un nuovo algoritmo per il mining dei condensed colocation pattern
DESCRIPTION
Abstract:Il mining dei colocation pattern è stato studiato per diverse tipologie di applicazioni. Nonostante ciò, spesso tale processo porta alla generazione di un numero eccessivamente elevato di candidati. In molti contesti, è sufficiente o preferibile esaminare un'approssimazione del participation index invece di un valore esatto. Questa scelta determina un insieme di colocation pattern compatto, i cui elementi vengono definiti condensed colocation pattern. Lo scopo di questa tesi è quello di proporre un algoritmo per il mining dei condensed colocation pattern. Tale algoritmo viene messo a confronto con altri algoritmi per i colocation pattern presenti in letteratura, per analizzarne l'efficienza e la qualità dei risultati.[Tesi di Laurea per la laurea triennale in Informatica presso l'Università Ca' Foscari di Venezia]TRANSCRIPT

Corso di Laurea(ordinamento ex D.M. 270/2004)in Informatica
Tesi di Laurea
U N N U O V O A L G O R I T M O P E RI L M I N I N G D E I C O N D E N S E DC O L O C AT I O N PAT T E R N
relatore
Dott. Claudio Silvestri
laureando
Andrea LazzarottoMatricola 833897
anno accademico
2012/2013


U N N U O V O A L G O R I T M O P E R I L M I N I N G D E IC O N D E N S E D C O L O C AT I O N PAT T E R N
andrea lazzarotto
Dipartimento di Scienze Ambientali, Informatica e StatisticaUniversità Ca’ Foscari
VeneziaOttobre 2013

Andrea Lazzarotto: Un nuovo algoritmo per il mining dei condensed colo-cation pattern, © Ottobre 2013

At leve er ikke nok. . .solskin, frihed og en lille blomst må man have.
— Hans Christian Andersen
Vivere non è abbastanza. . .uno deve avere il sole, la libertà e un piccolo fiore.


A B S T R A C T
Il mining dei colocation pattern è stato studiato per diverse tipologiedi applicazioni. Nonostante ciò, spesso tale processo porta alla gene-razione di un numero eccessivamente elevato di candidati. In molticontesti, è sufficiente o preferibile esaminare un’approssimazione delparticipation index invece di un valore esatto. Questa scelta determi-na un insieme di colocation pattern compatto, i cui elementi vengonodefiniti condensed colocation pattern. Lo scopo di questa tesi è quellodi proporre un algoritmo per il mining dei condensed colocation pat-tern. Tale algoritmo viene messo a confronto con altri algoritmi per icolocation pattern presenti in letteratura, per analizzarne l’efficienzae la qualità dei risultati.
vii


R I C O N O S C I M E N T I
Ci sono state numerose persone che a vario titolo hanno influenzatoed aiutato il percorso che mi ha portato al raggiungimento di questotraguardo. Un sentito ringraziamento va a tutti coloro i quali credonoin me, a partire dai miei genitori che mi hanno sempre supportato epermesso di proseguire negli studi.
Ringrazio coloro i quali sono miei compagni di studi ma soprattut-to amici quotidiani, anche se sono troppi per essere nominati uno peruno, meriterebbero ciascuno una menzione personale. Un grazie dicuore va inoltre alla mia migliore amica Paola, a Nicolò, e agli altriamici sempre presenti nella mia vita.
Le esperienze vissute durante il mio corso di laurea sono state nu-merose e variegate, ma quella dell’Erasmus resterà sempre un ricordovivo e indelebile. Pertanto desidero ringraziare le persone conosciutead Aabenraa, tra cui Tana, Sergio, Henrik, Justina, Silja, Bettina e tuttigli altri. Grazie per quello che è stato il mese che mi ha fornito finorala più intensa esperienza umana e accademica di sempre.
Infine, ringrazio il Dott. Claudio Silvestri per il suo ruolo di super-visore nella mia attività di tirocinio, il quale ha avuto fiducia nel miolavoro per questa tesi.
Andrea
ix


I N D I C E
i il mining dei colocation pattern 1
1 descrizione del problema 3
1.1 Concetti basilari . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Enunciato del problema . . . . . . . . . . . . . . . . . . . . 5
1.3 Strategie utilizzate in letteratura . . . . . . . . . . . . . . . 6
2 maximal colocation pattern 9
2.1 Definizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Enunciato del problema . . . . . . . . . . . . . . . . . . . . 11
2.3 Algoritmo MAXColoc . . . . . . . . . . . . . . . . . . . . . 11
3 top-k closed colocation pattern 17
3.1 Definizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Enunciato del problema . . . . . . . . . . . . . . . . . . . . 18
3.3 Algoritmo TopKColoc . . . . . . . . . . . . . . . . . . . . . 18
ii il nuovo algoritmo 25
4 condensed colocation pattern 27
4.1 Un nuovo tipo di colocation pattern . . . . . . . . . . . . . 27
4.2 Enunciato del problema . . . . . . . . . . . . . . . . . . . . 29
4.3 Algoritmo e caratteristiche delle soluzioni . . . . . . . . . . 31
4.4 Vantaggi attesi . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 analisi dei risultati 35
5.1 Descrizione dei test . . . . . . . . . . . . . . . . . . . . . . . 35
5.2 Confronto con MAXColoc . . . . . . . . . . . . . . . . . . . 35
5.3 Confronto con TopKColoc . . . . . . . . . . . . . . . . . . . 40
6 conclusioni 43
iii appendice 45
a porzioni significative di codice 47
a.0.1 main.cpp . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
a.0.2 Metodo FPGrowth da FPTree.cpp . . . . . . . . . . . . . 53
bibliografia 55
xi

E L E N C O D E L L E F I G U R E
Figura 1.1 Un esempio di grafo formato da S e R . . . . . 4
Figura 2.1 Pre-elaborazione e transazioni [11] . . . . . . . 10
Figura 2.2 Generazione dei candidati [11] . . . . . . . . . 12
Figura 2.3 Pruning dei sottoinsiemi in MAXColoc [11] . . 13
Figura 3.1 Pruning dei candidati in TopKColoc [10] . . . 19
Figura 4.1 Esempio di partizionamento non univoco . . . 29
Figura 5.1 Rappresentazione dei nodi contenuti in D1 . . 36
Figura 5.2 Risultati dell’Esperimento 1 . . . . . . . . . . . 38
Figura 5.3 Risultati dell’Esperimento 2 . . . . . . . . . . . 38
Figura 5.4 Risultati dell’Esperimento 3 . . . . . . . . . . . 39
Figura 5.5 Risultati dell’Esperimento 4 . . . . . . . . . . . 41
Figura 5.6 Risultati dell’Esperimento 5 . . . . . . . . . . . 41
Figura 5.7 Risultati dell’Esperimento 6 . . . . . . . . . . . 42
E L E N C O D E L L E TA B E L L E
Tabella 2.1 Variabili di input per MAXColoc . . . . . . . . 14
Tabella 2.2 Simboli utilizzati in MAXColoc . . . . . . . . . 15
Tabella 3.1 Variabili di input per TopKColoc . . . . . . . . 20
Tabella 3.2 Simboli utilizzati in TopKColoc . . . . . . . . . 22
Tabella 4.1 Variabili di input per TopKCondensed . . . . . 32
E L E N C O D E G L I A L G O R I T M I
Algoritmo 2.1 MAXColoc . . . . . . . . . . . . . . . . . . . . . 14
Algoritmo 3.1 TopKColoc . . . . . . . . . . . . . . . . . . . . . 21
Algoritmo 4.1 TopKCondensed . . . . . . . . . . . . . . . . . . 33
xii

Parte I
I L M I N I N G D E I C O L O C AT I O N PAT T E R N


1D E S C R I Z I O N E D E L P R O B L E M A
L’attività di data mining consiste nell’estrazione di informazioni dauna grande quantità di dati. L’utilizzo sempre più diffuso dei sen-sori e degli strumenti di raccolta automatica dei dati ha portato allaproduzione sempre maggiore di grandi collezioni di dati spaziali [4].
Da ciò deriva il crescente interesse per l’estrazione di informazioniutili ma implicite e di conseguenza è necessario disporre di algoritmiche consentano di affrontare il problema in modo efficiente [9]. Inquesto capitolo vengono presentate le definizioni generali relative alproblema del mining dei colocation pattern e sono presentate diversesoluzioni presenti in letteratura.
I Capitoli 2 e 3 specializzano la trattazione discutendo due speci-fici algoritmi e la Parte ii della tesi illustra il nuovo tipo di patternproposto, nonché un algoritmo per estrarne le istanze.
1.1 concetti basilari
Il nostro interesse si concentra sulle relazioni che intercorrono tra leistanze di elementi (o categorie) E = {e1, e2, . . . , em}. Tali relazionisono derivanti dal fatto che gli oggetti sono posizionati nello spazio.Il modo in cui tali istanze compaiono frequentemente vicine dà luogoa delle regolarità dette colocation pattern. Si può in sintesi dire che uncolocation pattern è un’associazione che rappresenta la coesistenza diun insieme di oggetti con un certo rapporto di vicinanza [7].
Alcuni esempi di utilizzo dei colocation pattern includono lo studiodella relazione tra le sorgenti di acque stagnanti e le malattie infettive,l’analisi delle combinazioni dei prodotti acquistati più spesso insiemenei supermercati, o i servizi richiesti dagli utenti di reti mobili in unadeterminata area geografica [10].
I campi di applicazione di questo tipo di data mining sono vastissi-mi e includono problematiche relative a biologia, scienze della terra,salute pubblica, trasporti, geografia, ingegneria e altro [4, 12]. Di se-guito vengono definiti i termini fondamentali relativi al mining deicolocation pattern, similmente a quanto riportato in Bow [2].
evento spaziale Un elemento di interesse.
Un esempio potrebbe essere un tipico punto di interesse come unaereoporto o una scuola. Tuttavia si può trattare anche del verificarsidi un evento appartenente ad una certa categoria, come ad esempioil verificarsi di un caso di infezione da virus.
3

4 descrizione del problema
Figura 1.1: Un esempio di grafo formato da S e R
colocation Sono dati un insieme di eventi spaziali E, le corrispon-denti istanze S e una relazione di vicinanza R su S. Una colo-cation X è un insieme di eventi X ⊆ E le cui istanze forma-no frequentemente clique o, in altre parole, formano spesso deisottografi completi in riferimento alla relazione R.
La relazione R vige sull’insieme delle istanze S formando un grafonon orientato i cui nodi ni sono elementi di S e ciascun arco (ni, nj)
è presente se e solo se i nodi ni e nj sono vicini secondo R, ovverose la loro distanza massima è sotto ad una certa soglia, per esem-pio 200 metri. In Figura 1.1 è possibile vedere un esempio di daticon eventi I = {Bar, Parco, Scuola} e gli archi che indicano le coppiedi nodi vicini. In questo caso si individuano le seguenti colocation:{B, P} , {B, S} , {P, S} e {B, P, S}.
colocation instance Un’istanza I di una colocation X è un in-sieme di oggetti I ⊆ S il quale include tutti i tipi di evento di Xe forma una clique.
Per esempio, nella Figura 1.1 {B.1, S.1} e {B.3, S.2} sono istanze di{B, S} mentre l’insieme {B.1, S.2} non costituisce un’istanza valida. Illivello di prevalenza di una colocation instance è usualmente misura-to tramite il participation index [2, 9]. Tale valore viene anche definitosupporto [7, 8, 12].
participation index Questa misura viene indicata con PI(X), re-lativamente ad una colocation X, ed è definita come:
PI(X) = minei∈X{Pr(X, ei)}
Nella formula, Pr(X, ei) rappresenta il participation ratio di untipo di evento ei nella colocation X.

1.2 enunciato del problema 5
participation ratio In una colocation X, si definisce il participa-tion ratio di un evento ei come il rapporto tra gli oggetti di tipoei nelle vicinanze delle istanze di X− {ei}. In sintesi:
Pr(X, ei) =Num. di oggetti distinti di tipo ei nelle ist. di X
Numero di elementi di ei
Prendendo sempre ad esempio la Figura 1.1, è possibile vedere comel’evento B abbia tre oggetti, mentre gli eventi P ed S presentano dueoggetti ciascuno. La colocation X = {B, S} ha istanze {B.1, S.1} e{B.3, S.2}. È possibile quindi calcolare i valori di Pr(X, ei) relativi aciascun evento spaziale e di conseguenza il valore di PI(X).
In particolare, per quanto riguarda l’evento B, si ha che Pr(X, B) =23 mentre per S si ha che Pr(X, S) = 2
2 = 1. Ne consegue che PI(X) =
min{ 2
3 , 1}= 2
3 è il corretto valore del participation index di X. Comeverrà approfondito nella seguente sezione, una colocation X vieneconsiderata frequente se il valore di PI(X) risulta maggiore di unadeterminata soglia.
1.2 enunciato del problema
Lo scopo di questa sezione è descrivere il problema del mining dei co-location pattern nella sua forma più generale, senza perciò trattare diuno specifico tipo di pattern. Nel Capitolo 2 vengono descritti i max-imal colocation pattern, mentre il Capitolo 3 affronta i top-k closedcolocation pattern. La definizione del condensed colocation patternintrodotto in questa tesi segue nel Capitolo 4.
Il problema può essere formulato nel seguente modo [9, 11, 12]:
dati
1. Un insieme di eventi spaziali E = {e1, . . . , em}
2. Un dataset di oggetti S = S1 ∪ . . . ∪ Sm in cui Si è un in-sieme di oggetti con tipo di evento ei, ciascuno dei qua-li contiene informazioni relative al tipo di evento ei, unidentificatore univoco e la posizione nello spazio
3. Una relazione di vicinanza R
4. Una soglia di prevalenza minima θ
sviluppare Un algoritmo per trovare tutti i colocation pattern fre-quenti in modo efficiente e corretto.
condizioni
1. R è una relazione simmetrica e riflessiva
2. La misura di prevalenza (participation index) è monotona

6 descrizione del problema
Un approccio naïve per la risoluzione di questo problema consistenell’effettuare un vero e proprio processo di brute force. Innanzituttosi procede ad individuare tutte le istanze di colocation che formanodelle clique secondo la relazione R. Quindi viene calcolato il valoredi PI(X) per ogni colocation X e l’insieme dei risultati viene filtratodagli elementi per cui PI(X) < θ.
Un procedimento di questo tipo comporta l’analisi di circa 2m diver-si insiemi di eventi, dove m = |E|. Ciò si traduce in una complessitàdi tipo esponenziale che rende impraticabile il mining in presenza digrandi quantità di dati. Per questo motivo sono stati sviluppati diver-si algoritmi con lo scopo di rendere efficiente il mining dei pattern.La prossima sezione elenca le principali tecniche utilizzate.
1.3 strategie utilizzate in letteratura
Le numerose pubblicazioni a riguardo del mining dei colocation pat-tern hanno prodotto diversi algoritmi dediti a risolvere il problemausando varie strategie e ottimizzazioni, tuttavia la maggior parte diessi è basata su un principio basilare denominato proprietà dellamonotonicità del participation index [9]:
proprietà di monotonicità Si consideri una qualsiasi coloca-tion Y che sia sottoinsieme di una colocation X. Dalla defini-zione del participation index segue che:
Y ⊂ X ⇒ PI(Y) ≥ PI(X)
Da questo deriva che se X è frequente, anche Y lo è.
Tutti gli algoritmi di seguito descritto sfruttano almeno in parte lasuddetta proprietà allo scopo di cercare di ridurre al minimo gli in-siemi di eventi candidati che devono essere analizzati per individuarei colocation pattern frequenti. La lista non è esaustiva in quanto noncomprende tutte le varianti del problema, alcune delle quali sarannodiscusse successivamente. Tuttavia elenca delle metodologie generaliche possono essere adattate a dei possibili problemi derivati.
Apriori
Si tratta del primo algoritmo sviluppato per sfruttare la proprietà dimonotonicità, descritto in Agrawal and Srikant [1]. Per essere precisi,l’algoritmo si occupa del mining delle association rule, ovvero regoleformate da implicazioni della forma ex ⇒ ey dove ex e ey sono eventispaziali contenuti in E. Tali regole sono supportate da un livello diconfidenza. Nonostante questa differenza rispetto alle colocation, ilprincipio di Apriori è di fondamentale importanza in quanto costitui-sce la base della maggior parte degli algoritmi per il mining dei co-location pattern sviluppati successivamente. In breve, la generazione

1.3 strategie utilizzate in letteratura 7
dei candidati (definiti itemset) avviene tramite un processo iterativoche inizia dagli insiemi composti da un solo elemento, raccogliendoin L1 i risultati frequenti. In ogni successiva iterazione k, il contenu-to di Lk−1 viene usato come base per formare gli elementi frequentiLk combinando elementi più piccoli. L’unione di tutti questi risultatiintermedi costituisce l’insieme degli itemset frequenti.
Co-location miner
Questo algoritmo viene introdotto in Shekhar and Huang [9] e si ap-plica ai colocation pattern, che vengono definiti tramite una relazionedi vicinanza R invece di usare transazioni. L’algoritmo Apriori vie-ne adattato con l’implementazione di una nuova procedura chiama-ta generalized apriori_gen: ciò è necessario in quanto, pur sembrandosimili, il problema delle colocation è molto diverso da quello delleassociation rule.
Joinless colocation mining
La differenza di questa strategia consiste nell’assenza di operazioni dijoin, le quali sono dispendiose in termini di tempo di esecuzione ed èdescritto in Yoo and Shekhar [12]. Il grafo degli eventi spaziali vienepartizionato seguendo un modello a stella o in alternativa un modelloa clique. Vengono quindi estratti dei candidati da ciascuna partizionie vengono filtrate quelle che sono le vere colocation instance, da cuivengono derivate le colocation.


2M A X I M A L C O L O C AT I O N PAT T E R N
Le caratteristiche dell’algoritmo Apriori descritto nel Capitolo 1 pon-gono delle limitazioni sulla scalabilità del suo utilizzo nell’analisi deidati. In particolare, esso si dimostra poco adatto al mining su insie-mi di dati molto grandi oppure densi. In presenza di pattern moltolunghi, la generazione ed il test di tutti i sottoinsiemi è spesso impra-ticabile, perciò gli algoritmi basati su Apriori possono essere vincolatia limitarsi all’analisi di pattern corti [11].
Tuttavia, i pattern lunghi si presentano molto frequentemente neidataset densi e pertanto è necessario tenerli in considerazione. Lo svi-luppo di nuove strategie ha reso possibile il mining di vari tipi di pat-tern. Nella seguente sezione vengono introdotti i maximal colocationpattern, che consentono di rappresentare in forma concisa tutti i colo-cation pattern. Successivamente viene definito formalmente il proble-ma della loro ricerca e viene presentato in particolare l’algoritmo pereffettuarne il mining descritto in Yoo and Bow [11].
2.1 definizioni
Innanzitutto è necessario definire il tipo di pattern qui considerato:
maximal colocation Si consideri una colocation X. Se X è fre-quente ma non esiste alcuna colocation Y tale che X ⊂ Y e Y èfrequente, allora X viene definita una maximal colocation.
Intuitivamente, dalla proprietà di monotonicità deriva che il maximalcolocation pattern X è rappresentativo anche di tutti i suoi sottoin-siemi Z1, . . . , Zn ⊆ X, in quanto se X è frequente, anche ogni Zi lo è.Prima di esporre l’enunciato del problema e un algoritmo per risol-verlo, è opportuno introdurre anche un ulteriore concetto che verràpoi utilizzato anche nei Capitoli 3 e 4:
pruning dei sottoinsiemi Durante l’elaborazione dei dati, nelcaso in cui venga stabilito che una colocation X è frequente, vie-ne meno l’interesse per i suoi sottinsiemi Z1, . . . , Zn ⊂ X. Si sup-ponga di avere una lista di colocation candidate da analizzare:da quanto detto si evince che è possibile eliminare dai candida-ti ogni sottoinsieme di X, in quanto verificarne la frequenza èsuperfluo. Questo processo di eliminazione dei candidati vienedetto pruning.
I meccanismi utilizzati per effettuare il pruning possono influire inmaniera significativa sul tempo di esecuzione dell’algoritmo utilizza-
9

10 maximal colocation pattern
Figura 2.1: Pre-elaborazione e transazioni [11]
to. In particolare, conta molto il metodo per verificare rapidamente larelazione di sottoinsieme tra due colocation.
Nelle sezioni seguenti verrà illustrato come l’utilizzo di opportunestrutture dati permetta di ottimizzare tale processo ed eliminare icandidati superflui il prima possibile. Ciò ha lo scopo di ridurre lospazio di ricerca.
Oltre all’importanza di eliminare i sottoinsiemi in modo rapido,è di grande beneficio la possibilità di generare un insieme iniziale dipotenziali colocation candidate escludendo fin dall’inizio le clique chenon possono essere presenti nel grafo dei dati. Allo scopo, vengonointrodotti due concetti utilizzati in Yoo and Bow [10] nonché in Yooand Bow [11] e nell’algoritmo proposto nel Capitolo 4:
neighborhood transaction Dato un oggetto oi ∈ S, si defi-nisce neighborhood transaction l’insieme di istanze di eventispaziali:
NT(oi) = {oi} ∪{
oj ∈ S|R(oi, oj) ∧ tipo di oi 6= tipo di oj}
Dove R è la relazione di vicinanza.
event neighborhood transaction L’insieme di eventi distintiin una neighborhood transaction viene definito event neighbor-hood transaction.
Va notato che, mentre NT(oi) è unica per ciascun oi, ci possono esse-re più event neighborhood transaction che fanno riferimento ad unostesso tipo di evento.
Inoltre, tipicamente l’insieme delle event neighborhood transactionè più compatto di quello contenente le neighborhood transaction. LaFigura 2.1 mostra un dataset con le neighborhood transaction e leevent neighborhood transaction.
Si può vedere ad esempio che l’oggetto D.2 ha una relazione di vici-nanza con A.1, C.1 e E.1 e quindi NT(D.2) = {D.2, A.1, C.1, E.1}. Perconvenzione il primo elemento rappresentato nell’insieme è l’oggettoa cui si riferisce la neighborhood transaction.

2.2 enunciato del problema 11
2.2 enunciato del problema
La formulazione del problema dei maximal colocation pattern è unavariante del problema descritto nel Capitolo 1:
dati
1. Un insieme di eventi spaziali E = {e1, . . . , em}2. Un dataset di oggetti S = S1 ∪ . . . ∪ Sm in cui Si è un in-
sieme di oggetti con tipo di evento ei, ciascuno dei qua-li contiene informazioni relative al tipo di evento ei, unidentificatore univoco e la posizione nello spazio
3. Una relazione di vicinanza R
4. Una soglia di prevalenza minima θ
sviluppare Un algoritmo per trovare tutti i maximal colocationpattern in modo efficiente e corretto.
condizioni
1. R è una relazione simmetrica e riflessiva
2. La misura di prevalenza (participation index) è monotona
Anche tale variante può essere risolta in modo simile con un metodonaïve. Analogamente al problema generale, è necessario individuaretutte le istanze di colocation che formano delle clique secondo la rela-zione R. Quindi viene calcolato il valore di PI(X) per ogni colocationX, si eliminano gli elementi per cui PI(X) < θ e i rimanenti vengonoanalizzati per effettuare il pruning dei sottoinsiemi.
2.3 algoritmo maxcoloc
L’algoritmo MAXColoc è stato ideato da Yoo and Bow [11] partendodalla considerazione che la verifica di tutte le clique che avviene inApriori sia il punto debole in merito all’efficienza e che è necessa-rio considerare anche pattern lunghi per risolvere il problema dellemaximal colocation.
Il design dell’algoritmo è basato su una procedura divisa in quattroparti: pre-elaborazione, generazione dei candidati, pruning dei candi-dati, e filtraggio delle istanze. Di seguito vengono descritte le variefasi riassumendo quanto illustrato nel loro paper, e successivamenteviene presentato l’algoritmo in pseudo-codice.
Pre-elaborazione
Il primo passo consiste nel rappresentare il dataset come un grafo,i cui vertici sono gli oggetti (istanze di eventi spaziali) e gli archi

12 maximal colocation pattern
Figura 2.2: Generazione dei candidati [11]
collegano i nodi per cui vale la relazione R(oi, oj). In seguito, si ge-nera la neighborhood transaction per ciascun nodo e le relative eventneighborhood transaction, necessarie per una generazione efficientedei candidati.
Generazione dei candidati
L’idea di base per generare un insieme possibilmente ridotto di candi-dati è quella di evitare l’inclusione di insiemi che non possono avereuna relazione di clique. Prendendo ad esempio la Figura 2.1, si no-ta che l’insieme di eventi {A, D, E} non costituisce una colocation inquanto le istanze di tali eventi non formano nessuna clique. Cono-scendo anticipatamente i candidati da evitare, è possibile ridurre iltempo di elaborazione necessario.
Per tale motivo, le neighborhood transaction vengono combinateper ricavare solo candidati che potrebbero formare clique. L’algoritmoimpiega una struttura dati derivante dall’FP-Tree e utilizza l’algorit-mo FP-Growth [3]. L’FP-Tree è una struttura dati che viene costruitaper ogni tipo di evento ei ∈ E e rappresenta in forma compatta leevent neighborhood transaction che hanno ei come riferimento.
In Figura 2.2 è possibile vedere gli FP-Tree generati per ciascun ti-po di evento. Ogni nodo dell’albero contiene tre informazioni: tipo dievento, conteggio e node-link. Il conteggio è determinato dal numerodi event neighborhood transaction che attraversano il nodo, scenden-do a partire dalla radice. Il node-link è un puntatore che fa riferi-mento al prossimo nodo dell’albero con il medesimo tipo di evento.

2.3 algoritmo maxcoloc 13
Figura 2.3: Pruning dei sottoinsiemi in MAXColoc [11]
Questo tipo di FP-Tree riferito ad un tipo di evento viene definitodagli autori il candidate pattern tree dell’evento.
Gli insiemi di eventi con una soglia di supporto minimo vengonogenerati utilizzando l’algoritmo FP-Growth [3] e i risultati vengonodefiniti star candidate. Le istanze di star candidate presenti nell’in-sieme delle neighborhood transactions sono dette star instance. FP-Growth fornisce come output anche un valore di supporto per i risul-tati, il quale rappresenta un limite superiore del participation indexdella possibile clique.
Va notato che gli star candidate non sono necessariamente can-didati di colocation, in quanto bisogna prima verificare che possasussistere effettivamente una relazione di clique tra tutti gli elemen-ti dell’insieme. Ad esempio, l’insieme {A, B, C} può essere una co-location soltanto nel caso in cui tra gli star candidate compaiano{A, B, C}, {B, A, C} e anche {C, A, B}. In questo caso si dice che{A, B, C} costituisce un clique candidate.
Pruning dei candidati
Per effettuare il pruning, si suppone che gli elementi di E possano es-sere ordinati secondo un ordinamento totale ≥L (per esempio l’ordinelessicografico). Viene costruito un albero dei sottoinsiemi, nel qualegli elementi di dimensione k sono ordinati, come mostrato in Figura2.3. Di ciascun nodo si individuano la testa (rappresentata dal tipo dievento) e la coda (rappresentata dal tipo dei figli). Per esempio, il no-do Y ha testa A e coda {B, C, D, E} e l’unione di questi elementi vienedefinita HUT [11]. Nel caso specifico HUT(Y) = {A, B, C, D, E}.
L’albero viene attraversato in due diversi modi: l’approccio depth-first serve ad identificare rapidamente i candidati di lunghezza mag-giore, mentre l’approccio breadth-first è utilizzato per effettuare ilpruning. Una volta individuata una maximal colocation X, ogni no-do n dell’albero viene valutato. Se HUT(n) ⊆ X, l’albero di radice nviene eliminato.

14 maximal colocation pattern
nome descrizione
E = {e1, . . . , em} Insieme di tipi di eventi spazialiS Dataset di eventi spazialiR Relazione di vicinanzaθ Soglia di prevalenza minima
Tabella 2.1: Variabili di input per MAXColoc
Codice dell’algoritmo
L’Algoritmo 2.1 riporta lo pseudo-codice di MAXColoc [11]. Rispettoalla versione originale ci sono delle lievi differenze: la condizione delciclo while riporta solo k ≥ 2, in quanto indicare anche C 6= ∅ risul-ta ridondante. Inoltre la funzione find_clique_instances prende comeinput SIc invece di SIk.
Algoritmo 2.1 MAXColoc1: NP = find_neighbor_pairs(S, R)2: (NT, ENT) = gen_neighbor_transactions(NP)3: for i = 1 to m do4: Ti = build_candidate_pattern_tree(ei, ENT, θ)5: C = gen_candidates(T1, . . . , Tm)6: k = find_longest_size(C)7: while k ≥ 2 do8: Ck = get_k_candidates(C, k)9: SIk = find_star_instances(Ck, NT)
10: for each candidate c ∈ Ck do11: CIc = find_clique_instances(SIc, c, NP)12: pic = calcute_pi(CIc)13: if pic > θ then14: insert(c, Rk)15: R = R ∪ Rk16: C = C− Ck17: C = subset_pruning(Rk, C)18: k = k− 119: return R
La Tabella 2.1 indica il significato delle variabili di input, mentrein Tabella 2.2 è contenuto l’elenco di tutti i simboli utilizzati. Leprincipali parti dell’algoritmo sono così suddivise [11]:
pre-elaborazione (righe 1–2) Il dataset viene convertito in ungrafo verificando la relazione R tra le coppie di punti. Que-sto può avvenire in diversi modi, a seconda del tipo di distan-za utilizzata. Le neighborhood transaction vengono generateraggruppando i vicini di ciascun nodo.

2.3 algoritmo maxcoloc 15
nome descrizione
NT Insieme di neighborhood transactionENT Insieme di event neighborhood transactionNP Insieme di tutte le coppie di nodi viciniTi Candidate pattern tree dell’evento ei
k Dimensione dei candidati consideratiC Insieme di tutti i candidatiCk Insieme dei candidati di dimensione kpi Participation index
CIc Insieme delle istanze di clique di cSIc Insieme delle star instance di cSIk Insieme di tutti gli SIc per cui |c| = kR Insieme di maximal colocation patternRk Insieme di maximal colocation pattern di dimensione k
Tabella 2.2: Simboli utilizzati in MAXColoc
generazione dei candidati (righe 3–5) Si costruisce un can-didate pattern tree per ogni tipo di evento, e gli star candidatevengono estratti usando FP-Growth. Successivamente, vengonocombinati per ottenere i clique candidate.
selezione dei candidati di dim . k (righe 6–8) Il processo dimining inizia dal valore massimo di k e prosegue fino ai can-didati di dimensione 2. Vengono quindi estratti i candidati dilunghezza k.
individuazione delle star instance (riga 9) Tutte le neigh-borhood transaction vengono suddivise in gruppi e vengonoestratte le star instance. Esse vengono inserite nel relativo insie-me S Ic , in cui ogni c è un elemento di Ck . L’insieme contenentetutti gli S Ic del passo k è S Ik .
filtraggio delle clique (righe 10–14) Tutte le relazioni tra inodi interessati vengono esaminate per filtrare solo le effetti-ve clique. Ne viene quindi calcolato il valore del participationindex e vengono inserite nell’insieme Rk .
aggiornamento e pruning (righe 15–17) L’insieme dei risul-tati viene aggiornato e viene effettuato il pruning dei sottoinsie-mi con la tecnica dell’HU T .
insieme dei risultati finale (riga 19) Il processo viene itera-to fino a che k non raggiunge 2 o l’insieme C risulta vuoto.Infine viene restituito l’insieme R dei risultati.


3T O P - k C L O S E D C O L O C AT I O N PAT T E R N
La maggior parte degli algoritmi di mining dei colocation patternrichiede che l’utente specifichi in input una soglia minima θ per in-dicare i pattern desiderati. Tuttavia, è spesso difficile decidere anti-cipatamente la soglia di prevalenza minima senza una precedenteconoscenza delle caratteristiche del dataset da analizzare [10].
Questo motivo si aggiunge a quanto precedentemente discusso nelCapitolo 2 come ulteriore ragione per sviluppare alternative ad Aprio-ri. In questo capitolo viene introdotto il concetto di closed colocationed è descritto il processo di mining dei k pattern maggiormente pre-valenti. Infine viene illustrato l’algoritmo per il mining presentato inYoo and Bow [10].
3.1 definizioni
Di seguito verrà considerato il tipo di pattern così definito:
closed colocation Una colocation X è definita closed colocationse non esiste alcun sovrainsieme Y ⊃ X con lo stesso livello disupporto, vale a dire P I (Y ) = P I ( X ) .
Ad esempio, se P I ( { A , B } ) = 23 e P I ( { A , B , C } ) = 2
3 risultache { A , B } non è una closed colocation ma { A , B , C } potrebbeesserlo, nel caso in cui rispettasse la definizione. Da ciò ne derivache una closed colocation X è rappresentativa dei suoi sottoinsiemiZ 1 , . . . , Z n ⊆ X e inoltre la sua misura di supporto fornisce unlimite inferiore al supporto di ogni Z i .
Volendo escludere la soglia minima θ dai dati di input, è neces-sario definire l’insieme dei pattern di interesse. In particolare, vieneintrodotto il parametro k che indica la quantità di closed colocationda considerare:
top- k closed colocation Sia L la lista di tutte le closed coloca-tion, ordinate in modo decrescente secondo il loro participationindex. L’insieme delle top-k closed colocation è definito come:{X 1 , . . . , X k } .
La definizione qui riportata è differente da quella presentata in Yooand Bow [10], che si basa sul considerare tutte le closed colocationX i tali che P I ( X i ) ≥ P I ( X k ) . In questo caso infatti l’insieme con-siderato potrebbe contenere un numero di elementi maggiore di k inalcune circostanze. Tuttavia l’algoritmo di seguito presentato estraesempre al massimo k closed colocation.
17

18 top-k closed colocation pattern
3.2 enunciato del problema
Anche la formulazione del mining dei top-k closed colocation patternrappresenta una variante del problema descritto nel Capitolo 1:
dati
1. Un insieme di eventi spaziali E = {e1, . . . , em}
a) Un dataset di oggetti S = S1 ∪ . . . ∪ Sm in cui Si è un in-sieme di oggetti con tipo di evento ei, ciascuno dei qua-li contiene informazioni relative al tipo di evento ei, unidentificatore univoco e la posizione nello spazio
b) Una relazione di vicinanza R
c) Un numero k di pattern desiderati
sviluppare Un algoritmo per trovare i top-k closed colocation pat-tern in modo efficiente e corretto.
condizioni
1. R è una relazione simmetrica e riflessiva
2. La misura di prevalenza (participation index) è monotona
L’approccio naïve in questo caso consiste inizialmente nel trovare tut-te le istanze di colocation formanti delle clique secondo R e calcolarneil participation index. Quindi è necessario trovare tutte le closed colo-cation, ordinarle in modo decrescente a seconda del loro supporto edinfine restituire i primi k elementi della lista.
3.3 algoritmo topkcoloc
L’algoritmo TopKColoc è stato introdotto in Yoo and Bow [10]. Oltrealle considerazioni sui punti di debolezza di Apriori discusse nella Se-zione 2.3, un’altra differenza rispetto ad altri algoritmi di mining è lamancanza di una soglia minima di supporto θ, in quanto il parametrodi input è invece il numero k di pattern richiesti.
In questa sezione vengono descritti gli aspetti principali dell’algo-ritmo TopKColoc, riassumendo il contenuto del paper originale: pre-elaborazione, generazione dei candidati, mantenimento della sogliaminima, riutilizzo delle istanze e ricerca dei sottoinsiemi. Successiva-mente viene mostrato e commentato lo pseudo-codice dell’algoritmo.
Pre-elaborazione
Questa fase risulta del tutto analoga a quanto descritto nella Sezione2.3, riguardante l’algoritmo MAXColoc.

3.3 algoritmo topkcoloc 19
Figura 3.1: Pruning dei candidati in TopKColoc [10]
Generazione dei candidati
Anche TopKColoc utilizza una struttura derivante dall’FP-Tree e l’al-goritmo FP-Growth [3]. La principale differenza rispetto a quanto il-lustrato nella Sezione 2.3 è che in questo caso non viene utilizzataalcuna soglia di supporto minimo nella generazione dei candidati:tutte le transazioni vengono usate per creare l’albero. Anche in que-sto caso i risultati sono corredati da un limite superiore di supporto,il quale viene definito upper participation index.
Mantenimento della soglia minima
Nonostante la mancanza di una soglia in input, è possibile utilizzareun accorgimento per ridurre il numero di candidati analizzati. I candi-dati vengono inseriti in un albero detto candidate subset tree, in modosimile a quanto descritto nella Sezione 2.3 per il processo di pruning.Nell’albero è importante che ogni nodo contenga anche il valore del-l’upper participation index della colocation relativa al percorso dallaradice al nodo stesso.
Anche nel caso in cui l’insieme dei risultati sia pieno, è necessarioverificare se le k colocation sono closed colocation oppure no, perchéin caso contrario altre colocation potrebbero essere inserite nei risulta-ti. In questo caso torna utile mantenere un valore interno θ impostatoal participation index del k-esimo risultato. Nel caso in cui il candida-to successivo avesse un upper participation index inferiore, sarebbecompletamente inutile valutarne l’inserimento.
Inoltre, è possibile eliminare anche i sovrainsiemi di tale candida-to in base alla proprietà di monotonicità. Il valore di θ viene perciòutilizzato per eliminare i sottoalberi la cui radice abbia un upper par-ticipation index inferiore alla soglia. Questo meccanismo è visibile inFigura 3.1 e consente di ridurre in modo significativo i candidati cheè necessario analizzare.
Riutilizzo delle istanze
L’algoritmo attraversa il candidate subset tree un livello alla volta,a partire da l = 2, utilizzando lo schema di pruning e cercando le

20 top-k closed colocation pattern
nome descrizione
E = {e1, . . . , em} Insieme di tipi di eventi spazialiS Dataset di eventi spazialid Relazione di vicinanzak Numero di closed colocation richieste
Tabella 3.1: Variabili di input per TopKColoc
istanze di clique. Una volta trovate delle star instance, è necessarioverificare che si tratti effettivamente di clique.
Questo può essere effettuato nel modo descritto nella Sezione 2.3,tuttavia il processo può essere ottimizzato. Ciò è possibile in quantoal passo l sono già note le clique del livello l − 1 le quali possonoessere riutilizzate per verificare se la coda di una star instance fosseanche una colocation instance.
Ricerca dei sottoinsiemi
Se una colocation X possiede un participation index PI(X) > θ èpossibile inserirla all’interno della lista dei risultati. Nel fare ciò ènecessario verificare se sono già presenti dei sottoinsiemi di X conlo stesso participation index, e in tal caso essi devono essere rimossi.Al fine di evitare di allungare inutilmente il tempo di elaborazione,la relazione di sottoinsieme viene verificata solo per i risultati il cuiparticipation index sia effettivamente uguale a quello di X.
Codice dell’algoritmo
L’Algoritmo 3.1 riporta lo pseudo-codice di TopKColoc [10]. Il co-dice è stato leggermente modificato: alla riga 23 è stato inserito unbreak, al contrario di continue per ovviare ad una contraddizione conla descrizione testuale dello pseudo-codice. A ciò si aggiunge il fat-to che la funzione filter_clique_instances è stata utilizzata includendoCIl−1 nella firma, in modo da enfatizzare l’ottimizzazione riguardo alriutilizzo delle istanze.
La Tabella 3.1 indica il significato delle variabili di input, mentrein Tabella 3.2 è contenuto l’elenco di tutti i simboli utilizzati. Leprincipali parti dell’algoritmo sono così suddivise [10]:
pre-elaborazione (righe 1–2) Il dataset viene convertito in ungrafo verificando la relazione R, in modo analogo a quanto fattoper MAXColoc nella Sezione 2.3.
generazione dei candidati (righe 3–6) Si costruisce un can-didate pattern tree per ogni tipo di evento, e gli star candidate

3.3 algoritmo topkcoloc 21
Algoritmo 3.1 TopKColoc1: NP = find_neighbor_pairs(S, d)2: (NT, ENT) = gen_neighbor_transactions(NP)3: for i = 1 to m do4: Ti = build_candidate_pattern_tree(ei, ENT)5: C = gen_candidates(T1, . . . , Tm)6: calculate_upper_pi(C)7: R = ∅8: l = 29: θ = 0
10: while Cl 6= ∅ do11: Cl = sort_by_upper_pi(Cl)12: if |R| = k then13: prune_candidates(C, l, θ)14: if Cl = ∅ then15: break16: SIl = find_star_instances(Cl , NT)17: CIl = ∅18: for all c ∈ Cl do19: if |R| = k ∧ c.upper_pi < θ then20: prune_candidates(C, l, θ)21: break22: if l > 2 then23: CIc = filter_clique_instances(SIc, CIl−1)24: else25: CIc = SIc26: pi = calculate_true_pi(CIc)27: if |R| < k then28: subsets = find_sub_closed(R, c, pi)29: if subsets = ∅ then30: insert(c, pi, R)31: else32: replace(R, subsets, c, pi)33: else34: if θ < pi then35: subsets = find_sub_closed(R, c, pi)36: if subsets = ∅ then37: replace(R, R.last, c, pi)38: else39: replace(R, subsets, c, pi)40: θ = R.last.pi41: CIl = CIl ∪ CIc42: l = l + 143: return R

22 top-k closed colocation pattern
nome descrizione
NT Insieme di neighborhood transactionENT Insieme di event neighborhood transactionNP Insieme di tutte le coppie di nodi viciniTi Candidate pattern tree dell’evento ei
l Lunghezza delle colocationθ Soglia minima internaC Insieme di tutti i candidatiCl Insieme dei candidati di dimensione k
c.upper_pi Approssimazione del participation index di cpi Vero participation index
CIc Insieme delle istanze di clique di cCIl Insieme delle istanze di clique di dimensione lSIc Insieme delle star instance di cSIl Insieme di tutti gli SIc per cui |c| = l
subsets Insieme di sottoinsiemi closed di un candidatoR Insieme di top-k closed colocation pattern
R.last Ultimo risultato presente in R
Tabella 3.2: Simboli utilizzati in TopKColoc
sono estratti usando FP-Growth, senza utilizzare una soglia mi-nima. Infine i risultati estratti vengono combinati per ottenere iclique candidate. Viene calcolato l’upper participation index diciascuno di essi.
scelta dei candidati di dim . l (righe 7–15) Il mining ha ini-zio da l = 2 e la soglia interna θ viene impostata a 0. Se l’insie-me R è pieno, viene avviata una procedura di pruning primadel mining al passo l . Se un candidato possiede un upper par-ticipation index maggiore di θ , tutti i suoi sottoinsiemi vengonoeliminati dall’insieme C l .
raccolta delle star instance (riga 16) Le istanze candida-te vengono estratte dall’insieme delle neighborhood transaction.
verifica della terminazione (righe 18–21) Se l’insieme R èpieno durante l’elaborazione del passo l , i candidati rimanentisubiscono una verifica dell’upper participation index. Se unodi essi presenta un valore inferiore a θ , i rimanenti vengonoeliminati e l’esecuzione salta al passo l + 1.
filtraggio delle clique (righe 22–26) Le vere clique vengo-no filtrate e si procede al calcolo del loro participation index.

3.3 algoritmo topkcoloc 23
aggiornamento dei risultati (righe 27–40) La modalità diaggiornamento dipende da R: se non è pieno, la colocation vie-ne inserita, sostituendo eventuali sottoinsiemi con lo stesso par-ticipation index. Se invece R è pieno, la colocation viene inseritasoltanto se ha un supporto maggiore di R .last, sostituendo glieventuali sottoinsiemi oppure R .last stesso. Il valore di θ vienequindi aggiornato.
insieme dei risultati finale (riga 43) Il processo viene itera-to fino a che non viene raggiunto un valore di l per cui Cl = ∅.Infine viene restituito l’insieme R dei risultati.


Parte II
I L N U O V O A L G O R I T M O


4C O N D E N S E D C O L O C AT I O N PAT T E R N
Nella Parte i è stato illustrato il mining dei colocation pattern da di-versi punti di vista e tramite varie strategie. In particolare, nei Capitoli2 e 3 la trattazione ha riguardato due varianti del problema aventi loscopo di ridurre l’insieme dei pattern risultanti. Questo avviene con-siderando soltanto determinate colocation scelte specificamente peressere rappresentative anche dei loro sottoinsiemi.
Nonostante queste soluzioni riescano a ridurre l’insieme dei risul-tati, entrambe sono comunque basate su una misura esatta del va-lore del supporto. Nella pratica, accade molto spesso che esistanocolocation con minime differenze negli elementi e nel participationindex. In questo caso, può essere sufficiente o preferibile esamina-re un’approssimazione della frequenza, invece di un valore esatto [8].Tale scelta può consentire l’eliminazione di diversi pattern ridondanti,permettendo di ottenere una lista di risultati più compatti.
Nelle seguenti sezioni viene introdotta una nuova tipologia di pat-tern che consente una approssimazione controllata del participationindex. Il problema del loro mining è presentato formalmente ed infineè descritto l’algoritmo che è stato sviluppato per risolverlo. Il Capito-lo 5 è invece dedicato all’analisi dei test effettuati su alcuni dataset eil Capitolo 6 contiene le conclusioni.
4.1 un nuovo tipo di colocation pattern
L’idea di effettuare il mining di colocation con una misura di sup-porto approssimata è in parte basata sul lavoro di Pei et al. [8]. Intale articolo gli autori si occupano dell’estrazione di pattern frequen-ti dai database transazionali e forniscono alcune possibilità per ladefinizione di una frequenza approssimata dei pattern. Tuttavia, ilproblema del mining dei colocation pattern è diverso dal precedente,a partire dal fatto che la misura di supporto viene definita tramite ilparticipation index.
Lo scopo di questa tesi è di definire il concetto di supporto approssi-mato per i colocation pattern e fornire un algoritmo che ne permettail mining. Prima di illustrare le nuove definizioni, è opportuno uti-lizzare un esempio, al fine di comprendere le motivazioni per cui èdesiderabile approssimare il supporto.
Si supponga di dover analizzare un dataset spaziale dal quale estrar-re i colocation pattern maggiormente frequenti e che due colocationsiano X = {A, B, C} con PI(X) = 30% e Y = {A, B, C, E} con PI(Y) =28.7%. I participation index sono qui indicati sotto forma percentua-
27

28 condensed colocation pattern
le. Molto spesso l’analista è interessato al significato dei dati e alleprevalenze che ne derivano, piuttosto che al calcolo del supporto conprecisione estrema. In questo caso, se ad esempio si tollera un erroreentro il 2%, risulta evidente che X può essere scartata dai risultati, inquanto essa è rappresentata da Y.
È possibile quindi definire il tipo di pattern trattato:
condensed colocation pattern Un condensed colocation pat-tern P è un insieme rappresentato da una colocation X e includeanche alcuni sottoinsiemi di X. In esso si individua un interval-lo di frequenza delimitato da estremi denominati PIlb e PIub. Inparticolare i sottoinsiemi Zi ⊆ X da considerarsi nel contestodel pattern P rispettano le seguenti condizioni:
1. Zi ∈ P⇒ PI(Zi) ≤ PI(X) + δ
2. PI(Zi) > PI(X) ∧ Zi /∈ P⇒ ∃Q|Zi ∈ Q
3. ∀Zi ∈ P [PIlb ≤ PI(Zi) ≤ PIub], in particolare poniamo:
a) PIlb = min {PI(Zi)|Zi ∈ P} = PI(X)
b) PIub = max {PI(Zi)|Zi ∈ P}
Dove δ è la massima approssimazione consentita e Q è un con-densed colocation pattern.
Dalla definizione deriva immediatamente che se Zi ⊂ X non fa par-te del condensed colocation pattern P rappresentato da X, esso saràincluso in un altro condensed colocation pattern Q. È facilmente ve-rificabile dalla proprietà di monotonia del participation index che siavrà P.PIub < Q.PIub.
L’utilizzo di questo intervallo ci consente di derivare informazioniapprossimate sulla frequenza delle colocation a partire dai patterntrovati. Supponiamo ad esempio che il processo di mining con δ = 2%produca tra i risultati il pattern {A, B, C, E} [28.7%, 30%] e si desideraricavare la frequenza della colocation W = {A, B, E}. Ci sono due casimutualmente esclusivi:
1. 28.7% ≤ PI(W) ≤ 30% e possiamo stimare il participationindex di W entro la tolleranza prefissata
2. W appare come sottoinsieme di un altro pattern nel dataset1, ilquale ha un valore di PIub maggiore
Da quanto mostrato deriva che estraendo i condensed colocation pat-tern si ottiene una rappresentazione compatta delle colocation fre-quenti. Inoltre, per avere una stima del participation index di W èsufficiente trovare il pattern con il valore di PIub maggiore tra tutti
1 Per semplicità si parla di W come un sottoinsieme del pattern P, tuttavia sarebbeformalmente più preciso specificare che si parla dell’eventuale relazione tra W e lacolocation X; la quale rappresenta il pattern P.

4.2 enunciato del problema 29
{A, B} [50%] {A, B, C, D} [46%]
{A, B, C} [48%] {A, B, C, D, E} [44%]
(a) Elenco delle closed colocation
{A, B, C, D} [46%, 50%]
{A, B, C, D, E} [44%, 44%]
(b) Partizionamento dall’alto
{A, B} [50%, 50%]
{A, B, C, D, E} [44%, 48%]
(c) Partizionamento dal basso
Figura 4.1: Esempio di partizionamento non univoco
quelli di cui W è sottoinsieme. La seguente sezione descrive il pro-blema del mining e della suddivisione delle colocation in condensedcolocation pattern, secondo la definizione precedentemente data.
4.2 enunciato del problema
Per quanto riguarda il processo di mining e partizionamento delle co-location in condensed colocation pattern, si verifica facilmente che lascelta della metodologia di suddivisione non è univoca [8]. Si prendaad esempio in considerazione un dataset le cui colocation sono indi-cate in Figura 4.1a, assieme al relativo supporto. Per semplicità sonomostrate solo le closed colocation, senza indicare tutti i sottoinsiemicon il medesimo supporto.
Le Figure 4.1b e 4.1c mostrano due possibili partizionamenti del da-taset con δ = 5%, i quali si possono definire rispettivamente dall’altoe dal basso. Intuitivamente, è possibile osservare come la suddivisionecambi a seconda di quali colocation vengono considerate per prime,perciò ce n’è può essere più di una.
Il partizionamento dall’alto viene effettuato considerando prima lecolocation di dimensione inferiore e successivamente estendendo icondensed colocation pattern assimilando i sovrainsiemi che rientra-no nella misura di approssimazione consentita. Nel prosieguo dellatrattazione verrà considerato questo tipo di partizionamento.
Tale scelta ha un vantaggio costruttivo in quanto permette di usareun algoritmo simile a TopKColoc, presentato nel Capitolo 3. Inoltre, ilpartizionamento dall’alto permette anche di ottenere una migliore ap-prossimazione del participation index delle colocation con frequenzamaggiore, come è possibile vedere nell’esempio.
Questo consente di effettuare una scelta simile a quella del miningdei top-k colocation pattern: permettere all’utente di indicare il nu-mero desiderato di pattern, senza specificare una soglia di supportominimo che in determinati contesti può essere difficile da prevede-re. È opportuno quindi definire un concetto analogo per i condensedcolocation pattern:

30 condensed colocation pattern
top-k condensed colocation pattern Sia L la lista di tutti iclosed colocation pattern selezionati partizionando le colocationdall’alto. Inoltre, si richiede che L sia ordinata in modo decre-scente secondo il valore di PIub. L’insieme dei top-k condensedcolocation pattern è definito come: {X1, . . . , Xk}.
La differenza importante tra le top-k closed colocation e i top-k con-densed colocation pattern riguarda la rappresentatività dei risultati.Infatti, mentre nel caso delle closed colocation si ha una corrispon-denza uno-a-uno tra risultato e closed colocation, un condensed co-location pattern potrebbe essere rappresentativo di più di una closedcolocation considerata secondo le definizioni date nel Capitolo 3.
Inoltre in generale un condensed colocation pattern ha la possibilitàdi aggregare un maggior numero di colocation. Questo deriva dalfatto che si tollera un margine di errore nel valore del participationindex. Il problema di mining qui considerato può essere formalizzatonel seguente modo:
dati
1. Un insieme di eventi spaziali E = {e1, . . . , em}
a) Un dataset di oggetti S = S1 ∪ . . . ∪ Sm in cui Si è un in-sieme di oggetti con tipo di evento ei, ciascuno dei qua-li contiene informazioni relative al tipo di evento ei, unidentificatore univoco e la posizione nello spazio
b) Una relazione di vicinanza R
c) Un numero k di pattern desiderati
d) Un valore δ rappresentante l’errore massimo sul participa-tion index
sviluppare Un algoritmo per trovare i top-k condensed colocationpattern in modo efficiente e corretto.
condizioni
1. R è una relazione simmetrica e riflessiva
2. La misura di prevalenza (participation index) è monotona
Il problema può essere risolto in modo naïve trovando tutte le istan-ze di colocation formanti clique e calcolandone il participation index.Successivamente è necessario filtrare i risultati individuando i con-densed colocation pattern partendo dai risultati di dimensione mini-ma. Infine i pattern vanno ordinati secondo PIub e i primi k vengonoprodotti come output.

4.3 algoritmo e caratteristiche delle soluzioni 31
4.3 algoritmo e caratteristiche delle soluzioni
L’algoritmo qui presentato, chiamato TopKCondensed, è una varian-te di TopKColoc, il quale è stato presentato nel Capitolo 3. Oltre alparametro k rappresentante il numero di condensed colocation pat-tern richiesti, l’adattamento necessita anche del parametro δ. Que-st’ultimo rappresenta la tolleranza massima che può essere accettatanell’effettuare l’accorpamento delle colocation.
Le fasi principali dell’algoritmo sono le stesse di TopKColoc: pre-elaborazione, generazione dei candidati, mantenimento della sogliaminima, riutilizzo delle istanze e ricerca dei sottoinsiemi.
Pre-elaborazione
Questa fase risulta del tutto analoga a quanto descritto nella Sezione2.3, riguardante l’algoritmo MAXColoc.
Generazione dei candidati
La fase di generazione dei candidati è invece totalmente affine allapropria corrispettiva in TopKColoc, come descritta nella Sezione 3.3.
Mantenimento della soglia minima
Il valore interno della soglia minima θ richiede una gestione più ac-curata: è necessario infatti considerare che i pattern contenuti nellalista dei risultati sono forniti di due valori limitanti l’intervallo disupporto, ovvero [PIlb, PIub]. Per questo motivo, effettuare il pruningin modo non accurato può portare all’eliminazione di candidati chepotrebbero invece essere inseriti in qualche pattern.
Chiamando R.last l’ultimo elemento della lista dei risultati, in Top-KCondensed alla fine della valutazione di ciascun candidato si im-posta θ = R.last.PIub − δ e il pruning viene effettuato rispetto allecolocation X con PI(X) < θ. In alcuni casi è possibile introdurreun’ottimizzazione che permette il pruning di un numero maggiore dicandidati, come sarà possibile vedere nello pseudo-codice presentatosuccessivamente nella trattazione.
Riutilizzo delle istanze
Anche TopKCondensed utilizza le informazioni acquisite al livellol − 1 per verificare rapidamente le clique di livello l, similmente aquanto mostrato per TopKColoc nella Sezione 3.3.

32 condensed colocation pattern
nome descrizione
E = {e1, . . . , em} Insieme di tipi di eventi spazialiS Dataset di eventi spazialid Relazione di vicinanzaδ Massima tolleranza sul participation indexk Numero di closed colocation richieste
Tabella 4.1: Variabili di input per TopKCondensed
Ricerca dei sottoinsiemi
Riguardo alla ricerca dei sottoinsiemi di un candidato X da inserire,non devono essere considerati soltanto i candidati con lo stesso par-ticipation index. Nel caso di TopKCondensed è necessario verificareogni risultato Yi per cui X.PIub − δ ≤ PI(Yi) ≤ X.PIlb, dove la par-te destra della disuguaglianza deriva dalla proprietà di monotonicità.Va notato che nel caso in cui δ = 0 si ottiene:
Yi.PIub − 0 ≤ PI(X) ≤ Yi.PIlb ⇒ Yi.PIub ≤ PI(X) ≤ Yi.PIlb
(def.→ Yi.PIub ≥ Yi.PIlb)⇒ Yi.PIlb ≤ PI(X) ≤ Yi.PIlb
⇒ PI(X) = Yi.PIlb
Dato che il pattern Yi rappresentato da W ha una tolleranza pari azero, ne deriva che PI(W) = Yi.PIlb = Yi.PIub. Questa è esattamentela condizione esaminata da TopKColoc. Quindi se δ = 0 l’algoritmoTopKCondensed è equivalente a TopKColoc.
Codice dell’algoritmo
L’Algoritmo 4.1 riporta lo pseudo-codice di TopKCondensed, mentrela Tabella 4.1 indica il significato delle variabili di input. I simboli uti-lizzati nel codice sono essenzialmente gli stessi di TopKColoc, comeindicati nella Tabella 3.2.
Le principali parti dell’algoritmo presentano numerose analogiecon quanto discusso nel Capitolo 3, tuttavia ci sono alcune fonda-mentali differenze:
pruning (righe 13–16 e 23–26) Come è stato descritto in prece-denza, normalmente il pruning dei candidati riguardarebbe lecolocation X con PI(X) < θ. Tuttavia, nel caso in cui l’elementoR.last abbia lunghezza pari a l, è impossibile che sia un sot-toinsieme della colocation c. Per tale motivo, e grazie al fattoche le colocation sono valutate in ordine decrescente secondoil participation index, è possibile effettuare un pruning con so-

4.3 algoritmo e caratteristiche delle soluzioni 33
Algoritmo 4.1 TopKCondensed1: NP = find_neighbor_pairs(S, d)2: (NT, ENT) = gen_neighbor_transactions(NP)3: for i = 1 to m do4: Ti = build_candidate_pattern_tree(ei, ENT)5: C = gen_candidates(T1, . . . , Tm)6: calculate_upper_pi(C)7: R = ∅8: l = 29: θ = 0
10: while Cl 6= ∅ do11: Cl = sort_by_upper_pi(Cl)12: if |R| = k then13: if R.last.size < l then14: prune_candidates(C, l, θ)15: else16: prune_candidates(C, l, R.last.PIlb)17: if Cl = ∅ then18: break19: SIl = find_star_instances(Cl , NT)20: CIl = ∅21: for all c ∈ Cl do22: if |R| = k ∧ c.upper_pi < θ then23: if R.last.size < l then24: prune_candidates(C, l, θ)25: else26: prune_candidates(C, l, R.last.PIlb)27: break28: if l > 2 then29: CIc = filter_clique_instances(SIc, CIl−1)30: else31: CIc = SIc32: pi = calculate_true_pi(CIc)33: if |R| < k then34: subsets = find_sub_closed(R, c, pi, δ)35: if subsets = ∅ then36: insert(c, pi, R)37: else38: replace(R, subsets, c, pi)39: else40: if θ < pi then41: subsets = find_sub_closed(R, c, pi, δ)42: if subsets = ∅ then43: replace(R, R.last, c, pi)44: else45: replace(R, subsets, c, pi)46: θ = R.last.PIub − δ47: CIl = CIl ∪ CIc48: l = l + 149: return R

34 condensed colocation pattern
glia R.last.PIlb ≥ θ. Questa operazione comporta una potenzialeriduzione dei candidati da valutare.
ricerca dei sottoinsiemi (righe 34 e 41) È necessario utiliz-zare anche il valore di δ nella chiamata alla funzione.
aggiornamento della soglia (riga 46) Anche in questo casosi tiene conto della tolleranza massima.
Soluzioni prodotte
L’output prodotto dall’esecuzione di TopKCondensed è formato dauna lista R dei top-k closed colocation pattern presenti nel dataset.Tali pattern sono ordinati in modo decrescente secondo il valore delrispettivo PIub. Per ogni pattern viene visualizzata la colocation chelo rappresenta e l’intervallo di frequenza [PIlb, PIub].
La rappresentazione dei k pattern non consente soltanto di stimareil supporto delle colocation rappresentative, bensì permette anche diottenere informazioni sulla frequenza di qualsiasi sottoinsieme di talicolocation. Per calcolare approssimativamente il participation indexdi una colocation X, è sufficiente trovare il minimo indice i per cuiX ⊆ Yi ∈ R. Si avrà che Yi.PIlb ≤ PI(X) ≤ Yi.PIub con 1 ≤ i ≤ k.
4.4 vantaggi attesi
In base alla definizione di condensed colocation pattern data nellaSezione 4.1, è atteso che l’insieme dei risultati prodotti da TopKCon-densed sia maggiormente compatto e rappresentativo rispetto all’ese-cuzione di TopKColoc. Con ciò si intende che a parità di k, la tolleran-za δ permette di ottenere una lista più significativa di pattern, i qualicontengono informazioni su un numero maggiore di colocation. Inol-tre, l’approssimazione consente l’eliminazione di pattern sostanzial-mente ridondanti. Tale effetto aumenta con l’aumentare di δ, ovveroriducendo la precisione.
Per quanto riguarda l’algoritmo MAXColoc, ci si aspetta che Top-KCondensed fornisca informazioni sulle stesse colocation in modopiù preciso, in particolare in riferimento al valore del supporto. Que-sto perché l’algoritmo qui proposto garantisce un tasso d’errore mas-simo nella misurazione del participation index, mentre MAXColocconsente solo di ottenerne un limite inferiore.

5A N A L I S I D E I R I S U LTAT I
Per effettuare delle verifiche qualitative sulla precisione dei dati estrat-ti tramite l’algoritmo TopKCondensed sono stati effettuati alcuni test,i quali sono descritti in questo capitolo. L’osservazione dei rispettivirisultati consente di apprezzare le differenze tra l’algoritmo propostoe rispettivamente MAXColoc e TopKColoc.
Oltre a ciò, la lettura dei risultati permette di verificare sperimen-talmente i vantaggi teorici attesi descritti nel Capitolo 4 e poggia lebasi per le conclusioni illustrate nel Capitolo 6.
5.1 descrizione dei test
Gli algoritmi MAXColoc, TopKColoc e TopKCondensed sono stati im-plementati utilizzando il linguaggio C++ e sono stati eseguiti su unsistema Linux con 4gb di memoria RAM e processore con frequen-za di 1 .60ghz. La strutturazione dei grafi è stata in parte basata suiprincipi contenuti in Li and Kiran [6], e alcuni esempi significativi dicodice sorgente sono presentati nell’Appendice A.
Per quanto riguarda i dati utilizzati, sono stati considerati i puntidi interesse della California [5], contenente 62 tipi di eventi e 103863
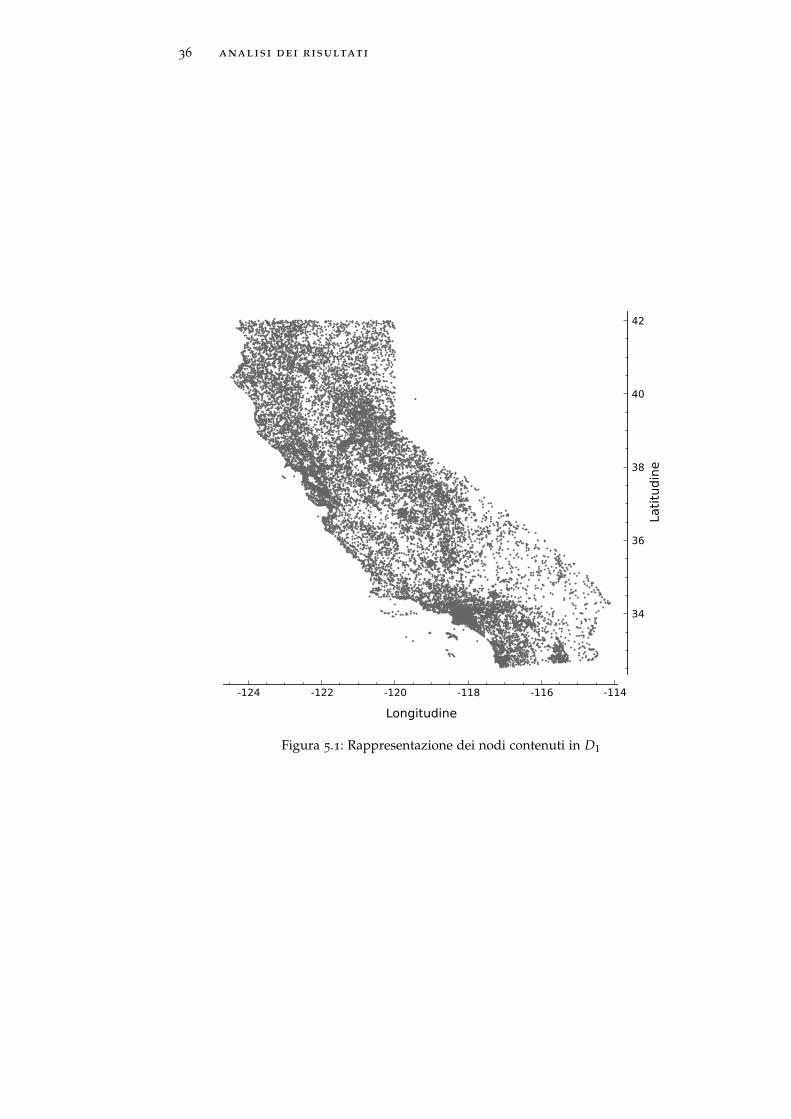
nodi. A partire dal dataset iniziale, sono stati prodotti sei datasetdifferenti D1, . . . , D6 aventi ciascuno 60 tipi di eventi e 24000 nodi.Una rappresentazione esemplificativa degli elementi contenuti in D1
è visibile in Figura 5.1, nella quale si può riconoscere la forma dellostato della California.
5.2 confronto con maxcoloc
Gli esperimenti condotti per confrontare TopKCondensed con MAX-Coloc si sono concentrati sulla verifica del livello di precisione dellamisura di supporto fornita dai due algoritmi. In tutti i casi di seguitodescritti, è stato eseguito TopKCondensed con un valore prefissato dik e quindi è stato selezionato il valore minimo di soglia riscontrato,ovvero R.last.PIlb come soglia minima θ da utilizzare con MAXColoc.
Questo permette di riscontrare le informazioni sulle medesime co-location in entrambi gli algoritmi. Con tale metodologia sono statieseguiti i seguenti test:
esperimento 1 – tolleranza Il valore di δ è stato fatto variarenell’insieme {2%, 4%, 6%, 8%} mentre è stato fissato il parame-tro k = 40 e la distanza massima tra nodi vicini è stata definitain 800 metri. Per questo test è stato usato D1.
35
36 analisi dei risultati
Figura 5.1: Rappresentazione dei nodi contenuti in D1

5.2 confronto con maxcoloc 37
esperimento 2 – numero di pattern Il valore di k è stato fattovariare nell’insieme {20, 30, 40, 50} mentre è stato fissato il pa-rametro δ = 4% e la distanza massima tra nodi vicini è statadefinita in 800 metri. Per questo test è stato usato D2.
esperimento 3 – distanza massima Il valore della distanza èstato fatto variare nell’insieme {600m, 800m, 1000m, 1200m}. Ilnumero di pattern è stato fissato a k = 40 e la tolleranza è stataposta a δ = 4%. Per questo test è stato usato D3.
Per effettuare una comparazione dei risultati, è stata costruita unalista di valori rappresentanti le frequenze delle colocation restituitedai due algoritmi. Nello specifico, per TopKCondensed è stata consi-derata la media aritmetica tra PIlb e PIub di ogni pattern, contando ilvalore una volta per ciascuna colocation rappresentata dal pattern. Ilconteggio viene memorizzato durante l’esecuzione della funzione re-place. Nel caso di MAXColoc, viene considerato il valore di frequenzarestituito e direttamente associato ad ogni colocation.
Una volta costruite le liste di frequenze relative a ciascuna esecuzio-ne degli algoritmi, sono stati disegnati dei box-plot in cui le scatolerettangolari rappresentano i limiti del primo e terzo quartile (q 1
4e q 3
4),
mentre la linea orizzontale interna individua la mediana.I segmenti che si estendono oltre ai rettangoli rappresentano i valo-
ri minimi e massimi nei dati, tra quelli interni al limite di 1.5 volte loscarto interquartile. La rappresentazione permette di ottenere infor-mazioni sintentiche ma significative sulla distribuzione dei valori difrequenza forniti dai due algoritmi.
Esperimento 1
La Figura 5.2 mostra i risultati. È possibile vedere che al variare del-la tolleranza, i valori di supporto forniti da MAXColoc sono sostan-zialmente simili e non presentano molta variazione, concentrandosisu frequenze molto basse. Al contrario, TopKCondensed individuaanche valori maggiori, quindi da ritenere più precisi.
La differenza marcata viene ridotta dall’aumentare di δ, anche inconsiderazione del fatto che una maggiore tolleranza permette la ri-levazione di numerose colocation specialmente con frequenza bas-sa. Nonostante ciò, è possibile riscontrare comunque dei valori piùprecisi nel caso di TopKCondensed.
Esperimento 2
La Figura 5.3 mostra i risultati. Nel caso di valori piccoli di k la diffe-renza è particolarmente marcata: mentre le frequenze individuate daMAXColoc sono totalmente appiattite, la distribuzione dei risultati diTopKCondensed è molto più ampia.

38 analisi dei risultati
Figura 5.2: Risultati dell’Esperimento 1
Figura 5.3: Risultati dell’Esperimento 2
5.2 confronto con maxcoloc 39
Figura 5.4: Risultati dell’Esperimento 3
Tale effetto viene ridotto in modo considerevole all’aumentare deipattern richiesti, per ragioni simili a quanto riportato nell’esperimen-to precedente. Si può osservare come anche in questo caso la tolle-ranza garantita sull’errore, determinata dal parametro δ, consente diottenere risultati decisamente più precisi nella misura del supporto.
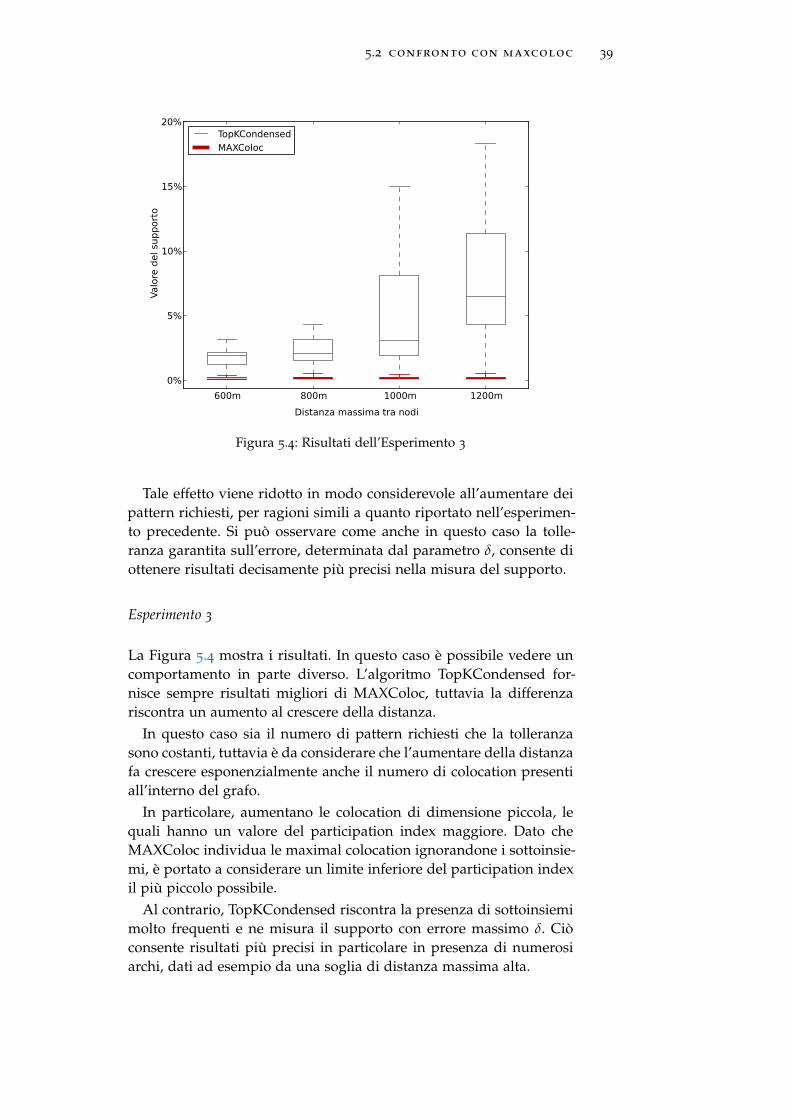
Esperimento 3
La Figura 5.4 mostra i risultati. In questo caso è possibile vedere uncomportamento in parte diverso. L’algoritmo TopKCondensed for-nisce sempre risultati migliori di MAXColoc, tuttavia la differenzariscontra un aumento al crescere della distanza.
In questo caso sia il numero di pattern richiesti che la tolleranzasono costanti, tuttavia è da considerare che l’aumentare della distanzafa crescere esponenzialmente anche il numero di colocation presentiall’interno del grafo.
In particolare, aumentano le colocation di dimensione piccola, lequali hanno un valore del participation index maggiore. Dato cheMAXColoc individua le maximal colocation ignorandone i sottoinsie-mi, è portato a considerare un limite inferiore del participation indexil più piccolo possibile.
Al contrario, TopKCondensed riscontra la presenza di sottoinsiemimolto frequenti e ne misura il supporto con errore massimo δ. Ciòconsente risultati più precisi in particolare in presenza di numerosiarchi, dati ad esempio da una soglia di distanza massima alta.

40 analisi dei risultati
5.3 confronto con topkcoloc
Per confrontare TopKCondensed con TopKColoc è utile analizzare ladifferenza di rappresentatività tra i risultati prodotti dai due algorit-mi. Nell’esecuzione dei test, entrambi gli algoritmi sono stati eseguiticon il medesimo valore di k e sono state analizzate le quantità dicolocation rappresentate, conteggiate nella funzione replace.
Per essere precisi, nella valutazione di TopKColoc, si è semplice-mente eseguito TopKCondensed con tolleranza nulla, cioè δ = 0. An-che in questo caso sono stati eseguiti tre differenti test, del tutto similia quelli descritti nella Sezione 5.2:
esperimento 4 – tolleranza Il valore di δ è stato fatto variarenell’insieme {2%, 4%, 6%, 8%} mentre è stato fissato il parame-tro k = 40 e la distanza massima tra nodi vicini è stata definitain 800 metri. Per questo test è stato usato D4.
esperimento 5 – numero di pattern Il valore di k è stato fattovariare nell’insieme {20, 30, 40, 50} mentre è stato fissato il pa-rametro δ = 4% e la distanza massima tra nodi vicini è statadefinita in 800 metri. Per questo test è stato usato D5.
esperimento 6 – distanza massima Il valore della distanza èstato fatto variare nell’insieme {600m, 800m, 1000m, 1200m}. Ilnumero di pattern è stato fissato a k = 40 e la tolleranza è stataposta a δ = 4%. Per questo test è stato usato D6.
Il confronto dei risultati è stato fatto conteggiando le colocation rap-presentate dagli output dei due algoritmi a parità di k pattern richie-sti. Dopodiché è stato prodotto un grafico per ciascun test.
Esperimento 4
La Figura 5.5 mostra i risultati. Dato che l’unico parametro ad esserevariato è stato δ, le quattro colonne rosse rappresentano di fatto unsolo output ripetuto quattro volte. Dal grafico è possibile vedere co-me una variazione della tolleranza aumenti drasticamente l’effetto dicompattazione fornito da TopKCondensed.
Ovviamente si deve tenere in considerazione che questa maggiorerappresentatività va a scapito dell’accuratezza relativa alla misura delparticipation index: non è possibile incrementare a dismisura δ, altri-menti il valore di supporto fornito dall’algoritmo sarebbe talmenteimpreciso da risultare inutile.
Esperimento 5
La Figura 5.6 mostra i risultati. Anche in questo caso, relativo allavariazione del parametro k, si possono notare chiaramente gli effetti

5.3 confronto con topkcoloc 41
Figura 5.5: Risultati dell’Esperimento 4
Figura 5.6: Risultati dell’Esperimento 5
42 analisi dei risultati
Figura 5.7: Risultati dell’Esperimento 6
della compressione derivanti dalla tolleranza sulla misura del partic-ipation index. L’aumento di k comporta anche una crescita del livellodi compressione.
Questo effetto è determinato dal criterio stesso con il quale le co-location vengono accorpate nei pattern. Esso è maggiore con valoridi k elevati anche in virtù del fatto che gli ultimi pattern presentanofrequenze inferiori. I risultati ottenuti con TopKCondensed rendonopossibile ricavare informazioni su un maggior numero di colocation,a parità di pattern richiesti.
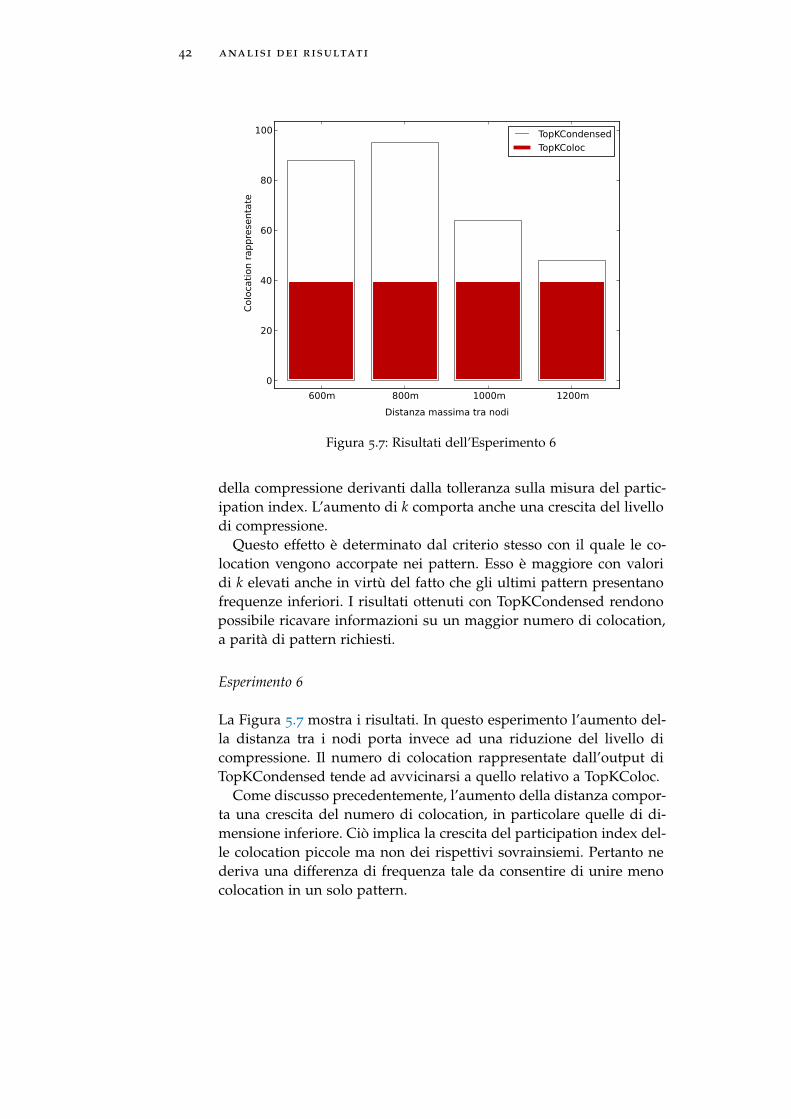
Esperimento 6
La Figura 5.7 mostra i risultati. In questo esperimento l’aumento del-la distanza tra i nodi porta invece ad una riduzione del livello dicompressione. Il numero di colocation rappresentate dall’output diTopKCondensed tende ad avvicinarsi a quello relativo a TopKColoc.
Come discusso precedentemente, l’aumento della distanza compor-ta una crescita del numero di colocation, in particolare quelle di di-mensione inferiore. Ciò implica la crescita del participation index del-le colocation piccole ma non dei rispettivi sovrainsiemi. Pertanto nederiva una differenza di frequenza tale da consentire di unire menocolocation in un solo pattern.

6C O N C L U S I O N I
In questa tesi è stato trattato il problema del mining delle colocation,approfondendo innanzitutto i concetti teorici basilari e le strategieutilizzate in letteratura. È stato quindi sviluppato il nuovo concettodi condensed colocation pattern ed è stato fornito un algoritmo pereffettuare il mining di questa tipologia di pattern.
I vantaggi teorici attesi sono stati verificati tramite dei test. Tali ve-rifiche hanno messo a confronto la soluzione proposta con altri duealgoritmi esistenti per le colocation. Ne è risultato che i condensed co-location pattern consentono una rappresentazione compatta di nume-rose colocation tramite una tolleranza di errore massimo. Inoltre, l’al-goritmo sviluppato risulta efficace nel fornire un insieme di risultatimaggiormente compatto e rappresentativo.
43


Parte III
A P P E N D I C E


AP O R Z I O N I S I G N I F I C AT I V E D I C O D I C E
In questa appendice vengono presentati le due parti più importantidella logica del programma, vale a dire il codice principale di TopK-Condensed e l’implementazione di FP-Growth. Il codice sorgente deisoftware relativi a TopKCondensed e MAXColoc, come implementatiper questa tesi, è disponibile all’indirizzo:
http://wwwstud.dsi.unive.it/alazzaro/BachelorThesis/
a.0.1 main.cpp
enum distanceType { euclidean, latlon };static map<string, distanceType> mapDistanceTypes;
void findStarInstances(map<Colocation, vector<Instance> >* results,vector<Colocation>& Cl, unsigned int l,vector<NeighborhoodTransaction>& nt) {
NeighborhoodTransaction tmpNt;for(vector<Colocation>::iterator i = Cl.begin(); i != Cl.end(); i++) {
Colocation& c = *i;(*results)[c] = vector<Instance>();int head = *(c.Getitems()->begin());
MiniNode h;h.Settype(head);h.Setid(0);tmpNt.Setreference(h);vector<NeighborhoodTransaction>::iterator low;low = lower_bound(nt.begin(), nt.end(), tmpNt);
for(vector<NeighborhoodTransaction>::iterator j = low;j != nt.end(); j++) {
NeighborhoodTransaction& tra = *j;/** We are interested only in transactions where the reference item* has the same type as the first element of c and we can exploit* the fact that nt is an ordered vector.*/if(tra.Getreference().Gettype() > head)
break;if(tra.getLength() < l)
continue;
set<MiniNode>* traNodes = tra.Getitems();vector<Instance> traInstances;// We manually insert the first elementset<int>* elems = c.Getitems();Instance first;first.addItem(tra.Getreference());traInstances.push_back(first);set<int>::iterator k = elems->begin();// Start from the secondfor(k++; k != elems->end(); k++) {
// Search elements of this typeset<MiniNode> results;/** MiniNode h above already served it’s purpose, we can re-use* it here instead of creating a new one.*/h.Settype(*k);set<MiniNode>::iterator low;low = lower_bound(traNodes->begin(), traNodes->end(), h);for(set<MiniNode>::iterator r = low;
r != traNodes->end(); r++) {MiniNode* current = (MiniNode*) &*r;if(current->Gettype() == *k)
results.insert(*current);
47

48 porzioni significative di codice
else break;}
if(results.size() == 0) {/** This transaction does not match and we need to stop.* Since .clear() does not free memory, we use this instead.* See also: http://lazza.me/1aJnktV*/vector<Instance>().swap(traInstances);break;
}else {
vector<Instance> updatedInstances;/** We need to make a copy of transaction instances FOR EACH* result and enqueue it.*/for(vector<Instance>::iterator ei = traInstances.begin();
ei != traInstances.end(); ei++) {Instance& current = *ei;for(set<MiniNode>::iterator ni = results.begin();
ni != results.end(); ni++) {Instance aCopy = current;MiniNode* newNode = (MiniNode*) &*ni;aCopy.addItem(*newNode);updatedInstances.push_back(aCopy);
}}
swap(traInstances, updatedInstances);}
}
for(vector<Instance>::iterator k = traInstances.begin();k != traInstances.end(); k++)
(*results)[c].push_back(*k);
}
}}
void filterCliqueInstances(vector<Instance>* results,vector<Instance>& SIc, vector<Instance>& CIl1) {
/** SIc is the set of star instances of candidate c* CIl1 is the SORTED set of all the clique instances of length l-1*/for(vector<Instance>::iterator i = SIc.begin(); i != SIc.end(); i++) {
Instance* current = (Instance*) &*i;set<MiniNode>* els = current->Getitems();MiniNode head = *(els->begin());els->erase(els->begin());bool push = binary_search(CIl1.begin(), CIl1.end(), *current);els->insert(head); // Revert the change!if(push)
results->push_back(*current);}
}
double calculateTruePi(vector<Instance>& CIc, Colocation& c, unsigned int l,FreqTracker& ft) {
/** This function is actually pretty simple. Given a colocation c and all of* its true instances, we count for each node type the ratio:* involved instances / total instances* The true PI is the lowest ratio.*/double result = 1.0; // cannot be more than thisset<int>* elements = c.Getitems();unsigned int idx = 0;for(set<int>::iterator i = elements->begin(); i != elements->end(); i++) {
set<unsigned int> different;for(vector<Instance>::iterator j = CIc.begin(); j != CIc.end(); j++) {
Instance& current = *j;set<MiniNode>* nodes = current.Getitems();set<MiniNode>::iterator elJ = nodes->begin();// We use idx to fastly index the set as it was a vectoradvance(elJ, idx);MiniNode* sameType = (MiniNode*) &*elJ;different.insert(sameType->Getid());
}
double fraction = ((double) different.size()) / ft.getFreq(*i);result = min(result, fraction);idx++;
porzioni significative di codice 49
}return result;
}
void findSubClosed(vector<Colocation>* results,vector<Colocation>& R, Colocation& c, double pi, double delta) {
set<int>* items = c.Getitems();for(vector<Colocation>::iterator i = R.begin(); i != R.end(); i++) {
Colocation& current = *i;if((pi < (current.GethighFreq() - delta)) ||
(pi > current.GetlowFreq()) ||(current.Getitems()->size() == c.Getitems()->size()))
continue;
set<int>* currItems = current.Getitems();bool ok = includes(items->begin(), items->end(), currItems->begin(),
currItems->end());if(ok)
results->push_back(current);}
}
void replaceSubsets(vector<Colocation>* R, vector<Colocation>* subsets,Colocation* c, double pi) {
double lowFreq = pi;double highFreq = pi;double members = 1;for(vector<Colocation>::iterator ci = subsets->begin();
ci != subsets->end(); ci++) {Colocation& co = *ci;highFreq = max(highFreq, co.GethighFreq());members += co.getmembers();
}c->SetlowFreq(lowFreq);c->SethighFreq(highFreq);c->Setmembers(members);sort(subsets->begin(), subsets->end());R->erase(
remove_if(R->begin(),R->end(),toBeReplaced(subsets)
),R->end()
);vector<Colocation>::iterator pos = upper_bound(R->begin(),
R->end(), *c, Colocation::upperPIsort);R->insert(pos, *c);
}
int main(int argc, char *argv[]) {// Initialize the map for threshold typesmapDistanceTypes["euclidean"] = euclidean;mapDistanceTypes["latlon"] = latlon;
if(argc != 6) {cerr << "Usage: TopKColoc filename distance threshold k" << endl;cerr << "Parameters:" << endl;cerr << " filename - the dataset" << endl;cerr << " distance - ’euclidean’ or ’latlon’" << endl;cerr << " threshold - maximum allowed distance of neighbours" << endl;cerr << " (’latlon’ distance is in kilometers)" << endl;cerr << " delta - percent value of tolerance for support" << endl;cerr << " k - number of top closed colocations" << endl;cerr << "Example: TopKColoc data.txt latlon 5.34 0.015 10" << endl;exit(1);
}
string filename = argv[1];string distance = argv[2];std::stringstream sstm, sstm2, sstm3;sstm << argv[3];double threshold;sstm >> threshold;sstm2 << argv[4];double delta;sstm2 >> delta;sstm3 << argv[5];unsigned int k;sstm3 >> k;
cerr << "Importing data..." << endl;ifstream infile(filename.c_str());if(!infile){
cerr << "ERROR: Data file not found" << endl;exit(1);
}

50 porzioni significative di codice
DatasetImporter d(filename);Graph g;FreqTracker typeFrequencies = d.parseOn(g);set<int>& typesList = d.GetintTypes();map<int, string>& typeMap = d.GettypeMap();
// Useful informationcerr << "Filename: " << filename << endl;int size = g.Getnodes()->size();cerr << "Number of nodes: " << size << endl;cerr << "Distance: " << distance << endl;cerr << "Threshold: " << threshold << endl;cerr << "Delta: " << delta << endl;cerr << "K: " << k << endl;
cerr << "Computing pairs..." << endl;
// See also: http://lazza.me/1d200Ysswitch(mapDistanceTypes[distance]) {
case euclidean:{
EuclideanThreshold thr(threshold);thr.applyOn(g);break;
}case latlon:
{LatLonThreshold thr(threshold);thr.applyOn(g);break;
}default:
cerr << "ERROR: The specified distance type is not valid" << endl;exit(1);
}
cerr << "Forming transactions..." << endl;vector<NeighborhoodTransaction> nt;vector<EventTransaction> ent;
set<Node>* nodes = g.Getnodes();
for (set<Node>::iterator i = nodes->begin(); i != nodes->end(); i++) {Node* n = (Node*) &*i;NeighborhoodTransaction tra = NeighborhoodTransaction(*n);nt.push_back(tra);ent.push_back(EventTransaction(tra));
}
cerr << "Sorting transactions..." << endl;
sort(nt.begin(), nt.end());sort(ent.begin(), ent.end());
cerr << "Finding star candidates..." << endl;/** In the following loop we build a FPTree for each node type and then we* perform the FP-Growth algorithm in order to extract the transactions for* building the colocation instances.*/map< int, set<Colocation> > transactionGroups;for(set<int>::iterator i = typesList.begin();
i != typesList.end(); i++) {FPTree fpt(*i, ent);
set<StarCandidate> partial = fpt.FPGrowth();transactionGroups[*i] = set<Colocation>();for(set<StarCandidate>::iterator j = partial.begin();
j != partial.end(); j++) {StarCandidate* star = (StarCandidate*) &*j;Colocation c(*star);transactionGroups[*i].insert(c);
}}
cerr << "Finding colocation candidates..." << endl;/** Due to the overly complicated syntax of a "for each" in C++ this looks* quite complicated. In reality, we just need to check that a transaction* is in every group (i.e. generated by every tree) before we can consider* it a candidate.*/set<Colocation> candidates;// This loop iterates over each node typefor(map<int, set<Colocation> >::iterator i = transactionGroups.begin();
i != transactionGroups.end(); i++) {set<Colocation> current = i->second;

porzioni significative di codice 51
// This loop iterates over each set/transactionfor(set<Colocation>::iterator j = current.begin();
j != current.end(); j++) {// This part is for checking if a set is a real colocation candidatebool ok = true;Colocation* c = (Colocation*) &*j;double minFreq = c->GetlowFreq();set<int>* tra = c->Getitems();for(set<int>::iterator k = tra->begin(); k != tra->end(); k++) {
int el = *k;set<Colocation>::iterator r = transactionGroups[el].find(*c);if(r == transactionGroups[el].end()) {
ok = false;break;
}else {
Colocation* other = (Colocation*) &*r;minFreq = min(minFreq, other->GetlowFreq());
}transactionGroups[el].erase(r);
}if(ok) {
c->SetlowFreq(minFreq);c->SethighFreq(minFreq);candidates.insert(*c);
}}
}
cerr << "Building the candidates subset tree..." << endl;
CSTree Cst(candidates);
cerr << "Starting the search process..." << endl;
vector<Colocation> R;unsigned int l = 2;vector<Instance> CIl1;double theta = 0;
vector<Colocation> Cl;Cst.getCandidatesByLength(&Cl, l);
while(Cl.size() != 0) {cerr << "Working for l = " << l << endl;sort(Cl.begin(), Cl.end(), Colocation::upperPIsort);
if(R.size() == k) {// If the last element is of size l, we can prune a bit moredouble pruneLimit;Colocation& last = R.back();if(last.Getitems()->size() < l)
pruneLimit = theta;else
pruneLimit = last.GetlowFreq();Cst.pruneCandidates(l, pruneLimit);/** Here we implement a simple binary search procedure, because the* one provided by the STL is not useful in this context. This is* why it’s better to use a vector instead of a list, otherwise the* indexing process is extremely complicated.*/unsigned int low = 0;unsigned int up = Cl.size() - 1;while(low < up) {
unsigned int mid = (low+up)/2;if(Cl[mid].GetlowFreq() >= pruneLimit)
low = mid + 1;else
up = mid;}unsigned int res;if (!((low == up) && Cl[low].GetlowFreq() >= pruneLimit))
res = low;else
res = min(low + 1, (unsigned int) Cl.size());Cl.resize(res);if(Cl.size() == 0)
break;} // end if |R|==k
map<Colocation, vector<Instance> > SIl;findStarInstances(&SIl, Cl, l, nt);vector<Instance> CIl;
for(vector<Colocation>::iterator it = Cl.begin();it != Cl.end(); it++) {

52 porzioni significative di codice
Colocation& c = *it;
if((R.size() == k) && c.GetlowFreq() < theta) {// If the last element is of size l, we can prune a bit moreColocation& last = R.back();if(last.Getitems()->size() < l)
Cst.pruneCandidates(l, theta);else
Cst.pruneCandidates(l, last.GetlowFreq());/** The original pseudocode contains the word "continue" but the* text is quite clear to state that it is the OUTER loop to be* continue. For this reason, here is a break for the inner for.*/break;
}
vector<Instance>& SIc = SIl[c];vector<Instance> CIc;// In the first step we don’t need to filterdouble pi;if(l > 2) {
filterCliqueInstances(&CIc, SIc, CIl1);// Remember instances for next stepCIl.insert(CIl.end(), CIc.begin(), CIc.end());pi = calculateTruePi(CIc, c, l, typeFrequencies);
}else {
CIl.insert(CIl.end(), SIc.begin(), SIc.end());pi = calculateTruePi(SIc, c, l, typeFrequencies);
}
c.SetlowFreq(pi); // Prepare for a possible insertionc.SethighFreq(pi);
if(R.size() < k) {vector<Colocation> subsets;findSubClosed(&subsets, R, c, pi, delta);
if(subsets.size() == 0) {vector<Colocation>::iterator pos = upper_bound(R.begin(),
R.end(), c, Colocation::upperPIsort);R.insert(pos, c);
}else {
replaceSubsets(&R, &subsets, &c, pi);} // end if subsets is empty (else part)
} // end if |R| < k (if part)else {
if(theta < pi) {vector<Colocation> subsets;findSubClosed(&subsets, R, c, pi, delta);
if(subsets.size() == 0) {R.pop_back();vector<Colocation>::iterator pos = upper_bound(R.begin(),
R.end(), c, Colocation::upperPIsort);R.insert(pos, c);
}else {
replaceSubsets(&R, &subsets, &c, pi);}
}} // end if |R| < k (else part)theta = R.back().GethighFreq() - delta;
} // end for each c in Cl
l++;swap(CIl1, CIl);sort(CIl1.begin(), CIl1.end()); // We need it for fast filteringvector<Colocation>().swap(Cl);Cst.getCandidatesByLength(&Cl, l);
} // end while Cl is not empty
for(vector<Colocation>::iterator i = R.begin(); i != R.end(); i++) {Colocation& c = *i;cout << c.str(typeMap) << endl;
}
return 0;} �

porzioni significative di codice 53
a.0.2 Metodo FPGrowth da FPTree.cpp
set<StarCandidate> FPTree::FPGrowth(set<int> ending) {/** FP-Growth is a recursive algorithm. The base case consists of a tree that* contains a single path. In this case the combinations are enumerated with* ease and the result is given. Otherwise, it’s necessary to recursively* call the procedure.*/set<StarCandidate> candidates;
// Base caseif(single) {
vector<FPNode*>* current = root.Getchildren();/** In this part we don’t need to go bottom-up. We get the list of the* children, but we know there can be only one or none. So we use the* iterator to check if we have reached the bottom.*/StarCandidate first;first.Setitems(ending);first.Setreference(root.Gettype());candidates.insert(first);
while(current->begin() != current->end()) {FPNode* node = *(current->begin());set<StarCandidate> newCandidates;int type = node->Gettype();for (set<StarCandidate>::iterator i = candidates.begin();
i != candidates.end(); i++) {// Here we really need a copy of *i called cStarCandidate c = *i;set<int>* items = c.Getitems();items->insert(type);c.Setfreq(((double) node->Getcount()) / root.Getcount());newCandidates.insert(c);
}candidates.insert(newCandidates.begin(), newCandidates.end());current = node->Getchildren();
}
candidates.erase(first);}
// Recursive partelse {
vector<int> nodeTypes;for(map<int, FPNode*>::iterator i = headerTable.begin();
i != headerTable.end(); i++) {nodeTypes.push_back(i->first);
}sort(nodeTypes.begin(), nodeTypes.end(), ft);reverse(nodeTypes.begin(), nodeTypes.end());
/** The following loop is the iterator over the different types of nodes.* We need to construct an FP-Tree ending with each node type.*/for(vector<int>::iterator i = nodeTypes.begin();
i != nodeTypes.end(); i++) {int& type = *i;/** For each node type, there could be more than one instance of it,* so more than one path ending with the same type. That’s why we* iterate through the different nodes of the same type.*/FPNode* current = headerTable[type];
// We need a copy of endingset<int> newEnding(ending.begin(), ending.end());newEnding.insert(type);
vector< set<StarCandidate> > typeCandidates;while(current != NULL) {
vector<EventTransaction> tmpCandidates;set<int> ancestors;// Generate the transaction with all the ancestorsFPNode* node = current;// Double check so we avoid the rootwhile (node != NULL) {
ancestors.insert(node->Gettype());node = node->Getparent();if(node->Getparent() == NULL)
break;}

54 porzioni significative di codice
EventTransaction tra;tra.Setitems(ancestors);tra.Setreference(root.Gettype());
// We need to insert it the same number of times of currentunsigned int times = current->Getcount();for(unsigned int k = 0; k < times; k++)
tmpCandidates.push_back(tra);
FPTree typeTree(root.Gettype(), tmpCandidates);typeTree.Getroot().Setcount(root.Getcount());set<StarCandidate> results = typeTree.FPGrowth(newEnding);
// We also need to add the "empty" transactionStarCandidate star;star.Setreference(root.Gettype());star.Setitems(newEnding);star.Setfreq(((double) current->Getcount()) / root.Getcount());results.insert(star);
typeCandidates.push_back(results);current = current->Getsibling();
} // end for each node of type T
/** In the following part we merge the partial results and then* add the current candidates to the global set of candidates.*/set<StarCandidate> partial;
for(vector< set<StarCandidate> >::iterator i = typeCandidates.begin();i != typeCandidates.end(); i++) {
set<StarCandidate>& subset = *i;for(set<StarCandidate>::iterator j = subset.begin();
j != subset.end(); j++) {StarCandidate* current = (StarCandidate*) &*j;// Check if the candidate is already partialif(partial.find(*current) != partial.end())
continue;
double freq = current->Getfreq();// Search for it in the other subsetsvector< set<StarCandidate> >::iterator o = i;for(o++; o != typeCandidates.end(); o++) {
set<StarCandidate>& searchSubset = *o;set<StarCandidate>::iterator search = searchSubset.find(*
current);if (search != searchSubset.end()) {
StarCandidate* found = (StarCandidate*) &*search;freq += found->Getfreq();
}}
current->Setfreq(freq);partial.insert(*current);
}}// Here we have finished merging the partial resultscandidates.insert(partial.begin(), partial.end());
} // end for each nodeType
}
return candidates;} �

B I B L I O G R A F I A
[1] Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithmsfor mining association rules. Proc. 20th Int. Conf. Very Large Da-ta Bases, VLDB, 1994. URL https://www.it.uu.se/edu/course/
homepage/infoutv/ht08/vldb94_rj.pdf.
[2] Mark Bow. Compact Co-location Pattern Mining. 2011. URLhttp://opus.ipfw.edu/masters_theses/3.
[3] Jiawei Han, Jian Pei, and Yiwen Yin. Mining frequent patternswithout candidate generation. ACM SIGMOD Record, 29(2):1–12,June 2000. ISSN 01635808. doi: 10.1145/335191.335372. URLhttp://portal.acm.org/citation.cfm?doid=335191.335372.
[4] Krzysztof Koperski and Jiawei Han. Discovery of spatial associa-tion rules in geographic information databases. Advances in spa-tial databases, 1995. URL http://link.springer.com/chapter/
10.1007/3-540-60159-7_4.
[5] Feifei Li, Dihan Cheng, and Marios Hadjieleftheriou. On tripplanning queries in spatial databases. In Proceedings of the 9th In-ternational Symposium on Spatial and Temporal Databases (SSTD),2005. URL http://www2.research.att.com/~marioh/papers/
sstd05-tpq.pdf.
[6] Wing Ning Li and Ravi Kiran. An object-oriented design andimplementation of reusable graph objects with C++: a case stu-dy. In Proceedings of the 1996 ACM symposium on Applied Compu-ting, 1996. ISBN 0897918207. URL http://dl.acm.org/citation.
cfm?id=331433.
[7] Nikos Mamoulis. Co-location Patterns, Algorithms. Encyclope-dia of GIS, pages 1–7, 2008. URL http://link.springer.com/
content/pdf/10.1007/978-0-387-35973-1_152.pdf.
[8] Jian Pei, Guozhu Dong, Wei Zou, and Jiawei Han. MiningCondensed Frequent-Pattern Bases. Knowledge and InformationSystems, 6(5):570–594, February 2004. ISSN 0219-1377. doi:10.1007/s10115-003-0133-6. URL http://link.springer.com/
10.1007/s10115-003-0133-6.
[9] Shashi Shekhar and Yan Huang. Discovering spatial co-locationpatterns: A summary of results. Advances in Spatial and Tempo-ral Databases, 2001. URL http://link.springer.com/chapter/
10.1007/3-540-47724-1_13.
55

56 bibliografia
[10] Jin Soung Yoo and Mark Bow. Mining top-k closed co-locationpatterns. In Spatial Data Mining and Geographical Knowledge Ser-vices (ICSDM), 2011 IEEE International Conference on, 2011. ISBN9781424483518. URL http://ieeexplore.ieee.org/xpls/abs_
all.jsp?arnumber=5969013.
[11] Jin Soung Yoo and Mark Bow. Mining maximal co-located eventsets. Advances in Knowledge Discovery and Data Mining, pages 351–362, 2011. doi: 10.1007/978-3-642-20841-6_29. URL http://link.
springer.com/chapter/10.1007/978-3-642-20841-6_29.
[12] Jin Soung Yoo and Shashi Shekhar. A joinless approach for mi-ning spatial colocation patterns. Knowledge and Data Engineering,IEEE Transactions on, 2006. URL http://ieeexplore.ieee.org/
xpls/abs_all.jsp?arnumber=1683769.

colophon
This document was typeset using the typographical look-and-feelclassicthesis developed by André Miede. The style was inspiredby Robert Bringhurst’s seminal book on typography “The Elements ofTypographic Style”. classicthesis is available for both LATEX and LYX:
http://code.google.com/p/classicthesis/
Happy users of classicthesis usually send a real postcard to theauthor, a collection of postcards received so far is featured at:
http://postcards.miede.de/