practical recommendations for gradient-based training of deep architectures
DESCRIPTION
Yoshua Bengio, Practical recommendations for gradient-based training of deep architectures, arXiv:1206.5533v2, 2012 の解説TRANSCRIPT

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
.
.
Practical Recommendations forGradient-Based Training of Deep Architectures
~Bengio先生のおすすめレシピ~
Yoshua Bengio
Universit de Montral
すずかけ論文読み会#6 2013/09/21紹介者:matsuda
1 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Outline
...1 勾配
...2 Hyper-Parameters考慮すべきハイパーパラメータハイパーパラメータの最適化
...3 デバッグと可視化Gradient Checking and Controlled OverfittingVisualizations and Statistics
...4 その他Multi-core machines, BLAS and GPUsSparse High-Dimensional Inputs
...5 まとめ
2 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
はじめに
”Neural Networks: Tricks of the Trade”という書籍の (改訂版の)草稿のようです今回はその中の一章,Bengio先生による Deep Learningのおすすめレシピを読み解いていきます
盛りだくさんなので,適宜飛ばします(よくわからないところを飛ばした,とも言います)
基本的に,CAEもしくは DAE(要は,正則化つきAuto-Encoders)を前提としています
RBMsの話もところどころに出てきます人工知能学会誌の Deep Learning特集が参考になりますので,そちらもどうぞ
7月号の麻生先生の記事,9月号の岡野原さんの記事が今回の内容と大きく関連
3 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Auto-Encodersの基本
.
.書こうとして力尽きました.他によい資料がいくらでもありますので,そちらをご覧ください..あらかじめ押さえておくべきこと..
.
NNは Forward-propagation, Back-propagationの二つのステップを繰り返して学習する,ということAuto-Encodersは,与えられたデータ自体を復元するようなネットワークを学習する教師なし学習である,ということAuto-Encodersの学習を Supervisedな学習の前段階として行う,という技術がある (Unsupervised Pre-training)ということ機械学習においては,過学習を抑えるために,正則化というテクニックがよく使われるということ
4 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
DAE/CAE.Auto-Encoders..
.JAE(θ) =
∑x∈D
L(x , g(f (x)))
.Denoising Auto-Encoders..
.
JDAE(θ) =∑x∈D
Ex [L(x , g(f (x)))]
x = x + ε, ε ∼ N(0, σ2)
.Contractive Auto-Encoders..
.JCAE(θ) =
∑x∈D
(L(x , g(f (x))) + λ‖δf (x)
δx‖2F )
※特定の状況において,CAEと DAEはほぼ等価 (前回の復習)5 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Outline
...1 勾配
...2 Hyper-Parameters考慮すべきハイパーパラメータハイパーパラメータの最適化
...3 デバッグと可視化Gradient Checking and Controlled OverfittingVisualizations and Statistics
...4 その他Multi-core machines, BLAS and GPUsSparse High-Dimensional Inputs
...5 まとめ
6 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
勾配の計算
勾配ベース,という場合は,以下のいずれかが用いられる確率的勾配法 (Stochastic Gradient Descent)
θ(t) ← θ(t−1) − εt∂L(zt , θ)
∂θ
ミニバッチ確率的勾配法
θ(t) ← θ(t−1) − εt1B
B(t+1)∑t ′=Bt+1
∂L(zt ′ , θ)
∂θ.
ミニバッチにおいて B = 1とした場合はふつうの SGD, B =データ数とした場合は (確率的ではない)勾配法
7 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
勾配の計算
NNはさまざまな「層」の組み合わせChain-Ruleを用いて,層ごとに勾配を計算すればよいのがポイント層をブロックのように組み合わせてネットワークを作ることができる
ブロックに対しては,あらかじめ損失と勾配がどのような形をしているのか計算しておくことができる
ブロックを提供しているライブラリがいろいろあるので,それを使おう
Torch, Lush, TheanoなどTheanoは記号微分が実装されている
8 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Theanoの例 (記号微分)
雰囲気をつかむための超簡単な例:
δ(x2)
δx= 2x
.Python Code..
.
from theano import ppx = T.dscalar(’x’) # xの関数であることを宣言y = x ** 2gy = T.grad(y, x) # yを xで微分 => x * 2f = function([x], gy)f(4) # => 8.0
9 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Torchで 10行ニューラルネット.Torch Lua Code..
.
require "nn"mlp=nn.Sequential(); #多層パーセプトロンinputs=2; outputs=1; HUs=20;mlp:add(nn.Linear(inputs,HUs)) #層の定義mlp:add(nn.Tanh())mlp:add(nn.Linear(HUs,outputs))criterion = nn.MSECriterion() #損失関数trainer = nn.StochasticGradient(mlp, criterion)trainer.learningRate = 0.01trainer:train(dataset) # SGDで学習
Torchにはさまざまな層,損失関数が用意されているSoftMax, Sigmoid, Tanh, HardTanh, Convolution, etc...MSECriterion, MarginRankingCriterion, etc...
10 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Outline
...1 勾配
...2 Hyper-Parameters考慮すべきハイパーパラメータハイパーパラメータの最適化
...3 デバッグと可視化Gradient Checking and Controlled OverfittingVisualizations and Statistics
...4 その他Multi-core machines, BLAS and GPUsSparse High-Dimensional Inputs
...5 まとめ
11 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
ハイパーパラメータのいろいろ
.最適化のためのパラメータ..
.
学習率 (初期値,減衰)ミニバッチのサイズイテレーション回数Momentum
.モデル自身のパラメータ..
.
隠れ層のユニット数重みの正則化ユニットの (アクティベーションの)スパース化活性化関数の選択
.その他..
.
重みの初期化 (のスケール)乱数前処理
12 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
最適化のためのパラメータ
学習率の初期値 ε010−6から 1の間に設定,0.1くらいがデフォルト.後述するようにかなり重要なパラメータなので,最適化すべき.学習率のスケジューリング εtO(1/tα)で減少するようスケジューリング.α < 1(O(1/t)より若干緩やか)がおおよその目安.
εt =ε0τ
max(t , τ)
上記のように,最初の τ イテレーションは減衰させず,その後減衰させるとよい,という報告もある (Bergstra andBengio, 2012)
13 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
最適化のためのパラメータ
ミニバッチのサイズ B32くらいが経験的によく,あまり調節の必要はないらしいイテレーション回数 Tvalidation-setを使って,validation-errorが減少しなくなったら止める (Early Stopping)ただし,errorを毎回測るのは無駄なので,ときどきでよい.Momentum β (Polyak and Juditsky, 1992)勾配自体を過去の平均と混ぜる (慣性をつけるイメージ)
g ← (1− β)g + βg
多くのケースでは β = 1(Momentumなし)でよいが,チューニングしたほうが良い場合も
14 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
モデル自身のパラメータ
.
.
隠れユニット数 (ネットワークの構造)重みの正則化 (Weight Decay)アクティベーションのスパース化活性化関数の選択
15 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
ネットワークの構造
過学習への対処が適切であれば,隠れ層のユニット数は基本的に「多いほど良い」ネットワークの構造は,各層が同じサイズで良い場合が多い(Larochelle et al., 2009) (ピラミッド or逆ピラミッドである必要はない)Unsupervised Pre-trainingを行う際は,純 Supervisedに比べて多くしたほうが良い (10倍とか)
Pre-trainingの段階においては,target-taskが分からないため,データの分布それ自体を学習しなければならない (高い表現力が要求される)単なる Supervisedな NNであれば,target-taskに対する損失を最小化すればよいため,比較的表現力が低くてもよい
16 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
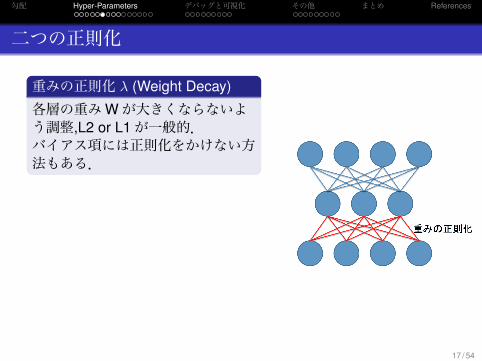
二つの正則化
.重みの正則化 λ (Weight Decay)..
.
各層の重みWが大きくならないよう調整,L2 or L1が一般的.バイアス項には正則化をかけない方法もある.
.アクティベーションのスパース化(Ranzato et al., 2007)など..
.
隠れ層がスパースになるよう,活性化関数を調整する→脳内のニューロンの発火はスパースである,という観察(sparse coding, sparseauto-encoder)
17 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
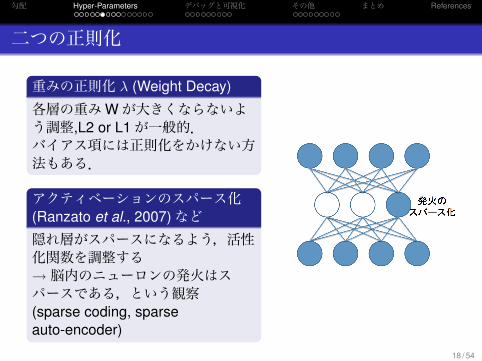
二つの正則化
.重みの正則化 λ (Weight Decay)..
.
各層の重みWが大きくならないよう調整,L2 or L1が一般的.バイアス項には正則化をかけない方法もある..アクティベーションのスパース化(Ranzato et al., 2007)など..
.
隠れ層がスパースになるよう,活性化関数を調整する→脳内のニューロンの発火はスパースである,という観察(sparse coding, sparseauto-encoder)
18 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
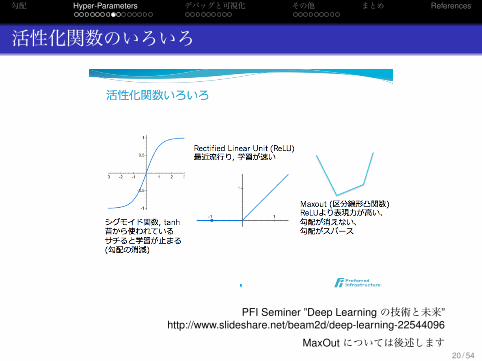
活性化関数
.代表的なもの..
.
Sigmoid 1/(1 + e−a)
Tanh ea+e−a
ea−e−a
Rectified Linear Unit (ReLU, Rectifier) max(0, a)
Hard tanh
.なめらかな関数..
.
表現力が高い (最終的な精度を期待できる)が,収束が遅い(勾配の消滅),
.非連続な関数..
.
収束は速く,勾配が疎だが,表現力が低い (最終的な精度が伸び悩むかもしれない)
出力層においては,問題の形 (回帰か,分類か,マルチラベルか)に応じて適切な関数が選べるが,隠れ層においては定石といえるものは無さそう
19 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
活性化関数のいろいろ
PFI Seminer ”Deep Learning の技術と未来”http://www.slideshare.net/beam2d/deep-learning-22544096
MaxOut については後述します20 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
その他のパラメータ
重みの初期化AEの場合,一様分布を用いるのが定石.tanhのユニットであれば,ノードの次数 (繋がっているエッジの数)を用いて,
w ∼ Uniform(−r , r), r =√
6/(fan-in + fan-out)
とする.(Glorot and Bengio, 2010)RBMsの場合は平均 0で分散が小さい (0.1 or 0.01)の正規分布を用いる (Hinton, 2010)乱数初期化によって得られる結果が異なるため,乱数の種を 10個くらい試して,それらを組み合わせる (平均を取る,マジョリティーを取る,最も良いものを取る)という方法もあります.バギングと関連あり.前処理基本データ依存.PCA,正規化,uniformizationなど
21 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
覚えておくべきこと
さまざまな値で試そうvalidation-errorは複雑なカーブを描くので,例えば 3点だけ調べる,とかでは不十分なことが多いlog-scaleで探索しよう例) 0.1と,0.11は殆ど変わらないことが多い.対して,0.01と 0.02は,結果が大きく異なることがある.計算量の問題ハイパーパラメータの探索に必要となる,validation errorの算出は計算量が大きい代わりに,より計算量の小さな指標が提案されているので,そちらを(以下略)
.現実的によく使われる手法 (座標軸降下法)..
.
...1 順番を決めて,あるパラメータに対して最適値を探索,
...2 パラメータを固定して,別なパラメータを最適化22 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Greedy layer-wise optimization
層ごとのハイパーパラメータは,層ごとに最適化してしまう(Mesnil et al., 2011).論文中の Algorithm 1 (超絶オミット)..
.
プレトレーニング:各層に対して:プレトレーニングを行い,最大 K個のパラメータ設定を残す
ファインチューニング:K個のパラメータそれぞれに対して:それぞれ validation-setで評価
.衝撃的な事実 (Bergstra and Bengio, 2012)..
.
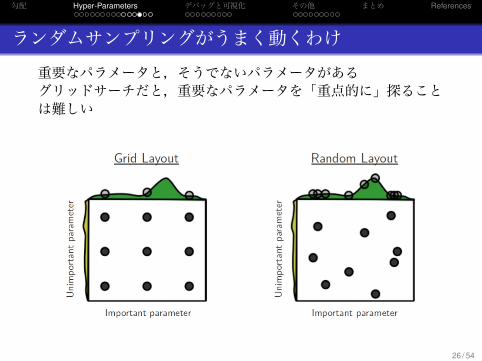
じつは,グリッドサーチ (などのシステマチックな探索)よりランダムサンプリングのほうがいいパラメータを早くみつけることができる!
特に,最適化すべきパラメーターが非常に多い場合
23 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Greedy layer-wise optimization
層ごとのハイパーパラメータは,層ごとに最適化してしまう(Mesnil et al., 2011).論文中の Algorithm 1 (超絶オミット)..
.
プレトレーニング:各層に対して:プレトレーニングを行い,最大 K個のパラメータ設定を残す
ファインチューニング:K個のパラメータそれぞれに対して:それぞれ validation-setで評価
.衝撃的な事実 (Bergstra and Bengio, 2012)..
.
じつは,グリッドサーチ (などのシステマチックな探索)よりランダムサンプリングのほうがいいパラメータを早くみつけることができる!
特に,最適化すべきパラメーターが非常に多い場合24 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
ハイパーパラメータのランダムサンプリング
Bergstra and Bengio, JMLR, 2013
25 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
ランダムサンプリングがうまく動くわけ重要なパラメータと,そうでないパラメータがあるグリッドサーチだと,重要なパラメータを「重点的に」探ることは難しい
26 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
ランダムサンプリング VSグリッドサーチ.ランダムサンプリングの利点 (速いだけでなく・・・)..
.
計算をいつやめても良い計算機が追加で利用可能になった場合,特にグリッドの再設定などの考慮を行わなくて良いそれぞれの trialは,非同期に行えるある trialが失敗しても,単に無視すればよい
結論:ハイパーパラメータはランダムサンプリングしましょう!
個人的には,ちょっと気持ち悪いと思う部分もありますが...
Low-discrepancy sequence(超一様分布列)を用いた実験計画法もあるようです
高次元の数値積分を効率よく計算するための「ばらけた」数列いわゆる「乱数」とは異なります
27 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
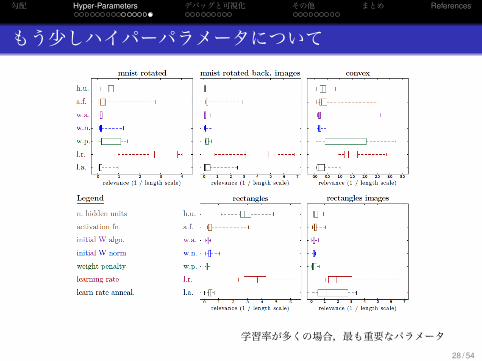
もう少しハイパーパラメータについて
学習率が多くの場合,最も重要なパラメータ28 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Outline
...1 勾配
...2 Hyper-Parameters考慮すべきハイパーパラメータハイパーパラメータの最適化
...3 デバッグと可視化Gradient Checking and Controlled OverfittingVisualizations and Statistics
...4 その他Multi-core machines, BLAS and GPUsSparse High-Dimensional Inputs
...5 まとめ
29 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
バグさがし
テイラー近似による微分値のチェック (ε = 10−4が目安)
∂f (x)
∂x≈ f (x + ε)− f (x − ε)
2ε+ o(ε2).
→非連続な活性化関数でも使えるのかは不明 ( ・ω・` )小規模のデータで試す
L-BFGSなどと SGDで全然違う解に収束していたら要注意メモリの扱いに注意する
一つのテクニックとして,メモリをアロケートするときにNaNで埋めておく,というテクニックがあるメモリ中の変なところにアクセスすると,NaNが伝播してくるので,バグが見つけやすくなるC++だと signaling_NaN()というものがある
30 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
過学習をおさえる
もちろん,バグ由来ではなく,そもそもモデルとして性能が出ないこともある過学習なのか,モデルの表現力がそもそも低いのかいろいろな解決法があります
訓練データを増やす (おそらく最もシンプル)正則化項を増やす/見直すマルチタスク学習(!)Unsupervised pre-training,目的関数に Unsupervisedな要素を加える (データの事前確率など)そもそもネットワークの構造を変える
要は設定変えてやり直せ,ってことです
31 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
可視化と統計値で学習結果をチェックしよう
各 epochにおける訓練データと validationデータのエラー率をチェックする→エラー率が訓練データに対しても下がらない場合は何かがおかしい→訓練データに対しても下がって validationデータに対して下がらない場合は過学習の兆候可視化
Hinton Diagram (Hinton, 1989) (重みの可視化)重みを直接画像にするt-SNE (van der Maaten and Hinton, 2008) (Embeddingの可視化)Manifold Tangent (Rifai et al., 2011b) (CAEで学習された多様体の上の距離を可視化)Learning Trajectory (Erhan et al., 2010b) (学習の軌跡の可視化)
32 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
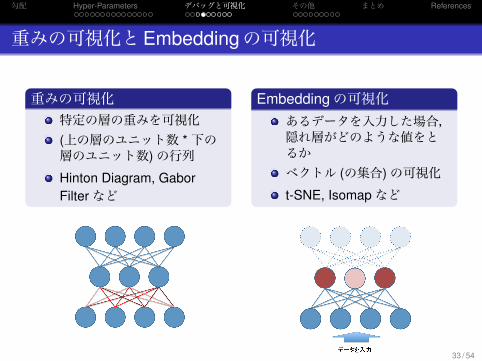
重みの可視化とEmbeddingの可視化
.重みの可視化..
.
特定の層の重みを可視化(上の層のユニット数 *下の層のユニット数)の行列Hinton Diagram, GaborFilterなど
.Embeddingの可視化..
.
あるデータを入力した場合,隠れ層がどのような値をとるかベクトル (の集合)の可視化t-SNE, Isomapなど
33 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Hinton Diagram(重みの可視化)
四角形の大きさは重みの絶対値,四角形の色は符号
殆どのセルで大きさが変わっていない場合は,学習できていなさそう,などの観察 (読解は匠の技っぽい)
34 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
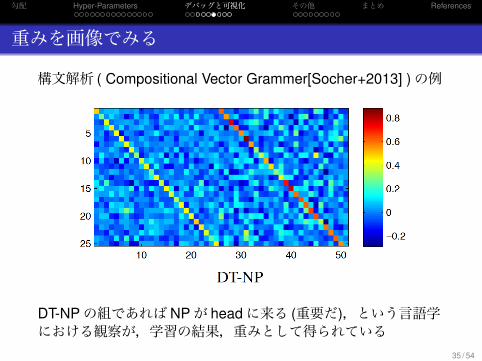
重みを画像でみる
構文解析 ( Compositional Vector Grammer[Socher+2013] )の例
DT-NPの組であれば NPが headに来る (重要だ),という言語学における観察が,学習の結果,重みとして得られている
35 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
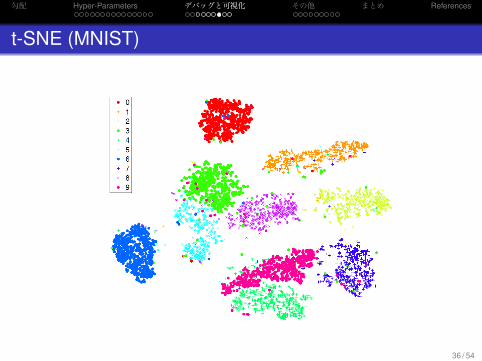
t-SNE (MNIST)
36 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
t-SNE (Turian’s Embedding)
37 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
t-SNE (Turian’s Embedding)
38 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
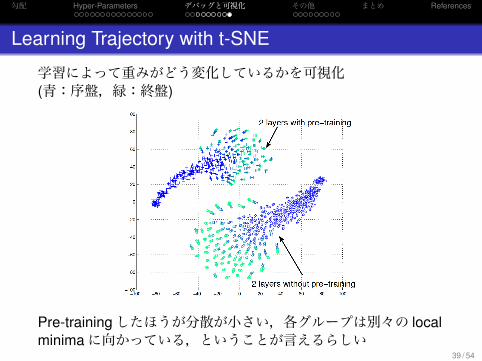
Learning Trajectory with t-SNE
学習によって重みがどう変化しているかを可視化(青:序盤,緑:終盤)
Pre-trainingしたほうが分散が小さい,各グループは別々の localminimaに向かっている,ということが言えるらしい
39 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Outline
...1 勾配
...2 Hyper-Parameters考慮すべきハイパーパラメータハイパーパラメータの最適化
...3 デバッグと可視化Gradient Checking and Controlled OverfittingVisualizations and Statistics
...4 その他Multi-core machines, BLAS and GPUsSparse High-Dimensional Inputs
...5 まとめ
40 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Multi-core machines, BLAS and GPUs
計算の殆どは行列演算BLASのようなライブラリを使うことで,マルチコアの恩恵を得られるGPUは適切に使えばとても速い,しかし難易度が高い
Theanoなら GPU用のコードも吐けますしおすすめです!GPUを用いる際は,メモリの少なさと CPU側との帯域の狭さが問題人工知能学会誌の岡野原さんの記事でも,マルチマシン,マルチ GPUの難しさについて扱われています
41 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Sparse High-Dimensional Inputs
スパース行列の演算には多少のオーバーヘッドがありますが,いわゆる Supervisedな NNではさほど問題になりませんしかし,Unsupervised Learningではけっこう問題(Reconstructionが重い)Sampled Reconstruction (Dauphin et al., 2011)という方法があります
42 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
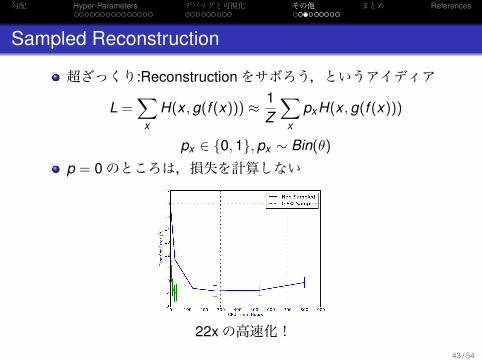
Sampled Reconstruction
超ざっくり:Reconstructionをサボろう,というアイディア
L =∑
x
H(x , g(f (x))) ≈ 1Z
∑x
pxH(x , g(f (x)))
px ∈ {0, 1}, px ∼ Bin(θ)
p = 0のところは,損失を計算しない
22xの高速化!43 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Open Questions
深い構造における学習の難しさ局所解が非常に多い初期化/設定によって,drasticallyに性能がかわるひとつの方向性として,カリキュラム学習 (Bengio et al.,2009)は有望
簡単な問題から順に学習させるC&Wの研究でみたように,ちょっとづつ語彙を増やす (言語モデルを複雑にする)など
「なぜ」深い構造は学習が難しいのかは,まだ分かっていないことが多い
パーツ自体は単純ではあるが全体の挙動は複雑 (人工知能学会誌の岡野原さんの記事より)正直,パラメータ多すぎますよね
44 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
カリキュラム学習
45 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
現在実験的に確かめられていること
Local training signal(すみません,ちょっとわかりませんでした)適切に初期化する
レイヤの重みのヤコビアンの特異値が 1に近くなるように初期化するとよいという報告も (Glorot and Bengio, 2010)(あれ?行列の特異値って一般に複数あるよね?)
活性化関数の選び方 (Glorot et al., 2011a)一般的には,対称な関数形のほうがよさそうRectifier(ReLU)は,非対称ながらうまく動く→勾配がよく伝播するのが理由のようだそれぞれの隠れ層の活性化関数をセンタリング(平均がゼロになるよう動かす)するとよいという報告もある (Raikoet al., 2012)
46 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Learning rateの呪いから逃れる
Learning rateは非常にクリティカルなパラメータ最近は適応的に学習率を決める方法も研究されています(AdaGrad(Duchi et al., 2011)など)各次元ごとに,重みの更新履歴を用いて,「大きく更新される重みは小さな学習率,そうでないものは学習率を大きく」というアイディア→逆の考え方もありそう
最初は SGDでおおよその解を見つけ,あとは共役勾配法やL-BFGSで丁寧に探索という方向性もあるようです
SGDは一次収束だが局所解に捕まりにくい,L-BFGSは収束が速い (超一次)だが局所解に弱い
47 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
その他,本稿で触れられていない最近の話題.DropOut..
.
過学習を防ぐテクニック隠れ層のノードのある割合 (半分とか)を無かった事にしてバックプロパゲーション推定時は重みを割ってつじつまをあわせるいろいろな亜種がある (DropConnect, MaxPooling, etc...)バギングの一種と解釈できるらしい
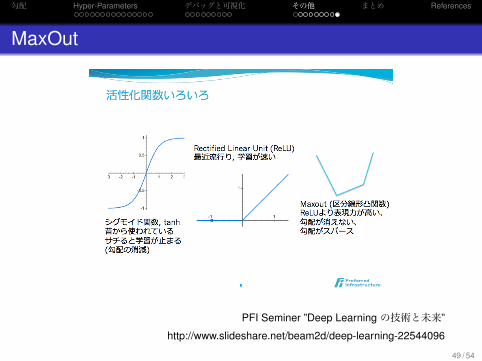
.MaxOut..
.
最近提案された活性化関数,さまざまな線形関数のMaxをとるSoftMaxとの組み合わせで任意の関数を表現できる(表現力の高い Softな活性化関数と,学習が速い非連続な活性化関数のイイトコどり)
48 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
MaxOut
PFI Seminer ”Deep Learning の技術と未来”
http://www.slideshare.net/beam2d/deep-learning-22544096
49 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
Outline
...1 勾配
...2 Hyper-Parameters考慮すべきハイパーパラメータハイパーパラメータの最適化
...3 デバッグと可視化Gradient Checking and Controlled OverfittingVisualizations and Statistics
...4 その他Multi-core machines, BLAS and GPUsSparse High-Dimensional Inputs
...5 まとめ
50 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
まとめ
Auto-Encoders Basedな Deep Learningを実装・利用する上で,知っておいたほうが良いことを紹介
ハイパーパラメータさまざまなハイパーパラメータとその役割ハイパーパラメータの最適化における定石
バグさがし・可視化のテクニック勾配の近似,t-SNE, Learning Trajectoryなど
その他,高次元な入力空間における留意事項GPU, Sampled Reconstruction, SGDと準ニュートン法の組み合わせなど
.まとめのまとめ..
.
ハイパーパラメータはランダムサンプリングしましょう!
やっぱりちょっと気持ち悪い...
51 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
参考文献 I
Bergstra, J. and Bengio, Y. (2012). Random search for hyper-parameter optimization.J. Machine Learning Res., 13, 281–305.
Polyak, B. and Juditsky, A. (1992). Acceleration of stochastic approximation byaveraging. SIAM J. Control and Optimization, 30(4), 838–855.
Larochelle, H., Bengio, Y., Louradour, J., and Lamblin, P. (2009). Exploring strategiesfor training deep neural networks. J. Machine Learning Res., 10, 1–40.
Ranzato, M., Poultney, C., Chopra, S., and LeCun, Y. (2007). Efficient learning ofsparse representations with an energy-based model. In NIPS’06.
Glorot, X. and Bengio, Y. (2010). Understanding the difficulty of training deepfeedforward neural networks. In AISTATS’2010, pages 249–256.
Hinton, G. E. (2013). A practical guide to training restricted boltzmann machines. InK.-R. Muller, G. Montavon, and G. B. Orr, editors, Neural Networks: Tricks of theTrade, Reloaded . Springer.
Hinton, G. E. (2010). A practical guide to training restricted Boltzmann machines.Technical Report UTML TR 2010-003, Department of Computer Science, Universityof Toronto.
52 / 54

勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
参考文献 II
Mesnil, G., Dauphin, Y., Glorot, X., Rifai, S., Bengio, Y., Goodfellow, I., Lavoie, E.,Muller, X., Desjardins, G., Warde-Farley, D., Vincent, P., Courville, A., and Bergstra,J. (2011). Unsupervised and transfer learning challenge: a deep learning approach.In JMLR W&CP: Proc. Unsupervised and Transfer Learning, volume 7.
Hinton, G. E. (1989). Connectionist learning procedures. Artificial Intelligence, 40,185–234.
van der Maaten, L. and Hinton, G. E. (2008). Visualizing data using t-sne. J. MachineLearning Res., 9.
Rifai, S., Dauphin, Y., Vincent, P., Bengio, Y., and Muller, X. (2011b). The manifoldtangent classifier. In NIPS’2011.
Erhan, D., Bengio, Y., Courville, A., Manzagol, P.-A., Vincent, P., and Bengio, S.(2010b). Why does unsupervised pre-training help deep learning? J. MachineLearning Res., 11, 625–660.
Dauphin, Y., Glorot, X., and Bengio, Y. (2011). Sampled reconstruction for large-scalelearning of embeddings. In Proc. ICML’2011.
Bengio, Y., Louradour, J., Collobert, R., and Weston, J. (2009). Curriculum learning. InICML’09.
Glorot, X., Bordes, A., and Bengio, Y. (2011a). Deep sparse rectifier neural networks.In AISTATS’2011.
53 / 54
勾配. . . . . . . . . . . . . . .Hyper-Parameters
. . . . . . . . .デバッグと可視化
. . . . . . . . .その他 まとめ References
参考文献 III
Raiko, T., Valpola, H., and LeCun, Y. (2012). Deep learning made easier by lineartransformations in perceptrons. In AISTATS’2012.
Duchi, J., Hazan, E., and Singer, Y. (2011). Adaptive subgradient methods for onlinelearning and stochastic optimization. Journal of Machine Learning Research.
54 / 54