redesigning mpi shared memory communication for large multi-core architecture
TRANSCRIPT

Redesigning MPI shared memory communication for large multi-core architecture
Miao Luo, Hao Wang, Jerome Vienne, Dhabaleswar K. Panda Computer Science - Research and Development, Volume 28, Issue 2-3,
pp 137-146, May 2012

• 背景:メニーコア普及に伴いイントラノード通信の重要性が増している。イントラノードでのMPI通信は共有メモリを用いて実装されることが多い。
• 問題:従来のイントラノード通信の実装はコア数増加に関してスケーラビリティが考慮されていなかった。
• 提案:スケーラビリティを実現するイントラノード通信の手法を提案した。
• 評価:提案手法はコア数が多い環境で遅延や帯域幅を改善した。
2

背景

インターノードでのMPI通信
4
Ethernet, InfiniBand, etc.
ノードA ノードB
メッセージ
• MPIとは並列計算のためのライブラリの規格 • 1対1通信や集団通信などを定義している • 分散並列環境で動く並列プログラムの開発を助ける

イントラノードでのMPI通信
5
ノードA
プロセスC
プロセスA プロセスB
プロセスD
メッセージ
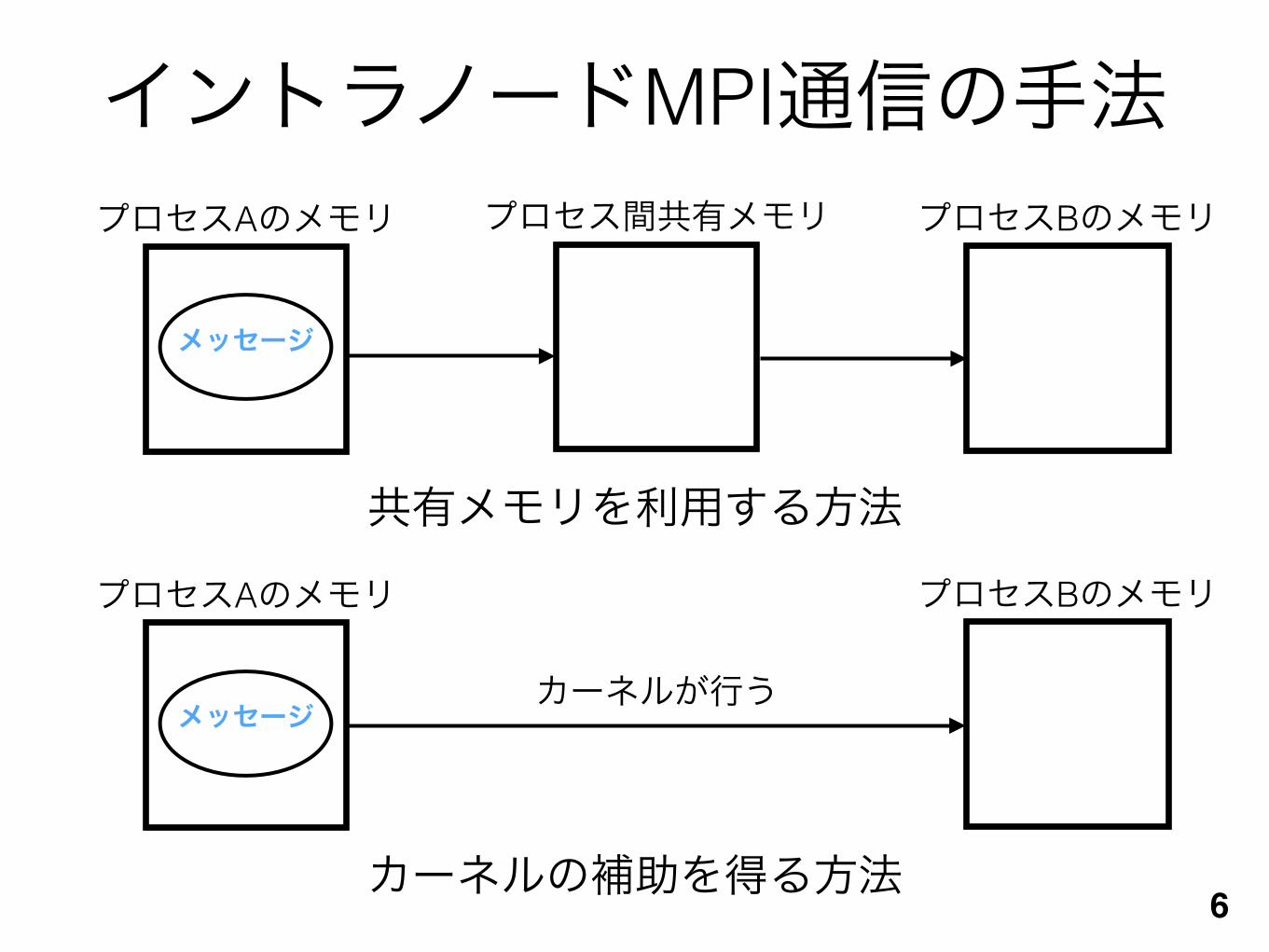
イントラノードMPI通信の手法
6
プロセスAのメモリ
メッセージ
プロセス間共有メモリ プロセスBのメモリ
プロセスAのメモリ
メッセージ
プロセスBのメモリ
共有メモリを利用する方法
カーネルの補助を得る方法
カーネルが行う

イントラノードMPI通信の手法
7
帯域幅 レイテンシ セキュリティ メモリアクセス
共有メモリ 低 低 安全 多い
カーネル補助 高 高 やや危険 少ない

メニーコアの普及• 現在のコンピュータ・クラスタのノードはマルチ
CPUやマルチ・コアがほとんど
• これからも1ノードあたりのコア数は増加し、cluster-on-chipの時代が来ると考えられる
8

イントラノード通信のスケーラビリティ
• コア数が増えていったとき、従来の共有メモリを用いたイントラノード通信はスケールするのか?
• 既存の実装について調査した:
• MVAPICH2 (輪講で紹介するのはこちらのみ)
• MPICH2-Nemesis
9

MVAPICH-2 (小さいデータサイズ)
10
データ 送信側が書いたサイズ
受信側が読んだサイズ
データ 送信側が書いたサイズ
受信側が読んだサイズ
A-B間の共有バッファ
A-C間の共有バッファ
データ 送信側が書いたサイズ
受信側が読んだサイズ
B-C間の共有バッファ
・ ・ ・
• 全てのプロセスのペアごとに共有バッファを用意する
• プロセス数がn個なら空間計算量は
• 送信側と受信側が共有バッファを監視して読み込み・書き込みのタイミングを決める
O(n2)

MVAPICH-2 (大きいデータサイズ)
11
共有バッファ 共有バッファ
共有バッファ 共有バッファ
送信側プロセスの 共有バッファプール
送信側プロセス
受信側プロセス
メッセージ
共有バッファのポインタ

問題

既存のイントラノード通信の問題
• MPICH2やMPICH2-Nemesisのイントラノード通信は比較的少ないコア数を想定していた
• コア数がスケールするにつれて問題が発生する:
• 共有データ構造への頻繁なアクセス
• 頻繁なポーリング
• メッセージが大きい場合のメモリ効率13

共有データ構造への頻繁なアクセス
14
キャッシュ
コア
コア
コア
コア
キャッシュ
コア
コア
コア
コア
メモリ
キャッシュ インバリデーション
メモリバス競合

頻繁なポーリング
15
データ 送信側が書いたサイズ
受信側が読んだサイズ
データ 送信側が書いたサイズ
受信側が読んだサイズ
A-B間の共有バッファ
A-C間の共有バッファ
データ 送信側が書いたサイズ
受信側が読んだサイズ
B-C間の共有バッファ
プロセスA
プロセスB
プロセスC
1プロセスがポーリングするバッファの数はO(n)

メッセージが大きい場合のメモリ効率
• 大きいメッセージのための共有バッファプールは、各プロセスごとに一定量確保される
• 大きいメッセージを送らないプロセスでは、このプールは無駄となってしまう
16

提案

提案• スケーラビリティの問題を解決するため、以下の3つの手法を提案する:
• Shared Tail Cyclic Buffer 共有データのサイズを減らす
• State-Driven Polling Schemeポーリングする頻度を減らす
• On-demant Global Shared Memory Pool メモリ利用効率を上げる
18

Shared Tail Cyclic Buffer
19
Shared Tail
送信側プロセス
受信側プロセス
新しいデータ
Head Tail
• ポインタが末尾まで進んだら先頭ヘループ • メッセージがバッファに収まりきらない場合は分割
HeadTail

State-driven Polling scheme
20
公平な ポーリング
• 全てのプロセスを普通プロセスか優先プロセスに分類する
• 頻繁にメッセージを送るプロセスは優先プロセスになる
優先 ポーリング
優先のみ ポーリング
• 公平なポーリング: 全てのプロセスをポーリング • 優先ポーリング: 優先プロセス→普通プロセスの順でポーリング
• 優先のみポーリング: 優先プロセスのみポーリング

On-demand Global Shared Memory Pool
21
バッファ バッファ
プロセスAの 共有バッファプール
バッファ バッファ
プロセスBの 共有バッファプール
・・・
送信側 受信側

評価

実験環境• MPI実装: OpenMPI (OMPI), MPICH2 (NEMESIS),
MVA-PICH2 (MV2), 提案手法 (NEW)
• 計算ノード:
• 32コア - 2.4GHz AMD Magny-Cours, 64GB Mem
• 64コア -1.4GHz AMD Opteron, 128GB Mem
• 実験回数: 1000回23

遅延の評価• OSUベンチマークで評価
• MPI_SendとMPI_Recvによるping-pong処理
2432コア 64コア
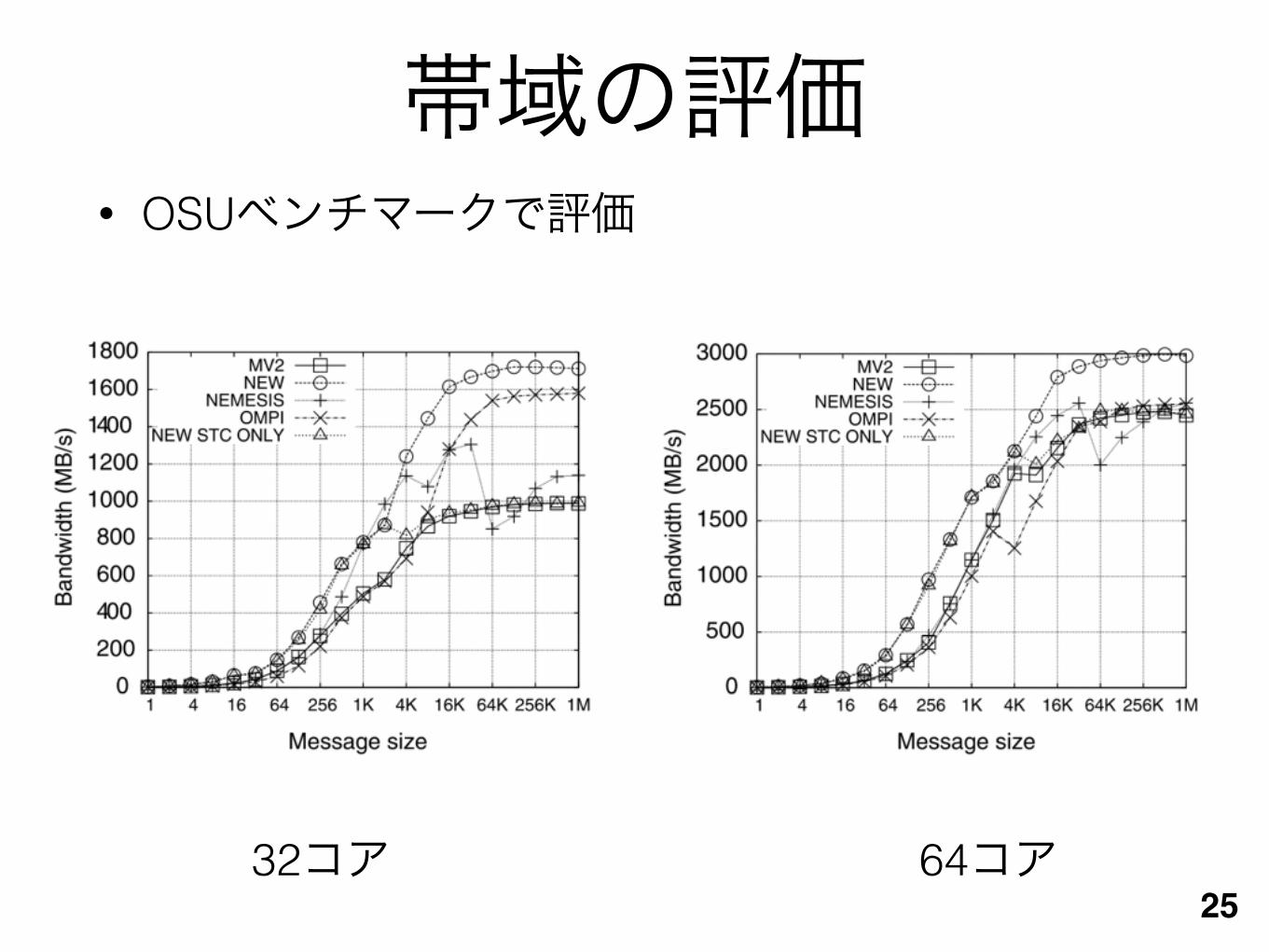
帯域の評価• OSUベンチマークで評価
2532コア 64コア
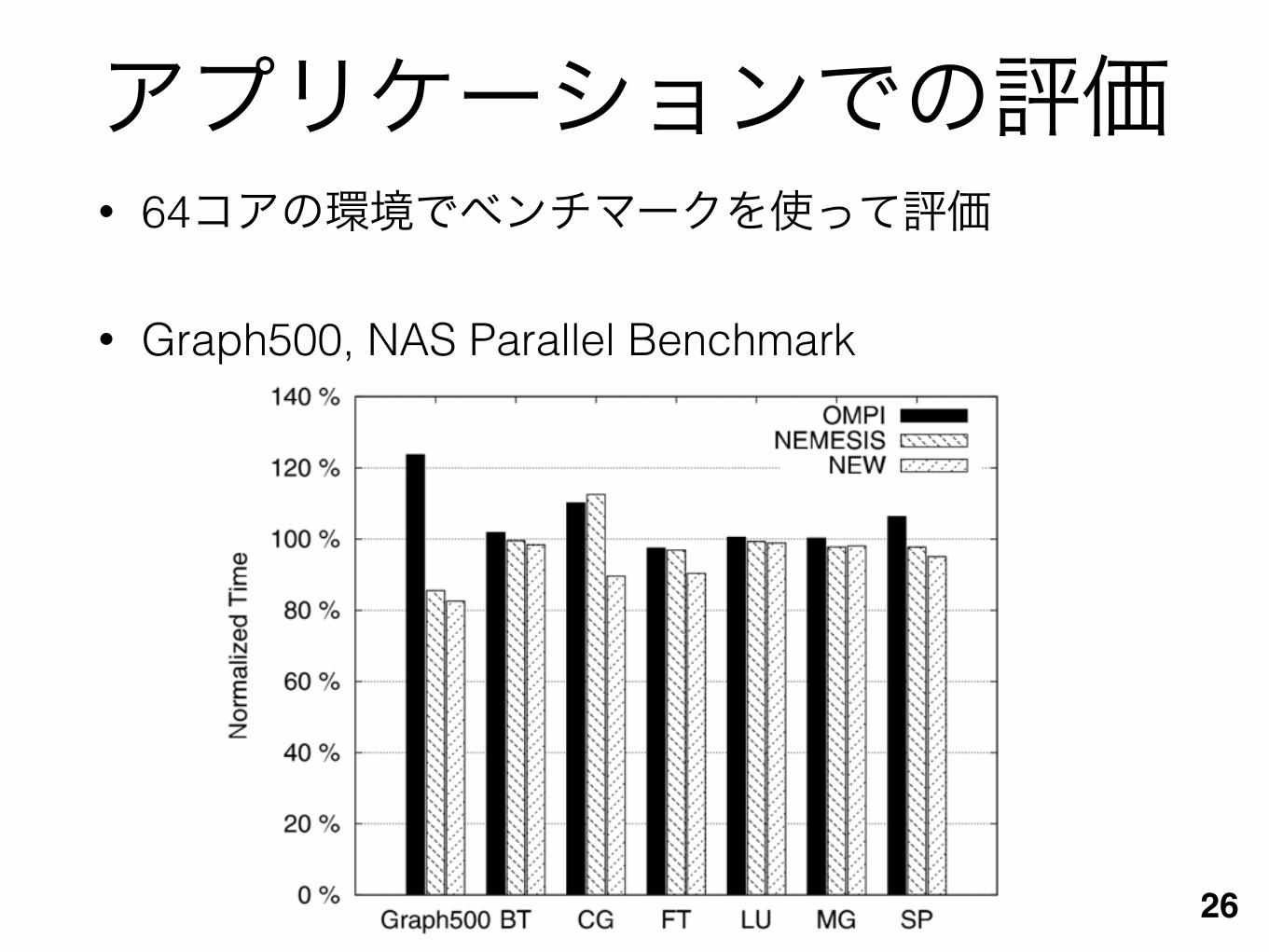
アプリケーションでの評価• 64コアの環境でベンチマークを使って評価
• Graph500, NAS Parallel Benchmark
26

まとめ
• メニーコア時代の到来とともに、イントラノード通信のスケーラビリティが重要となる
• 提案手法はスケールした際の共有バッファへのアクセス、ポーリング頻度、メモリ利用効率を改善した
• 実機で評価した結果、提案手法は遅延・帯域・アプリケーションのパフォーマンスなどを改善していた
27