ボケるrnnを学習したい (chainer meetup 01)
TRANSCRIPT

ボケるRNNを学習したい
Chainer Meetup #01
Motoki Sato @aonotas
12/19
1

佐藤 元紀(さとう もとき) 来年4月からNAIST松本研に行く予定 休学中のM1です @aonotas あおのたす
Chainer Meetupの参加枠に漏れる →LT枠で参加を決める(水曜) ボケるRNNを学習しよう! →学習コードを動かす(木曜) →学習が終わらない (今ココ 2時間前) →バグが見つかる (1時間前) →一応学習できた…? 温かい目で見守ってください。
自己紹介
2

Karpathy, Andrej, and Li Fei-Fei. "Deep visual-semantic alignments for generating image descriptions." arXiv preprint arXiv:1412.2306 (2014).
画像をRNNで説明する研究
3
1. CNNで特徴抽出 2. RNN(LSTM)で説明文を生成

ボケるRNNを学習したい
4
写真で一言ボケるサービス
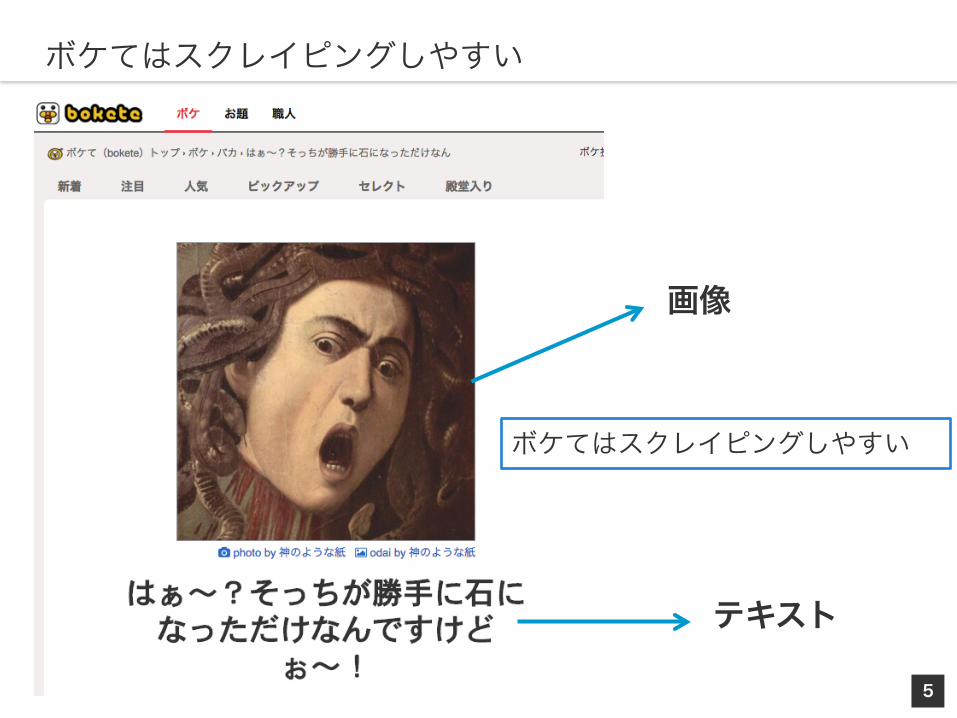
画像
ボケてはスクレイピングしやすい
5
テキスト
ボケてはスクレイピングしやすい

学習済CNNに画像を入力して、 最終層のベクトルを使う @mattyaさんのCNNのコードが参考になります https://github.com/mattya/chainer-gogh/blob/master/models.py RNN(LSTM)の入力として画像の特徴ベクトルを入力する Chainerのexamplesに入っているtrain_ptbが参考になります。 https://github.com/pfnet/chainer/blob/master/examples/ptb/train_ptb.py LSTM 1層 入力層:dropout 出力層:softmax → Linear (誤差関数でsoftmax_cross_entoropyを使ってるため不要) 誤差関数:softmax_cross_entropy
学習コード
6
CNN
RNN
構造

学習データに対してボケる
7
予測: 何 回 押し て も もう お湯 が 出 ない </s> (予測文字と同じ文章.)

未知データに対してボケる
8
正解: 「 俺 の 彼女 が 観 に 来 て くれ てる 」 『 俺 の 彼女 も だ 』 「 手 振っ てる 」 『 俺 の 彼女 も だ 』 「 投げ キッス まで 」 『 ? … … 俺 の 彼女 も だ 』 </s>

未知データに対してボケる
9
予測: 友人 の AV コレクション が ひたすら 顔 </s>

• Chainerで学習コードを書く時間は短縮できる • 今回500サンプル → 2万サンプルでやってみたい
• 一応発表に間に合って良かった
• ボケるRNNはでき…る!?
感想
10