soft computing
TRANSCRIPT

Seminarski rad: Soft Computing -racunska inteligencija
(Computational Intelligence)
Popovic ZoranCentar za multidisciplinarne studije
Univerzitet u Beogradu
4. septembar 2006
Sazetak
Ovaj tekst je zamisljen kao pregled sadrzaja knjiga i radova izoblasti racunske inteligencije. Rad je pisan pomocu TEX-a tj. LATEX-akao njegovog dijalekta i jfig alata - [PG] i [TB].
Profesor: Dragan Radojevic

Soft Computing - racunska inteligencija (Computational Intelligence) 1
Sadrzaj
1 Poglavlje 1 - Soft Computing, uvod 4
2 Fazi logika i fazi sistemi 5
2.1 Uvod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Fazi skupovi - osnovni pojmovi i definicije . . . . . . . . . . . 5
2.3 Operacije i relacije nad fazi skupovima . . . . . . . . . . . . . 7
2.4 Fazi relacija . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.1 Fazi relacije indukovane preslikavanjem . . . . . . . . . 10
2.5 Konveksnost, ogranicenost i druge osobine . . . . . . . . . . . 10
2.6 Reprezentovanje, princip prosirenja . . . . . . . . . . . . . . . 11
2.7 Lingvisticke promenljive, t-norme i s-norme . . . . . . . . . . 12
2.8 Fazi logika i fazi zakljucivanje . . . . . . . . . . . . . . . . . . 16
2.8.1 Konacna Bulova algebra . . . . . . . . . . . . . . . . . 17
2.8.2 Percepcija, Haseov dijagram strukture BA . . . . . . . 18
2.8.3 Generalizovan Bulov polinom . . . . . . . . . . . . . . 21
2.8.4 Logicka agregacija i primer mreze . . . . . . . . . . . . 24
2.8.5 Fazi logika, formalna definicija . . . . . . . . . . . . . . 25
2.8.6 Hajekov pristup, fazi teorija modela i ontologije . . . . 27
2.8.7 Zadeov pristup . . . . . . . . . . . . . . . . . . . . . . 28
2.8.8 Kompoziciono pravilo zakljucivanja . . . . . . . . . . . 29
2.8.9 Max-Min zakljucivanje . . . . . . . . . . . . . . . . . . 30
2.8.10 Max-Proizvod zakljucivanje . . . . . . . . . . . . . . . 31
2.8.11 Pravila sa vise premisa, vise pravila i procedura za-kljucivanja . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.9 Defazifikacija (Defuzzification) . . . . . . . . . . . . . . . . . . 34
2.10 Kompleksnost i izracunljivost . . . . . . . . . . . . . . . . . . 35
2.11 Fazi logika i alternativne teorije verovatnoce . . . . . . . . . . 35
2.11.1 Dempster-Sejferova teorija . . . . . . . . . . . . . . . . 36
2.11.2 Zakljucivanje s uverenjem . . . . . . . . . . . . . . . . 37
2.11.3 Mere verovanja i neverovanja i ukupno uverenje . . . . 37
2.11.4 Propagiranje uverenja . . . . . . . . . . . . . . . . . . 38
2.11.5 Mogucnost i potrebnost . . . . . . . . . . . . . . . . . 39
2.12 Racunanje s recima . . . . . . . . . . . . . . . . . . . . . . . . 40
2.13 Fazi algoritmi . . . . . . . . . . . . . . . . . . . . . . . . . . . 46

2 Seminarski rad
3 Neuronske mreze 473.1 Uvod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.2 Osnovni model neurona . . . . . . . . . . . . . . . . . . . . . . 483.3 Grupisanje neurona i struktura NM . . . . . . . . . . . . . . . 533.4 Obuka i ucenje NM . . . . . . . . . . . . . . . . . . . . . . . . 563.5 Propagiranje unazad . . . . . . . . . . . . . . . . . . . . . . . 58
3.5.1 Varijante povratnog propagiranja . . . . . . . . . . . . 623.5.2 Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . 633.5.3 (M)ADALINE . . . . . . . . . . . . . . . . . . . . . . . 64
3.6 Vrste NM i oblasti primene . . . . . . . . . . . . . . . . . . . . 663.7 NM takmicenja, klasifikacije i druge . . . . . . . . . . . . . . . 66
3.7.1 Kvantizacija vektora sa ucenjem . . . . . . . . . . . . . 673.7.2 Protiv-propagaciona NM (Counter-propagation) . . . . 683.7.3 Adaptivno-rezonantna teorija (ART) . . . . . . . . . . 683.7.4 Stohasticke (verovatnosne) NM . . . . . . . . . . . . . 70
3.8 (Neo)kognitron . . . . . . . . . . . . . . . . . . . . . . . . . . 713.9 Asocijaciranje podataka . . . . . . . . . . . . . . . . . . . . . 71
3.9.1 Asocijativne memorije, BAM . . . . . . . . . . . . . . 713.9.2 Hofildove memorije . . . . . . . . . . . . . . . . . . . . 733.9.3 Hemingova mreza . . . . . . . . . . . . . . . . . . . . . 753.9.4 Bolcmanova masina . . . . . . . . . . . . . . . . . . . . 763.9.5 Prostorno-vremensko prepoznavanje . . . . . . . . . . . 77
4 Genetski algoritmi 794.1 Uvod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.2 Kodiranje i problemi optimizacije . . . . . . . . . . . . . . . . 794.3 Kanonski GA . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.3.1 Operatori GA . . . . . . . . . . . . . . . . . . . . . . . 814.3.2 Primer kanonskog GA . . . . . . . . . . . . . . . . . . 81
4.4 Seme, teorema seme i posledice . . . . . . . . . . . . . . . . . 824.4.1 Uloga i opis prostora pretrage . . . . . . . . . . . . . . 824.4.2 Teorema seme . . . . . . . . . . . . . . . . . . . . . . . 844.4.3 Binarni alfabet i n3 argument . . . . . . . . . . . . . . 864.4.4 Kritike sema teoreme, uopstena teorema seme . . . . . 86
4.5 Ostali modeli evolucionog racunanja . . . . . . . . . . . . . . . 874.5.1 Dzenitor . . . . . . . . . . . . . . . . . . . . . . . . . . 884.5.2 CHC . . . . . . . . . . . . . . . . . . . . . . . . . . . . 884.5.3 Hibridni algoritmi . . . . . . . . . . . . . . . . . . . . . 89

Soft Computing - racunska inteligencija (Computational Intelligence) 3
4.6 Alternativni operatori odabiranja GA . . . . . . . . . . . . . . 894.7 Paralelni GA . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
4.7.1 Globalne populacije sa paralelizmom . . . . . . . . . . 904.7.2 Model ostrva . . . . . . . . . . . . . . . . . . . . . . . 904.7.3 Celijski GA . . . . . . . . . . . . . . . . . . . . . . . . 90
4.8 Primeri GA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 914.8.1 Evoluirajuce NM . . . . . . . . . . . . . . . . . . . . . 914.8.2 Klasifikacija i konceptualizacija . . . . . . . . . . . . . 924.8.3 Ucenje fazi pravila evolucijom . . . . . . . . . . . . . . 924.8.4 Evoluiranje programa . . . . . . . . . . . . . . . . . . . 93

4 Seminarski rad
1 Poglavlje 1 - Soft Computing, uvod
Pojam Soft Computing odnosno pojam racunske inteligencije (RI = Com-putational Intelligence / Computational Science, ponegde se javlja i pojambioinformatika, sto nije slucajno - mnogi modeli racananja i ideje su potekleod bioloskih modela i uzora) u koje se ubrajaju oblasti fazi (Fuzzy) logike i sis-tema, neuronskih mreza (NM) i genetskih algoritama (GA) se nekako posebnoizdvajaju iz tema i oblasti pokrivenih temama i oblastima vestacke inteligen-cije (VI). Jedan od osnovnih razloga za to potice od bliske povezanosti VI saklasicnom logikom i teorijom algoritama i izracunljivosti u matematici (kakozbog aspekta deklarativnog znanja prisutnog u VI, tako i zbog same prirodeproblema po definiciji) naspram oblasti RI gde je ta veza slabija ili bar nijeiste prirode kao kod klasicne matematike. Iz istih razloga se npr. fazi logikanemoze svesti prosto na neki oblik (primene) teorije verovatnoce i statistikeiako to moze izgledati na prvi pogled tako (karakteristicna funkcija lici nafunkciju raspodele slucajne promenljive).
Svaka od ovih oblasti se cesto kombinuje sa nekom oblasti VI (jedna odzajednickih osobina i ciljeva RI i VI su inteligentni agenti) ali postoje i mnogemeduveze i hibridi NM, GA, fazi sistema i srodnih oblasti sto ih takode ciniposebnom celinom. Poznato je, primera radi, da se neke klase problemakoji se koriste za obucavanje i optimizaciju koeficijenata NM ili nekih fazisistema najefikasnije resavaju upotrebom GA, ili da se neke klase fazi mrezazakljucivanja mogu jednostavno pretociti u NM i obratno, itd.
Ova oblast racunarstva je danas jedna od najzivahnijih u smislu novihteoretskih otkrica, ali i novih prakticnih primena. Jedna od osnovnnih za-jednickih osobina razlicitih disciplina RI jeste borba sa kompleksnoscu i ne-preciznoscu konceptualizacije sveta i percepcije sveta (pored pojma modelaracunanja) - jednostavnost konceptualizacije je suprotstavljena sa komplek-snoccu i nejasnocom realnog sveta, ali je isto tako slozenost konceptualizacijeusko grlo primenjivosti i efikasnosti u VI. Mnoge podoblasti nisu jos uvek do-voljno dobro proucene - bilo da su tek u nastajanju ili se preispituju novemogucnosti i produbljuju teoretske osnove kao sto je kod fazi sistema slucaj.Jedan od najpoznatijih Zadeovih kriticara, R. E. Kalman (inace poznat i poistrazivanjeima u oblasti linarnih dinamickih sistema, filtera i NM), navodiu jednoj prepisci kao osnovnu zamerku fazi logici i fazi sistemima nedostataknjihove primene u veoma slozenim oblastima gde se to ocekivalo vise - [birth]- zamerka stoji, ali i VI i RI kao discipline racunarstva su prolazile kroz krizeu kojima se ocekivalo vise i izlazile iz njih - novi rezultati se tek ocekuju.

Soft Computing - racunska inteligencija (Computational Intelligence) 5
2 Fazi logika i fazi sistemi
2.1 Uvod
Fazi logika (,,fuzzy” - nejasan, neodreden) na neki nacin potice jos od1930. kada je Lukasiewicz predlozio da domen poznatih operatora Bulovealgebre bude prosiren nekim vrednostima izmedu 0 i 1 (⊥ i >). Zade (LotfiA. Zadeh, 1965.) tu ideju dalje formalizuje i tako nastaje formalna teorijafazi logike. Godinama su se mnogi pojmovi i problemi naknadno resavali, alitreba pre svega imati na umu cinjenicu da fazi logika nije isto sto i klasicnaaristotelovska logika (samo u nekim specijalnim trivijalnim slucajevima sesvodi na nju - npr. u fazi logici princip iskljucenja treceg nemora da vazi,stavise ne vazi uopste ako je prava fazi logika u pitanju) i zato predstavljapogled na svet koji je drugaciji od onog uvrezenog i baziranog na klasicnojlogici tj. predikatskom racunu i ZF (Zermelo-Frankel) teoriji skupova. Kodfazi logike je osobina egzaktnosti nekako ,,labavija” u odnosu na klasicnulogiku, sto ne znaci da je fazi logika manje formalna. Pod fazi sistemima sepodrazumevaju razlicite teoretske i prakticne primene fazi teorije (skupova ilogike).
2.2 Fazi skupovi - osnovni pojmovi i definicije
Fazi logika se zasniva na skupovima i elementima cija se pripadnost meripre nego da egzaktno pripradaju ili ne pripadaju skupu.
Definicija 2.1 Neka je X domen tj. prostor elemenata ili objekata x, sto semoze oznaciti i sa X = x.Fazi skup (ili fazi klasa) A u X je karakterisan funkcijom pripadnosti tj.karakteristicnom funkcijom
µA(x) : X → [0, 1]
koja dodeljuje elementu x stepen pripadnosti skupu A.
U opstem slucaju, domen µA moze biti podskup od X, a vrednost moze bitielement nekog zadatog parcijalno uredenog skupa P umesto [0, 1]. To se mozezapisati i kao µA(x) = Degree(x ∈ A) gde je 0 ≤ µA(x) ≤ 1. NAPOMENA:(fazi) pripadnost skupu ovde ne treba shvatati kao pripadnost u klasicnomsmislu - trivijalno ,,x pripada A” akko µA(x) > 0 - netrivijalno, treba uvesti

6 Seminarski rad
dva broja α > β td. 0 < α, β < 1, i tada ,,x pripada A” akko µA(x) ≥ α,,,x ne pripada A” akko µA(x) ≤ β, ,,x je je neodredene pripadnosti premaA” akko β < µA(x) < α (ovo vodi ka trovalentnoj logici sa vrednostimanpr. >, ⊥ i ? respektivno - Kleene, 1952). Ako je A skup u klasicnom smislu(,,crisp” - ostar), tada ako je µA(x) = 1 onda je x ∈ A, odnosno ako jeµA(x) = 0 onda je x /∈ A (za skupove u klasicnom smislu, ili jednostavnoreceno za skupove, karakteristicna funkcija uzima samo dve vrednosti: 0 i1). Fazi skupovi kod kojih karakteristicna funkcija dostize 1 su normirani.Primer: cesto se koristi trougao (ili fazi broj c, neki put zgodnije shvacen kaointerval sa pesimistickom i optimistickom granicom), fazi skup A = A(c, a, b)u X = R cija karakteristicna vrednost ima vrednost 0 u svim tackama narealnoj osi osim izmedu temena (c− a, 0) i (c + a, 0) trougla koja leze na osi,a u trecem temenu (c, µA(c)) linearno dostize najvecu vrednost:
µA(c,a,b)(x) =
ba(x− c + a), c− a ≤ x < c;− b
a(x− c− a), c ≤ x ≤ c + a;
0, x /∈ [c− a, c + a].
c c+ac−a gde je 0 ≤ b = µA(c,a,b)(c) ≤ 1 najveca vrednost kojudostize karakteristicna funkcija.
Pored ovih koriste se i drugi oblici osnovnih vrsta karakteristicnih funkcija(trapezoid i druge krive) kao sto su (navedeni su normirani fazi skupovi):
s-krivina X2X1
µs(x1,x2)(x) =
0, x < x1;12
+ 12cos[ x−x2
x2−x1π], x1 ≤ x ≤ x2;
1, x > x2.
gde su x1 i x2 leva i desna prevojna tacka.
z-krivina X2X1
µs(x1,x2)(x) =
0, x < x1;12
+ 12cos[ x−x1
x2−x1π], x1 ≤ x ≤ x2;
1, x > x2.
(simetricna prethodnoj u odnosu na x osu)

Soft Computing - racunska inteligencija (Computational Intelligence) 7
π-krivina (zvono) X4X1 X2 X3
µπ(x1,x2,x3,x4)(x) = min[µs(x1,x2)(x), µz(x3,x4)(x)]
gde je vrh zvona ravan izmedu x2 i x3.
U literaturi (npr. u [LPROFS]) se npr. definise i kardinalnost fazi skupa kao:
card(A) =∑x∈X
µA(x)
ili kao kardinalnost skupova nosaca Supp(A) ili jezgra Ker(A) gde je
Supp(A) =def x| µA(x) 6= 0, Ker(A) =def x| µA(x) = 1Ako se kardinalnost posmatra kao mera skupa, alternativnim definicijama,,i” ili ,,ili” operatora (t-norme i s-norme kasnije u tekstu) se moze dobiti kar-dinalnost koja nije aditivna mera, ali se zadrzava bitna osobina monotonosti(sto se dovodi u vezu sa osobinama fazi logike naspram klasicne logike). Naosnovu ovoga se moze definisati entropija fazi skupa (Kosko, 1986):
E(A) = Card(A ∩ A)/Card(A ∪ A) ili kaoE(A) = −k
∑u∈U [µA(u) log µA(u)+µA(u) log µA(u)] gde je k neka konstanta.
2.3 Operacije i relacije nad fazi skupovima
• Jednakost -Dva fazi skupa A i B su jednaka, sto se pise A = B, akko µA(x) = µB(x)za svako x ∈ X (skraceno, µA = µB).
• Podskup -Fazi skup A je podskup fazi skupa B, sto se oznacava sa A ⊂ B, akkoµA ≤ µB.
• Komplement -komplement fazi skupa A se oznacava sa A i definise sa:µA(x) =def 1− µA(x)
• Presek -za presek C = A ∩B vazi: µA∩B(x) =def min[µA(x), µB(x)] =µA(x) ∧ µB(x) za sve x ∈ X, skraceno: µC = µA(x) ∧ µB

8 Seminarski rad
• Unija -za uniju C = A ∪B vazi: µA∪B(x) =def max[µA(x), µB(x)] =µA(x) ∨ µB(x) za sve x ∈ X, skraceno µC = µA ∨ µB
• Oduzimanje -µA−B = µA ∧ (1− µB)
Za ovako definisane operacije vaze poznate lepe osobine kao sto su to npr.De Morganovi i distributivni zakoni (ovo sledi iz samih definicija, npr. DeMorganovi zakoni slede iz 1−max[µA, µB] = min[1−µA, 1−µB] za slucajeveµA(x) > µB(x) i µA(x) < µB(x)). Ovakve relacije skupova su ,,ostre” (nisufazi, ili vaze ili ne vaze), i postoje predlozi kako se mogu i one definisati kaofazi u (Gottwald, Pedrycz):
inclt(A,B) =∧x∈X
(µA(x)φµB(x)), xφy =def
∨z| t(x, z) ≤ y
gde je funkcija t neka t-norma (obicno minimum). Tada je A ⊆ B ⇔inclt(A,B) = 1. Jednakost A = B ⇔ A ⊆ B ∧ B ⊆ A se tada mozezapisati i kao eqt(A,B) =def t(inclt(A,B), inclt(B, A)). Osim sto su ovimdefinisani komplement, presek i unija fazi skupova, ovo se kasnije koristikod lingvistickih promenljivih (dalje u tekstu) za logicke operacije negacije iveznike ,,i” i ,,ili”, respektivno.
Pored ovih operacija i relacija koriste se i algebarske operacije nad faziskupovima:
• Algebarski proizvod -
µAB = µA µB
Ocigledno vazi: AB ⊂ A ∩B.
• Algebarski zbir -µA+B = µA + µB
- pod uslovom da vazi µA(x) + µB(x) ≤ 1 za svako x ∈ X.
• Mnozenje skalarom -
µαB = α µB, α ∈ [0, 1]

Soft Computing - racunska inteligencija (Computational Intelligence) 9
• Apsolutna razlika -
µ|A−B| = |µA − µB|(za obicne skupove |A − B| se svodi na komplement A ∩ B u odnosuna A ∪B)
• Konveksna kombinacija - za fazi skupove A, B i Λ:
(A,B; Λ) = ΛA + ΛB
sto u obliku karakteristicnih funkcija izgleda ovako:
µ(A,B;Λ)(x) = µΛ(x)µA(x) + [1− µΛ(x)]µB(x), za svaki x ∈ X.
Osnovna osobina ovakve kombinacije je A ∩ B ⊂ (A,B; Λ) ⊂ A ∪ Bza svaki Λ sto je posledica nejednakosti min[µA(x), µB(x)] ≤ λµA(x) +(1 − λ)µB(x) ≤ max[µA(x), µB(x)], x ∈ X, 0 ≤ λ ≤ 1. Stavise, zasvaki fazi skup C td. A∩B ⊂ C ⊂ A∪B postoji fazi skup Λ - njegovakarakteristicna funkcija je onda:
µΛ(x) =µC(x)− µB(x)
µA(x)− µB(x), x ∈ X
• Fazifikacija Ovim operatorom se moze napraviti fazi skup od ostrog
ili fazi skupa, a karakterise ga jezgro K(x) = 1/x koje svakom x ∈ X
dodeli odgovarajuci fazi skup koji se moze zapisati skraceno kao 1/x.
Fazifikacija F (A) (fazi) skupa A se takode oznacava sa A i vazi:F (A) = F (A; K) =
∫X
µA(x)K(x) =∫
XµA(x)x.
U praksi se cesto koriste dodatne operacije nad karakteristicnom funkci-jom kojom se odreduju (odnosno modifikuju) dodatno granice tj. ogranicenjaili odredbe (hedges) pripadnosti skupu (prosiruju je ili skupljaju - u nared-nim primerima se moze pretpostaviti da je A fazi skup visokih osoba):
• Koncentracja (VEOMA) - µCON(A)(x) = (µA(x))2 npr. koncetracijadaje skup VEOMA visokih osoba
• Dilatacija (DONEKLE) - µDIL(A)(x) = (µA(x))1/2 npr. dilatacijadaje skup DONEKLE (MANJE ILI VISE) visokih osoba

10 Seminarski rad
• Intenziviranje (ZAISTA) -
µINT (A)(x) =
2(µA(x))2, ako je 0 ≤ µA(x) ≤ 1/21− 2(1− µA(x))2, ako je 1/2 < µA(x) ≤ 1
npr. dilatacija daje skup zaista visokih osoba (intenzivira pripadnostizrazeno visokih, a smanjuje pripadnost ostalih)
• Snazno (VEOMA VEOMA) - µPOW (A,n)(x) = (µA(x))n pojacanjeµPOW za n=3 ili vece ...
Operatorima i ogranicenjima se prave derivati fazi skupova.
2.4 Fazi relacija
Fazi relacija je prirodno prosirenje pojma fazi skupova kao i relacijeu klasicnoj teoriji skupova (funkcija je specijalan slucaj relacije). Takose n-arnoj fazi relaciji A u Xn pridruzuje n-arna karakteristicna funckijaµ(x1, · · · , xn) gde je xi ∈ X, i = 1, n. Kod binarnih relacija A i B se uvodikompozicija (tzv. max-min kompozicija, moze biti i max-proizvod ako sekoristi proizvod umesto min operatora) B A definisana sa:
µBA(x, y) = Supν min[µA(x, ν), µB(ν, y)]
Kompozicija ima osobinu asocijativnosti A (B C) = (A B) C).
2.4.1 Fazi relacije indukovane preslikavanjem
Neka je T preslikavanje prostora X u Y i B fazi skup u Y sa karak-teristicnom funkcijom µB(y). Inverzno preslikavanje T−1 indukuje fazi skupA u X cija je karakteristicna funkcija odredena sa µA(x) = µB(y), za svakox ∈ X: T(x)=y. Obratno, ako je A fazi skup u X, karakteristicna funkcija zafazi skup B indukovan preslikavanjem T za y ∈ Y moze imati vise vrednostiako T nije 1-1 pa se zato definise sa µB(y) = maxx∈T−1(y)[µA(x)], y ∈ Y .
2.5 Konveksnost, ogranicenost i druge osobine
Osobina konveksnosti se takode moze izgraditi i biti korisna kao i kodobicnih skupova. U narednoj definiciji se pretpostavlja da je X realan euk-lidski prostor Rn.

Soft Computing - racunska inteligencija (Computational Intelligence) 11
Definicija 2.2 Fazi skup A je (strogo) konveksan akko su skupovi Γα =x| µA(x) ≥ α (strogo) konveksni za svako α ∈ (0, 1].
Alternativna i neposrednija definicja je:
Definicija 2.3 Fazi skup A je konveksan akko
µA[λx1 + (1− λ)x2] ≥ min[µA(x1), µA(x2)]
za svako x1 i x2 u X i svako λ ∈ [0, 1] (ako se ≥ zameni sa > dobija se jakakonveksnost).
Iz prve definicije sledi druga (ako α = µA(x1) ≤ µA(x2), onda x2 ∈ Γα iλx1 + (1 − λ)x2 ∈ Γα i odatle sledi i µA(x1) = min[µA(x1), µA(x2)]) kao iobratno (ako α = µA(x1) onda je Γα skup svih x2 td. µA(x2)geqµA(x1) isvaka tacka λx1 + (1 − λ)x2, 0 ≤ λ ≤ 1 je u Γα pa je to onda konveksanskup). Moze se dokazati teorema:
Teorema 1 Ako su A i B konveksni, onda je to i njihov presek.
Definicija 2.4 Fazi skup je ogranicen akko su skupovi Γα = x| µA(x) ≥ αograniceni za svako α > 0 (za svako α > 0 postoji konacna vrednost R(α)takva da je ||x|| ≤ R(α) za svako x ∈ Γα).
Posto je X euklidski mogu se definisati ε-okoline i supremum M = supx[µA(x)](M je ,,maksimalna ocena u A”) je esencijalno dostignut u nekoj tacki akosvaka ε-okolina te tacke sadrzi tacke iz Q(ε) = x| µA(x) ≥ M− ε. Core(A)je skup svih takvih tacaka i moze se pokazati da je takode konveksan ako jeA konveksan. Mogu se dalje izgradivati i druge vazne osobine fazi skupovakao sto je Zade pokazao (npr. separabilnost fazi skupova).
2.6 Reprezentovanje, princip prosirenja
Do sada smo razmatrali neprekidne karakteristicne funkcije zadate anal-iticki. Fazi skup s diskretnim vrednostima se moze jednostavno prikazati kaovektor karakteristicnih vrednosti A = (µ1, ..., µn) ako se domen posmatrakao konacan (ili prebrojiv) vektror vrednosti. Tacnije, fazi skup se posmatrakao ostar skup ili jos bolje, niz uredenih parova A = ((µ1, x1), ..., (µn, xn))gde je µi = µA(xi). Uz konvenciju zapisa uredenih parova sa ,,/” i unijekao ,,+” to se moze zapisati i kao A =
∑ni=1 µA(xi)/xi ako je X diskretan,

12 Seminarski rad
odnosno A =∫
XµA(x)/x ako nije. Skraceni zapis koji se najcesce koristi
je samo µA(x) uz podrazumevane vrednosti domena X. Fazi skup se mozeposmatrati kao unija fazi singltona gde je fazi singlton fazi skup sa samojednom vrednoscu A = (µA(x), x) (njegov nosac Supp(A) je kardinalnosti1) za neko x ∈ X, tj. skraceno A = µ/x gde je µ = µA(x), x ∈ X. Npr.ostar skup se onda zapisuje kao X = 1/x1 + · · ·+ 1/xn ili X = x1 + · · ·+ xn.
Relacija se onda prikazuje npr. kao:
R =∫
XµR(x1, · · · , xn)/(x1, · · · , xn) ili
R = µ1R/(x1
1, · · · , x1n) + · · ·+ µm
R/(xm1 , · · · , xm
n ).
Sami stepeni pripadnosti mogu biti fazi skupovi, na primer ako je domenU = Pera, Mika, Slavko i ako su fazi skupovi malo, srednje, puno defin-isani nad domenom V = 0.0 + 0.1 + · · · + 1.0 onda bi npr. fazi podskup Ateskih mogao da bude:
A = malo/Mika + srednje/Pera + puno/Slavko
Zade definise princip prosirenja za preslikavanja na sledeci nacin: ako jef : U → V preslikavnje, fazi skup A = µ1/u1 + · · ·µn/un nad U tj. A =∫
UµA(u)/u onda vazi f(A) = µ1/f(u1)+· · ·+µn/f(un) =
∫U
µA(u)/f(u). Zaslucaj funkcije vise promenljivih takode vazi F (A) =
∫U×V
µA(u) ∧ µG(v)/f(u, v).Principom prosirenja uopste se svaka dobra osobina klasicne teorije skupova(i nekih njenih posledica) prenosi na fazi teoriju skupova (ili odgovarajucufazi teoriju) kada je to moguce (fazifikacijom). Ovo je napravilo dosta nevolja,kao sto ce u daljem tekstu biti objasnjeno - fazi logika i teorija skupova jeuopstenje klasicne logike i teorije skupova, a ne obratno.
2.7 Lingvisticke promenljive, t-norme i s-norme
Oznake vrednosti lingvisticke promenljive su recenice nekog (prirodnogili vestackog) jezika L koje mogu imati donekle nejasno znacenje kao npr.starost sa vrednostima mlad, srednje, star - onda je svakoj od vrednosti do-deljen fazi podskup vrednosti iz domena skupa starosti (broj godina). Stepenpripadnosti V al(x is A) = µA(x) elementa fazi skupa A je stepen istinitostiizraza x is A gde fazi skup A postaje osobina. Lingvisticka promenljiva mozeuzeti vrednost iz svog skupa termova T (term set) koji predstavlja (ostar,

Soft Computing - racunska inteligencija (Computational Intelligence) 13
jednostavnosti radi) skup oznaka kojima se dodeljuju fazi skupovi nad istimdomenom (ponegde se u literaturi kaze za domen da je bazna promenljiva)fazi relacijom µN(t, x), t ∈ T, x ∈ X td. oznaci t ∈ T odgovara skup M(t)sa karaktersicnom funkcijom µM(x) = µN(t, x) i cesto se krace pise samo tumesto M(t). Primer:
µN(mlad, x) =
1, x ≤ 25;(1 + (x−25
5)2)−1, x > 25.
onda je fazi podskup mlad skupa godina X = 0, · · · , 100:
mlad =
∫ 25
0
1/x +
∫ 100
25
(1 + (
x− 25
5)2
)−1
/x
Term moze biti atomski ili slozen, gde kod slozenih ucestvuju:
1. logicka negacija i veznici (i i ili)
2. odredbe
3. zagrade i sl. simboli
Pomenuta relacija µN se moze definisati rekurzivno za slozene terme na os-novu vrednosti za atomske terme i prema definicijama logickih operatora iodredbi. Primer: ako je u atomski term a h odredba onda se moze posm-trati h kao operator koji slika fazi skup M(u) u M(hu) - npr. x = veomane mlad = (¬mlad)2 tj. V al(x) = (1 − V al(mlad))2 kao karakteristicnafunkcija. Formalnije, svaki operator i veznik nad fazi skupovima M(x) vrsineku promenu koja se moze analiticki zapisati, npr. M(x∧y) = M(x)∩M(y)tj. V al(x ∧ y) = x ∧ y.
Vrednost terma sa veznicima se moze definisati uopsteno t-normamaza ,,i” veznik i s-normama (t-konormama) za ,,ili” veznik (pored ranijepomenute definicije preseka i unije fazi skupova za ,,i” i ,,ili”, respektivno).
Preslikavanje t : [0, 1]2 → [0, 1] je t-norma ako ispunjava sledece uslove(tj. aksiome generalizovane konjunkcije, fazi-logickog I-veznika):
1. t(x, 1) = x (granica)
2. t(x, y) = t(y, x) (komutativnost)

14 Seminarski rad
3. y1 ≤ y2 ⇒ t(x, y1) ≤ t(x, y2) (monotonost)
4. t(x, t(y, z)) = t(t(x, y), z) (asocijativnost)
Klasicne t-norme su:
• tmin(x, y) = min(x, y) (Gedelova t-norma ∧G, odnosno Zadeova t-normaili standardni presek)
• tL(x, y) = max(0, x + y − 1) (t-norma Lukasiewicz-a ∧L)
• tproizvod(x, y) = xy (proizvod t-norma ∧P )
• t∗(x, y) =
x, y = 1;y, x = 1;0, inace.
(drasticni presek)
Vazi t∗ ≤ tL ≤ tproizvod ≤ tmin i za proizvoljnu t-normu t moze se pokazatida vazi t∗ ≤ t ≤ tmin. Karaktersticna funkcija preseka je onda µA∩B(x) =t(µA(x), µB(x)).
Preslikavanje c : [0, 1]2 → [0, 1] je s-norma (t-konorma) ako ispunjavasledece uslove (aksiome, simetricno prethodnom):
1. c(x, 0) = x (granica)
2. c(x, y) = c(y, x) (komutativnost)
3. y1 ≤ y2 ⇒ t(x, y1) ≤ t(x, y2) (monotonost)
4. t(x, t(y, z)) = t(t(x, y), z) (asocijativnost)
Klasicne s-norme su:
• cmax(x, y) = max(x, y) (standardna unija, odnosno Gedelova s-norma∨G)
• cL(x, y) = min(1, x + y) (∨L)
• csuma(x, y) = x + y − xy (∨P tj. algebarska suma)

Soft Computing - racunska inteligencija (Computational Intelligence) 15
• c∗(x, y) =
x, y = 0;y, x = 0;1, inace.
(drasticna unija)
Vazi takode cmax ≤ cproizvod ≤ cL ≤ c∗ i za proizvoljnu t-konormu c mozese pokazati da vazi cmax ≤ c ≤ c∗. Karaktersticna funkcija unije je ondaµA∪B(x) = c(µA(x), µB(x)).
Moze vaziti veza izmedu dualnih t-normi i t-konormi (i obratno, na os-novu De Morganovih zakona - u opstem slucaju ove veze ne moraju vaziti):c(x, y) = 1− t(1− x, 1− y). Tada se mogu definisati parovi dualnih konormi- npr. (tmin, cmax), (tL, cL), (tproizvod, csuma), (t∗, c∗). Ove funkcije se moguuopstiti i na vise promenljivih:
tmin(x1, · · · , xn) = min(x1, · · · , xn), cmax(x1, · · · , xn) = max(x1, · · · , xn)
tL(x1, · · · , xn) = max(0,n∑
i=1
xi − n + 1), cL(x1, · · · , xn) = min(0,n∑
i=1
xi)
tproizvod(x1, · · · , xn) = x1 · · · xn, csuma(x1, · · · , xn) =n∑
i=1
(−1)i+1∑
τ=komb(i)
i∏j=1
xτ(j)
Kao sto se ovim aksiomama definisu t-norme i s-norme kao neka vrstauopstenja konjunkcije i disjukcije (i odgovarajucih stepena istinitosti rekurzivnimdefinicijama V al nad fazi iskazima), tako se moze definisati i uopstena ne-gacija n : [0, 1] → [0, 1] aksiomama:
• n(0) = 1, n(1) = 0 (granicni uslovi)
• x ≤ y ⇒ n(y) ≤ n(x)
• n(n(x)) = x
gde opet imamo primere negacije: nG(x) = 0 za x > 0, inace nG(0) = 1,nL(x) = 1 − x. Takode, definise se i operator i (moze se shvatiti opet kaonekakvo uopstenje operatora implikacije) i : [0, 1]2 → [0, 1] tako da vazeaksiome:
• x ≤ y ⇒ i(x, z) ≥ i(y, z)
• y ≤ z ⇒ i(x, y) ≤ i(x, z)

16 Seminarski rad
• i(0, y) = 1, i(x, 1) = 1
• i(1, 0) = 0
Slicno kao i ranije, mogu vaziti veze (po uzoru na klasicnu logiku): i(x, y) =c(n(x), y) - primer je iKD(x, y) = max (1− x, y) (Kleene-Dienes). Druginacin da se ovo definise je reziduum operator (opet po uzoru na klasicnulogiku): i(x, y) = sup z ∈ [0, 1]| t(x, z) ≤ y. Tada vazi (u zavisnosti odt-norme):
i(x, y) =
1, x ≤ y;1− x + y = iL(x, y), ∧L;y = iG(x, y), ∧G;xy
= iP (x, y), ∧P .
Takode, veza i(x, y) = n(t(x, n(y))) vazi za Zadeovu logiku (iKD, tG, nL) ilogiku Lukasiewicz-a (iL, tL, nL), ali ne vazi za Gedelovu (iG, tG, nG), nitilogiku proizvoda (iP , tP , nG). Mera relacija podskupa (subsumption) A ⊂ Bse onda moze definisati kao: infx∈X i(A(x), B(x)), a kompozicija binarnihrelacija nad ostrim skupovimam kao:
(R1 R2)(x, z) = supy∈Y
t(R1(x, y), R2(y, z))
Relacija R je tranzitivna akko je (R R)(x, z) ≤ R(x, z).
Skup termova T moze biti generisan nekom kontekstno slobodnom gra-matikom G = (VX , VT , P, S) tj. T = L(G), gde je onda skup terminala VT
skup atomskih termova (semantika se gradi prema prethodnom). Ovakvoracunanje vrednosti odnosno znacenja lingvisticke promenljive vodi ka zna-cenju uslovnih recenica i fazi zakljucivanju - odnosno, definisanju fazi logikereci.
2.8 Fazi logika i fazi zakljucivanje
Aristotelov princip iskljucenja treceg (objekat nemoze istovremeno imatii nemati osobinu, ili sustina paradoksa iskaza koji negira svoju tacnost) kaoosnovno nacelo klasicne logike je narusen u slucaju visevrednosne logike gdesu onda osnove logike promenjene (sto je jos Jan Lukasiewicz primetio do-davanjem trece vrednosti ,,1
2” - problem ,,polupune ili poluprazne”case). U
opstem slucaju, konvencionalne fazi logike se ne nalaze u Bulovom okviru

Soft Computing - racunska inteligencija (Computational Intelligence) 17
(kao ni visevrednosne). Takode, princip prosirenja (ekstenzionalnosti) nijeosnovni pojam Bulove algebre ma koliko bio koristan (suvisna aksioma u al-gebarskom smislu, kako ce dalje biti pojasnjeno - ,,To je vrlo uobicajena itehnicki korisna pretpostavka”(P. Hayek, Metamathematics of Fuzzy Logic)- ali isto tako je bilo sasvim uobicajeno i tehnicki korisno smatrati u sred-njem veku da je zemlja jedna ravna ploca). Ideja kojom bi se ovo sve mogloprevazici je uopstavanje klasicne Bulove algebre (Calculus of Logic GeorgeBoole, 1848), i to formalnom algebarskom definicijom Bulove logike i fazilogike, ili npr. interpolativnom realizacijom Bulove algebre (IBA, realnalogika).
Fazi logika (njen primer) je struktura ([0, 1], t, s, n), gde je t t-norma (gen-eralizovana konjunkcija), s s-norma (generalizovana disjunkcija), i n gener-alizovana negacija, uz ranije pomenute aksiome (negacija ce biti objasnjenau jednom od narednih odeljaka).
2.8.1 Konacna Bulova algebra
Konacna Bulova algebra (BA) je struktura (BA(Ω),∩,∪, C), BA(Ω) =P (P (Ω)), Ω = a1, ..., an, kod koje vaze zakoni:
• asocijativnosti: (x ∪ y) ∪ z = x ∪ (y ∪ z), (x ∩ y) ∩ z = x ∩ (y ∩ z)
• komutativnosti: x ∪ y = y ∪ x, x ∩ y = y ∩ x
• apsorpcije: x ∩ (x ∪ y) = x, x ∪ (x ∩ y) = x
• distributivnosti: x∩(y∪z) = (x∩y)∪(x∩z), x∪(y∩z) = (x∪y)∩(x∪z)
• komplementarnosti: x∪Cx = 1, x∩Cx = 0 (principi iskljucenja trecegi konzistentnosti)
Poznate teoreme su onda: idempotencija (a∪a = a, a∩a = a), ogranicenost(a ∩ 0 = 0, a ∩ 1 = a, a ∪ 0 = a, a ∪ 1 = 1), involucije (a = CCa), DeMorganovi zatkoni (C(a ∪ b) = Ca ∩ Cb, C(a ∩ b) = Ca ∪ Cb). Receniceiskaznog racuna cine takode BA, i u klasicnoj dvovrednosnoj (binarnoj) logicivazi princip iskljucenja treceg.

18 Seminarski rad
2.8.2 Percepcija, Haseov dijagram strukture BA
Fazi logiku Zade cesto pominje kao osnovu racuna percepcijama gde sepod percepcijom podrazumeva neka (normalizovana) brojna vrednost naosnovu koje se moze zakljuciti neka osobina posmatranog objekta (opetizrazena normalizovanom brojnom vrednoccu), ili doneti neka odluka (per-cepcija kao dozivljaj alternative donosioca odluke). Te brojne vrednosti ne-maju posebno veze sa nekakvim verovatnosnim vrednostima (uopstenje BA irazlaz sa klasicnom logikom se prenosi i na teoriju verovatnoce u fazi slucaju).Percepcija zavisi od coveka do coveka (ili sistema), kao i od problema do prob-lema. Suma otezanih vrednosti atributa (npr. J(a, b) = waa+wbb, wa+wb =1) nije dovoljno izrazajna kao kriterijumska funkcija - primer (slike 2.8.3a i2.8.3b ispod) je prostor boja koji se na ovaj nacin ne moze pokriti (ako su dveatomske boje tacke u njihovoj ravni, ovakva suma je samo 1-dimenzionalnaduz izmedu njih):
(slika 2.8.3a)
(slika 2.8.3b)
Da bi se takvom interpolacijom dobio ceo prostor boja, neophodno je imati8 atomskih boja (za 3 osnovne RGB boje):

Soft Computing - racunska inteligencija (Computational Intelligence) 19
(slika 2.8.3c)
(slika 2.8.3d)
Ovo je ilustracija razlike izmedu BA (u smislu interpolacije) i fazi logike kaouopstenja. Ideja interpolativne realizacije BA ilustruje se (slicno prethod-nom) Haseovim dijagramom (graf parcijalno uredenog skupa gde se ori-jentacija podrazumeva, npr. uredenje u pravcu dole-gore):
(Haseov dijagram strukture BA)
Ovim dijagramom se slikovito prikazuje struktura elemenata BA u slucajuΩ = a, b, gde se za svaki ugao kvadrata (a = 0, b = 0 je donji levi) i cvoradijagrama crnim kvadraticem npr. indikuje da li moze imati vrednost 1:

20 Seminarski rad
(tumacenje vrednosti elemenata BA)
Za svaki takav element BA (Bulovu fukciju) se onda lako moze napravitiistinitosna tablica:

Soft Computing - racunska inteligencija (Computational Intelligence) 21
2.8.3 Generalizovan Bulov polinom
Svaki element konacne Bulove algebre moze se jednoznacno prikazati gen-eralizovnim Bulovim polinomom (GBP) koji moze da uzima vrednosti sarealnog intervala [0, 1]. Za ovo ce biti potreban pojam strukturne funkcijeσϕ : P (Ω) → 0, 1 datog kvalitativnog atributa ϕ ∈ BA(Ω), koja odredujekoji su atomski atributi (elementi BA koji sadrze samo ∅) ukljuceni (sadrzani)u ϕ. Za primarne atribute ai vazi:
σai(S) =
1, ai ∈ S;0, ai 6∈ S.
, ai ∈ Ω, S ∈ P (Ω).
U ostalim slucajevima gradi se izraz (u nekakvoj normalnoj formi, svodi sena Zegalkinove polinome jer strukturne funkcije imaju samo dve vrednosti -onda se gubi potreba za koeficijentima i eksponentima) prema pravilima:
σa∧b(S) = σa(S) ∧ σb(S)
σa∨b(S) = σa(S) ∨ σb(S)
σCa(S) = 1− σa(S)
Generalizovan proizvod ⊗ se moze definisati na vise nacina - primeri (ϕ, ψ ∈BA(Ω)):
• ϕ⊗ ψ = min (ϕ, ψ) (Gedelova t-norma)
• ϕ⊗ ψ = ϕ · ψ (logika proizvoda)
• ϕ⊗ ψ = max (0, ϕ + ψ − 1) (t-norma Lukasiewicz-a)
Iako je generalizovani proizvod veoma slican t-normi (koji u fazi pristupuigra nekakvu ulogu logickog veznika, sto se u opstem slucaju ne poklapa saklasicnom konjunkcijom), igra sasvim drugu ulogu u IBA, i treba ga posma-trati kao aritmeticki operator (polinoma).
Definicija 2.5 Svakom ϕ =⋃
S∈P (Ω) σϕ(S)α(S) ∈ BA(Ω) dodeljuje se GBP
ϕ⊗(x):
ϕ 7→ ϕ⊗(x) = −→σϕ−→α ⊗(x) =
∑
S∈P (Ω)
σϕ(S)α⊗(S)(x), x ∈ Xm

22 Seminarski rad
gde je α⊗(S) GBP za atomske elemente α(S) =⋂
ai∈S ai
⋂aj∈Ω−S Caj,
S ∈ P (Ω) (vrednosno relevantan deo):
α⊗(S)(x) = α⊗(S)(a1, ..., an) =∑
C∈Ω−S
(−1)|C|⊗
ai∈C∪S
ai(x)
dok je −→σϕ vrednosno irelevantan (strukturni) deo.
Generalizovan proizvod ispunjava (po definicij) u potpunosti iste aksiome kaoi t-norma, i jos jednu aksiomu dodatno - aksiomu nenegativnosti :
α⊗(S)(x) ≥ 0, ∀S ∈ P (Ω)
Strukturni deo (strukturni vektor −→σ ϕ = [σϕ(S)|S ∈ P (Ω)]) u potpunostiispunjava sve aksiome BA (dakle, vaze i iste teoreme za njega). Primer, zaΩ = a, b:
S = a, b : a ∩ b 7→ α⊗(S)(a, b) = a⊗ b
S = a : a ∩ Cb 7→ α⊗(S)(a, b) = a− a⊗ b
S = b : Ca ∩ b 7→ α⊗(S)(a, b) = b− a⊗ b
S = ∅ : Ca ∩ Cb 7→ α⊗(S)(a, b) = 1− a− b + a⊗ b
Primeri, dalje - ako je φ, ψ ∈ BA(Ω), onda je:
(ϕ)⊗(x) = −→σ ϕ−→α ⊗(x), x ∈ Xm
(ϕ ∩ ψ)⊗(x) = −→σ (ϕ∩ψ)−→α ⊗(x)

Soft Computing - racunska inteligencija (Computational Intelligence) 23
(ϕ ∪ ψ)⊗(x) = −→σ (ϕ∪ψ)−→α ⊗(x)
(Cϕ)⊗(x) = −→σ (Cϕ)−→α ⊗(x) = 1− (ϕ)⊗(x)
Ideja interpolacije GBP se moze ilustrovati odgovarajucim Haseovim dija-gramima (zbir vrednosti atomskih elemenata u drugom sloju od dole je 1,∑
S∈P (Ω) α⊗(S)(x) = 1), gde se razlicitim nijansama predstavljaju vrednosti
u intervalu [0, 1] (umesto klasicnog 0, 1) koje su dodeljene (vrednosti nemoraju biti cak ni simetricne u odnosu na atomske elemente, ili atribute), avrednost svakog elementa je suma vrednosti njegovih atoma:
(vrednosti elemenata u interpolativnom slucaju)
(svaki element ima vrednost u [0, 1], atomski elementi nisu unija drugih atomskih elemenata)

24 Seminarski rad
2.8.4 Logicka agregacija i primer mreze
Strogo formalno, fazi logika je uopstenje BA. Prethodno opisanim uopste-njem vaze sve aksiome i dobre osobine BA iako vrednosti GBP nisu binarne,i upravo vrednosno relevantan deo vodi ka generalizaciji BA koja ,,dozvoljavafazi slucajeve”. Ako se definise norma atributa || · || : Ω → [0, 1] i generalizo-vani pseudo-Bulov polinom (GpBP) kao linearna konveksna suma elemenataIBA:
πϕ⊗(||a1||, ..., ||an||) =m∑
i=1
wiϕ⊗i (||a1||, ..., ||an||),
m∑i=1
wi = 1, wi ≥ 0, i = 1,m
iz definicije GBP sledi (ϕi ∈ BA(Ω)):
πϕ⊗(||a1||, ..., ||an||) =m∑
i=1
∑
S∈P (Ω)
χσ(ϕi)(S)α⊗(S) =∑
S∈P (Ω)
µ(S)α⊗(S)
gde je α⊗(S) =∑
C∈P (Ω)−S (−1)|C|⊗
aj∈S∪C ||aj||, a µ je strukturna funkcija
GpBP πϕ⊗ i predstavlja karakteristicnu funkciju fazi skupa µ : P (Ω) → [0, 1]definisanu sa (slicno karakteristicnoj funkciji u ZF teoriji skupova, ali nijeisto):
µ(S) =m∑
i=1
wiχσ(ϕi)(S)
Funkcije χσ(ϕi) predstavljaju logicku strukturu odgovarajucih elemenata izBA (mogu biti aditivne, monotone ili uopstene - u fazi slucaju). Njima segrade logicke agregacije Agg : [0, 1]n → [0, 1] kao pseudo-logicke funkcije ko-jima se opisuju u uopstenom slucaju vrednosti (fazi) logickih izraza, karak-terisane merom agregacije µ(S) (strukturnom funkcijom) i ⊗ operatorom.Primera radi, ako je mera agregacije:
µOR(S) =
1, S 6= ∅;0, S = ∅.
i ⊗ = min, onda je operator logicke agregacije:
AggminµOR
(||a1||, ..., ||an||) = max (||a1||, ..., ||an||)O svemu ovome detalji se mogu naci u [RD], [AQM] i [RD2]. Tako se mogugraditi Bulove mreze (Bulove funkcije koje se racunaju u iteracijama slicno

Soft Computing - racunska inteligencija (Computational Intelligence) 25
Bajesovim mrezama) koje koriste [0, 1] kao ulazne vrednosti, ali i fazi mreze.
Primer: ako su a, b, c normalizovane brojne ocene nekih objekata gde sedaje prednost b ako je a veliko, odnosno c u suprotnom, i ako je veci arit-meticki prosek vazan kriterijum onda bi primer logicke agregacije bio:
Agg⊗(a, b, c) =1
2
a + b + c
3+
1
2ϕ⊗(a, b, c)
gde je ϕ⊗(a, b, c) = ((a∩ c)∪ (Ca∩ b))⊗ = b+a⊗ c−a⊗ b, a mera agregacijeje µ = 1
6(σa +σb +σc)+
12(σa∧σc)∨(Cσa∧σb) (nad S ∈ P (Ω)). Za konkretnu
realizaciju ⊗ ≡ · agregacije dobija se brojna vrednost koja ispravno odslikavasve zadate kriterijume.
2.8.5 Fazi logika, formalna definicija
Postoji finija hijerarhija formalnih logika, primer iz [AV] (u algebarskomsmislu):
U osnovi ove ideje lezi definicija pojma latice:
Definicija 2.6 Latica L = (X,≤,∧,∨) predstavlja parcijalno ureden skup(X,≤) sa RAT aksiomama, kod koga postoji najveca donja granica x ∧ y =infx, y (meet) i najmanja gornja granica x∨y = supx, y ( join) za svakox, y ∈ X.

26 Seminarski rad
(primer Bulove latice podskupova (|Ω = 1|) i jedne slobodne Bulove algebre (|Ω| = 2))
Pored partitivnog skupa proizvoljnog nepraznog skupa, postoje i mnogi drugiprimeri latica, medu kojima je i slobodna Bulova algebra generisana atom-skim recenicama iskaznog racuna, koja je izomorfna sa klasicnom binarnomBulovom algebrom (taj izomorfizam na BA(0, 1) je zapravo istinitosnavrednost, i uopste, moze se pokazati da je svaka konacna BA izomorfna saBA nekog partitivnog skupa, a detaljnije osobine izomorfizama daje Stounovateorema reprezentacije Bulovih algebri).
Definicija 2.7 Ako je L univerzalno ogranicena latica tj. 0 ≤ x ≤ 1 zasvako x ∈ X, i ako postoji preslikavanje ¬ : L → L takvo da je:
• x ≤ ¬(¬x) (slaba negacija)
• ¬y ≤ ¬x ako x ≤ y (antitonost, pokazuje se da je povezana sa DeMorganovim zakonima)
• ¬0 = 1, ¬1 = 0 (Bulovi granicni uslovi)
onda je takav par (L,¬) fazi logika (primer modela je ([0, 1], iKD, tG, sG, nL)).Ako dodatno vazi zakon nekontradiktornosti x ∧ ¬x = 0 za svako x ∈ L,onda ta struktura predstavlja logiku (ovako definisana slaba negacija se zovei pseudo komplement, a ako vazi involucija onda je to jaka negacija).
Bulova algebra se onda definise kao komplementarna distributivna latica (ne-gacija postaje jaka, za razliku od intuicionisticke logike). Znacaj GpBP uodnosu na ovu formalnu algebarsku definiciju fazi logike je jasnija primena,i s druge strane, bolja formalna utemeljenost u odnosu na zadeovsku fazilogiku (koja je vec dozivela mnoge prakticne primene, ali i kritike).

Soft Computing - racunska inteligencija (Computational Intelligence) 27
2.8.6 Hajekov pristup, fazi teorija modela i ontologije
Poseban uopsteni slucaj predstavljaju reziduirane latice kao strukturekoja predstavlja laticu + monoid + aksiome rezidualnosti ((∀x, y, z ∈ L)y ≤x\z ⇔ x · y ≤ z ⇔ x ≤ z/y, najveci y se zapisuje kao y ≤ x\z tj. desnirezidual, najveci x kao x ≤ z/y tj. levi rezidual), BL algebre BL(L,→,⊗,⊥)(⊗ je snazna konjunkcija) sa Hajekovim skupom aksioma (modus ponens kaopravilo zakljucivanja) i neprekidnom t-normom kao njihovo uopstenje. U BLjezik se dodatnim definicijama uvode dodatni logicki veznici:
• slaba konjunkcija: A ∧B ≡ A⊗ (A → B)
• negacija: ¬A ≡ A → ⊥ (slicno intuicionistickom pristupu)
• ekvivalencija: A ↔ B ≡ (A → B) ∧ (B → A) (sto se moze pokazatiekvivalentnim sa (A → B)⊗ (B → A))
• slaba disjunkcija: A ∨B ≡ ((A → B) → B) ∧ ((B → A) → A)
• > ≡ ⊥ → ⊥Hajekove aksiome (u maniru iskaznog racuna i Hilbertovog formalnog sis-tema) jesu:
(BL1 )(A → B) → ((B → C) → (A → C))(BL2) A⊗B → A(BL3) A⊗B → B ⊗ A (za koju se pokazalo da je suvisna)(BL4) A⊗ (A → B) → B ⊗ (B → A)(BL5a) (A → (B → C)) → (A⊗B → C)(BL5b) (A⊗B → C) → (A → (B → C))(BL6) (A → (B → C)) → (((B → A) → C) → C)(BL7) ⊥ → A
Aksiome BL logike prvog reda BL1 su:
(∀1) (∀x)A(x) → A(y)(∃1) A(y) → (∃x)A(x)(∀2) (∀x)(A → B) → (A → (∀x)B)(∃2) (∀x)(A → C) → ((∃x)A → C)(∃2) (∀x)(A ∨ C) → ((∀x)A ∨ C)

28 Seminarski rad
(y je smena za x u A, x nije slobodna u C)
Kod BL1 je moguce konstruisati tako i teoriju modela ((∀x)A(x) ≡ infx ||A(x)||,(existsx)A(x) ≡ supx ||A(x)||, gde je ||A|| ≡ V al(A) stepen istinitosti zadati model M i t-normu). Tako razlicite t-norme definisu semantiku (atime i s-norme, i uopstene implikacije i negacije, tj. funkcije t, c, n i i,kako su vec ranije definisane) razlicitih fazi logika: Lukasiewicz-evu, Gede-lovu, proizvod (produkt) logiku, ili neku drugu - i svakoj modeli odgovarajuodredenoj algebri (BL u uopstenom slucaju, MV-algebri, G-algebri, pro-dukt algebri) i sistemu aksioma (BL, i dodatno ¬¬A → A, A → A ∧ A,¬¬A → ((A → (A ∧B)) → (B ∧ ¬¬B)), redom).
Za razliku od pristupa Hajekove fazi logike, fazi deskriptivne logika (DL)koja polazi od dijalekta deskriptivnih logika (koje predstavljaju prosirenjefrejmova i semantickih mreza, pre svega nastale kao praktican sintaksni alatkoji je kasnije upotrebljen u standardima web ontologija). DL se sastoji izvise jezika cije kombinacije daju razlicite dijalekte, i svodi se na PR1 re-strikovan na unarne i binarne predikate, i jezik za upravljanje konceptimatj. opisima domena - razmatra se ovo prvo pre svega. Medutim, u [FDL] i[GCI] navedeni dijalekat DL koji se prosiruje u fazi DL omogucava prakticnuupotrebu fazi logike nad Web ontologijama (dijalekat namenjen OWL-DLjeziku, kao i OWL koji je veoma blizak DL, jednim od osnovnih strukturasemantickog web-a). Na sintaksnom nivou DL nije potpuno formalna jernije moguce konstruisati odgovarajucu teoriju modela i pokazati komplet-nost. Hajek u [PH] navodi postupak kojim se ovo moze prevazici upotrebomposebne definicije zadovoljivosti gde je onda moguce iskazati kompletnost DL,ali pod uslovim da se koristi iskljucivo logika Lukasiewicz-a (zbog uvodenjalogickih konstanti u jezik, sto je problematicno) i da se ne koristi kvantifika-tor ,,mnogi”. Pored toga, kritikuje ovo resenje zbog kompleksnosti racunanja(kao i klasicnu DL), kao i zbog problema implementacije.
2.8.7 Zadeov pristup
U klasicnom iskaznom racunu implikacija je logicki operator (veznik) cijase vrednost moze zadati tabelom. U zadeovskoj fazi logici umesto iskaznihpromenljivih se koriste fazi skupovi i proizvod skupova kao implikacija. Prepotpune definicije fazi recenica ovog tipa potrebno je definisati proizvod fazi

Soft Computing - racunska inteligencija (Computational Intelligence) 29
skupova A nad U i B nad V :
A×B =def
∫
U×V
µA(u) ∧ µB(v)/(u, v)
jer se implikacijom prakticno formira fazi relacija medu fazi promenljivama.Tako se recenica ,,Ako A onda B” zapisuje kao A×B (Mamdani) ili recenica,,Ako A onda B inace C” moze zapisati kao A × B + ¬A × C (Zade: paako se odbaci inace-grana onda se dobija A × B + ¬A × V ). Dakle, u fazilogici se implikacija moze definisati na vise nacina. Sledi deo tabele varijantiiz [FOUND] (koje su proucavali Mizumoto, Zimmerman 1982.) kao relacijanad U × V , u ∈ U , v ∈ V :
Ra 1 ∧ (1− u + v)Rm (u ∧ v) ∨ (1− u)Rc u ∧ vRb (1− u) ∨ v
Prakticno se najcesce koriste pomenuti max-proizvod i max-min (npr.Rc, dok Zade koristi Rb i Ra).
2.8.8 Kompoziciono pravilo zakljucivanja
Ako je je R fazi relacija od U ka V , x fazi podskup od U , y fazi podskupnad V indukovan fazi skupom x se dobija kao kompozicija (x kao unarnarelacija):
y = x R
Ovo pravilo se smatra prosirenjem modus ponensa (uopsteni MP - General-ized Modus Ponens, GMP). Ono dozvoljava (pored osobina klasicnog MP)npr. da nekakva promena premise (npr. odredbama) daje nakon primeneistog pravila nekakvu promenu u zakljucku (B′ = A′ R, R = A → Bproizvoljna kompatibilna (u smislu kompozicije) fazi relacija, A′ i B′ sunastali od A i B redom, primenom ogranicenja, algebarskih operacija ili ne-gacije ili njihovom kompozicijom). Najcesce koriscena pravila zakljucivanjasu:
uopsteni modus ponens A→B,A′B′ gde je B′ = A′ (A → B)
uopsteni modus tolens A→B,B′A′ gde je A′ = (A → B) B′

30 Seminarski rad
zakon tranzitivnosti (silogizam) A→B,B→CA→C
De Morganovi zakoni ¬(A ∧B) = ¬A ∨ ¬B¬(A ∨B) = ¬A ∧ ¬B
Uopste, fazi iskaz se moze predstaviti kao ,,X je A” (gde je X domen,A fazi skup - problemom iskazivanja fazi vrednosti recenica ovakvog tipakoje podsecaju na recenice prirodnog jezika se bavi posebna oblast (fazi)racunanja recima) a fazi pravilo kao
X je A → Y je B
Ovakvo pravilo uspostavlja relaciju medu fazi iskazima (nije implikacija) iobicno se takvo pravilo zapisuje u obliku matrice. Ovakva se fazi asocija-tivna matrica R koja mapira fazi skup A u fazi skup B zove jos i Fazi Asoci-jativna Memorija (Fuzzy Associative Memory - FAM, Kosko, 1992). Umestoobicnog linearnog preslikavanja b = R a zadatog matricnim mnozenjembj =
∑ni=1 aimij, j = 1, n obicno se koristi operator max-min kompozi-
cije b = R a zadat sa bj = maxi=1,nmin[ai,mij], j = 1, n (madamoze biti i max-proizvod kompozicija). Uopsteni postupak dobijanja ma-trice R =
∏A→B:
∏A→B =
V al(a1 → b1) V al(a1 → b2) · · ·V al(a2 → b1)
. . ....
= (rij) = R
i vazi∏
B =∏
A ∏
A→B - zavisno od definisanja operatora implikacije (ilii-norme) V al(ai → bj) = i(ai, bj) definise se i matrica zakljucivanja R.
Ako je data skup iskaza X je Ai → Y je Bi, ova matrica moze zapravobiti relacija MAMD(x, y) =
∨ni=1(Ai(x) ∧ Bi(y)) (spisak svih mogucnosti,
tzv. Mamdanijeva formula), ili RULES(x, y) =∧n
i=1(Ai(x) → Bi(y)) (kon-junkcija svih implikacija) u smislu generalizovanog modus ponensa.
2.8.9 Max-Min zakljucivanje
Ako se minimumom definise operator implikacije mij = V al(ai → bj) =min(ai, bj) onda se za data dva fazi skupa na osnovu ove formule definisematrica M .

Soft Computing - racunska inteligencija (Computational Intelligence) 31
Ako su u pitanju ,,trougani” fazi skupovi (granica linearna), onda seslikanje nekog skupa A′ svodi na odsecak B na visini vrha preseka A i A′
na nize, sto proizilazi iz definicije i osobina ovakvog preslikavanja. Npr.ako je µA(xk) pomenuti vrh ili jedna diskretna izmerena vrednost, sto senajcesce koristi kao ulaz (kao da su ostale vrednosti ulaznog vektora 0), vaziza diskretne vrednosti y ∈ X:
b(y) = µA(xk) ∧ µB(y), y ∈ X
B
B’
PraviloA B
A
A’
2.8.10 Max-Proizvod zakljucivanje
Ovaj nacin zakljucivanja se dobija ako se proizvodom definise operatorimplikacije mij = aibj.

32 Seminarski rad
Pravilo
B’
B
A’
A
BA
Preslikavanje trouglova ima osobine b(y) = µA(xk) · µB(y), y ∈ X ako jeµA(xk) pomenuti vrh) slicne prethodnom, ali se ovde dobija ,,snizeni” aliceo trougao umesto odsecka. Za jednu ulaznu diskretnu vrednost onda vazi:
b(y) = µA(xk)µB(y), y ∈ X
2.8.11 Pravila sa vise premisa, vise pravila i procedura zakljucivanja
Ako imamo dve premise A i B (moze ih biti i vise, analogno) razresenjemozemo naci (Kosko, 1992) posavsi od toga kao da imamo dva pravila A → Ci B → C sa svojim matricama MAC i MBC td. vazi:
A′ MAC = CA′
B′ MBC = CB′
Tada se definise C ′ = CA′ ∧ CB′ ako je u pitanju konjunkcija (i-link) A ∧B → C, odnosno C ′ = CA′ ∨ CB′ ako je u pitanju disjunkcija (ili-link)A ∨ B → C. U ranije pomenutom specijalnom slucaju trouglastih skupova,minimum odnosno maksimum respektivno konjunkcija odnosno disjunkcijavrhova trouglova odreduje prag odsecanja odnosno sabijanja (zavisno od togada li se koristi max-min ili max-proizvod zakljucivanje) skupa B. Za datediskretne ulazne vrednosti ai = µA(xi) i bj = µB(yj) i diskretne vrednostiz ∈ X domena vazi onda:

Soft Computing - racunska inteligencija (Computational Intelligence) 33
C ′ Spajanje Zakljucivanjemin(ai, bj) ∧ µC(z) I Max-Minmax(ai, bj) ∧ µC(z) ILI Max-Minmin(ai, bj)µC(z) I Max-Proizvodmax(ai, bj)µC(z) ILI Max-Proizvod
Ako postoji vise pravila L1 → R1, · · · , Ln → Rn sa svojim matricamaM1, · · · ,Mn onda se zakljucak moze dobiti disjunkcijom M =
∨ni=1 Mi element-
na-element matrica svih tih pravila (vid ili-linka). U fazi ekspertnom sistemuu svakom cilkusu racunanja prakticno sva pravila odjednom ucestvuju u svimkombinacijama koja namece fazi mreza zakljucivanja. Postoje skoljke zapravljenje fazi ekspertnih sistema (kao sto su to npr. FLOPS, MATLABFuzzy Toolbox ili FuzzyCLIPS) ali su takvi fazi produkcioni sistemi sklonikombinatornoj eksploziji i jos uvek daju dobre rezultate samo u specificnimoblastima. Zavisno od prirode pravila moguce je to racunanje optimizovatido izvesne granice. Jedan od nacina je obelezavanje pravila tezinama wi (npr.srazemerno normi matrice pravila) i odbacivanje onih ispod zadatog praga,kao i upotreba nekog od dodatnih else-linkova (pored i-linka i ili-linka):
• istinitosno-kvalifikacionog linka: za svako pravilo Ri, i = 1, · · · , n seracuna koeficijent Ti =
∫x∈X
µBi(x)/
∫x∈X
µB(x) i onda se uzima rezul-tat pravila Rj maksimalnog koeficijenta Tj = max Ti.
• aditivnog linka: µ′B =∑
µBiwi za pravila Ri, i = 1, · · · , n koja ucestvuju.
Moglo bi se reci da je ovakva procedura fazi zakljucivanja petorka (I, C, L, s, t)gde je I neka relacija implikacije, C operator kompozicije, L else-link koji sekoristi, s i t izabrane (ko)norme (moguca je i kombinacija razlicitih proce-dura). Takode, kao specificna primena ovakvih sistema (gde je moguca par-alelizacija) javlja se racunanje ovakvih fazi mreza zakljucivanja upotrebomodgovarajucih VLSI arhitektura kao i u kombinaciji sa drugim Soft Comput-ing tehnikama. Ohrabrajuci rezultat je dao i Kosko 1992. teoremom kojompokazuje da klasa aditivnih fazi sistema uniformno aproksimira proizvoljnuneprekidnu funkciju nad domenom koji je kompaktan (ogranicen i zatvorenu slucaju realnog skupa).
Dijagram strukture klasicnog fazi ekspertnog sistema:

34 Seminarski rad
Mehanizam fazi zakljucivanja
Baza fazi pravila
Fazifikacija
Defazifikacija
Fazi podaci / ostri podaci
Fazi upiti / ostri upiti
Baza znanja (fazi)
Korisnicki interfejs
Karakteristicne funcije
Ucenje fazi pravila
2.9 Defazifikacija (Defuzzification)
Ako imamo fazi zakljucak, za njegovo tumacenje se prakticno cesto ko-risti defazifikacija gde se obicno nekim postupkom izdvoji jedna diskretnavrednost fazi skupa kao reprezent (postupak suprotan onom koji se naziva,,fazifikacija” gde se razlictim metodama kodiraju konceptualizovani podaciu fazi skupove - npr. nesiguran broj se opisuje trouglom kao fazi skupom).Najcesce se koristi fazi centroid odnosno nekakva sredina u odnosu na pri-padnost kao tezinu (najbliza vrednosti u X):
y′ =
∑ni=1 yiµB′(yi)∑n
i=1 yi
tj. y =
∫µB′(y)ydy∫µB′(y)dy
Ako se trazi zakljucak na osnovu vise fazi pravila A1 → B1, ..., An → Bn
onda se uzima da je ukupni fazi zakljucak B′ =⋃n
i=1 B′i tj. µB′(x) =
maxi=1,n[µB′i(x)] (opet vid ili-linka, i-link se realizuje minimumom) i njegovcentroid se tumaci kao diskretna vrednost zakljucka na osnovu svih polaznih

Soft Computing - racunska inteligencija (Computational Intelligence) 35
premisa A′. Za fazi sistem oblika:
pravila
Y1 is B1 if X1 is A11, · · · , Xn is A1
n...
Ym is Bm if X1 is Am1 , · · · , Xn is Am
n
X1 is A′1, · · · , Xn is A′
n (cinjenice)
L. X. Wang je pokazao da defazifikacija njegovog zakljucka y is B′ pred-stavlja univerzalni aproksimator:
µ′B(y) =∨
x1,···,xn
[(n∏
i=1
µA′i(xi)
)(m∨
j=1
n∏i=1
µAji(xi)
)µBj(y)
]
2.10 Kompleksnost i izracunljivost
Pokazuje se da su tautologije Hajekove logike (oblik formalizacije fazilogike) ko-NP kompletne (nezadovoljivost je NP kompletna), zadovoljive for-mule NP kompletne, a odgovarajuci predikatski racun je u opstem slucajuneodluciv po Hajeku (Hanikova 2002, Hajek 2005). Ukratko, nije svakat − norma izracunljiva. S druge strane, pokazano je da svaka aksiomati-zabilna i kompletna fazi teorija jeste izracunljiva (uz pogodno definisanuizracunljivost fazi skupova, Gerla, 2006 - ne postoje jos svi potrebni rezultatiu tom smislu, kao sto je to Church-ova teorema). U svakom slucaju, ociglednoje da fazi sistemi prakticno zahtevaju vise racunanja nego klasicni (nema do-voljno dobrih poredenja sa verovatnosnim), kao i dodatna istrazivanja u veziformalnog zasnivanja i teorije modela.
2.11 Fazi logika i alternativne teorije verovatnoce
Verovatnoca se bavi nekim dogadajem koji se nakon eksperimenta de-sio ili nije - u realnosti je cesto tesko odrediti sta se desilo, ali nesto stose ,,otprilike” desilo je koncept fazi skupa (drustvene pojave, ili npr. dali je pala kisa ili mozda samo malo ?). Dakle, ostar dogadaj X = u zaslucajnu promenljivu X i u ∈ U sa nekom verovatnocom p(X=u) moze bitidodeljen nekom fazi skupu A nad U nekim stepenom odredenim njegovomkaraktersticnom funkcijom (koja, ocigledno, ima potpuno drugaciju ulogu odraspodele slucajne promenljive). Tada se moze naci verovatnoca fazi skupa

36 Seminarski rad
kao p(A) =∫
UµA(u)p(X = u). Primer: ako je X sa uniformnom raspode-
lom na nekom skupu kardinalnosti n onda je p(A) =∑
µA(u)/n. Za takveskupove se onda kaze da su fazi dogadaji. Za njih takode vaze osobine ostrihdogadaja: p(¬A) = 1−p(A), p(A∪B) = p(A)+p(B)−p(A∩B), A ⊆ B ⇒p(A) ≤ p(B). Za karakteristicnu funkcjiju fazi dogadaja X = u se onda kazeda je funkcija distribucije mogucnosti Poss(X = u) tog dogadaja.
Zade nejasnocu prirodnog jezika i sveta opisuje osobinom f-granularnosti(gde se vise vrednosti nekih atributa grupisu u granule nerazdvojivoscu,slicnoscu, blizinom ili funkcionalnoscu). On klasicnu teoriju verovatnoce kaoi logiku vezuje za merenja i merljive aktivnosti, dok fazi logiku i verovatnocuvezuje za percepciju (perception-based probability theory = PTp). Obicnateorija verovatnoce se nadograduje u tri nacelna koraka do PTp: najprese prethodno skiciranom f-generalizacijom verovatnoce, dogadaji i relacijevezuju za fazi skupove i dobija se PT+. U drugom koraku se f.g-generalizacijomverovatnoce, dogadaji i relacije cine f-granularnim. Npr. ako je Y = f(X)preslikavanje, onda se f moze opisati kolekcijom fazi pravila ,,Y is Bi ako Xis Ai” gde su Ai i Bi (i = 1, · · · , n) fazi skupovi u X i Y , redom. Tako se do-bija PT++. Poslednji korak obuhvata postupak nl-generalizacije koji se svodina postupak opisivanja potrebnih osobina uslovima preciziranim prirodnimjezikom (Precisiated Natural Language = PNL), npr. X isp (P1|A1 + · · · +Pn|An) gde su Ai fazi skupovi a Pi njihove verovatnoce (detalnjije o tome uracunanju s recima).
2.11.1 Dempster-Sejferova teorija
Za razliku od ekspertnih sistema kao sto je PROSPECTOR baziranih naBajesovom principu verovatnosnog zakljucivanja ili formalizama kao sto suMarkovljevi i skriveni Markovljevi lanci (stohasticki konacni automati kodkojih je prelazak iz stanja u stanje obelezen verovatnocom, kod skrivenihje cak nemoguce unapred odrediti prelaske stanja vec samo posledica), ne-verovatnosne (neprobabilisticke) teorije koriste pristup koji nije u okvirimastandardne teorije verovatnoce. Tako su Dempster i Sejfer (Dempster 1967,Shafer 1976) otkrili ovakav jedan pristup u kojem je polazna ideja meranazvana masom m(E) dogadaja u U ili skupa dogadaja i onda posma-trati nekakvu donju i gornju granicu verovatnoce takvog skupa dogadaja- mogucnost (credibility) Cr(E) i verovatnost (Plausibility) Pl(E). Tadavaze aksiome Dempster-Sejferove (D-S) teorije:

Soft Computing - racunska inteligencija (Computational Intelligence) 37
A1 0 ≤ m(E) ≤ 1 (ako je m(E) > 0 onda je E zizni element)
A2∑
E⊂U m(E) = 1
A3 Cr(E) =∑
C⊆E m(C)
A4 Pl(E) = 1− Cr(¬E) =∑
C*E m(C)
Pokazuje se da je ∀E ⊆ E Cr(E) + Cr(¬E) ≤ 1, P l(E) + Pl(¬E) ≥1, Cr(E) ≤ Pl(E). Potpuno neznanje o ziznom elementu E (ili domenu)je iskazano sa Cr(E) = Cr(¬E) = 0, P l(E) = Pl(¬E) = 1. Nesig-urnost u zakljucivanju se propagira niz lanac zakljucivanja ali i kombinuje- predlaze se jednostavno sledece: ako je A1 ∩ A2 = A3 6= ∅ onda vazim(A3) = m(A1)m(A2). Npr. za pravila: E1 → H1(β1), E2 → H2(β2) vazionda m(H) = m(H1)m(H2) = Cr(E1)β1Cr(E2)β2 gde su β1 i β2 koeficijentiuverenja zakljucka. Dalje se racuna Cr(H) i Pl(H) ako je potrebeno premaaksiomama.
2.11.2 Zakljucivanje s uverenjem
Znacenje uverenja naspram verovatnoce vezuje za prakticno iskustvo, in-tuitivno ljudsko znanje i drugaciji formalni aparat. Uverenje predstavljameru da je nesto moguce odnosno verovanja da je tako (moguce naspramverovatno). Pravilo E1 ∧ E2... → Hβ tako ima faktor uverenja β (certainityfactor) koji ima vrednost od −1 (potpuno netacno) do 1 (potpuno tacno).MYCIN koristi takav pristup (Giarratano, Riley, 1989), s tim da je naglasakbio na mehanizmu i formuli koja bi imala osobine: komutativna (da bi seizbegla zavisnost rezultata od redosleda primene pravila) i asimptotna (svakopravilo koje dodatno podupre uverenje ga povecava asimptotski ka 1).
2.11.3 Mere verovanja i neverovanja i ukupno uverenje
Uvode se mere verovanja µB (belief) i neverovanja µD (disbelief) takodetako da budu komutativne i asimptotne. Nakon prikupljanja svih podataka(za i protiv) i racunanja ovih mera za datu hipotezu H se odreduje ukupnouverenje (net belief): β = µB−µD. Na osnovu dokaza E uverenje u hipotezuse moze uvecati ako je p(H|E) > p(H) ili smanjiti ako je p(H|E) < p(H)(odnosno, povecava se neverovanje u potonjem slucaju):

38 Seminarski rad
µB(H, E) =
1, ako je p(H) = 1max [p(H|E),p(H)]−p(H)
1−p(H), inace.
µD(H,E) =
1, ako je p(H) = 0min [p(H|E),p(H)]−p(H)
−p(H), inace.
... i odavde se vidi da je 0 ≤ µB(H, E) ≤ 1 i 0 ≤ µD(H, E) ≤ 1. Dalje,β(H, E) = µB(H,E) − µD(H, E) ima vrednost -1 ako E potpuno opovr-gava H, 0 ako E nije dokaz (nedostatak dokaza - E je nezavisan od H tj.p(H|E) = p(H) pa su obe mere i uverenje onda jednake 0), ili 1 ako Epotpuno potvrduje H. Zbir β(H,E) + β(¬H,E) uopste ne mora biti 1.
2.11.4 Propagiranje uverenja
Za dato praviloE → H β(PRAV ILO)
racuna se uverenje kao β(H, E) = β(E)β(PRAV ILO). Ako je u pitanjukonjunkcija
E1 ∧ E2... → H β(PRAV ILO)
onda je:β(H,E1 ∧ E2...) = min
iβ(Ei)β(PRAV ILO)
a ako je disjunkcija
E1 ∨ E2... → H β(PRAV ILO)
u pitanju onda je:
β(H, E1 ∨ E2...) = maxi
β(Ei)β(PRAV ILO)
Ako dva pravila zakljucuju o istoj hipotezi, onda se ,,akumulira” uverenjeprema (Shortliffe, Buchanan, 1975):
µB(H, E1&E2) =
0, µD(H,E1&E2) = 1µB(H, E1) + µB(H, E2)(1− µB(H,E1)), inace.

Soft Computing - racunska inteligencija (Computational Intelligence) 39
µD(H,E1&E2) =
0, µB(H, E1&E2) = 1µD(H,E1) + µD(H,E2)(1− µD(H,E1)), inace.
... odnosno, ako se odmah racuna uverenje (β1 i β2 su izracunata uverenjadvaju pravila):
β(β1, β2) =
β1 + β2(1− β1), ako je β1, β2 > 0
β1+β2
1−min [|β1|,|β2|] , jedan od β1, β2 < 0
β1 + β2(1 + β1) inace.
Pokazuje se da se dubinom ovakvog zakljucivanja brzo gomilaju greske (racunanja).
2.11.5 Mogucnost i potrebnost
Kao uopsteni koncept mere neuverljivosti (uncertainity) nekog dogadaja(ili skupa) E, Zade, Sugeno, Duboa i Prade (Duboius, Prade, 1988) uvodetzv. parametar uverenja g(E) : 0 ≤ g(E) ≤ 1, E ⊆ U . Kada je do-gadaj siguran, onda je g(E) = 1 ili ako je nemoguc onda je g(E) = 0- obratno ne mora da vazi. Mogucnost (possibility) Π : U → [0, 1] jestepen kojim neka hipoteza H ocenjena mogucom (npr. od strane nekogeksperta). Mogucnosti H i ¬H su slabo povezane za razlik od njihovihverovatnoca: max (Π(H), Π(¬H)) = 1. Za nju vazi (∀A,B ⊂ U)Π(A ∪B) =max(Π(A), Π(B)). Ako je Π(A) = 1 i A∩E 6= ∅ onda je dogadaj E siguran,inace je Π(A) = 0. Takode, potrebnost (necessity) je funkcija N : U → [0, 1]td. (∀A, B ⊂ U)N(A ∩ B) ≤ min(N(A), N(B)). Pored ovih, vazna je ifunkcija raspodele mogucnosti (possibility distribution) Poss : U → [0, 1] td.Poss(E) = Π(E). Vaze aksiome:
a1 E1 ⊆ E2 ⇒ g(E1) ≤ g(E2) (monotonost)
a2 (∀A,B ⊂ U)g(A ∪B) ≥ max(g(A), g(B))
a3 (∀A,B ⊂ U)g(A ∩B) ≤ min(g(A), g(B))
a4 Π(A) = 1−N(¬A)
a5 min(N(A), N(¬A)) = 0

40 Seminarski rad
a6 (∀A ⊆ U)Π(A) ≥ N(A)
a7 N(A) > 0 ⇒ Π(A) = 1
a8 Π(A) < 0 ⇒ N(A) = 0
a9 Π(A) + Π(¬A) ≥ 1
a10 N(A) + N(¬A) ≤ 1
Moze se pokazati da je Cr ekvivalentno potrebnosti N i Pl da je ekvivalentnomogucnosti Π akko zizni elementi formiraju ugnjezdene nizove skupova (akosu zizni elementi elementarni tj. cine ih samo pojedini dogadaji a ne skupovi,onda je ∀E Cr(E) = Pl(E) = p(E)), tako da su D-S i teorija mogucnosti iposebnosti prosirenje standardne teorije verovatnoce za razliku od teorije uv-erenja. Ako je E fazi skup onda se distribucija mogucnosti moze iz normiranekarakteristicne funkcije tog skupa.
2.12 Racunanje s recima
Ukratko, fazi racunanje s recima (CW = Computing with Words) se bavifazi vrednoscu kanonskih formi (canonical form) oblika: X is R gde je R fazirelacija a X uslovljena promenljiva (constrained, u smislu bliskom ,,test-scoresemantics” i CLP, Constrained Logic Programming). Vise takvih uslova segrupise oko jednog iskaza p nekog (prirodnog npr.) jezika sto se pise kao:
p → X is R
i to je jedna eksplicitacija iskaza p. Spomenut je ranije u tekstu vec uslovnioblik ,,Y is B if X is A”, a ovakvi i prethodni uslovi se nazivaju osnovnim.Prirodni jezik (NL = Natural Language) namece potebu za opstijim oblikomuslova, i Zade predlaze generalizovani oblik uslova ,,X isr R”gde diskretnapromenljiva ,,r” u kopuli ,,isr” upucuje na koji nacin R uslovljava X:
e jednakost (skraceno =)
d disjunktivno (moguce - possibilistic - skraceno blanko:ima znacenje PossX = u = µR(u) gde je R = ΠX distribucijamogucnosti (possibility distribution))
c konjunktivno

Soft Computing - racunska inteligencija (Computational Intelligence) 41
p verovatnosno (npr. X isp N(m, σ2))
λ vrednost verovatnoce
u uobicajeno (usuality)
rs slucajni skup (random set, Dempster-Sejferova teorija radi sa ovakvim iprethodnim uslovima - kao pravilo zakljucivanja: X isp P, (X, Y ) is Q →Y isrs R)
rsf slucajni fazi skup (random fuzzy set)
fg fazi graf (lukovi su obelezene stepenom pripadnosti - vid fazi relacije R =∑Ai ×Bi za pravila ,,Y is Bi ako X is Ai”)
...
Za propagiranje ovakvih uslova se koriste fazi pravila zakljucivanja kao stoje GMP, ali i dodatna pravila za pojedine vrste uslova kao sto su to npr.:
Konjunktivno pravilo 1 X is A, X is BX is A∩B
Konjunktivno pravilo 2 X is A, Y is B(X,Y ) is A×B
Disjunktivno pravilo 1 X is A ili X is BX is A∪B
Disjunktivno pravilo 2 X is A ili Y is B(X,Y ) is (A×V )∪(U×B)
Konjunktivno pravilo za isc X isc A, X isc BX isc A∩B
Disjunktivno pravilo za isc X isc A ili X isc BX isc A∪B

42 Seminarski rad
Projektivno pravilo (X,Y ) is AY is projV A
gde je projV A = supu A
Surjektivno pravilo X is A(X,Y ) is A×V
Kompoziciono pravilo X is A, (X,Y ) is BY is AB
Uopsteni modus ponens X is A, Y is C if X is BY is A(B×C)
Pravilo preslikavanja (princip ekstenzije) X is Af(X) is f(A)
gde je f : U → V i µf(A)(ν) = supu: ν=f(u) µA(u)
Pravilo inverznog preslikavanja f(X) is A
(X is f (−1)(A)
gde je µf (−1)(A)(u) = µA(f(A))
Pravilo modifikacije uslova X is mAX is f(A)
gde je m modifikator kao sto je
to negacija (¬) ili odredba (veoma, donekle, zaista, i sl.) a f odredujekako modifikator menja skup
Pravilo kvalifikacije verovatnoce (X is A) is ΛP is Λ
gde je X slucajna promenljivanad domenom U sa distribucijom (gustinom verovatnoce) p(u), Λ jelingvisticki verovatnosni izraz (verovatno, veoma verovatno i sl.) i P jeverovatnoca fazi dogadaja X is A:
P =
∫
U
µA(u)p(u)du
Konceptualna struktura racunanja s recima polazi od znacenja iskaza p kojise dvema procedurama iz baze objasnjenja (ED = Explanatory Database)pretvara u odg. promenljivu X i relaciju R i to je onda instanca te bazei element baze instanci objasnjenja (EDI). Cilj je iz pocetne baze znanjaodnosno iskaza (IDS = Initial Data Set) i upita izvesti iskaz iz zavrsne bazeznjanja (TDS = Terminal Data Set).

Soft Computing - racunska inteligencija (Computational Intelligence) 43
Iskazi NL
lingv. promenljiva
Polazak Fazi skup
granula
fazi pravilo
fazi graf
iskazi NL
semantika (test−score)
fazi uslovi
propagiranje uslova
izvedeni uslovi
lingv. aproksimacija
iskazi u NL zakljucci
premise
kanonske forme
zaklj. u fazi logici
IDS CW TDS
Iskazi NLeksplikacijaiskaza
propagiranjeuslova
transformacijauslova
Takode, Zade izgraduje racun pitanja i odgovora (uspostavlja se fazirelacija medu njima) kao vid pristupa slozenim i nepreciznim sistemima (kojidonosi elemente pretrage fazi baze znanja). Napomena: Zade u svojem tek-stu koristi , sa znacenjem =def :
Definicija 2.8 Atomsko pitanje Q je odredeno trojkom Q , (X, B, A), gdeje Q skup objekata (lingvistickih promenljivih) na koje se atomsko pitanjeodnosi, B je oznaka pitanja (telo) odnostno klase objekata ili atributa, A jeskup mogucih dozvoljenih odgovora. Kada je potrebno, instance Q, X i A seobelezavaju malim slovia q, x, a. Kada se X i A podrazumevaju pise se:
Q , B

44 Seminarski rad
a specificno pitanje sa dozvoljenim odgovorom
Q/A , B?a
odnosnoq/a , B?a
Ova trojka se moze posmatrati kao skup promenljivih B(x), x ∈ X takoda vazi B(x) = a i neka numericka vrednost ili lingvisticka su dodeljenipromenljivi B(x). Npr. odgovor na pitanje ,,0.8 je da li je vaza crvena”jeekvivalentno crvena(vaza) = 0.8. Q/A par se naziva pitanje/odgovor parom.
Pitanje je klasifikaciono ako se B odnosi na fazi skup kao objekat, atribu-ciono ako se odnosi na atribut (vrednost fazi skupa). Kod klasifikacionogpitanja, odgovor a predstavlja stepen pripadnosti x u B, npr. odgovor mozebiti ostar (numericki) a , 0.8 ili lingvisticki a , srednje. Kod atribu-cionog pitanja Q = B? odgovor a predstavlja vrednost atributa B, npr.B , starost, i x , Pera, gde a moze biti numericki a , 35 ili lingvistickia , veoma mlad td. vazi µmlad = 1 − S(20, 40) za domen U = [0, 100] (za-pravo z-kriva) i sl.
Ugnjezdeno pitanje ,,Da li je tacno da je (...((x is w) is τ1)... is τn)” imaodgovor oblika a , ((x is w) is τ1 · · · is τn).
Na primer, ako je kao ranije B , starost i pitanje ,,Da li je tacno da (Perais mlad)”tada, ako odgovor a , 0.5 na pitanje onda je Perina starost zadatasa B(Pera) = µB
−1(0.5) = 30 gde je B(Pera) = µB−1(τ) = µB
−1τ . Uopste,za a , (x is w1) is τ (w1 je fazi podskup domena U) vazi a∗ , x is w2 gdeje w2 = µw1
−1 τ , gde je je kompozicija fazi relacija. Tada je za prethodni

Soft Computing - racunska inteligencija (Computational Intelligence) 45
primer τ je lingvisticka istinitosna vrednost karakterisana sa µτ . Za pomenutiugnjezdeni upit onda vazi a∗ , x is wn+1 gde je:
wn+1 = µwn
−1 τn
wn = µwn−1
−1 τn−1
...
w2 = µ1−1 τ1
Na osnovu ovoga se definisu slozena (kompozitna) pitanja sa ciniocima Q1, · · · , Qn
i telima B1, · · · , Bn koja su n-adicna (npr. ako n = 1 onda su monadicna) ikarakterisana relacionom reprezentacijom B(B1, · · · , Bn). Uvode se tabelarnizapisi, ili skraceni algebarski: i-ti red tabele je onda zapisan kao odg. Q/Aparovi Q1r
1i · · ·Qnr
ni //Qri ili samo r1
i r2i · · · rn
i //ri i tada je B =∑
i r1i r
2i · · · rn
i //ri.Postoji i analiticka interpretacija ovakvih pitanja. Granajuci upiti su ondaoblika Q∗ = a2
1a11a
31//a1 + a2
1a11a
32//a2 + a2
1a12//a2 + · · ·.
Vise o tome u [words], [GRAN], [SCFL] i [FSNEW].

46 Seminarski rad
2.13 Fazi algoritmi
Fazi algoritam bi nacelno mogli opisati kao ureden skup fazi instrukcijanakon cijeg se izvrsenja dobija priblizno resenje nekog problema ili neka akcija(fazi instrukcije se ticu fazi skupova, verovatnoca, dogadaja, relacija, funkcijai drugih fazi entiteta). Kod fazi ekspertnih sistema je naglasak na mehanizmufazi zakljucivanja kome je prepustena kontrola toka izvrsenja pojedinih op-eracija. Kod fazi algoritama kontrola toka vise lici na klasicne algoritme- mogu se uporediti i sa prosirenim mrezama prelaska (ATN - AugmentedTransition Networks) kojima su pridodata fazi uslovna pravila na prelaskui operacije nad fazi skupovima i relacijama (fazi Petri mreze i fazi grafovi,gde se fazi algoritam svodi na fazi relaciju tj. racunanje se tada svodi naracunanje te fazi relacije). Fazi algoritam podrazumeva i ostre (klasicne)iterativne i kontrolne elemente. Zade algoritme deli u cetiri nacelne grupe:
1. Definicioni algoritam - definise trazeni fazi skup u terminima zadatihfazi skupova (izrazen fazi operacijama nad njima, mozda rekurzivno)ili daje efektivnu proceduru odredivanja pripadnosti istom (npr. pred-stavljanje slozenih pojmova kao sto je rukopis jednostavnijim fazi poj-movima).
2. Generacioni algoritam - za razliku od prethodnih generise trazeni skup(npr. pomenuti rukopis)
3. Relacioni i bihejvioristicki algoritam - opisuje vezu ili veze medu fazipromenljavama, a ako pri tom opisuje (simulira) ponasanje nekog sis-tema onde je takav algoritam bihejvioristicki.
4. Algoritam odluka - daje priblizan opis strategije ili pravila odluke (npr.upravljanje nekim sistemom)
Na Zadeovoj stranicu [WWW] se mogu naci njegovi originalni tekstovi, ali iprezentacije rada BISC (The Berkeley Initiative in Soft Computing), gde serazmatraju fazi sistemi pomenuti u zadnja dva poslednja odeljka kao i nekedruge njihove primene.

Soft Computing - racunska inteligencija (Computational Intelligence) 47
3 Neuronske mreze
3.1 Uvod
Proucavanje ljudskog mozga i razmisljanja je u razlicitim oblicima starohiljadama godina. Osnovnim naucnim i bioloskim principima funkcionisanjamozga raspolazemo tek nesto vis od 100-200 godina - pogotovu se dugo nijeznalo nista o funkcionisanju osnovnog gradivnog elementa nervnog sistema imozga - nervne celije, neurona. Mogla bi se napraviti podela disciplina kojeproucavaju funkcionisanje ljudskog mozga i strukture neurona prema brojuneurona: brojem reda 1011 tj. na nivou celog mozga kao organa se bavelogika, psihologija, i sl. Negde na sredini bi bila, recimo, neurohirurgija, aneurologija i neuronauke onda odatle sve do pojedinih neurona. Vestackeneuronske mreze ili skraceno, neuronske mreze (NM), su matematicki i elek-tronski modeli rada struktura neurona na najnizoj lestvici po broju neurona,od pojedinih do negde reda od 103 do 104 (uglavnom daleko manje, a primeraradi, samo jedan neuron moze imati i do 10000 dendrita tj. ,,ulaza” iz drugihneurona) - i to dosta grubi modeli (ne uzimaju se obzir npr. hemijski procesii supstsnce, neurotransmiteri (zaduzeni za prenos potencijala u sinaptickimspojevima), promenu strukture u toku vremena, hormone i drugo, vec se uz-imaju u obzir samo elektricni impulsi) - ali koji dobro aproksimiraju rad NMna tom nivou.
Istorijski gledano, prvi korak u nastajanju NM napravili su neurofiziolog1943. Varen Mekalok (Warren McCulloch) i matematicar Volter Pits (WalterPitts) svojim radom o tome kako bi neuroni mogli raditi i jednostavnim mod-elom realizovanim elektricnim kolima (pokazalo se da to nije sasvim tacanmodel bioloskih NM ali je znacajno uticao na kasnije modele - svaki neuronje funkcija koja zavisi od vremena i ulaznih signala kombonovanih logickimoperacijama, npr. N3(t) = ¬N2(t−1)∨N1(t−2)), zatim Donald Hebb 1949.otkricem favorizovanja putanja koje su vec koriscene. Nekako s razvojemracunarskih tehnologija i VI (od 1956. okupljanjem u Dartmutu) uporedopostaje popularnija i ideja NM - Dzon fon Nojman predlaze osnovne elek-tronske elemente za realizaciju neurona, 1959. prva poznata prakticna pri-mena (ADALINE). Frenk Rozenblat 1962. daje poznatu strukturu ,,Percep-tron” u knjizi ,,Principi neurodinamike” (ponderisani zbir ulaza i prag kojidaje dve vrednosti) koji je mogao da klasifikuje prostor ulaza u dve klase.Medutim Marvin Minski i Sejmur Papert 1969. u svojoj knjizi ,,Percep-

48 Seminarski rad
troni” pokazuju da takva struktura nemoze da realizuje mnoge veoma jed-nostavne operacije kao sto je to npr. logicka XOR-kapija (jer jednoslojni per-ceptron klasifikuje samo linearno separabilne skupove - dok je, kako je 1951.S.C. Kleene pokazao, Mekalok-Pitsov model neurona sposoban racunski ek-vivalentno elektronskim racunarima). Takvi zakljuci i pre svega losa ,,opstaklima” u vezi NM su stvorila krizu i mnogi istrazivacki projekti su ostalibez prihoda. Tako je bilo sve do sredine 80-tih (1982. Dzon Hopfild (JohnHopfield, Caltech) i Kohonen nasli nove strukture NM i primene, i nekakoback-propagation algoritam postaje ponovo popularan iako ga je grupa au-tora otkrila jos 70-tih: Werbor, Parker, Rumelhart, Hinton, Williams).
3.2 Osnovni model neurona
Bioloski neuron, kako je pomenuto, ima mnogo dendrita (ulaza) oko some(sredisnji deo s jedrom) i samo jedan izlaz (akson), koji se preko sinapsispaja s mnogo dendrita drugih neurona. Svaki dendrit moze uticati na eksc-itaciju ili inhibiciju neurona - ako je dovoljno ekscitovan, neuron se okida tj.

Soft Computing - racunska inteligencija (Computational Intelligence) 49
salje elektricni impuls (od 70-100 mV koji nastaje kao razlika u potencijalutecnosti unutar i izvan celijske membrane Na-K pumpom) niz akson (u pros-eku je frekvencija okidanja najvise 100 puta u sekundi, a signal nalik talasuputuje od jedne do druge Ranvijeove tacke aksona - ta tacka ponovo dostizepotencijal potreban za okidanje tek za 1 ms - refraktorna perioda). Pokazujese da je dovoljno sve racunati u vremenski jednakim koracima (sinaptickimkasnjenjem), iako to nije sasvim precizan model bioloske NM. Zanimljivo jeda visok stepen paralelizacije prisutan u bioloskoj NM (ciji su osnovni el-ementi - neuroni - snage reda najvise 10−3s) omogucava neuporedivo vecuracunsku moc nego danasnji racunari ciji su osnovni elementi brzine reda10−9s.
i
r
fa
qy
t
in
i0w k
E
ε
k k(x , y )
x
x* *y
i
w
i1w
i1w
i1w
w i1
wi1
= b (bias)i0
iX
iOΣ i
PEi
i2
i3
in−1inX
X
.
.
.
X
X
1X
y i
i
( net )
Osnovne komponente vestackog neurona (odnosno modela neurona) kaoosnovnog procesnog elementa (PE - ili procesnog cvora, jedinice) NM su:
1. ulazi sa tezinskim koeficijentima (ponderima) - ulazi se obicnopredstavljaju vektorom tj. kolonom realnih brojeva xi = [xi
j]Tj =
[xij(t)]
Tj (za i-ti PE), kao i ponderi (sinapticke tezine) wij = wij(t)

50 Seminarski rad
(takode za i-ti PE tj. neuron), koji nacelno zavise od vremena tj. odbroja iteracija t - stavise, ceo sistem moze zavisiti od vremena i tadaje dinamicki sistem). Cesto se koristi i jedan dodatan specijalan kon-stantni ulaz, tzv. bias bi, ili ako je xi
0 = 1 za sve i onda se mozesmatrati da je jednak odgovarajucim ponderima wi0 tj. vektor ponderab = [wi0]
Ti se moze posmatrati kao kolona kojom je matrica W = [wij]
prosirena s leve strane u [b|W ] - ali je krace isto obelezena sa W .
2. funkcija sumiranja - sumiranje ponderisanih ulaza (ulaza uparenih sasvojim odgovarajucim tezinskim koeficijentima, sto cesto podrazumevai njihovo mnozenje) odnosno njihovo agregiranje u jednu vrednost izrazenuopet realnim brojem realizuje se odgovarajucom funkcijom net odnosnooperatorom. To je najcesce skalarni proizvod (zbir proizvoda ulaza sasvojim ponderom - tada je vektor funkcija sumiranja svih PE linearnioperator net = [neti]i
T = Wx + b, ali moze biti i nesto drugo. Nekefunkcije na tu vrednost naknadno primenjuju i aktivacionu funkciju Fi
koja se recimo menja s vremenom ili zavisi od vremenski prethodnevrednosti aktivacione funkcije (ako se matrica koeficijenata W = [wij]prikaze kao matrica redova W = [wi]
T tj. wi = [wi1, · · · , wij, · · ·]T ):
neti(t) = net([xij(t)]j
T, [wij(t)]j
T ) =∑
j
wij(t)xij(t) = W (t) xi(t),
tj. net(wi, xi) = wT
i · xi, ai(t) = Fi(ai(t− 1), neti(t))
Umesto indeksa i mogao bi se npr. koristiti par (h, i) indeksa od kojihh npr. ukazuje kojem sloju pripada dati PE, ali ovako je prakticnijerasporediti indekse u particije Sh koje predstavljaju slojeve.
3. transfer funkcija - rezultat funkcije sumiranja se prosleduje unarnojfunkciji yi(a) = fi(ai(t)) koja najcesce daje vrednost 0 osim ako seprede prag okidanja (threshold) koji predstavlja osnovni parametar izato je sinonim za transfer funkciju funkcija praga okidanja. Neke klaseNM koriste funkcije transfera sa dodatnim parametrom, temperaturnimkoeficijentom (sto nije isto sto i temperatura - sum koji se dodaje po-jedinim neuronima), koji takode ucestvuje u obucavanju NM sto mozedosta da ubrza proces ucenja. Primeri transfer funkcija (najcesce seupotrebljavaju linearna i sigmoid funkcije izmedu ostalog zato sto susvuda diferencijabilne) oblika y = f(a) sa pragom okidanja u nuli:

Soft Computing - racunska inteligencija (Computational Intelligence) 51
kapija, stepenasta funkcija y =
0, a < 0;1, a ≥ 0.
simetricna kapija y =
−1, a < 0;1, a ≥ 0.
linearna (identitet) y = a
lin. sa zasicenjem y =
0, a < 0;a, 0 ≤ a ≤ 1;1, a > 1.
simetricna lin. sa zasic. y =
−1, a < −1;a, −1 ≤ a ≤ 1;1, a > 1.
logaritamski sigmoid y = 11+e−a
hiperbolicki tangens sigmoid y = ea−e−a
ea+e−a
softmaks y = eneti∑j enetj
pozitivna linearna y =
0, a < 0;a, a ≥ 0.
integrator y(t) =∫ t
0a(τ)dτ
funcija takmicenja 1 samo ako ima najveci izlaz u sloju, 0 inace

52 Seminarski rad
4. skaliranje i ogranicenje - izlaz transfer funkcije se mnozi nekim ko-eficijentom i dodaje mu se neka konstantna vrednost (gain) - ovo seretko koristi, a cilj je da izlaz u bude u granicama nekog intervala (ko-risti se u nekim specijalnim modelima bioloskih NM - James Anderson,brain-state-in-the-box).
5. funkcija izlaza i kompeticioni ulazi - uobicajeno je da funkcijaizlaza bude jednaka izlazu transfer funkcije yi(t) = oi(t). Neke topologijeNM dozvoljavaju da izlaz bude dodatno modifikovan kompeticionimulazima koji dolaze od susednih neurona (na istom nivou ili sa visenivoa) i inhibiraju ga ako nije dovoljno jak. Drugo, kompeticioni ulazicesto uticu na izbor neurona koji ce ucestvovati u procesu ucenja iliadaptacije.
6. funkcija greske i povratno-propagirana vrednost - U vecini NMkoje uce racuna se razlika nekog zeljenog izlaza (nakon prethodnogkoraka) i trenutnog izlaza (npr. iz skupa ulaza i izlaza za obucavanje)ε(x) = ∆(y(x)) = y∗(x) − y(x) gde je ε(x) = [ε(x)j]
Tj . Takva razlika
se prosleduje funkciji greske (koja moze da stepenuje razliku, zadrzinjen znak, itd.) i dobijeni rezultat, koji se zove trenutna greska iliterm greske, se prosleduje funkciji ucenja nekog (drugog) procesnogelementa (i to obicno propagiranjem unazad). Racuna se npr. prosecnakvadrirana greska nad skupom obucavanja E = 1
p
∑xi
∑mj=1 εj(xi)
2, gdesu xi ulazi skupa obucavanja sa p elemenata i m izlaznih neurona.
7. funkcija ucenja - u svakom krugu ucenja (koji sledi obicno nakonprethodnih koraka i zapocinje preispitivanjem izlaznih procesnih ele-menata) funkcija ucenja ili adaptaciona funkcija procesnih elemenatakojima se prosledi ulaz u funkciju ucenja modifikuje vrednosti koefi-cijenata svojeg neurona (npr. zbir ulaznog koeficijenta sa proizvodomulaznog koeficijenata i adaptacionog ulaza). Jedan pristupa bi mogaobiti resavanje sistema jednacina (cak diferencijalnog za mnoge klase di-namickih i rekurentnih NM, fizicki modeli) cije bi resenje (ekvilibrium)bilo oblika wnovo
ij = G(wistaroij , xi, xj, · · ·) ali se to pokazuje neupotre-
bljivim za bilo koju slozeniju strukturu. Ucenje moze biti nadgledano(supervised) gde postoji ucitelj, bilo kao skup za obucavanje (poz-natih ispravnih ulaza i izlaza) ili spoljna ocena valjanosti rezultata.Ucenje moze biti i nenadgledano (unsupervised) bez spoljne ocenepo nekom ugradenom pravilu - ucenje kroz rad, bez primera.

Soft Computing - racunska inteligencija (Computational Intelligence) 53
3.3 Grupisanje neurona i struktura NM
Sam neuron (pa ni jedan sloj nepovezanih neurona) nije dovoljan za ioleslozeniji problem. Prvi pokusaj nasumicnog grupisanja i povezivanja neuronase pokazao neuspesnim - zakljucak: neophodna je struktura NM odnosnotopologija (veza) NM (ako se posmatra NM kao specifican graf). Najjed-nostavnija i dosad najcesce upotrebljavana struktura NM koja se pokazalaveoma uspesnom je rasporedivanje neurona po slojevima. Tri osnovna tipapostoje:
1. Sloj ulaza - vektor ulaza se obicno posmatra izdvojeno od ostatka struk-ture NM. Preko ulaza NM komunicira sa spoljasnim svetom (npr. sen-zori) ili ulaznim datotekama
2. skriveni slojevi - nalaze se izmedu ulaznog i izlaznog sloja. Mozeih biti vise i nepostoji posebno teorijsko ogranicenje njihovog brojaosim prakticnih iskustava i nekih delimicnih teorijskih dokaza kojimase pokazuje da je 4-5 slojeva dovoljno za vecinu problema proizvoljnekompleksnosti. Pokazuje se da povecanje kompleksnosti (kod topologijeprimerene problemu) najcesce zahteva povecanje broja neurona po nekimslojevima a ne broja slojeva
3. izlazni sloj - neuroni ciji se izlazi uzimaju kao rezultat racunanja NM

54 Seminarski rad
Neuroni unutar slojeva obicno nisu povezani osim u nekim slucajevimagde se takve lateralne veze koriste za takmicenje sa drugima ili inhibiciju(lateralna inhibicija) - sto zavisi od pondera. Moguca je razlicita upotrebaparametara i drugih komponenti (transfer funkcije npr.) po slojevima. Tokobrade podataka (odnosno signala) ide od ulaznih neurona ka narednim slo-jevima (skrivenim) sve do izlaznih i veze se grade samo izmedu susednihslojeva (cesto u maniru svaki sa svakim):
• ako postoji veza od i-tog do j-tog PE onda vazi oi = xjqj
za neke indekseulaza qj (s tim da je dozvoljeno da i-ti PE bude povezan sa vise drugihPE - jednostavnosti radi se uzima da je qj = i),
• za vektor ulaznih vrednosti x = [xi]Ti vazi tako xi = xu
qugde su u indeksi
ulaznih PE a qu odg. indeksi ulaza (jedan ulaz moze biti povezan savise PE - jednostavnosti radi uzima se da se poklapa qu = i),
• vektor izlaznih vrednosti y = [yj]Tj je isto tako jednak [ov]T gde su v
indeksi odgovarajucih izlaznih PE

Soft Computing - racunska inteligencija (Computational Intelligence) 55
Kod ranije opisane matrice Wh = [wij] sloja h (h = 1, r, formata (uh +1) × sh) indeks i oznacava onda indeks PE u trenutnom sloju a indeks jprethodnog sloja. Ako se posmatra matrica W (formata (s + r + n + 1) ×(s + r + n + 1)) svih PE X = [xi]i onda je prakticno koristiti podmatrice Wh
namenjene datom sloju h, ali se onda dodatno mora paziti na veze medu PE(koji izlazi se dodeljuju kojim ulazima). Ako se W prikaze na sledeci nacin:
net[h] = Wx[h] =
I1 0 0 · · · 0W1 0 0 · · · 00 I2 0 · · · 00 W2 0 · · · 0...
. . ....
0 · · · 0 Ir 00 · · · 0 Wr 0m
0...0
xh1−1 ≡ 0xh1
xh1+1
...xh2
xh2+1 ≡ 00...0
, Ih = [1, 0, · · · , 0]
gde je s broj PE, r broj slojeva, a podmatrica Wh ona koja se odnosi na sloj h(ulazni sloj u x[h] se posmatra kao nekakav prvi niz vrednosti, zatim slede os-tale izlazne komponente svakog od slojeva redom, sve od izlaznog; vrste Ih susirine kao i Wh, a tu su samo da sacuvaju bias za naredni sloj), onda se vektorulaznih vrednosti x = [x0, x1, · · ·]T (bias x0 = 1) za dati sloj moze prikazatikao x[h] = [0, · · · , 0|xh1 · · · xh2|0, · · · , 0]T gde su h1 i h2 pocetni i krajnji indekssloja h (h2−h1+1 su particije s+r+n+1, pod uslovom da su tako uredeni).Racunanje onda pocinje ulaznim vektorom [x0, · · · , xn, 0, · · · , 0] ∈ Rn i slojem1, tako da izlazi y[h] = [0, · · · , 0|yh1 · · · yh2|0, · · · , 0]T = f(net[h]) = f(Wx[h])postaju ulazi narednog sloja tj. x[2]=y[1], i tako redom do poslednjeg slojay[r] = [0, · · · , 0, y1, · · · , ym]T i vektora izlaza y ∈ Rm (najbolje je da f vrsibar ,,pomeranje” za svaki sloj na odg. pozicije indeksa u y, tacnije za sirinuWh jer se tako onda koristi jedna matrica W za sve slojeve, npr. f(x) =
f0([0h 0E 0 ]x) ...). Ovo je samo jedan od mogucih nacina reprezentacije i al-
goritma racunjanja. Ovakav model racunanja je poznat kao racunanje napred(feedforward) koji se prepoznaje po skoro-dijagonalnoj strukturi matrice W ,ali su moguce i druge varijante. Neki put se koriste povratne veze (feed-

56 Seminarski rad
back, rekurentne NM - ove NM narusavaju prethodno pomenutu dijagonal-nost i cine performanse i ucenje slozenijim) - od krajnjih neurona (izlazaobicno) ka prethodnim (npr. u smislu adaptacije ili nekog posebnog mod-ela toka iteracija racunanja po slojevima - rekurentni ciklus daje rezultatkada dostigne ekvilibrijum tj. postane stabilan) - ovo je formalizam oblikakonacnih automata ([NN-AA], gde se stabilnost uporeduje sa osobinom ne-promenjivosti stanja konacnog automata, vektor pondera je stanje, funkcijaucenja je funkcija promene stanja, itd). Takode, cesto se strukturom NMeksplicitno ili implicitno (zavisno od nacina obuke i toka racunanja) u pro-cesu racunanja stvaraju specijalizovani slojevi ili cak delovi slojeva kojimase postize neki specifican zadatak ili deo resenja problema (npr. ulazni neu-roni vrse nekakvo rasporedivanje slike kao ulaznog signala unutrasnjem slojukoji izdvaja tj. klasifikuje njegove odredene osobine (,,feature selectors”,zaobljenost, vertikalne i horizontalne crte) a onda ih naredni sloj finije klasi-fikuje u odredena slova).
Na kraju, ovako opisana (jedna od najopstijih) klasa NM predstavlja nekuvrstu ,,univerzalnih klasifikatora” ili aproksimatora objektivne funkcijef : Rn → Rm, odakle slede mnoge osobine ali i ogranicenja NM (upotrebomklasicnog aparata matematicke analize ili drugih metoda masinskog ucenja -npr. da bi se odredio potreban broj slojeva i PE, ili potrebna velicina skupaobucavanja i pocetni parametri obuke), i pitanje kada i koje takve funkcijepripadaju NERF klasi (Network Efficiently Representable Functions).
3.4 Obuka i ucenje NM
Brzina ucenja η je jedan od bitnih parametara koji uticu na proces ucenjaNM (srazmeran je globalnom koeficijentu funkcija ucenja tj. utice na velicinekoraka (delti) kojima se menjaju vrednosti u procesu ucenja). Ako je brz-ina premala onda proces moze da traje predugo, a ako je brzina prevelikaonda se moze desiti da u procesu ucenja ne dode do nekih finijih promena i

Soft Computing - racunska inteligencija (Computational Intelligence) 57
eliminacija nepotrebnih osobina (u gradijent metodi globalni optimum mozeprevilikim korakom biti preskocen; mnoge varijante obuke su vidovi gradijent(hill-climbing) pretrazivanja prostora stanja u cilju minimizovanja greske) iliproces moze da postane nestabilan (traze se metode koje koriste i jedno idrugo). Topologija NM je cesto staticna (oznaceni graf tj. veze PE, broj slo-jeva i broj PE po slojevima), cak je pozeljno npr. u matrici nalik W obelezitipondere koji se ne menjaju. Medutim, moguce je da se u procesu obucavanjai topologija menja pored koeficijenata. Zakoni ucenja:
Hebovo pravilo Ako su dva povezana neurona oba aktivna (ekscitovana)onda treba povecati ponder veze izmedu njih
Hopfildovo pravilo Slicno prethodnom - samo se uzima u obzir i kada obaneurona nisu aktivna i tada se smanjuje odg. ponder, a uvecanja ismanjenja pondera se rade srazmerno brzini ucenja
Delta pravilo Najcesce upotrebljavano, gde se ulazni koeficijenti smanjujutako da se smanji razlika trenutnog i zeljenog izlaza. Pravilo menjapondere tako da smanjuje prosecnu kvadriranu greku NM (Least MeanSquare = LMS metod, ili poznato kao Widrow-Hoff pravilo ucenja).Povratno propagiranje (back-propagation) kao ucenje radi tako stoizvod transfer funkcije od delte propagira na prethodni nivo da biizracunao potrebne razlike pondera i tako redom sve do ulaznog nivoa,a proces racunanja vrednosti izlaza na osnovu ulaza (i takav tip mreze)se zove racuanje napred (feedforward). Treba voditi racuna o tomeda skup za obucavanje bude potpuno nasumicno rasporeden, inace semoze desiti da NM nemoze da dostigne zeljenu tacnost.
Pravilo spustanja niz gradijent Gotovo isto kao i prethodno pravilo, uzdodatni koeficijent ucenja koji se mnozi vrednoscu ucenja kojom semenja ponder - ovo se koristi npr. kod NM gde su potebne razlicitebrzine ucenja po razlicitim slojevima NM. Pokazuje se da manja brzinau ulaznim slojevima i veca u izlaznim ubrzava konvergenciju u mnogimslucajevima (ovo je korisno kada npr. ne postoji postoji poseban modelna osnovu koga su formirani ulazi). Optimalna vrednost brzine ucenjaje ηopt = 1/λmax gde je λmax najveca karakteristicna vrednost Hesiana
greske H(w) = [ ∂2E(w)∂wki∂wkj
]ij (primer ocene u [LSC]), 0 < ηk < 2ηopt td.
je wki(t + 1) = wki(t)− ηk∂E
∂wki.

58 Seminarski rad
Kohonenovo pravilo ucenja (Teuvo Kohonen) procesni elementi se takmiceda bi dobili priliku da uce i menjaju svoje koeficijente. Procesni elements najvecim izlazom (,,pobednik”) dobija priliku da inhibira takmace ilida ekscitira susede. Jedino pobednikov izlaz se racuna i jedino pobed-nik i susedi imaju pravo da menjaju svoje koeficijente. Uobicajenoje da je na pocetku definicija susedstva veca, ali da se suzava tokomobuke. Pobednicki element je po definiciji najblizi ulazu pa se kaze daovavke NM modeliraju distribuciju ulaza (sto je dobro za statisticka itopoloska modeliranja) i zovu se zato samoorganizujucim preslikavan-jima ili samoorganizujucim topologijama.
Pravilo kaskadne korelacije Pravilo (Scott Fahlman) gde se pocinje odnekog okvira i minimalne strukture NM, a onda se tokom obuke di-namicki dodaju PE u skrivenim slojevima (ili citavi slojevi) i njihovikoeficijenti se zamrzavaju nakon obuke i postaju stalni detektori os-obina (feature detectors).
3.5 Propagiranje unazad
Klasican algoritam obuke uopstenim delta pravilom i povratnim propagi-ranjem, kao i odgovarajuca struktura NM racunanjem unapred jeste najcescekoriscen i primenjivan oblik NM. Uopsteni zadatak je aproksimacija funkcijeφ : Rn → Rm uz dovoljno dobar skup obuke (training set) S = (x∗k, y∗k)k=1,p gdeje y∗k = φ(x∗k), 1 ≤ k ≤ p i p dovljno veliki broj (kriterijumi za S i p sledekasnije). Tada se za svaki par obucavanja (x∗k, y
∗k) = ([x∗ku]
Tu , [y∗kv]
Tv ) racuna
aproksimacija yk na osnovu xk = x∗k racunanjem unapred. Vazi xku = xkiqi
tj. xku = xkiu prema ranijoj konvenciji zapisa, gde je i indeks proizvoljnjog
ulaznog PE sa odgovarajucim indeksom ulaza qi = u (svi ulazni PE uzi-maju odgovarajuce ulazne vrednosti iz xk), onda po ranijim formulama vazi(zanemareno je vreme, aktivaciona funkcija je identicna funkciji sumiranja):
netki (t) = net([xkij ]T
j, [wk
ij]T
j) =
∑j
wkijx
kij ,
tj. net(wki , xk) = (wk
i )T · xk, ak
i = netki , oki = yki = fki(aki )
Moze se pretpostaviti da je kod wij indeks i polazna PE a indeks j narednaPE u racunanju (W bi mogla biti prakticno kvadranta matrica svih PE uz

Soft Computing - racunska inteligencija (Computational Intelligence) 59
dodatak kolona slobodnih vektora tj. slobodnih koeficijenata po ranije nave-denoj konvenciji, ali se uglavnom racuna samo sloj po sloj, a i vektor xk seonda formira na odgovorajuci nacin, npr. koordinate koje se ne racunaju sujednake nuli). Slicno vazi za izlazne cvorove i izlazne vrednosti yk = [ykj]
Tj :
ykv = okj = ykj = fkj(akj ), gde su j indeksi odgovarajucih izlaznih PE. Skica
algoritma povratne propagacije kod kojeg pocetne vrednosti W nisu posebnobitne bi bila:
1. racuna se izlaz yk na osnovu x∗k iz skupa za obucavanje: yk = f(Wx∗k)
2. uporeduju se vrednosti zadatih izlaza y∗k i dobijenih yk: εkj = y∗kj− ykj,i racuna se greska odnosno funkcija greske:
E = 2p
∑k Ek gde je Ek = 1
2
∑mj=1 εkj
2
3. racuna se funkcija ucenja (koliko treba dodati ili oduzeti svakom koefi-cijenu) na osnovu povratnih veza i delta pravila - odgovor na pitanjekoliko i u kom smeru promeniti (povecati ili smanjiti - da bi se smanjilarazlika ide se u pravcu negativnog gradijenta) koeficijente daje gradi-
jent OEk = [ ∂Ek
∂wjv]j gde vazi ∂Ek
∂wjv= −(y∗kj − ykj)
∂fj
∂netkj
∂netkj∂wjv
i gde su j
indeksi sloja neurona koji se razmatra (pocinje se od izlaznog). Premadefiniciji vazi:
∂netkj∂wjv
= (∂
∂wjv
L∑v=1
wjvxkv) = xkv
− ∂Ek
∂wjv
= (y∗kj − ykj)fj′(netkj )xkv
Ako se definise delta ∆kwjv =def η(y∗kj − ykj)fj′(netkj )xkv = ηδkjxkv,
gde je term greske δkj =def (y∗kj − ykj)fj′(netkj ) = εkjfj
′(netkj ), (η > 0je brzina ucenja) onda je funkcija ucenja u tom koraku definisana sa:
wjv(t + 1) = wjv(t) + ∆kwjv(t) = wjv(t) + ηδkj(t)xkv(t)
Ako je transfer funkcija linearna, onda je fj′ = 1 i tada je
∆kwjv =def η(y∗kj − ykj)xkv

60 Seminarski rad
a ako je funkcija logaritamski sigmoid onda je fj′ = fj(1−fj) = ykj(1−
ykj) i tada je
∆kwjv =def η(y∗kj − ykj)ykj(1− ykj)xkv
4. promeni zadate koeficijente prema prethodnom delta pravilu za sve PEu istom sloju, a onda to ponavljaj za prethodne slojeve redom sve doulaznog uz pretpostavku da je ispravka ulaza trenutnog sloja jednakagresci izlaza prethodnog sloja:
• osnovno pitanje je kako izracunatu gresku distribuirati na odgo-varajuce izlaze prethodnog sloja:
Ek =1
2
m∑j=1
(y∗kj − ykj)2 =
1
2
m∑j=1
(y∗kj − fj(netkj ))2
=
=1
2
m∑j=1
(y∗kj − fj(∑
v
wkjvx
kjv ))
2
• gde se pretpostavlja da je veza izlaza prethodnog sloja v i ulazanarednog sloja j: ykv = xk
j i dalje onda vazi:
∂Ek
∂wvu
=1
2
∑j
∂
∂wvu
(y∗kj − ykj)2 = −
∑j
(y∗kj − ykj)∂fj
∂netku
∂netku∂wvu
∆kwvu = ηfv′(netkv)x
ku
∑j
(y∗kj − ykj)fj′(netkj )wjv
• Dakle, ispravka koeficijenata prethodnog sloja zavisi od termovagresaka narednog sloja:
∆kwvuηfv′(netkv)x
ku
∑j
δkjwjv, δkv = fv′(netkv)
∑j
δkjwjv
wvu(t + 1) = wvu(t) + ηδkvxku
dakle, term greske skrivenog sloja je isti kao i term greske za ulaznisloj. Moze biti koristan i faktor momenta α:
wvu(t + 1) = wvu(t) + ηδkvxku + α∆wvu(t− 1)

Soft Computing - racunska inteligencija (Computational Intelligence) 61
5. ponovi ove korake za sve ostale parove iz skupa obucavanja
6. ponavljaj ove korake sve dok se greska E nad svim parovima iz skupaobucavanje ne svede ispod zadate granice
Izjednacavanje ispravke ulaza narednog sloja i greske izlaza prethodnogje sustina povratnog propagiranja greske. Jedna iteracija kroz ceo skupobucavanja se zove epoha. Opisani model (sa racunanjem unapred, koji nijedinamicki, nema povratnih i lateralnih veza) je primer viseslojnog percep-trona, s tim da se onda obicno koristi sigmoid kao transfer funkcija. Ako seneke dodatne osobine uvedu onda vise nije dovoljno uporediti racunanje NMsa aproksimacijom realne funkcije.
Moglo bi se reci da NM karakterisu: topologija (nacin povezanosti struk-ture, kao kod obelezenog grafa), postupak racunanja izlaza na osnovu ulaza, ipostupak obucavanja. U narednom delu teksta ce biti dato nekoliko poznatihprimera i klasa NM. Racunanje i obuka mogu biti modelirane u klasicnojsekvencijalnoj arhitekturi (npr. kao program na obicnom kucnom racunaru,ili pomocu specijalizovanog okruzenja kakvo npr. nudi MATLAB sa do-datkom za NM), i vec tada mogu biti veoma korisna primena (primera radi,OCR algoritmi dobrim delom tako rade, prepoznavanje govora, neegzaktnaobrada prirodnog jezika i drugo). Takav nacin realizacije je i veoma pogodan

62 Seminarski rad
za simulacije i kao razvojno okruzenje u kojem se isprobavaju razliciti modeli,sto neke specijalizovane programibilne hardverske implementacije jos uvek nenude u takvom obimu (integrisana tehnologija namenjena NM). Ipak, jednaod glavnih snaga NM lezi upravo u mogucnosti visokog stepena paralelizacije(na nivou slojeva npr. u racunanju napred) i realizaciji u analognim VLSIarhitekturama i drugim odgovarajucim paralelnim arhitekturama (hardver-ski recimo SMP, softverski npr. distribuirano procesiranje koje se poklapa sakonekcionizmom u srodnim oblastima gde se proucava mnogostruko povezi-vanje osnovnih elemenata). Ponekad se obuka radi samo simulacijama, aeksploatacija NM (ili ,,recall”) u specijalizovanoj arhitekturi.
3.5.1 Varijante povratnog propagiranja
Varijanta povratnog propagiranja je delta-delta (Delta Bar Delta, RobertJacobs) pravilo, gde svaki ponder ima svoju brzinu ucenja koja se mozemenjati vremenom (trebalo bi da opada, i ponasa se heuristicki - ocekivanagreska utice na kasniju obuku) - raste linearno inkrementalno kada greska nemenja znak, opada geomteriski ako greska cesto menja znak, greska ne uticedirektno (ne ide se najstrmijim spustom niz gradijent), a koristi se i procenazakrivljenja povrsine greske (vece promene kod vecih zakrivljenja).
Postoji i prosireno delta-delta pravilo (Ali Minai, Ron Williams) gdese koristi i faktor momenta (trenutna delta zavisi od prethodne - promenesu glatkije i manje je oscilacija), kao i eksponencijalnog usporavanja rasta.Takode, pamte se greske i koeficijenti svake epohe ako su bolji od prethodneda bi se kasnije vratile (stohasticki) ako se prede prag tolerancije.
Usmerena slucajna pretraga uopste ne koristi gradijent vec nasumicemenja koeficijente, pamti smer promene slicno prethodnim varijantama, aline koristi povratno propagiranu gresku - samo izlaznu. Metoda je zatodosta brza, dobro radi s manjim brojem neurona, ali mnogo vise zavisi odrazumevanja problema tj. od pocetne konfiguracije koeficijenata. Kao u pre-trazi po dubini pamti se najbolja nadena konfiguracija i greska, a koristese i usmerene komponente (slicno momentima) koje se dodaju svakoj na-sumicnoj promeni, kao i samo-podesavajuce varijanse koje uticu na velicinekoraka izmene.
NM viseg reda ili funkcionalno povezane NM (Yoh-Han Pao) predstavl-jaju prosirenja prethodnih metoda gde se samo dodaju novi ulazi kao termovialgebarskih kombinacija ulaza. Formiraju se najpre proizvodi kombinacija(drugog reda, treceg reda, itd.) ulaza, zatim se na njih dodatno primenjuju

Soft Computing - racunska inteligencija (Computational Intelligence) 63
neke funkcije (sin, cos, min, max).
Postoje tri osnovne preporuke (,,preko palca”) u projektovanju ove klasemreza:
1. kako raste kompleksnost odnosa ulaza i izlaza, tako povecavati brojneurona u skrivenim slojevima. Rumelhart predlaze da neuroni koji nemenjaju koeficijente bitno u toku obuke mogu da ne ucustvuju dalje ilida budu cak izbaceni pod nekim uslovima.
2. ako se proces kojim se resava problem i koji se modelira neuronskommrezom moze podeliti u vise razlicitih faza, onda treba povecati brojskrivenih slojeva (inace dodatni slojevi ne predstavljaju dobro uopstenjeresenja vec redundansu u pamcenju)
3. broj elemenata skupa obucavanja predstavlja gornju granicu broja neu-rona u skrivenim slojevima (veoma je vazno da broj ne bude prevelikijer se time dobija NM koja ,,znadobro skup obucavanja ali nema dobrugeneralizaciju proizvoljnog ulaza) - preporuka je da se broj elemenataskupa obucavanja podeli sa zbirom dimenzija ulaza i izlaza n + m ionda podeli sa faktorom koji varira od 2 do 10 za relativno cist skupobucavanja, pa sve do 50 za skup u kome je prisutno dosta gresaka (summoze pozitivno da utice na konvergenciju) u podacima. Ako ulazi pri-padaju razlicitim klasama, treba ih nasumice birati jer NM tezi ,,dazaboravi”prethodne (generalizacija je sposobnost prepoznavanja ulazau istoj klasi).
Inicijalne vrednosti se mogu nasumice birati (±0.5) kao i bias, dok η trebada bude relativno mala (0.05 do 0.25).
3.5.2 Perceptron
Minski i Papert su konceptualizovali percpetron predikatski (za razlikuod Rozenblata koji to cini u terminima verovatnoce). Tada je izlaz Ψ =1 akko
∑i αϕnϕn > θ za neki prag θ gde su φi najjednostavniji predikati
oblika φi = 1 akko je tacka na retini (ulaznom senzoru) ukljucena, a αi suodg. tezinski koeficijenti. Binarni perceptron y(x) = f(w · x + w0) korististepenastu funkciju kao transfer funkciju (linearni perceptron - ako korstilinearnu, inace se podrazumeva logaritamski sigmoid). Kako je pomenuto,

64 Seminarski rad
takva struktura nemoze da radi kao XOR kapija jer nemoze da klasifikujetakve ulaze - to se resava dodavanjem jednog skrivenog sloja sa 2 neurona, ito je onda primer viseslojnog perceptrona. Priroda binarnog perceptrona jeda n-dimenzioni ulaz klasifikuje u dve klase u Rn koje razdvaja jedna n− 1-dimenziona hiperravan odredena sa w · x + w0 = 0 (w su koeficijenti PE), itada se mogu parovi obucavanja (x∗, y∗), x∗ ∈ Rn, y∗ ∈ 0, 1 mogu svrstatiu 3 kategorije - uspesne (poklapaju se y = y(x∗) i y∗), promasene iznad T+
w
(ne poklapaju se i y = 1) i promasene ispod T−w (ne poklapaju se i y = 0).
Tada je pravio ucenja ojacavanjem (reinforcement):
w(t + 1) =
w(t), poklapaju se;w(t) + ε(t)x, x ∈ T+
w ;w(t)− ε(t)x, x ∈ T−
w .
za neko ε > 0. Ovo pravilo ucenja generalizovano znaci da ne postoji skupobucavanja vec se povremeno vrse korekcije u interakciji sa okolinom. Prob-lem moze nastati ako NM zaboravi polako prethodno nauceno na taj nacin- cilj je naci strategiju tako da se greska odnosno procena ocekivane greskesmanjuje svakom korekcijom. Jos opstije, za Markovljev proces (zadat slicnokonacnim automatima: stanjima, distribucijom ulaznih vrednosti po stan-jima (obzervacija, senzacija), distribucijom cene po stanju i distribucijomprelaska po stanju i ulazu), cilj je pronaci Markovljev lanac najmanje cene.Dve teoreme se mogu naci u [NN-AA] koje pokazuju dve osobine ovakvogobucavanja kod Perceptrona - da konvergira ako postoji resenje, i kriteri-jum konvergencije (ako su klase separabilne (n−1)-dimenzionom hiperravni,uz dodatne uslove za brzinu ucenja gde npr. tu spadaju pored konstanti iε(t) = 1/t ili ε(t) = t).
3.5.3 (M)ADALINE
Ova vrsta NM spada u klasu mreza namenjenih obradi vremenski uzorko-vanog signala (medu novije vrste spadaju npr. mreze recirkulacije - Ge-offrey Hinton, James McCLelland). Iako su (M)ADALINE mreze istori-jski medu najstarijim, njihova primena postoji i danas (uklanjanje ehoaiz telefonskih linija tako realizovanim adaptivnim filterom (hibridom) se idanas koristi, realizacija savremenih modema, itd). ADAptive LInear NEu-ron (standardna funkcija sumiranja je ALC - Adaptive Linear Combiner)je iste strukture kao i perceptron sa linearnom simetricnom transfer funkci-jom. Ako je x(t) niz impulsa uzorkovanih tokom jednakih vremenskih raz-

Soft Computing - racunska inteligencija (Computational Intelligence) 65
maka (odmeraka), filter se moze zadati svojim odgovorom (tehnika prozora)h(t) = R(t, δ(t)), δ(t) = 1 za t = 0 inace 0, i racunati konvolucijomy(t) = R(t, x(t)) =
∑∞i=−∞ h(i)x(t + i) (pored Furijeove transformacije i
drugih DSP tehnika). Transverzni filter uzima n − 1 prethodnih i trenutniuzorak - upotebom aktivacione funkcije kasnjenja (delay: a(t + 1) = net(t))se moze realizovati ADALINE struktura ciji su ulazni vektori x(t) kojim serealizuje takav filter (moze se koristiti i za predvidanje vrednosti tj. uzorka).Obucavanje ADALINE se vrsi slicno delta pravilu (w(t+1) = w(t)+ 2µεkxk
za εk = y∗k − yk i brzinu ucenja µ - ako je R = [xk · · · xk]T matrica korelacije
ulaza a λmax njena najveca karakteristicna vrednost, onda bi trebalo da bude0 < µ < 1/λmax).
Many ADALINE (MADALINE) - viseslojni ADALINE, moze se obucavatii pravilom MRII najmanjeg poremecaja (least disturbance) gde se greskaracuna kao broj pogresnih izlaza - biraju dva PE sa najmanjom aktivacijom(realnom sumom) i menja se ponder tako da se promeni bipolarna vrednost iprihvata promena ako je greska smanjena nakon racunanja, a onda se ponovipostupa za par takvih povezanih PE. Ispod se nalazi ilustracija NM kojaprepoznaje 4 razlicite kategorije - u 5× 5 senzora se nalazi ulazni sloj, zatimslede 4 skrivena sloja (zapravo jedan u 4 grupe) cije izlaze ,,skuplja”jedanADALINE (koji predstavljaju izlazni sloj sa 4 PE, sto daje 16 kombinacijaodnosno kategorija kojih ovakva NM moze da klasifikuje).

66 Seminarski rad
3.6 Vrste NM i oblasti primene
Nacelne kategorije primena NM su:
• predvidanje (nije obavezno isto sto i ekstrapolacija): povratno propagi-ranje, delta-delta, usmerena slucajna pretraga, samoorganizujuca pres-likavanja u povratno propagiranje
• klasifikacija: kvantizacija vektora sa ucenjem, protiv-propagacione NM,verovatnosne NM
• asociranje podataka (slicno klasifikaciji, ali dodatno detektuje greskuu ulaznim podacima): Hopfildove memorije, BAM, Hemingove mreze,prostorno-vremensko prepoznavanje, Bolcmanova masina
• konceptualizacija podataka (analiza ulaznih podataka koja daje relacijemedu njima): ART, samoorganizujuce mape
• filteri, kompresija podataka (npr. kao u digitalnoj obradi signala):(M)ADALINE, recirkulacija
3.7 NM takmicenja, klasifikacije i druge
Navedene klase NM se manje ili vise razlikuju od NM sa povratnim propa-giranjem, mnoge predstavljaju pojednostavljenu varijantu odgovarajuceg re-kurentnog dinamickog modela (za stanje u ekvilibrijumu takvog sistemazadatog diferencijalnim jednacinama). Moguce su, naravno, i razlicite hi-bridne vrste. Najpoznatija klasa neuronskih mreza takmicenja su one satransfer funkcijom takmicenja i pomenutim Kohonenovim pravilom ucenja,kao i samoorganizujuca preslikavanja (mape, Feature Map Classifier - FMC)- varijacije takvih mreza nazivamo mrezama takmicenja ili kompetitivnim.Samoorganizujuce mape traze PE i pobednika ciji je vektor pondera najbliziulaznom vektoru ||x−wi|| = minj ||x− wj|| koji onda dobija pravo da menjasvoje koeficijente tokom ucenja i da potpuno inhibira ostale.
Racunanje se radi na uopsteniji nacin jer se dopustaju inhibitorne later-alne veze (zij moze uticati na sve u sloju ili dalje, ili samo na geometrijskookruzenje) i term gubitka r(yi(t)):
yi(t + ∆t) = yi(t)− (r(yi(t)) + neti +∑
j
zijyj(t))∆t

Soft Computing - racunska inteligencija (Computational Intelligence) 67
gde je neti =∑
j wijxj. Lateralna inhibicija moze biti jednostavnija negotrazenje najveceg izlaza. Pravilo ucenja je oblika wi(t + 1) = α(t)(x −wi(t))U(yi) (wi = [wij]j je vektor koeficijenata za i-ti PE, U je oblik ste-penaste funkcije td. je U(yi) = 1 za yi > 0, inace je U(yi) = 0). Obicno se neobucava samo pobednik vec njegovo okruzenje NC (susedstvo koje se definisekao neka geometrijska okolina - kako Kohonen napominje, ova geometrijskaosobina nedostaje drugim NM) i onda je wi(t + 1) = wi(t) + α(t)(x− wi(t))za i ∈ NC , inac je wi(t + 1) = 0.
3.7.1 Kvantizacija vektora sa ucenjem
Primer je hibridna varijanta povratnog propagiranja i Kohonenove NM(Tuevo Kohonen) - kvantizacija vektora sa ucenjem (Learning Vector Quan-tization). Pored ulaznog sloja, koristi se jedan Kohonenov (gde PE koji jenajblizi ulazu se proglasava pobednikom i jedino njegovom ulazu se dozvol-java okidanje i kasnija promena koeficijenata prema ispravnosti klasifikacije)skriveni sloj i jedan izlazni (u izlaznom sloju je onoliko PE koliko bi trebaloda bude klasa). Kohonenov sloj je grupisan prema klasama (broj PE posvakoj klasi moze biti razlicit zavisno od problema). Desava se da neki PEsuvise cesto pobeduje a neki suprotno, i zato se uvodi mehanizam svesnosti- ako cesto pobeduje dobija ,,krivicu”i biva inhibiran. Meri se frekvencijapobedivanja svakog PE kao i prosecna frekvencija, i onda se dodaje biasproporcionalan razlici (koji se vremenom smanjuje kako ucenje napreduje).Takode, koristi se i mehanizam ogranicenja (boundary adjustment algorithm)kada je greska dovoljno mala, kada pobednik nije u dobroj klasi, kada je prvisledeci u dobroj klasi a vektor obucavanja izmedu - pobednik se udaljava odulaza, a drugi priblizava. U ranim fazama ucenja se ,,odbijanje” iskljucuje(ako pobednik nije u dobroj klasi).

68 Seminarski rad
3.7.2 Protiv-propagaciona NM (Counter-propagation)
Postoje slicnosti sa prethodnom strukturom, ali se ovde koristi izlaz donekleravnopravno u toku obuke kao i ulaz. Dodatni sloj koji normalizuje ulaz (sloj1 - tako da bude zbir ulaza uvek jednak, npr. 1 - da bi se izbegla osobina Ko-honenovog sloja da preveliki (po normi) vektori nadjacavaju slabije). SvakiPE ulaznog kompetitivnog sloja 2 zajedno sa svim ulazima cini ulaznu zvezdu(instar), a zajedno sa svim vezama ka PE u izlaznom sloju 3 cini izlaznuzvezdu (Grossberg outstar); transfer je stepenast. Obucava se vidom deltapravila (pod wi se podrazumeva vektor koeficijenata krace zapisano): kaoulazna zvezda i sa vektorom ulaza x ima ∆wi = α(x − wi), a kao izlaznazvezda za ∆wi = β(yi − wi) za i-ti PE, s tim da kao izlazna zvezda (pobed-nik) ima u yi uracunate i ulaze vektora y u toku obuke. U toku eksploatacijeje y = 0 (0 < α, β < 1). Postoje problemi kod ulaza koje skriveni sloj tretiraposebno iako su u istoj klasi (onda se se nekako uslovljava samo za odredeneklase). Metodu je razvio Robert Hecht-Nielsen.
3.7.3 Adaptivno-rezonantna teorija (ART)
Ove mreze predstavljaju vid prosirenja kompetitivnih mreza kao sto suto protiv-propagaciona i druge kompeticione mreze. Nastale su kao posledicanekih bioloskih modela, Stiven Grosberg 70-tih daje taj model podstaknutdilemom plasticnosti i stabilnosti koja se ogleda u pitanju kada NM treba dauci (bude plasticna) a kada da ostane stabilna kod nebitnog ulaza. Resenjeje bilo u povratnim vezama izmedu ulaznog sloja i kompetitivnog. ARTprepoznaje ulaz i brze dolazi do rezonantnog (stabilnog) stanja ako je ulazvec naucen ili dodatno potvrden ili dolazi do odbacivanja (reseta) - ucenjenastupa tek nakon stabilnog stanja (ekvilibrijuma). Postoje dve varijante:ART1 gde su ulazi binarni (iz 0, 1) i ART2 gde mogu biti realne velicine.

Soft Computing - racunska inteligencija (Computational Intelligence) 69
Sustina ART strukture je:
• ulazni sloj F1 koji je povezan sa F2 po principu svaki sa svakim uzspecijalne pozitivne pondere A1, max(D1, 1) < B1 < 1 + D1, C1, D1 injima odredenu sumarnu funkciju neti - svaki PE ima samo jednu odg.ulaznu vrednost Ii kao i ulaze iz F2 i G, a izlaz se racuna obicnomstepenastom funkcijom (prelaz u nuli) uz pravilo 2/3 (dodatnim koefi-cijentima): svaki PE u mora da ima bar 2 tipa izvora od 3: I, F2 (tj. Vi
kao klasicna sumarna funkcija), G (ovo omogucava dva stanja F1 sloja- subliminalni, kada je u ,,rezononaci” I sa F2 i supraliminalni, kadaje F2 neaktivan ali postoji ulaz) koje obezbeduje stabilnost.
• kompetitivni sloj F2 se racuna sa ulazima iz F1 simetricno prethodnom,s tim da nema ulaze, ima ulaz iz A, a izlazi ka F1 su izracunati kompet-itivnom transfer funkcijom (izlaz samo jedne jedinice cija je sumarnafunkcija netj jednaka maksimumu svih sumarnih funkcija u sloju, os-tale su 0), dok su izlazi ka svim PE u F2 izracunati takode stepenastomfunkcijom (dva izlaza se mogu dobiti kombinacijom sa po dva dodatnaspecijalna PE da bi se prevazislo ogranicenje definicije osnovnog PE).
• jedinica pojacanja G radi po principu da je ekscitovana samo ako je F2neaktivan i ima nekog ulaza (|I| = ∑
f(Ii) > 0), tj. F2 ga inhibira
• jedinica A - prethodni PE cine sistem paznje, dok orjentacioni sistemcini PE A i zaduzen je za koordiniranje neslaganja slojeva F1 i F2 -ulazi su mu u vezani za F1: ako su P i Q ponderi, A se okida ako jeP |I| − Q|S| > 0 tj. |S|/|I| < p, 0 < p < 1 (p = P/Q ≤ 1 parametarvigilance) i tada se desava reset : pobednicki izlaz iz F2 se anulira kaoi ostali izlazi u F2, inace je rezonanca dostignuta (ulazi su prepoznati)i primenjuju se asimptotska pravila promene pondera
Izlazi PE se nazivaju kratkotrajnom memorijom (Short Term Memory, STM),a ponderi dugotrajnom memorijom (LTM). Koeficijenti wij od F2 ka F1 (Top-Down LTM Traces) se racunaju za indeks j sloja F2 i j sloja F1 po principu:
wij =
−wij + 1, netj i neti aktivni;−wij, netj aktivan i neti neaktivan;0, oba neaktivna.
inicijalno wij(0) >B1 − 1
D1
Asimptotske vrednosti (u ekvilibrijumu, ako je I pobuden dovoljno dugoi ako su pocetne vrednosti dovoljno velike - postoji kriterijum) pondera

70 Seminarski rad
su 1 za sve povezane sa pobednikom, 0 ostali. Obrnuto, od F1 ka F2:wji = Koj[(1 − wji)Lf(neti) − wji
∑k 6=i f(netk)], 0 < wji(0) < L
L−1+M(M
broj PE u F1, L > 1), gde je oj kompeticioni izlaz j-tog PE, f stepenastafunkcija sloja F1, net ulazna sumarna funkcija, a K i L > 1 konstante kojeuticu na brzinu ucenja (opet se favorizuje pobednicki PE, postoji asimptotskirezim ubrzanog ucenja gde je wji = 0 kada je neti neaktivan, L
L−1+|S| inace,
|S| =∑
f(neti)). Eksploatacija pocinje racunanjem izlaza yi = f(neti) F1na osnovu ulaza i neti = Ii
1+A1(Ii+B1)+C1, zatim propagacija od F1 ka F2 i
racunanje izlaza F2, zatim racunanje opet F1 sa neti = Ii+D1Vi−B1
1+A1(Ii+D1Vi)+C1, i
onda na osnovu novih izlaza iz F1 i testiranjem A dolazi ili do reseta (odbaci-vanja ulaza) i novog ciklusa ili do rezonovanja (prepoznavanja ulaza i ucenja- promene pondera). ART2 je samo donekle slicna ART1 ali zahteva nestoslozeniji mehanizam racunanja - detalji u [NNALG]. Zamerka ART NM jeosetljivost na greske u ulazima.
3.7.4 Stohasticke (verovatnosne) NM
Ucenjem sa nadgledanjem ove NM za dati skup obucavanja razvijajufunkcije distribucije (uz upotrebu statistickih metoda u cemu su bliske meto-dama masinskog ucenja - Bajesovih klasifikatora, Parcenovog prozora - ParzenEstimator: p(x) = 1
N
∑Ni=1 W (x)(x− xi) za neko jezgro W (npr. ocekivana
Gausova kriva) kojim se distribucija slucajne promenljive procenjuje), upotre-bljava se softmaks transfer funkcija za sloj gde ima PE koliko i kategorija

Soft Computing - racunska inteligencija (Computational Intelligence) 71
koje se klasifikuju. U eksploataciji se onda ovim funkcijama procenjujeverovatnoca da ulaz pripada nekoj od klasa. Veelenturf daje model samoorga-nizujucih mapa koje koriste Bajesov princip i distribucije slucajnih promenljivih,[NN-AA].
3.8 (Neo)kognitron
Posavsi od ideje funkcionisanja cula vida i nadredenih nervnih strukturaautori ove vrste NM (Fukushima, Hubel, Weisel, prvobitni kognitron datirajos od sredine 70-tih) su dosli do strukture masivnih visenivoovskih hijer-arhija grupa slojeva. Sustina je podela slojeva u dva tipa: grupe S-slojeva(jednostavne, simple) i C-slojeva (kompleksne, complex) gde su veze od ulazaili C-slojeva ka S-slojevima mnogostruke (po jedna veza u C-sloju za svaki S-sloj u prethodnoj grupi) ali vezane za isti polozaj (geometrijski), dok veze odS-slojeva ka C-slojevima nisu mnogostruke ([NNALG]: najvisi PE naziva se,,baka”(grandmother) samo zbog analogije u vezi sa bioloskom kognitivnompretpostavkom o postojanju nervne celije u ovakvoj hijerarhiji negde u mozgukoja se okida kada takva struktura prepozna baku). Nacin racunanja i obukeje specifican i tice se citavih slojeva (uz upotrebu varijante delta pravila). Ko-riste se posebno i lateralna inhibicija i elementi nenadgledanog obucavanja.
3.9 Asocijaciranje podataka
3.9.1 Asocijativne memorije, BAM
Istorijski, bi-direkcione asocijativne memorije (Bart Kosko) su nastale kaouopstenje Hopfildovih memorija - uvodni pojmovi:

72 Seminarski rad
Definicija 3.1 Ako je Hn = x = (x1, · · · , xn) ∈ Rn| xi = ±1 Hemingovakocka (Hamming), Hemingovo rastojanje h(x, y) za x, y ∈ Hn je 1
2
∑ni=1 |xi − yi|
(broj xi i yi koordinata koje se razlikuju).
Veza izmedu euklidskog rastojanja d i h je d = 2√
h. Ako je S = (x1, y1), · · · , (xL, yL)| xi ∈Rn, yi ∈ Rm (egzemplari - primeri ispravnog asociranja), onda se definisutri vrste asocijativnih memorija (linearni asocijatori):
1. Heteroasocijativna memorija - predstavlja preslikavanje kod kogavazi Φ(x) = yi akko je x po h najblize xi u odnosu na S.
2. Interpolaciona asocijativna memorija - predstavlja presikavanja Φza koje vazi (∀(xi, yi) ∈ S)Φ(xi) = yi, i vazi da ako je x = xi +d, d 6= 0(xi iz S) onda postoji neko e 6= 0 td. je Φ(x) = y + e.
3. Autoasocijativna memorija - uz pretpostavku xi = yi predstavljapreslikavanje kod koga vazi Φ(x) = xi akko je x po h najblize xi uodnosu na S.
Matematicki nije tesko konstruisati ovakva preslikavanja - npr. ako je xiortonormiran skup
xi · xj = δij =
0, i 6= j;1, i = j.
onda je to Φ(x) = (y1x1T +· · ·+yLxL
T )x = Wx (po definiciji). Ovo je ujednoi definicija bidirekcionih asocijativnih memorija (BAM) - ako se koriste xi
umesto yi onda je BAM autoasocijativna (onda je W simetricna): preslika-vanje nety = Wx i netx = W T y i x(t + 1) = f(x(t)), y(t + 1) = f(y(t))(transfer funkcija kao simetricna linearna sa zasicenjem) cine BAM. Vektorx je ulazni, y izlazni, i veze su dvosmerne - koeficijenti su vezani za PE u obasmera. BAM ima lepu osobinu da su koeficijenti odredeni u potpunosti akopostoji S sa L ortogonalnih elemenata i to je onda obuka u jednom prolazukroz skup obucavanja.
Racunanje BAM (recall) se radi na sledeci nacin:
1. prenesi (x0, y0) na PE oba sloja2. propagiraj vrednosti x sloja na sloj y i tamo promeni koeficijente3. propagiraj nazad vrednosti iz sloja y na sloj x i tu promeni koeficijente
kao i prethodnom slucaju

Soft Computing - racunska inteligencija (Computational Intelligence) 73
4. ponavljaj prethodne korake sve dok ne dode ni do jedne promenekoeficijenata oba sloja
Dva nedostatka BAM: ako se preoptereti brojem egzemplara (negde do15% broja PE kod Hopfildove NM) moze se desiti da se stabilizuje u vred-nostima koje nisu ocekivane (crosstalk), kao i ako su egzemplari previse slicni.
Ako je E(x, y) = yT Wx BAM funkcija energije (funkcija Ljapunova uteoriji dinamickih sistema, vezana za kriterijum stabilnosti), moze se dokazatiteorema (iz tri dela):
Teorema 21. svaka promena vektora x ili y ima za posledicu smanjenje E2. E je ogranicena odozdo sa Emin = −∑
ij wij
3. kada se E menja, menja se za konacnu vrednost
Ova teorema opisuje E kao funkciju Ljapunova (ogranicena funkcija param-etara dinamickog sistema) sto garantuje stabilnost BAM (jos jedna lepa os-obina, dokaz u [NNALG]).
3.9.2 Hofildove memorije
Ako se iskoristi prethodno opisana struktura autoasocijativne BAM, dvasloja x se mogu prikazati kao jedan sa rekurentnim vezama:

74 Seminarski rad
Jedina bitna razlika struktura BAM i Hopfildovih memorija je ulazni slojI i diskretna transfer funkcija (skoro stepenasta), za i-ti PE:
net = Wx + I, x(t + 1) =
−1, x < Ui;x(t), x = Ui;1, x > Ui.
, gde je Ui prag okidanja.
Hopfild je originalno koristio binarne vektore v sa vi ∈ 0, 1 umestonavedenih bipolarnih xi ∈ −1, 1 - matrica W =
∑i (2vi − 1)(2vi − 1)T se
ne menja ovim, a funkcija energije postaje (polovina BAM - polovina brojaPE):
E =1
2
∑i
∑
j, j 6=i
viwijvj −∑
i
Iivi +∑
i
Uivi
Ovo je diskretna Hopfildova memorija. Hopfildova memorija je neprekidnaako su izlazi neprekidne funkcije ulaza (racunanje je donekle drugacije) -inace je diskretna. Izlaz PE neprekidne Hopfildove memorije je:
vi = g(λui) =1
2(1 + tanh (λui))
gde je ui ukupni ulaz neti a λ konstanta jacine (gain). Ako λ → ∞ ondaneprekidni model postaje diskretan - stabilne tacke nisu prelaze u temenaHemingove kocke (ako λ → 0 onda stabilne tacke prelaze u jednu singularnu).Broj PE bi trebalo da bude jednak broju ulaza. Hopfildove i srodne NM suklasicni primeri rekurentnih mreza. Jedna od uspesnih primena Hopfildovihmemorija je resavanje problema putujeceg trgovca.

Soft Computing - racunska inteligencija (Computational Intelligence) 75
3.9.3 Hemingova mreza
Ovu klasu NM je sredinom 80-tih smislio Ricard Lipman kao prosirenjeHopfildovih mreza u kojem se bipolarni ulaz klasifikuje na osnovu najmanjegreske po Hemingovoj metrici 1
2
∑mi=1 |xi − yi| = m/2−1
2
∑mi=1 xiyi za [−1, 1]m.
Obucavanje se vrsi skupom ulaza i izlaza (klasa), gde je broj PE u skrivenomsloju (za kategorije) isti kao i broj PE u izlaznom sloju kojih ima koliko i klasa(kategorija), odnosno kao i broj egzemplara (vektora duzine broja ulaza) - zarazliku od Hopfildovih mreza gde je broj PE u skrivenom sloju jednak brojuulaza. Ako je n broj kategorija (egzemplara y∗), ulaza ima m, f pozitivnalinearna transfer funkcija i 0 < ε < 1/n onda za ulazni sloj (t = 0) vaziyi(0) = neti(0) + m/2 gde su wij(0) = yi∗
j , a za izlazni (kompetitivan) slojvazi:
wij(t) =
1, i = j;−ε, i 6= j.
tj. za t > 0 je onda
yi(t) = f(neti(t)) = f [yi(t− 1)− ε∑
j 6=i
wijyj(t− 1)]
- nakon nekog broja iteracija tako pobeduje izlaz kategorije sa najvecim izla-zom ulaznog sloja.

76 Seminarski rad
3.9.4 Bolcmanova masina
Ovo je donekle model slican Hopfildovim memorijama (isto se definiseenergija stanja koja se minimizuje) - razliku cini upotreba metode simulira-nog ocvrscavanja (simulated annealing, Ackley, Hinton, Sejnowski, 1985) prieksploataciji u odnosu na iteracije Hopfildovih memorija, a koristi i posebanmetod obucavanja. Povecana temperatura dodaje sum svim PE na pocetkuobucavanja, a do kraja procesa ocvrscavanja (po rasporedu) bi trebalo dadostigne nulu (slicno odgovarajucim termodinamickim procesima). Posma-tra se promena energije stanja i-te PE izmedu izlaza 0 i 1 ∆i = neti (posledicadefinicije). Algoritam racunanja bi bio:
1. postavi izlaze ulaznih PE na ulazni vektor x
2. postavi izlaze skrivenog sloja na slucajno odabrane binarne vrednosti
3. slucajno odabranoj PE i postavi izlaz na 1 verovatnocom p = 11−e−neti/T
4. ponavljaju se prethodna dva koraka odreden broj puta (recimo da svePE imaju istu verovatnocu promene izlaza) i to je procesni krug
5. ponavlja se prethodni korak dok se ne dostigne termalni ekvilibrijum(ili pretpostavljeni broj koraka)
6. smanjuje se temperatura T po rasporedu (schedule) koji se odredujeproizvoljno, idealno Tt = T0
1+t.

Soft Computing - racunska inteligencija (Computational Intelligence) 77
Ako se posmatraju distribucije pondera vidljivog sloja (ulaza i izlaza)p+(v) preko skupa obucavanja i skupa istih nakon svake eksploatacije p−(v),ispostavlja se da je njihovo rastojanje (Kullback-Leibler):
G =∑
v p+(v) ln p+(v)p−(v)
i ∂G∂wij
= − 1T[p+
ij − p−ij]
gde su p+ij i p−ij verovatnoce da su PE i i j obe ukljucene u pozitivnoj i neg-
ativnoj fazi redom. Pozitivna faza obucavanja je kada su vidljivi PE fiksiranivektorima iz skupa obucavanja (clamped), inace je negativna. Obucavanje sevrsi smenjivanjem pozitivnih i negativnih faza (uz racunanje parametara uKonvergencija je bolja nego kod Hopfildovih memorija (bolje pronalazi glob-alni minimum), ali je ogranicenje broja egzemplara u odnosu na broj PEisto, a proces racunanja i obucavanja prilicno slozen (racunski skup - detaljiu [NNALG]).
3.9.5 Prostorno-vremensko prepoznavanje
Na osnovu nekih Grosbergovih modela (Spatio-Temporal Pattern Recog-nition) iz 70-tih Robert Hekt-Nilsen razvija ovu klasu NM koju naziva ,,lav-ina”(Avalanche), koja je specijalizovana za probleme prepoznavanja vre-menskih sekvenci (koje se ponavljaju, pogotovu, recimo audio signala - nizuzoraka moze imati i ,,prostornu” dimenziju ako se posmatra npr. po

78 Seminarski rad
frekventnim kanalima kao niz koji se menja vremenom) i njihovog klasi-fikovanja. Na primer, skup obucavanja je skup nizova frekvencija u vre-menu za svaku rec koja se prepoznaje - ako se posmatra struktura mrezekoja prepoznaje jednu rec, onda ulaza ima koliko i frekventnih kanala aPE koliko i vremenskih sekvenci - svaki izlaz je povezan sa svim nared-nim PE po vremenskom rasporedu. Ulaz se normalizuje i struktura se mozeuporediti sa protiv-povratnim NM ako se izuzme vremenska dimenzija. Glob-alni bias term Γ se dodaje svakom PE, koji postavlja promenljivi prag oki-danja protiv koga se takmice i koji obezbeduje da najbolje poredenje pobedi.Obucavanje je varijanta Kohonenovog (Kosko-Klopf: koeficijenti ulaza seobucavaju kompetitivno, a medu PE wij = (−cwij + dxixj)U(xi)U(−xj)gde je U stepenasta funkcija, wii = 0) uz funkciju A(x) koja se menja vre-menom (funkciju napada, ,,attack function”, za 0 < c < 1 je A(x) = cxako je x < 0, inace A(x) = x), koja se koristi i u toku eksploatacije. Akoje neti =
∑k qikxk + d
∑i−1j=1 yj (d je koeficijent jacine), f pozitivna lin-
earna transfer funkcija, izlazi se onda definisu diferencijalnim jednacinamayi = A(−ayi + bf(neti−Γ)). Vrednost se aproksimira onda npr. racunanjemyi(t + ∆t) = yi(t) + yi∆t.

Soft Computing - racunska inteligencija (Computational Intelligence) 79
4 Genetski algoritmi
4.1 Uvod
Profesor Dzon Holand tokom 1960-tih pa sve do 1975. proucava saucenicima (De Dzong) i predlaze zanimljivu klasu modela racunanja kojeje nazvao ,,Genetski Algoritmi”(GA), koji koriste ideju bioloskih evolucionihprocesa za resavanje problema iz sirokog domena. Ideja se javljala i ranije,Rechenberg (Evolutionsstrategie 1965-1972) je npr. razvio metod optimizacijeaerodinamickih modela. Skica algoritma kojim se ovo realizuje se zove ikanonski GA (canonical genetic algorithm) i klasa algoritama koji predstavl-jaju varijacije kanonskog GA daje definiciju GA u uzem smislu. U siremsmislu, GA (evoluciono racunanje, evolutional computing) je bilo koji algo-ritam koji koristi operatore odabiranja i rekombinacije da bi generisao noveuzorke prostora pretrage baziranog na modelu populacije (ovi termini ce daljeu tekstu biti razjasnjeni).
4.2 Kodiranje i problemi optimizacije
Dve osnovne komponente GA zavise od problema koji se reava - kodi-ranje ulaznih parametara u neku internu reprezentaciju (najcesce se ko-riste nizovi bitova ili karaktera) i funkcija evaluacije stanja u prostoru pre-trage (ili objektivna funkcija, tradicionalno to moze biti npr. neka funkcijaf(x1, · · · , xn) ciji se optimum trazi). Kodirani ulazni parametri mogu unetinepotrebnu redundansu (npr. ako ulazni parametar ima vrednosti od 0-799 ikoristi se 10 bita za internu reprezentaciju, onda ostaje 224 internih vrednosti,,neiskorisceno” - resenje mozda moze biti da i one iskoriste redundantno ilida predstavljaju ,,lose” elemente) i uticu kasnije na samu strukturu ali iperformanse sistema. S druge strane, funkcija evaluacije zbog prirode prob-lema moze biti zadata samo nekom aproksimacijom i moze veoma da uticena performanse sistema.
Sam prostor pretrage, prostor resenja i problem uticu na efikasnost algo-ritma pretrage. Uopste, velicina prostora pretrage zavisi od kodiranja ulaznihparametara i moze se primera radi predstaviti brojem bitova l (zajedno sapretpostavkom o nezavisnosti parametara), i tada je velicina reda 2l - rec-imo da problemi pocinju negde za l > 30, a u realnosti je to cesto dalekovece. Primer: ocena prostora pretrage u sahu je 2400 (ako je prosecan broj

80 Seminarski rad
mogucih poteza u svakom koraku 16 i 100 ukupan broj poteza prosecne par-tije) - kada bi svaki atom univerzuma od njegovog nastanka do danas racunaopotez po pikosekundi bili bi tek na pocetku (Winston P, 1992). Recimo daako broj resenja nije gust u prostoru pretrage onda nema smisla koristitimetod grube sile, pogotovu ako je prostor pretrage veci. Alternativa grubojsili je algoritam koji ,,bolje poznaje problem” i u tom smislu GA spadaju u,,slabe” algoritme jer nemaju posebne pretpostavke o problemu. Ako ne pos-toji algoritam koji koristi gradijente (funkcija evaluacije nije diferencijabilnaili ima mnogo lokalnih optimuma - GA neki svrstavaju medu opste metodepretrage koji ne koriste gradijente) ili koristi neku heuristiku, ili ne postojispecificno resenje (iako ce verovatno GA nalaziti resenje, to verovatno necebiti najbolje i najefikasnije ali ce biti veoma blizu) onda bi GA mogao bitiveoma dobro resenje (u suprotnom to cesto nije). Primer: mreze sortiranja(Knuth, 1973.) elemenata predstavljaju problem u kome je cilj naci u stomanjem broju niz poredenja (i zamena mesta) da bi se sortirao niz brojeva- za n = 16 je nadeno najmanje resenje reda 60 (Green), dok je upotrebomGA (Hillis, 1992.) dobijeno resenje reda 65.
4.3 Kanonski GA
Stanje pretrage GA se predstavlja populacijom sirine n koja predstavljaskup od n nizova (binarnih) duzine l. Svaki od tih nizova se naziva hromozom(Holand) ili genotip (Schaffer, 1987) i svakome od njih je dodeljena brojnavrednost, fitnes (fitness - zdravlje, jacina). Objektivna funkcija i fitnes secesto koriste kao termini ravnopravno, ali u pravom smislu fitnes je dodel-jen jednom hromozomu i specifican je bas za taj hromozom, dok objektivnafunkcija nacelno zavisi od cele populacije a ne od pojedinog hromozoma.Obicno se racuna evaluacija fi hromozoma i u populaciji, a onda se fitnesracuna kao fi/f gde je f prosecna evaluacija hromozoma u populaciji (objek-tivna funkcija moze biti onda fi, f ili max(fi)). Fitnes hromozoma se nekiput racuna i kao njegov rang u populaciji (Baker, 1985; Whitley, 1989) ilikao izbor metodom turnira (Goldberg, 1990). Na osnovu pocetne populacije(ciji izbor moze biti dosta bitan) odnosno trenutne populacije, primenomGA transformacija (ili GA operatora) racuna se nova populacija i za ciklusovakvog iterativnog procesa kaze se da daje jednu generaciju GA (u smislubroja iteracija).

Soft Computing - racunska inteligencija (Computational Intelligence) 81
4.3.1 Operatori GA
Operatori GA su:
- odabiranje (selekcija): predstavlja proces odabira hromozoma iz popu-lacije za ucestvovanje u reprodukciji (procesu stvaranja naredne pop-ulacije) - najprostije je (uniformno) nasumice odabrati, ali se obicnouzima uzima u obzir fitnes koji je srazmeran verovatnoci odabira hro-mozoma (ili npr. uniformno se odabire hromozom iz kolekcije u kojojsvaki hromozom ucestvuje onoliko puta koliki mu je fitnes)
- rekombinacija (ukrstanje, crossover): postupak u kome se dva hro-mozoma kombinuju i stvaraju dva nova hromozoma tako sto se naodabranoj poziciji (mestu, lokusu) c prekidaju hromozomi i preostalidelovi menjaju mesta - npr. hromozomi duzine l = 16 bita:
Hromozom 1: 11010 \/ 01100101101Hromozom 2: yxyyx /\ yxxyyyxyxxy-------------------------------- rekombinuju se na 5. mestu u nizove:Hromozom’ 1: 11010yxxyyyxyxxyHromozom’ 2: yxyyx01100101101
- mutacija: Na proizvoljnim mestima izabranog hromozoma se nasumicemenja bit (pozicija, alel - vise alela koji se kodiraju u parametar cineonda gen)
4.3.2 Primer kanonskog GA
Konacno, jedan primer kanonskog GA izgleda ovako:
1. Kreiraj inicijalnu populaciju od n hromozoma duzine l (bita)
2. Izracunaj fitnes za svaki hromozom u populaciji
3. Ponavljaj sledece dok se ne stvori n potomaka:
• Vrsi odabir para hromozoma (verovatnoca odabira hromozomatreba da bude srazmerna fitnesu) principom zamene (mogu bitiizabrani ponovo hromozomi koji su vec bili odabrani)

82 Seminarski rad
• Verovatnocom pc (,,stepen rekombinacije”) napraviti rekombinacijuhromozoma na (uniformno) slucajno odabranom mestu - ako se neradi rekombinacija, napraviti samo replike roditelja. Postoji vari-janta vistruke rekombinacije (multi-crossover) na vise (uniformno)slucajno odabranih mesta (tada stepen rekombinacije odredujebroj mesta ukrstanja hromozoma)
• Verovatnocom pm izvrsiti mutaciju oba potomka i smestiti ih upopulaciju novih hromozoma (ako ih ima neparan broj moze sejedan izbaciti nasumice)
4. Zameniti trenutnu populaciju novom (prakticno, postoji privremenapopulacija dobijena polazeci od trenutne, koja se u toku prethodnihkoraka transformise svakim GA operatorom navedenim redom cime sedobija nova populacija)
5. Ici na korak 2. sve dok objektivna funkcija ne ukaze da je populacijadostigla potrebne kriterijume (ili se npr. premasi ogranicenje brojaiteracija)
Verovatnoca pm se bira obicno tako da bude veoma mala (ispod 0.001),
4.4 Seme, teorema seme i posledice
4.4.1 Uloga i opis prostora pretrage
Hiperravni prostora pretrage ili seme su delovi ukupnog prostora pretragedobijeni fiksiranjem alela reprezenta - npr. hiperravni (red o(H) je prakticnobroj fiksiranih alela hiperravni) oblika 0****...*** i 1****...***, sa nji-hovim reprezentacijama i statistikama se zovu seme prvog reda. Mogu sedalje razmatrati podseme ili preseci sema - posebno je zanimljiva osobina(ispravnog) GA da ako se prate brojevi hromozoma po semama (frekvenceuzorkovanja) i prosek njihovogo fitnesa pre rekombinacije, nakon rekombi-nacije broj hromozoma po podsemama proporcionalno odgovara proizvoduprethodne frekvencije i prosecnog fitnesa (kako se i ocekuje). Ova vrednostse obelezava sa:
M(H, t + 1/2) = M(H, t)f(H, t)
f(t)
gde se simbolicno sa t+1/2 obelezava privremena populacija nakon rekombi-nacije (ako je t pre rekombinacije, trenutna), M(H, t) je frekvenca hiperravni
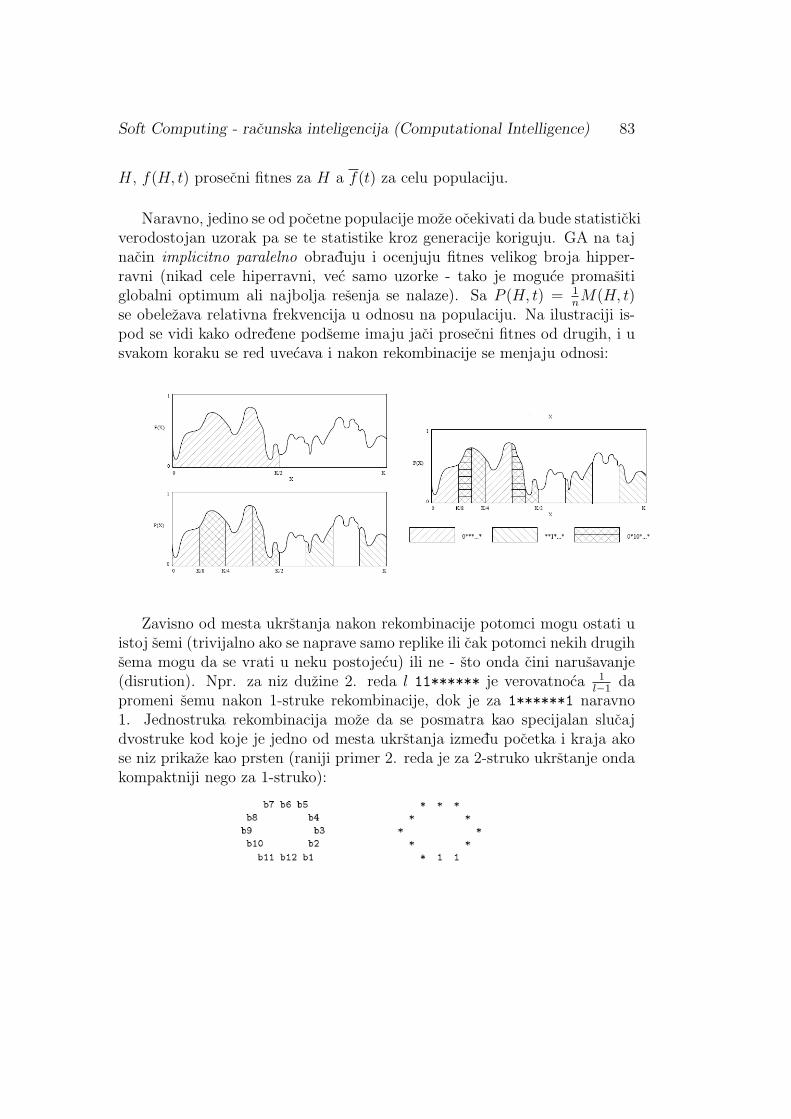
Soft Computing - racunska inteligencija (Computational Intelligence) 83
H, f(H, t) prosecni fitnes za H a f(t) za celu populaciju.
Naravno, jedino se od pocetne populacije moze ocekivati da bude statistickiverodostojan uzorak pa se te statistike kroz generacije koriguju. GA na tajnacin implicitno paralelno obraduju i ocenjuju fitnes velikog broja hipper-ravni (nikad cele hiperravni, vec samo uzorke - tako je moguce promasitiglobalni optimum ali najbolja resenja se nalaze). Sa P (H, t) = 1
nM(H, t)
se obelezava relativna frekvencija u odnosu na populaciju. Na ilustraciji is-pod se vidi kako odredene podseme imaju jaci prosecni fitnes od drugih, i usvakom koraku se red uvecava i nakon rekombinacije se menjaju odnosi:
Zavisno od mesta ukrstanja nakon rekombinacije potomci mogu ostati uistoj semi (trivijalno ako se naprave samo replike ili cak potomci nekih drugihsema mogu da se vrati u neku postojecu) ili ne - sto onda cini narusavanje(disrution). Npr. za niz duzine 2. reda l 11****** je verovatnoca 1
l−1da
promeni semu nakon 1-struke rekombinacije, dok je za 1******1 naravno1. Jednostruka rekombinacija moze da se posmatra kao specijalan slucajdvostruke kod koje je jedno od mesta ukrstanja izmedu pocetka i kraja akose niz prikaze kao prsten (raniji primer 2. reda je za 2-struko ukrstanje ondakompaktniji nego za 1-struko):

84 Seminarski rad
Ako niz sadrzi bitove (alele) koji su kompaktno rasporedeni (blizu jednidrugima, imaju osobinu povezanosti - linkage) manja je verovatnoca da semabude narusena rekombinacijom. Meru kompaktnosti seme odreduje definisucavelicina (defining length) ∆(H) = Ix − Iy gde je Ix najveca pozicija alelela
koji nije *, a Iy najmanja. Tako je onda ∆(H)l−1
verovatnoca da ce 1-strukim
ukrstanjem doci do narusavanja. Cesto se koristi inverzija kao dodatni GAoperator, ali to je interesantno samo ako cuva kodiranje (ili ako kodiranjene zavisi od polozaja, npr. obelezavanjem bitova), inace predstavlja samosnaznu mutaciju. Takode se koristi kao GA operator rekombinacije i uni-formno ukrstanje gde se se alel svakog potomka racuna uzima nasumice odbilo kojeg od roditelja redom (dobra strana mu je nezavisnost od ∆(H) i kodi-
ranja). Verovatnoca narusavanja za uniformno ukrstanje je (1 − (1/2)o(H)−1
sto je mnogo losije od 2-strukog koje se pokazuje boljim od 1-strukog ali i odukrstanja veceg stepena.
4.4.2 Teorema seme
Za GA je ocigledno pozeljno izbeci narusavanje sema, sto pracenje prethod-nih statistika i naredna teorema sema fundamentalna za GA karakterisu kaobitne osobine (dokaz npr. u [GA-TUT]):
Teorema 3
P (H, t+1) ≥ P (H, t)f(H, t)
f
[1− pc
∆(H)
l − 1(1− P (H, t))
f(H, t)
f
](1−pm)o(H)
Osnovna posledica ove teoreme je da se narusavanje ukrstanja i mutacijamora minimizovati - npr. smanjivanjem ili ukidanjem mutacije (mada naru-savanje ne mora biti jedini kriterijum efikasnosti GA, npr. evaluacija se mozedinamicki menjati vremenom u toku rada). Eksperimenti u kojima ucestvujusamo selekcija i mutacija su pokazali da GA i onda moze da radi (sa man-jim performansama, tacnije takav algoritam je barem reda n puta sporiji,[GA-INTRO] - Random-Mutation Hill Climbing). Mnogo je veci problemtzv. prevremena konvergencija - kada svih hromozomi u populaciji postanuveoma slicni ili isti (genetska raznolikost(diversity): npr. sve jedinice ili svenule ako su bitovi) a nije dostignuto zadovoljavajuce resenje (to se pogotovudesava ako je populacija dovoljno mala, kada je preporucljivije koristiti uni-formnu i visestruka ukrstanja). Mutacija zato ima pozitivnu ulogu prover-avanja trenutnog stanja populacije - ovo samo donekle podseca na prob-

Soft Computing - racunska inteligencija (Computational Intelligence) 85
lem prevazilazenja lokalnog minimuma gradijent metode - klasicni GA za-pravo prestavlja model uzorkovanja hiperravni (statisticki ,,uzorkivaci sema”)odnosno model racunanja nad semama, dok u specijalnim slucajevima i al-ternativnim oblicima radi kao hill-climbing. Prakticna posledica ovoga je dase fitnes mora skalirati (podesavati) svakom generacijom jer se varijansa pop-ulacije smanjuje (pa je selektivni pritisak na populaciju fitnesom oslabljen) -jedno resenje je da se prati razlika fitnesa i najmanjeg fitnesa u populaciji ilida se koristi fitnes po rangu (ureden ravnomerni niz brojeva u datom opsegu- rank based). Postoji i jedna osobina GA i ovakvog pogleda na seme - ,,pre-vara”sema, koja se neki put desava kada razlicite seme sukobljenih osobinazavaraju pretragu resenja GA (Goldberg, Whitley, Grefenstette).
Ilustracija ispod pokazuje kako se u 4-dimenzionalnom binarnom pros-toru (hiperkocki) ponasa 1-struko ukrstanje (isprekidane tackice) u odnosuna 2-struko u rekombinaciji 0000 i 1111:
To se moze posmatrati ovako: ako se trazi minimalna putanja izmeducvorova gde je uniformno ukrstanje u prednosti - u jednom koraku stize dokomplementarnog cvora: ako je h Hemingovo rastojanje roditelja, iskljucujuciroditelje uniformno ukrstanje moze proizvesti 2h − 2 razlicita potomka, a 1-struko 2(h−1). Naredna dva hromozoma su prikazana pored bez zajednickihalela koje Buker (Booker, 1987) naziva reduciranim surogatima:
0001111011010011 ----11---1-----1
0001001010010010 ----00---0-----0

86 Seminarski rad
Oba se nalaze u hiperravni 0001**101*01001* gde se rekombinacija odigravau 4-dimenzionalnoj hiperravni (vaze iste osobine GA operatora).
4.4.3 Binarni alfabet i n3 argument
Za binarnu populaciju velicine n hromozoma duzine l u sema redi i bi tre-
balo da bude n2i populacije (velicina particije), a takvih sema ima 2i
(li
).
Ako je bitno naci broj uzoraka φ hiperravni najveceg reda θ = log(n/φ) pred-stavljene datom populacijom (Fitzpatrick, Grefenstette, 1988, [GA-TUT])tako da bude statisticki verodostojan, pokazuje se da GA racuna nad bro-
jem razlicitih hiperravni reda n3. Vazi 2θ
(lθ
)≥ n3 = (2θφ)3 za dobro
odabranu velicinu populacije - na osnovu l ukupan moguci broj hiperravnije 3l, a za n = 3l imamo najvise n hiperravni - dakle, potrebno je izabratirazumno dosta manje n koje ce dati zeljene performanse.
Dva su osnovna argumenta protiv upotrebe alfabeta alela hromozomavece kardinalnosti: manji broj hiperravni nad kojim se vrsi racunanje, ireprezentacija moze zahtevati vecu populaciju da bi bila statisticki oprav-dana. S druge strane, resenje moze biti bolje prilagodeno problemu ako sekoristi alfabet vece kardinalnosti i mogu se definisati neki novi dodatni GAoperatori.
4.4.4 Kritike sema teoreme, uopstena teorema seme
Teorema seme je nejednakost dobijena majorizacijama u kojima su zane-marani ,,neocekivani” dobici i gubici rekombinacijom, i drugo, fitnes pop-ulacije se menja iz generacije u genaraciju, tako da je procena dobra samonarednu generaciju ali ne i vise narednih bez sagledavanja svih sema u pop-ulacijama - ali zato postoji egzaktnija verzija sema teoreme (Vose, Liepins,Nix, 1993.). Polazi se se od modela u kome se posmatra P (Si, t) t-te pop-ulacije S = Si1 , · · · , Sin nizova Si kojih za duzinu l ima v = 2l. Tadaje verovatnoca da je i-ti niz odabran za reprodukcij si. Ako je relacija ek-vivalencije ∼ definisana sa x ∼ y ⇔ (∃γ > 0)x = γy u celoj populaciji(γ = γ0/f) onda je si ∼ P (Si, t)f(Si). Ako je pt
k = P (Sk, t) (pt = [ptk]k ∈ Rv)
i ri,j(k) verovatnoca da niz k potice od rekombinacije nizova i i j, onda je

Soft Computing - racunska inteligencija (Computational Intelligence) 87
matematicko ocekivanje:
Ept+1k =
∑i,j
stis
tjri,j(k)
Ako je matrica M = [mij] matrica td. mij = ri,j(0), ovo se moze uopstitiza bilo koji niz k operatorom ekskluzivne disjunkcije ⊕ td. ri,j(k ⊕ q) =ri⊕k,j⊕k(q), tj. ri,j(k) = ri,j(k ⊕ 0) = ri⊕k,j⊕k(0). Ekskluzivna disjunkcijazamenjuje ukrstanje (kombinaciju) i mutaciju (rekombinacija se shvata kaokompozicija kombinacije i mutacije), npr.:
gde se onda permutacijom σ td. je σj[s0, · · · , sv−1]T = [sj⊕0, · · · , sj⊕v−1]
T
moze definisati uopsteni operator za ceo prostor pretrage:
M(s) = [(σ0s)T M(σ0s), · · · , (σv−1s)
T M(σv−1s)]T
Ako je fitnes matrica F zadata tako sto se funkcija evaluacije f(i) nalazi nadijagonali (i-toj vrsti i koloni, ostalo nule), onda vazi
st+1 ∼ FM(st)
Dalje prosirenje ovakvog modela se vezuje za Markovljeve lance (Vose, 1993).
4.5 Ostali modeli evolucionog racunanja
Postoje dva populaciono-bazirana algoritma racunanja koji predstavl-jaju varijaciju Holandovog GA ili su nezavisno razvijeni: evoluciono pro-gramiranje i evolucione strategije. Evoluciono programiranje je osno-vano knjigom vise autora (L. Fogel, Ownes, Walsh, ,,Artificial IntelligenceThrough Simulated Evolution”, 1966) gde su organizmi (individue tj. hromo-zomi) konacni automati ciji se fitnes meri sto uspesnijim resavanjem zadateciljne funkcije (npr. pomnuti Knutov problem sortiranja, ili LISP programi).Evolucione strategije (ES) su bazirane na pomenutoj knjizi Rehenberga(1973. kao i Schwefel, 1975. i 1981.). Dva osnovna primera su µ + λ − ES

88 Seminarski rad
(µ roditelji daju λ potomke, selekcijom najboljih i od jednih i drugih se do-bijaju naredni µ roditelji) i (µ, λ)-ES (koja je u skladu sa kanonskim GA gdepotomci zamenjuju roditelje pre selekcije). Rekombinacija u ES dozvoljava inove operatore koji npr. prave prosek parametara.
4.5.1 Dzenitor
Dzenitor (Genitor) klasa GA je nastala 1988-1989. (Whitley), a Syswerda(1989.) ih naziva GA ,,stalnog stanja”(steady state) iako su vece varijansenego kanonski GA (i time skloniji gresci uzorkovanja, ,,genetskom odlivu”).Osnovne razlike u odnosu na kanonski GA su:
• reprodukcija daje samo jednog potomka - dva roditelja se biraju i njihovpotomak se odmah smesta u populaciju
• ubacivanjem potomka u populaciju hromozom najmanjeg fitnesa ,,is-pada”iz populacije (Goldberg i Deb 1991. su pokazali da ovo pravimnogo veci selektivni pritisak)
• koristi se rangiranje pre nego uopsteni fitnes (daje konstantniji pritisakna populaciju)
Dzenitor je primer µ + λ − ES - akumulacija poboljsanih hromozoma upopulaciji je monotona.
4.5.2 CHC
Ovo je opet primer GA koji prikuplja monotono najbolje potomke (LarryEshelman 1991. - CHC = Cross generational elitist selection, Heterogeneousrecombination (by incest prevention) and Cataclysmic mutation). CHC ek-splicitno pozajmljuje µ + λ-ES: posle rekombinacije bira se N najbolji in-dividua od roditlje i potomaka zajedno za narednu generaciju u kojoj seizbacuju duplikati (Goldberg pokazuje da ovo daje dovoljan selektivni priti-sak). CHC pored ovako ,,elitistickog”odabiranja u kome se pravi nasumicanizbor takvih roditelja primenjuje i dodatni uslov na osnovu koga se praviizbog individua za reprodukciju: individue moraju biti udaljene medusobnopo Hemingovom rastojanju (ili nekom drugom) bar koliko neko zadato (ovopromovise raznolikost, diverzitet tj. ,,sprecava incest”). Koristi se varijantauniformnog ukrstanja kojim se tacno polovina bitova razmeni. Mutacija sekoristi da bi se ponovo zapocela pretraga kad populacija pocne da konvergira

Soft Computing - racunska inteligencija (Computational Intelligence) 89
i tada se primenjuje masivno ali se uvek sacuva najbolja individua u nared-noj generaciji. Ova metoda je najefikasnija za populacije manjeg obima (do50).
4.5.3 Hibridni algoritmi
Kombinovanjem najboljih klasicnih metoda optimizacije i pretrage sa GAdaje najbolje od oba sveta (L. Davis). Dejvis koristi cesto kodiranje realnimumesto celim brojevima i domen-specificne operatore rekombinacije. Upotre-bom gradijent metoda i metoda optimizacije dodaje se ucenje evolucionomprocesu (kao i pomenute metode masinskog ucenja, npr. [LSC]). Kodiranjenaucene informacije je onda evolucija Lamarkovog tipa (cime se gubi osobinaracunanja nad semama). Dobro se ponasa u resavanju problema optimizacije(kao vid visestruke i paralelne gradijent metode, a pri tom donekle zadrzavai osobine GA). Medutim, ako se naucene informacije ne prenose u narednegeneracije ali uticu na mogucnost boljeg opstanka pojedinih individua u pop-ulaciji onda je to domen-specificno resenje koje ne utice na seme (u biologijipoznatko kao Boldvinov efekat).
4.6 Alternativni operatori odabiranja GA
U odnosu na ranije pomenute alternativne metode (npr. elitizma i steady-state), metod rangiranja se razlikuje od obicne selekcije samo racunanjemfitnesa pri odabiru. Tada pomenuti problem promene varijanse tokom radaGA se moze resiti (Forrest, 1985) i sigma skaliranjem, gde je V al(i, t) funkcijaocekivanog fitnesa u t-toj iteraciji za i-ti hromozom:
V al(i, t) =
1 + f(i,t)+f(t)
2σ(t), σ(t) 6= 0;
1, σ(t) = 0.
gde je σ(t) standardna devijacija fitnesa populacije u toj iteraciji. Kod nekihproblema se pokazao veoma korisnim poznati metod simuliranog ocvrscavanja:
V al(i, t) =ef(i,t)/T
[ef(i,t)/T ]
gde se temperatura smanjuje do nule po nekom rasporedu tokom racunanja.

90 Seminarski rad
4.7 Paralelni GA
Jedna od glavnih osobina GA je pomenuta implicitna paralelnost, ali imogucnost masivne paralelizacije. U ovoj klasi GA cilj je raspodeliti nekakopopulaciju razlicitim procesorima (kao uopstenim jedinicama racunanja) sasto vecim stepenom paralelizacije i sto manji obimom komunikacije meduprocesorima.
4.7.1 Globalne populacije sa paralelizmom
Najjednostavniji nacin da se ovo realizuje je da se iskoristi kanonski GA stim da se selekcija radi metodom turnira (nasumice se biraju dva hromozomai onda na osnovu evaluacije najbolji ide dalje, Goldberg, Deb, 1990-1991:pokazuju da je ovo identicno kao i fitnes po rangu). Tako n/2 (n je paran)procesora dobija nasumice po dva hromozoma i dalje se sve odvija paralelnou svakoj generaciji.
4.7.2 Model ostrva
Ako postoji manji broj procesora i koristi se veca populacija, onda jepotreban drugaciji model. Populacija se podeli u ostrva koja se dodelesvakom procesoru koji dalje nad njima radi bilo kojim od GA. Povremeno,na svakih 5 generacija recimo, vrsi se migracija odnosno razmena odredenog(manjeg) broja hromozoma cime se deli genetski materijal medu ostrvimai procesorima (Whitley, Starkweather, Gorges-Schleuter, 1990-1991). Os-trva mogu biti razlicite velicine i prema tome razlicitih osobina kao i vrste iparametri GA koji rade na procesorima.
4.7.3 Celijski GA
Ako je arhitektura procesora takva da su povezani samo sa susedima umatrici (i to npr. po stranicama samo cetiri suseda) onda je globalna na-sumicna selekcija neprakticna, vec se koristi samo lokalno uporedivanje (kojemoze biti stohasticke prirode) sa samo jednim potomkom. Ova arhitekturaje inspirisana celijskim automatima (npr. matrica ili niz bitova kod kojihse naredno stanje jedinstveno odreduje vrstom konacnih automata kod ko-jih je funkcija prelaska definisana za svaku celiju i njenu okolinu a stanja subinarna). Operatorima GA je dovoljna samo lokalna celija sa susedima utom slucaju. Ne postoje eksplicitna ostrva u ovom modelu, ali se implicitno

Soft Computing - racunska inteligencija (Computational Intelligence) 91
javlja struktura slicna ostrvima (ovakva separacija se naziva ,,izolacija udal-jenoscu”):
Nakon nekoliko generacija se smanjuje broj kompaktnih celina u smislu slicnostigenetskog materijala a njihova povrsina se uvecava.
4.8 Primeri GA
Primera ima mnogo kao i u ostalim oblastima racunske inteligencije, aliovde izdvajamo dva problema koja se oslanjaju na ranije pomenute primere.Od komercijalnih skoljki gde se mogu praviti modeli GA mozemo opet izd-vojiti MATLAB sa (Direct Search Toolbox) odgovarajucim dodatkom.
4.8.1 Evoluirajuce NM
Pomenuta je primena GA k za optimizaciju neuronskih mreza. Ako jetopologija fiksna i koristi se racunanje napred, osnovna primena bi moglabiti trazenje optimalnih vrednosti pondera (David Montana, Lawrence Davis,1989). Upotreba gradijent metode moze dati resenja koja nisu najbolja(lokalni minimum ukupne greske), ili ga je tesko primeniti (nediferencija-bilna transfer funkcija). Medutim jos je veci izazov trazenje odgovarajucetopologije i menjanje topologije u toku procesa ucenja. Direktan metod (Ge-offrey Miller, Peter Todd, Shailesh Hedge, 1989) podrazumeva postupak ukome se koristi matrica koja odreduje topologiju (npr. 1 ako je dozvoljena

92 Seminarski rad
veza izmedu PE, 0 ako nije) i dobijenu su uspesni rezultati za neke probleme.Hiroaki Kitano 1990. pokazuje da se metodom gramatickog kodiranja mogudobiti efikasnije bolja resenja - kontekst slobodnim gramatikama se generisestruktura pomenute matrice koristeci pravila sa cije desnse strane se nalazeterminali koji cine gradivne elemente matrice formata 2 × 2. Hromozomitakvog metoda su kraci i metod se moze lakse prilagodavati specificnom prob-lem, dok je u oba slucaja duzina hromozoma dinamicki promenljiva. Takodese moze evoluirati i funkcija ucenja - npr. ako je ∆wij = f(yi, yj, y
∗j , wij)
linearna funkcija odredena koeficijentima (ispred sabiraka koji predstavljajuargumente funkcije kao i njihove proizvode) kao paramterima koji se opti-mizuju GA.
Klasa NM kod kojih su ulazi grupisani u gene i kodirani u klase kojeimaju lingvisticko znacenje (npr. gen duzine 4 bita predstavlja atribut kojiima cetiri vrednosti - cetiri boje, primera radi) kao i izlaz koji ima izlaznihPE koliko i kategorija se mogu proucavati standardnim Data Mining meto-dama kao crna kutija. U [DATAMINING] se daje primer GA koji koristihromozome ciji su geni vrednosti tezinski koeficijenti (obelezeni njihovimindeksima), gde se fitnes racuna kao proizvod njihove vrednosti (pondera).Populacija se onda tumaci kao serija ako-onda pravila koja ukazuju na vezuulaza i izlaznih kategorija.
4.8.2 Klasifikacija i konceptualizacija
Prethodni primer predstavlja primenu GA u problemima klasifikacija ikonceptualizacije znanja (u smislu otkrivanja implcitnih, unutrasnjih relacijamedu ulaznim podacima, najcesce bas tog oblika ako-onda pravila). Takavpristup trazi najpre uocavanje nekih jednostavnih nepovezanih osobina (npr.figura se sastoji iz odredenog broja pravih ili krivih linija, seku se ili ne seku,postoje kruzni oblici itd.) koje mogu biti biti pripremljene drugom metodom(NM ili neka klasicna metoda), a onda GA otkriva znacajne osobine i pravila.GA u odnosu na klasicne metode vestacke inteligencije ima tu prednost dane zahteva posebno predznanje o problemu heuristicke ili neke druge prirode.
4.8.3 Ucenje fazi pravila evolucijom
Ideja je primeniti GA na hromozome koji predstavljaju skupove pravilaciji su geni razlcitog tipa (oznake promenljivih ili kakateristicne funkcije,

Soft Computing - racunska inteligencija (Computational Intelligence) 93
njihovi parametri, koeficijenti uverenja, uslovni elementi, itd.) kojim se ondaoptimizuje broj pravila koji ucestvuje u radu fazi ekspertnog sistema, kao iostali njegovi elementi (Lim, Furuhashi). Evaluacija moze onda biti testiranjepravila na probnom skupu podataka ili klasicna analiticki zadata funkcija.
4.8.4 Evoluiranje programa
Ideja programa koji samostalno pisu programe koji resavaju zadate prob-leme je dugo vec izazov vestacke inteligencije bez nekog dobrog opsteg resenja.Pristup upotrebom GA koji je razvio Dzon Koza (1992-1994.) se zasniva naevoluciji LISP koda. Skica algoritma je sledeca:
1. (preduslov) zadat je skup mogucih funkcija i terminala (identifikatora)kao i fitnes koji npr. predstavlja tabelu vrednosti funkcije ciji se kodtrazi (dakle trazi se funkcija koja vraca rezultat na osnovu ulaznogidentifikatora, a time se ujedno i dodatno specifican ocekivani rezultati prostor pretrage)
2. generise se pocetni skup proizvoljnih programa (lista) koji cine pocetnupopulaciju (koji su ogranicene duzine u smislu dubine liste kao stabla)
3. fitnes se racuna na osnovu skupa zadatih vrednosti (ocekivanih ulaznihi izlaznih vrednosti)
4. primenjuju se uobicajeni GA operatori, s tim da su ovde hromozomiproizvoljne duzine i specificne strukture - liste, tako da se rekombinacijasvodi na razmenu delova lista (ili podstabla ako se liste posmatrajukao drvece). Koza ostavlja 10% populacije nepromenjeno i ne koristimutaciju (oslanjajuci se na dovoljno veliku i raznoliku pocetnu pop-ulaciju). Funkcija evaluacije bi trebala, naravno, da nagraduje kraca(jednostavnija) resenja.
Ovo je samo jednostavan primer ovakvog pristupa resavanju problema, uslozenijim slucajevima uspeh nije srazmerno veci i daleko je od toga da pos-toji opste resenje.
Evoluirajuci jednodimenzionalni celijski automati (niz binarnih celija)mogu se posmatrati kao modeli racunanja kod kojih se uz odgovarajucufunkciju prelaska nakon odredenog broja iteracija dolazi do niza koji pred-stavlja rezultat ili ne, a moze se dobiti i nestabilan proces (Mitchell, Hraber,

94 Seminarski rad
Crutchfield, 1993). Primena GA u ovom slucaju se svodi na trazenje pravefunkcije prelaska a fitnes bi bio odreden stepenom poklapanja rezultata ibrzinom konvergencije. Slicno ranije pomenutom Knutovom problemu sor-tiranja, rezultati dobijeni upotrebom GA su veoma blizu konkretnih resenjakoje su pronasli ljudi, ali ne i bolji za dovoljno slozene probleme.

Soft Computing - racunska inteligencija (Computational Intelligence) 95
Knjige koriscene tokom pisanja ovog rada, kao i sajtovi sa dokumentaci-jom - Zade preporucuje A. Kofmana (1972-1977) za detaljniji uvid u teorijufazi skupova i fazi logike.
Literatura
[IC] Lotfi A. Zadeh: Information And Control (Ch. 8: Fuzzy Sets), 1965.
[words] Lotfi A. Zadeh: Fuzzy Logic = Computing With Words, (IEEETransactions On Fuzzy Systems, Vol. 4) 1996.
[FSNEW] Lotfi A. Zadeh: Outline of a New Approach to the Analysis ofComplex Systems and Decision Processes, (IEEE Transactions On Sys-tems, Man, and Cybernetics, Vol. SMC-3 no. 1), 1973.
[PT] Lotfi A. Zadeh: Probability Theory and Fuzzy Logic, 2002.
[RD] Radojevic D., There is Enough Room for Zadeh’s Ideas, Besides Aris-totle’s in a Boolean Frame, Soft Computing Applications, 2007. SOFA2007. 2nd International Workshop on 21-23 Aug. 2007 (Pages 79 - 82),DOI 10.1109/SOFA.2007.4318309
[AQM] Marko MIRKOVIC, Janko HODOLIC, Dragan RADOJEVIC, AG-GREGATION FOR QUALITY MANAGEMENT
[AV] Andreas de Vries, Algebraic hierarchy of logics unifying fuzzy logic andquantum logic, Lecture Notes - http://arxiv.org/pdf/0707.2161.pdf
[RD2] Radojevic D., Interpolative Realization of Boolean Algebra as a Con-sistent Frame for Gradation and/or Fuzziness, ISBN 978-3-540-73184-9
[ALG] Lotfi A. Zadeh: A fuzzy-algorithmic approach to the definition ofcomplex or imprecise concepts, (Int. J. Man-Machine Studies 8) 1975.
[PH] WHat does mathematical fuzzy logic offer to description logic ? PetrHajekhttp://www.cs.cas.cz/semweb/download.php?file=05-10-Hajek&type=pdf
[FDL] A Fuzzy Description Logic for the Semantic Web, Umberto Straccia,http://faure.isti.cnr.it/~straccia/download/papers/BookCI06a/BookCI06a.pdf

96 Seminarski rad
[GCI] General Concept Inclusions in Fuzzy Description Logics - Giorgos Stoi-los, Umberto Straccia, Giorgos Stamou, Jeff Z. Pan, 2006
[LPROFS] Ludeek Matryska: Logic Programming with Fuzzy Sets, 1993.
[SCFL] Lotfi A. Zadeh Soft Computing and Fuzzy Logic, 1994
[birth] L. A. Zadeh: The Birth and Evolution of Fuzzy Logic, 1990.
[FESFR] William Siler, James J. Buckley: FUZZY EXPERT SYSTEMSAND FUZZY REASONING, (Wiley-Interscience) 2005.
[NNALG] James A. Freeman, David M. Skapura: Neural Networks - Algo-rithms, Applications and Programming Techniques, (Addison Wesley)1991.
[FOUND] Nikola K. Kasabov: Foundations of Neural Networks, Fuzzy Sys-tems, and Knowledge Engineering, (MIT Press) 1996.
[GA-TUT] Darrell Whitley: A Genetic Algorithm Tutorial
[GA-INTRO] Mitchell Melanie: An Introduction to Genetic Algorithms,(MIT Press) 1999.
[DATAMINING] Data mining neural networks with genetic algorithms, AjitNarayanan, Edward Keedwell, Dragan Savic
[NN-INTRO] Ben Krose, Patrick van der Smagt: An introduction to NeuralNetworks, 1996.
[NN-AA] L. P. J. Veelenturf: Analysis and Applications of Artificial NeuralNetworks, (Prentice Hall) 1995.
[ANNT] Dave Anderson, George McNeil: Artificial Neural Networks Tech-nology, 1992
[NND] Martin T. Hagan, Howard B. Demuth, Mark Beale: Neural NetworksDesign
[LSC] Learning and Soft Computing, (MIT Press) Vojislav Kecman, 2001.
[GRAN] Lotfi A Zadeh Toward A Theory Of Fuzzy Information GranulationAnd Its Centrality, 1997

Soft Computing - racunska inteligencija (Computational Intelligence) 97
[JD] John Durkin: Expert Systems - Design and Development
[BIOINFORMATICS] Pierre Baldi, Sφren Brunak: Bioinformatics, The Ma-chine Learning Approach, (MIT Press) 2001.
[NNINT] Integrating rough set theory and fuzzy neural, 2002.
[HBTNN12] Handbook Of Brain Theory And Neural Networks Part 1 & 2,(MIT Press) 2003.
[TB] Donald E. Knuth: The TeXbook
[PG] Predrag Janicic, Goran Nenadic: OSNOVI LATEX-A
[WWW] http://plato.stanford.edu/entries/logic-fuzzy/
http://ieee-cis.org/
http://www.cs.berkeley.edu/~zadeh/
http://www.cs.ubc.ca/labs/lci/
http://www.genetic-programming.com/
http://www.genetic-programming.org/
http://en.wikipedia.org/wiki/BL_(logic)
http://en.wikipedia.org/wiki/Computational_Intelligence
http://en.wikipedia.org/wiki/Bioinformatics
http://en.wikipedia.org/wiki/Connectionism
http://en.wikipedia.org/wiki/Artificial_neural_network
http://en.wikipedia.org/wiki/Boltzmann_machine
http://en.wikipedia.org/wiki/Simulated_annealing
http://www.aaai.org/home.html
http://en.wikipedia.org/wiki/Universal_algebra
http://en.wikipedia.org/wiki/Logic_programming