tenmax data pipeline experience sharing
TRANSCRIPT

2 0 1 7 . 0 9
T e n M a x D a t a P i p e l i n e E x p e r i e n c e S h a r i n g
P o p c o r n y ( 陸 振 恩 )

DataCon.TW2017
Who am I
• 陸振恩 (a.k.a popcorny, Pop)
• Director of Engineering @TenMax
• 之前經歷
– 交大資科所
– 第四屆趨勢百萬程式競賽冠軍
– 聯發科技 (2005- 2010)
– SmartQ (2011 – 2014)
– cacaFly/TenMax (2014-present)
• FB: https://fb.me/popcornylu
2

DataCon.TW2017
Current Workload
• 0.1B ~ 1B events generated per day
• About 200G data generated per day
• Data everywhere
– Reporting
– Analytics
– Content Profiling
– Audience Profiling
– Machine Learning
3

DataCon.TW2017
Context
• Each AD request has an serial of events: Request Impression Click
• We call it a session, which is identified by sessionId.
• Generate hourly report for sessions
– with some metrics (requests, impres, clicks)
– grouped by some dimensions (ad, space, geo, device, …)
4
Request Impression ClickSession: 1
Request Impression ClickSession: 2
Request Impression ClickSession: 3
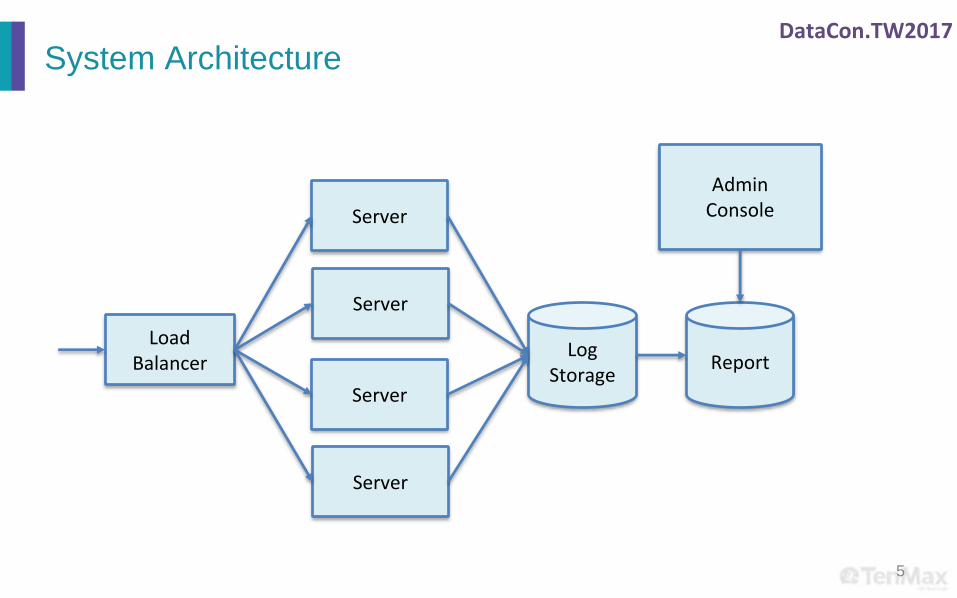
DataCon.TW2017
System Architecture
5
AdminConsole
LoadBalancer
LogStorage
Report
Server
Server
Server
Server

DataCon.TW2017
Data Pipeline
6
BidRequestRaw Events
Sessions Reportgroup bysessionId
mergeevents
aggregatemetrics
group bydimensions
Hourly
EventStream

DataCon.TW2017
Our Data Pipeline Timeline
7
2015 2016 2017
DataCon.TW2017
Data Pipeline Version 1
8
2015 2016 2017

DataCon.TW2017
Data Pipeline Version 1
• MongoDB 2.3
• Why MongoDB?
– Schemaless
– Horizontal scale out
– Replication
9
NoSQL is Hot!!
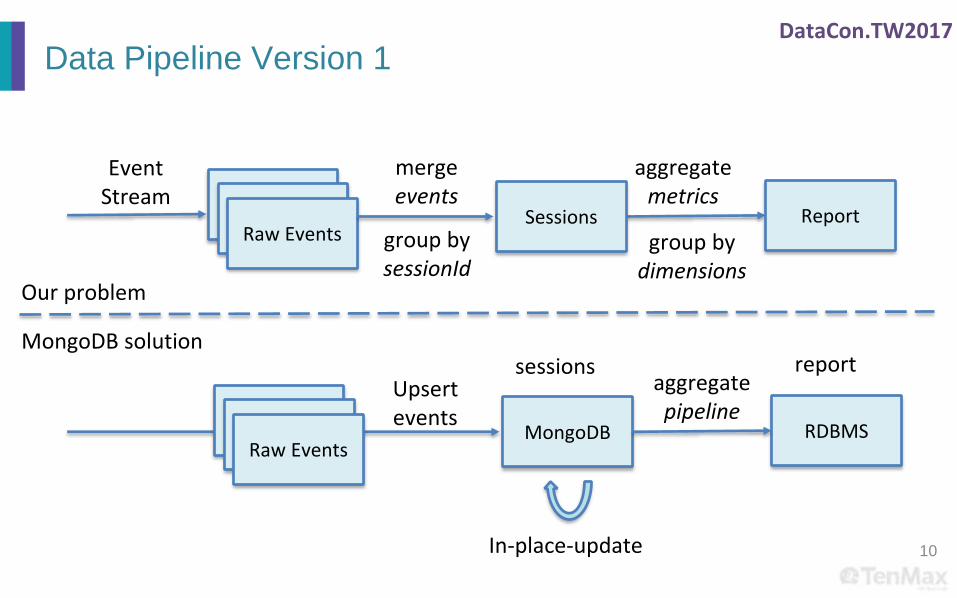
DataCon.TW2017
Data Pipeline Version 1
10
BidRequestRaw Events
Sessions Reportgroup bysessionId
mergeevents
aggregatemetrics
group bydimensions
EventStream
MongoDB RDBMS
In-place-update
aggregatepipeline
Upsertevents
MongoDB solutionsessions report
Our problem
BidRequestRaw Events

DataCon.TW2017
Problem: Poor Write Performance
• MMAPv1 storage engine
– In-place update
– Fragmentation
– Random Access
– Big DB file
11
More Bytes + Random Access =Poor Performance

DataCon.TW2017
Problem: Hard to Operate
• Too many roles of server
– Mongos
– Shard master
– Shard slave
– Config server
12

DataCon.TW2017
Data Pipeline Version 2
13
2015 2016 2017

DataCon.TW2017
Data Pipeline Version 2
• Cassandra 2.1
• Feature
– Google BigTable-like Architecture
– Excellent Write Performance
– Peer-to-peer architecture
– Data Compression
14
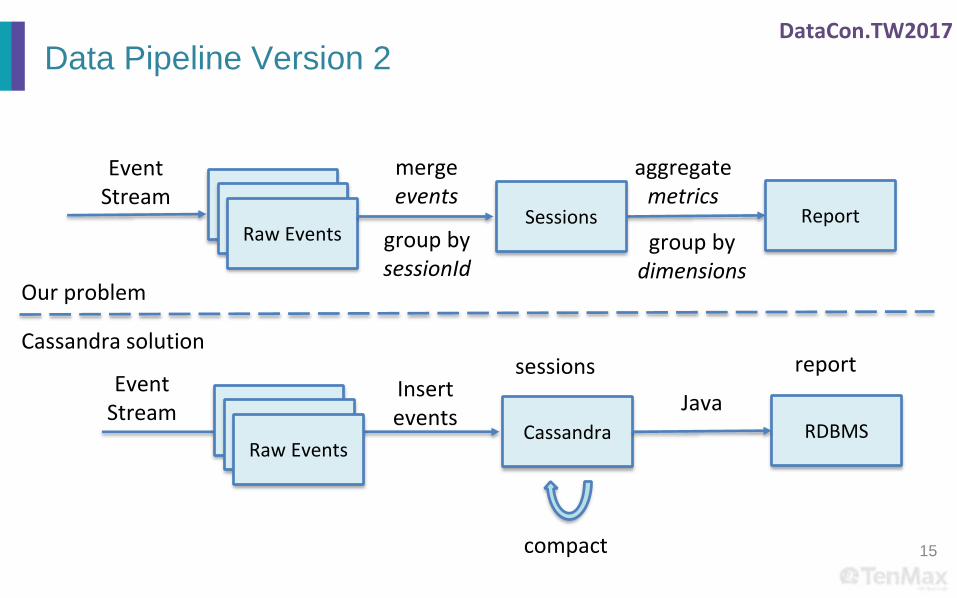
DataCon.TW2017
Data Pipeline Version 2
15
BidRequestRaw Events
Sessions Reportgroup bysessionId
mergeevents
aggregatemetrics
group bydimensions
EventStream
Cassandra RDBMS
compact
JavaInsertevents
Cassandra solutionsessions report
Our problem
BidRequestRaw Events
EventStream
DataCon.TW2017
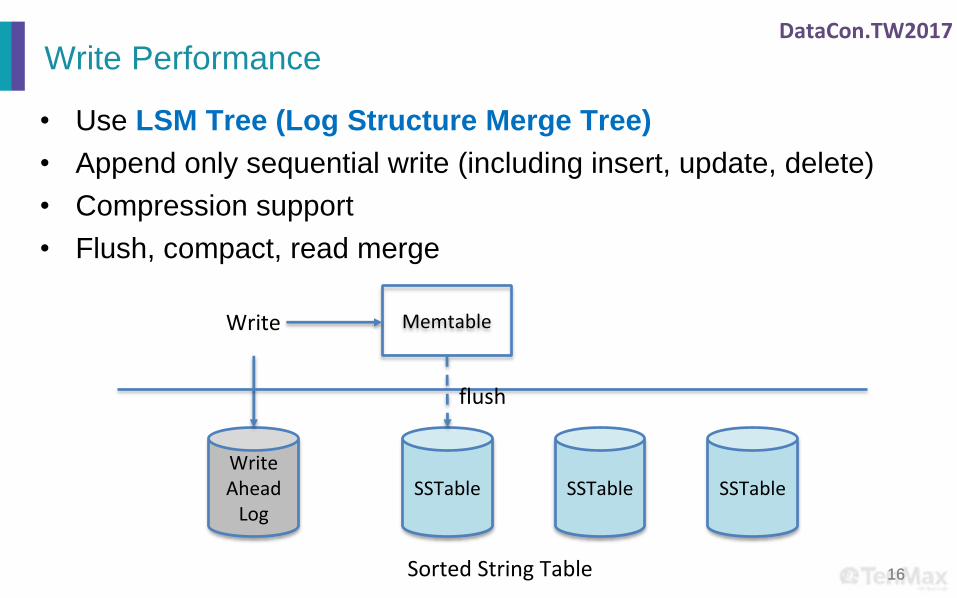
Write Performance
• Use LSM Tree (Log Structure Merge Tree)
• Append only sequential write (including insert, update, delete)
• Compression support
• Flush, compact, read merge
1616
Write Ahead
LogSSTable SSTable
Write Memtable
SSTable
flush
Sorted String Table
DataCon.TW2017
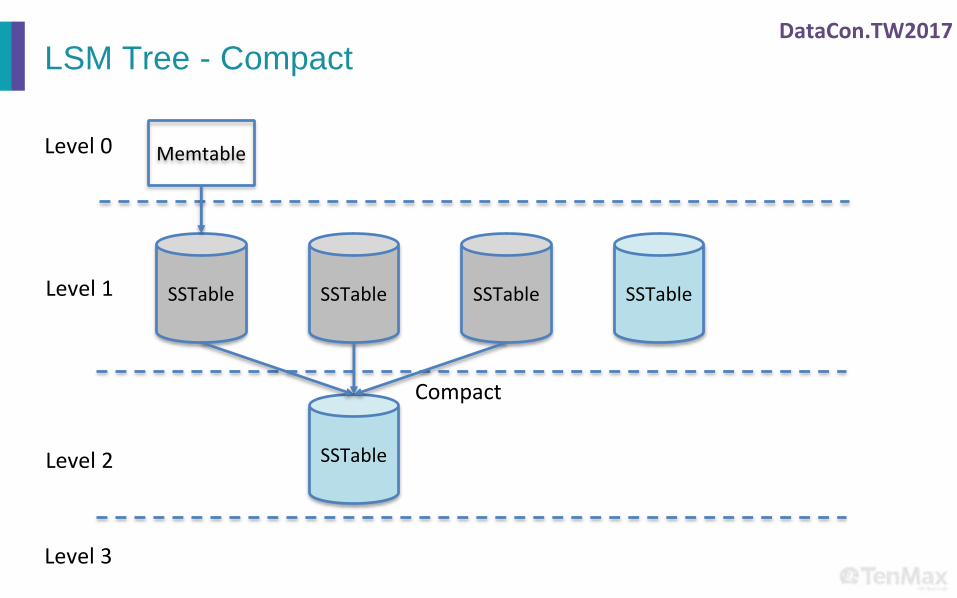
LSM Tree - Compact
SSTable SSTable SSTable SSTable
SSTable
Level 1
Level 2
Level 3
Level 0 Memtable
Compact
DataCon.TW2017
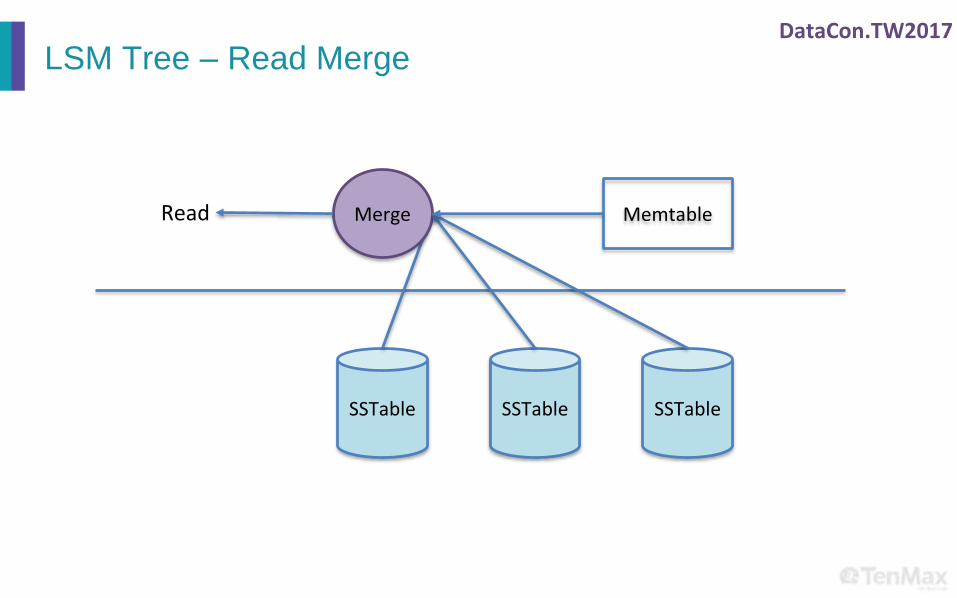
LSM Tree – Read Merge
SSTable SSTable SSTable
Read MemtableMerge

DataCon.TW2017
Write Performance
• Who use LSM Tree?
1919

DataCon.TW2017
Peer-to-Peer Architecture
• Every nodes are
– Contact server
– Coordinator
– Data Node
– Meta Server
• Easy to operate!
20
coordinator
Replica1
Replica2
Replica3

DataCon.TW2017
How about aggregate
• Cassandra has no group-aggregation
• How to aggregate?
– Java Stream (thanks java8)
– Poppy (an in-house dataframe library)
https://github.com/tenmax/poppy
21
Cassandra RDBMS
AggregateInsertevents
report
BidRequestRaw Events
EventStream
Grouping

DataCon.TW2017
Problem: Cost
• SSD Disk costs USD $0.135 per month per GB, while Azure Blob
costs USD $0.02 per month per GB.
• SSD Disk should allocate space in advance, while Azure Blob is pay-
as-you-use.
• Azure Blob replicate data even for lowest pricing tier
• Azure Blob is much scalable and reliable than self-hosted cluster.
• People Cost
22
Cloud Storage Rocks!!

DataCon.TW2017
Problem: Aggregation
• In-house solution is not easy to evolve, while
Hadoop/Spark is a huge ecosystem
• Scalability issue
• Lack key feature: Group by high cardinality key
– Group by visitor
– Aggregate Multi-dimensional OLAP cubes
23
DataCon.TW2017
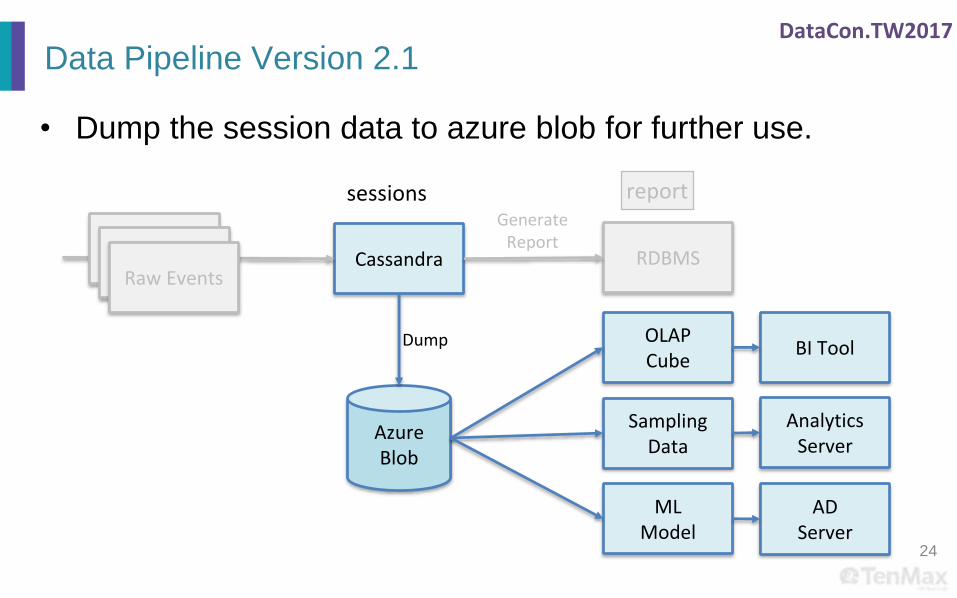
Data Pipeline Version 2.1
24
Cassandra RDBMS
GenerateReport
sessions report
BidRequestRaw Events
AzureBlob
OLAPCube
MLModel
SamplingData
Dump
• Dump the session data to azure blob for further use.
BI Tool
AnalyticsServer
ADServer

DataCon.TW2017
Data Pipeline Version 3
25
2015 2016 2017

DataCon.TW2017
Data Pipeline Version 3
• Kafka 0.11+ Fluentd + Azure blob + Spark 2.1
• Why
– Azure Blob is cheap
– High throughput for Azure Blob
– Spark is a Map-Shuffle-Reduce framework, making
grouping by high cardinality key possible.
26
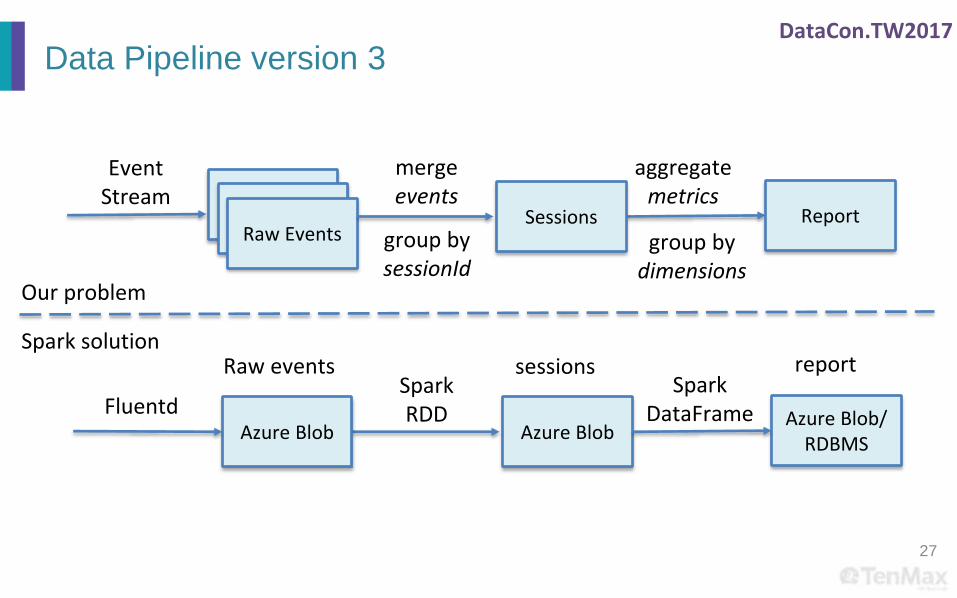
DataCon.TW2017
Data Pipeline version 3
27
BidRequestRaw Events
Sessions Reportgroup bysessionId
mergeevents
aggregatemetrics
group bydimensions
EventStream
Azure BlobAzure Blob/
RDBMS
SparkRDD
Spark solutionsessions report
Our problem
Azure BlobFluentd
Raw eventsSpark
DataFrame
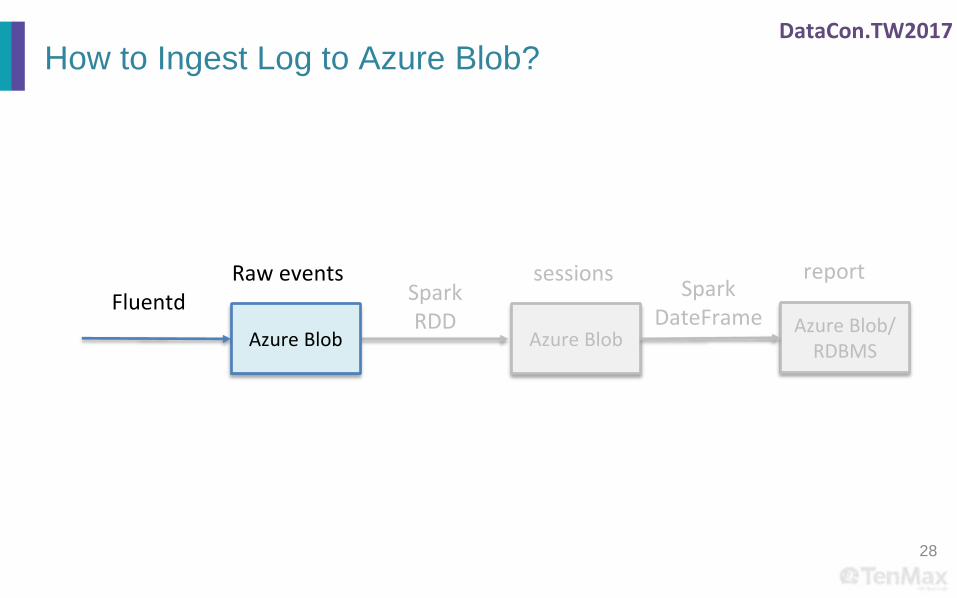
DataCon.TW2017
How to Ingest Log to Azure Blob?
28
Azure BlobAzure Blob/
RDBMS
SparkRDD
sessions report
Azure Blob
FluentdRaw events
SparkDateFrame
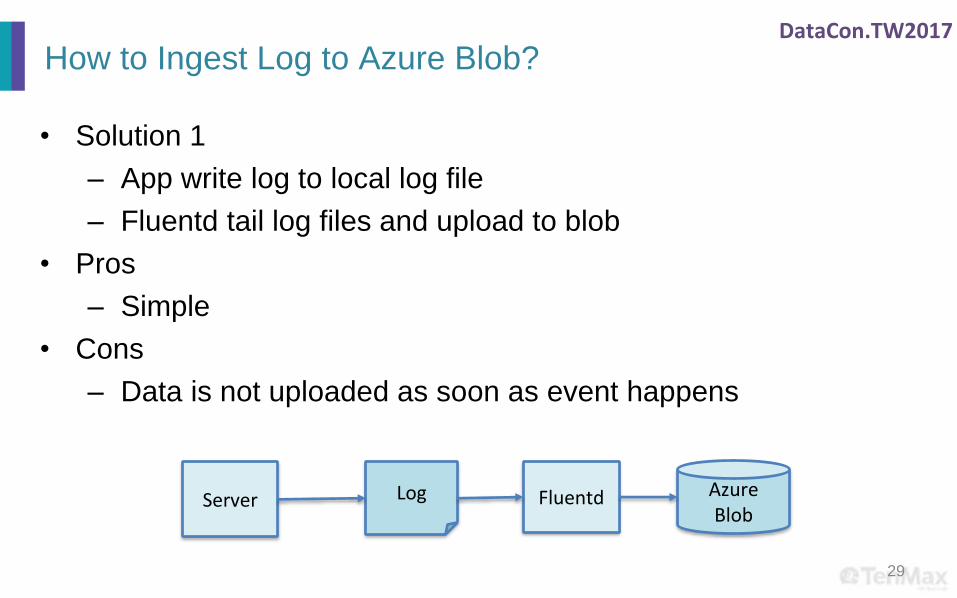
DataCon.TW2017
How to Ingest Log to Azure Blob?
• Solution 1
– App write log to local log file
– Fluentd tail log files and upload to blob
• Pros
– Simple
• Cons
– Data is not uploaded as soon as event happens
29
LogServer Fluentd AzureBlob

DataCon.TW2017
How to Ingest Log to Azure Blob?
• Solution 2
– App append log to kafka
– Fluentd consume logs and batch-upload to blob
• Pros
– Log is stored as soon as event happens
– Log can be used for multiple purpose
• Cons
– Server aware of Kafka
– If connection to kafka fails, server need to handle buffer or OOM
30
Server Kafka Fluentd AzureBlob
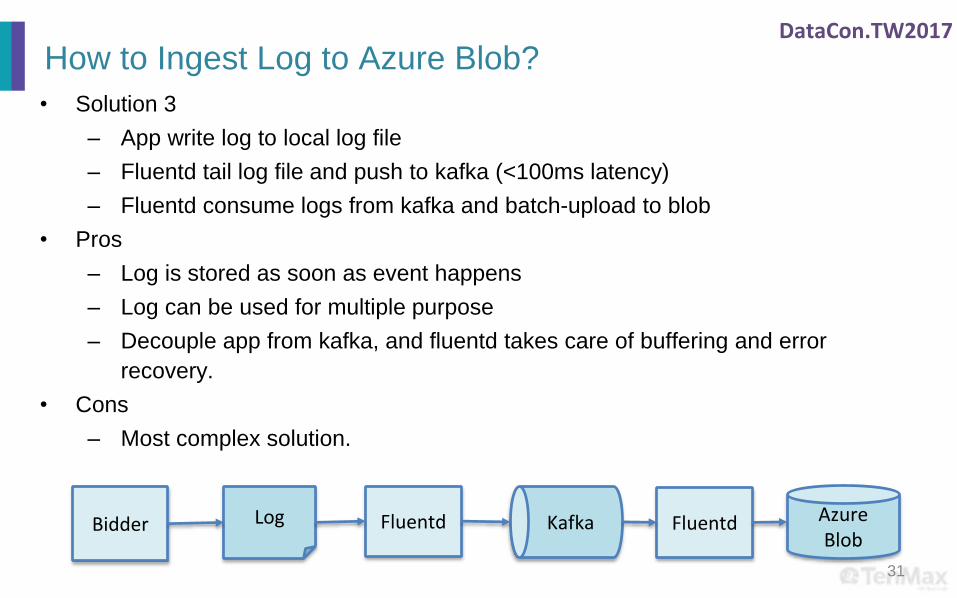
DataCon.TW2017
How to Ingest Log to Azure Blob?
• Solution 3
– App write log to local log file
– Fluentd tail log file and push to kafka (<100ms latency)
– Fluentd consume logs from kafka and batch-upload to blob
• Pros
– Log is stored as soon as event happens
– Log can be used for multiple purpose
– Decouple app from kafka, and fluentd takes care of buffering and error
recovery.
• Cons
– Most complex solution.
31
Bidder Kafka Fluentd AzureBlob
FluentdLog

DataCon.TW2017
Event-Time Window
• A click event may happens after several minutes from the
impression event. How to merge these events?
32
Id: 1ts: 10:58Event: impre
Id: 2ts: 10:59Event: impre
Id: 1ts: 11:02Event: click
Id: 3ts: 11:02Event: impre
Id: 3ts: 11:03Event: click
11:00
How to merge these events?

DataCon.TW2017
Event-Time Window
• Our solution
– Fluentd uploads events to the partition window
according to the session timestamp (partts) instead
of ingest timestamp.
– sessionId is type of TimeUUID, which embeds
timestamp in UUID.
– For every events
partts = timestampOf(sessionId)
33
DataCon.TW2017
Event-Time Window
34
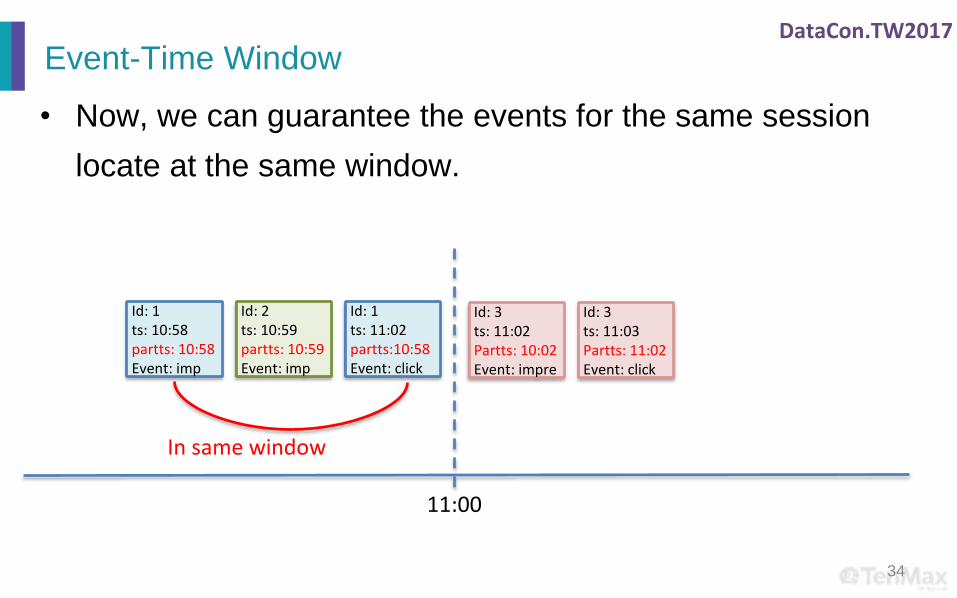
Id: 1ts: 10:58partts: 10:58Event: imp
Id: 2ts: 10:59partts: 10:59Event: imp
Id: 1ts: 11:02partts:10:58Event: click
Id: 3ts: 11:02Partts: 10:02Event: impre
Id: 3ts: 11:03Partts: 11:02Event: click
11:00
• Now, we can guarantee the events for the same session
locate at the same window.
In same window
DataCon.TW2017
Spark RDD and Spark SQL
35
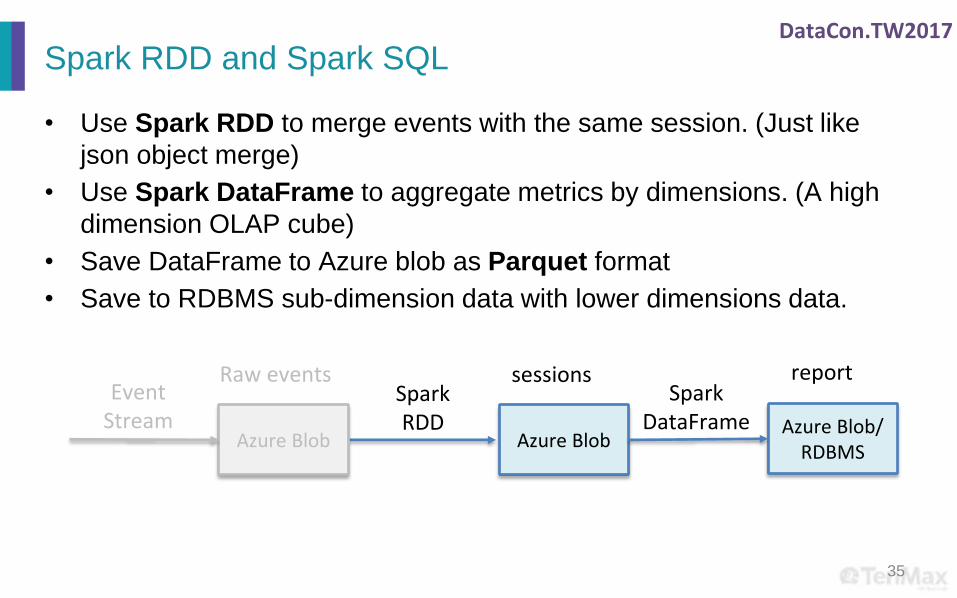
• Use Spark RDD to merge events with the same session. (Just like
json object merge)
• Use Spark DataFrame to aggregate metrics by dimensions. (A high
dimension OLAP cube)
• Save DataFrame to Azure blob as Parquet format
• Save to RDBMS sub-dimension data with lower dimensions data.
Azure BlobAzure Blob/
RDBMS
SparkRDD
sessions report
Azure Blob
EventStream
Raw eventsSpark
DataFrame

DataCon.TW2017
Lessons Learned
• Everything is tradeoff.
• For big data, trade features for cost effective
– DFS for batch source
– Kafka for stream source
• Cloud Storage is very cheap!! Use it now
• Spark is a great tool for processing data. Even for non-
distributed application.
36

DataCon.TW2017
Storage Comparison
37
RDBMS Document Store(e.g. MongoDB)
BigTable-like Stores(e.g. Cassandra)
Distributed File System(e.g. Azure Blob, AWS S3, HDFS)
File/Table Scan Yes Yes Yes Yes
Point Query Yes Yes Yes
Secondary Index Yes Yes Yes*
AdHoc Query Yes Yes
Group and aggregate Yes Yes
Join Yes Yes*
Transaction Yes

DataCon.TW2017
Storage Comparison
38
RDBMS Document Store(e.g. MongoDB)
BigTable-like Stores(e.g. Cassandra)
Distributed File System(e.g. Azure Blob, AWS S3, HDFS)
Cost * ** ** *****
Query Latency ***** **** *** *
Throughput ** ** ** *****
Scalability * *** *** *****
Availability * *** *** *****

DataCon.TW2017
Where We Go Next?
• Stream processing
• Serverless Model for analytics workload
39

DataCon.TW2017
Stream Processing
• Why
– Latency
– Incremental Update
• Trend
– Batch and Stream in one system
– Exactly-once semantic
– Support both ingest time and event time
– Low watermark for late event
– Structured Streaming
40

DataCon.TW2017
Serverless Model for Analytics Workload
• Analytics Workload Characteristic
– Low utilization rate
– Require huge resource suddenly
– Interactive
• Not suitable for provisioned VMs solution, like
– AWS EMR, Azure HDInsight, GCP DataProc
• Serverless Solutions
– Google BigQuery, AWS Athena, Azure Data Lake Analytics
41
DataCon.TW2017
Recap
42
2015 2016 2017

DataCon.TW2017
43
Thanks
Question?