realtime distributed log colletct system
TRANSCRIPT


整体介绍
❖ 系统背景 why
❖ 效果如何 how
❖ 系统架构 what
❖ 开源组件详解
❖ 线上运维
❖ 未来

系统背景
❖⼀一组数据
5000wPV,1500w⽇日志/⽇日
❖⽬目前⽇日志⽅方案问题基于MSMQ/Rabbitmq消息队列的⽇日志⽅方案
net版:1分钟聚合错误⽇日志+延迟30m/最⾼高延迟60m以上
java版:15秒聚合或者50条聚合
存储数据:SqlServer + 7天
❖ ⽇日志⽬目标低延迟:实时性- 秒级,分钟级
海量性 :数据存储1个⽉月,甚⾄至更多
查询速度快

如何使⽤用
❖ 多种条件组合❖ 列表+详情展⽰示❖ ⽀支持模糊查询❖ ⽀支持⼿手写sql(todo……)
平滑的从使⽤用SqlServer查询过渡到页⾯面筛选查询
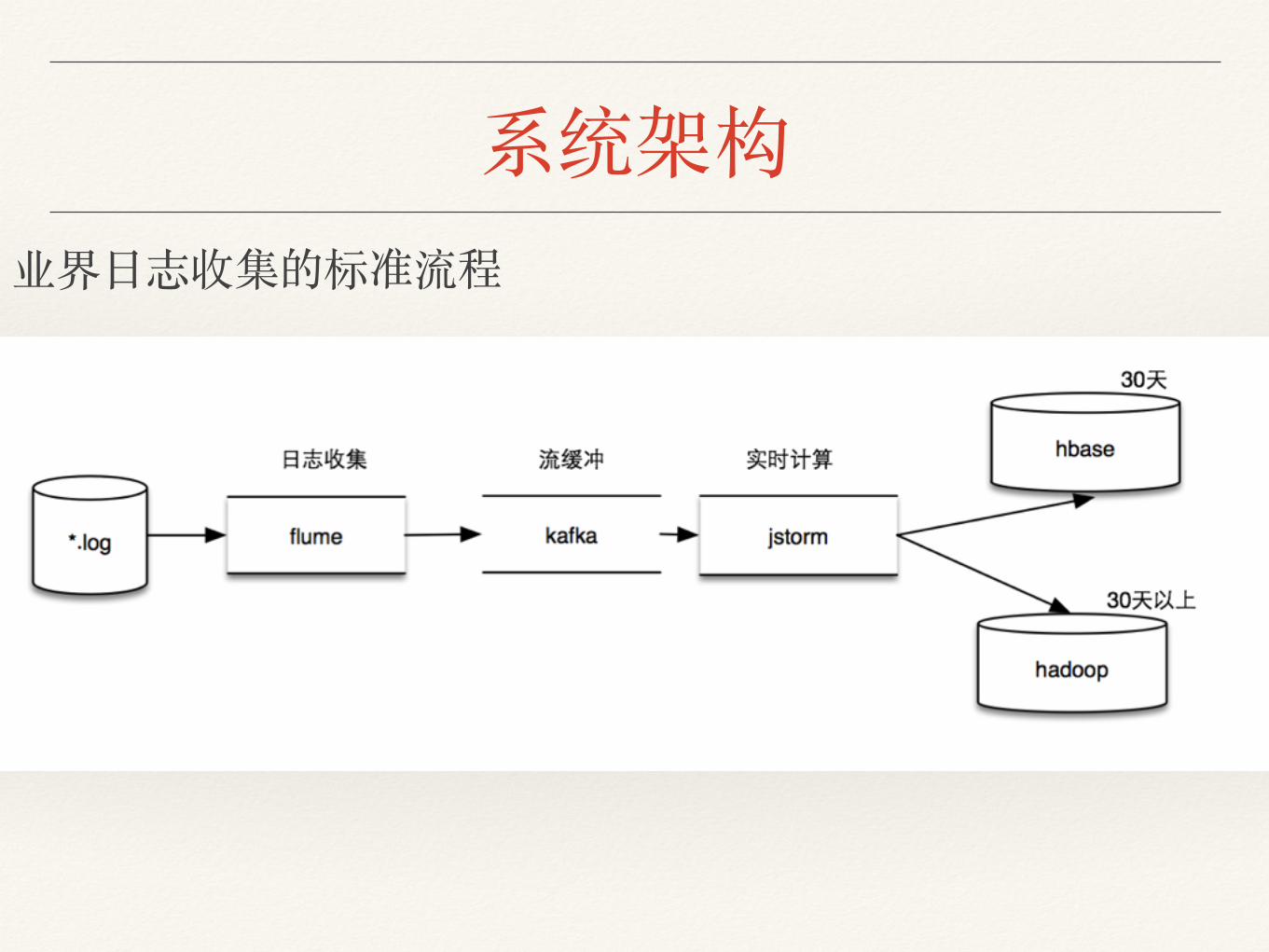
系统架构业界⽇日志收集的标准流程

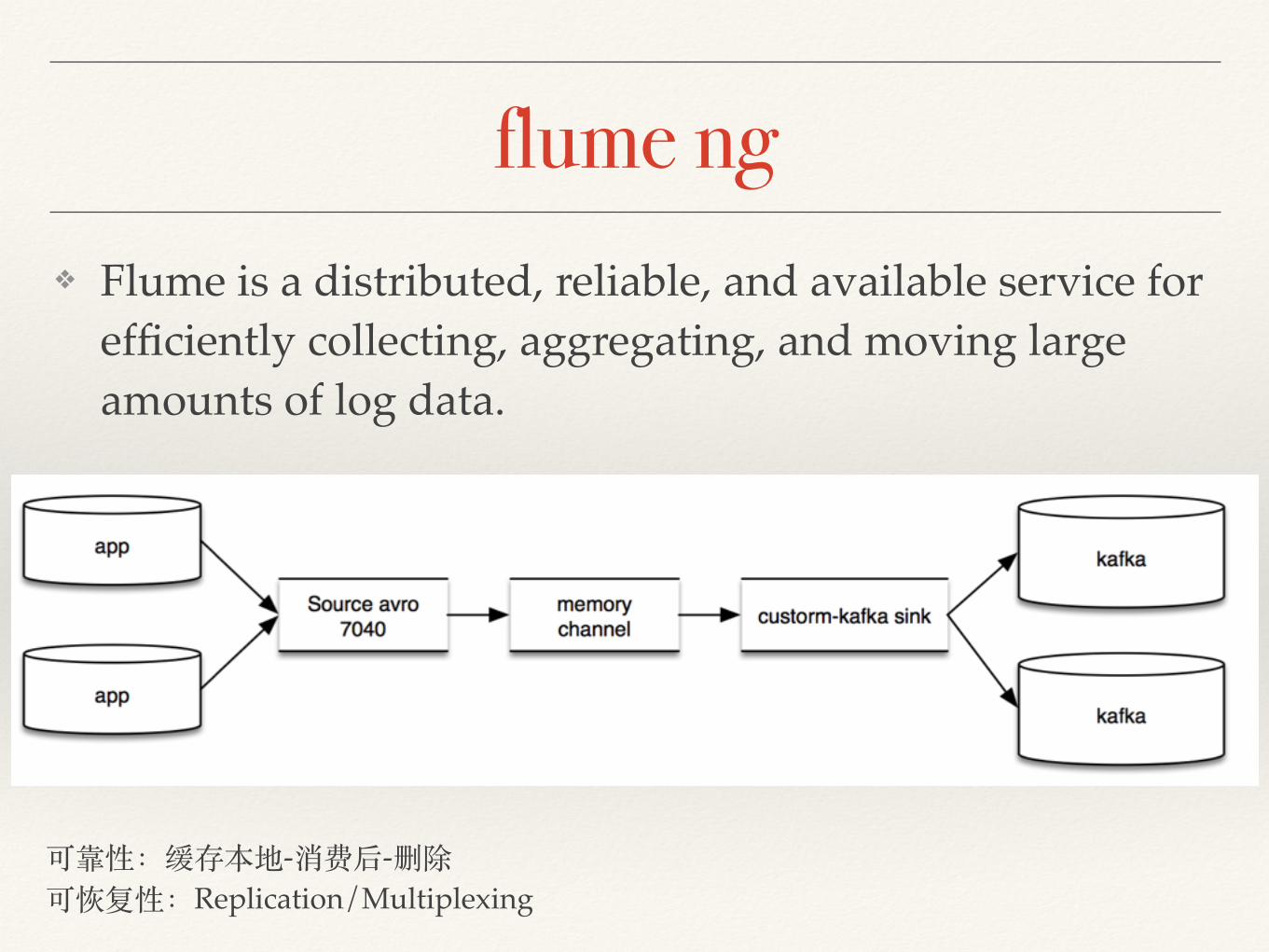
flume ng❖ Flume is a distributed, reliable, and available service for
efficiently collecting, aggregating, and moving large amounts of log data.
可靠性:缓存本地-消费后-删除可恢复性:Replication/Multiplexing
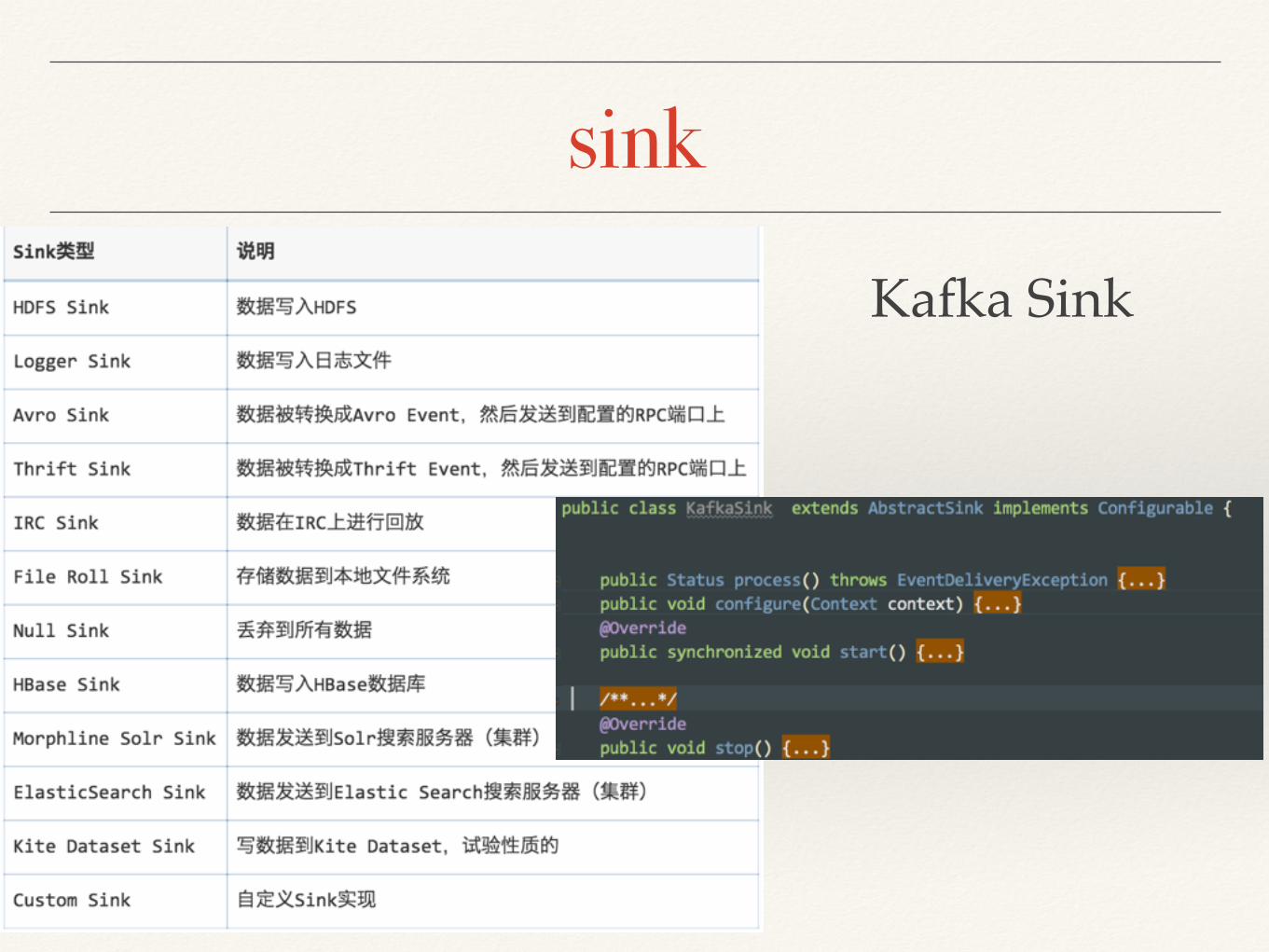
sinkKafka Sink

kafka❖ Apache Kafka is publish-subscribe messaging rethought as a
distributed commit log.
❖ ⼀一个分布式系统,易于向外扩展;
❖ 它同时为发布和订阅提供⾼高吞吐量;
❖ 它⽀支持多订阅者,当失败时能⾃自动平衡消费者;
❖ 它将消息持久化到磁盘,因此可⽤用于批量消费,例如ETL,以及实时应⽤用程序。
❖ 话题(Topic)/⽣生产者(Producer)/代理(Broker)/消费者
❖ 解耦、冗余、扩展性、异步通信
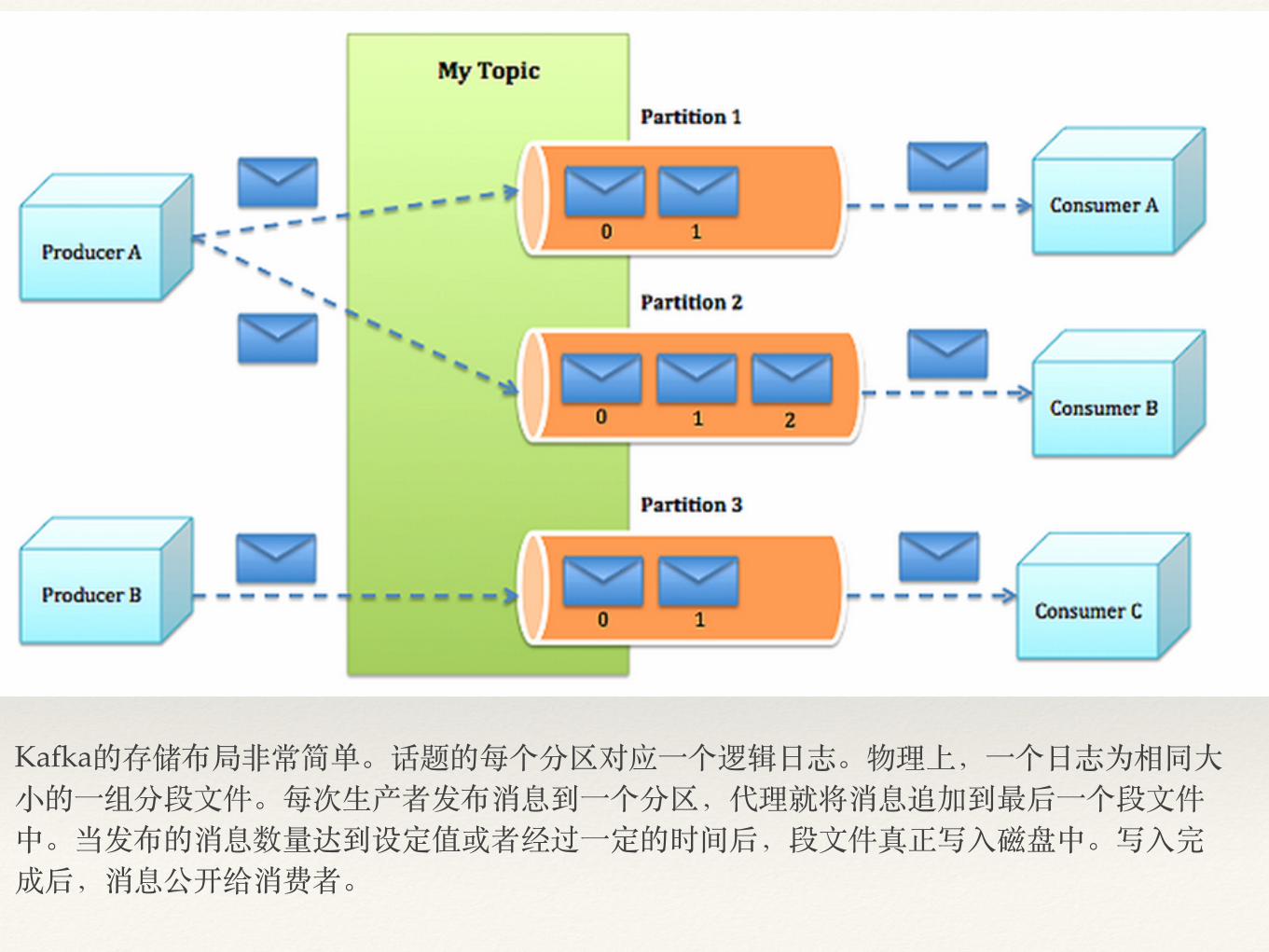
Kafka的存储布局⾮非常简单。话题的每个分区对应⼀一个逻辑⽇日志。物理上,⼀一个⽇日志为相同⼤大⼩小的⼀一组分段⽂文件。每次⽣生产者发布消息到⼀一个分区,代理就将消息追加到最后⼀一个段⽂文件中。当发布的消息数量达到设定值或者经过⼀一定的时间后,段⽂文件真正写⼊入磁盘中。写⼊入完成后,消息公开给消费者。

Storm/JStorm❖ a free and open source distributed realtime computation
system
❖ 分布式、低延迟、⾼高性能、易扩展、容错性
❖ 基于消息的流⽔水线处理模型,任务调度系统
❖ 适合:信息流处理(聚合分析)、持续计算(实时数据统计监控)、分布式rpc调⽤用

why jstorm❖ Nimbus 实现HA
❖ 彻底解决Storm雪崩问题:底层RPC采⽤用netty + disruptor保证发送速度和接受速度是匹配的
❖ 新增supervisor、Supervisor shutdown时、提交新任务,worker数不够时,均不⾃自动触发任务rebalance
❖ 新topology不影响现有任务,新任务⽆无需去抢占⽼老任务的cpu,memory,disk和net
❖ 减少对ZK的访问量:去掉⼤大量⽆无⽤用的watch;task的⼼心跳时间延长⼀一倍;Task⼼心跳检测⽆无需全ZK扫描
❖ Worker 内部全流⽔水线模式:Spout nextTuple和ack/fail运⾏行在不同线程
❖ 性能:ZeroMq, ⽐比storm快30%;netty时, 和storm快10%,并且稳定⾮非常多
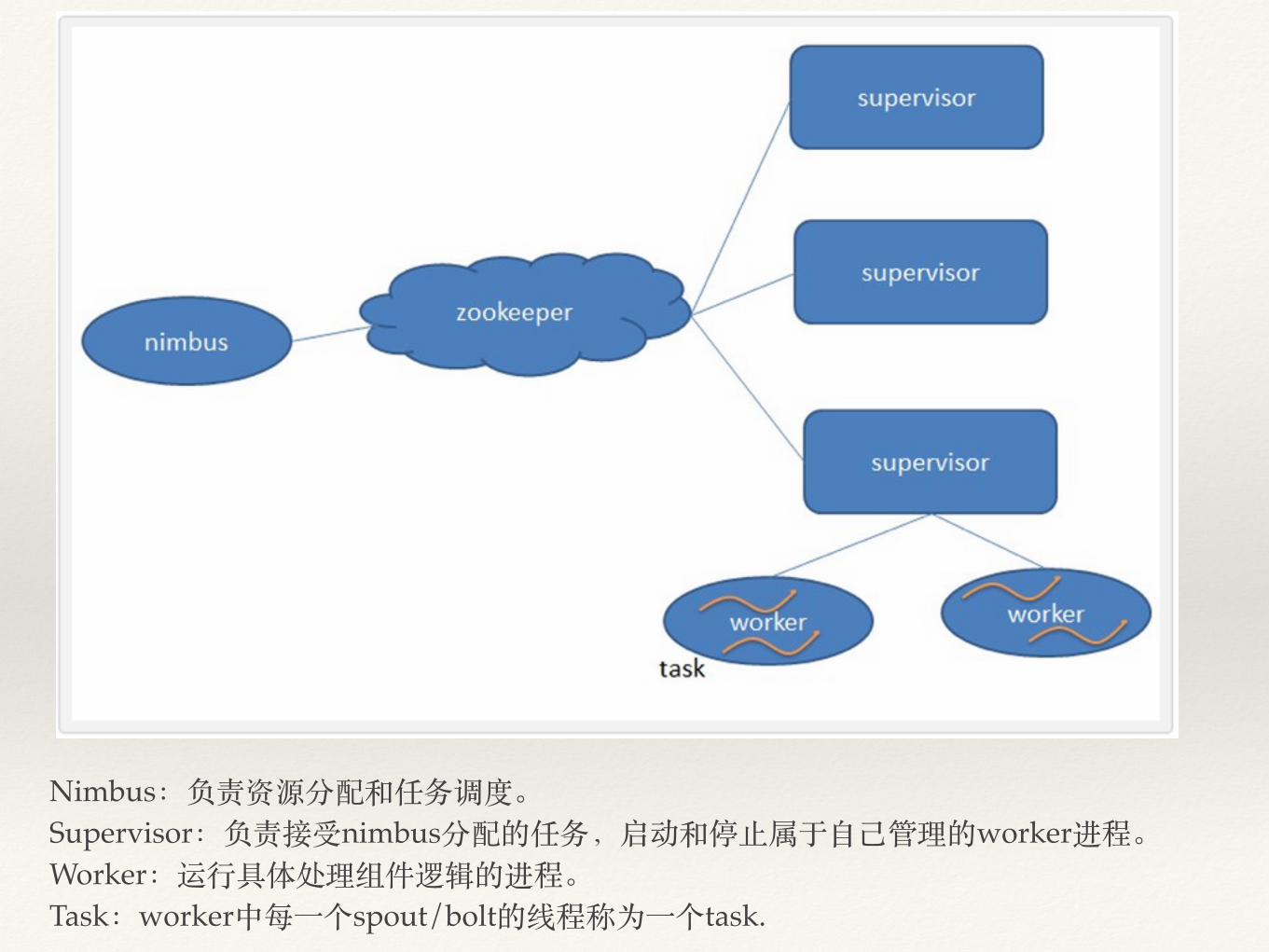
Nimbus:负责资源分配和任务调度。Supervisor:负责接受nimbus分配的任务,启动和停⽌止属于⾃自⼰己管理的worker进程。Worker:运⾏行具体处理组件逻辑的进程。Task:worker中每⼀一个spout/bolt的线程称为⼀一个task.
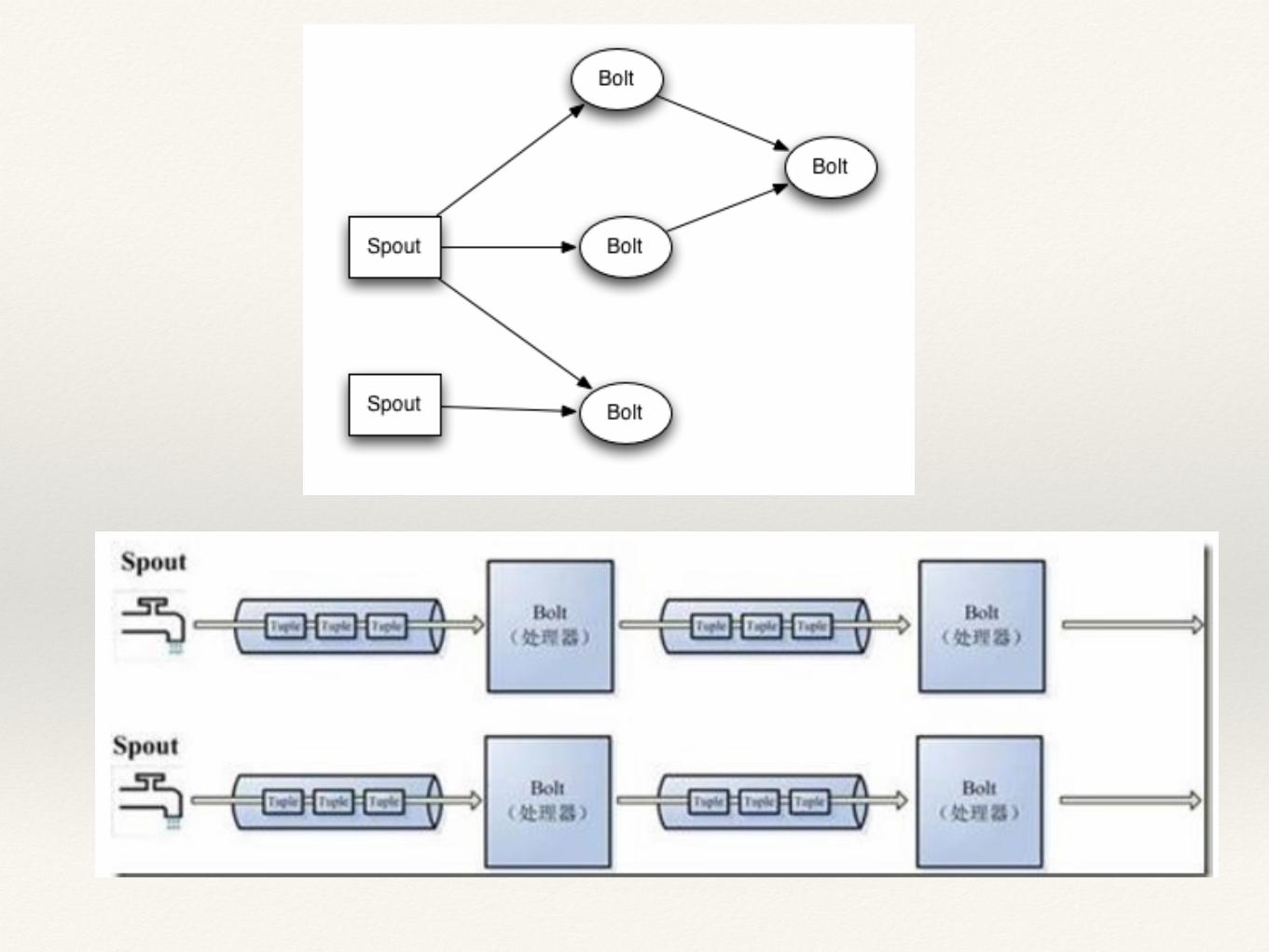

Topology:storm中运⾏行的⼀一个实时应⽤用程序,因为各个组件间的消息流动形成逻辑上的⼀一个拓扑结构。Spout:在⼀一个topology中产⽣生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。Spout是⼀一个主动的⾓角⾊色,其接⼝口中有个nextTuple()函数,storm框架会不停地调⽤用此函数,⽤用户只要在其中⽣生成源数据即可。Bolt:在⼀一个topology中接受数据然后执⾏行处理的组件。Bolt可以执⾏行过滤、函数操作、合并、写数据库等任何操作。Bolt是⼀一个被动的⾓角⾊色,其接⼝口中有个execute(Tuple input)函数,在接受到消息后会调⽤用此函数,⽤用户可以在其中执⾏行⾃自⼰己想要的操作。Tuple:⼀一次消息传递的基本单元。本来应该是⼀一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填⼊入各个value就⾏行了,所以就是⼀一个value list.Stream:源源不断传递的tuple就组成了stream。stream grouping:即消息的partition⽅方法。Storm中提供若干种实⽤用的grouping⽅方式,包括shuffle, fields hash, all, global, none, direct和localOrShuffle等

jstorm ui 监控页⾯面

性能调优❖ ⼀一个task消耗⼀一个cpu slot和⼀一个memory slot 默认cpu slot是(cpu 核数 -1), memory slot数(物理内存⼤大⼩小 * 75%/1g), 如果⼀一个worker上运⾏行task⽐比较多时,需要将memory slot size设⼩小(默认是1G), ⽐比如512M, memory.slot.per.size: 535298048。推荐⼀一个worker运⾏行2个task。
❖ spout中nextTuple和ack/fail运⾏行在不同的线程中,⿎鼓励⽤用户在nextTuple⾥里⾯面执⾏行block操作,节省CPU时间,避免spout空跑,浪费cpu时间
❖ 在架构上,推荐 “消息中间件 + jstorm + 外部存储” 3架马车式架构,⽅方便jstorm重启,减少耦合
❖ ⾮非事务环境中,尽量使⽤用IBasicBolt, ⾃自动实现了ACK机制代码
❖ 建议不超过1个⽉月,强制重启⼀一下supervisor, 因为supervisor是⼀一个daemon进程, 不停的创建⼦子进程,当使⽤用时间过长时, ⽂文件打开的句柄会⾮非常多,导致启动worker的时间会变慢,因此,建议每隔⼀一周,强制重启⼀一次supervisor
❖ jstorm使⽤用的zk和应⽤用使⽤用的zk区别,nimbus节点上建议不运⾏行supervisor, 并建议把nimbus放置到ZK 所在的机器上运⾏行
❖ ZK 的maxClientCnxns=500,Linux对外连接端⼜⼝口数限制,TCP client对外发起连接数达到28000左右时,就开始⼤大量抛异常 “# echo "10000 65535" > /proc/sys/net/ipv4/ip_local_port_range”

demo

hbase❖ Apache HBase™ is the Hadoop database, a distributed,
scalable, big data store. random, realtime read/write access to your Big Data.
❖ 海量数据存储/快速随机访问/⼤大量写操作(BigTable场景/实时⽇日志/消息中⼼心等)
❖ 特点:列式存储
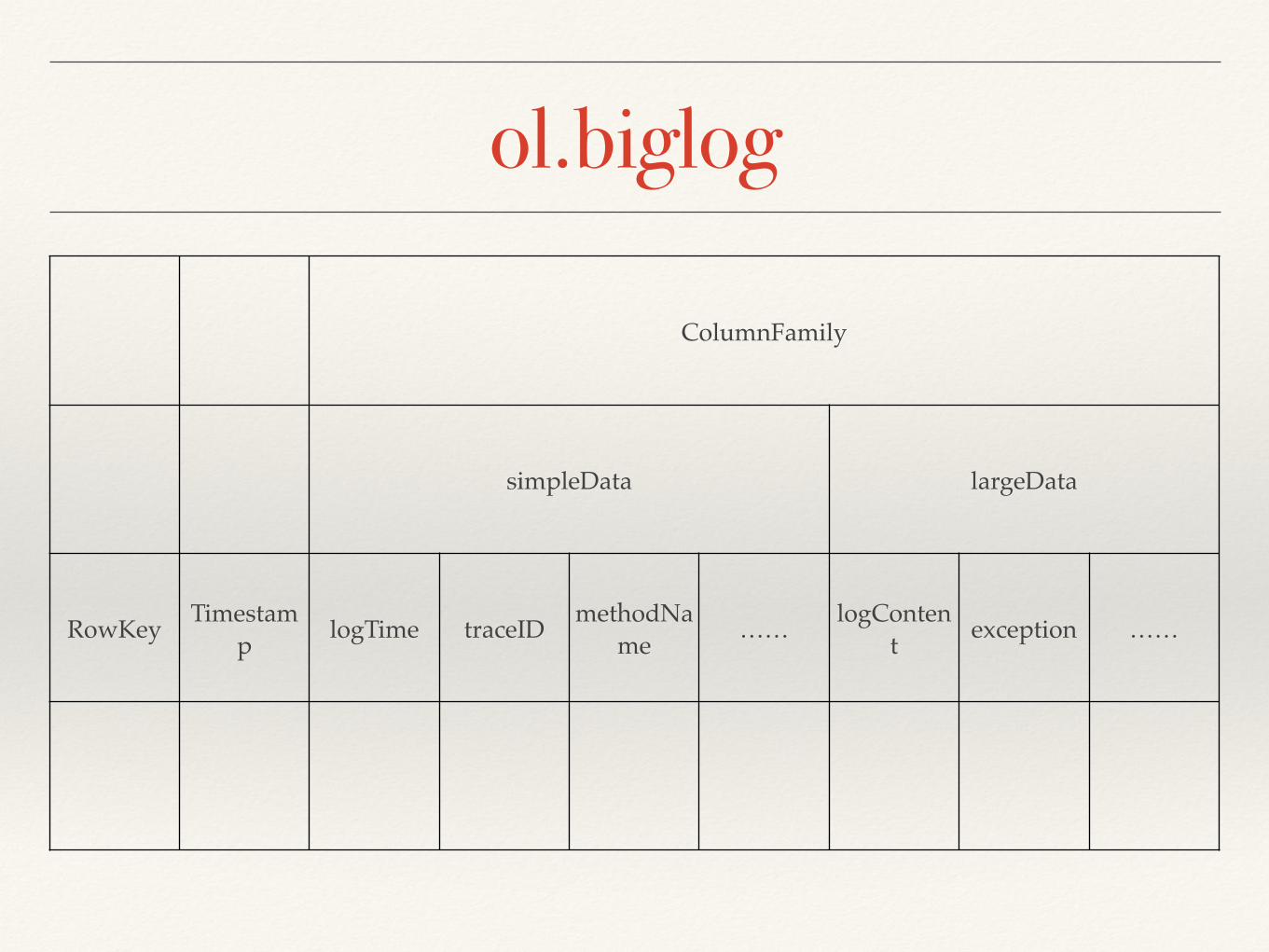
ol.biglog
ColumnFamily
simpleData largeData
RowKey Timestamp logTime traceID methodNa
me …… logContent exception ……

Phoenix❖ High performance relational database layer over HBase
for low latency applications. we put the SQL back in NoSql.
❖ Phoenix 的性能很⾼高,相对于 hbase 原⽣生的scan 并不会差多少,⽽而对于类似的组件 hive、Impala等,性能有着显著的提升.
❖ ⽀支持select/insert/delete/group by/order by/limit /index等常⽤用语句
❖ ⽀支持max/avg/count/sum/lower/substr/now/toDate/等常⽤用函数
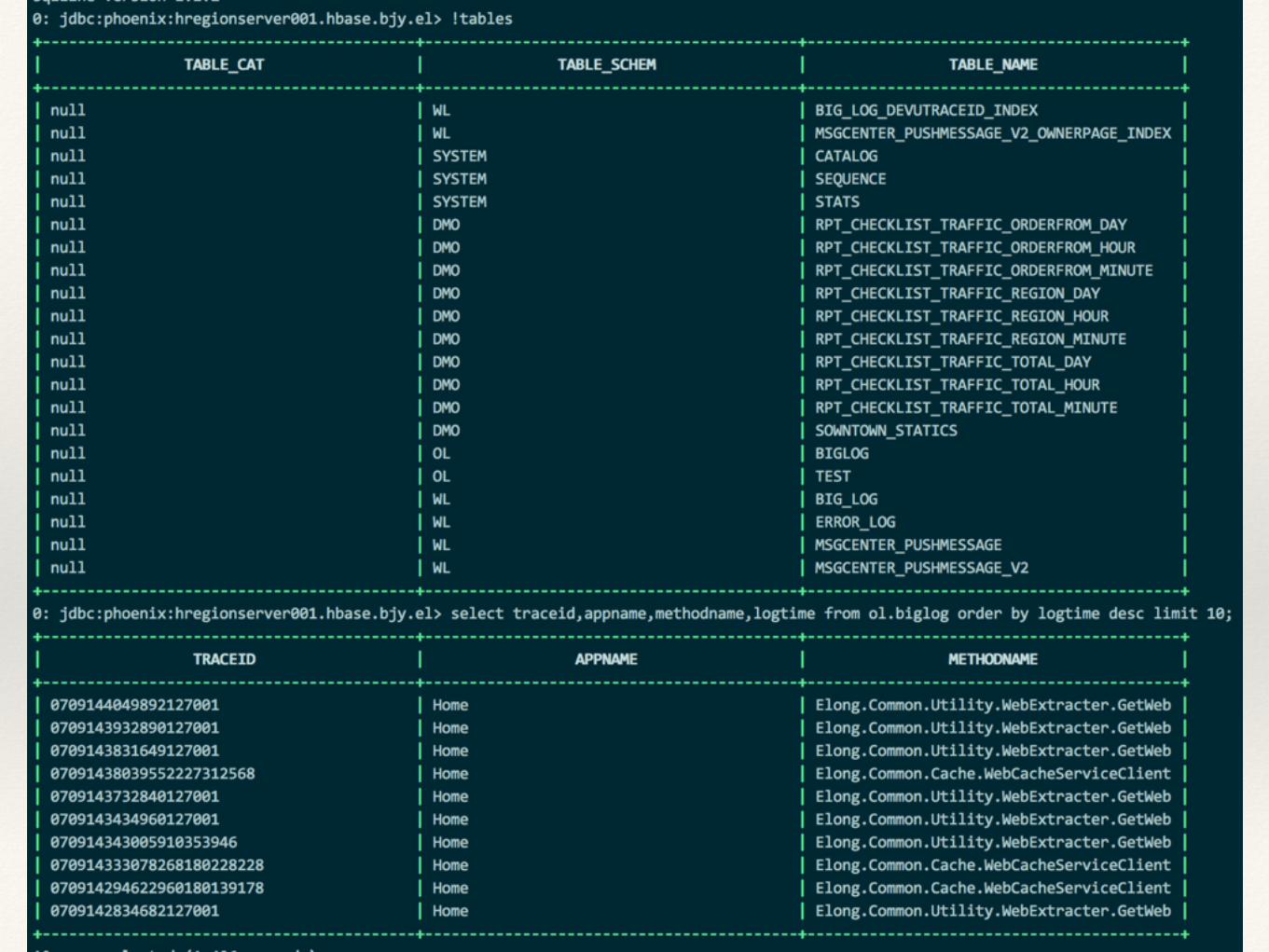
Phoenix客户端查询界⾯面

与mybaits集成❖ guide.parent.driverClassName=org.apache.phoenix.jdbc.PhoenixDriver
❖ guide.parent.initialSize=5
❖ guide.parent.maxActive=15
❖ guide.parent.maxIdle=10
❖ guide.parent.minIdle=5
❖ guide.parent.logAbandoned=true
❖ guide.parent.removeAbandoned=true
❖ guide.parent.removeAbandonedTimeout=30
❖ guide.parent.maxWait=3000
❖ guide.parent.defaultAutoCommit=false
❖ guide.phoenix.jdbcUrl=jdbc:phoenix:10.35.66.72:2181

zookeeper❖ ⼤大型分布式系统的可靠协调服务系统,⽤用来解决分布式应⽤用中经常遇到的⼀一些数据管理问题,如:统⼀一命名服务、状态同步服务、集群管理、分布式应⽤用配置项的管理等。
❖ 官⽅方建议Zookeeper集群⾄至少包含3个节点,每个节点上存储⼀一份数据,主节点挂掉后可以重新选取⼀一个节点作为主节点。只要保证集群内有⼀一半以上的节点存活,集群就可对外提供服务。

JStorm中使⽤用Zookeeper主要⽤用于Storm集群各节点的分布式协调⼯工作,具体功能如下:
1. 存储客户端提供的topology任务信息,nimbus负责将任务分配信息写⼊入Zookeeper,supervisor从Zookeeper上读取任务分配信息;
2. 存储supervisor和worker的⼼心跳(包括它们的状态),使得nimbus可以监控整个集群的状态, 从⽽而重启⼀一些挂掉的worker;
3. 存储整个集群的所有状态信息和配置信息。
Hbase中使⽤用Zookeeper :1. 存储-ROOT-表地址、HMaster地址2. HMaster随时感知各个HRegionServer的健康状况3. Zookeeper避免HMaster单点问题

线上运维
http://gitlab.dev/online_web/web_logplatform/blob/master/doc/%E7%94%9F%E4%BA%A7%E8%BF%90%E7%BB%B4/%E6%9C%BA%E5%99%A8%E7%BA%BF%E4%B8%8A
%E8%BF%90%E7%BB%B4%E6%89%8B%E5%86%8C.md

未来
❖ Jstorm/zookeeper/flume 组件的监控重启
❖ 全组⽇日志的落地
❖ checklist的报警集成
❖ ……

参考学习资料
❖ http://gitlab.dev/online_web/web_logplatform/tree/master/doc
❖ http://www.ixirong.com/categories/%E5%A4%A7%E6%95%B0%E6%8D%AE/

QA