prd-025 - amazon cloudsearch
TRANSCRIPT

Amazon Web Services
cloud-aws.com
Amazon CloudSearch
Hangout 25 del 18.08.2014
● Davide Riboldi● Massimo Della Rovere
Oggi vediamo come creare un motore di ricerca utilizzando il servizio di Amazon CloudSearch.
#cloudaws

● Anche se in apparenza creare un motore di ricerca per le proprie applicazioni web può sembrare una cosa abbastanza semplice in realtà è una delle operazioni più difficili da sviluppare in assoluto.
● Proprio per questo anche prodotti molto conosciuti e sviluppati da grandi community come WordPress, Drupal, Joomla etc, etc, nonostante le numerose funzioni messe a disposizione hanno sempre avuto un motore di ricerca particolarmente scadente.

● Un’altra conseguenza legata alla complessità di creare un motore di ricerca interno è che molti sviluppatori preferisco utilizzare dei servizi esterni come Google, Bing e Yahoo per ottenere i risultati direttamente dalle query dei motori di ricerca.
● Però questa tecnica ha due grossi svantaggi, il primo riguarda il limite di non permettere query su pagine e contenuti privati, il secondo che i risultati sono poco personalizzabili sull’aspetto grafico.
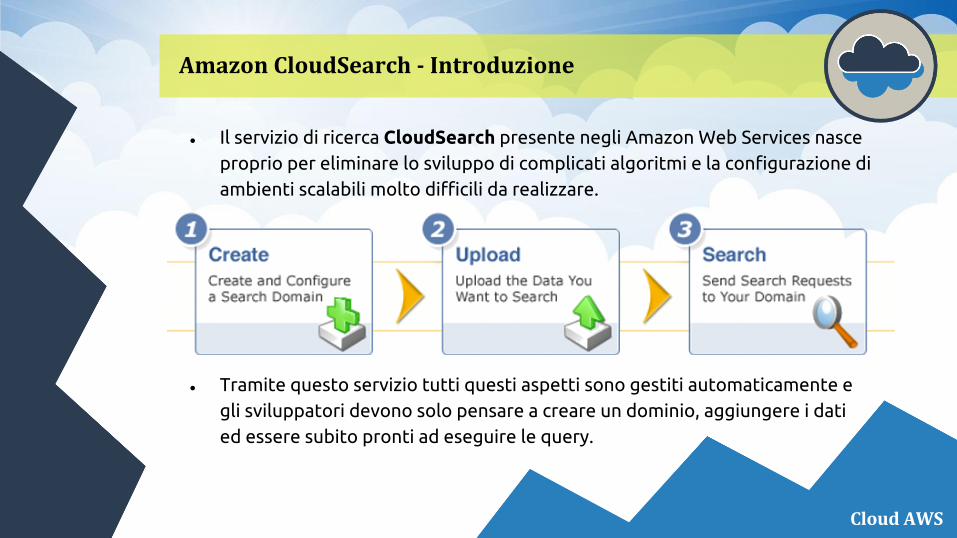
● Il servizio di ricerca CloudSearch presente negli Amazon Web Services nasce proprio per eliminare lo sviluppo di complicati algoritmi e la configurazione di ambienti scalabili molto difficili da realizzare.
● Tramite questo servizio tutti questi aspetti sono gestiti automaticamente e gli sviluppatori devono solo pensare a creare un dominio, aggiungere i dati ed essere subito pronti ad eseguire le query.

● Sulla qualità del servizio di ricerca non è necessario entrare troppo nei dettagli tecnici ma basta pensare che gli algoritmi e le tecniche usate sono le stesse che vengono utilizzate dal sito amazon.com
● Che come sapete mette a disposizione un numero notevole di prodotti ed elabora milioni di query giornaliere. Come al solito la referenza più grande degli Amazon Web Service è proprio Amazon stessa.
● http://aws.amazon.com/cloudsearch/testimonials/

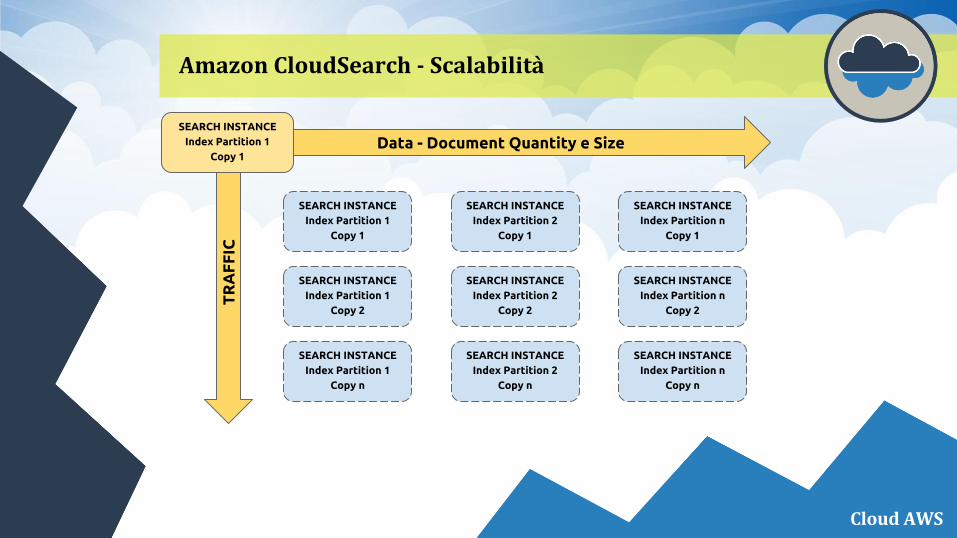
● Ogni collezione di dati, su cui bisogna costruire un motore di ricerca con CloudSearch, deve essere contenuto in un solo dominio di ricerca.
● Ogni dominio di ricerca può essere gestito da una o più istanze in base alla potenza di calcolo necessaria e alla mole di dati da memorizzare.
● Quando si crea un nuovo dominio di ricerca verrà indicata un’istanza search.m1.small per default ma sarà possibile cambiarla secondo le proprie esigenze.
SEARCH INSTANCEIndex Partition 1
Copy 1
SEARCH INSTANCEIndex Partition 1
Copy 2
SEARCH INSTANCEIndex Partition 1
Copy n
SEARCH INSTANCEIndex Partition 2
Copy n
SEARCH INSTANCEIndex Partition 2
Copy 2
SEARCH INSTANCEIndex Partition 2
Copy 1
SEARCH INSTANCEIndex Partition n
Copy 1
SEARCH INSTANCEIndex Partition n
Copy 2
SEARCH INSTANCEIndex Partition n
Copy n
D Data - Document Quantity e SizeSEARCH INSTANCE
Index Partition 1Copy 1
TR
AFF
IC

● Amazon riporta nella documentazione ufficiale un documento di esempio IMDb contenente informazioni su un film, se si prende come base questo tipo di memorizzazione la capacità di una singola istanza è la seguente:
search.m1.small 2 milioni di documenti search.m2.xlarge 16 milioni di documenti
search.m1.large 8 milioni di documenti search.m2.2xlarge 32 milioni di documenti
● Ovviamente i dati riportati sono solo indicativi e possono cambiare drasticamente in base al documento usato come unità di memorizzazione, in ogni caso se si supera la capacità legata ad una istanza m2.2xlarge, il servizio CloudSearch aggiungerà fino a 9 istanze contemporanee.

● Una volta attivato un dominio di ricerca è possibile effettuare delle query che generano dei risultati in formato JSON e XML. Ogni dominio di ricerca viene associato ad un URL univoco che è possibile utilizzare nelle proprie applicazioni, lo stesso end-point può essere usato anche per aggiornare l’indice e aggiungere nuovi documenti alla ricerca.
● Amazon CloudSearch mette a disposizione un “query language” per eseguire le ricerche con specifici campi, eseguire complesse ricerche booleane, reperire informazioni e specificare il formato dei dati che si vogliono ottenere di ritorno. È possibile indicare le opzioni di controllo che riguardano le query sui termini e i parsers come Lucene.

1 2 3 4

● Run a Text Search: viene messo a disposizione un semplice form per testare le query di ricerca ed analizzare i risultati, è possibile anche inserire delle opzioni avanzate come ad esempio la selezione dei campi su cui effettuare la ricerca, il metodo usato, etc etc.
● Access Policies: è possibile specificare le autorizzazioni di accesso al nostro dominio di ricerca, la configurazione consigliata è permettere a tutti il servizio di ricerca e bloccare completamente il servizio documenti ad eccezione del nostro indirizzo IP.
● Availability Options: in questa sezione al momento si trova la possibilità di attivare la modalità Multi-AZ (available zone) che permette di avere delle istanze attive nelle altre zone di disponibilità. Per default l’opzione è disattiva perché prevede costi aggiuntivi.

● Indexing Options: selezionando questo menu è possibile visionare i campi che vengono usati come chiavi, è possibile aggiungerne altri o rimuovere quei campi che non si vuole più indicizzare. Ricordarsi che gli indici necessitano di memoria e consumano risorse.
● Scaling Options: durante la fase di avvio del dominio abbiamo lasciato nella sezione della scalabilità i valori di default, tramite questa sezione è possibile personalizzare le caratteristiche del nostro dominio di ricerca sul tipo di istanza e la replica dei dati.
● Suggesters: in questa sezione possiamo aggiungere dei suggerimenti che saranno legati ad un campo di ricerca. Per ogni suggerimento dovremmo specificare un nome, il campo di riferimento, il tipo di matching e l’espressione di ordinamento (sort).

Cloud Computing
Amazon Web Service 1
AmazonSNS
AmazonMFA
AmazonCloudFront
AmazonFree Trial
AmazonS3
AmazonGlacier
Amazon Web Service 2
ElasticTranscoder
Storagegateway
AmazonSES
AmazonCloudTrial
AmazonCloudWatch
AmazonSQS
AmazonIAM Top 10
AmazonRDS
AmazonIAM
AmazonRoute 53