文献紹介:semeval-2012 task 1: english lexical simplification
TRANSCRIPT

Lucia Specia, Sujay Kumar Jauhar, Rada Mihalcea. In Proceedings of the 6th International Workshop on
Semantic Evaluation (SemEval-2012), pp.347-355, 2012.
Presented by 梶原 智之

�
2
SemEval-2012 Task 1: English Lexical Simplification
� タスク:対象語の文脈中での言い換えを平易に並べる � 評価セット:5人の英語非母語話者 語彙的換言のためのデータを平易に並び替え
� 評価尺度:kappa-indexを用いて2語間の関係を評価 � トップ:文脈依存の素性と文脈非依存の素性を組み合わせ Trial データで SVM-ranker を学習したシステム
� 文脈非依存の情報:頻度が強い(難易度との相関が強い) � 文脈依存の情報:全体にあまり有効ではなかった → 易しい単語は難しい文脈と関連が薄い可能性がある
� 今後の課題:文全体を書き換えるアプローチ

� � Hitler committed terrible atrocities during the second
World War. � Complex: atrocities � Synonyms: abomination, cruelty,
enormity, violation � WSD: abomination, cruelty, violation � Simplest: cruelty
� Hitler committed terrible cruelties during the second World War.
3
語彙平易化の流れ

� � 語彙平易化アプローチのstate-of-the-artを前進 � 共通の評価の枠組みを提供 � 語彙平易化の概念とも関連する 一般的な「曖昧性」を認識する
� 仮説:平易の概念は、文脈に強く依存する。 → 同じ対象語に同じ言い換えリストを与えても 文脈によって難易度ランキングが異なる
4
SemEval-2012 Task1の目的

� � 文脈と対象語が与えられる� その文脈中での対象語の換言リストも与えられる� 対象語と換言リストの語を “平易な” 順に並べる� 平易な表現とは、非母語話者にとって理解しやすいという(ゆるい)定義
� どうしても主観が入る作業なので、人間のアノテーションにも多くの不一致が見られる(システムにとっては更に難しいだろう)
5
Task Definition

� � SemEval-2007 English Lexical Substitution Taskのコーパスを修正
� Webから集められた英語の均衡コーパス � 201種類の対象語 × 10文脈 = 2,010文
� 対象語:名詞、動詞、形容詞、副詞 � Trial:Test = 300:1,710
� アノテーション:文脈中で対象語を言い換える � アノテータ:5人の英語母語話者
6
コーパスの作成

� � 対象語:bright(形容詞)
� 文脈:During the siege, George Robertson had appointed Shuja-ul-Mulk, who was a <head>bright</head> boy only 12 years old and the youngest surviving son of Aman-ul-Mulk, as the ruler of Chitral.
� 言い換え:intelligent × 3 clever × 3 smart × 1
7
Original Corpus

� � アノテーション:対象語とその換言を 文脈中で平易な順に並べる
� アノテータ:英語が流暢な非母語話者(大学1年生) � Trial データセット:4人(一致度:38.6%) � Test データセット:5人 (一致度:39.8%)
� 一致度は明らかに低いが、このアノテーション作業が非常に主観的な作業であることに考慮する必要がある
� なお、言語や教育の背景が同じで、英語力が非常に 近い2人のアノテータ間の一致度は、 大52%であった
� 終的には、平均ランクを用いてデータを統合する 8
Lexical Simplification Corpus

� � Annotator 1: {clear}{light}{bright}{luminous}{well-lit} � Annotator 2: {well-lit}{clear}{light}{bright}{luminous} � Annotator 3: {clear}{bright}{light}{luminous}{well-lit} � Annotator 4: {bright}{well-lit}{luminous}{clear}{light}
� 例えば、”clear”の平均ランクは (1+2+1+4) ÷ 4 = 2 � 同様に、light:3.25, bright:2.5, luminous:4, well-lit:3.25
� gold-standard: {clear}{bright}{light, well-lit}{luminous}
9
Lexical Simplification Corpus
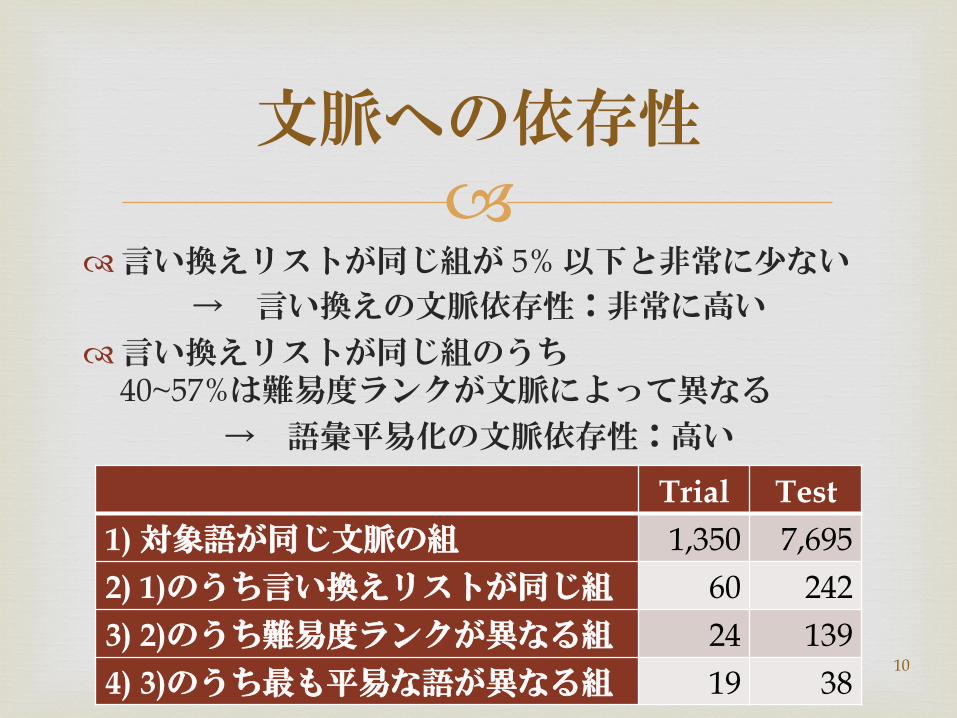
� � 言い換えリストが同じ組が 5% 以下と非常に少ない
→ 言い換えの文脈依存性:非常に高い � 言い換えリストが同じ組のうち
40~57%は難易度ランクが文脈によって異なる → 語彙平易化の文脈依存性:高い
10
文脈への依存性
Trial Test
1) 対象語が同じ文脈の組 1,350 7,6952) 1)のうち言い換えリストが同じ組 60 2423) 2)のうち難易度ランクが異なる組 24 1394) 3)のうち も平易な語が異なる組 19 38

� � N:文脈の総数 � Pn(A):システム出力と評価セットの実際の一致率 � Pn(E):システム出力と評価セットの偶然の一致率 � 一致率:単語の組(a, b)について、rank(a<b)、 rank(a=b)、rank(a>b)の3種類の一致率
11
評価尺度:kappa-index
κ =
Pn (A)−Pn (E)1−Pn (E)n=1
N
∑N

� � L-Sub Gold
� SemEval-2007の言い換えコーパスのスコア � 文脈中での言い換えの「適合度」 � 文脈を考慮したベースライン
� Random � 言い換えリストから無作為に選択
� Simple Freq. � Google Web 1T Corpusから得た単語出現頻度 � 文脈を考慮しないベースライン
12
ベースライン

� � L-Sub Gold
� 言い換えコーパスのスコアは1~5の整数値であり 複数の単語に同じスコアが振られる場合が多い
� Simple Freq. � 単純な手法にもかかわらず、とても性能が高い (このベースラインを超えたシステムは1つ)
13
ベースライン
Trial Test
L-Sub Gold 0.050 0.106Random 0.016 0.012Simple Freq. 0.397 0.471

� � ANNLOR-lmbing
� Google n-grams → Microsoft Web n-grams � Microsoft Web n-grams から得られる 前後4単語ずつを用いた言語モデル尤度
� ANNLOR-simple � Simple English Wikipedia から得られる 単語 n-grams (1~3) と、その頻度
14
システムの概要
Baseline Kappa Team-System Kappa
L-Sub Gold 0.106 ANNLOR-lmbing 0.199Random 0.012 ANNLOR-simple 0.465Simple Freq. 0.471

� � EMNLPCPH-ORD:co-trainingで二値分類器を学習
� データ � Labeled:Trialデータセット � Unlabeld:WordNetとコーパスから半教師あり学習で抽出
� 素性 � ウェブコーパスから得られる単語n-gramや文字n-gram � 平易なコーパスと普通のコーパスの単語の分布の異なり � 文脈と似た文書の構文的な難しさ � 単語の長さ � 文字3-gram言語モデルから得られる単語の認知度 15
システムの概要

� � EMNLPCPH-ORD1
� co-training-1:コーパスに基づく素性 � co-training-2:構文難易度、単語長、文字3-gramLM
� EMNLPCPH-ORD2 � co-training-1:コーパスに基づく素性、構文難易度 � co-training-2:単語長、文字3-gramLM
16
システムの概要
Baseline Kappa Team-System Kappa
L-Sub Gold 0.106 EMNLPCPH-ORD1 0.405Random 0.012 EMNLPCPH-ORD2 0.393Simple Freq. 0.471

� � UNT-SimpRank ※ Light:Google n-gramsを除く
� Google n-grams, Simple English Wikipedia, 話し言葉コーパスから得た単語出現頻度
� 単語の長さ、WordNetから得た単語の語義数
� UNT-SaLSA � Google n-grams の 3-gram 頻度の和 ※ [w1][w2][wt], [w1][wt][w3], [wt][w2][w3]
17
システムの概要
Baseline Kappa Team-System Kappa
L-Sub Gold 0.106 UNT-SimpRank 0.471Random 0.012 UNT-SimpRankLight 0.449Simple Freq. 0.471 UNT-SaLSA -0.082

� � SB-mmSystem � 単語:WordNetから得た頻度 � 複合表現:compositional semanticsの指標を用いた関連度 � 品詞付与と語義曖昧性解消によって、語義別の頻度を計算
� UOW-SHEF-SimpLex � SVM ranker を Trialデータセットで学習 � 素性:n-gram頻度モデル、bag-of-wordsモデル、 平易化指向の心理言語学的な指標
18
システムの概要
Baseline Kappa Team-System Kappa
L-Sub Gold 0.106 SB-mmSystem 0.289Random 0.012 UOW-SHEF-SimpLex 0.496Simple Freq. 0.471

�
19
Official Results and RankingRank Team-System Kappa
1 UOW-SHEF-SimpLex 0.496
2
UNT-SimpRank 0.471
Baseline-Simple Freq. 0.471
ANNLOR-simple 0.465
3 UNT-SimpRankLight 0.449
4 EMNLPCPH-ORD1 0.405
5 EMNLPCPH-ORD2 0.393
6 SB-mmSystem 0.289
7 ANNLOR-lmbing 0.199
8 Baseline-L-Sub Gold 0.106
9 Baseline-Random 0.013
10 UNT-SaLSA -0.082

� � 上位のシステムは全て頻度を指標にしている
→ 頻度と難易度には非常に強い相関がある
� トップのシステムは文脈依存の情報と 文脈非依存の情報を組み合わせている
� Trialデータが少ないので教師あり学習手法は少ない (大規模なデータでは性能の向上を確認)
20
考察

� � なぜ文脈依存の情報の効果が大きくないのか?
� 仮説:人間が作る文は、一貫した難易度である。 (一貫して易しい or 一貫して難しい)
� 本タスク:文中の一語だけを平易化する → 易しい単語は難しい文脈と関連が薄い可能性
� これは、文脈依存の情報が有効でない理由であると同時に、文脈非依存の情報が有効である理由である
21
考察
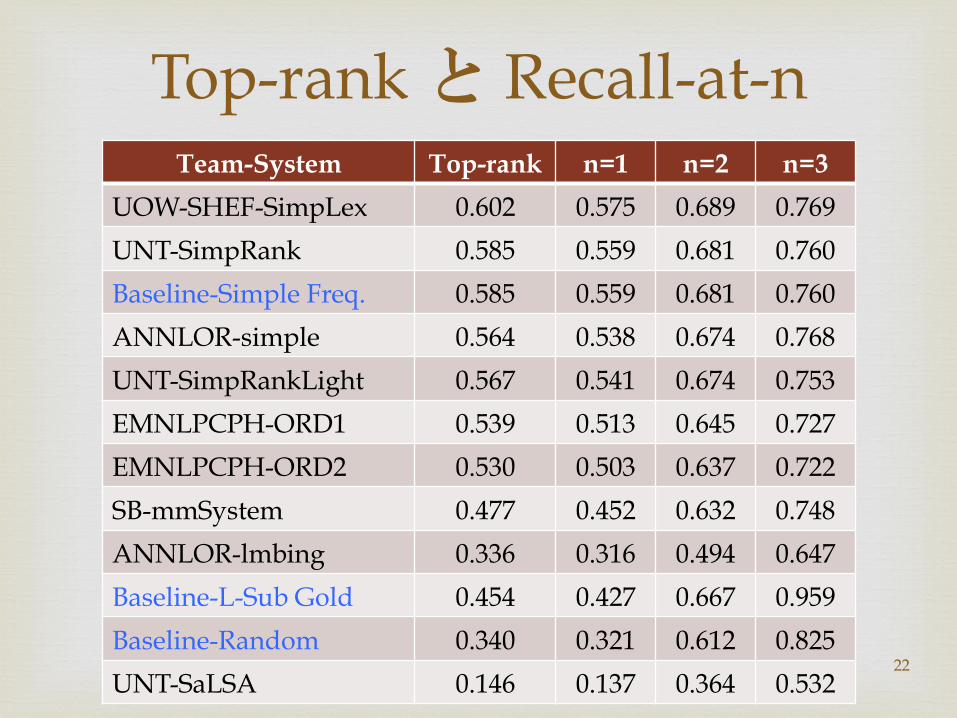
� Team-System Top-rank n=1 n=2 n=3
UOW-SHEF-SimpLex 0.602 0.575 0.689 0.769
UNT-SimpRank 0.585 0.559 0.681 0.760
Baseline-Simple Freq. 0.585 0.559 0.681 0.760
ANNLOR-simple 0.564 0.538 0.674 0.768
UNT-SimpRankLight 0.567 0.541 0.674 0.753
EMNLPCPH-ORD1 0.539 0.513 0.645 0.727
EMNLPCPH-ORD2 0.530 0.503 0.637 0.722
SB-mmSystem 0.477 0.452 0.632 0.748
ANNLOR-lmbing 0.336 0.316 0.494 0.647
Baseline-L-Sub Gold 0.454 0.427 0.667 0.959
Baseline-Random 0.340 0.321 0.612 0.825
UNT-SaLSA 0.146 0.137 0.364 0.53222
Top-rank と Recall-at-n

�
23
SemEval-2012 Task 1: English Lexical Simplification
� タスク:対象語の文脈中での言い換えを平易に並べる � 評価セット:5人の英語非母語話者 語彙的換言のためのデータを平易に並び替え
� 評価尺度:kappa-indexを用いて2語間の関係を評価 � トップ:文脈依存の素性と文脈非依存の素性を組み合わせ Trial データで SVM-ranker を学習したシステム
� 文脈非依存の情報:頻度が強い(難易度との相関が強い) � 文脈依存の情報:全体にあまり有効ではなかった → 易しい単語は難しい文脈と関連が薄い可能性がある
� 今後の課題:文全体を書き換えるアプローチ

�
24

� � 独立な2つの素性集合を設定 � 一方の素性集合のみを用いてラベル付き訓練データから 分類器1をを作成
� 分類器1を用いてラベルなし訓練データの判別を行い、 信頼性の高いものをラベル付き訓練データに加える
� 同様に、もう一方の素性集合から分類器2を作成し、 ラベル付き訓練データを増やす
� 2つの素性集合が独立なので、一方の素性から判断して 追加される事例が、もう一方の素性から見るとランダム であることが保証されているため、分類精度が向上する
� 実装は容易で、文書分類や固有表現抽出に応用されている 25
Co-training