speech recognition using neural network
TRANSCRIPT

PRESENTATION ONSPEECH RECOGNITION USINGNEURAL NETWORK
Prepared by-
Kamonasish Hore (100103003)
CSE , Dept. of IT,IST, Gauhati University

Outlines:
Introduction Objective Benefits of Speech recognition Literature Survey Hardware and Software Requirement Specifications Proposed Work Phases of the Project Conclusion Future Scope Bibliography

Introduction:
What is Speech?
The faculty or act of expressing or describing thoughts, feelings, or perceptions by the articulation of words.
A form of communication in spoken language, made by a speaker before an audience.

Speech Recognition:
Speech Recognition (SR) is the ability to translate a dictation or spoken word to text.
Also known as “automatic speech recognition” (ASR), “computer speech recognition”, or “speech to text” (STT)

Where it can be used ? Dictation
System control/navigation
Commercial/Industrial applications
Personal Computers
Health Care
Telephony - Smart-phones - Customer Helpline Services

Artificial Neural Networks: An artificial neural network is a computer program, which
attempt to emulate the biological functions of the Human brain. They are an excellent classification systems, and have been
effective with noisy, patterned, variable data streams containing multiple, overlapping, interacting and incomplete cues.
Neural networks do not require the complete specification of a problem, learning instead through exposure to large amount of example data.
Neural networks comprise of an input layer, one or more hidden layers, and one output layer. The way in which the nodes and layers of a network are organised is called the networks architecture.

Objective:
The project is started with a sole aim in mind that the design should be able to recognize the voice of a person by analyzing the speech signal.

Benefits of Speech Recognition:
There are many pros of speech recognition out which few are listed below:
Faster than “hand-writing”. Allows for better spelling, whether it be in text or
documents.
Helpful for people with a mental or physical disability.
Hands-free capability.

Literature Survey: In the journal [1] entitled "Speech Recognition in the Electronic Health
Record" whose authors are Sherry Doggett, Julie A. Dooling (RHIA), Susan Lucci (RHIT, CHPS, CMT, AHDI-F ) have done work on ‘Speech Recognition in the Electronic Health Record (EHR)’ using Front-end speech recognition (FESR) and back-end speech recognition (BESR) technologies help in the production of legible and comprehensive document(s). It also serves as a productivity tool to help lower costs and increase productivity, especially when compared to the manual labor required by traditional dictation and transcription in the field of healthcare.
In the paper [2] entitled “ Literature Review on Automatic Speech Recognition” whose authors are Wiqas Ghai, Khalsa College (ASR) of Technology & Business Studies, Mohali, Punjab and Navdeep Singh, Mata Gujri College, Fatehgarh Sahib, Punjab have done work in the field of ‘Automatic Speech Recognition(ASR)’ for developing an effective ASR for different languages and to show technological perspective of ASR in different countries They have used artificial neural networks (ANNs), mathematical models of the low-level circuits in the human brain, to improve speech-recognition performance, through a model known as the ANN-Hidden Markov Model (ANN-HMM) which have shown improvements in large-vocabulary speech recognition systems.

Hardware and Software Requirement specifications:
Microphone. Software for converting the voice signal into .wav file
format. Laptop/Desktop Matlab (R2011a and above)
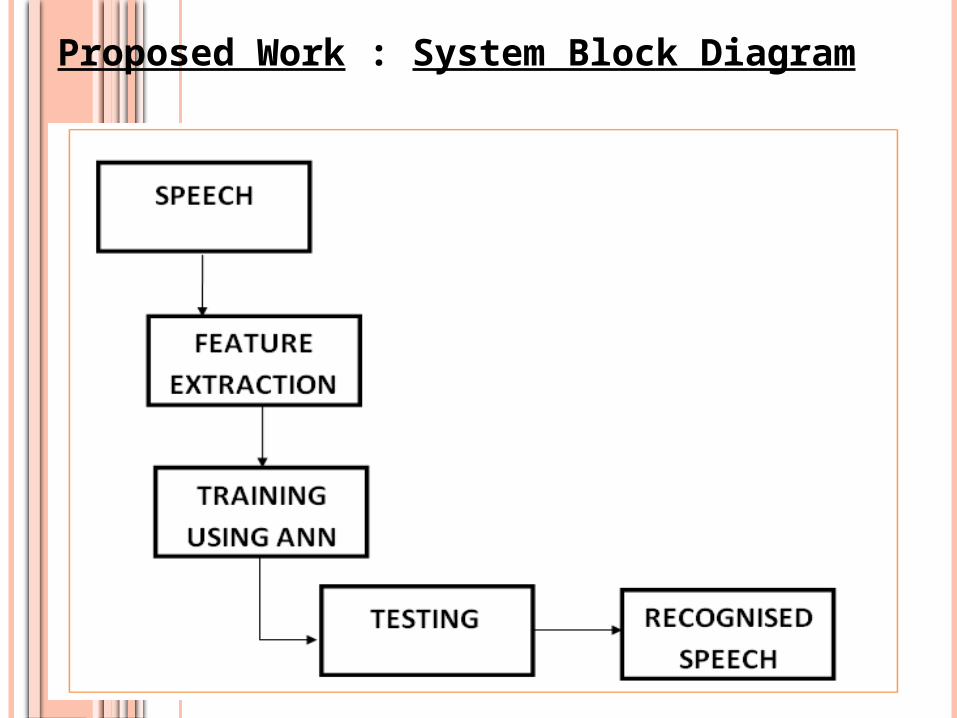
Proposed Work : System Block Diagram

Phase 1: Creating a specific data set (0 - 9).
Phase 2: Recording the data.
Phase 3: Feature Extraction.
Phase 4: Analyzing and evaluating to a specific value/ Training.
Phase 5: Evaluating the system against the real time data/ Testing.
Phase 6: Analyzing the identification results.
Phases of the Project:

Phase 1: Creating a specific data set (0 - 9).
A data set is build containing the numerical words (0-9) of English language. We had selected to use the numerical words as it would save our time and it would help us to make extreme feature extraction of speaker’s voice.
Data set for numeric words Zero (0) One (1) Two (2) Three (3) Four (4) Five (5) Six (6) Seven (7) Eight (8) Nine (9)

Phase 2: Recording the data.
Now, the next part of the project, the recording part, which requires a headphone connected to our working system (laptop) where our proposed system is being implemented and tested.
We had selected the Numerical words set for this purpose and recorded the voice using the in-built Matlab function “Wave record”, which records sound using PC-based audio input device.
The recording for each sample is done for 2 sec. each with standard sampling rate of 44100 Hz which is also approved by International Phonetic Association as Standard sample rate for Speech processing.

Phase 3: Feature Extraction.
We had given the numerical set to around 50 speech (30 male and 20 female) to speak out their voice at different expressions and environment.
After recording we select all the voices and convert the vector into matrix form.
As given as vector input, it creates a matrix one column at a time also ‘vec2mat’ places extra entries in the output matrix if necessary.

Phase 4: Analyzing and evaluating to a specific value/ Training.
This phase contributes to the decision logic part of our project.

Phase 5: Evaluating the system against the real time data/ Testing.
This phase is the last and designated indispensible part of our project.
In the training phase we had trained the neuron with 500 different samples of speech containing from both male and female in different environments and expressions.
During testing phase our program was tested with 10 male and 10 female different samples and found the samples to be recognized, and also resulted that with the increase of number of samples accuracy rate of recognition increases.
The testing environment should be soundproof so that we shall get the result with more accuracy.

Phase 6: Analyzing the identification results.
In this phase the result of different voice sample is discussed.
After taking the voice sample i.e. numeric (0-9) from both male and female, we calculate the recognition percentage of the samples in different sets of samples as taking 10,20,30,40 and 50 voices per numeric word in analytical part of our program.

Phase 6: Analyzing the identification results.
Table for 50 voice samples:
For 50 voice samples
Recognition Rate (%)
Un-Recognized Rate (%)
Zero(0) 82 18One(1) 88 12Two(2) 80 20
Three(3) 88 12
Four(4) 82 18
Five(5) 80.8 19.2
Six(6) 82.6 17.4
Seven(7) 83 17
Eight(8) 86 14
Nine(9) 86 14

Recognition graph for 50 voice samples.

Variation graph between No. of Voices (0-9) Vs Recognition Rate.

Calculating Recognition Rate:
Recognition rate = Voice (0+1+2+3+4+5+6+7+8+9) X 100%
10
Table of final Recognition Rate achieved by different voice samples.
No. of voice samples
Recognition Rate
10 75.120 75.3530 77.1540 80.0850 83.84

The final out-put of the project i.e. speech recognition is shown below:- (Program runned in Matlab)

Conclusion: The main objective of this project was to identify speech of a
person using neural network.
In order to meet this objective we had taken the numerical digits from Zero to Nine (0-9) as the data set to be fed to the system.
The system is tested against the voice signal of around 50 persons and system gives approximately 82% accuracy.
Lastly on completion, we can conclude our project with words that with the increase of number of samples, the recognition rate increases gradually.

Future Scope:
Accuracy will become better and better.
Dictation speech recognition will gradually become accepted.
Small hand-held writing tablets for computer speech recognition dictation and data entry will be developed, as faster processors and more memory become available.
Microphone and sound systems will be designed to adapt more quickly to changing background noise levels, different environments, with better recognition of extraneous material to be discarded.

Bibliography: [1] Russell, Ingrid. "Neural Networks Module". Retrieved 2012
[2] "Speech Recognition in the Electronic Health Record (Updated)." Journal of AHIMA 84, no.9 (Sept 2013).
[3] International Journal of Computer Applications (0975 – 8887), Volume 41– No.8, March 2012.
[4] International Journal of Engineering Trends and Technology- Volume4Issue2- 2013.
[5] International Journal of Computer Applications (0975 – 8887), Volume 41– No.8, March 2012.

THANK YOU