presentazione joinmapreduce
TRANSCRIPT

Join in Map ReduceReduceSide Join

Cos’è Map Reduce?• MapReduce è un modello di programmazione per l’elaborazione
su cluster di grandi datasets di dati attraverso algoritmi paralleli e distribuiti.
• Il nome MapRedudce deriva dal paradigma funzionale su cui si basa che prevede due fasi distinte:
Map Reduce• MapReduce prende un input, lo divide in tante parti più piccole,
esegue il codice del mapper su ciascuna di queste parti, poi passa tutti i risultati prodotti ad uno o più reducer che uniscono tutti i risultati in uno solo secondo il codice con cui è stato definito.


Reduce Side Join
MAPREDUCE PATTERN• Permette il Join tra molteplici datasets insieme attraverso
chiavi esterne.• E’ il pattern di join più semplice da implementare, ma
anche il più potente. Può essere usato per implementare qualsiasi tipo di join.
• Non pone limitazioni alla dimensionalità dei datasets utilizzati.
• Richiede una grande quantità di banda di rete per lo scambio di dati tra mapper e reducer.

STRUTTURA I mapper preparano l’operazione di join
Prendono i record di input da ciascuno dei datasets Estraggono la chiave esterna da ogni record Generano la coppia (Chiave,Valore). Usano come “chiave” la
chiave esterna estratta e come “valore” il record di ingresso a cui viene concatenato un opportuno flag, per distinguerlo in base al datasets da cui viene estratto.
I reducer eseguono l’operazione di join desiderata collezionando i valori in liste temporanee Si itera l’elaborazione su queste liste ed i record di ogni datasets
vengono uniti tra loro In output vengono dati un numero di file corrispondenti al
numero di task di reduce
Reduce Side Join

Reduce Side Join

Reduce Side Join
DATASETS• I datasets utilizzati vogliono simulare informazioni su
utenti ed i loro numeri di telefono da un lato, e numeri di telefono ed operatori telefonici dall’altro.

Reduce Side Join
DRIVER CODE• Nella fase di configurazione definiamo le caratteristiche
del job di join in termini di sorgenti in ingresso (i path dei due file in cui sono contenuti i datasets).
• Bisogna anche definire le tipologie di join da implementare (in questa versione è implementato l’innerjoin classico, ma con questo pattern è possibile facilmente implementare anche le altre tipologie di outerjoin)
PROBLEMASi vuole determinare gli utenti a quali operatori telefonici appartengono.


Reduce Side Join
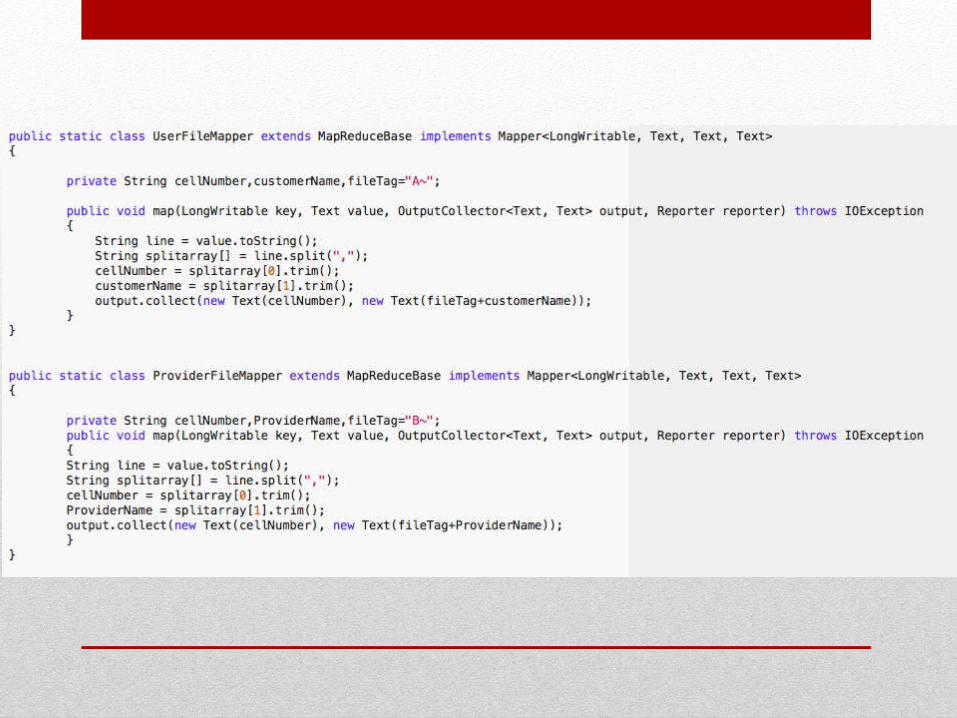
MAPPERS• Vengono utilizzati due mapper differenti per elaborare gli
input iniziali dei due datasets (ProviderDetails, UserDetails). Vengono estratte rispettivamente le loro chiavi (cell number) e viene generata la coppia chiave, valore.
• Per il dataset degli utenti viene concatenato in testa al valore il carattere A e per il dataset dei provider il carattere B, al fine di riconoscere la provenienza dei record.

Reduce Side Join
REDUCERS• I Reducer copiano in memoria (in due liste separate
rispetto ai due datasets) tutti i valori di ogni gruppo, mantenendo traccia della provenienza di ciascun record grazie al flag posto dai mapper.
• In seguito, considerando ogni chiave, se le liste rispetto ai due datasets non sono vuote viene effettuato il join. (inner join)


Reduce Side Join
ALTRI JOIN• Altre operazioni di join (leftjoin, rightjoin, fulljoin)
potevano essere eseguite tenendo conto che le liste siano vuote o meno e sostituendo “Null” a tali valori.


Reduce Side Join
• Copiare i file dal locale

Reduce Side Join
• Eseguo il jar del join specificando che si richiede un innerjoin

Reduce Side Join
• Il risultato viene memorizzato nella cartella output_innerjoin


Reduce Side Join
PIG• l’operazione di innerjoin è eseguita facilmente con un script Pig Latin, infatti
basta solamente il comando di “JOIN” , mentre per gli altri join bisogna specificarne il tipo.

Reduce Side Join