rechnerarchitektur - ti.informatik.uni-frankfurt.de · 2 seite 3 johann wolfgang...
TRANSCRIPT

1
Seite 1
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
RechnerarchitekturVorlesungsbegleitende Unterlagen
WS 2003/2004
Klaus Waldschmidt
Teil 17
Parallelarchitekturen
Seite 2
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Klassifikation nach Flynn (1972)
SISD (single instruction, single data stream)
Rechner mit einfachem Befehls- und Datenstrom
MISD (multiple instruction, single data stream)
Rechner mit mehrfachem Befehls- und einfachem Datenstrom
SIMD (single instruction, multiple data stream)
Rechner mit einfachem Befehls- und mehrfachem Datenstrom
MIMD (multiple instruction, multiple data stream)
Rechner mit mehrfachem Befehls- und mehrfachem Datenstrom
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
2
Seite 3
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
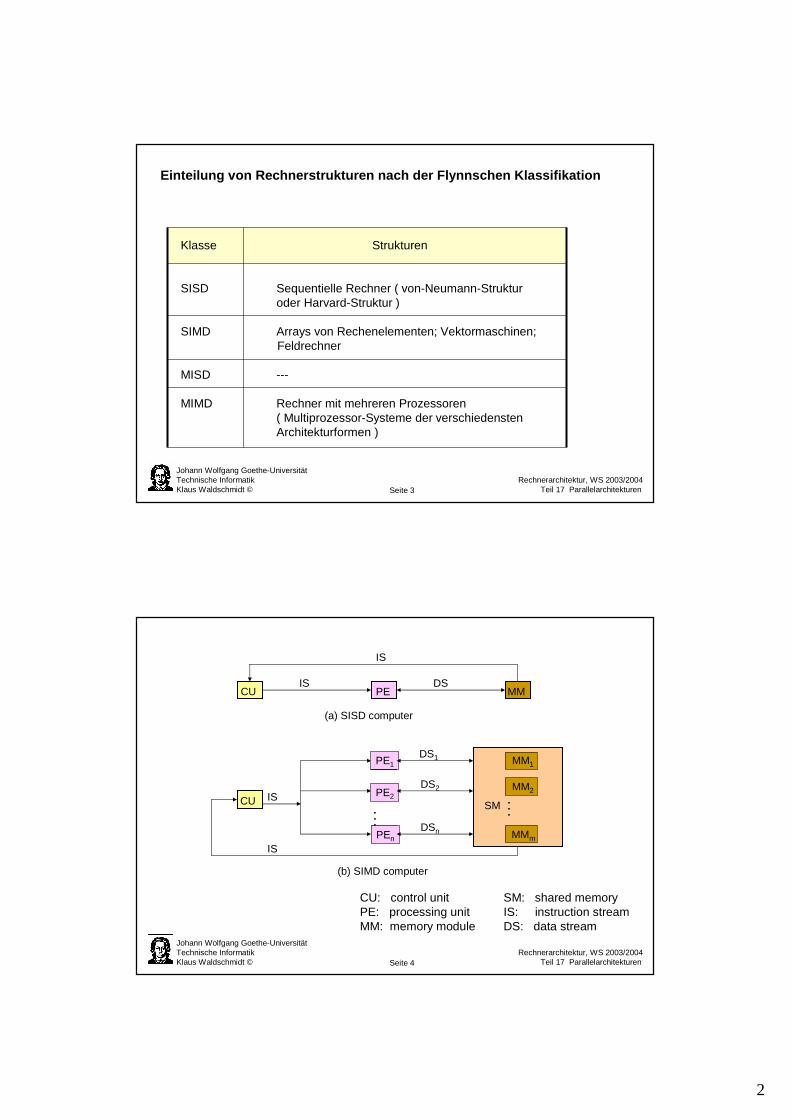
Einteilung von Rechnerstrukturen nach der Flynnschen Klassifikation
Klasse Strukturen
SISD Sequentielle Rechner ( von-Neumann-Struktur oder Harvard-Struktur )
SIMD Arrays von Rechenelementen; Vektormaschinen;Feldrechner
MISD ---
MIMD Rechner mit mehreren Prozessoren( Multiprozessor-Systeme der verschiedenstenArchitekturformen )
Seite 4
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
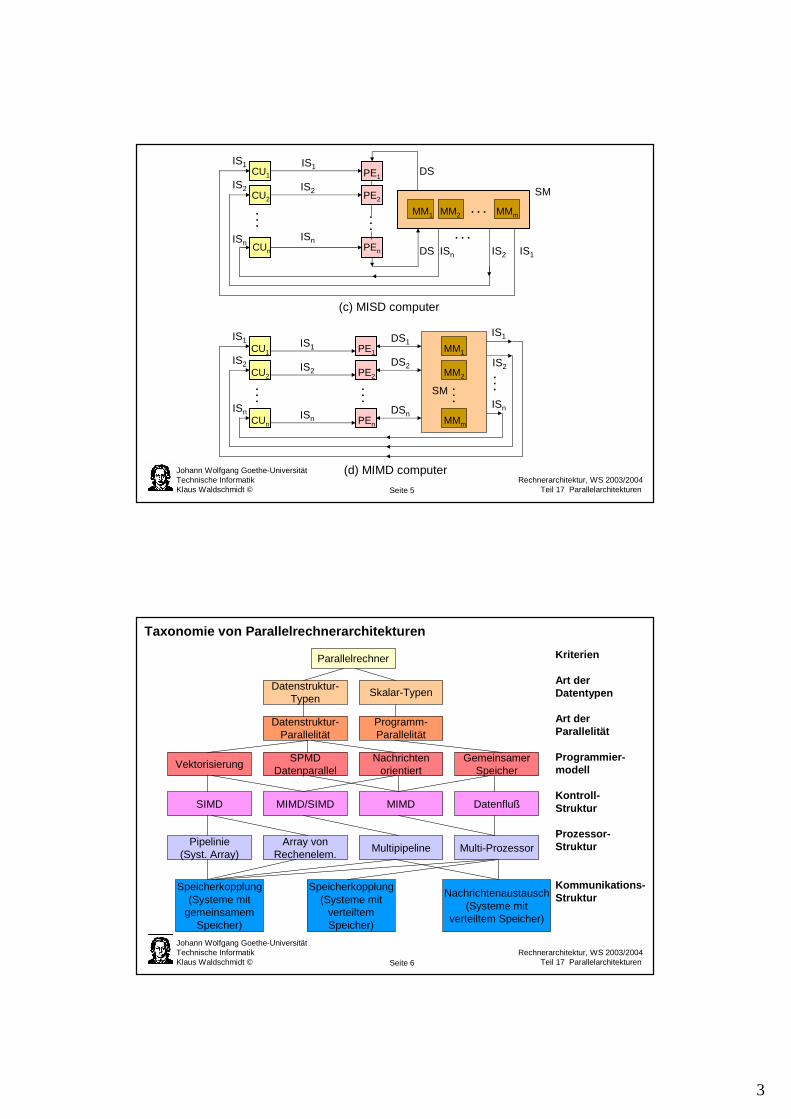
CU: control unit SM: shared memoryPE: processing unit IS: instruction streamMM: memory module DS: data stream
(a) SISD computer
PECU MM
IS
DSIS
PE1
PE2
PEn
IS
. . .
(b) SIMD computer
IS
DS1
DSn
DS2
CU
MM1
MM2
MMm
. . .SM
3
Seite 5
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
(c) MISD computer
(d) MIMD computer
. . .
. . .
. . .PEn DS
DS
SM
CU1
CUn
CU2
IS1
IS2
ISn
IS1IS2ISn
IS1
IS2
ISn
. . .
. . . . .
.
PE1
PE2
PEn
DS1
DS2
DSn
CU1
CU2
CUn
IS2
IS1
ISn
ISn
IS2
IS1IS1
IS2
ISn
. . .
MM1
MM2
MMm
SM
. . .MM1 MM2 MMm
PE2
PE1
Seite 6
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
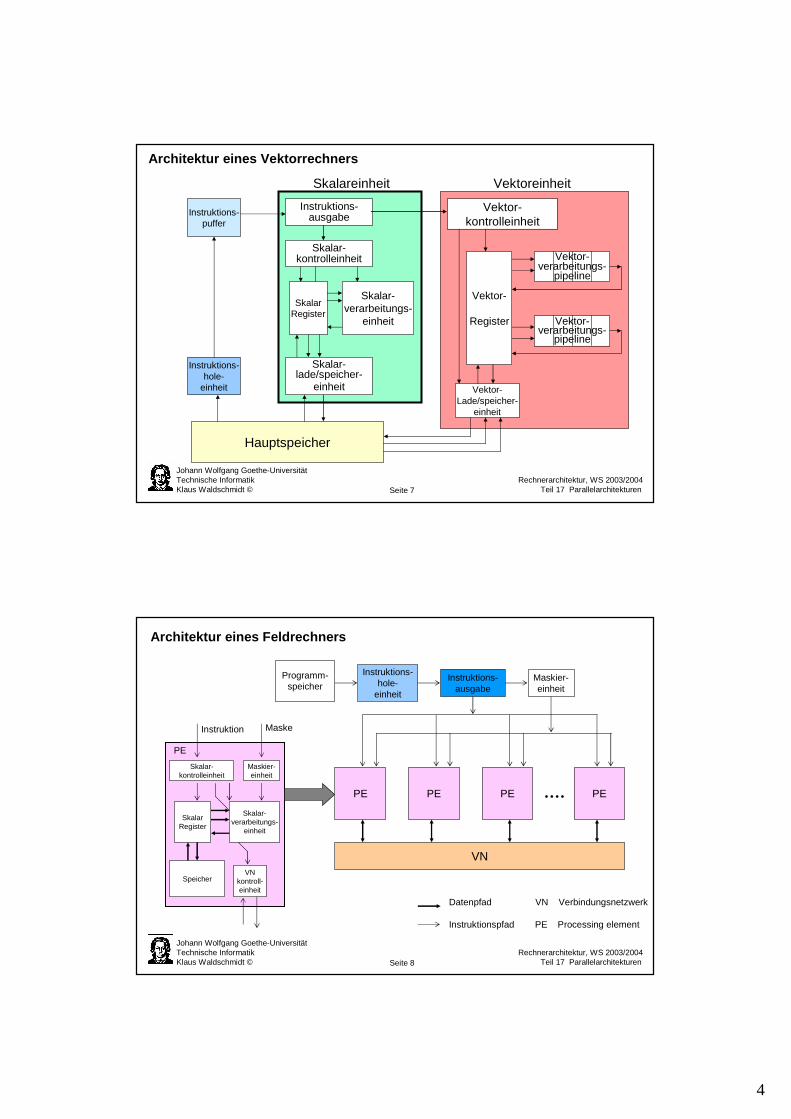
Taxonomie von Parallelrechnerarchitekturen
Parallelrechner
Datenstruktur-Typen
Skalar-Typen
Datenstruktur-Parallelität
Programm-Parallelität
SPMDDatenparallel
VektorisierungNachrichten
orientiertGemeinsamer
Speicher
MIMD/SIMDSIMD MIMD Datenfluß
Array vonRechenelem.
Pipelinie(Syst. Array)
Multipipeline Multi-Prozessor
Speicherkopplung(Systeme mit
gemeinsamemSpeicher)
Speicherkopplung(Systeme mit
verteiltemSpeicher)
Nachrichtenaustausch(Systeme mit
verteiltem Speicher)
Kriterien
Art der Datentypen
Art derParallelität
Programmier-modell
Kontroll-Struktur
Prozessor-Struktur
Kommunikations-Struktur
4
Seite 7
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
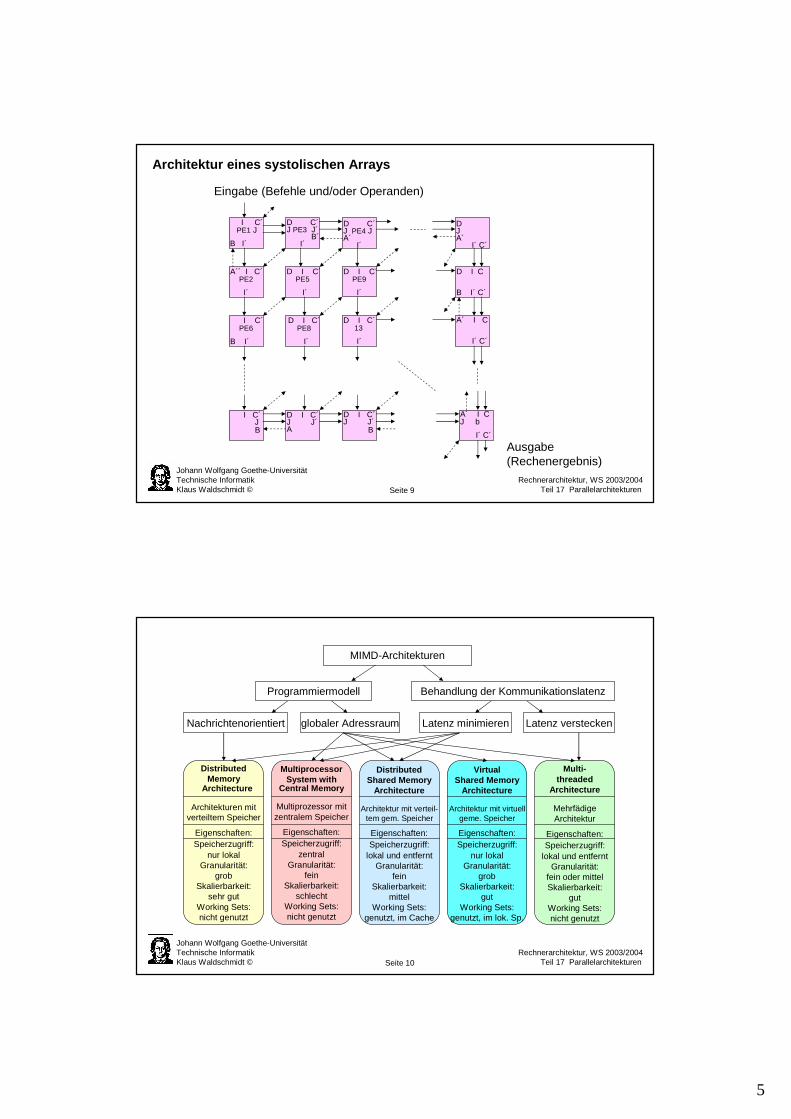
Architektur eines Vektorrechners
Hauptspeicher
Instruktions-hole-
einheit
Instruktions-puffer
Instruktions-ausgabe
Skalar-kontrolleinheit
Skalar-lade/speicher-
einheit
SkalarRegister
Skalar-verarbeitungs-
einheit
Vektor-kontrolleinheit
Vektor-Lade/speicher-
einheit
Vektor-
Register
Vektor-verarbeitungs-
pipeline
Vektor-verarbeitungs-
pipeline
Skalareinheit Vektoreinheit
Seite 8
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Programm-speicher
Instruktions-hole-
einheit
Instruktions-ausgabe
Maskier-einheit
PE PE PE PE
VN
Datenpfad VN Verbindungsnetzwerk
Instruktionspfad PE Processing element
PE
Skalar-kontrolleinheit
Maskier-einheit
SkalarRegister
Skalar-verarbeitungs-
einheit
SpeicherVN
kontroll-einheit
Instruktion Maske
Architektur eines Feldrechners
5
Seite 9
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Architektur eines systolischen Arrays
Eingabe (Befehle und/oder Operanden)
D I C
B I´ C´
D I C´PE5
I´
D I C´PE9
I´
A´´ I C´PE2
I´
D C´J PE4 JA´
I´
D C´J PE3 J´
B´I´
I C´PE1 J
B I´
I C´PE6
B I´
D I C´PE8
I´
D I C´13
I´
A´ I C
I´ C´
D JA´
I´ C´
A´ I CJ b
I´ C´
D I C´J J´
B
D I C´J J´A
I C´JB
Ausgabe(Rechenergebnis)
Seite 10
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
MIMD-Architekturen
Programmiermodell Behandlung der Kommunikationslatenz
Nachrichtenorientiert globaler Adressraum Latenz minimieren Latenz verstecken
Multi-threaded
Architecture
MehrfädigeArchitektur
Eigenschaften:Speicherzugriff:
lokal und entferntGranularität:
fein oder mittelSkalierbarkeit:
gutWorking Sets:nicht genutzt
VirtualShared Memory
Architecture
Architektur mit virtuellgeme. Speicher
Eigenschaften:Speicherzugriff:
nur lokalGranularität:
grobSkalierbarkeit:
gutWorking Sets:
genutzt, im lok. Sp.
DistributedShared Memory
Architecture
Architektur mit verteil-tem gem. Speicher
Eigenschaften:Speicherzugriff:
lokal und entferntGranularität:
feinSkalierbarkeit:
mittelWorking Sets:
genutzt, im Cache
MultiprocessorSystem with
Central Memory
Multiprozessor mitzentralem Speicher
Eigenschaften:Speicherzugriff:
zentralGranularität:
feinSkalierbarkeit:
schlechtWorking Sets:nicht genutzt
DistributedMemory
Architecture
Architekturen mitverteiltem Speicher
Eigenschaften:Speicherzugriff:
nur lokalGranularität:
grobSkalierbarkeit:
sehr gutWorking Sets:nicht genutzt
6
Seite 11
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
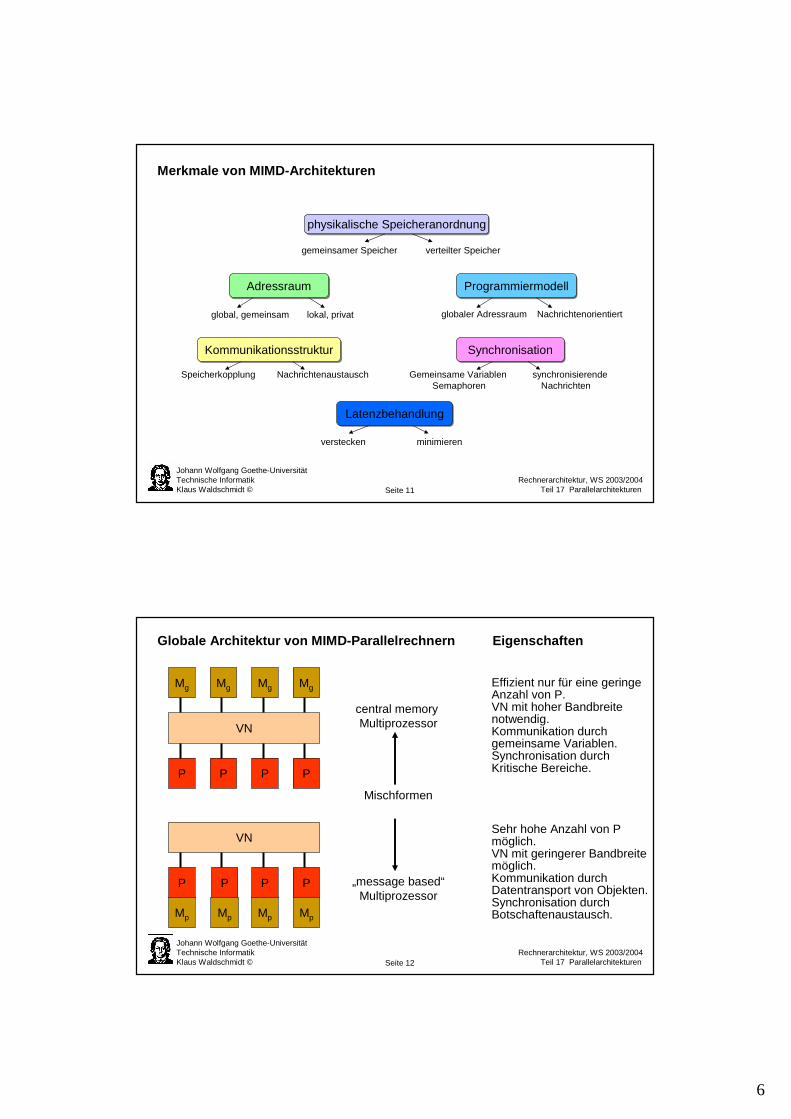
physikalische Speicheranordnungphysikalische Speicheranordnung
AdressraumAdressraum ProgrammiermodellProgrammiermodell
KommunikationsstrukturKommunikationsstruktur SynchronisationSynchronisation
LatenzbehandlungLatenzbehandlung
gemeinsamer Speicher verteilter Speicher
global, gemeinsam lokal, privat globaler Adressraum Nachrichtenorientiert
Speicherkopplung Nachrichtenaustausch Gemeinsame Variablen synchronisierendeSemaphoren Nachrichten
verstecken minimieren
Merkmale von MIMD-Architekturen
Seite 12
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Mg
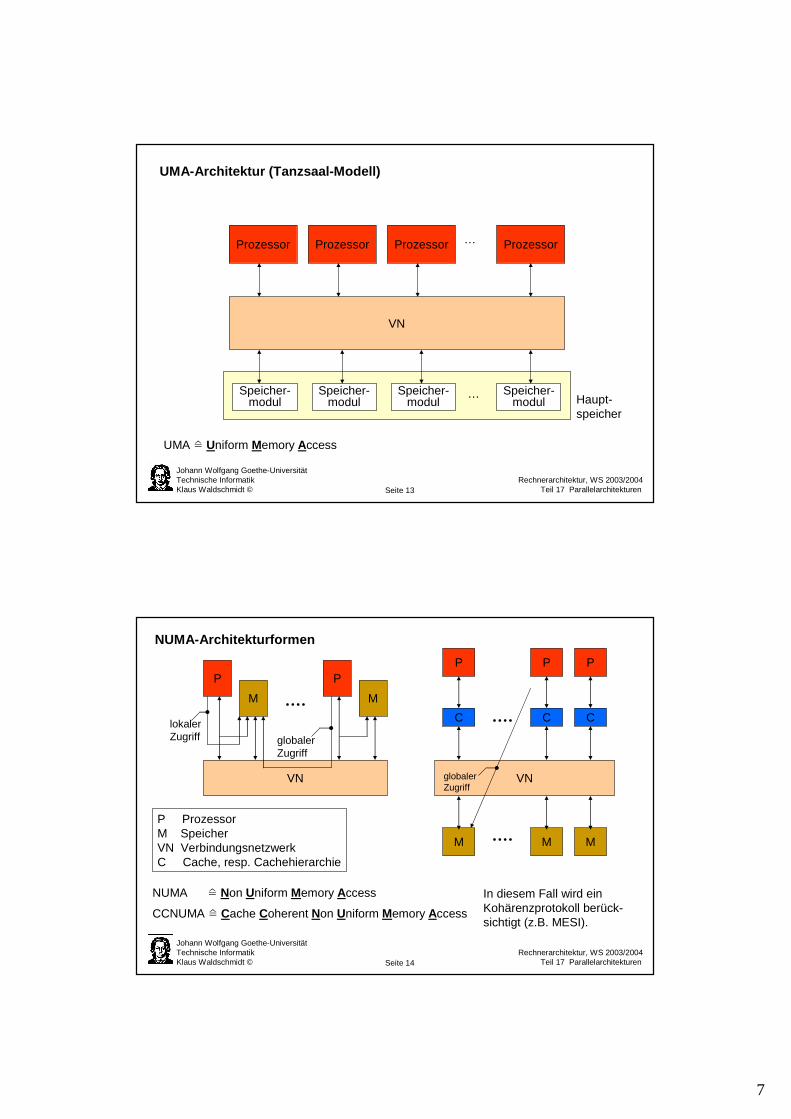
Globale Architektur von MIMD-Parallelrechnern Eigenschaften
Mg Mg Mg
VN
P P P P
central memoryMultiprozessor
Mischformen
„message based“Multiprozessor
VN
P P P P
Effizient nur für eine geringe Anzahl von P.VN mit hoher Bandbreitenotwendig.Kommunikation durch gemeinsame Variablen.Synchronisation durchKritische Bereiche.
Sehr hohe Anzahl von P möglich.VN mit geringerer Bandbreitemöglich.Kommunikation durch Datentransport von Objekten.Synchronisation durchBotschaftenaustausch.Mp Mp Mp Mp
7
Seite 13
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
VN
Prozessor Prozessor Prozessor Prozessor
Speicher-modul
Speicher-modul
Speicher-modul
Speicher-modul
…
…
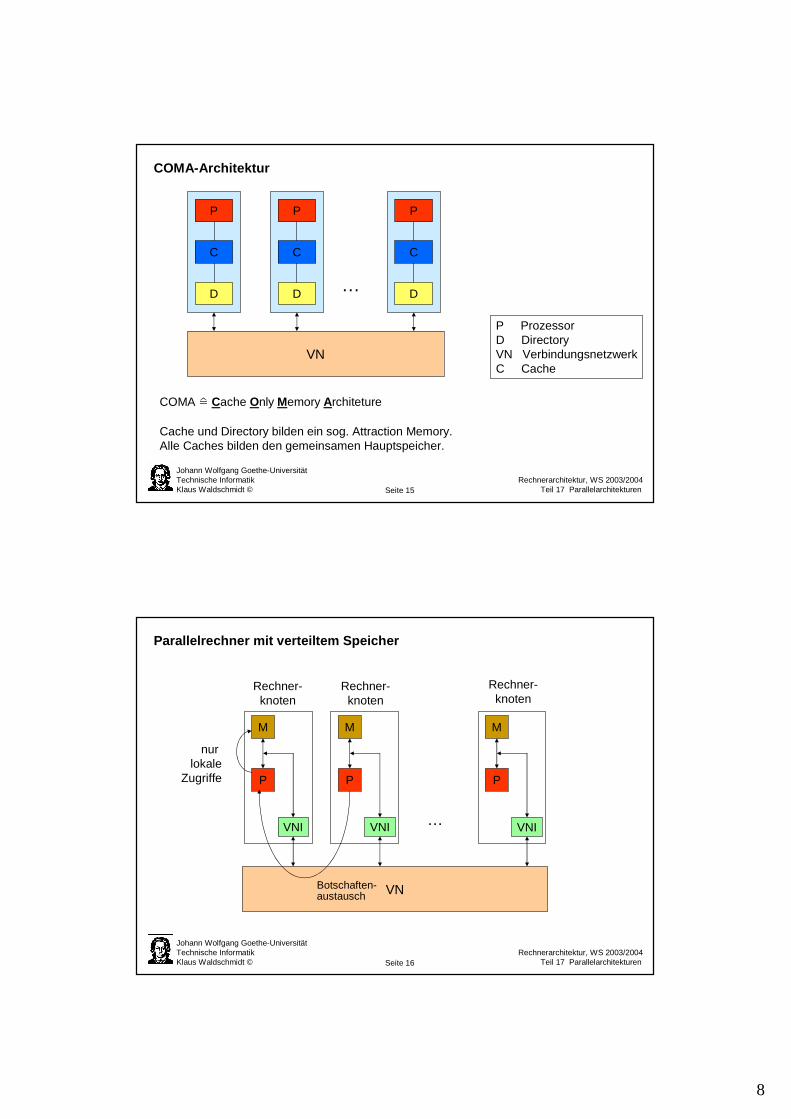
UMA-Architektur (Tanzsaal-Modell)
Haupt-speicher
UMA � Uniform Memory Access
Seite 14
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
P ProzessorM SpeicherVN VerbindungsnetzwerkC Cache, resp. Cachehierarchie
VN VN
P
M M
P
globalerZugriff
lokalerZugriff
C CC
P PP
M M M
globalerZugriff
NUMA-Architekturformen
NUMA � Non Uniform Memory Access
CCNUMA � Cache Coherent Non Uniform Memory Access
In diesem Fall wird einKohärenzprotokoll berück-sichtigt (z.B. MESI).
8
Seite 15
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
COMA-Architektur
P ProzessorD DirectoryVN VerbindungsnetzwerkC Cache
VN
P
D
P
D
P
D…
C C C
COMA � Cache Only Memory Architeture
Cache und Directory bilden ein sog. Attraction Memory.Alle Caches bilden den gemeinsamen Hauptspeicher.
Seite 16
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Parallelrechner mit verteiltem Speicher
VN
Rechner-knoten
Rechner-knoten
Rechner-knoten
Botschaften-austausch
…VNI VNI VNI
P
M
P P
MM
nur lokale
Zugriffe

9
Seite 17
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
gemeinsameVariable
gemeinsamer Adressraum
Prozess BProzess A
Botschaftenaustausch
Prozess A Prozess B
lokaler Adressraum lokaler Adressraum
Botschaft
Kommunikation in Parallelrechnern
gemeinsameVariable
Seite 18
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Verbindungsstrukturen
Beurteilungskriterien, Unterscheidungsmerkmale u. Klassifikation
Das Verbindungsnetz ist das Medium, über das die Kommunikation der Prozessoren untereinander und der Zugriff auf gemein-same Ressourcen abgewickelt werden.
Beurteilungskriterien:
• Komplexität• Durchmesser• Regelmäßigkeit• Blockierungseigenschaft• Erweiterbarkeit• Skalierbarkeit• Ausfalltoleranz• Wegefindung
Systematik
Die Einteilung der Verbindungsnetz-werke wird nach folgenden Kriterien vorgenommen:
1. Topologie2. Verbindungsarten3. Steuerung des Verbindungs-
aufbaues4. Arbeitsweise
Die Topologie spielt die herausragendeRolle, da sie die Skalierbarkeit wesentlich mitbestimmt.

10
Seite 19
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
In Monoprozessoren und in Parallel-rechnern wird das Verbindungsnetz-werk häufig abstrakt als black boxdargestellt. Es ist jedoch häufig sowohlinnerhalb eines Prozessors als auchin Parallelrechnern höherer Granularitätdie entscheidende architekturelleHardwareressource.
Verbindungsnetzwerke dienen demTransport von Daten und Botschaften zwischen den Modulen innerhalb einesProzessors als auch zwischen Pro-zessoren.
Innerhalb von SIMD-Architekturen findet manVerbindungsnetzwerke zur Ankopplung vonSpeichern und zur Konfiguration von Mehr-fachpipelines.
In MIMD-Architekturen dienen sie zur Kommunikation zwischen Prozessen aufden Prozessoren.
Seite 20
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
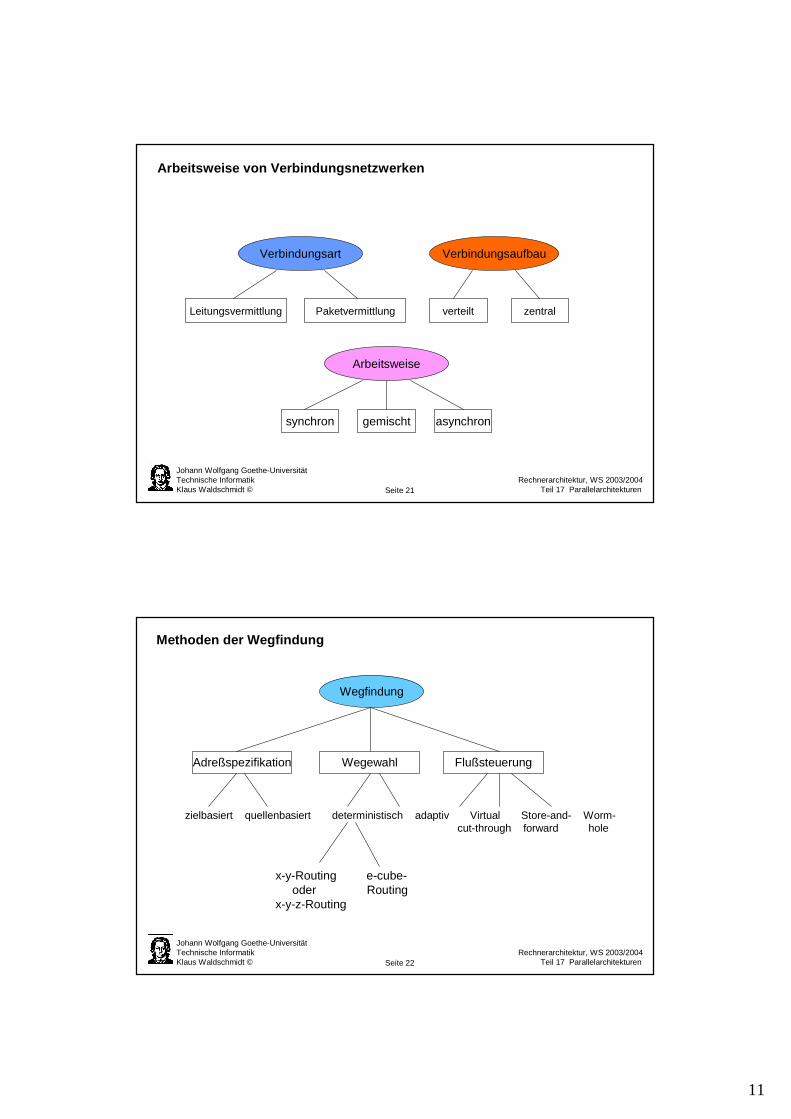
regulär irregulär
statisch dynamisch
1dim 2dim 3dim einstufig mehrstufig
vollst. Vernetzung Hypercube Bus Crossbar Banyan ... Delta
Topologie
Klassifikation von Verbindungsnetzwerken
11
Seite 21
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Arbeitsweise von Verbindungsnetzwerken
Verbindungsart Verbindungsaufbau
Leitungsvermittlung Paketvermittlung verteilt zentral
Arbeitsweise
synchron gemischt asynchron
Seite 22
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Wegfindung
Adreßspezifikation Wegewahl Flußsteuerung
zielbasiert quellenbasiert deterministisch adaptiv Virtual Store-and- Worm-cut-through forward hole
x-y-Routing e-cube-oder Routing
x-y-z-Routing
Methoden der Wegfindung

12
Seite 23
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Direkte Netze (statische Netze, einstufige Netze)
In einem direkten Netz besitzt jedes PE eine Anzahl fester Leitungen zu benach-barten PEs, entlang derer Nachrichten unmittelbar von PE zu PE gesendet werden können. Das Netz beschränkt sich somit auf Verbindungsleitungen; Vermittlungsfunktionen werden durch die PEs selbst ausgeübt, indem Nach-richten entlang der existierenden Leitung gesendet werden.
Da in direkten Netzen nur eine Stufe von Verbindungsleitungen existiert, wird in vielen Arbeiten die Bezeichnung einstu-fige Netze genutzt.
Benutzt wird auch gerne der Begriffstatische Netze, da die Verbindung zwischen Paaren von PEs ohne Möglichkeit der Rekonfiguration erfolgt.
Seite 24
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
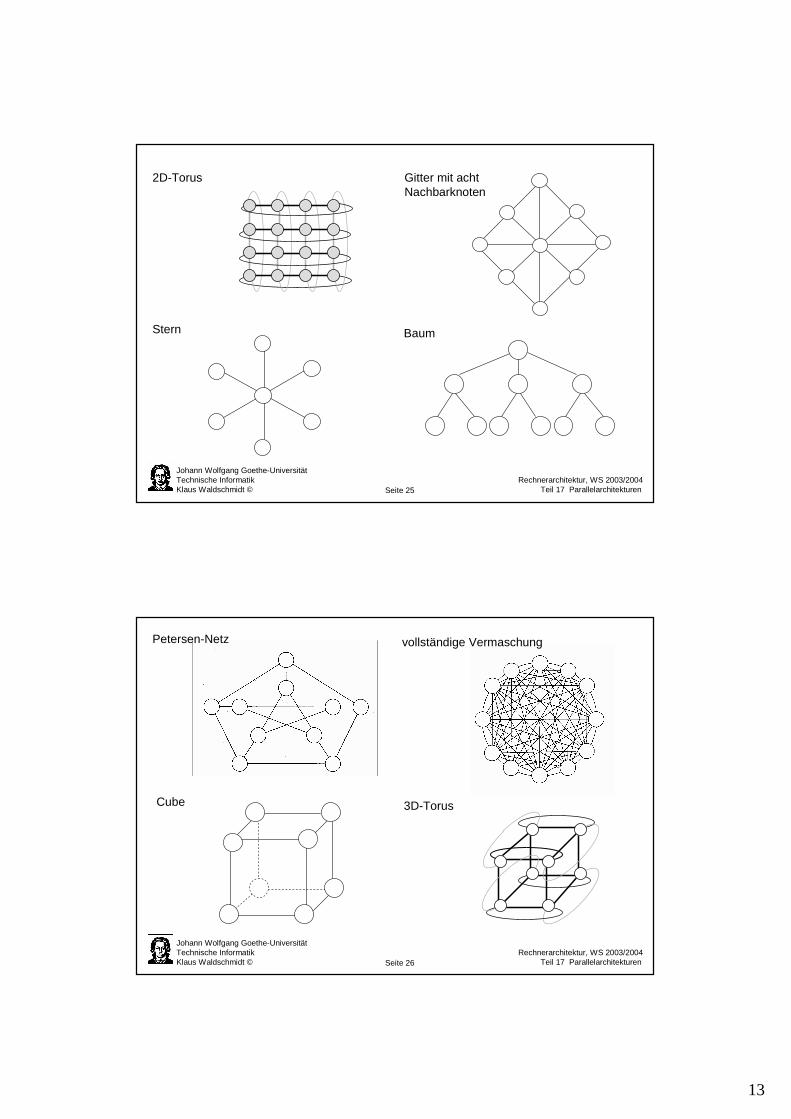
Topologie direkter Netze
Ring
Gitter
Kette
Chordaler Ring
13
Seite 25
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
2D-Torus Gitter mit achtNachbarknoten
Stern Baum
Seite 26
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Petersen-Netz vollständige Vermaschung
Cube 3D-Torus
14
Seite 27
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
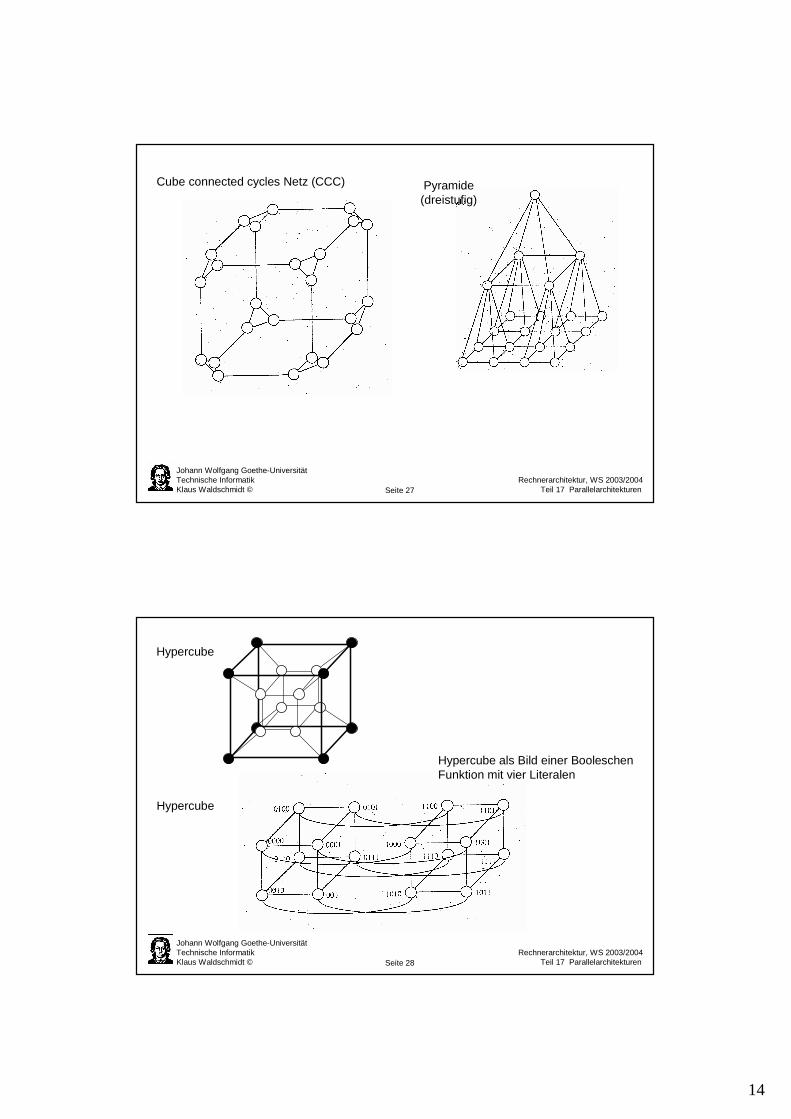
Pyramide(dreistufig)
Cube connected cycles Netz (CCC)
Seite 28
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Hypercube
Hypercube
Hypercube als Bild einer BooleschenFunktion mit vier Literalen

15
Seite 29
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Verbindungsfunktionen
Topologische Verbindungsstrukturen direkterNetze können mittels Verbindungsfunktionenbeschrieben werden.
Verfügt ein Knoten Q eines Netzes über eineVerbindungsfunktion f(Q), so werden beimAusführen dieser Funktion Daten von Kno-ten Q zum Knoten D = f(Q) transferiert.
In einigen Netzen (z.B. Ring und Cube) istdie Verbindungsfunktion für alle Knoten gleich, in anderen Netzen (z.B. Baum)ist sie von Knoten zu Knoten unterschied-lich.
Seite 30
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Indirekte Netze, dynamische Netze, ein- oder mehrstufige indirekte Netze
Ein indirektes Netz führt die Vermittlungsauf-gaben mittels aktiver Koppelelemente eigen-ständig durch. In vielen indirekten Netzen istjedes PE nur über einen Ein- und einen Aus-gang mit dem Netz verbunden. Die Netze bedienen sich einer oder mehrerer Stufenvon Koppelelementen, in denen die Nach-richten durch das Netz geleitet werden.
Die Koppelelemente dieses Netzes habenim einfachsten Fall zwei Ein- und zwei Ausgänge und können zur Datenvermitt-lung die Zustände straight und exchangeannehmen.
Durch Hinzufügen der Zustände upperbroadcast und lower broadcast können Nachrichten von einem Eingang zu beiden Ausgängen vermittelt werden.
Da die Verbindungsstruktur durch die Koppelelemente verändert und somitden jeweiligen Eigenschaften angepasstwerden kann, wird oft der Begriff „dynamische“ Netze genutzt, im Gegen-satz zu den direkten „statischen“ Netzen.
Indirekte Netze unterscheiden sich in der Komplexität, Größe und Funktionalität der Koppelelemente, der Anzahl der Stufen und der Struktur der Leitungsführungzwischen den Stufen.

16
Seite 31
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Q1 Q1
Q1 Q1
O1
O2
I1 I2
Q11 Q21
Q12 Q22
O1
O2
I1 I2I1 I2 I3
Q1 Q2 Q3
O1 O1´
2 x 2 Crossbar Shuffle Bus
Grundstrukturen der dynamischen Netze sind der 2 x 2 Crossbar, das Shuffle und der Bus.Sie stellen einstufige Netze dar.
Schaltelement
Ausgangsknoten(readport)
I - Eingangssignale
O - Ausgangssignale
Q - Steuersignale
Seite 32
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Einstufige Shuffle-Exchange Netz
Das Shuffle dient als Grundstruktur für den Aufbau mehrstufiger Verbindungsnetzwerke.
Verbindungsnetz 2 x 2 Koppelelement (Shuffle)01
23
45
67
01
23
45
67
Koppelelement
Straight Exchange
Lower UpperBroadcast Broadcast
Die Shuffle-Funktion wird von den Verbin-dungsleitungen ausgeführt. Ein 2x2-Koppelelement kann die Daten entwedergeradeaus (Straight) vermitteln oder aus-tauschen (Exchange). Um die Daten von
von einer Quelle zu einer Senke zu transportierensind üblicherweise mehrere Durchläufe (maximal�log2n�) durch das Netz notwendig (rezirkulierendesNetz).Einstufige Shuffle-Exchange Netze werden für Durchschalte- und Paketvermittlung verwendet.
Q (unwahr) Q (wahr)
Q B Q B

17
Seite 33
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
01
23
45
67
01
23
45
67
p2 p1 p0
0 0 00 0 1
0 1 00 1 1
1 0 01 0 1
1 1 01 1 1
p2 p1 p0
0 0 00 0 1
0 1 00 1 1
1 0 01 0 1
1 1 01 1 1
p1 p0 p2
0 0 00 1 0
1 0 01 1 0
0 0 10 1 1
1 0 11 1 1
p1 p0 p2
0 0 10 1 1
1 0 11 1 1
0 0 00 1 0
1 0 01 1 0
shuffle exchange
Einstufiges Verbindungsnetz mit Shuffle und exchange Funktion der Koppelelemente
Seite 34
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Mehrstufige Netze mit Shuffle-Elementen
BayanBaseline
CubeDeltaFlip
Indirekt CubeOMEGA
Alle diese Netze sind nicht blockierungsfrei.Als Schaltelemente werden Shuffle-Koppel-elemente eingesetzt. Die Unterschiede zwischen den Netzen liegen in der Art derLeitungsführung zwischen den Koppel-elementen.
Bei n Ein-/Ausgängen werden log n Ebenenund n/2 ·log n Elementen benötigt.

18
Seite 35
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Durchschaltevermittelndes Netz
In einem durchschaltevermittelnden Netz wird vordem Datentransfer eine vollständige Verbindung zwischen Quelle und Senke aufgebaut, entlang der dann Daten transferiert werden. Dies kann aufunterschiedliche Weise geschehen; so kann der Verbindungsaufbau zum Beispiel durch eine zen-trale Steuerung erfolgen oder durch Versenden eines Vermittlungspaketes, das durch das Netztransferiert wird und dabei eine Verbindung aufbaut.
Paketvermittlung
In einem paketvermittelnden Netz wer-den Vermittlungsinformationen und Da-ten zu einem Paket zusammengefasst, das durch das Netz transferiert wird, ohne jedoch eine vollständige Verbin-dung aufzubauen. Im einfachsten Fall der Speichervermittlung wird ein Paket, das über mehrere Zwischenstufen ver-mittelt werden muss, in jeder dieser Stufen komplett zwischengepuffert(Store-and-Forward-Methode).
Schaltmethodiken
Es wird unterschieden in:
- Durchschaltevermittlung, Leitungsvermittlung
- Paketvermittlung
Seite 36
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Vermittlungsfunktion und Datentransport
Es wird unterschieden in:
- Verbindungsorientierte Kommunikation- Verbindungslose Kommunikation
Verbindungsorientierte Kommunikation
Bei der verbindungsorientierten Kommu-nikation wird eine Verbindung zwischen Quelle und Senke etabliert, die für die gesamte Dauer der Datenübertragunggenutzt wird. Die Verbindung kann in einem durchschaltevermittelnden Systemphysikalisch über eine feste Leitung be-stehen, oder sie kann in einem paketver-mittelnden System lediglich virtuell exis-tieren, indem die Pakete, aus denen dieNachricht besteht, stets über den glei-chen Kommunikationsweg geleitet werden.
Verbindungslose Kommunikation
Bei einer verbindungslosen Kommunikation wer-den Nachrichtenpakete über die jeweils günstig-sten Verbindungsleitungen gesendet, wobei keinbevorzugter Kommunikationsweg existiert. Dies ist nur in einem paketvermittelnden System mög-lich, in dem während des Datentransports auch Vermittlungsfunktionen ausgeübt werden. Bei durchschaltevermittelnden Systemen werden nach erfolgtem Verbindungsaufbau lediglich Nutzdaten transportiert. In Kommunikations-systemen herrscht die verbindungsorientierte Kommunikation vor, sowohl im klassischen analogen Telefonnetz als auch im modernen Breitbandnetz. Bei paketvermittelnden Parallel-rechnern wird je nach Netz auch die verbin-dungslose Kommunikation eingesetzt, (bei-spielsweise bei direkten Netzen mit adaptiver Wegsuche).

19
Seite 37
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Es wird unterschieden in:
- store-and-forward Strategie- worm-hole Strategie
Store-and-forward Strategie
Bei der „store-and-forward“ Strategie werden die Pakete in jeder Vermittlungs-station vollständig zwischengespeichert. Die Adressinformation wird interpretiert und wenn der erforderliche Leitungsweg zur Verfügung steht, wird das Paket zurnächsten Vermittlungsstation weiterge-reicht. Die Vermittlung ist völlig dezentralund eine Flußkontrolle wird erst erforder-lich, wenn die Speicherkapazität der Ver-mittlungsstellen nicht mehr ausreicht.
PaketvermittlungWorm-hole Strategie
Bei der „worm-hole“ Strategie wird das Paket vom Sender in das VN eingespeist und sucht sich wie ein „Wurm“ den Weg durch die Ver-mittlungsstationen. In den Vermittlungsstellen ist nur ein minimaler Speicher vorhanden, der gerade ausreicht um den Kopf einer Nachricht aufzunehmen und die dort gespeicherte Adress-information zu interpretieren. Der Rest der Nachricht liegt dann in den davor benutzten Vermittlungsstellen und wird durch die auto-matische Flußkontrolle beim Weiterschalten desKopfes hinterher gezogen. Am Ende des Paketsbefindet sich eine Endemarkierung, die den Weg für weitere Pakete wieder freigibt. Die Vor-teile dieser Strategie, nämlich die geringe Spei-cherkapazität in den Vermittlungsstellen und derschnelle Weitertransport (Pipelining) durch dasNetzwerk, haben sie sehr bekannt gemacht.
Seite 38
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Nachrichtenkopf
Vermittlungsstelle
Verbindungskanal
„worm-hole“
Nachrichtenende Nachrichten-
pake
t
Vermittlungsstrategie bei der Paketvermittlung (worm-hole)

20
Seite 39
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Worm-hole-Routing
Beim Worm-hole-Routing erfolgt der Daten-transport über Zwischenschritte. Hierbeiwerden die Pakete in kleinere Komponen-ten, die Flits, aufgeteilt. Das erste Flit ent-hält die Verbindungsinformation, und in jeder Stufe wird auf dieser Basis die erfor-derliche Verbindung geschaltet. Nach Auf-bau der Verbindung erstrecken sich die Flits eines Paketes daher über mehrereStufen zwischen Quelle und Senke. Wenndas Paket länger als der aufgebaute Weg ist, wird eine vollst. Verbindung verfügbar, entlang derer weitere Flits schnell trans-portiert werden können.
Die wesentlichen Vorteile des Worm-hole-Routing sind die reduzierte Latenzzeit zwischen dem Absenden einer Nachrichtund dem Empfang an der Senke sowie die variable Paketlänge, die nicht durch Pufferplatz in einer Zwischenstufe be-schränkt wird. Ein Nachteil ist die Mög-lichkeit von Verklemmungen, wodurchNachrichten nie an ihr Ziel gelangenkönnen.
Seite 40
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Vor- und Nachteile des Worm-hole-Routing
Vorteile:
• reduzierte Latenzzeit zwischen Absendeneiner Nachricht und dem Empfang an derSenke
• variable Paketlängedie Paketlänge wird nicht durch Puffer-platz in einer Zwischenstufe beschränkt.
Nachteile:
• Möglichkeit von VerklemmungenNachrichten gelangen nie an ihr Ziel
Abhilfe schafft das Mad Postman Routing oder dasVirtual-Cut-Through Routing in paketvermittelndenNetzen.

21
Seite 41
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
PE A
Router A
PE B
Router B
PE C
Router C
Worm-hole-Routing
Es liegt eine geschaltete Verbindung zwischen den Prozessorelementen A und Cin einem durchgeschalteten Netz vor. Weitere Verbindungsanfragen können zu Konflikten führen.
Seite 42
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Virtual-Cut-Through-Routing
Das Virtual-Cut-Through Routing ist eineErweiterung des Worm-hole Routing fürpaketvermittelnde Netze. Pakete werdenüber das Netz transferiert und in jederStufe weitervermittelt. Ist ein Weg zurnächsten Stufe verfügbar, wird nicht aufdas Eintreffen des gesamten Paketes gewartet. Stattdessen werden die schonverfügbaren Flits schnellstmöglichweitergeleitet. Somit entspricht es demWorm-hole Routing bei dem ein Paket den gesamten Weg von der Quelle bis zur Senke belegen kann.
Ist jedoch keine Verbindungsleitung zur nächsten Stufe verfügbar, so muss der Transfer gestopptwerden. Hierzu existieren in den einzelnen Stu-fen des Netzes Pufferspeicher, die die Pufferungeines kompletten Paketes ermöglichen (Store-and Forward Routing). Das Paket wird weiterge-leitet, sobald eine freie Leitung zur nächstenStufe existiert.
Eine längere Wegblockierung kann nicht eintre-ten, weil gestoppte Pakete vollständig in denRoutern zwischengespeichert werden können.Jedoch ist die Paketlänge durch die Größe deskleinsten Puffers begrenzt.Wird diese Begrenzung nicht eingehalten, er-folgt ein Pufferüberlauf.

22
Seite 43
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Senke A
Senke B
Zugriffskonflikt am Netzausgang
Senke A
Senke B
Konflikt im Inneren des Netzes
Konflikte
Werden Nachrichten von zwei odermehr Quellen gleichzeitig zur selbenSenke gesendet, so resultiert ein Ausgangskonflikt und nur eine derNachrichten kann vermittelt werden. In vielen Netzen ergeben sich Kon-flikte auch innerhalb des Netzes, wenn Nachrichten zwar an unter-schiedliche Senken adressiert sind,intern streckenweise jedoch den-selben Weg benötigen.
Während interne Konflikte in blockie-rungsfreien oder rearrangierbarenNetzen vermieden werden können,sind Ausgangskonflikte verkehrsab-hängig und können daher durch topologische Maßnahmen nicht umgangen werden.
Quelle A
Quelle B
Quelle B
Quelle A
Seite 44
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Klassifizierung indirekter Netze
Indirekte Verbindungsnetze können einstufig(s = 1) oder mehrstufig (s > 1) sein. Beispielefür einstufige indirekte Netze sind dasCrossbar Netz und das einstufige Shuffle-Exchange Netz. Mehrstufige Netze werdenauch als Multistage Interconnection Net-works (MINs) bezeichnet.
Verbindungsnetze, in denen genau einWeg von jeder Quelle zu jeder Senkeexistiert, werden als indirekte Einpfad-netze bezeichnet. Existiert mehr als einWeg, so handelt es sich um indirekteMehrpfadnetze.

23
Seite 45
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Verhalten eines Crossbar Netzes
Das Crossbar Netz (such Kreuzschienen-verteiler oder Koppelvielfach) ermöglichtbeliebige blockierungsfreie Permutationen(auch Multicast und Broadcast) ohne Re-konfiguration. Der Verteiler besteht aushorizontalen und vertikalen Bussen.
0
1
2
3
3210
An jedem Kreuzungspunkt (Koppelpunkt)befindet sich ein Schalter durch den derhorizontale mit dem vertikalen Bus ver-bunden werden kann.
Crossbar mit 4 Ein- und Ausgängen
Koppelpunkt
Die eingezeichneten Verbindungen zeigen eine Permutation von Eingang kzu Ausgang (k+1)mod4.
Seite 46
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
Einsatz von Crossbar Netzen
Dieses einstufige und indirekte Netz findetaufgrund der hohen Leistungsfähigkeit undder hohen Regularität in sehr schnellenSystemen und als Baustein mehrstufiger, hierarchischer großer Netze Verwendung.
Crossbar mit 4 Ein- und 6 Ausgängen
Die eingezeichneten Leitungen zeigen Multicast-Verbindungenvon Eingang 0 nach 0 und 3 sowie von Eingang 3 zu den Ausgängen 1, 2, 4 und 5.
Insgesamt sind jedoch E · A Schalter erforder-lich, so dass die Netzgröße aufgrund der hohenHardwarekomplexität und aus Kostengründenbegrenzt bleibt.
0
1
2
3
321 540
24
Seite 47
Johann Wolfgang Goethe-UniversitätTechnische Informatik Rechnerarchitektur, WS 2003/2004Klaus Waldschmidt © Teil 17 Parallelarchitekturen
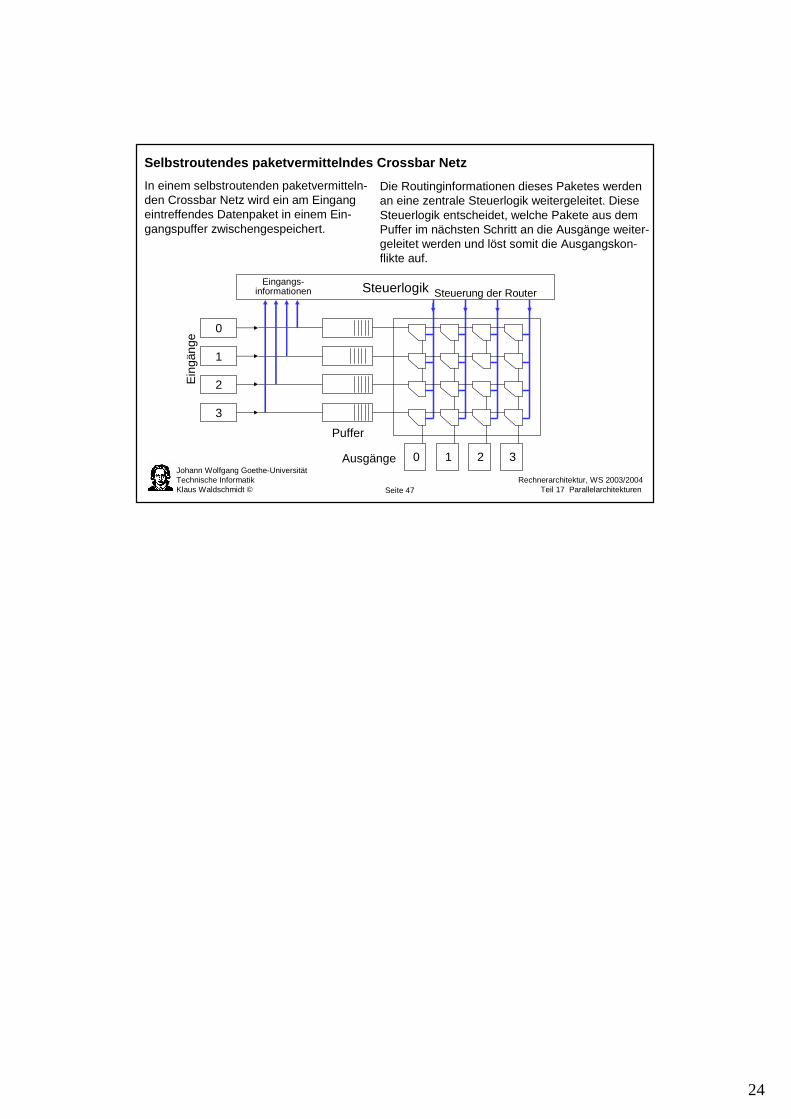
Selbstroutendes paketvermittelndes Crossbar Netz
0
1
2
3
Steuerlogik Steuerung der Router
Ausgänge
Puffer
Ein
gäng
e
Eingangs-informationen
In einem selbstroutenden paketvermitteln-den Crossbar Netz wird ein am Eingang eintreffendes Datenpaket in einem Ein-gangspuffer zwischengespeichert.
Die Routinginformationen dieses Paketes werden an eine zentrale Steuerlogik weitergeleitet. Diese Steuerlogik entscheidet, welche Pakete aus dem Puffer im nächsten Schritt an die Ausgänge weiter-geleitet werden und löst somit die Ausgangskon-flikte auf.
3210