s01 t3 data_engineer
TRANSCRIPT

データサイエンスと データエンジニア
草薙 昭彦 (@nagix) MapR Technologies

自己紹介
• 草薙 昭彦 (@nagix) • MapR Technologies
データエンジニア
NS-‐SHAFT
無料!

業界の話

IT業界のトレンド
• ビッグデータ、クラウド、IoT/M2M • データ活用の位置付けの変化 – 分析が企業の競争力に – リアルタイムなデータそのものがビジネス価値に

なぜ今データサイエンスか
• 深い顧客の理解なしではビジネスは難しくなってきている – Web、モバイル、SNS、センサーなど、顧客に関す
るあらゆるデータ
• 人材の不足 – 個人の勘と経験ではなく、学術として整備 – 米国の大学ではコースが充実

Google トレンド

で、なぜ今?
• なぜ大きな会社も小さな会社も? – 巨大銀行からスタートアップまで
• なぜいろいろな業界で? – 金融、Web、製造、セキュリティ、・・・
• なぜいろいろなアプリケーションで? – 広告ターゲティング、不正検知、故障予測、・・・
• なぜ同じタイミングで?

ありがちな回答 より大量のデータが、より急速に生成される データサイズが最大容量の1台のコンピュータにも収まりきらなくなる データの生成や格納に必要なコストが下がり続けている
これは正しい回答ではありません

分析のスケーリングの法則
• 80:20 ルール – はじめはわずかな努力で大きな成果が得られる – ところが急激にリターンが減っていく
• 一方、分析に必要なコストは – これまで: 規模を増やすとコストは指数関数的に
増加 – Big Data: コストの増加は直線的
• 分析のROIの構造が根本的に変わった!

2,0000 500 1000 1500
1
0
0.25
0.5
0.75
Scale
Value
データの規模、システムの規模、チームの規模
分析で得られる価値

2,0000 500 1000 1500
1
0
0.25
0.5
0.75
Scale
Value
データの規模、システムの規模、チームの規模
これまで: 分析にかかるコスト

2,0000 500 1000 1500
1
0
0.25
0.5
0.75
Scale
Value
データの規模、システムの規模、チームの規模
これまで: 分析で得られるリターン

2,0000 500 1000 1500
1
0
0.25
0.5
0.75
Scale
Value
Big Data: 分析にかかるコスト

2,0000 500 1000 1500
1
0
0.25
0.5
0.75
Scale
Value
Big Data: 分析で得られるリターン

データサイエンティストって どういう職業?
• ゴール – データに価値を見いだし – データに関するストーリーを伝えること
• そのために – 必要なデータを引き出し – 統計や機械学習の知識を駆使してモデルを作り – 結果を生成 – 顧客や経営層とのコミュニケーションを行う

データエンジニアってどういう職業?
• ゴール – データを適切な場所に適切な形式で格納し – 利用者がアクセスできるように整備する
• そのために – データ処理のニーズを明確化し – ニーズを満たすストレージ基盤を設計構築し – データフローやアクセスアプリケーションを整備
• Big Data の 3V を扱えるシステムを構築する

技術の話

データサイエンティストに 求められるスキル
• 統計学、機械学習 – R, SPSS, SAS, Knime, Weka, RapidMiner, SciPy, …
• データの整形・フィルタリング・正規化・加工 – Python, Java, Hadoop, Hive, SQL, Spark, Excel, …
• 可視化、プレゼンテーション • 貼っておきます
– データサイエンティストというかデータ分析職に就くための最低限のスキル要件とは hYp://tjo.hatenablog.com/entry/2015/03/13/190000
– データサイエンティスト養成読本 hYp://www.amazon.co.jp/dp/4774158968

データエンジニアに求められるスキル
• Python, Java, Hadoop, Hive, SQL, Spark, … • OS, ネットワーク, ストレージ, クラウド, …
Image via Data Science 101
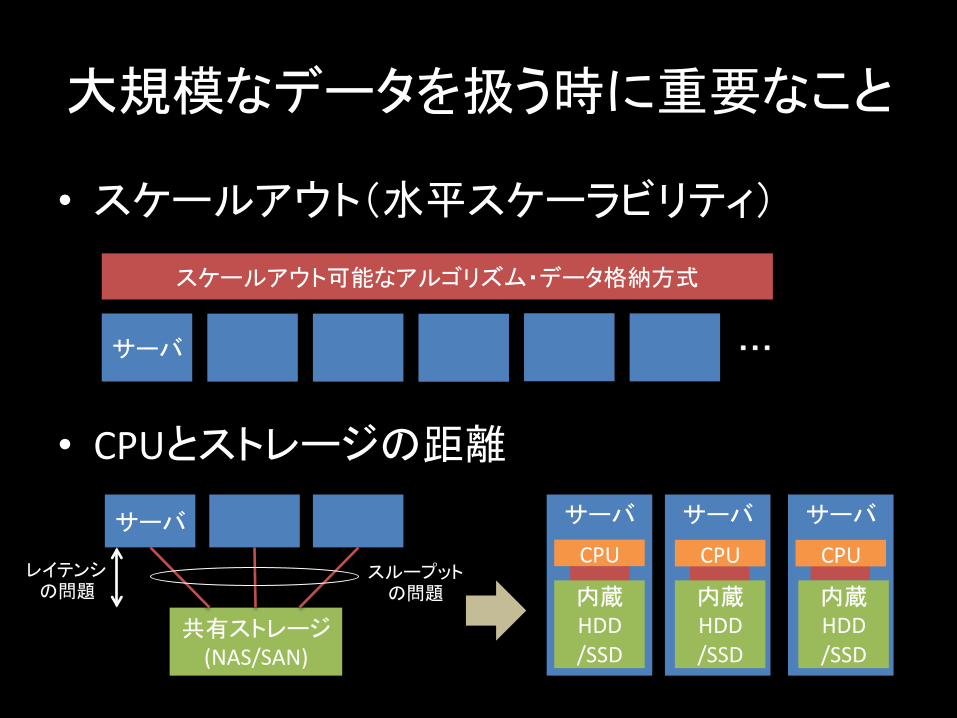
大規模なデータを扱う時に重要なこと
• スケールアウト(水平スケーラビリティ)
• CPUとストレージの距離
サーバ ・・・
スケールアウト可能なアルゴリズム・データ格納方式
共有ストレージ (NAS/SAN)
サーバ
レイテンシ の問題
スループット の問題
サーバ
サーバ
サーバ
内蔵 HDD /SSD
内蔵 HDD /SSD
内蔵 HDD /SSD
CPU CPU CPU

大規模なデータを扱う時に重要なこと
• Data Gravity(データの重力)
Web App
Data
分析 App
Data
会計 App
Data
マーケApp
Data
販売 App
Data 販売 App
Data
会計
App マーケ App

Hadoopって?
サーバ サーバ サーバ サーバ サーバ サーバ

Hadoopって?
サーバ Hadoop Distributed File System (HDFS)
データをブロックに分割して分散配置、 3つのレプリカ作成

Hadoopって?
サーバ Hadoop Distributed File System (HDFS)
分割されたデータをMap、Reduceという単位で並列分散処理
MapReduce

Hadoopって?
Hadoop Distributed File System (HDFS)
MapReduce Hadoop コア

Hadoopって?
Hadoop Distributed File System (HDFS)
MapReduce
Hive
SQLクエリ エンジン
HBase
NoSQL データベース
Pig
データ加工 フレームワーク
Mahout
機械学習
Zoo Keeper
分散レポジトリ
・・・
MapReduce/HDFS を使いやすくするための無数のプロジェクト

Sparkって?
• (主に)MapReduce の置き換え – バッチだけでなくインタラクティブな処理も – メモリを最大限利用し、より効率よく
Spark
Spark SQL
SQLクエリ エンジン
Spark Streaming
ストリーム処理
MLlib
機械学習
GraphX
グラフ処理
Spark R
R on Spark
HDFS またはその他のファイルシステム

分析と機械学習
• 従来からの分析 – 集計、レポート、見える化、ルールベース処理
• 機械学習による応用 – 予測、カテゴリ分類、レコメンド、異常検知
• データ分析のステップ
1. ビジネスとデータの理解 2. データの準備 3. モデルの作成 4. モデルの評価 5. モデルの展開

Python と Hadoop/Spark
• MapReduce を Python で – mrjob, Pydoop
• Pig – Jython, cpython でユーザー定義関数を書く
• Hadoop を管理する – snakebite
• Spark を Python で – PySpark
Hadoop with Python hYp://www.slideshare.net/DonaldMiner/hadoop-‐with-‐python

ビジネスの話

よくある悩み
• どこにデータがあるか分からない • 効果がわからないものに予算がつかない • 分析のスキルが足りない • 分析はできてもビジネスに結びつかない

ビジネスに分析を生かしている企業
hYp://itpro.nikkeibp.co.jp/atcl/column/14/122600137/122600002/ 「我々の仕事は、対話(アナログ)とデータ分析(デジタル)の比率がそれぞれ50%ずつ。これが理想」 花王・石黒勲氏
hYp://special.nikkeibp.co.jp/ts/aricle/ae0d/180043/ 「スキルが高いデータサイエンティストより問題解決ができる人材」「高度な分析技術はまず要らない」 リコー・佐藤敏明氏

分析をビジネスに活用するために 重要なこと
• 分析の8割は基本的なスキルでカバーできる • 分析には業務知識が必須 • 「データを中心に考える」文化の醸成 • ステップを踏んで少しずつ成果を出す • コミュニケーション

ありがとうございました