelizationLoop carried dependence due to exposed use of c[:i1+n] prevents parallelization
main:43, Generating copyout(c[:n],b[:n])45, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code45, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
48, Loop is parallelizableAccelerator kernel generatedGenerating Tesla code48, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
pgcc -O3 -acc -Minfo=accel -ta=tesla,cc60 main.o -o run
C

簡単なOpenACC: kernels 指示文(5)n コンパイル
ü データの独立性を見切り、並列化。
49
pgfortran -O3 -mp -acc -ta=tesla,cc60 -Minfo=accel -c main.f90calc:
13, Generating copyin(a(:,:))Generating copyout(c(:,:))Generating copyin(b(:,:))
14, Loop is parallelizable15, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code14, !$acc loop gang, vector(4) ! blockidx%y threadidx%y15, !$acc loop gang, vector(32) ! blockidx%x threadidx%x
main:61, Generating copyout(c(:,:),b(:,:))62, Loop is parallelizable63, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code62, !$acc loop gang, vector(4) ! blockidx%y threadidx%y63, !$acc loop gang, vector(32) ! blockidx%x threadidx%x
68, Loop is parallelizableAccelerator kernel generatedGenerating Tesla code68, !$acc loop gang, vector(4) ! blockidx%y threadidx%y
!$acc loop gang, vector(32) ! blockidx%x threadidx%xpgfortran -O3 -mp -acc -ta=tesla,cc60 -Minfo=accel main.o -o run
F

Tips: なぜデータの独立性を見切れないかn エイリアス(変数の別名)
n 主にポインタの利用n 右は一見データ独立でも…n foo(&a[0],&a[1]) のような呼び出しをすればデータ独立でない!
n 不明瞭な書き込み参照先n インデックス計算
n 計算結果がループ変数に対して独立かどうかわからない
n Fortranでも、多次元配列を一次元化すると起こる
n 逆にCでも、多次元配列を使えば独立性を見切れる
n 間接参照50
void foo(float *a, float *b){for (int i=0; i<N; i++)
b[i] = a[i];}
これってデータ独立?
for (int i=0; i<N; i++){j = i % 10;b[j] = a[i];
}
インデックス計算
for (int i=0; i<N; i++){b[idx[i]] = a[i];
}
間接参照

簡単なOpenACC: loop 指示文(1)n 04_loopコード
ü 03_kernelsコードにloop independent の追加
51
void calc(unsigned int nx, unsigned int ny, const float *a, const float *b, float *c){const unsigned int n = nx * ny;
#pragma acc kernels copy(a[0:n], b[0:n], c[0:n])#pragma acc loop independent
for (unsigned int j=0; j<ny; j++) {#pragma acc loop independent
for (unsigned int i=0; i<nx; i++) {const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}}
}
openacc_basic/04_loop
// main 関数内#pragma acc kernels copyout(b[0:n], c[0:n])
{#pragma acc loop independent
for (unsigned int i=0; i<n; i++) {b[i] = b0;
}#pragma acc loop independent
for (unsigned int i=0; i<n; i++) {c[i] = 0.0;
}}
C

簡単なOpenACC: loop 指示文(1)n 04_loopコード
ü 03_kernelsコードにloop independent の追加
52
subroutine calc(nx, ny, a, b, c)...
!$acc kernels copyin(a,b) copyout(c)!$acc loop independent
do j = 1,ny!$acc loop independent
do i = 1,nxc(i,j) = a(i,j) + b(i,j)
end doend do
!$acc end kernelsend subroutine
openacc_basic/04_loop
! main 関数内!$acc kernels copyout(b,c)!$acc loop independent
do j = 1,ny!$acc loop independent
do i = 1,nxb(i,j) = b0
end doend do
c(:,:) = 0.0!$acc end kernels
F
各次元についてloop指示文を指定する(並列サイズなどを指定したいなど)場合、do文で書き下す必要がある。

簡単なOpenACC: loop 指示文(2)n コンパイル
ü ループが並列化され、カーネルが生成された。
53
$ make pgcc -O3 -acc -Minfo=accel -ta=tesla,cc60 -c main.ccalc:
13, Generating copy(a[:n],c[:n],b[:n])15, Loop is parallelizable17, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code15, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */17, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */
main:45, Generating copyout(c[:n],b[:n])48, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code48, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
52, Loop is parallelizableAccelerator kernel generatedGenerating Tesla code52, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
openacc_basic/04_loop
C
※Fortran版は既に並列化されていたため省略。loopindependentをつける事による挙動の変化はない。(少なくともPGIcompilerver.18.7では)

簡単なOpenACC: loop 指示文(3)n 04_loopコードの実行
ü 答えは正しいが、実行時間が大変長い。
ü ソースコードをみると、calc関数でカーネル前後にGPUとCPU間のデータ転送が発生する。これが性能低下させている。
54
$ qsub ./run.sh$ cat run.sh.o??????mean = 3000.00Time = 70.414 [sec]
openacc_basic/04_loop
void calc(unsigned int nx, unsigned int ny, const float *a, const float *b, float *c){const unsigned int n = nx * ny;
#pragma acc kernels copy(a[0:n], b[0:n], c[0:n])#pragma acc loop independent
for (unsigned int j=0; j<ny; j++) {#pragma acc loop independent
for (unsigned int i=0; i<nx; i++) {const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}}
}
allocate, H -> D
D->H, deallocate

簡単なOpenACC: data指示文(1)n 05_dataコード
ü 04_loopにdata指示文追加
ü copy/copyin/copyout/create は既にデバイス上確保されているデータに対しては何もしない。present として振舞う。(OpenACC2.5以降)
ü 配列 a, b, c は利用用途に合わせた指示節を指定。 55
// main関数内#pragma acc data copyin(a[0:n]) create(b[0:n]) copyout(c[0:n])
{#pragma acc kernels copyout(b[0:n], c[0:n])
{#pragma acc loop independent
for (unsigned int i=0; i<n; i++) {b[i] = b0;
}#pragma acc loop independent
for (unsigned int i=0; i<n; i++) {c[i] = 0.0;
}}
for (unsigned int icnt=0; icnt<nt; icnt++) {calc(nx, ny, a, b, c);
}}
openacc_basic/05_data
present として振舞う。
a: allocate, H -> Db: allocatec: allocate
a: deallocateb: deallocatec: D->H, deallocate
C

簡単なOpenACC: data指示文(1)n 05_dataコード
ü 04_loopにdata指示文追加
ü copy/copyin/copyout/create は既にデバイス上確保されているデータに対しては何もしない。present として振舞う。(OpenACC2.5以降)
ü 配列 a, b, c は利用用途に合わせた指示節を指定。 56
! main関数内!$acc data copyin(a) create(b) copyout(c)!$acc kernels copyout(b,c)!$acc loop independent
do j = 1,ny!$acc loop independent
do i = 1,nxb(i,j) = b0
end doend do
c(:,:) = 0.0!$acc end kernels
do icnt = 1,ntcall calc(nx, ny, a, b, c)
end do
!$acc end data
openacc_basic/05_data
present として振舞う。
a: allocate, H -> Db: allocatec: allocate
a: deallocateb: deallocatec: D->H, deallocate
F
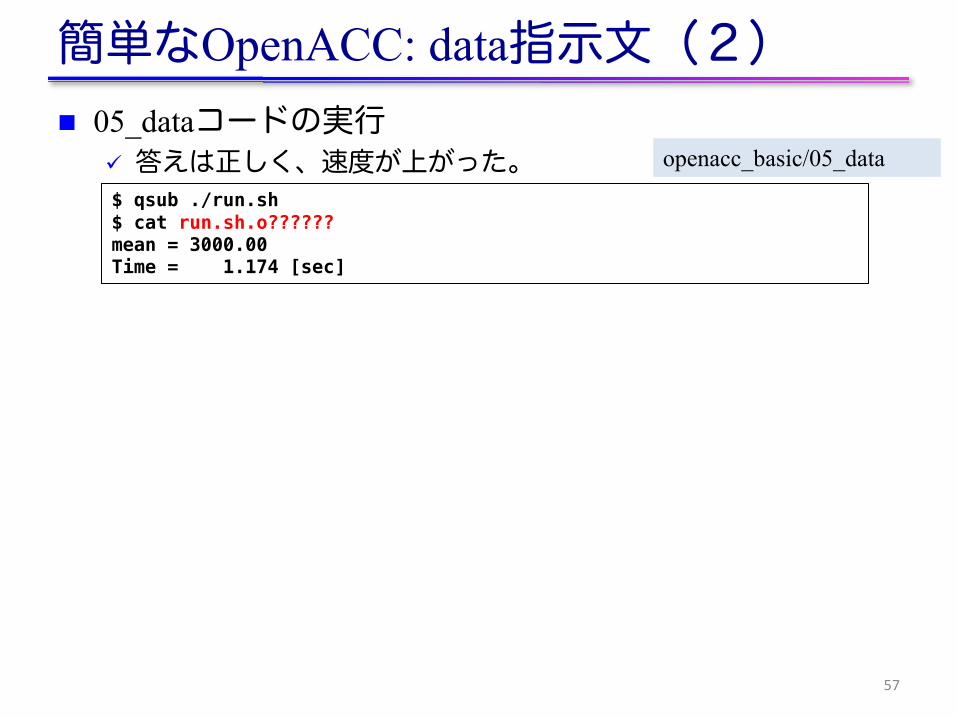
簡単なOpenACC: data指示文(2)n 05_dataコードの実行
ü 答えは正しく、速度が上がった。
57
$ qsub ./run.sh$ cat run.sh.o??????mean = 3000.00Time = 1.174 [sec]
openacc_basic/05_data
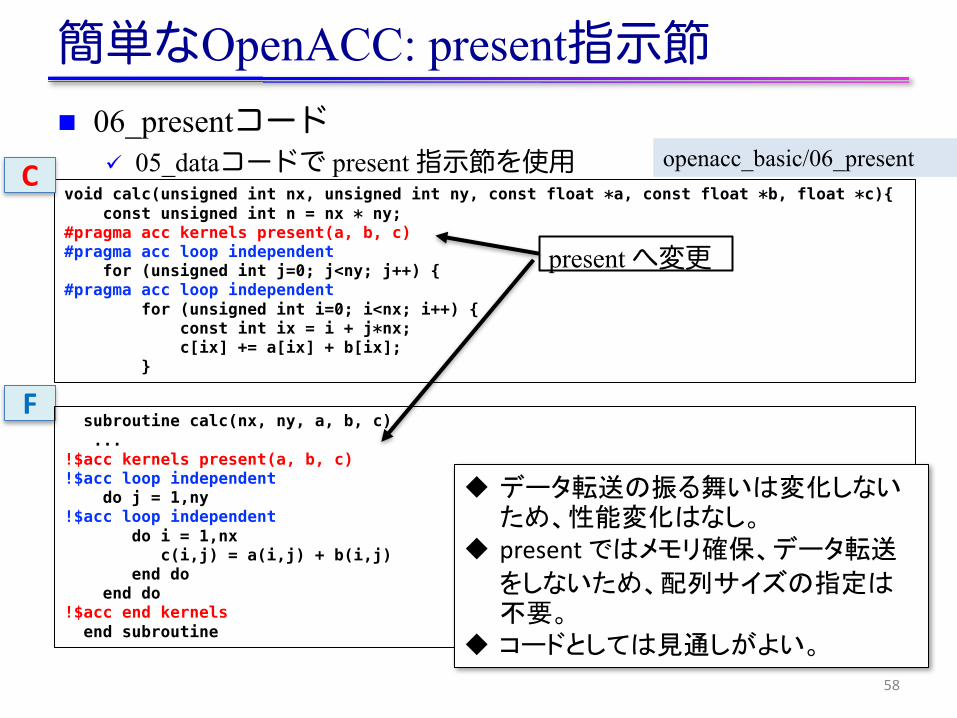
簡単なOpenACC: present指示節n 06_presentコード
ü 05_dataコードで present 指示節を使用
58
void calc(unsigned int nx, unsigned int ny, const float *a, const float *b, float *c){const unsigned int n = nx * ny;
#pragma acc kernels present(a, b, c)#pragma acc loop independent
for (unsigned int j=0; j<ny; j++) {#pragma acc loop independent
for (unsigned int i=0; i<nx; i++) {const int ix = i + j*nx;c[ix] += a[ix] + b[ix];
}
openacc_basic/06_present
present へ変更
C
Fsubroutine calc(nx, ny, a, b, c)...
!$acc kernels present(a, b, c) !$acc loop independent
do j = 1,ny!$acc loop independent
do i = 1,nxc(i,j) = a(i,j) + b(i,j)
end doend do
!$acc end kernelsend subroutine
u データ転送の振る舞いは変化しないため、性能変化はなし。
u presentではメモリ確保、データ転送をしないため、配列サイズの指定は不要。
u コードとしては見通しがよい。

リダクション計算(1)n リダクション計算
ü 配列の全要素から一つの値を抽出ü 総和、総積、最大値、最小値などü 出力が一つのため、並列化に工夫が必要(CUDAでの実装は煩雑)
59
double sum = 0.0;for (unsigned int i=0; i<n; i++) {
sum += array[i];}
321
24156
654 987
6 15 24
45
1. 各スレッドが担当する領域をリダクション
2. 一時配列に移動3. 一時配列をリダクショ
ン4. 出力を得る
スレッド1 スレッド2 スレッド3

リダクション計算(2)n loop 指示文に reduction 指示節を指定
ü reduction 演算子と変数を組み合わせて指定
n Reduction 指示節ü acc loop reduction(+:sum)
ü 演算子と対象とする変数(スカラー変数)を指定する。n 利用できる主な演算子と初期値
ü 演算子: +, 初期値: 0ü 演算子: *, 初期値: 1ü 演算子: max, 初期値: leastü 演算子: min, 初期値: largest
60
double sum = 0.0;#pragma acc kernels#pragma acc loop reduction(+:sum)for (unsigned int i=0; i<n; i++) {
sum += array[i];}

簡単なOpenACC: reduction指示節(1)n 07_reductionコード
ü 06_presentコードで reductionを使用
ü data 指示文で c を create に変更。n 07_reductionコード
ü リダクションコードが生成された。
61
openacc_basic/07_reduction// main 関数内
for (unsigned int icnt=0; icnt<nt; icnt++) {calc(nx, ny, a, b, c);
}
#pragma acc kernels#pragma acc loop reduction(+:sum)
for (unsigned int i=0; i<n; i++) {sum += c[i];
}
$ make pgcc -O3 -acc -Minfo=accel -ta=tesla,cc60 -c main.c(省略)main:(省略)67, Loop is parallelizable
Accelerator kernel generatedGenerating Tesla code67, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
Generating reduction(+:sum)
C

簡単なOpenACC: reduction指示節(1)n 07_reductionコード
ü 06_presentコードで reductionを使用
ü data 指示文で c を create に変更。n 07_reductionコード
ü リダクションコードが生成された。
62
openacc_basic/07_reductionsum = 0
!$acc kernels present(c)!$acc loop reduction(+:sum)
do j = 1,ny!$acc loop reduction(+:sum)
do i = 1,nxsum = sum + c(i,j)
end doend do
!$acc end kernels
$ make pgfortran -O3 -mp -acc -ta=tesla,cc60 -Minfo=accel -c main.f90(省略)main:(省略)
86, Loop is parallelizableAccelerator kernel generatedGenerating Tesla code84, !$acc loop gang, vector(4) ! blockidx%y threadidx%y86, !$acc loop gang, vector(32) ! blockidx%x threadidx%x
Generating reduction(+:sum)
F
並列ループ毎にreduction
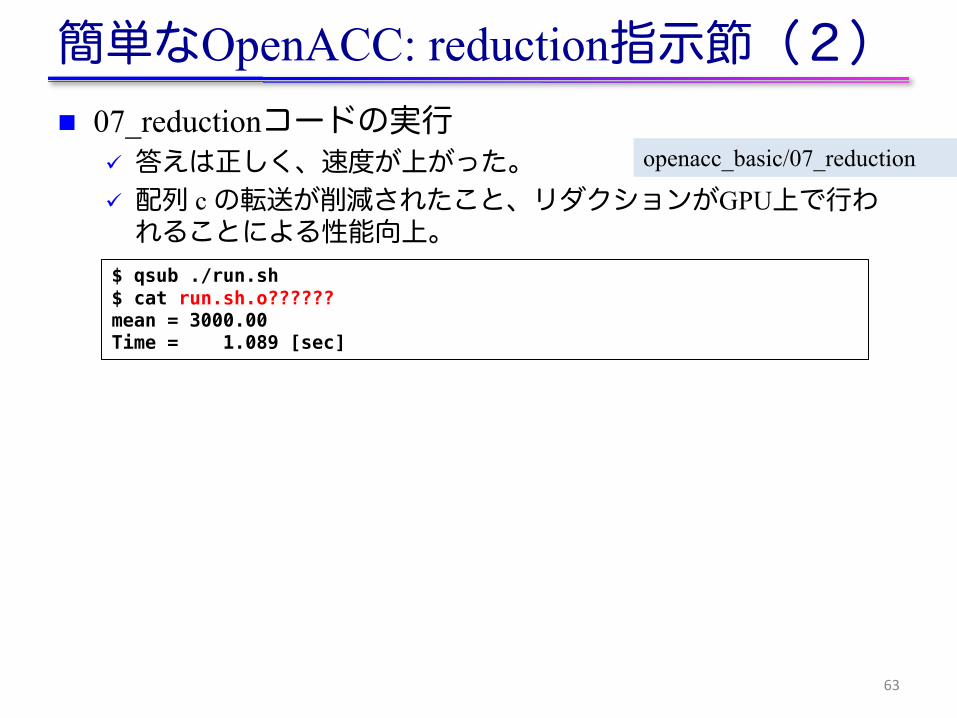
簡単なOpenACC: reduction指示節(2)n 07_reductionコードの実行
ü 答えは正しく、速度が上がった。ü 配列 c の転送が削減されたこと、リダクションがGPU上で行われることによる性能向上。
63
$ qsub ./run.sh$ cat run.sh.o??????mean = 3000.00Time = 1.089 [sec]
openacc_basic/07_reduction

OpenACC化のステップのまとめn OpenACC化のための3つの指示文の適用
ü kernels 指示文を用いてGPUで実行する領域を指定ü data 指示文を用い、ホスト-デバイス間の通信を最適化ü loop 指示文を用い、並列処理の指定
64
#pragma acc data copyin(a[0:n]) create(b[0:n], c[0:n]){
#pragma acc kernels{
#pragma acc loop independentfor (unsigned int i=0; i<n; i++) {
b[i] = b0;}
#pragma acc loop independentfor (unsigned int i=0; i<n; i++) {
c[i] = 0.0;}
}
for (unsigned int icnt=0; icnt<nt; icnt++) {calc(nx, ny, a, b, c);
}
#pragma acc kernels#pragma acc loop reduction(+:sum)
for (unsigned int i=0; i<n; i++) {sum += c[i];
}} openacc_basic/07_reduction
C

OpenACC化のステップのまとめn OpenACC化のための3つの指示文の適用
ü kernels 指示文を用いてGPUで実行する領域を指定ü data 指示文を用い、ホスト-デバイス間の通信を最適化ü loop 指示文を用い、並列処理の指定
65
!$acc data copyin(a) create(b,c)!$acc kernels present(b,c)!$acc loop independent
do j = 1,ny!$acc loop independent
do i = 1,nxb(i,j) = b0
end doend do
c(:,:) = 0.0!$acc end kernels
do icnt = 1,ntcall calc(nx, ny, a, b, c)
end do!続く
openacc_basic/07_reduction
F
!続き
sum = 0!$acc kernels present(c)!$acc loop reduction(+:sum)
do j = 1,ny!$acc loop reduction(+:sum)
do i = 1,nxsum = sum + c(i,j)
end doend do
!$acc end kernels!$acc end data

OPENACC入門実習
66

実習n 3次元拡散方程式のOpenACC化
ü サンプルコード: openacc_diffusion/01_original
n 3次元拡散方程式のCPUコードにOpenACC の kernels, data,loop 指示文を追加し、GPUで高性能で実行しましょう。
67
for(int k = 0; k < nz; k++) {for (int j = 0; j < ny; j++) {
for (int i = 0; i < nx; i++) {const int ix = nx*ny*k + nx*j + i;const int ip = i == nx - 1 ? ix : ix + 1;const int im = i == 0 ? ix : ix - 1;const int jp = j == ny - 1 ? ix : ix + nx;const int jm = j == 0 ? ix : ix - nx;const int kp = k == nz - 1 ? ix : ix + nx*ny;const int km = k == 0 ? ix : ix - nx*ny;
fn[ix] = cc*f[ix] + ce*f[ip] + cw*f[im] + cn*f[jp] + cs*f[jm] + ct*f[kp] + cb*f[km];
}}
}
diffusion.c, diffusion3d 関数内
openacc_diffusion/01_original
C

実習n 3次元拡散方程式のOpenACC化
ü サンプルコード: openacc_diffusion/01_original
n 3次元拡散方程式のCPUコードにOpenACC の kernels, data,loop 指示文を追加し、GPUで高性能で実行しましょう。
68
do k = 1, nzdo j = 1, ny
do i = 1, nx
w = -1; e = 1; n = -1; s = 1; b = -1; t = 1;if(i == 1) w = 0if(i == nx) e = 0if(j == 1) n = 0if(j == ny) s = 0if(k == 1) b = 0if(k == nz) t = 0fn(i,j,k) = cc * f(i,j,k) + cw * f(i+w,j,k) &
+ ce * f(i+e,j,k) + cs * f(i,j+s,k) + cn * f(i,j+n,k) &+ cb * f(i,j,k+b) + ct * f(i,j,k+t)
end doend do
end do
diffusion.f90, diffusion3d 関数内
openacc_diffusion/01_original
F

拡散現象シミュレーション(1)n 拡散現象
ü コップの中に赤インクを落とすと水中で拡がるü 次第に拡散し赤インクは拡がり、最後は均一な色になる。
n 拡散方程式のシミュレーションü 各点のインク濃度の時間変化を計算する
69

n データ構造ü 計算したい空間を格子に区切り、一般に配列で表す。ü 計算は3次元であるが、C言語では1次元配列として確保することが一般的。
ü 2ステップ分の配列を使い、タイムステップを進める(ダブルバッファ)。
n サンプルコードは、ü 計算領域: nx * ny * nz (3次元)ü 最大タイムステップ: ntとなっている。
拡散現象シミュレーション(2)
70
t = n t = n+1t = n+2
t = n+3
時間ステップを進める

拡散現象シミュレーション(3)n 2次元拡散方程式の離散化の一例
7171
0 0
0 64
0
0
0
0
0
0
0 0
0 0
0 00 0 0
0 00 0 0
0
最初の状態
0 0
0 32
0
0
0
8
8
0 0
0 0
8 0
0 80 0 0
0 00 0 0
1回目の平均後
0 1
1 20
2
0
0
8
8
0 0
2 0
8 1
0 82 2 0
0 10 0 0
2回目の平均後
自分自身の値の4倍上下左右の値平均後の自分自身の値
1 2 3 4 5繰り返し平均化を行うと、インクが拡散します。
1
2
3
4
5
j
i

拡散現象シミュレーション(4)n 2次元拡散方程式の計算例
72

CPUコードn CPUコードのコンパイルと実行
n OpenACCコードでは、どのくらいの実行性能が達成できるでしょうか?
73
$ cd openacc_diffusion/01_original$ make$ qsub ./run.sh# cat run.sh.o??????time( 0) = 0.00000time( 100) = 0.00610time( 200) = 0.01221...time(1000) = 0.06104time(1100) = 0.06714time(1200) = 0.07324time(1300) = 0.07935time(1400) = 0.08545time(1500) = 0.09155time(1600) = 0.09766Time = 20.564 [sec]Performance= 2.17 [GFlops]Error[128][128][128] = 4.556413e-06
実行性能解析解との誤差

OpenACC化(0): Makefile の修正n Makefile に OpenACC をコンパイルするよう –acc などを追加しましょう
74
CC = pgccCXX = pgc++GCC = gccRM = rm -fMAKEDEPEND = makedepend
CFLAGS = -O3 -acc -Minfo=accel -ta=tesla,cc60GFLAGS = -Wall -O3 -std=c99CXXFLAGS = $(CFLAGS)LDFLAGS =...
F90 = pgfortranRM = rm -f
FFLAGS = -O3 -mp -acc -ta=tesla,cc60 -Minfo=accel...
C
F

OpenACC化(1): kernelsn diffusion3d関数に kernelsを追加しましょう
75
#pragma acc kernels copyin(f[0:nx*ny*nz]) copyout(fn[0:nx*ny*nz])for(int k = 0; k < nz; k++) {
for (int j = 0; j < ny; j++) {for (int i = 0; i < nx; i++) {
const int ix = nx*ny*k + nx*j + i;const int ip = i == nx - 1 ? ix : ix + 1;const int im = i == 0 ? ix : ix - 1;const int jp = j == ny - 1 ? ix : ix + nx;const int jm = j == 0 ? ix : ix - nx;const int kp = k == nz - 1 ? ix : ix + nx*ny;const int km = k == 0 ? ix : ix - nx*ny;
fn[ix] = cc*f[ix] + ce*f[ip] + cw*f[im] + cn*f[jp] + cs*f[jm] + ct*f[kp] + cb*f[km];
}}
}
return (double)(nx*ny*nz)*13.0;}
make して実行してみましょう。
diffusion.c, diffusion3d 関数内
C

!$acc kernels copyin(f) copyout(fn)do k = 1, nz
do j = 1, nydo i = 1, nx
w = -1; e = 1; n = -1; s = 1; b = -1; t = 1;if(i == 1) w = 0if(i == nx) e = 0if(j == 1) n = 0if(j == ny) s = 0if(k == 1) b = 0if(k == nz) t = 0fn(i,j,k) = cc * f(i,j,k) + cw * f(i+w,j,k) &
+ ce * f(i+e,j,k) + cs * f(i,j+s,k) + cn * f(i,j+n,k) &+ cb * f(i,j,k+b) + ct * f(i,j,k+t)
end doend do
end do!$acc end kernels
OpenACC化(1): kernelsn diffusion3d関数に kernelsを追加しましょう
76
make して実行してみましょう。
diffusion.f90, diffusion3d 関数内
F

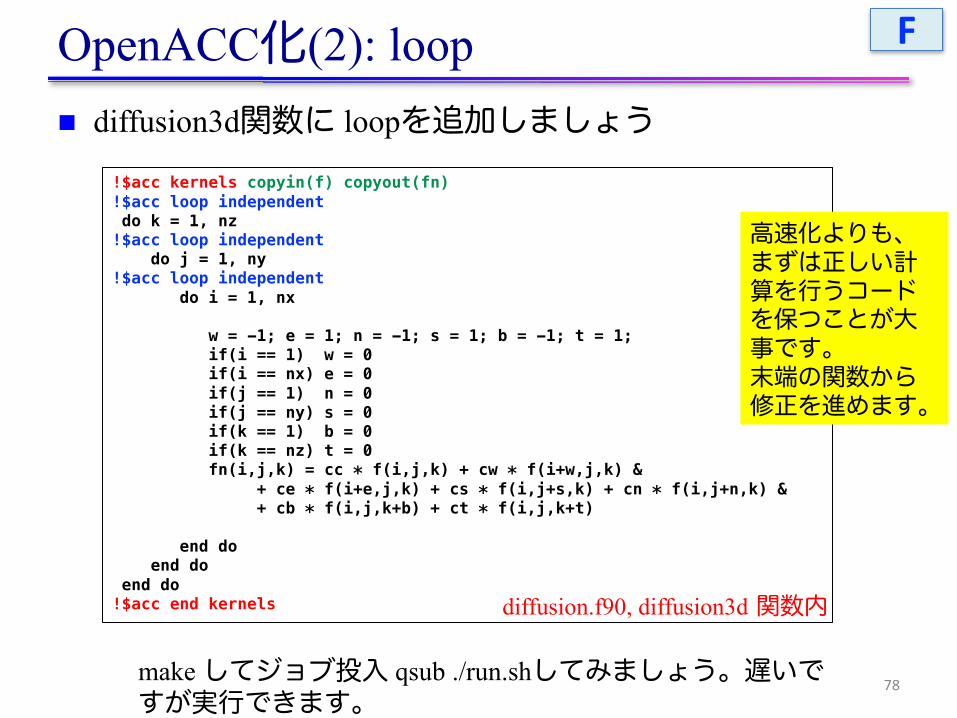
OpenACC化(2): loopn diffusion3d関数に loopを追加しましょう
77
#pragma acc kernels copyin(f[0:nx*ny*nz]) copyout(fn[0:nx*ny*nz])#pragma acc loop independent
for(int k = 0; k < nz; k++) {#pragma acc loop independent
for (int j = 0; j < ny; j++) {#pragma acc loop independent
for (int i = 0; i < nx; i++) {const int ix = nx*ny*k + nx*j + i;const int ip = i == nx - 1 ? ix : ix + 1;const int im = i == 0 ? ix : ix - 1;const int jp = j == ny - 1 ? ix : ix + nx;const int jm = j == 0 ? ix : ix - nx;const int kp = k == nz - 1 ? ix : ix + nx*ny;const int km = k == 0 ? ix : ix - nx*ny;
fn[ix] = cc*f[ix] + ce*f[ip] + cw*f[im] + cn*f[jp] + cs*f[jm] + ct*f[kp] + cb*f[km];
}}
}
return (double)(nx*ny*nz)*13.0;}
make してジョブ投入 qsub ./run.shしてみましょう。遅いですが実行できます。
diffusion.c, diffusion3d 関数内
高速化よりも、まずは正しい計算を行うコードを保つことが大事です。末端の関数から修正を進めます。
C
OpenACC化(2): loopn diffusion3d関数に loopを追加しましょう
78make してジョブ投入 qsub ./run.shしてみましょう。遅いですが実行できます。
!$acc kernels copyin(f) copyout(fn)!$acc loop independentdo k = 1, nz
!$acc loop independentdo j = 1, ny
!$acc loop independentdo i = 1, nx
w = -1; e = 1; n = -1; s = 1; b = -1; t = 1;if(i == 1) w = 0if(i == nx) e = 0if(j == 1) n = 0if(j == ny) s = 0if(k == 1) b = 0if(k == nz) t = 0fn(i,j,k) = cc * f(i,j,k) + cw * f(i+w,j,k) &
+ ce * f(i+e,j,k) + cs * f(i,j+s,k) + cn * f(i,j+n,k) &+ cb * f(i,j,k+b) + ct * f(i,j,k+t)
end doend do
end do!$acc end kernels
高速化よりも、まずは正しい計算を行うコードを保つことが大事です。末端の関数から修正を進めます。
F
diffusion.f90, diffusion3d 関数内

OpenACC化(3): データ転送の最適化(1)n diffusion3d関数で present とし、main関数で data を追加
79
#pragma acc kernels present(f, fn)#pragma acc loop independent
for(int k = 0; k < nz; k++) {#pragma acc loop independent
for (int j = 0; j < ny; j++) {#pragma acc loop independent
for (int i = 0; i < nx; i++) {const int ix = nx*ny*k + nx*j + i;const int ip = i == nx - 1 ? ix : ix + 1;const int im = i == 0 ? ix : ix - 1;const int jp = j == ny - 1 ? ix : ix + nx;const int jm = j == 0 ? ix : ix - nx;const int kp = k == nz - 1 ? ix : ix + nx*ny;const int km = k == 0 ? ix : ix - nx*ny;
fn[ix] = cc*f[ix] + ce*f[ip] + cw*f[im] + cn*f[jp] + cs*f[jm] + ct*f[kp] + cb*f[km];
}}
}
return (double)(nx*ny*nz)*13.0;}
diffusion.c, diffusion3d 関数内
なお、 present にしなくても期待通りに動作します。
C

OpenACC化(3): データ転送の最適化(1)n diffusion3d関数で present とし、main関数で data を追加
80
diffusion.f90, diffusion3d 関数内
なお、 present にしなくても期待通りに動作します。
F
!$acc kernels copyin(f) copyout(fn)!$acc loop independentdo k = 1, nz
!$acc loop independentdo j = 1, ny
!$acc loop independentdo i = 1, nx
w = -1; e = 1; n = -1; s = 1; b = -1; t = 1;if(i == 1) w = 0if(i == nx) e = 0if(j == 1) n = 0if(j == ny) s = 0if(k == 1) b = 0if(k == nz) t = 0fn(i,j,k) = cc * f(i,j,k) + cw * f(i+w,j,k) &
+ ce * f(i+e,j,k) + cs * f(i,j+s,k) + cn * f(i,j+n,k) &+ cb * f(i,j,k+b) + ct * f(i,j,k+t)
end doend do
end do!$acc end kernels

OpenACC化(4): データ転送の最適化(2)n diffusion3d関数で present とし、main関数で data を追加
81
#pragma acc data copy(f[0:n]) create(fn[0:n]){
start_timer();
for (; icnt<nt && time + 0.5*dt < 0.1; icnt++) {if (icnt % 100 == 0)
fprintf(stdout, "time(%4d) = %7.5f¥n", icnt, time);
flop += diffusion3d(nx, ny, nz, dx, dy, dz, dt, kappa, f, fn);
swap(&f, &fn);
time += dt;}
elapsed_time = get_elapsed_time();}
copy/create など適切なものを選びます。make して実行してみましょう。どのくらいの実行性能が出ましたか?OpenACC化の例は、
main.c, main 関数内
openacc_diffusion/02_openacc
C

OpenACC化(4): データ転送の最適化(2)n diffusion3d関数で present とし、main関数で data を追加
82
!$acc data copy(f) create(fn)call start_timer()
do icnt = 0, nt-1if(mod(icnt,100) == 0) write (*,"(A5,I4,A4,F7.5)"), "time(",icnt,") = ",time
flop = flop + diffusion3d(nx, ny, nz, dx, dy, dz, dt, kappa, f, fn)
call swap(f, fn)
time = time + dtif(time + 0.5*dt >= 0.1) exit
end do
elapsed_time = get_elapsed_time()!$acc end data
copy/create など適切なものを選びます。make して実行してみましょう。どのくらいの実行性能が出ましたか?OpenACC化の例は、
main.f90, main 関数内
openacc_diffusion/02_openacc
F

PGI_ACC_TIME によるOpenACC 実行の確認n PGIコンパイラを利用する場合、OpenACCプログラムがどのように
実行されているか、環境変数PGI_ACC_TIMEを設定すると簡単に確認することができる。
n Linuxなどでは、環境変数PGI_ACC_TIME を1に設定し、プログラムを実行する。$ export PGI_ACC_TIME=1$ ./run
n Reedbush でジョブに環境変数PGI_ACC_TIME を設定する場合は、ジョブスクリプト中に記載する。$ cat run.sh.... /etc/profile.d/modules.shmodule load pgi/18.7export PGI_ACC_TIME=1
./run
83openacc_diffusion/03_openacc _pgi_acc_timeサンプルコードは、

PGI_ACC_TIME によるOpenACC 実行の確認n ジョブ実行が終わると、標準エラー出力にメッセージが出力される。
84
$ cat run.sh.e??????Accelerator Kernel Timing data/lustre/pz0115/z30115/lecture/lecture_samples/openacc_diffusion/03_openacc_pgi_acc_time/main.c
main NVIDIA devicenum=0time(us): 6,35938: data region reached 2 times
38: data copyin transfers: 1device time(us): total=3,327 max=3,327 min=3,327 avg=3,327
55: data copyout transfers: 1device time(us): total=3,032 max=3,032 min=3,032 avg=3,032
/lustre/pz0115/z30115/lecture/lecture_samples/openacc_diffusion/03_openacc_pgi_acc_time/diffusion.c
diffusion3d NVIDIA devicenum=0time(us): 101,73119: compute region reached 1638 times
25: kernel launched 1638 timesgrid: [4x128x32] block: [32x4]device time(us): total=101,731 max=64 min=62 avg=62
elapsed time(us): total=136,255 max=540 min=81 avg=8319: data region reached 3276 times
データ移動の回数
起動したスレッド カーネル実行時間

OpenACCによるICCGソルバーの並列化
85

ICCGソルバーのOpenACC化(1)n 実習コード: openacc_iccg/
ü 基本的にはOpenMPパートで使ったコードと同一です。ü 一部バグフィクスが入っています。ü INPUT.dat の内容を実行時引数で上書きできるように改変しています。(input.c/f 内、input_commandline 関数参照)
ü ソースコードと同じフォルダに実行ファイル(run)が作られます。
86
openacc_iccg/01_original OpenMPコード。これを改変します。
openacc_iccg/02_setup OpenACC化を行うための準備をしたOpenMPコード。
openacc_iccg/03_unified Unifiedmemory機能を用いたOpenACCコード。(後述)
openacc_iccg/04_data_present Unifiedmemory機能を用いないOpenACCコード。
openacc_iccg/05_exclude_datacpy_time
CPU-GPU間のデータ転送時間を時間計測から除いたOpenACCコード。
openacc_iccg/06_optimized 上をOpenACCで出来る範囲内で最適化OpenACCコード。

CPUコードn ジョブスクリプト
n 実行時引数の意味ü 引数指定なしの場合は、
INPUT.DAT の値が使用される
87
$ cat ./run.sh#! /bin/sh #PBS -q h-lecture#PBS -l select=1:mpiprocs=1:ompthreads=18#PBS -W group_list=gt00#PBS -l walltime=00:05:00
cd $PBS_O_WORKDIR
. /etc/profile.d/modules.shmodule load pgi/18.7
numactl ./run -n 128 -c -20 -nt 18
-nx 128 NX=128
-n128 NX=NY=NZ=128
-c-20 NCOLORtot =-20
-e 1.0e-8 EPSICCG= 1.0e−08
-nt 18 PEsmpTOT =18
openacc_iccg/01_original

CPUコードの実行n 実行結果
88
$ qsub ./run.sh$ cat ./run.sh.o?????### THREAD number= 18
You have 2097152 elements.How many colors do you need ?
#COLOR must be more than 2 and#COLOR must not be more than 2097152CM if #COLOR .eq. 0
RCM if #COLOR .eq.-1CMRCM if #COLOR .le.-2=>color number: 20
### CM-RCM
### FINAL COLOR NUMBER 20
1048364.225619E-01 sec. (assemble)1 1.316128E+01
101 5.322509E-01201 2.774891E-04301 5.453948E-08318 9.298776E-09
N= 20971522.488712E+01 sec. (solver)
openacc_iccg/01_original
収束履歴を見て、OpenACC実装があってるかどうかを判断します。※足し算の順序の変動による桁落ちなどにより、ぴったり同じになるとは限りません。
C版は標準エラーに出力されます。実行結果は run.sh.e???? を見てください

OpenACC化の準備:Makefile の修正
n OpenACC用のMakefileの作成
89
CC = pgccOPTFLAGS= -O3 -mpTARGET = run
F90 = pgfortranF90OPTFLAGS= -O3 –mp…TARGET = run
CC = pgccOPTFLAGS= -O3 -acc -Minfo=accel -ta=tesla:cc60TARGET = run
F90 = pgfortranF90OPTFLAGS= -O3 -acc -Minfo=accel-ta=tesla:cc60…TARGET = run
-Minfo=accelでコンパイラメッセージの出力OpenACCではコンパイラメッセージの確認が極めて重要
openacc_iccg/02_setup
C F

OpenACC化の準備:ジョブスクリプトn run.sh の編集
90
#! /bin/sh#PBS -q u-lecture #PBS -l select=1:mpiprocs=1:ompthreads=18 #PBS -W group_list=gt00 #PBS -l walltime=00:05:00
cd $PBS_O_WORKDIR
. /etc/profile.d/modules.shmodule load pgi/18.7
./run -n 128 -c -20 -nt 18
#! /bin/sh#PBS -q h-lecture #PBS -l select=1:mpiprocs=1:ompthreads=1#PBS -W group_list=gt00 #PBS -l walltime=00:05:00
cd $PBS_O_WORKDIR
. /etc/profile.d/modules.shmodule load pgi/18.7
numactl ./run -n 128 -c -20 -nt 1
openacc_iccg/02_setup
PEsmpTOT で GPU のスレッド数を制御するのは現実的ではないため、PEsmpTOT=1とし、別の方法で制御する。

OpenACC化の準備:変数のサイズ
91
extern intsolve_ICCG_mc(int N, int NL, int NU, int NPL, int NPU, int *indexL, int *itemL, int *indexU, int *itemU, double *D, double *B, double *X, double *AL, double *AU, int NCOLORtot, int PEsmpTOT, int *SMPindex, int *SMPindexG, double EPS, int *ITR, int *IER)
solver_ICCG_mc.c
C
n Cでは配列のサイズ情報が必須となるü NPL, NPU を関数の引数に追加 openacc_iccg/02_setup
main.c
if(solve_ICCG_mc(ICELTOT, NL, NU, NPL, NPU, indexL, itemL, indexU, itemU,D, BFORCE, PHI, AL, AU, NCOLORtot, PEsmpTOT,SMPindex, SMPindexG, EPSICCG, &ITR, &IER)) goto error;
extern intsolve_ICCG_mc(int N, int NL, int NU, int NPL, int NPU, int *indexL, int *itemL, int *indexU, int *itemU, double *D, double *B, double *X, double *AL, double *AU, int NCOLORtot, int PEsmpTOT, int *SMPindex, int *SMPindexG, double EPS, int *ITR, int *IER);
solver_ICCG_mc.h
OpenACCでの並列化戦略
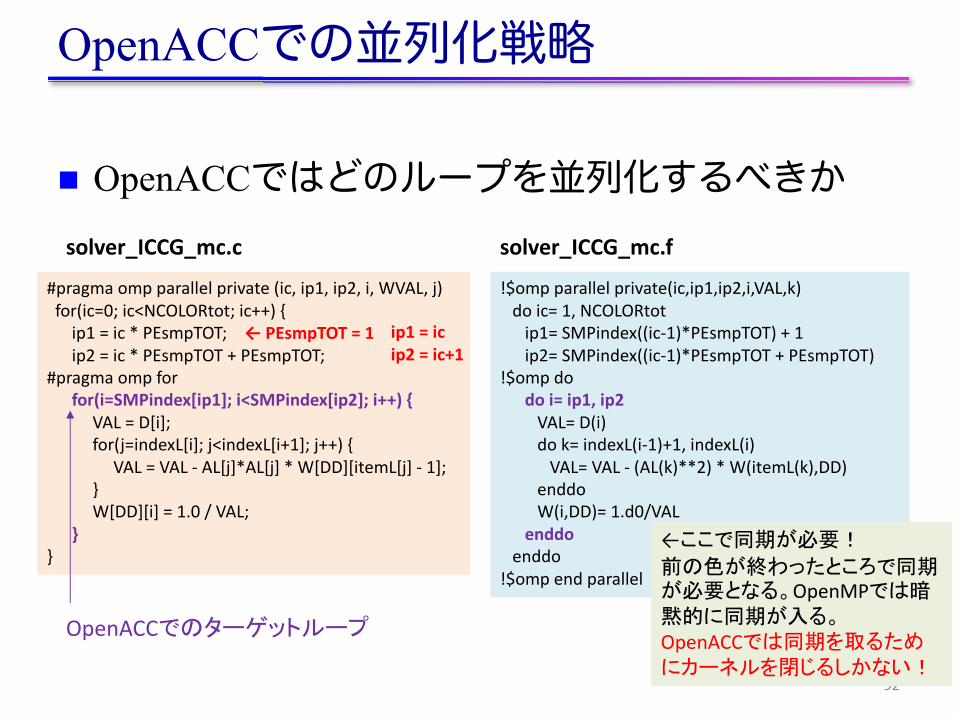
n OpenACCではどのループを並列化するべきか
92
#pragmaompparallelprivate(ic,ip1,ip2,i,WVAL,j)for(ic=0;ic<NCOLORtot;ic++){ip1=ic*PEsmpTOT;ip2=ic*PEsmpTOT+PEsmpTOT;
#pragmaompforfor(i=SMPindex[ip1];i<SMPindex[ip2];i++){
VAL=D[i];for(j=indexL[i];j<indexL[i+1];j++){
VAL=VAL- AL[j]*AL[j]*W[DD][itemL[j]- 1];}W[DD][i]=1.0/VAL;
}}
solver_ICCG_mc.c
!$ompparallelprivate(ic,ip1,ip2,i,VAL,k)doic=1,NCOLORtotip1=SMPindex((ic-1)*PEsmpTOT)+1ip2=SMPindex((ic-1)*PEsmpTOT+PEsmpTOT)
!$ompdodoi=ip1,ip2VAL=D(i)dok=indexL(i-1)+1,indexL(i)VAL=VAL- (AL(k)**2)*W(itemL(k),DD)
enddoW(i,DD)=1.d0/VAL
enddoenddo
!$ompendparallel
solver_ICCG_mc.f
← PEsmpTOT =1 ip1=icip2=ic+1
OpenACCでのターゲットループ
←ここで同期が必要!前の色が終わったところで同期が必要となる。OpenMPでは暗黙的に同期が入る。OpenACCでは同期を取るためにカーネルを閉じるしかない!

OpenACC 指示文の挿入
93
#pragmaompparallelprivate(ic,ip1,ip2,i,WVAL,j)for(ic=0;ic<NCOLORtot;ic++){ip1=ic*PEsmpTOT;ip2=ic*PEsmpTOT+PEsmpTOT;
#pragmaompfor#pragmaacc kernelscopyin(D[0:N],indexL[0:N+1],AL[0:NPL],itemL[0:NPL],SMPindex[0:NCOLORtot*PEsmpTOT])copy(W[0:4][0:N])#pragmaacc loopindependent
for(i=SMPindex[ip1];i<SMPindex[ip2];i++){VAL=D[i];
#pramgaaccloopseqfor(j=indexL[i];j<indexL[i+1];j++){
VAL=VAL- AL[j]*AL[j]*W[DD][itemL[j]- 1];}W[DD][i]=1.0/VAL;
}}
solver_ICCG_mc.c
!$ompparallelprivate(ic,ip1,ip2,i,VAL,k)doic=1,NCOLORtotip1=SMPindex((ic-1)*PEsmpTOT)+1ip2=SMPindex((ic-1)*PEsmpTOT+PEsmpTOT)
!$ompdo!$acc kernelscopyin(D,indexL,AL,itemL)copy(W)!$acc loopindependent
doi=ip1,ip2VAL=D(i)
!$accloopseqdok=indexL(i-1)+1,indexL(i)VAL=VAL- (AL(k)**2)*W(itemL(k),DD)
enddoW(i,DD)=1.d0/VAL
enddo!$accendkernelsenddo
!$ompendparallel
solver_ICCG_mc.f
← PEsmpTOT =1 ip1=icip2=ic+1
配列のサイズを一々書くのめんどくさい! 配列のサイズ情報を書く必要はない
↓このループは短いので逐次計算 (長さ3or6)

サイズ記述をサボる方法1:Unified Memory
n Unified memory とはü CPU のメモリと GPU のメモリをあたかも共有メモリであるかのように見せる機能のことuCPU/GPU のメモリ上でページフォルト(古いデータ領域へのアクセス)が発生すると、自動的にGPU/CPUからデータを転送する
ü NVIDIA GPU の機能。OpenACCの標準機能ではないn OpenACC で使う場合
ü PGI compiler の場合、-ta=tesla,cc60,managed をつけるü Data 指示文が全て無視され、Unified memory 機能にデータ転送を任せるu従って、OpenACC として正しくないプログラムも動いてしまう
ü CPU 側の挙動が極端に遅くなったりする94

Unified Memory を使った OpenACC化
95
n Unified Memory用のMakefileの作成
CC = pgccOPTFLAGS= -O3 –mp -acc -Minfo=accel-ta=tesla:cc60TARGET = run
F90 = pgfortranF90OPTFLAGS= -O3 -acc -Minfo=accel-ta=tesla:cc60…TARGET = run
CC = pgccOPTFLAGS= -O3 -acc -Minfo=accel -ta=tesla:cc60,managedTARGET = run
F90 = pgfortranF90OPTFLAGS= -O3 -acc -Minfo=accel-ta=tesla:cc60,managed…TARGET = run
openacc_iccg/03_unified
C F

Unified Memory を使った OpenACC化
96
#pragma omp parallel for private (i)for(i=0; i<N; i++) {
X[i] = 0.0;W[1][i] = 0.0;W[2][i] = 0.0;W[3][i] = 0.0
}
solver_ICCG_mc.c
!$omp parallel do private(i)do i= 1, N
X(i) = 0.d0W(i,2)= 0.0D0W(i,3)= 0.0D0W(i,4)= 0.0D0W(i,R)= B(i)
enddo
solver_ICCG_mc.f
#pragma omp parallel for private (i)#pragma acc kernels#pragma acc loop independent
for(i=0; i<N; i++) {X[i] = 0.0;W[1][i] = 0.0;W[2][i] = 0.0;W[3][i] = 0.0;
}
!$omp parallel do private(i)!$acc kernels!$acc loop independent
do i= 1, NX(i) = 0.d0W(i,2)= 0.0D0W(i,3)= 0.0D0W(i,4)= 0.0D0W(i,R)= B(i)
enddo!$acc end kernels
kernels と、loop independent / reduction を 挿入しましょう!
openacc_iccg/03_unified

Unified Memory 版の結果チェック
97
### CMRCM
### FINAL COLOR NUMBER 20
4.502711e-01 sec. (assemble)1 1.316128e+01
101 5.322509e-01201 2.774891e-04301 5.456694e-08318 9.277044e-09
N= 20971521.155157e+00 sec. (solver)
run.sh.eXXXXX### CM-RCM
### FINAL COLOR NUMBER 20
1048364.452479E-01 sec. (assemble)1 1.316128E+01
101 5.322509E-01201 2.774891E-04301 5.456694E-08318 9.277044E-09
N= 20971521.052020E+00 sec. (solver)
run.sh.oXXXXX※標準エラー出力
n 収束履歴が概ね一致ü 足し算の順序の違いによる、桁落ちなどが影響
n 正しいことを確かめながら、徐々に OpenACC化することが大事ü Unified memory で結果が合うなら、少なくともデータ転送以外は正しく
実装できているということn GPU で実行されている solver 部分は速いが、CPU 部分が遅い

サイズ記述をサボる方法2:present 指示子
98
#pragma acc enter data ¥copyin(D[:N],indexL[:N+1]) ¥copyin(AL[:NPL],itemL[:NPL],AU[:NPU]) ¥copyin(indexU[:N+1],itemU[:NPU]) ¥copyin(SMPindex[0:NCOLORtot*PEsmpTOT]) ¥create(X[:N],W[:4][:N])
#pragma omp parallel for private (i)#pragma acc kernels present(X,W)#pragma acc loop independent
for(i=0; i<N; i++) {X[i] = 0.0;W[1][i] = 0.0;W[2][i] = 0.0;W[3][i] = 0.0;
}
...
#pragma acc exit data ¥delete(D[:N],indexL[:N+1],W[:4][:N]) ¥delete(AL[:NPL],itemL[:NPL],AU[:NPU]) ¥delete(indexU[:N+1],itemU[:NPU]) ¥delete(SMPindex[0:NCOLORtot*PEsmpTOT]) ¥copyout(X[:N])
solver_ICCG_mc.c!$acc enter data!$acc& copyin(B,D,indexL,itemL)!$acc& copyin(indexU,itemU,AL,AU)!$acc& create(X,W)
!$omp parallel do private(i)!$acc kernels present(X,W,B)!$acc loop independent
do i= 1, NX(i) = 0.d0W(i,2)= 0.0D0W(i,3)= 0.0D0W(i,4)= 0.0D0W(i,R)= B(i)
enddo!$acc end kernels
...
!$acc exit data!$acc& delete(B,D,indexL,itemL) !$acc& delete(indexU,itemU,AL,AU,W)!$acc& copyout(X)
solver_ICCG_mc.f
Data 指示文で転送済にしてしまえば、kernels毎にデータサイズの記述の必要はない
※Makefileからmanegedを外すのを忘れずに
openacc_iccg/04_data_present

実習n EX1:Makefile、ジョブスクリプト、INPUT.datを編集し、CPU実行時の出力を得てください
n EX2:全並列化ループ(OMP DO で並列化されているところ)をOpenACCで並列化してくださいn コンパイラメッセージに注意!n 常にCPUでの結果と突き合わせ!
n 計算順序が変わるため、必ずしも一致しないn この時点で遅くても気にしない!
n EX3:データ転送を最適化してくださいn EX4:ジョブスクリプトを変更し、問題サイズや色数を変化させ、速度への影響をみてくださいn PGI_ACC_TIMEは若干速度に影響を与えるので、計測時はexport PGI_ACC_TIME=0 (ジョブスクリプト)としてください
99

まとめn GPUとOpenACCの基礎についてn ICCGソルバーを題材とし、OpenACC化を行なった
n ICCGソルバーのOpenACC化を通じ、以下を実習したn kernels指示文による並列化n コンパイラメッセージの見方n PGI_ACC_TIMEの出力n データ転送の最適化
100

Q & An アカウントは1ヶ月有効です。
n ぜひご自分のアプリで試してくださいn アンケートへの協力をお願いします。
101