検索技術の活用による広告配信relevance向上
TRANSCRIPT

1
検索技術の活⽤による広告配信Relevance向上
FB Ads API Meetup #3
2016年10⽉ 篠原英治

2
Name:Eiji Shinohara / 篠原 英治Role:• AWS Solutions Architect
- Ad Tech- Subject Matter Expert
- Search servicesTwitter : @shinodoggBlog : http://shinodogg.comSlideshare: http://www.slideshare.net/shinodogg
Who am I?
#AWSAdTechJP
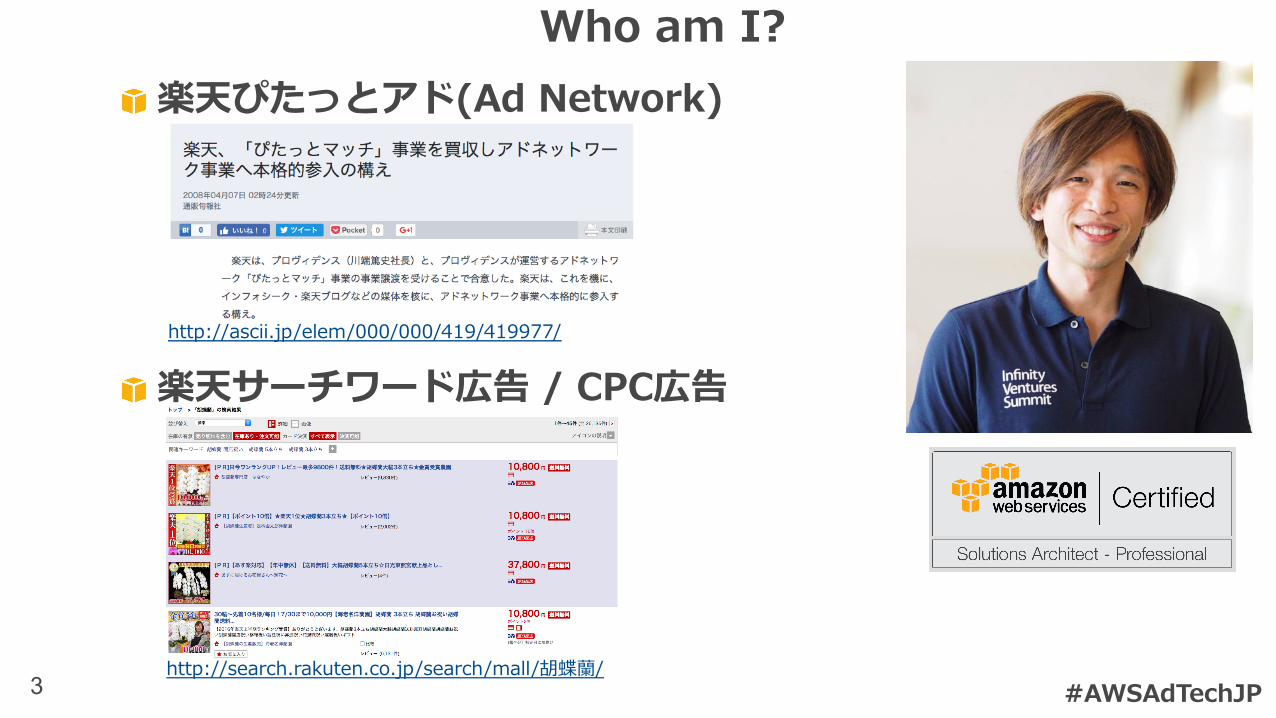
3
楽天ぴたっとアド(Ad Network)
楽天サーチワード広告 / CPC広告
Who am I?
http://ascii.jp/elem/000/000/419/419977/
http://search.rakuten.co.jp/search/mall/胡蝶蘭/#AWSAdTechJP

4
AWS Solutions Architect

5
AWS Solutions Architect
AWSに関するご相談よろず承ります!

6
AWS Solutions Architect
にしても、、、圧倒的○○○○感!

7
Facebook広告API

8
Facebook広告API

9
Facebook広告API

10
Facebook広告API
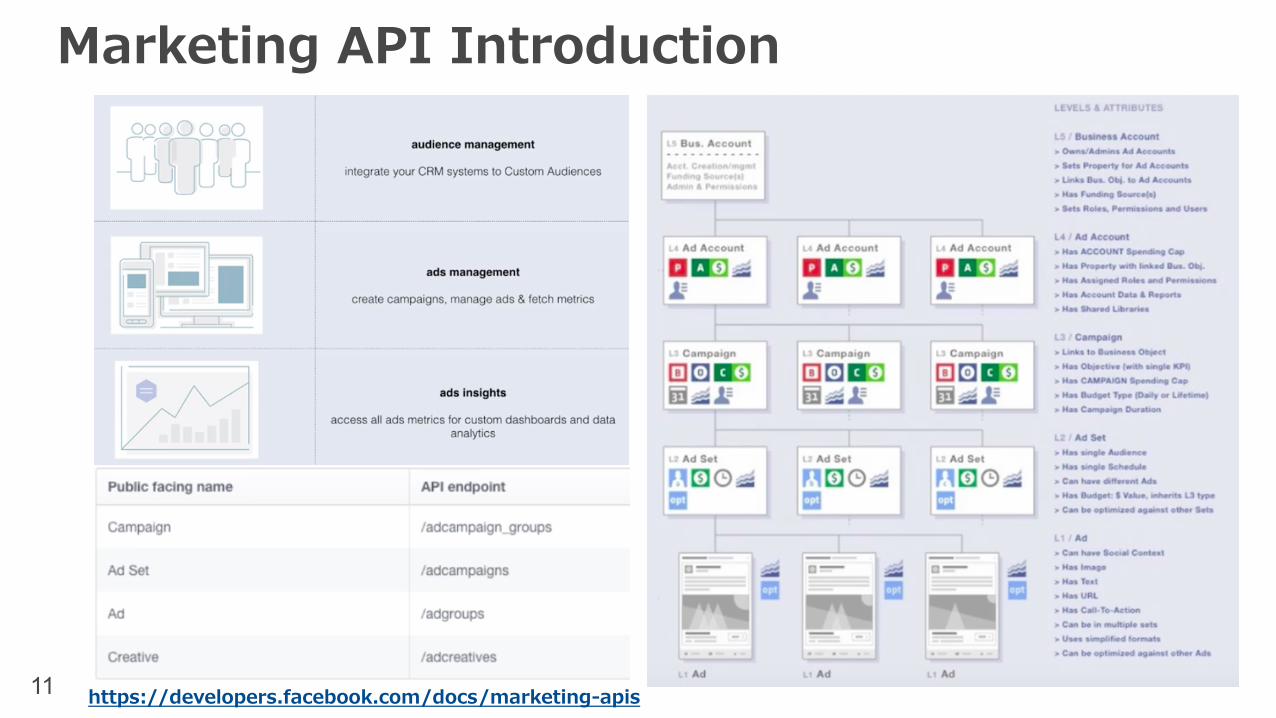
11
Marketing API Introduction
https://developers.facebook.com/docs/marketing-apis

12
Marketing API Introduction
https://developers.facebook.com/docs/marketing-apis

13
Marketing API update• 気が利いてる感: フィードバックを重要視していると予想– Sandbox mode
• こういうのないの?って⾔われてた…• AWSにもサンドボックス的なアカウントあると嬉しい
かも– Ads Copy API
• 単純にコピーするだけならありそうだけど• Deep Copy / Shallow Copyは嬉しい

14
Lucene/Solr Revolution 2016• 検索技術に関するカンファレンスに参加しました@Boston

15
Lucene/Solr Revolution 2016• Target(スーパーマーケット)の事例– 『アーモンド』で検索されたら、、
• アーモンドチョコレート• アーモンドミルク• アーモンドキャンディ
– 多岐にわたる商材からドンピシャのものを表⽰するのは難しい

16
Lucene/Solr Revolution 2016• Target(スーパーマーケット)の事例 - チューニング前– 7 ring check binder (⽳が7つのバインダー)

17
Lucene/Solr Revolution 2016• Target(スーパーマーケット)の事例 - チューニング後– 7 ring check binder (⽳が7つのバインダー)

18
Lucene/Solr Revolution 2016• Flipkart(インドのEC)の事例 - チューニング前– 検索⽤のインデックスが更新された頃には在庫切れ…
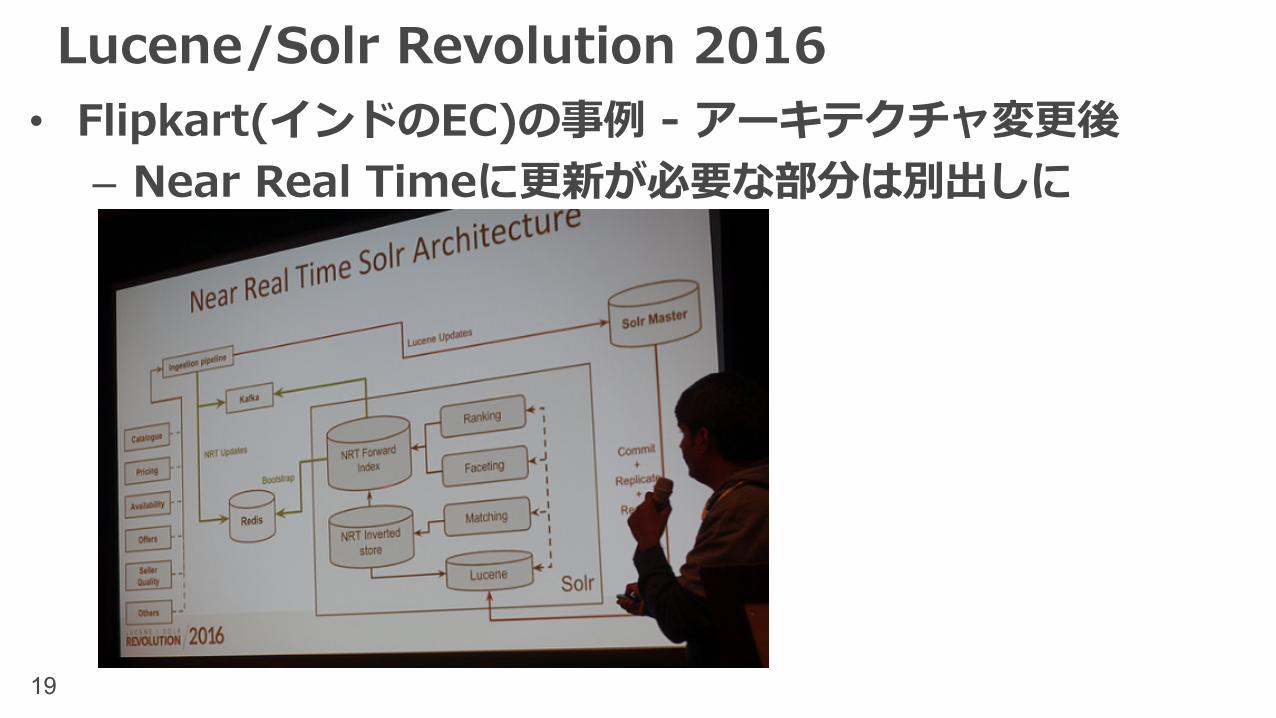
19
Lucene/Solr Revolution 2016• Flipkart(インドのEC)の事例 - アーキテクチャ変更後– Near Real Timeに更新が必要な部分は別出しに
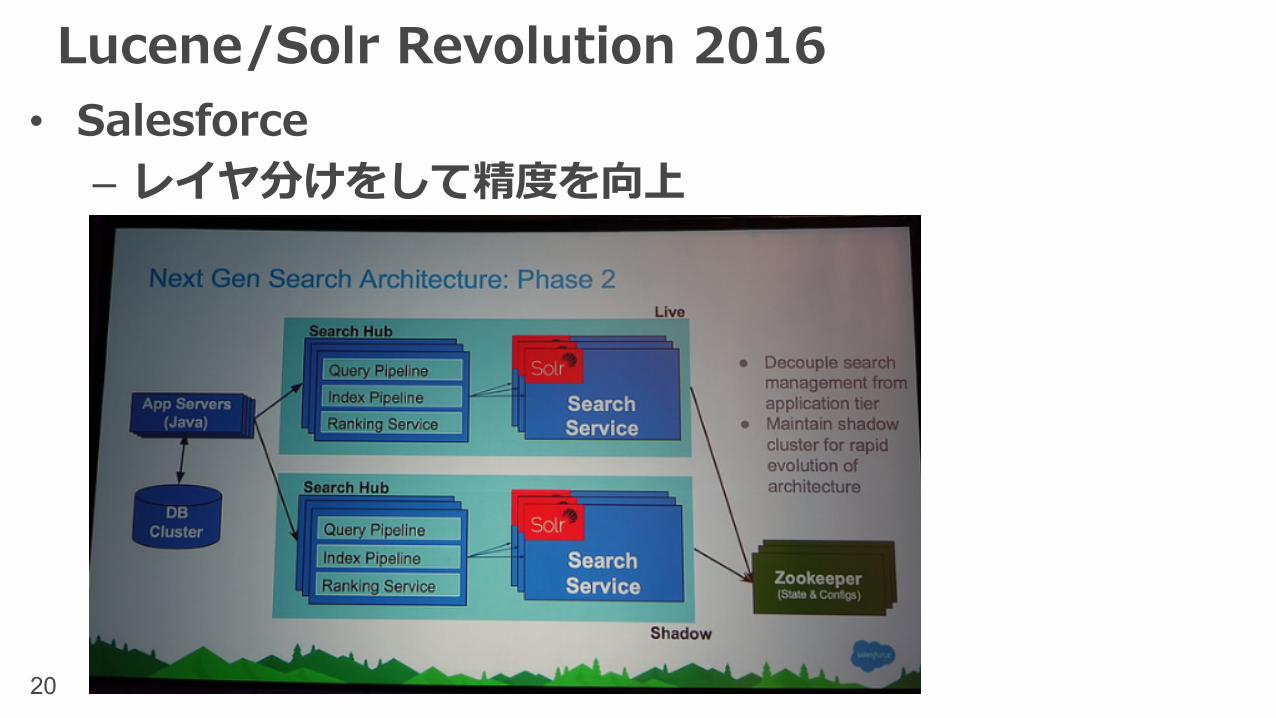
20
Lucene/Solr Revolution 2016• Salesforce– レイヤ分けをして精度を向上

21
Lucene/Solr Revolution 2016• Salesforce– レイヤ分けをして精度を向上
• 検索エンジンでSimilarity(TF-IDF)• 独⾃コンポーネントでソート• 機械学習アプローチで作成したモデルを使って精度向上

22
Lucene/Solr Revolution 2016• 検索技術のこれまでとこれから: Lucidworks Treyさん– 基本: 転置インデックス, TF-IDF, Query Formulation,,,– 拡張: シノニム展開, Entity Recognition– クエリ: クエリのパース, ブースト,,– Relevancy:機会学習, AB Testing– Self-Learning
23
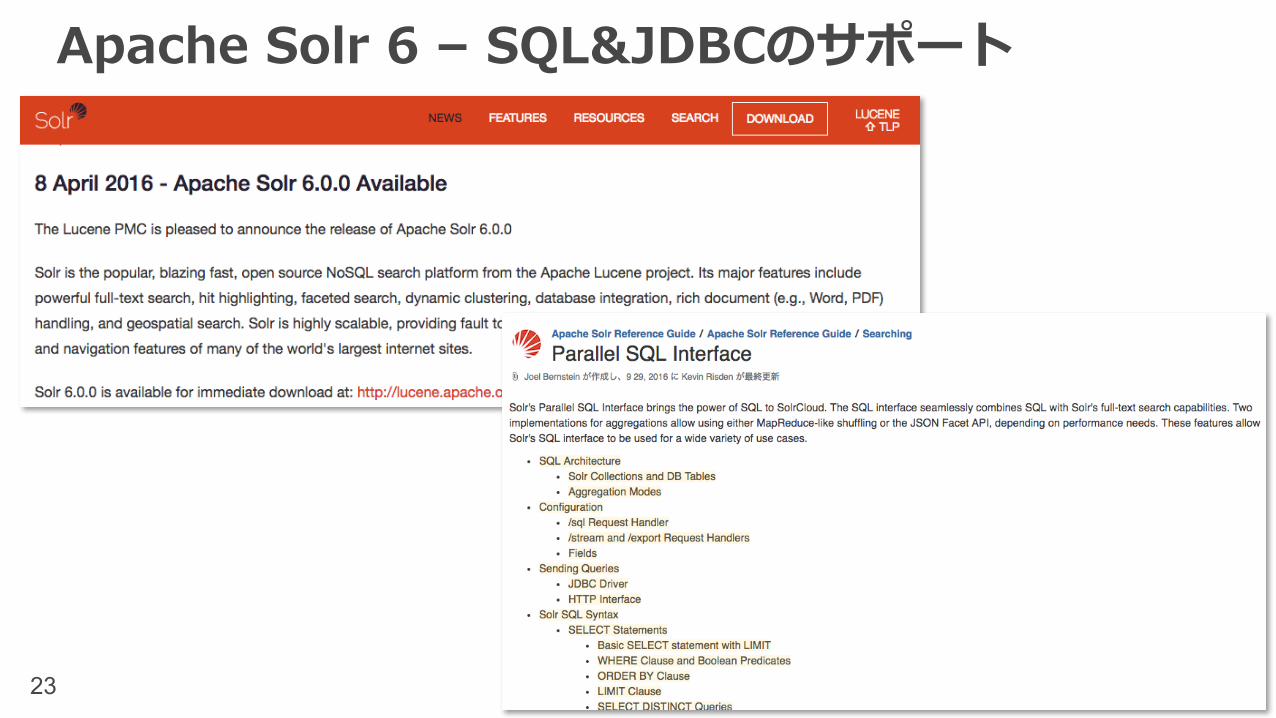
Apache Solr 6 – SQL&JDBCのサポート
24
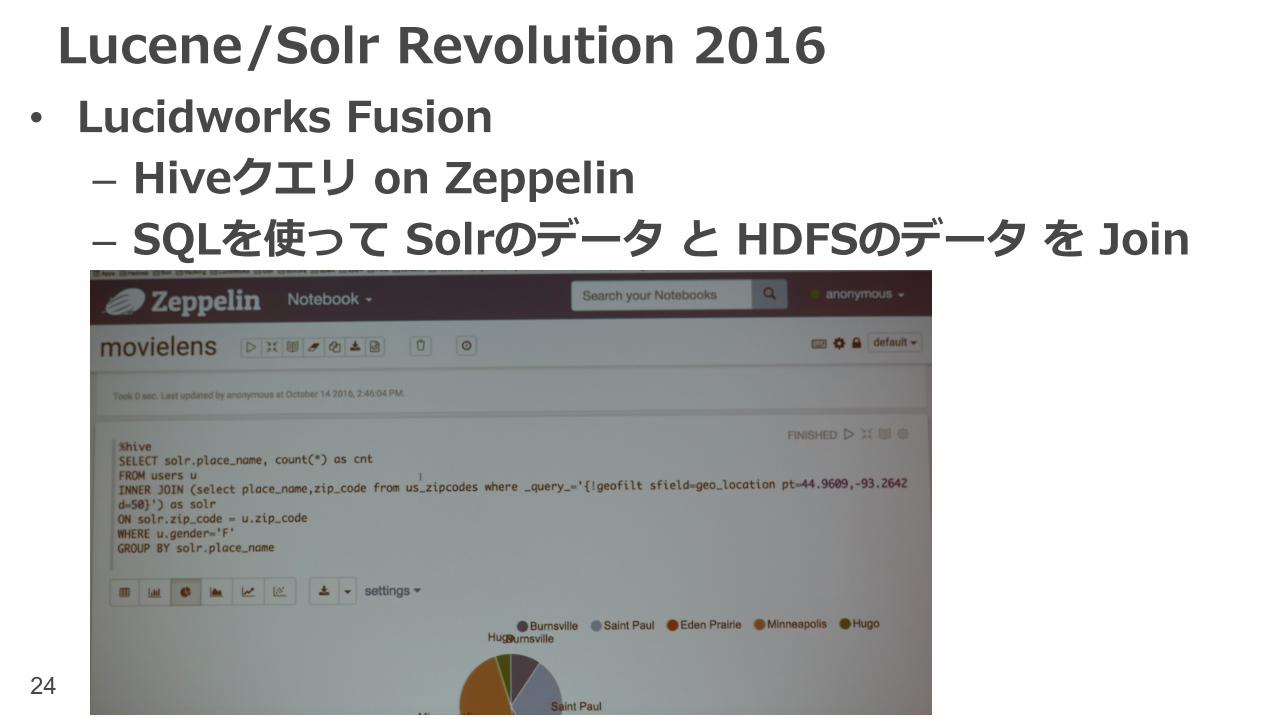
Lucene/Solr Revolution 2016• Lucidworks Fusion– Hiveクエリ on Zeppelin– SQLを使って Solrのデータ と HDFSのデータ を Join
25
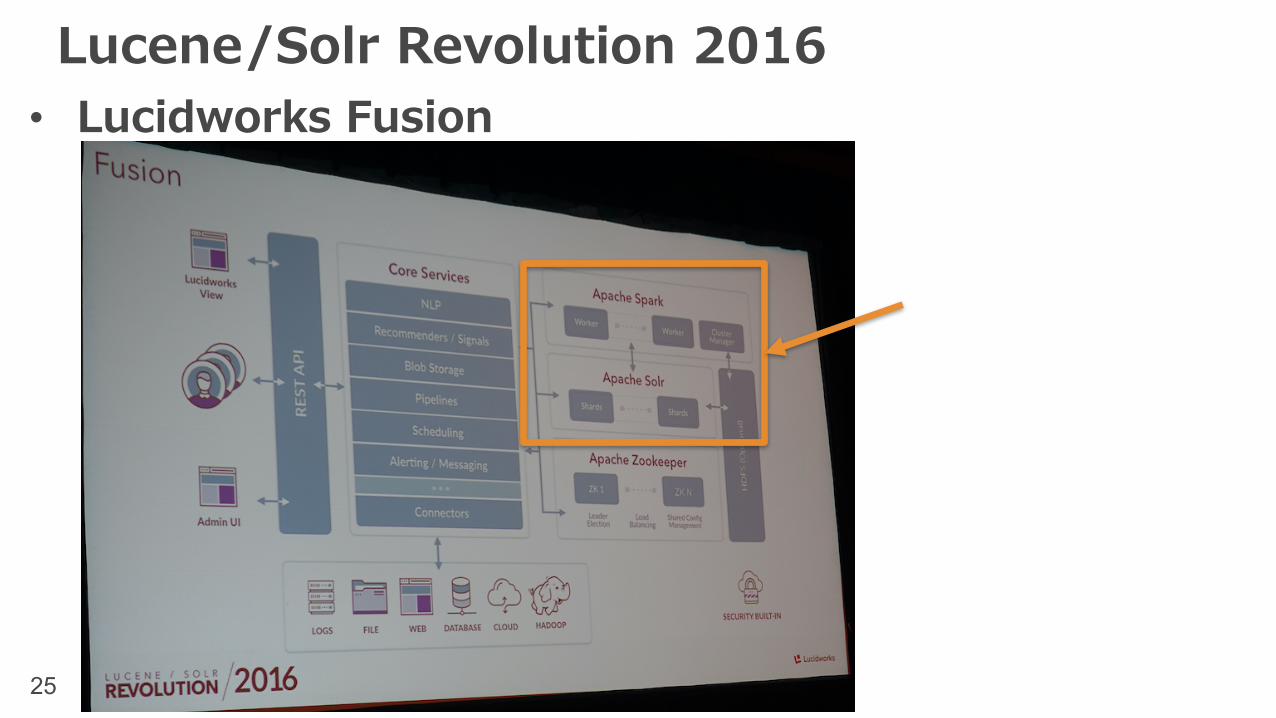
Lucene/Solr Revolution 2016• Lucidworks Fusion

26
Lucene/Solr Revolution 2016• Lucidworks Fusion

27
Lucene/Solr Revolution 2016• Lucidworks Fusion
k-means, random forests, support vector machine,,,アドテクの世界でもBigData活⽤の⽂脈で⽤いられている技術

28
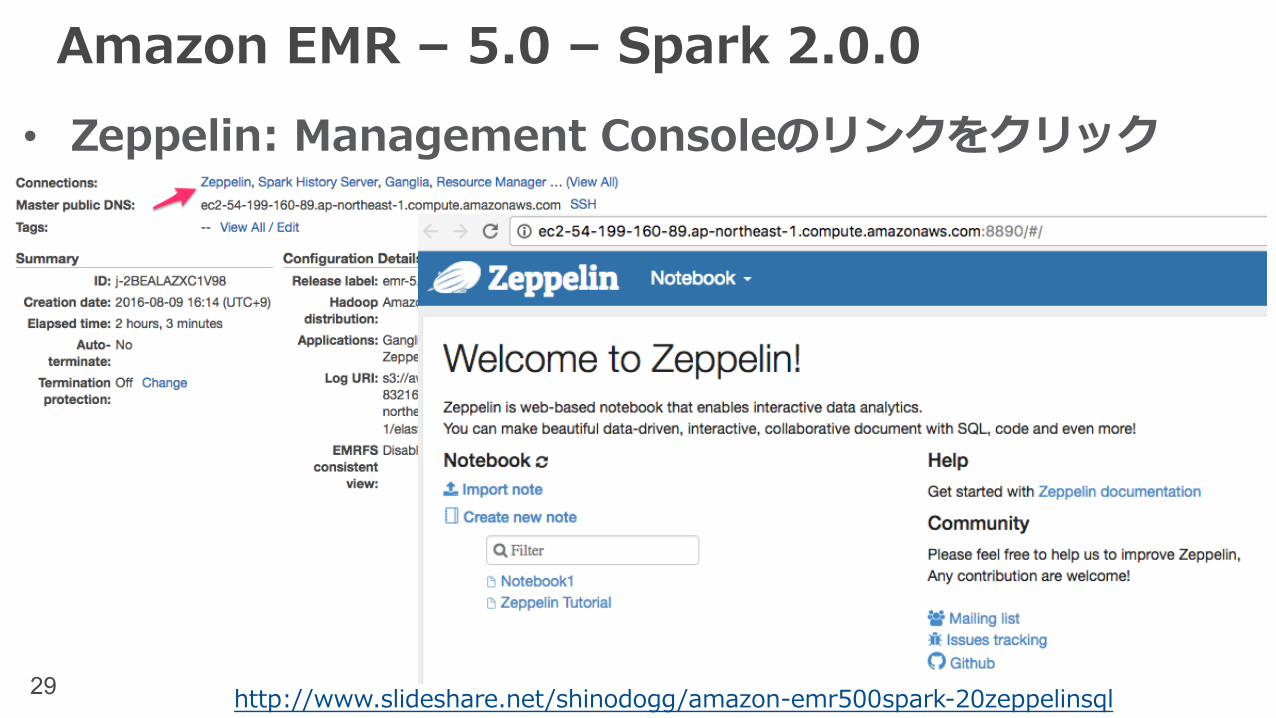
Amazon EMR – 5.0 – Spark 2.0.0
http://www.slideshare.net/shinodogg/amazon-emr500spark-20zeppelinsql
29
• Zeppelin: Management Consoleのリンクをクリック
Amazon EMR – 5.0 – Spark 2.0.0
http://www.slideshare.net/shinodogg/amazon-emr500spark-20zeppelinsql
30
• 開発チームには Apache Solr の Commiter もいます :)Amazon CloudSearch / Amazon Elasticsearch Service
https://twitter.com/shinodogg/status/533290209430216705
https://www.instagram.com/p/BLiYQI7gfZB/
31
精度の⾼い広告配信• 検索技術 と BigData技術 組み合わせて Relevance向上!
http://www.slideshare.net/shinodogg/accerelating-adtech-on-aws-awsadtechjp https://twitter.com/hisashinakayama/status/786508986140983296

32
アドテクノロジーもアマゾンで#AWSAdTechJP