trend micro big data platform and apache bigtop
TRANSCRIPT

葉祐欣 (Evans Ye) Big Data Conference 2015
Trend Micro Big Data Platform and Apache Bigtop

Who am I• Apache Bigtop PMC member
• Apache Big Data Europe 2015 Speaker
• Software Engineer @ Trend Micro
• Develop big data apps & infra
• Has some experience in Hadoop, HBase, Pig, Spark, Kafka, Fluentd, Akka, and Docker

Outline• Quick Intro to Bigtop
• Trend Micro Big Data Platform
• Mission-specific Platform
• Big Data Landscape (3p)
• Bigtop 1.1 Release (6p)

Quick Intro to Bigtop

Linux Distributions

Hadoop Distributions

Hadoop Distributions
We’re fully open sourced !

How do I add patches?

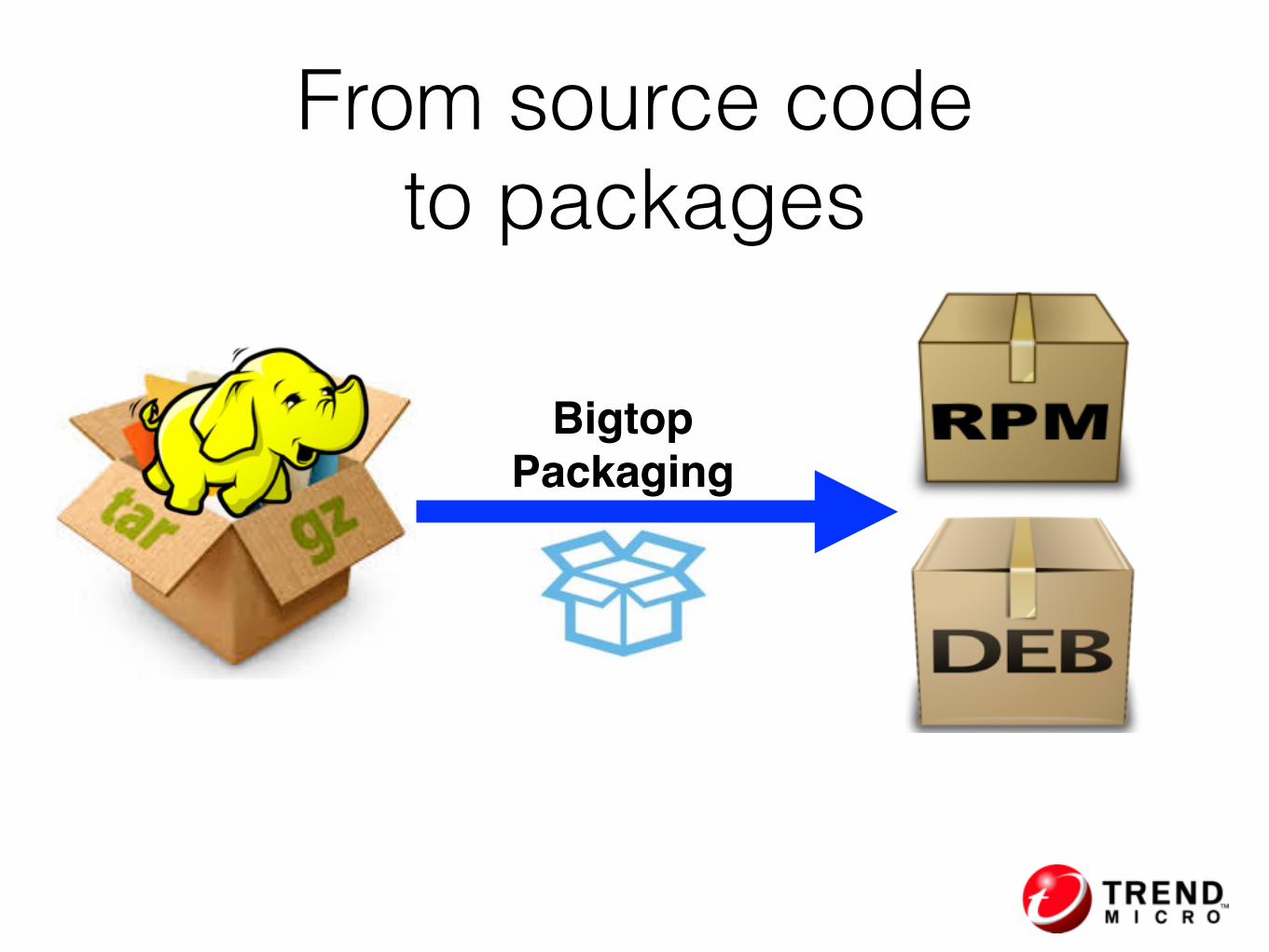
From source code to packages
BigtopPackaging

Bigtop feature set
Packaging Testing Deployment Virtualization
for you to easily build your own Big Data Stack

Supported components

• $ git clone https://github.com/apache/bigtop.git
• $ docker run \--rm \--volume `pwd`/bigtop:/bigtop \--workdir /bigtop \bigtop/slaves:trunk-centos-7 \bash -l -c ‘./gradlew rpm’
One click to build packages
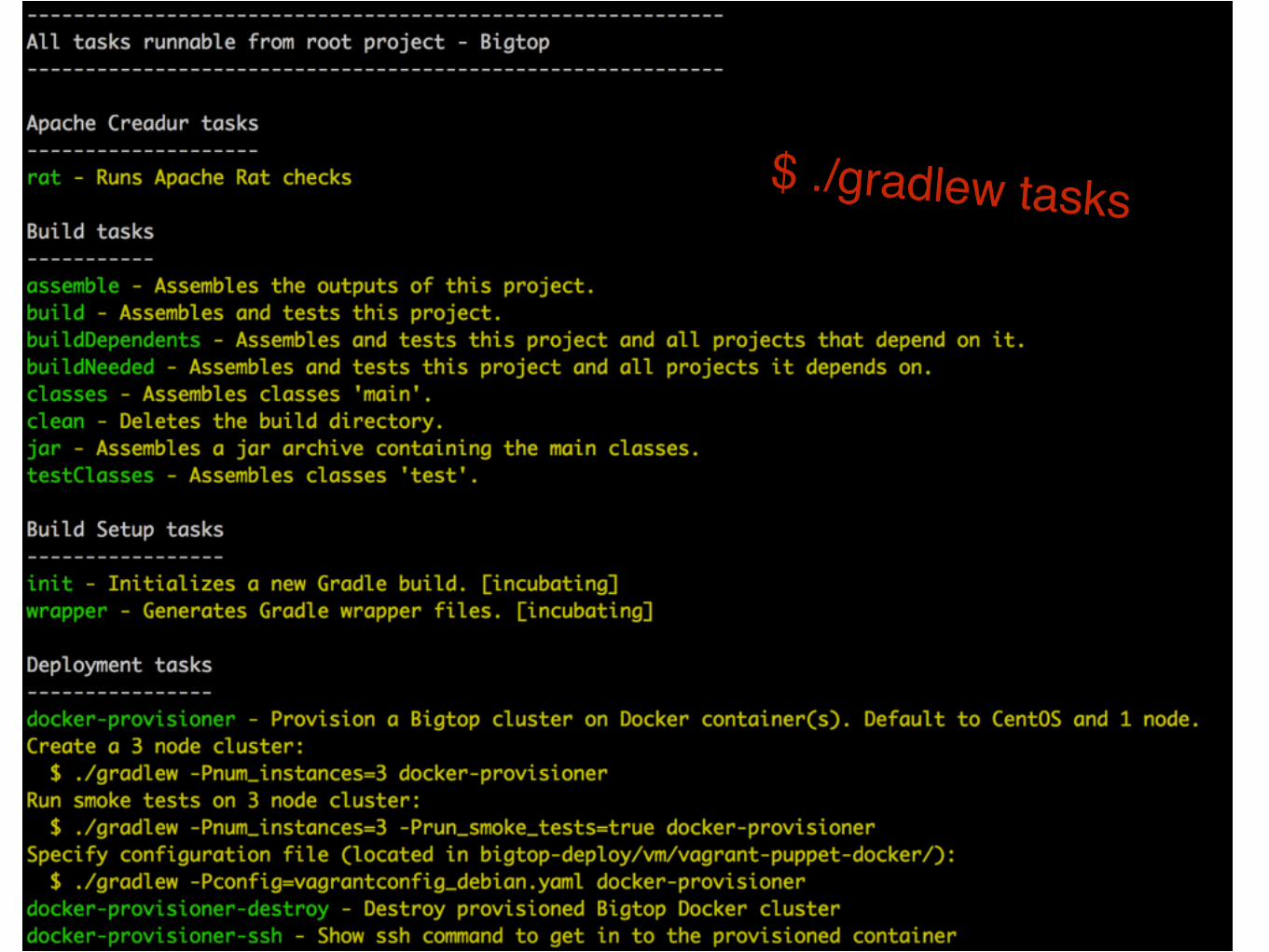
• $ ./gradlew tasks’


One click Hadoop provisioning
./docker-hadoop.sh -c 3
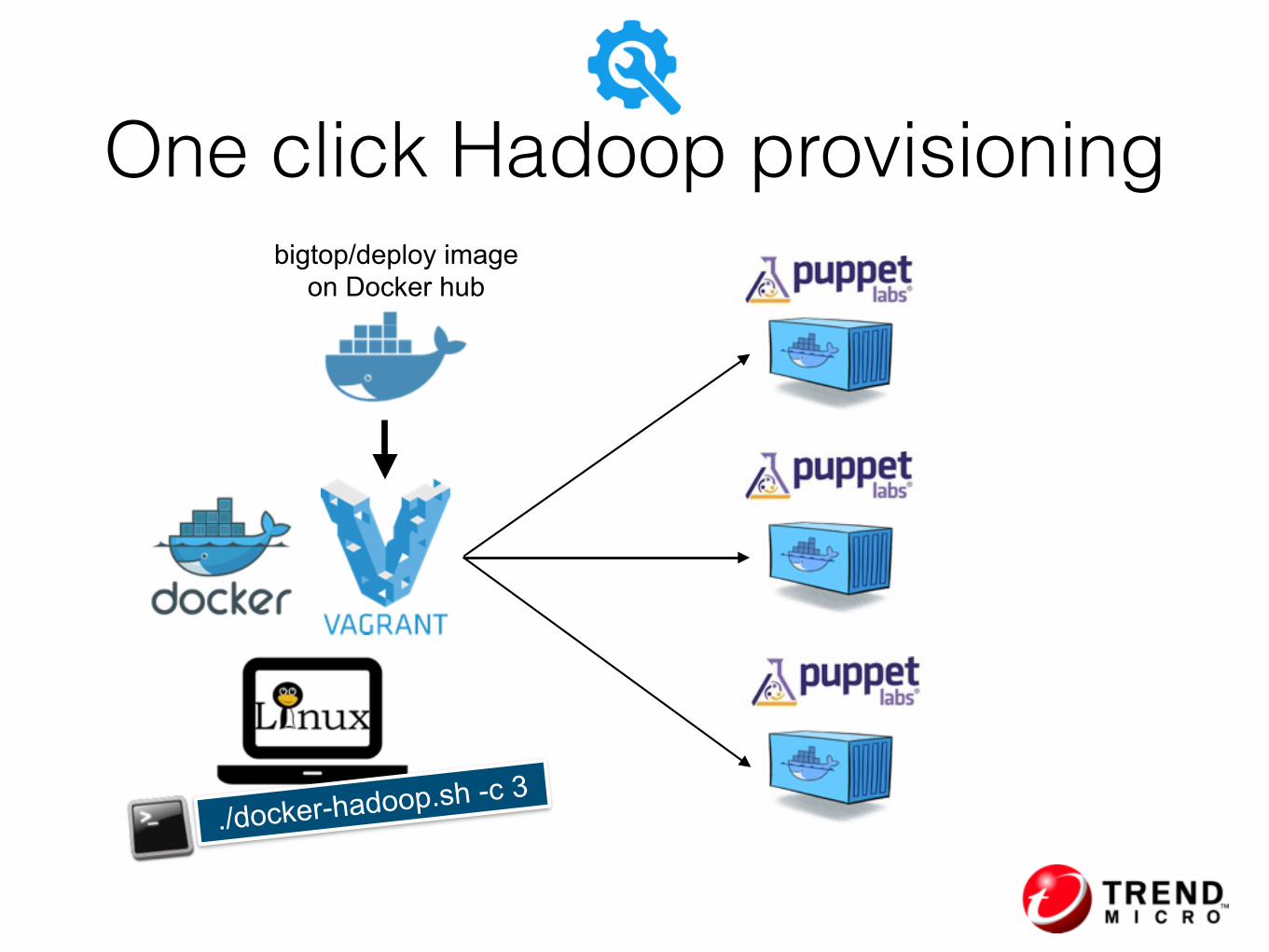
bigtop/deploy image on Docker hub
./docker-hadoop.sh -c 3
One click Hadoop provisioning
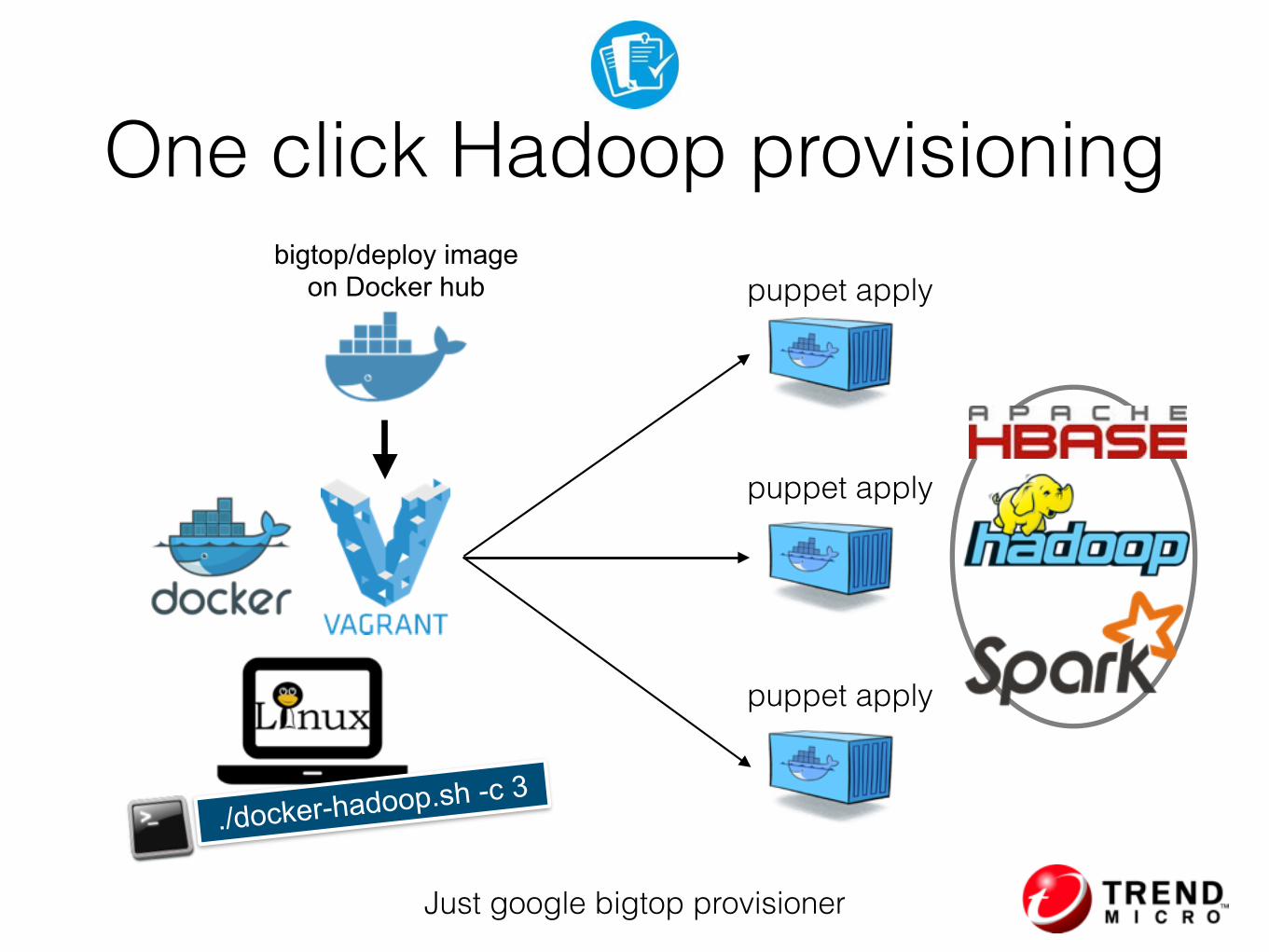
bigtop/deploy image on Docker hub
./docker-hadoop.sh -c 3
puppet apply
puppet apply
puppet apply
One click Hadoop provisioning
Just google bigtop provisioner

Should I use Bigtop?

If you want to build your own customised Big Data Stack

Curves ahead…

Pros & cons• Bigtop
• You need a talented Hadoop team
• Self-service: troubleshoot, find solutions, develop patches
• Add any patch at any time you want (additional efforts)
• Choose any version of component you want (additional efforts)
• Vendors (Hortonworks, Cloudera, etc)
• Better support since they’re the guy who write the code !
• $

Trend Micro Big Data Platform

• Use Bigtop as the basis for our internal custom distribution of Hadoop
• Apply community, private patches to upstream projects for business and operational need
• Newest TMH7 is based on Bigtop 1.0 SNAPSHOT
Trend Micro Hadoop (TMH)

Working with community made our life easier
• Knowing community status made TMH7 release based on Bigtop 1.0 SNAPSHOT possible

Working with community made our life easier
• Contribute Bigtop Provisioner, packaging code, puppet recipes, bugfixes, CI infra, anything!
• Knowing community status made TMH7 release based on Bigtop 1.0 SNAPSHOT possible

Working with community made our life easier
• Leverage Bigtop smoke tests and integration tests with Bigtop Provisioner to evaluate TMH7

Working with community made our life easier
• Contribute feedback, evaluation, use case through Production level adoption
• Leverage Bigtop smoke tests and integration tests with Bigtop Provisioner to evaluate TMH7

Hadoop YARN
Hadoop HDFS
Mapreduce
Ad-hoc Query UDFsPig
App A App C
Oozie
Resource Management
Storage
Processing Engine
APIs andInterfases
In-house Apps
Trend Micro Big Data Stack Powered by Bigtop
Kerb
eros
App B App D
HBase
Wuji
Solr Cloud
Hadooppet (prod) Hadoocker (dev)Deployment

Hadooppet
• Puppet recipes to deploy and manage TMH Big Data Platform
• HDFS, YARN, HA auto-configured
• Kerberos, LDAP auto-configured
• Kerberos cross realm authentication auto-configured(For distcp to run across secured clusters)
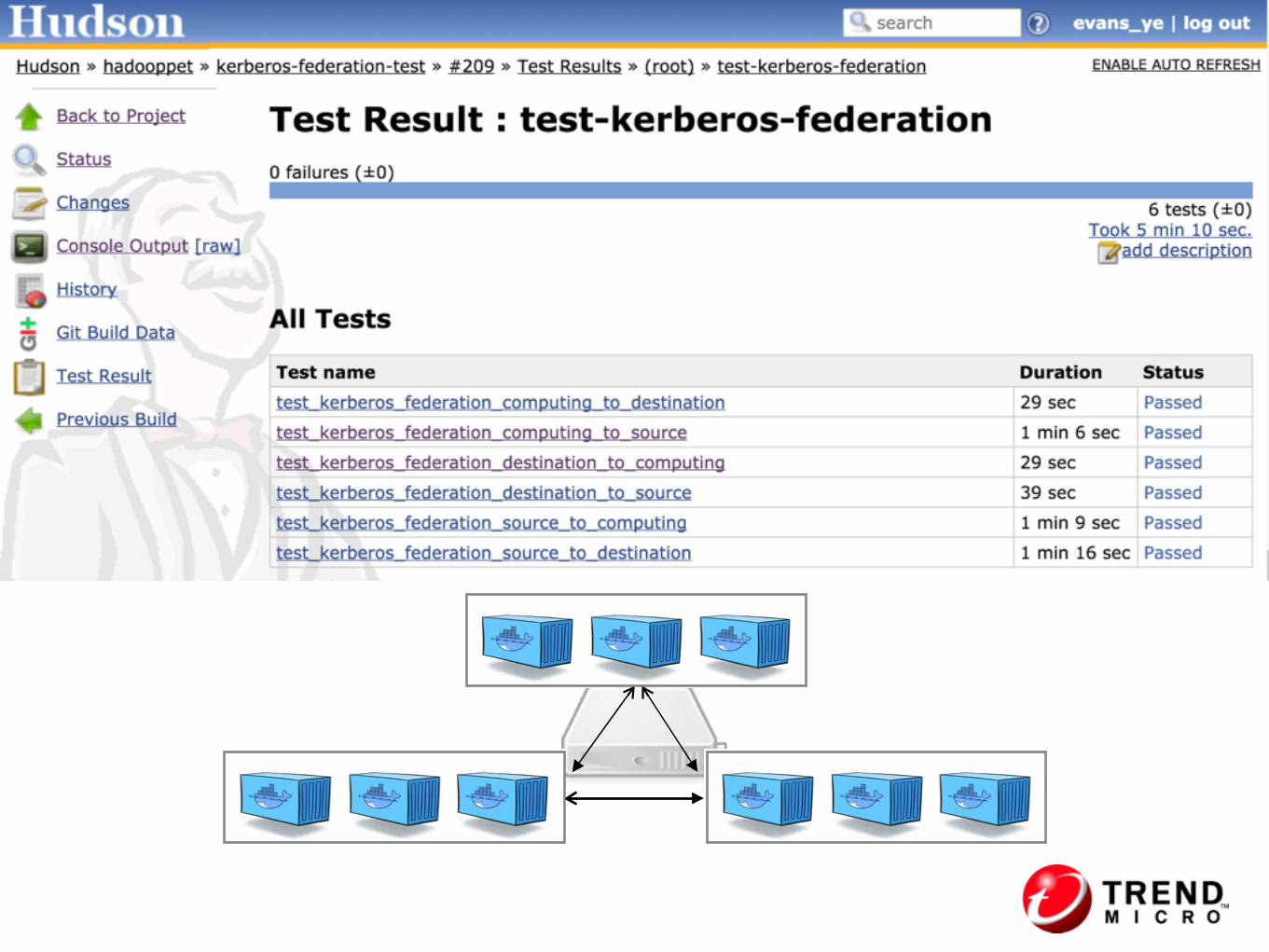

• A Devops toolkit for Hadoop app developer to develop and test its code on
• Big Data Stack preload images—> dev & test env w/o deployment —> support end-to-end CI test
• A Hadoop env for apps to test against new Hadoop distribution
• https://github.com/evans-ye/hadoocker
Hadoocker
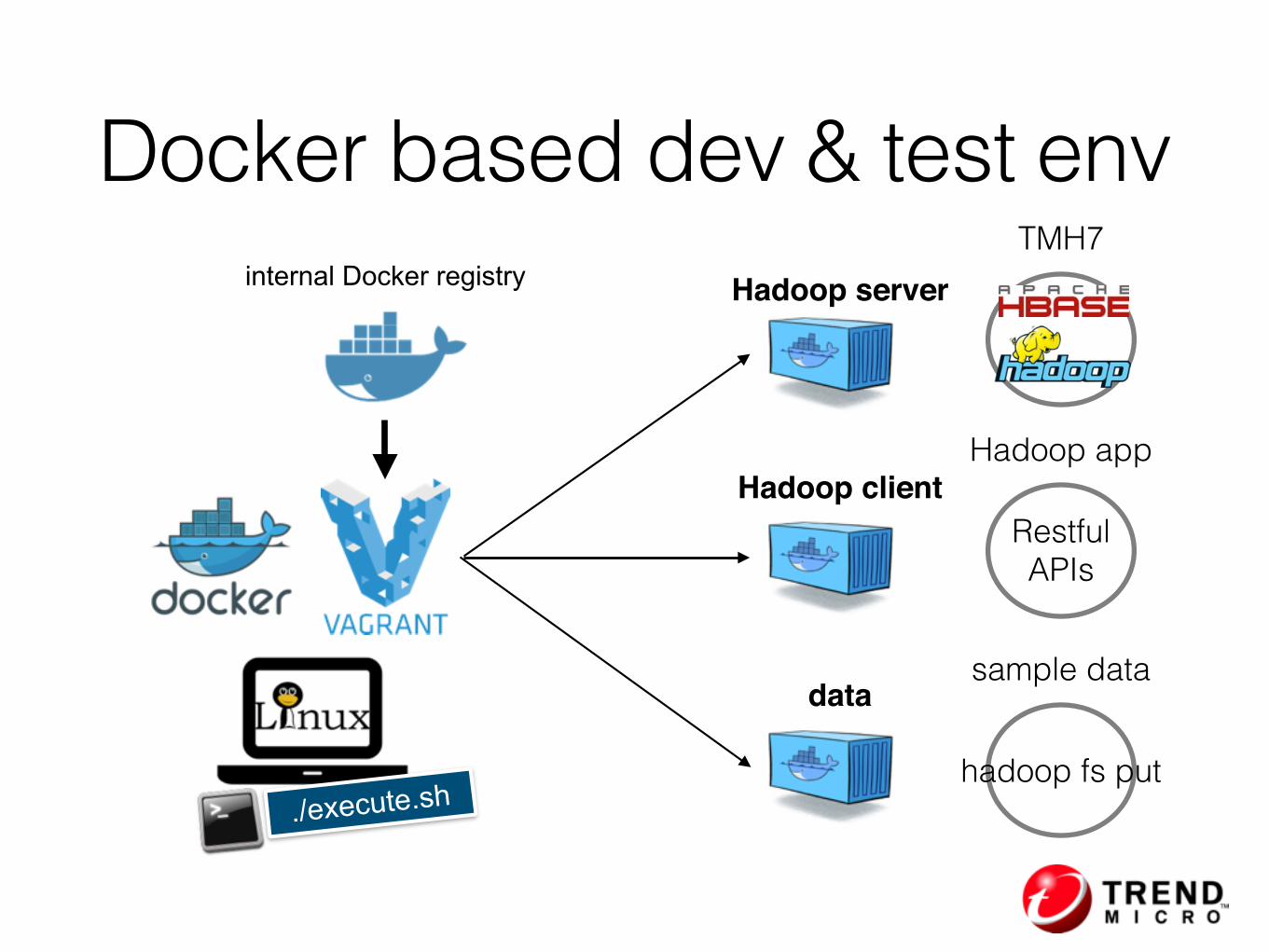
internal Docker registry
./execute.sh
Hadoop server
Hadoop client
data
Docker based dev & test envTMH7
Hadoop app
Restful APIs
sample data
hadoop fs put
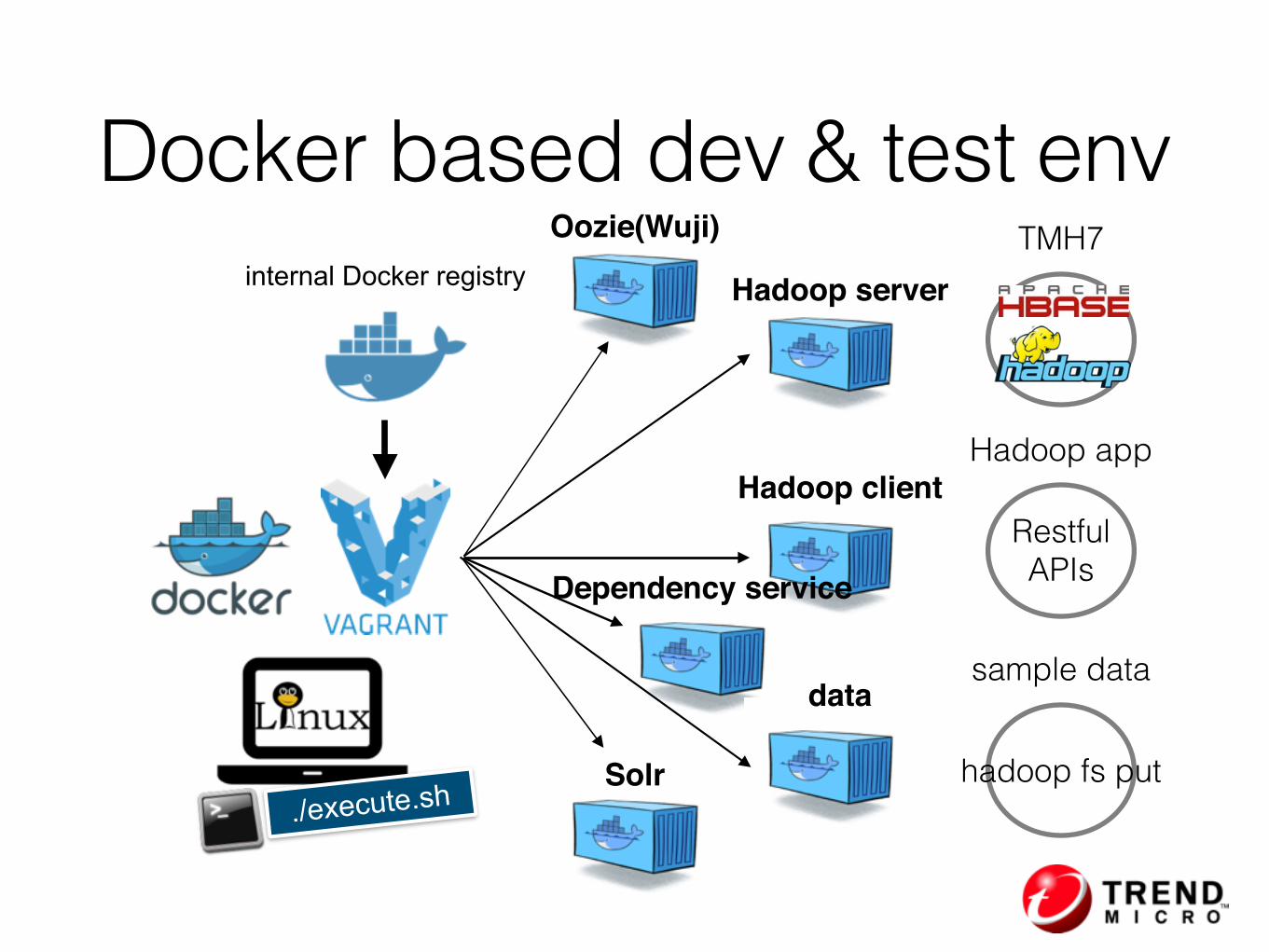
internal Docker registry
./execute.sh
Hadoop server
Hadoop client
data
TMH7
Hadoop app
Restful APIs
sample data
hadoop fs putSolr
Oozie(Wuji)
Dependency service
Docker based dev & test env

Mission-specific Platform

Use case• Real-time streaming data flows in
• Lookup external info when data flows in
• Detect threat/malicious activities on streaming data
• Correlate with other historical data (batch query) to gather more info
• Can also run batch detections by specifying arbitrary start time and end time
• Support Investigation down to raw log level

Lambda Architecture
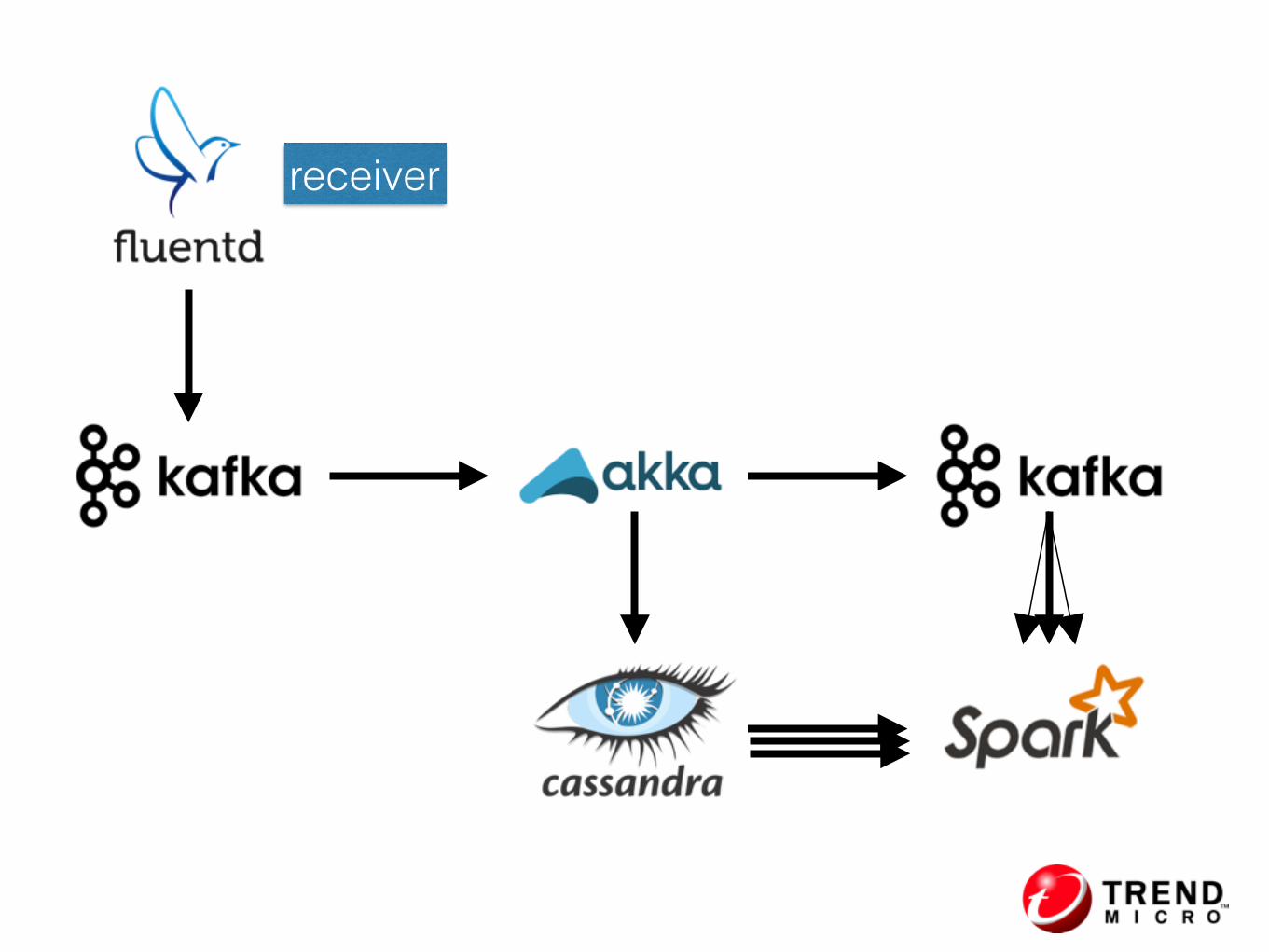
receiver
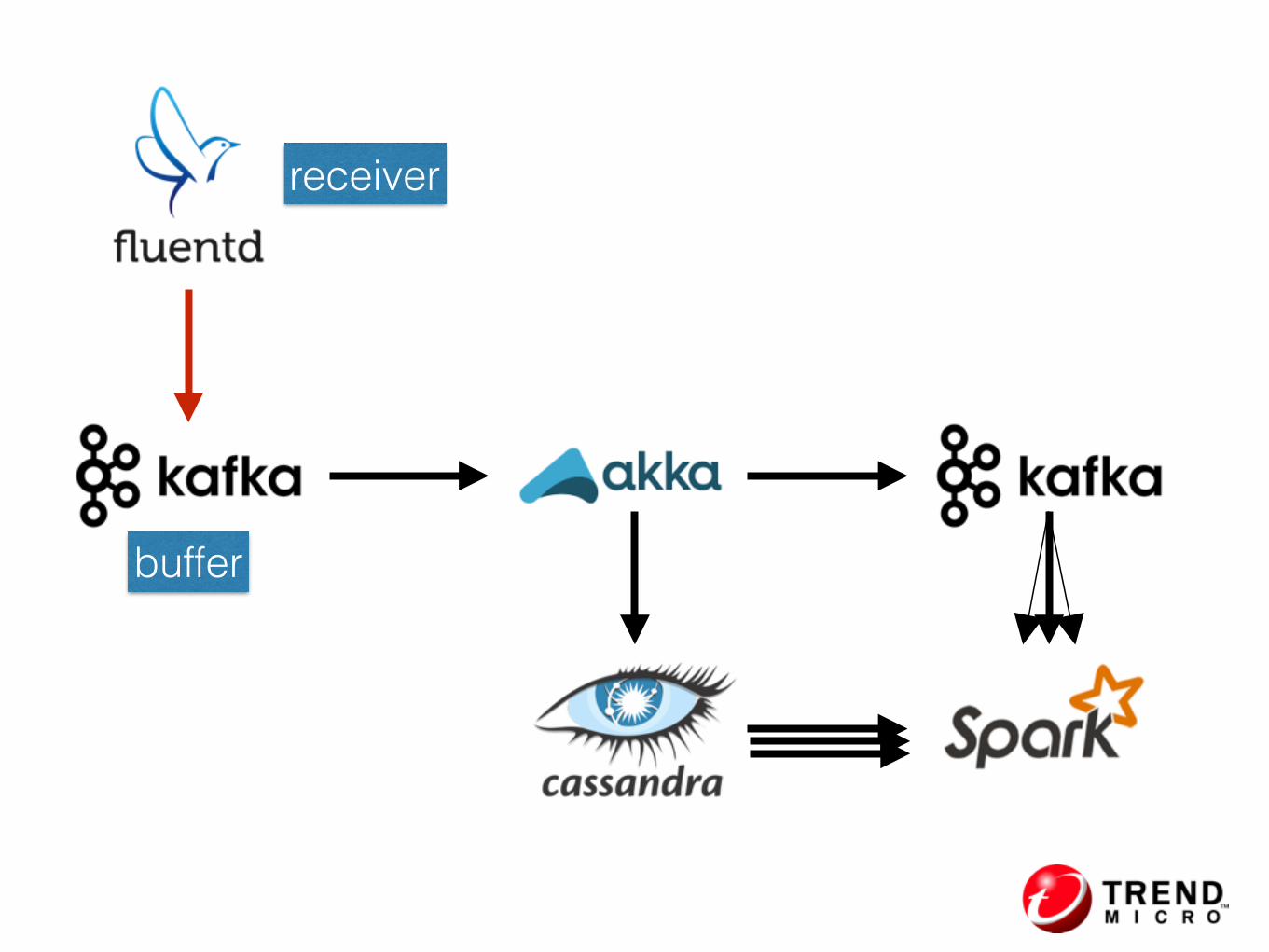
receiver
buffer
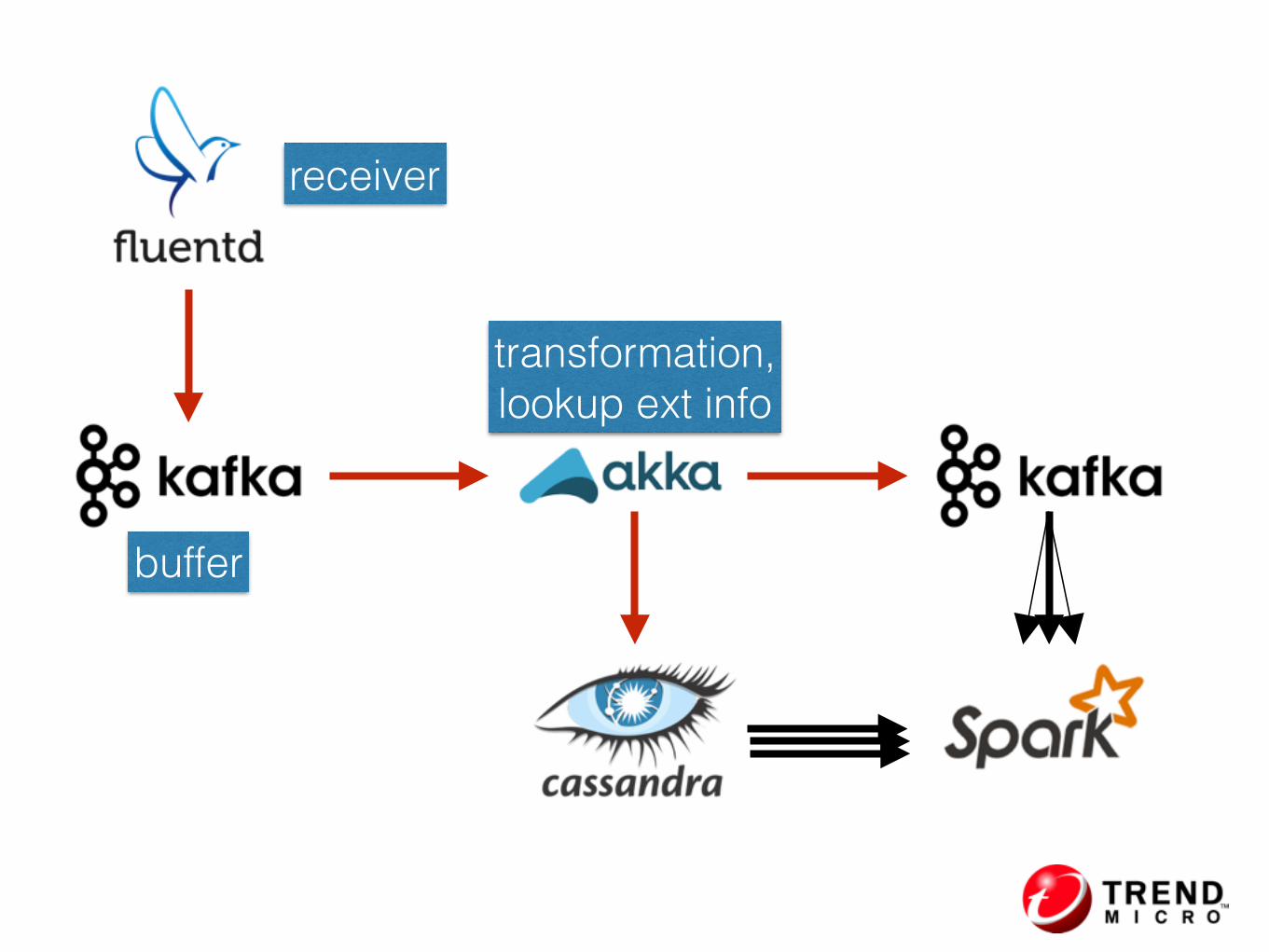
transformation, lookup ext info
receiver
buffer
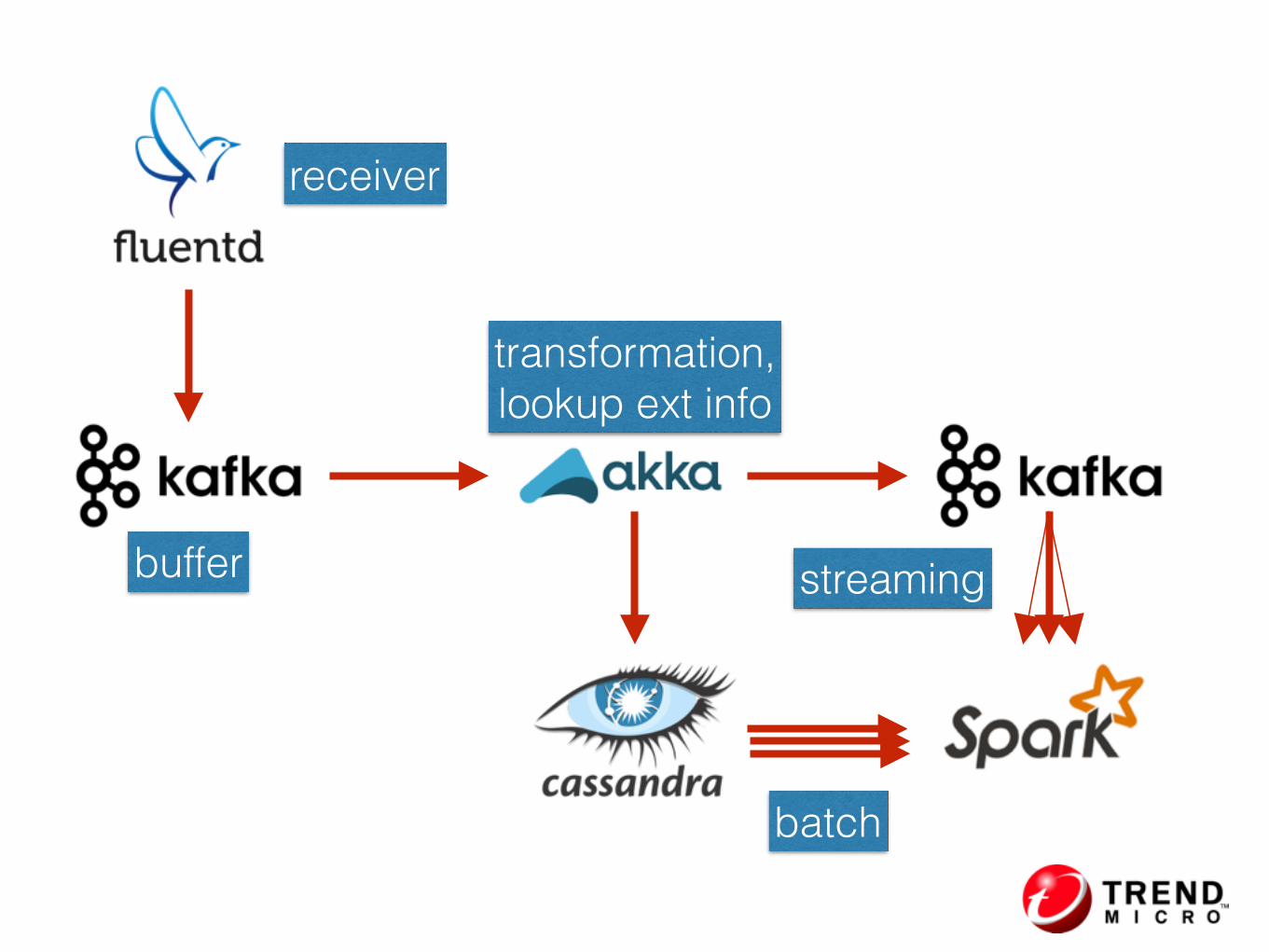
batch
streaming
receiver
buffer
transformation, lookup ext info
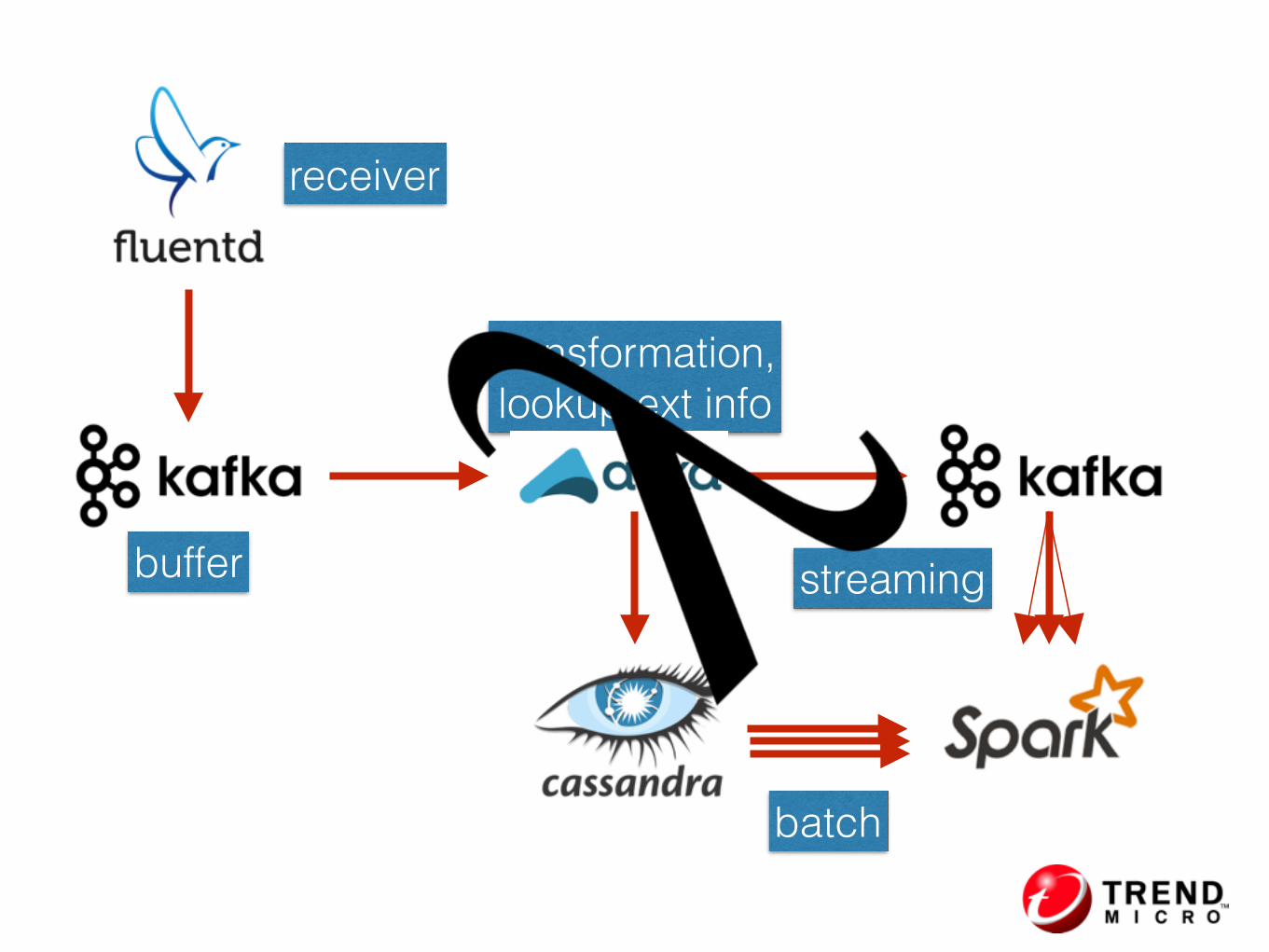
transformation, lookup ext info
batch
streaming
receiver
buffer

• High-throughput, distributed publish-subscribe messaging system
• Supports multiple consumers attached to a topic
• Configurable partition(shard), replication factor
• Load-balance within same consumer group
• Only consume message once a b c

• Distributed NoSQL key-value storage, no SPOF
• Super fast on write, suitable for data keeps coming in
• Decent read performance, if design it right
• Build data model around your queries
• Spark Cassandra Connector
• Configurable CA (CAP theorem)
• Choose A over C for availability and vise-versaDynamo: Amazon’s Highly Available Key-value Store
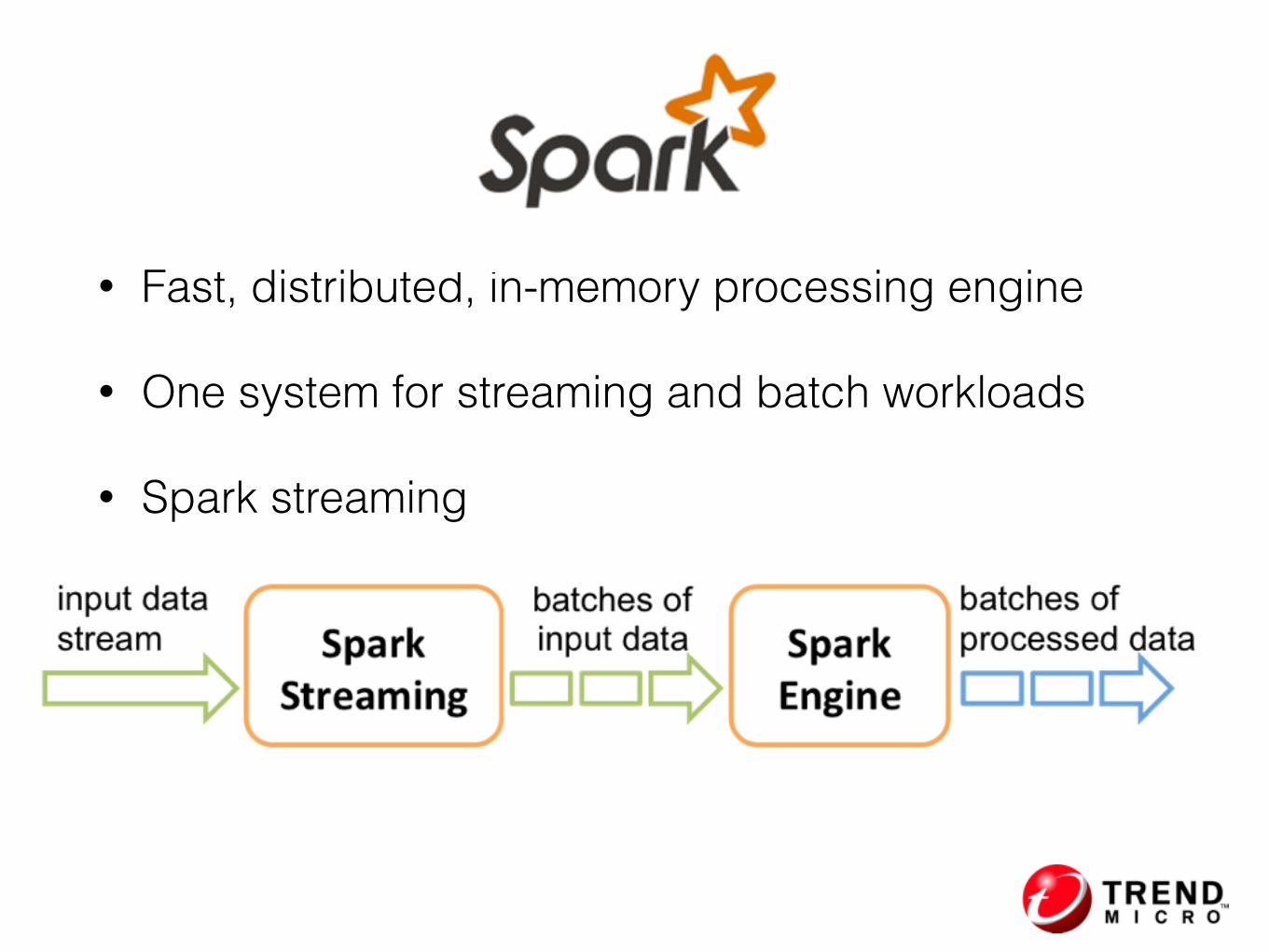
• Fast, distributed, in-memory processing engine
• One system for streaming and batch workloads
• Spark streaming

Akka• High performance concurrency framework for Java and Scala
• Actor model for message-driven processing
• Asynchronous by design to achieve high throughput
• Each message is handled in a single threaded context (no lock, synchronous needed)
• Let-it-crash model for fault tolerance and auto-healing system
• Clustering mechanism to scale out
The Road to Akka Cluster, and Beyond

Akka Streams• Akka Streams is a DSL library for streaming computation on Akka
• Materializer to transform each step into Actor
• Back-pressure enabled by default
Source Flow Sink
The Reactive Manifesto
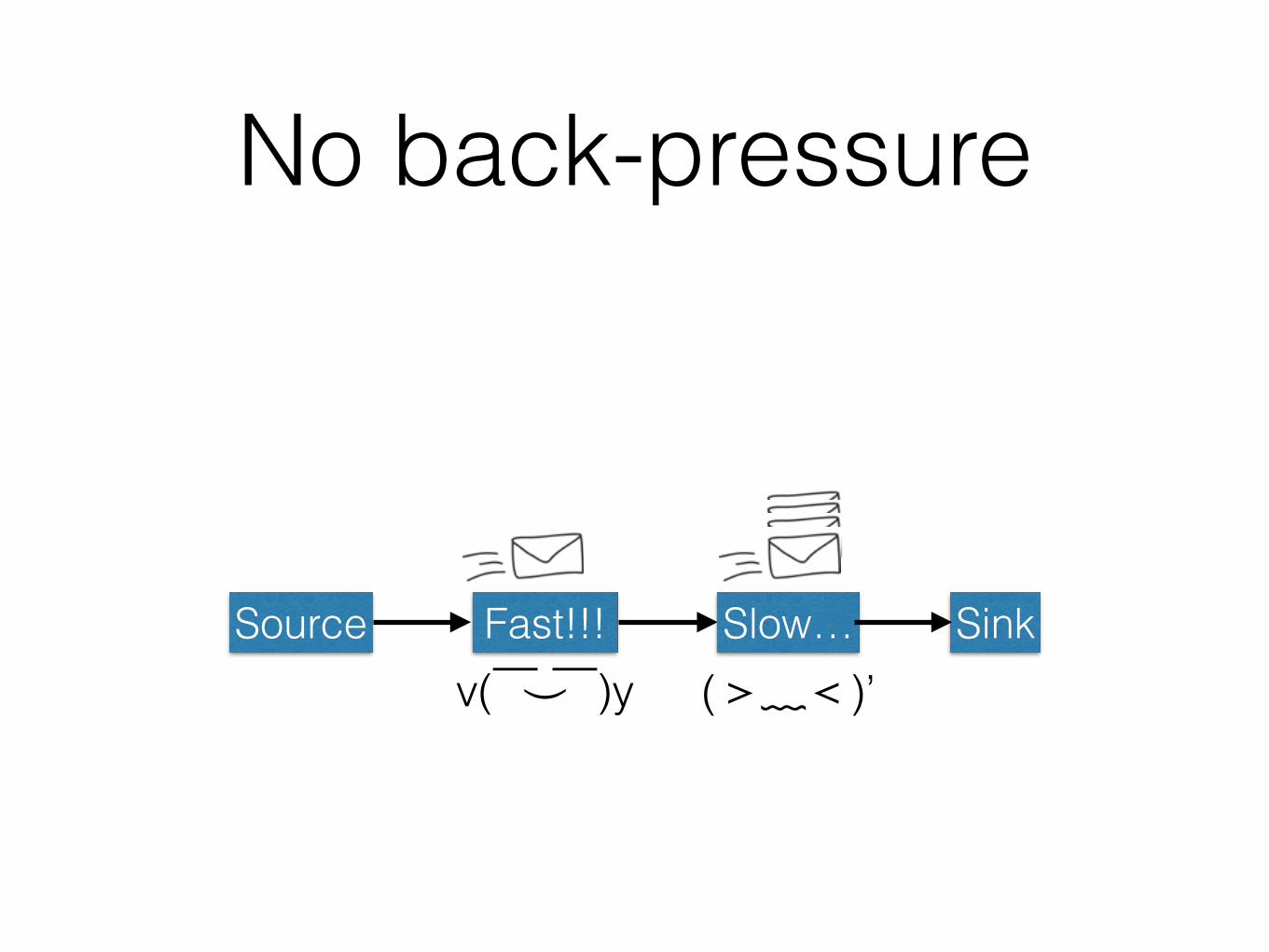
No back-pressure
Source Fast!!! SinkSlow…(>﹏<)’v( ̄︶ ̄)y
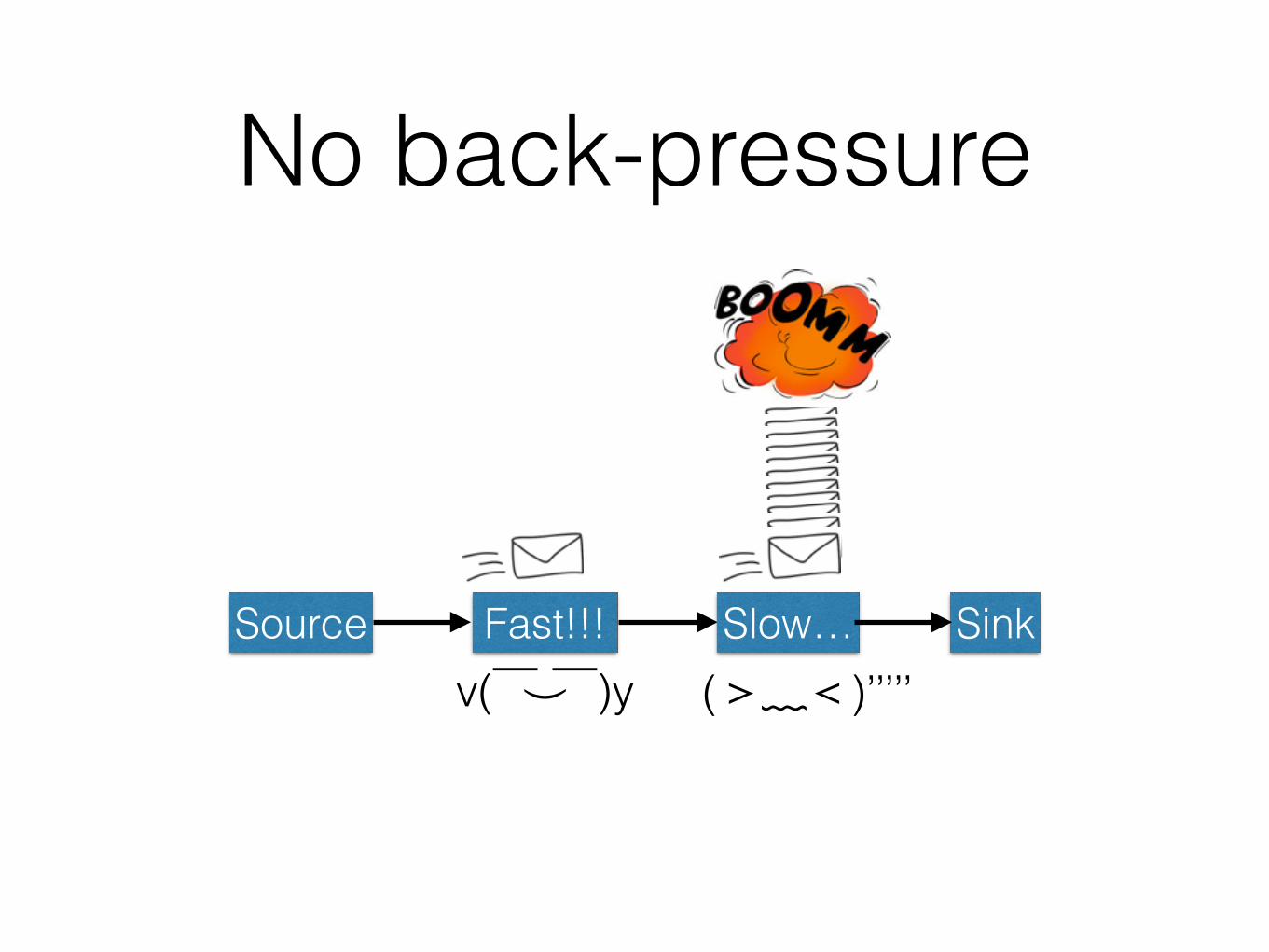
No back-pressure
Source Fast!!! SinkSlow…(>﹏<)’’’’’v( ̄︶ ̄)y
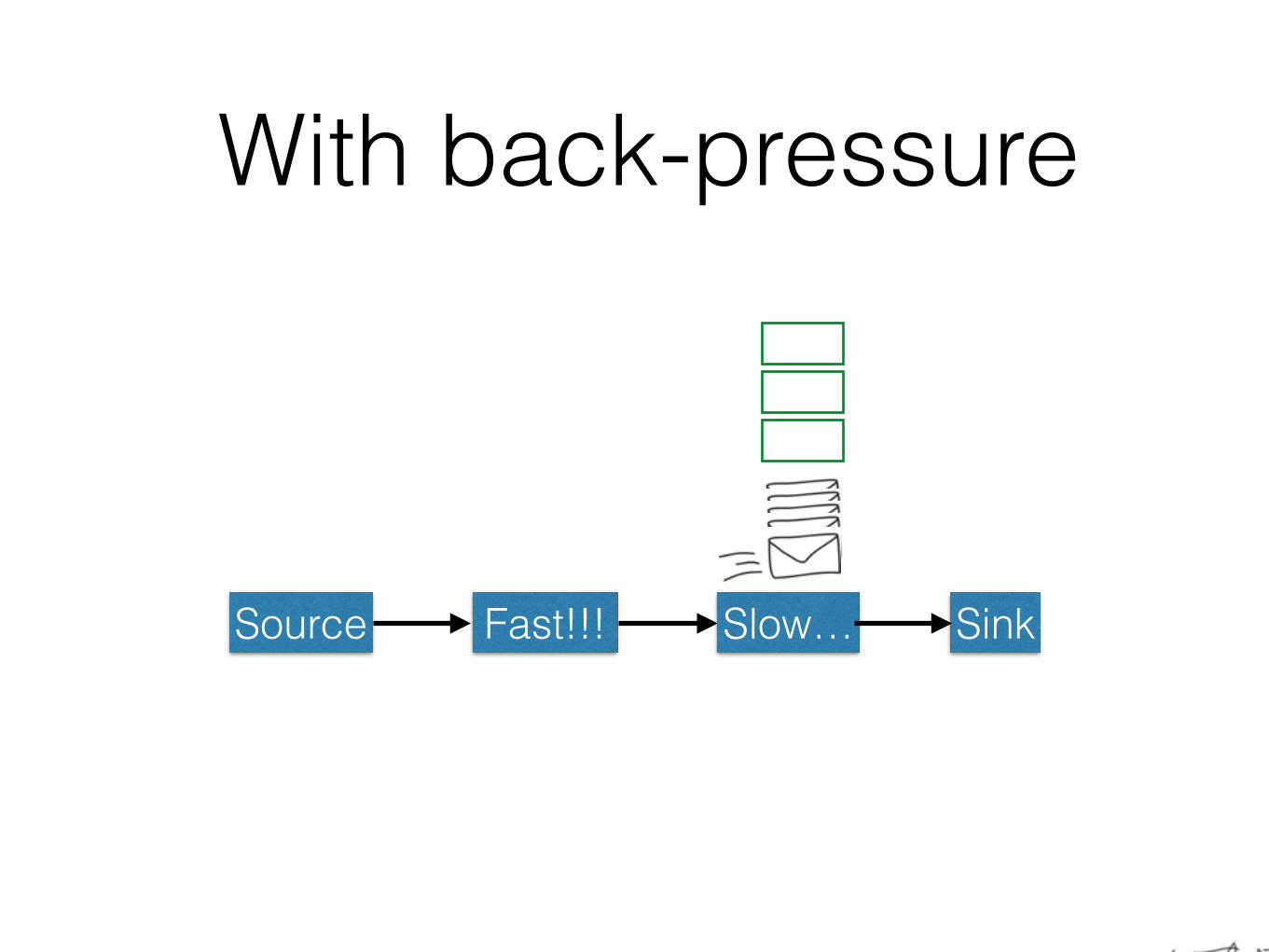
With back-pressure
Source Fast!!! SinkSlow…
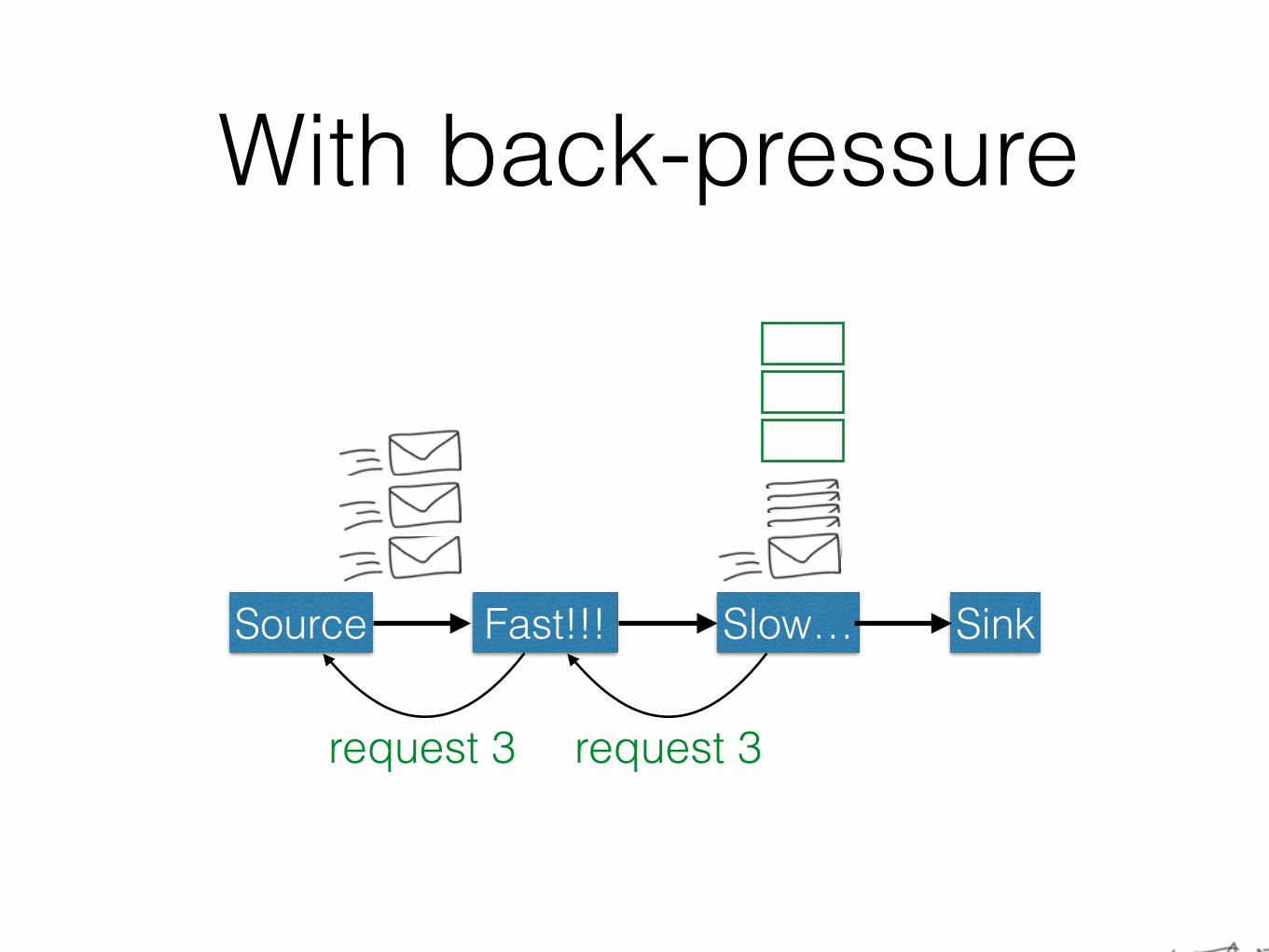
With back-pressure
Source Fast!!! SinkSlow…
request 3request 3

Data pipeline with Akka Streams• Scale up using balance and merge
source: http://doc.akka.io/docs/akka-stream-and-http-experimental/1.0/scala/stream-cookbook.html#working-with-flows
worker
worker
worker
balance merge
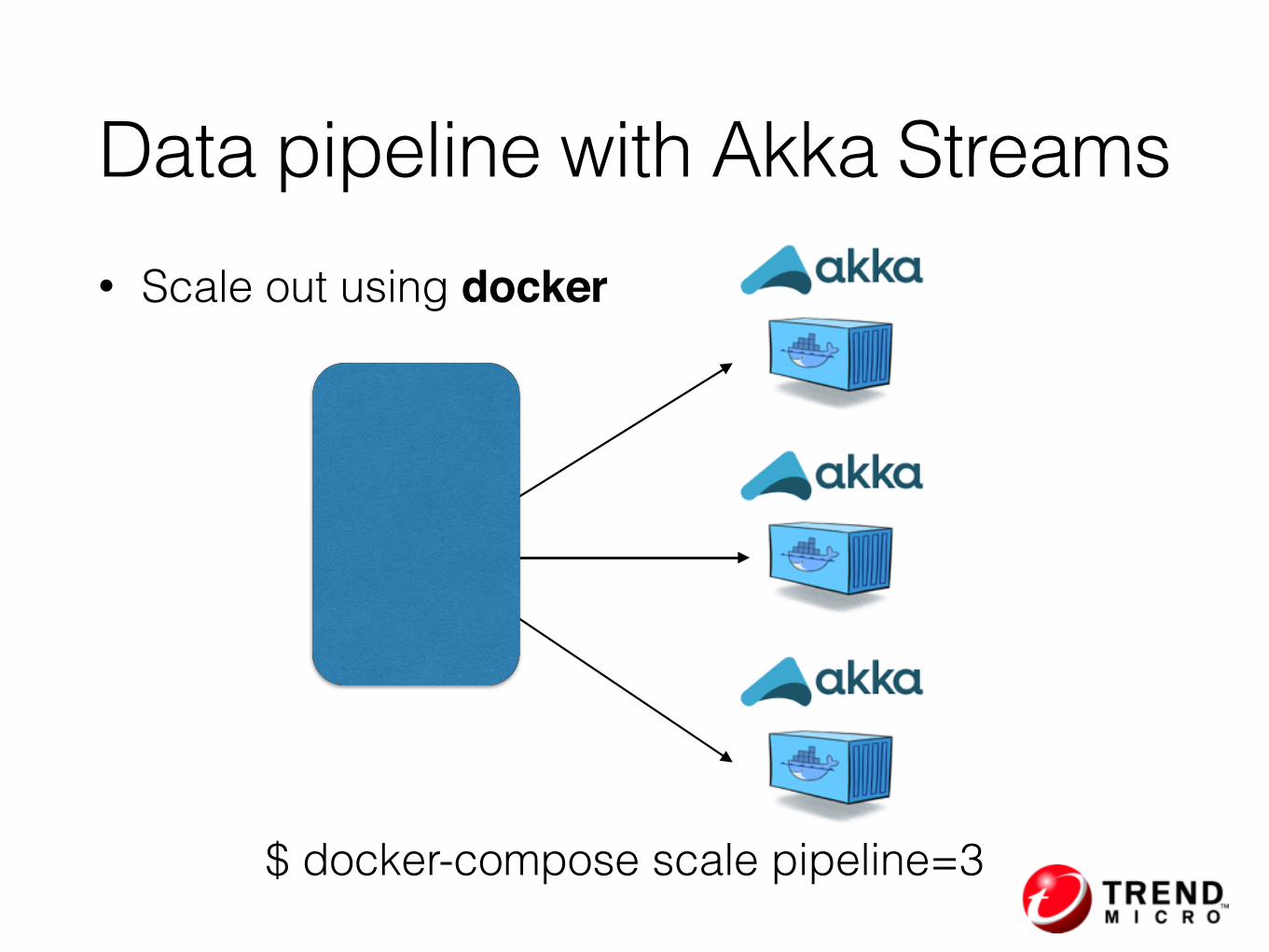
• Scale out using docker
Data pipeline with Akka Streams
$ docker-compose scale pipeline=3

Reactive Kafka • Akka Streams wrapper for Kafka
• Commit processed offset back into Kafka
• Provide at-least-once delivery guarantee
https://github.com/softwaremill/reactive-kafka

Message delivery guarantee• Actor Model: at-most-once
• Akka Persistence: at-least-once
• Persist log to external storage (like WAL)
• Reactive Kafka: at-least-once + back-pressure
• Write offset back into Kafka
• At-least-once + Idempotent writes = exactly-once

• Spark: both streaming and batch analytics
• Docker: resource management (fine for one app)
• Akka: fine-grained, elastic data pipelines
• Cassandra: batch queries
• Kafka: durable buffer, fan-out to multiple consumers
Recap: SDACK Stack

Your mileage may vary

we’re still evolving

Remember this:

The SMACK StackToolbox for wide variety of data processing scenarios

SMACK Stack• Spark: fast and general engine for large-scale data
processing
• Mesos: cluster resource management system
• Akka: toolkit and runtime for building highly concurrent, distributed, and resilient message-driven applications
• Cassandra: distributed, highly available database designed to handle large amounts of data across datacenters
• Kafka: high-throughput, low-latency distributed pub-sub messaging system for real-time data feeds
Source: http://www.slideshare.net/akirillov/data-processing-platforms-architectures-with-spark-mesos-akka-cassandra-and-kafka

Reference• Spark Summit Europe 2015
• Streaming Analytics with Spark, Kafka, Cassandra, and Akka (Helena Edelson)
• Big Data AW Meetup
• SMACK Architectures (Anton Kirillov)

Big Data Landscape

• Memory is faster than SSD/disk, and is cheaper
• In Memory Computing & Fast Data
• Spark : In memory batch/streaming engine
• Flink : In memory streaming/batch engine
• Iginte : In memory data fabric
• Geode (incubating) : In memory database
Big Data moving trend

• Off-Heap storage is a JVM process memory outside of the heap, which is allocated and managed using native calls.
• size not limited by JVM (it is limited by physical memory limits)
• is not subject to GC which essentially removes long GC pauses
• Project Tungsten, Flink, Iginte, Geode, HBase
Off-Heap, Off-Heap, Off-Heap
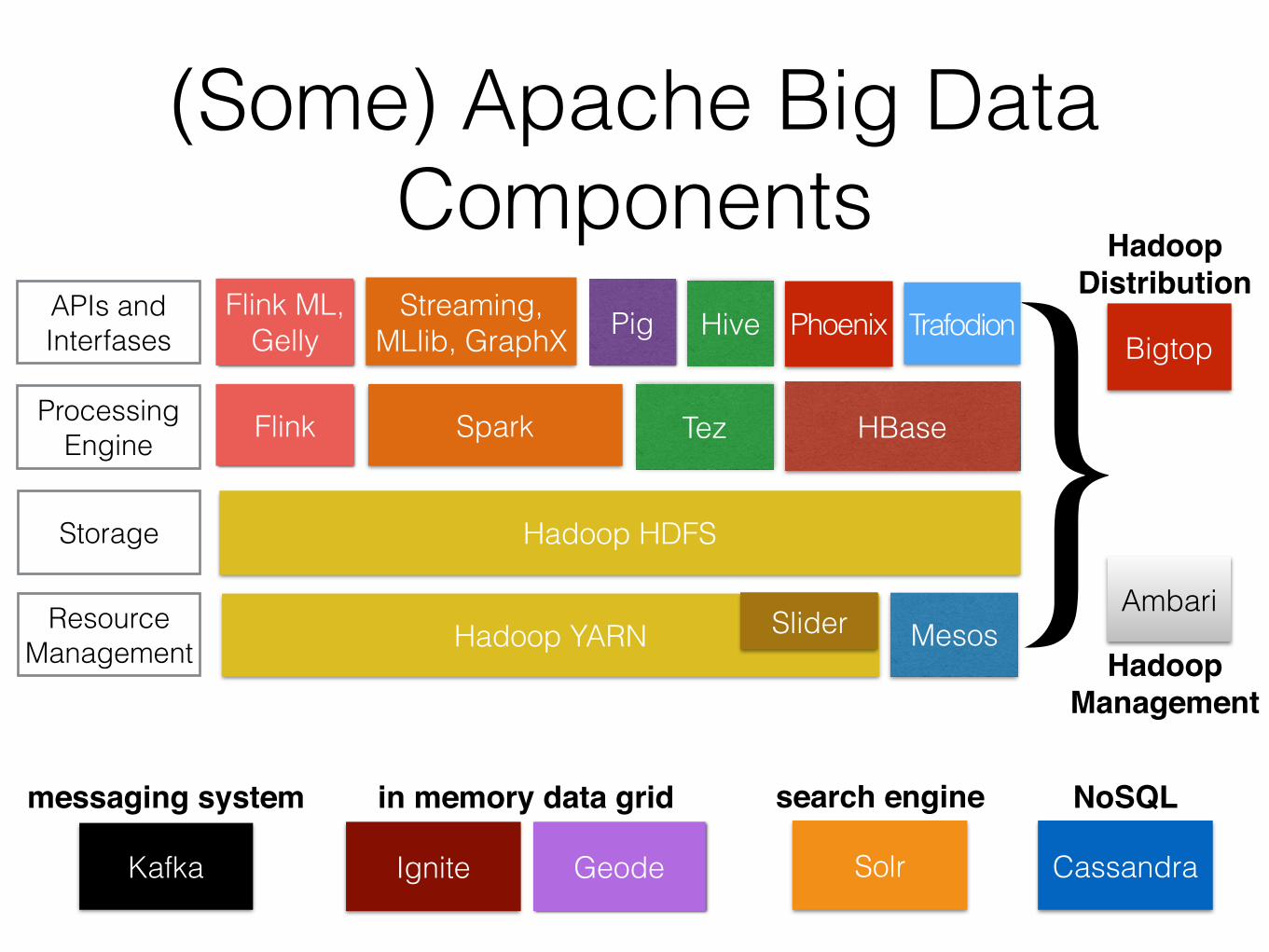
Pig
Hadoop YARN
Hadoop HDFS
Resource Management
Storage
Processing Engine
(Some) Apache Big Data Components
Slider
Flink Spark
Flink ML, Gelly
Streaming, MLlib, GraphX
Kafka
HBase
Mesos
Tez
Hive Phoenix
Ignite
APIs andInterfases
Geode
Trafodion
Solr
}messaging system in memory data grid search engine
Bigtop
Ambari
Hadoop Distribution
Hadoop Management
Cassandra
NoSQL

Bigtop 1.1 ReleaseJan, 2016, I expect…

Bigtop 1.1 Release• Hadoop 2.7.1
• Spark 1.5.1
• Hive 1.2.1
• Pig 0.15.0
• Oozie 4.2.0
• Flume 1.6.0
• Zeppelin 0.5.5
• Ignite Hadoop 1.5.0
• Phoenix 4.6.0
• Hue 3.8.1
• Crunch 0.12
• …, 24 components included!

Hadoop 2.6• Heterogeneous Storages
• SSD + hard drive
• Placement policy (all_ssd, hot, warm, cold)
• Archival Storage (cost saving)
• HDFS-7285 (Hadoop 3.0)
• Erasure code to save storage from 3X to 1.5Xhttp://www.slideshare.net/Hadoop_Summit/reduce-storage-
costs-by-5x-using-the-new-hdfs-tiered-storage-feature

Hadoop 2.7• Transparent encryption (encryption zone)
• Available in 2.6
• Known issue: Encryption is sometimes done incorrectly (HADOOP-11343)
• Fixed in 2.7
http://events.linuxfoundation.org/sites/events/files/slides/HDFS2015_Past_present_future.pdf

Rising star: Flink• Streaming dataflow engine
• Treat batch computing as fixed length streaming
• Exactly-once by distributed snapshotting
• Event time handling by watermarks

• Integrate and package Apache Flink
• Re-implement Bigtop Provisioner using docker-machine, compose, swarm
• Deploy containers on multiple hosts
• Support any kind of base image for deployment
Bigtop Roadmap

Wrap up

• Hadoop Distribution
• Choose Bigtop if you want more control
• The SMACK Stack
• Toolbox for variety data processing scenarios
• Big Data Landscape
• In-memory, off-heap solutions are hot
Wrap up

Questions ?
Thank you !