visual mining studio チュートリアル mining studio チュートリアル 株式会社 ntt...
TRANSCRIPT

Visual Mining Studio チュートリアル
株式会社 NTT データ数理システム
東京都新宿区信濃町 35 番地 信濃町煉瓦館 1 階
Phone:03-3358-6681
Fax:03-3358-1727
2016 年 3 月更新

2
目次
1. はじめに ......................................................................................................................... 3
2. 解析の前に ...................................................................................................................... 4
2.1. 起動しましょう ....................................................................................................... 4
2.2. ウインドウの説明 ................................................................................................... 4
2.3. VAP 上で VMSTUDIO を利用する ............................................................................ 5
3. データ「菖蒲」を分析する ............................................................................................ 7
3.1. データの取り込み ................................................................................................... 7
3.2. 集計でデータの概要をつかむ ............................................................................... 11
3.3. 異常なデータを取り除く ...................................................................................... 14
3.4. データを目で見る ................................................................................................. 17
3.5. クラスタを抽出する .............................................................................................. 21
3.6. 作業を中断します ................................................................................................. 27
3.7. この章のまとめ ..................................................................................................... 29
4. データ「MARKET」を分析する .................................................................................. 30
4.1. データの取り込み ................................................................................................. 30
4.2. データの意味と解析の目的 ................................................................................... 33
4.3. 欠損値を除外する ................................................................................................. 35
4.4. 要因を分析する ..................................................................................................... 38
4.5. モデルを検証する ................................................................................................. 46
4.6. この章のまとめ ..................................................................................................... 50
5. POS データを分析する ................................................................................................ 51
5.1. データの導入 ......................................................................................................... 51
5.2. アソシエーション分析とは ................................................................................... 54
5.3. アソシエーション分析アイコンを使う................................................................. 56
5.4. 分析結果とルールの重要性 ................................................................................... 58
5.5. リフトの値を見る ................................................................................................. 62
5.6. 長いルールを抽出する .......................................................................................... 65
5.7. この章のまとめ ..................................................................................................... 68
索引 ...................................................................................................................................... 70

3
1. はじめに
Visual Mining Studio(VMStudio)をご利用いただきありがとうございます。VMStudio
は、Visual Analytics Platform(VAP)上で動く、データマイニングに必要な様々な処理をグ
ラフィカルに行うことのできる統合解析ツールです。
図 1-1 解析画面
この文章はデータマイニングがどのようなもので、実際に VAP、VMStudio でどのよう
に分析作業を行うのかを大まかに知りたい方を対象にしています。この文章では実際に
VAP、VMStudio にデータを導入し、解析する作業を通じて「データマイニング」がどの
ようなものかを自然に理解することができるようになっています。
以下では、次の 3 種類のサンプルデータを順番に解析します。
菖蒲 … 集計・グラフ表示・クラスタ分析・クリーニング・K-Means 法
market … 列属性変更、Decision Tree・予測
POS データ … アソシエーション分析(バスケット分析)
それぞれのデータに対して用いる解析手法・アイコンを併記しましたので、必要な解析
手法が明確な方は対応する章をお読みください。

4
2. 解析の前に
2.1. 起動しましょう
まず VAP を起動してみましょう1。
VAP を起動するには、インストール終了後「スタート」メニューの MSI Solutions 以下
の VAP を選択します(図 2-1)。
図 2-1 VAP の起動
すると、VAP が起動します。また S-PLUS をインストールした上で、S-PLUS と連携を
行っている場合、同時に S-PLUS も起動します。
2.2. ウインドウの説明
VAP が起動すると、下図のようなウインドウが開きます。
VAP、VMStudio を用いた解析は、このウインドウの大部分を占めるプロジェクトボー
ド上で行います。このボード上にアイコンを置いていくことによって処理を進めていきま
す。
1 VAP、VMStudio のインストール作業については、インストールガイドを参照して行って
ください。ここではインストール作業、ライセンス登録は既に終了しているものとします。

5
図 2-2 VAP メインウインドウ
ウインドウ左側にある縦長のウインドウはオブジェクトブラウザと呼び、データ解析で
用いる処理アイコンやデータが格納されています。各アイコンは種類・機能ごとにフォル
ダに分類されています。フォルダは Windows でフォルダを開くのと同じように操作する
ことができます。
VAP、VMStudio でのデータ解析は、オブジェクトブラウザ上のアイコン群を、プロジ
ェクトボードに貼り付けることによって行います。
2.3. VAP 上で VMStudio を利用する
VMStudio はインストールしただけでは利用できません。VAP 上で利用する製品として
VMStudio を選択する必要があります。まず、メニューバーの製品(P)をクリックし、製品
の選択(S)をクリックします。
図 2-3 製品の選択
表示された製品の選択ダイアログで Visual Mining Studio の選択にチェックを入れ、OK
ボタンをクリックします。なお、利用数は製品の「現在の利用者数 / 同時利用可能なユー
ザ数」を表わします。同時利用の上限まで製品が利用されている場合、その状態では利用
プロジェクトボード
オブジェクトブラウザ

6
できませんので、利用者間で調整を行ってください。
図 2-4 製品の選択ダイアログ
Visual Mining Studio が利用可能な状態で OK ボタンをクリックすると、ダイアログは閉
じられ、オブジェクトブラウザ上に Visual Mining Studio というフォルダが現れます。
図 2-5 製品選択に伴うオブジェクトブラウザの表示の変化
以上で VMStudio の機能を利用する準備が整いました。次章より VAP、VMStudio を用
いた分析方法について説明します。

7
3. データ「菖蒲」を分析する
この章では、菖蒲.txt というデータを用いて、
VAP、VMStudio の基本操作に慣れる
クラスタ分析を行う
ことを目的にデータ分析を行います。
3.1. データの取り込み
データマイニングは、まず分析の対象となる「データ」を取り込むことから始めます。
VAP では以下の条件を満たすテキストファイルが解析可能です。
ファイル名の拡張子が .csv または .txt
同じ行のデータがカンマ、タブ、スペース、セミコロンで区切られている
本章で使用するデータのサンプルが、ルートフォルダ2 ¥Samples¥Visual Mining Studio
フォルダ以下にあります。ここではこのサンプルデータの取り込み方法を説明します。
ここで取り込む 菖蒲.txt は、統計学者 Fisher が統計分析のために、実際に植物の菖蒲
(アヤメ)を測定したデータ(の一部を変更したもの)です。データの形式は図 3-1 のよ
うにデータがコンマで区切れており、1 行目はそれぞれの列のタイトルになっています。
図 3-1 菖蒲.txt の先頭部分
2 ルートフォルダとは、VAP をインストールしたフォルダのことです。インストール時に
特に指定しない場合、マシンが 32bitOS であれば C:¥Program Files¥Mathematical
Systems Inc¥Visual Analytics Platform となります。64bit OS であれば C:¥Program
Files(x86)¥Mathematical Systems Inc¥Visual Analytics Platform となります。インスト
ール時に変更した場合は、指定したフォルダがルートフォルダになります。以下では特に
断らずにルートフォルダと書きます。
種類,がく長,がく幅,花びら長,花びら幅
Setosa,51,35,14, 2
Setosa,49,30,14, 2
Setosa,47,32,13, 2
Setosa,46,31,15, 2
Setosa,50,36,14, 2
…
1行目=タイトル
行

8
データの取り込みは図 3-2 のように、エクスプローラなどからプロジェクトボードにド
ラッグ&ドロップして行います(図の矢印)。菖蒲.txt をドラッグすると、「菖蒲」アイコ
ンができます。もしくは、図 3-3 のようにプロジェクトボード上で右クリックして、「新
規アイコン」→「外部データ入力」→「ファイル」から菖蒲.txt を選択することで、アイ
コンを作成できます。
図 3-2 マウスの左ボタンを押したまま移動(ドラッグ&ドロップ)
図 3-3 プロジェクトボード上で右クリック

9
次に、データを VAP 内部形式に変換する作業を行います(これをデータインポートとい
います)。貼り付けた「菖蒲」アイコンをダブルクリックすると、図 3-4 のようなデータ
インポートウインドウが表示されます。
図 3-4 データインポートウインドウ
データを内部形式に取り込むには、各列のデータが数値(整数、実数)であるか文字列
であるかを選択する必要があります(これをデータの属性といいます)。データインポート
ウインドウには自動で判別した属性が表示されますが、手動で列毎に指定することができ
ます。
またオプションの「先頭行を列名として使う」という欄にチェックが入っていますが、
このオプションはもし先頭行からデータが始まる場合にはこの欄のチェックは外します。
このデータの場合、先頭行は列名ですので、チェックを入れたままにしてください。
図 3-5 「先頭行を列名として使う」オプション

10
今回は特に設定の変更はありませんので、そのまま OK ボタンを押し、データインポー
トを開始します。インポートが終了すると、データ&グラフビューが自動的に起動し、イ
ンポートされた結果が表示されます。データ&グラフビューを閉じた後にもう一度データ
を確認したい場合には、「菖蒲」アイコンを右クリックして、メニューからデータビュー
を選択すると、データを表示することができます(図 3-6)
図 3-6 データビュー

11
3.2. 集計でデータの概要をつかむ
次にデータの集計を行い、菖蒲が種類ごとにいくつデータがあるかカウントしてみまし
ょう。集計アイコンを図 3-7 のように置きます3。
図 3-7 集計アイコンを貼り付ける
次にデータアイコンと集計アイコンを矢印線でつなぎます。次のようにします。
(1) 始点となるアイコンにマウスポインタをあわせ、マウスの中央ボタン4を押して、押し
たままにする。
(2) 終点となるアイコンにボタンを押したまま移動し、そこでボタンを離す
3 集計アイコンは データ操作フォルダにあります。
4 マウスによってはホイール(縦に回転する構造のもの)になっていますが、この場合は
ホイールごと押し込みます。中央ボタンがない場合は右・左の順でボタンを押しこみます。
中央ボタンを
押しながら
マウスを移動
ここで左ボタ
ンを押す
ここで左ボタン
を押す
ここで左ボタン
を押す
ここで左ボタン
を押す
押したまま
移動
押したまま
移動
左ボタンを離す
とアイコン貼り付
け

12
データ処理をおこなうための処理の流れ(処理フロー)が完成しました。この処理フロ
ーを実行するには処理アイコン(ここでは集計アイコン)を右クリックして、メニューか
ら実行を選択します。選択すると集計アイコンは菖蒲アイコンからデータを取得して処理
を始めます。
図 3-8 アイコンの実行
集計アイコンをつないだ場合、集計についてのパラメータを要求されます。ここでは、
集計方法 : 項目カウンタ
集計対象列名 : 種類 にチェック
と設定して OK ボタンを押します。
図 3-9 集計アイコンのパラメータ設定

13
OK ボタンを押すと処理が開始します。処理が終了すると、メッセージウインドウ(画
面下部分)に OK メッセージが出ます。
図 3-10 メッセージウインドウの表示
集計アイコンの処理が終わると、集計アイコンの「集計」の文字が、黒から赤に変わり
ます。これは、集計アイコンの処理が終わってアイコンが処理結果を保持しているという
ことを示しています。
図 3-11 実行後アイコン名は赤くなる
アイコンが保持している計算結果を確かめるには、処理アイコン(ここでは集計アイコ
ン)を右クリックして、メニューから「データビュー」→「開く」を選択します。結果は
図のように、菖蒲の種類 Setosa, Virginica, Versicolor それぞれが 50 回(50 行)出現して
いることがわかります。
図 3-12 データビュー

14
3.3. 異常なデータを取り除く
取り込んだデータ菖蒲のデータビューを行って、もう一度内容を確認してください。よ
く見ると、がく長が 0 になっている行があります。
図 3-13 菖蒲データ
このように実際のデータには、データの入力ミスや、測定の取りこぼしなどで値が欠落
したり、異常な値が含まれていたりすることがあります5。このような値のことを欠損値と
いいます。欠損値を含んだデータをそのまま処理すると、実態に合わない結果や、矛盾を
含んだ結果を導くことがあるので、データを詳細に分析する前に、この欠損値を何らかの
形で処理する作業(クリーニング)が必要になります。
5 この菖蒲.txt では説明のために、Fisher が用いたオリジナルのデータに人為的に 0 を入
れています。

15
がく長が 0 になっている行を取り除くことにしましょう。オブジェクトブラウザの「デ
ータ操作」以下にあるクリーニングアイコンを貼り付けて、図のように菖蒲から矢印を繋
いで実行します。
図 3-14 クリーニングアイコンの実行
すると、パラメータ設定ウインドウが開きます。がく長が 0 になっている行をデータか
ら取り除くには、がく長のパラメータを次のように設定します。
欠損値検出 : ユーザ指定
欠損値基準 : 0
欠損値補完 : 除外
このパラメータの意味は「がく長がユーザの指定した値(=0)になっている場合、その
行を除外せよ」という意味です。設定が終了したら OK ボタンを押します。
図 3-15 クリーニングアイコンパラメータ設定

16
クリーニングアイコンを右クリックしてデータビューを選択し、内容を確認してくださ
い。元のデータは 150 行ありましたが、クリーニングアイコンの結果は 148 行に減ってい
て、クリーニングで欠損値の含まれていた 2 行が除外されたことがわかります。
図 3-16 上 : データアイコン「菖蒲」の内容、 下 : クリーニングアイコンの内容

17
3.4. データを目で見る
菖蒲のデータの構造を視覚的に把握するために、データをグラフで見てみましょう。
グラフ表示するには、表示したいデータを持っているアイコンの下流に、データ&グラ
フビューアイコンをつなぎます(アイコンは、オブジェクトブラウザの表示フォルダにあ
ります)。ここでは図のようにクリーニングアイコンの下流に繋ぎます。
図 3-17 グラフ表示アイコン
データ&グラフビューアイコンを実行(ダブルクリックで行うことができます)すると、
データビューが現れます。ここでは右上にあるグラフアイコンをクリックしてください。
図 3-18 データビューからグラフビューを呼び出す

18
グラフを描画するウインドウが現れます。ここでは、
X 軸(横軸) : 花びら長
Y 軸(縦軸) : 花びら幅
となるような散布図を描画することにします。画面上部の散布図のグラフをクリックし
てください。
図 3-19 散布図パラメータ設定画面を呼び出す
散布図の設定画面が表示されます。設定画面では、1 行目の x に花びら長を、y に花び
ら幅を設定し、菖蒲の種類ごとの分布を見るために、色には種類を設定します。また、散
布図の点を大きくするためにサイズのラジオボタンを「単位あたり」とし、5.0pt となるよ
うにします。
図 3-20 散布図パラメータ設定
以上の設定ができましたらグラフ設定画面の下部にある OK ボタンをクリックします。
すると、散布図が描画されます。

19
図 3-21 散布図表示の結果(赤い点線は表示されません)
グラフの 1 点がアヤメの測定データ 1 つに対応します。また、種類ごとに色分けされて
表示されます。このグラフを見ると、図の赤い点線でアヤメが 2 つの「かたまり」に分か
れているようにみえます。この「かたまり」のことをクラスタといいます。クラスタとは、
データの性質(ここでは花びら長、花びら幅などの変数)が似ているもの同士の集団のこ
とです。菖蒲のデータの場合、菖蒲の種類ごとに特徴的ながく長、がく幅などの数値を持
っていて、このようなクラスタが形成されるものと考えられます。
それぞれの色が菖蒲のどの種類に対応しているかを表示させるには、右上の凡例ボタン
をクリックします。
図 3-22 凡例の表示
20
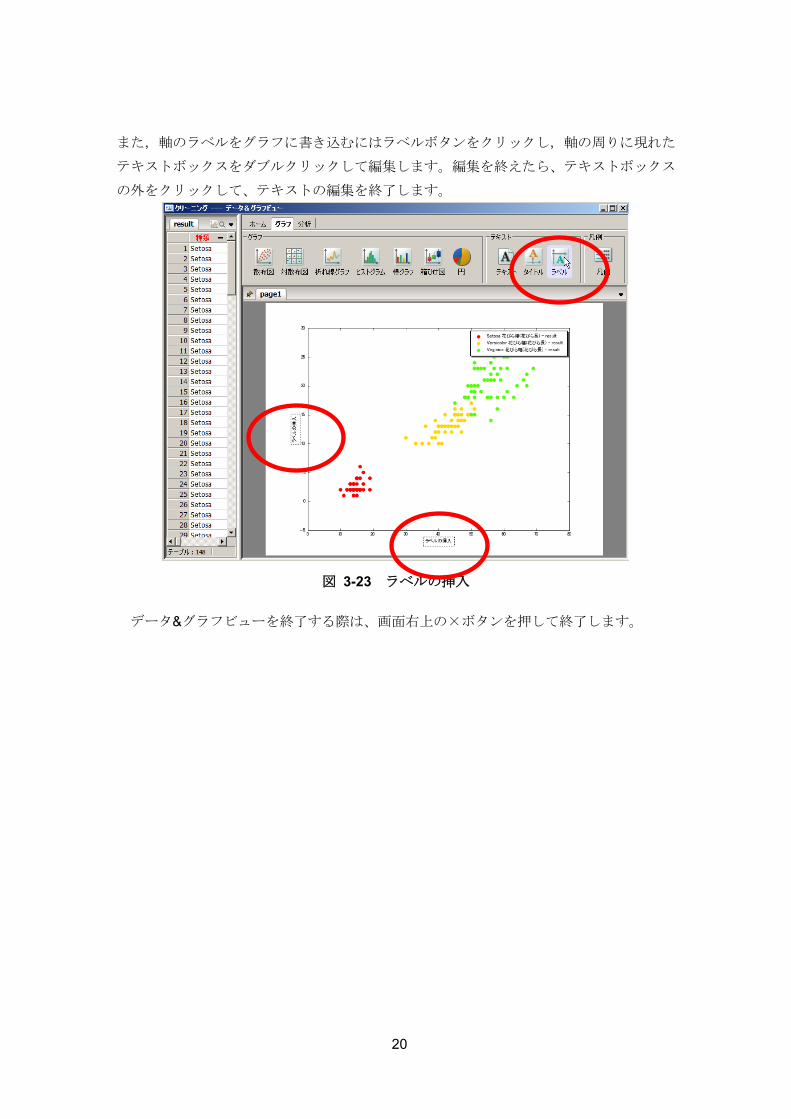
また,軸のラベルをグラフに書き込むにはラベルボタンをクリックし,軸の周りに現れた
テキストボックスをダブルクリックして編集します。編集を終えたら、テキストボックス
の外をクリックして、テキストの編集を終了します。
図 3-23 ラベルの挿入
データ&グラフビューを終了する際は、画面右上の×ボタンを押して終了します。

21
3.5. クラスタを抽出する
グラフ表示で、菖蒲のデータはクラスタを形成していることが確認できましたが、この
クラスタ抽出を自動で行う方法として、クラスタ分析があります。(クラスタ分析を行う
アイコンはオブジェクトブラウザの Visual Mining Studio→クラスタ分析の下にあります)
クラスタ分析は、データの行と行の「近さ」を計算し、近いデータを集団にまとめる分
析手法で、データの集団としての性質を大まかに捉えたい場合に有効な手法です。
クラスタ分析には分割型、凝縮型などの手法がありますが、ここでは分割型クラスタ分
析で最も単純な K-Means 法を用いてアヤメのデータに対してクラスタ分析を行います。
クリーニングをおこなったデータに、K-Means 法アイコンをつなぎます。
図 3-24 K-Means 法アイコン

22
実行すると、パラメータ設定ウインドウが出るので、次のように設定します。
対象列選択: がく長・がく幅・花びら長・花びら幅を選択(×印をつける)
距離計算方法 : Manhattan
クラスタの数 : 3
繰り返し最大数 : 100
規格化オプション: チェックしない
乱数の初期値6:1
図 3-25 K-Means 法アイコンのパラメータ設定
このように指定した場合、対象列名で指定した 4 つの数値列を用いて、データ間の距離
を計算し、距離の近いもの同士をクラスタとして抽出します。
K-Means 法の場合、抽出するクラスタの数は固定です。ここでは菖蒲の種類にあわせて
3 と入力します。
6 乱数の初期値を手動で固定すると、毎回同じ結果を得ることができます。自動を選択す
ると、実行のたびに異なった結果が得られます。
23
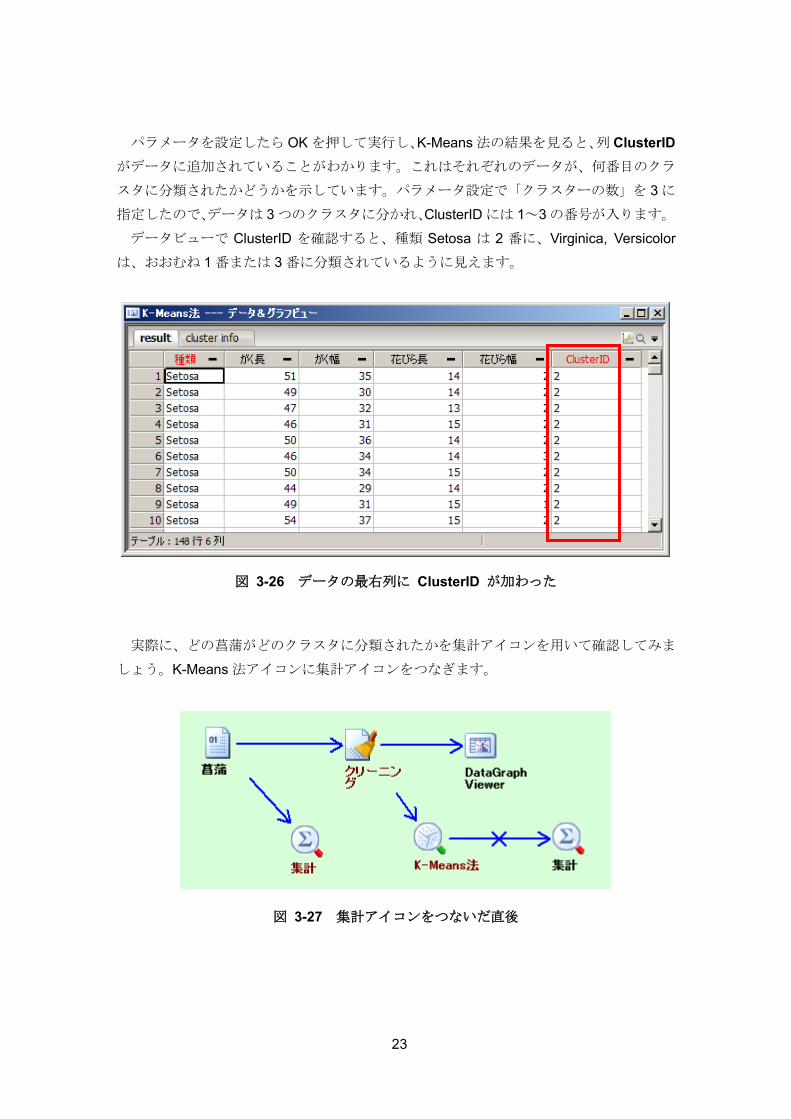
パラメータを設定したら OK を押して実行し、K-Means 法の結果を見ると、列 ClusterID
がデータに追加されていることがわかります。これはそれぞれのデータが、何番目のクラ
スタに分類されたかどうかを示しています。パラメータ設定で「クラスターの数」を 3 に
指定したので、データは 3 つのクラスタに分かれ、ClusterID には 1~3 の番号が入ります。
データビューで ClusterID を確認すると、種類 Setosa は 2 番に、Virginica, Versicolor
は、おおむね 1 番または 3 番に分類されているように見えます。
図 3-26 データの最右列に ClusterID が加わった
実際に、どの菖蒲がどのクラスタに分類されたかを集計アイコンを用いて確認してみま
しょう。K-Means 法アイコンに集計アイコンをつなぎます。
図 3-27 集計アイコンをつないだ直後

24
ここで、K-Means 法から集計アイコンへの矢印に×印が表示されました。この×印は、
K-Means 法の出力が 2 種類ある7ので、どのデータに対して集計を行うのかが決まってお
らず、集計アイコンの入力が不定になっていることに由来するものです。入力を一意に決
めるためには、入力マッチング変更を行います。入力マッチング変更を行うには集計アイ
コンを右クリックして、メニューから入力マッチング変更を選択します。
図 3-28 入力マッチング変更
入力マッチング定義ウインドウが表示されますので、table に対応するデータ名を
K-Means 法(1).result
とします(通常、何もする必要はありません)
図 3-29 入力マッチング定義ウインドウ
7 K-Means 法は図 3-26 で確認したデータ(result)のほかに、cluster info と呼ばれるデ
ータを出力しています。このデータはクラスタの中心の値が含まれています。

25
OK ボタンを押すと、入力が一意に決まり、集計アイコンへの矢印の×印は消えます。
図 3-30 マッチングが取れた状態
集計アイコンを実行して、パラメータを次のように指定します。
集計方法 : 項目カウンタ
集計キー列名 : 種類
集計対象列名 : ClusterID
これは「菖蒲の種類ごとに ClusterID をカウントする」という意味です。
図 3-31 集計アイコンの実行

26
実行結果は、図のようになります。
図 3-32 集計結果
この結果は、例えば 4 行目は
「種類 Versicolor のうち、ClusterID 1 番のものは、全部で 48 個(48 行)ある」
ということを意味しています。
集計結果からは、次のことがわかります。
Setosa は、すべて 2 番のクラスタに分類された。Setosa は Virginica, Versicolor と
は異なる特徴を有している種類である。
Versicolor は、1 番、Virginica は 3 番のクラスタに属するものが多いが、そうでな
いものもある。両者は異なる性質を有しているものの、やや類似しているといえる
であろう。
K-Means 法のパラメータ設定で、対象列として「種類」は指定しませんでした。しかし、
数値列(がく長、がく幅、花びら長、花びら幅)の情報だけからでも、菖蒲のデータがい
くつかの特徴的な集団を形成していることがわかりました。
このように、クラスタ分析はデータの識別子であるクラス(ここでは種類)がわからな
い場合でも、特徴の似ているもの同士の集団を抽出する手法として用いられます。

27
3.6. 作業を中断します
作成した処理フローを保存するには、プロジェクトという単位で保存します。プロジェ
クトを保存するには図のように、メニューから プロジェクト → 名前をつけて保存を選
択します。
図 3-33 名前をつけてプロジェクトを保存
名前を入力して、OK を押すとプロジェクトが保存されます。ここでは、Project1.pr0 と
いう名前をつけて保存します。

28
図 3-34 プロジェクト名を入力
保存したプロジェクトはオブジェクトブラウザのプロジェクトに表示されます。プロジ
ェクトの編集を再開するには、右クリックメニューからプロジェクトを開くを選択します。
図 3-35 プロジェクトを開く

29
3.7. この章のまとめ
この章では次のことを学びました。
データの導入方法(インポート)
集計アイコンの使い方
欠損値の処理(除外)の方法
グラフ表示アイコンの使い方
クラスタ分析の基礎
プロジェクトの保存

30
4. データ「market」を分析する
この章では、market というデータを用いて、
モデリングアイコン(Tree & Random Forest)を使う
モデリングアイコンを用いて予測を行う
ことを目的にデータ分析を行います。
4.1. データの取り込み
まず、market データをインポートしましょう。market データは、ルートフォルダ
¥Samples¥Visual Mining Studio 以下にあります。「菖蒲」を取り込んだのと同様にして、
エクスプローラなどからドラッグ&ドロップしてデータアイコンを作成します。
図 4-1 market データをプロジェクトボード上に配置
market アイコンをダブルクリックして、
カンマ区切り
usage のみ実数、残りの列を文字列
としてインポートします。今回は特に設定の変更の必要はありませんので、そのまま
OK ボタンをクリックしてください。

31
図 4-2 データインポート画面設定
次に usage 列は本来、整数列なので、列属性の変更を行います8。market データから列
属性変更アイコンへ矢印を結びます。
図 4-3 列属性変更アイコンへの接続
8 データインポートの画面で usage 列の列属性を整数と変更して読み込もうとすると、テ
キストは実数であるのに整数で読み込もうとするため、警告が発生し、エラー処理方法、
エラー時補填値の設定に従って値が書き換えられてしまいます。
32
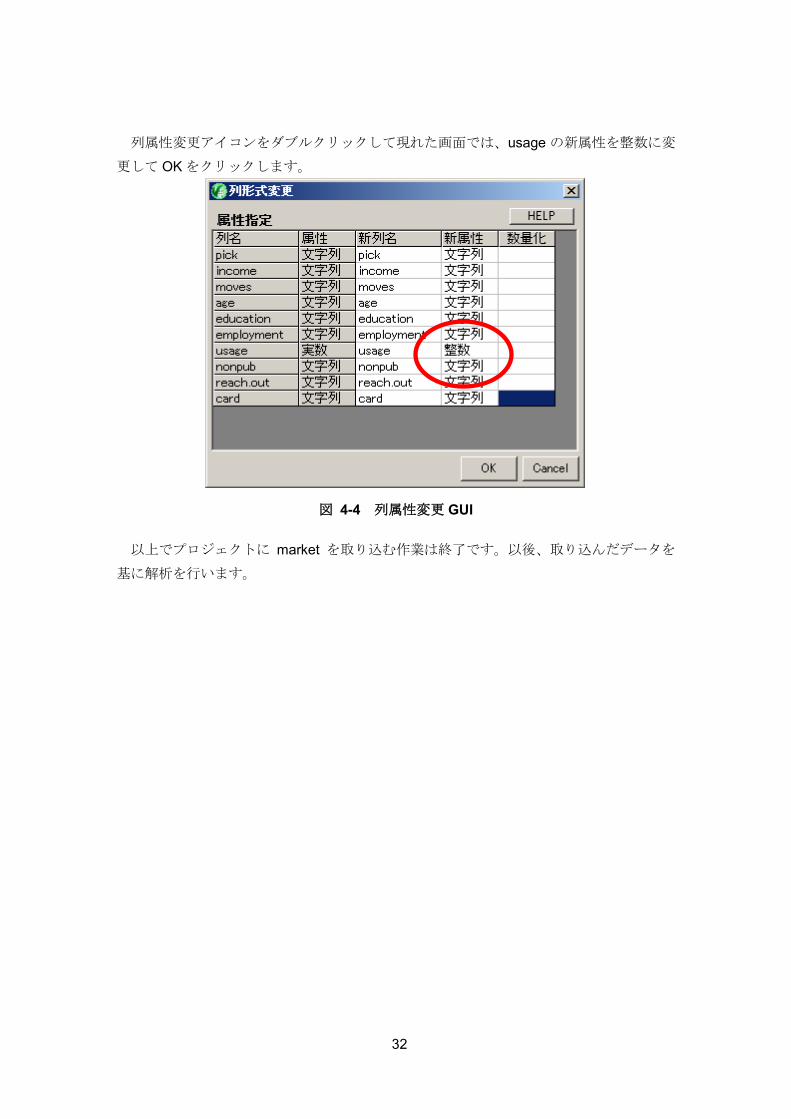
列属性変更アイコンをダブルクリックして現れた画面では、usage の新属性を整数に変
更して OK をクリックします。
図 4-4 列属性変更 GUI
以上でプロジェクトに market を取り込む作業は終了です。以後、取り込んだデータを
基に解析を行います。

33
4.2. データの意味と解析の目的
この market というデータは 1986 年に、アメリカの電話会社 AT&T が長距離電話会社の
選択に関して行った市場調査のデータです。データの各行が顧客に対応していて、それぞ
れの顧客の属性や、選択した電話会社などの情報で構成されています。
図 4-5 データ「market」(列属性変更後)
データの各列は、それぞれ次のような意味を持っています。
pick 優先的に選択する電話会社
income 収入
moves 過去5年間の引越し回数
age 年齢
education 学歴
employment 職種
usage 月平均利用時間
nonpub 電話帳に載せないかどうか
reach.out 割引サービスに加入していたか
card 電話利用カードの有無
このうち pick は、AT&T を選択したか、それ以外の電話会社を選択したか、ということ
を意味しており、AT&T にとっては自分の会社を選択したかどうか、という非常に重要な
変数となります。またこれ以外の列は、顧客の収入、年齢などの属性データになっていま
す。

34
では、このデータから、どのような人が AT&T を選択する傾向があるか分析できないで
しょうか。また、収入や年齢が既知の場合に、その人がどの電話会社を選択するかを予測
できないでしょうか。それができれば、電話会社は新規顧客を獲得するときに、対象を限
定できることになります。
このような分析を行うには、分類分析を行います。分類分析では、まず列 pick が既知の
データを用いて、収入や学歴等の個人情報から、その顧客が優先的に選択する長距離電話
会社を予測するモデルを作成します。そして、そのモデルを用いて、未知の顧客がどの電
話会社を選択するかを予測する、という手順を取ります(図 4-6)
図 4-6 モデルの作成と予測(概念図)

35
4.3. 欠損値を除外する
もう一度、元のデータを眺めてください。一部に "NA" というデータがあるのがわかり
ます。この "NA" というデータは Non-Available(利用不可) の頭文字をとったもので、
「そのデータが取得できなかった」または「そのデータが不明である」ということを明示
的にあらわす記号です。
このような欠損値(→3.3 節を参照)を含んだまま、データを解析するのは困難ですの
で、ここではクリーニングアイコンを用いて "NA" を含む行を除外します。図のように列
属性変更アイコンの下流にクリーニングアイコンをつけてください。
図 4-7 クリーニングアイコンの配置
前章で行ったように、クリーニングのパラメータを指定しますが、このデータの場合、
usage を除いたすべての列で "NA" が出現します。1 列ごとにパラメータを指定しても良
いですが、この作業は非常に面倒です。以下のように行うと、複数の列に対して同じパラ
メータを一度に指定することができます。
まず income の「欠損値検出」を「ユーザ指定」とします。
次に、Shift キーを押したまま、card の「欠損値検出」欄を左クリックします。すると、
すべての列の「欠損値検出」欄が「ユーザ指定」に変更されます。
36
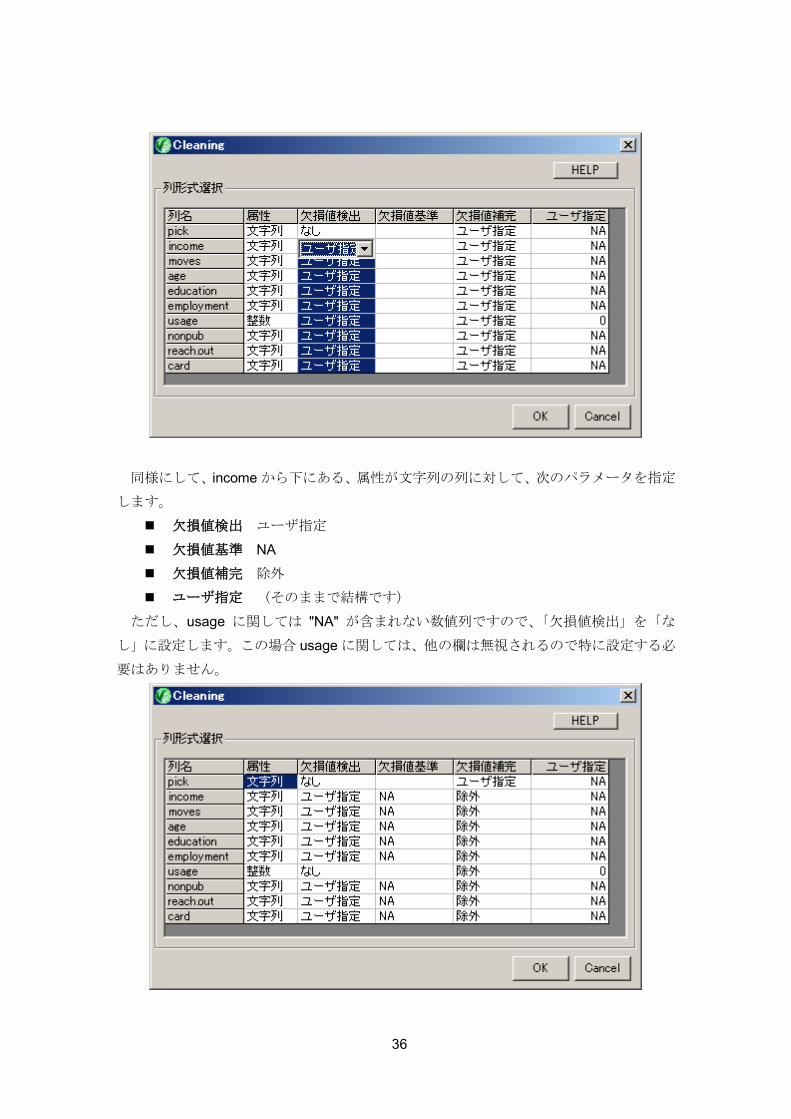
同様にして、income から下にある、属性が文字列の列に対して、次のパラメータを指定
します。
欠損値検出 ユーザ指定
欠損値基準 NA
欠損値補完 除外
ユーザ指定 (そのままで結構です)
ただし、usage に関しては "NA" が含まれない数値列ですので、「欠損値検出」を「な
し」に設定します。この場合 usage に関しては、他の欄は無視されるので特に設定する必
要はありません。

37
すべてのパラメータの設定が終わったら、OK ボタンを押してクリーニングを実行しま
す。実行前に 1000 行あったデータは、データビューで確認すると 759 行に減っているこ
とが確認できます。

38
4.4. 要因を分析する
データのクリーニングが終了しましたので、このデータに対して pick を予測するための
モデルを作成します。このモデルを作成するためにここでは Decision Tree (決定木)を
使用します。
決定木は、図のような木構造のモデルを用います。未知のデータのクラスを予測するに
は、根(ルート)から始まるノードを順次たどっていきます。各ノードには条件が書かれ
ていて、その条件に対応するような枝を順次たどります。そして最後に行き着いた終端ノ
ード(または葉)にはそれぞれクラスが対応していて、このクラスが予測結果となります。
例えば、図の決定木の場合、Age が "35-44"、Card が "N" となっているデータは、根
から最も右の枝をたどって4番の葉に到達し、pick は ATT であることがわかります。
決定木を用いた分析を行うには、まずクラスがわかっているデータから、クラスを予測
するための決定木を作成する必要があります。作成をおこなうアイコン(Tree & Random
Forest アイコン9)は、オブジェクトブラウザの Visual Mining Studio → モデリング の
下にあります。このアイコンをクリーニングアイコンの下流につないで実行してください。
9 Ver 8.1 より追加されたアイコンです。旧来の DecisionTree アイコンと比べて、決定木
モデル構築のユーザーインターフェースを大幅に刷新しています。また Random Forest
(複数のランダムな決定木によるアンサンブルモデル。詳しくは VMStudio 技術資料等を
参照)機能を新たに追加しています。ここでは新アイコン(Tree & Random Forest)の方
を用いて分析を行います。
1: ATT
Age ?
Usage ? Card ?
2: OCC 3: OCC 4: ATT
35未満
20 未満 Y 20 以上 N
35以上
根
葉

39
実行すると、Tree & Random Forest のパラメータ設定ウインドウが現れます。
図 4-8 パラメータ設定ウインドウ
ここで以下のようにパラメータを設定します。ここでは、表示されたそのままのパラメ
ータを利用することにします。
生成方法 … 対話画面での成長
分岐方法 … Gini 係数
節点最小データ数 … 0.8 (%)
変数の最大分岐数(共通) … 5
節点の不純度 … 0.01

40
高さ制限 … 無制限
目的変数 … pick
説明変数 … income ~ card すべてをチェック
最大分岐数…カテゴリ列は無制限、数値列は共通(=5)
パラメータ入力ウインドウで実行を押すと、Decision Tree の対話作成画面が現れます。
最初に表示されている四角は、根(ルートノード)に当たります。ノードの中に描かれ
た円グラフは、ノードに含まれるデータ(ここではルートノードなので全データ)につい
て、目的変数のクラスの割合を表します。ノード上にマウスカーソルを当てると、クラス
の割合が数値で表示され、OCC を 46.6%、ATT を 53.4%の人が選択したことが分かりま
す。
図 4-9 ノードの内訳
この状態では、根はそのまま葉となっており、葉は一枚しかないため、すべてのデータ
を ATT と予測することになります。ユーザはこの対話画面で、ノードを一段ずつ成長させ
ていくことにより、より良い予測をする決定木を作成する必要があります。

41
このルートを成長(分岐)させるには、ノードを右クリックして一段成長を選択します。
すると、データから最も効率の良い分岐変数を選択して、枝が成長します。「分岐条件」
にチェックを入れると、選択された分岐変数と分岐条件が表示されます。この例では、分
岐変数として usage が選択され10、ルートノードから、5 つの子ノードが成長します。
10
ここで usage を選んだのは、パラメータ設定画面の「分岐方法」で指定した Gini 係
数で見たときに最も効率のよい分岐変数になっているからです。分岐変数を手動で選択す
るには、ノードを右クリックしてメニューから強制分岐を指定します(詳しくはマニュア
ルを参照してください)
チェックを入れます
分岐条件が表示されます
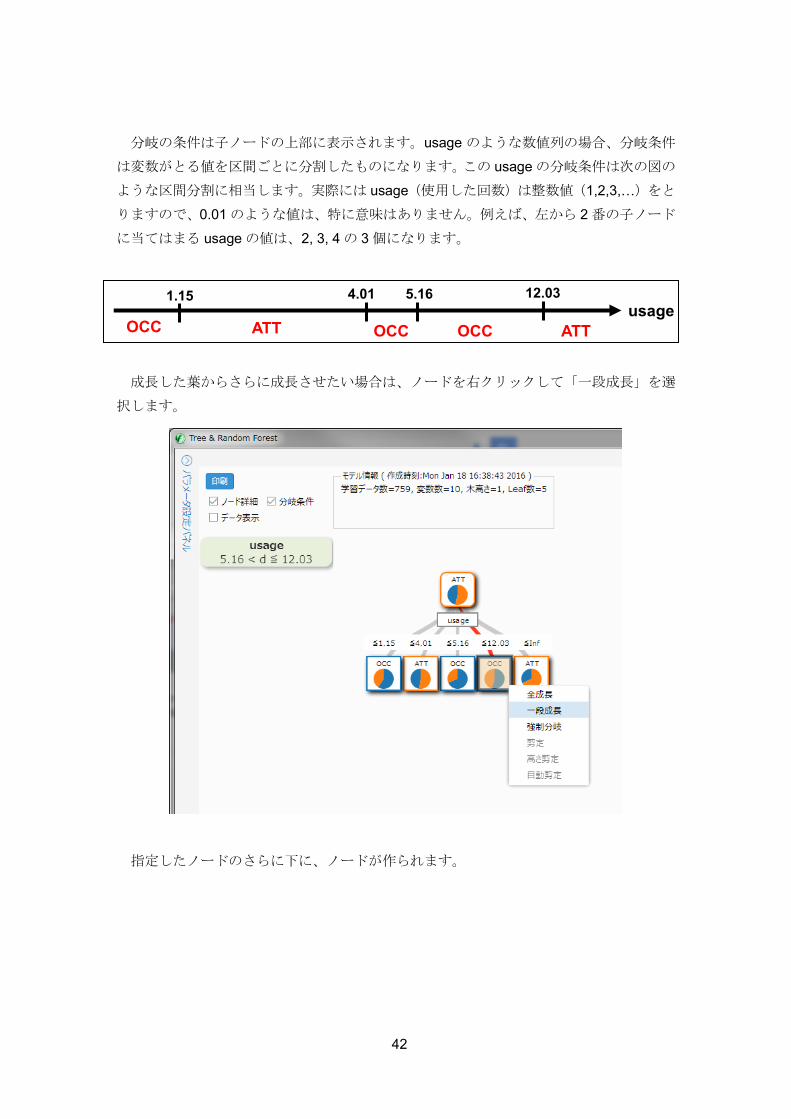
42
分岐の条件は子ノードの上部に表示されます。usage のような数値列の場合、分岐条件
は変数がとる値を区間ごとに分割したものになります。この usage の分岐条件は次の図の
ような区間分割に相当します。実際には usage(使用した回数)は整数値(1,2,3,…)をと
りますので、0.01 のような値は、特に意味はありません。例えば、左から 2 番の子ノード
に当てはまる usage の値は、2, 3, 4 の 3 個になります。
成長した葉からさらに成長させたい場合は、ノードを右クリックして「一段成長」を選
択します。
指定したノードのさらに下に、ノードが作られます。
usage 12.03 5.16 4.01 1.15
ATT OCC OCC ATT OCC

43
この一段成長をすべてのノードに対して行い、末端まで成長させるには、ルートノード
を右クリックして全成長を選択します。

44
全成長が終了すると、図のような表示になります。
ツリーが大きくなって表示しきれない場合は、マウスのホイールを上下に動かしたり、
右上のスームスライドを調整することで、表示エリアを自由に縮小・拡大することが出来
ます。
図 4-10 縮小してツリーの全体を表示
45
ツリーの作成を終了するには、ウインドウ右上端の×ボタンをクリックするか、閉じる
ボタンをクリックします。結果は次のようになります。Tree & Random Forest アイコンの
中身をデータビューで見ると、図のようになっています。
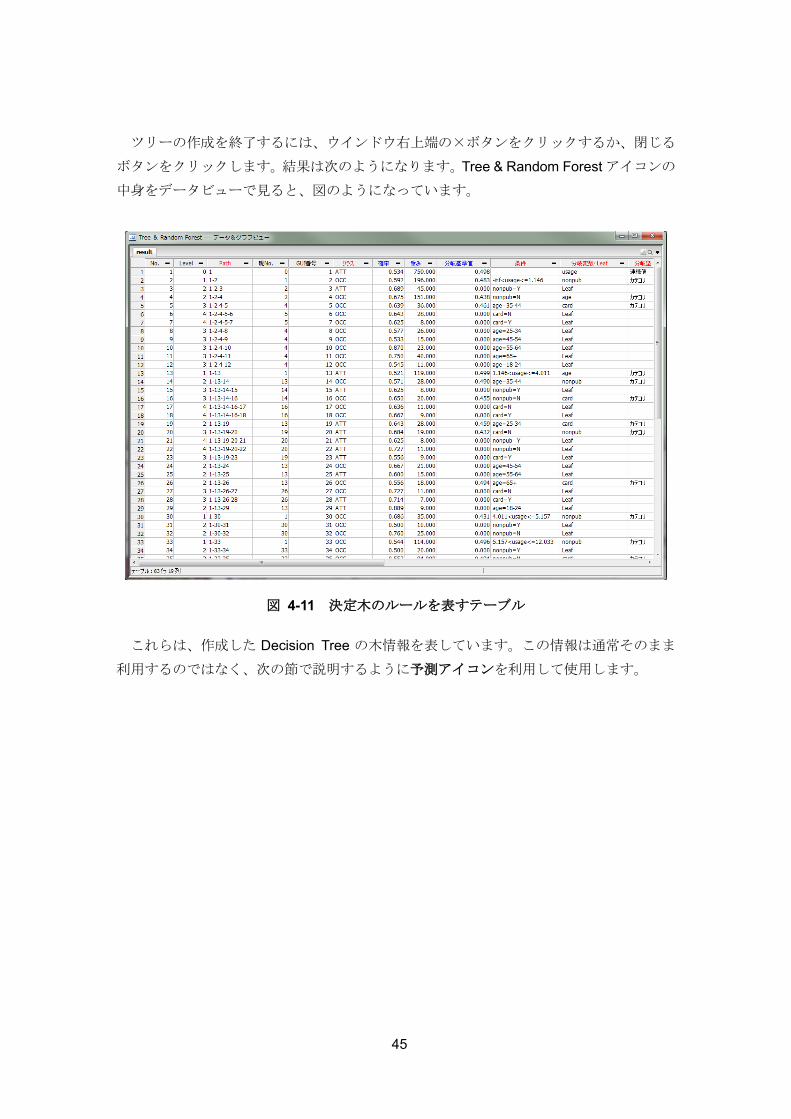
図 4-11 決定木のルールを表すテーブル
これらは、作成した Decision Tree の木情報を表しています。この情報は通常そのまま
利用するのではなく、次の節で説明するように予測アイコンを利用して使用します。

46
4.5. モデルを検証する
前節で Decision Tree を用いてクラスを予測するモデルを作成しました。このモデルの
性能を評価するには予測アイコンを利用します。
予測アイコンを利用するには、まず、オブジェクトブラウザの Visual Mining Studio →
モデリング → 予測 をプロジェクトボードに貼り付けます。そして、Tree & Random
Forest とクリーニングアイコンから 2 本の矢印線を結んで図のようなフローを作成しま
す。
このフローはいったい何を意味しているのでしょうか?まずクリーニングアイコンから
は、データが予測アイコンに流れます。そして Tree & Random Forest アイコンからは作
成したモデルそのものが予測アイコンに流れます。予測アイコンでは、入力データに対し
て、入力したモデルを適用して予測・検証を行います11。
このように予測アイコンは、データとモデルを組で入力して用います。データだけ、モ
デルだけで利用することはできません。また、入力するモデルは、Tree & Random Forest
だけではなく、モデリングフォルダの下にあるモデル作成アイコンならどれでも利用可能
です。
11
この例では、モデル作成に用いたデータを予測に用いています。しかし、モデルは学習
に用いたデータに偏った学習をする(過学習と言います)ことがあり、例のような評価方
法は実はあまり良い方法ではありません。一般的には入力データを分割して、一方で学習
し、一方でモデルの評価をおこなったりします。

47
予測アイコンを実行すると、図のようなパラメータ設定画面が現れます。
ウインドウの一番上には、入力したモデルの情報があわられます。ここでは、Decision
Tree で学習したモデルであることが表示されます。
また、処理選択欄では、このアイコンで行う処理を選択します。ここではモデルの性能
評価を行いたいので、検証を選択します。また、出力オプションの「対象データも出力」
のチェックは不要です。
OK ボタンを押すと処理が開始します。結果は図のようになります。
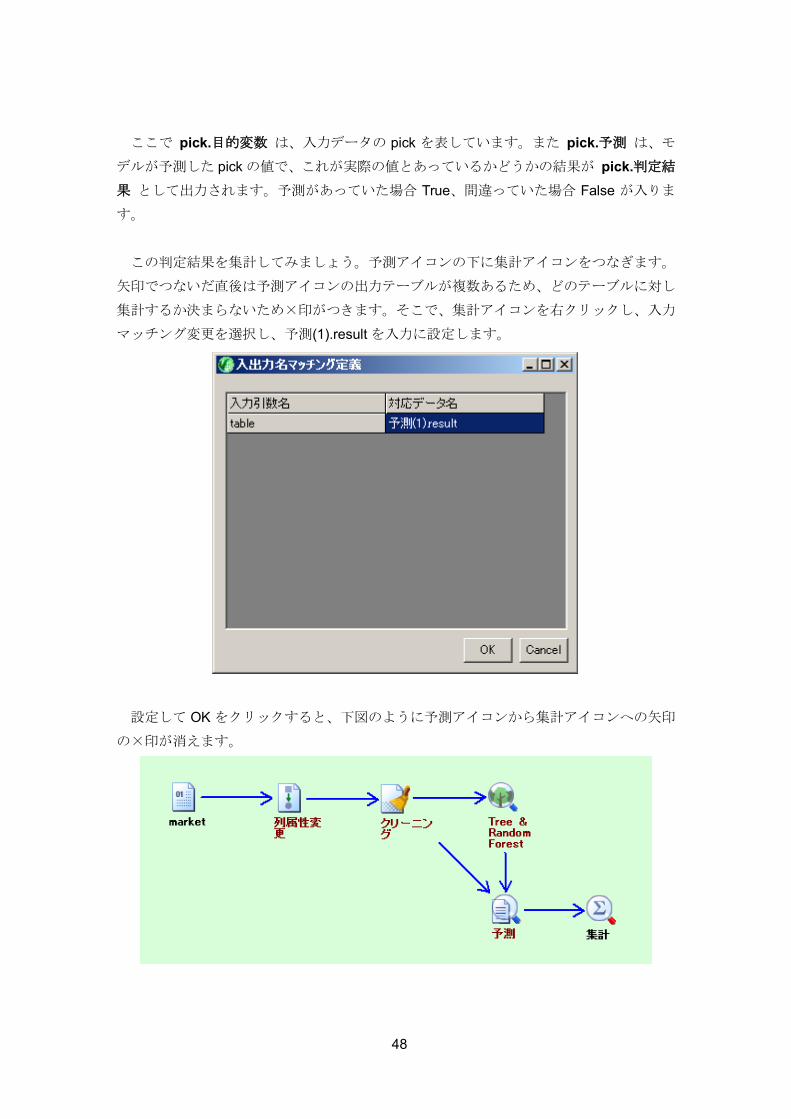
48
ここで pick.目的変数 は、入力データの pick を表しています。また pick.予測 は、モ
デルが予測した pick の値で、これが実際の値とあっているかどうかの結果が pick.判定結
果 として出力されます。予測があっていた場合 True、間違っていた場合 False が入りま
す。
この判定結果を集計してみましょう。予測アイコンの下に集計アイコンをつなぎます。
矢印でつないだ直後は予測アイコンの出力テーブルが複数あるため、どのテーブルに対し
集計するか決まらないため×印がつきます。そこで、集計アイコンを右クリックし、入力
マッチング変更を選択し、予測(1).result を入力に設定します。
設定して OK をクリックすると、下図のように予測アイコンから集計アイコンへの矢印
の×印が消えます。

49
集計アイコンを起動し、パラメータを次のように設定します。
集計方法 … 項目カウンタ
集計キー列名 … pick.目的変数
集計対象列名 … pick.判定結果
実行した結果を見ると、次のようにクラスごとに判定結果を集計した値が表示されます。
この結果から、約 30%の確率で誤った結果を返していることがわかります。

50
4.6. この章のまとめ
この章では次のことを学びました。
列属性変更、クリーニングアイコンを使った、データの前処理
Decision Tree によるモデル作成
作成したモデルの評価

51
5. POS データを分析する
この章では、スーパーマーケットにおける購入データ(POS データ)を用いて、
アソシエーション分析(バスケット分析)を行う
POS 分析に対する集計を行う
ことを目的にデータ分析を行います。
5.1. データの導入
この章で使うPOSデータは、サンプルプロジェクトPOSデータ.prjに収められており、
このプロジェクトからデータだけを取り出す作業が必要です。以下のようにプロジェクト
をインポートして、データを抽出してください。
まず、VMStudio を利用する製品として選択した状態で、メニューバーの プロジェクト
→ インポート を選択します。
ファイル選択ウインドウが開きますので、ルートフォルダ(→7 ページの脚注を参照)
¥Samples¥Visual Mining Studio フォルダに移動し、POS 分析.prj を選択します。

52
プロジェクトがインポートされ、表示されます。
次に、このプロジェクトの POS データアイコン をオブジェクトブラウザのデータフォ
ルダにドラッグ&ドロップします。POS データが、データフォルダに取り込まれます。実
際の PC 上では、ルートフォルダ¥Users¥[ユーザ名]¥データ 以下に保存されます。

53
この POS データを分析する新規のプロジェクトを作成しましょう。メニューバーの プ
ロジェクト → 新規作成 を選択します。そして図のように POS データをプロジェクトに
ドラッグ&ドロップしてデータを貼り付けます。
これで POS データを分析する準備が整いました。

54
5.2. アソシエーション分析とは
導入したデータをダブルクリックして、データビューウインドウを開いて中身を見てく
ださい。このデータは擬似的に作成した、スーパーマーケットにおける商品購入データで
す。
図 5-1 商品購入データ
データの列は、それぞれ次のような意味を持っています。
ID番号 … レシートごとに一意につけられた通し番号
商品名 … 購入した商品の名前
数量 … 商品を購入した個数
金額 … 商品の単価
ID番号 1つがそれぞれ来店客 1人に対応し、それぞれの来店客が購入した商品の情報が、
商品名、数量、金額として現れています。例えば ID 番号 1 の来店客は、乳製品とパンを 1
つずつ購入して、合計 247 円の買物をしたことがわかります。
アソシエーション分析12は、このようなスーパーマーケットのデータなどに対して、ど
の商品が同時に購入されているか、どの商品の組み合わせが頻繁に現れるか、というルー
ル(前提と結論)を抽出する分析のことです。アソシエーション分析は、どの商品の組み
合わせが買い物かご(バスケット)に入れられるかについての分析であることから、バス
12
アソシエーション分析は、このような POS データに対する分析だけではなく、さまざ
まな事象間の関連性を導くのに用いることができます。

55
ケット分析とも呼ばれます。
図 5-2 アソシエーション分析は、バスケット分析とも呼ばれる
この分析の結果、乳製品とパンが同時購入される頻度が高いことがわかれば、このスー
パーのパンの売り場に乳製品(牛乳やヨーグルト)を置くことや、パンの購入者に対して
乳製品を割り引くようなキャンペーンを実行すれば、パンと乳製品の売上が上昇すること
が期待されます。
56
5.3. アソシエーション分析アイコンを使う
導入したデータに対してアソシエーション分析をおこなってみましょう。アソシエーシ
ョン分析アイコンは、オブジェクトブラウザの Visual Mining Studio → アソシエーショ
ン分析 フォルダの下にあります。アイコンを貼り付けて POS データからのフローを作成
します。
アソシエーション分析アイコンをダブルクリックして、パラメータ設定画面を開きます。
ここでは次のようにパラメータを指定します(図 5-3)
最低サポート(%) … 0
最低信頼度(%) … 0
ルールの長さ13 … 2 (注意!)
Lift … 0
Conviction … 0
対象列名 … 商品名だけにチェックを入れる。
次に「オプション」タブをクリックして、次のようにパラメータを設定します(図 5-4)。
キー列 … ID 番号
出力オプション… 列番号
以上の設定ができましたら、OK ボタンをクリックしてください。
13
「ルールの長さ」は、前提のルールの長さと結論のルールの長さの和です。指定した値
以下の長さになるルールのみを抽出します。ルールの長さを 2 とすると、前提のルールは
1 つ、結論のルールは 1 つということになります。

57
図 5-3 アソシエーション分析のパラメータ設定
図 5-4 アソシエーション分析のオプション設定

58
5.4. 分析結果とルールの重要性
アソシエーション分析アイコンを右クリックし、データビューを選択して実行結果を見
てみましょう。
図 5-5 アソシエーションルールの結果
この結果は、1 つの行がそれぞれ 1 つのルール(ここでは買物のパターン)を表してい
ます。例えば、1 行目は、
前提… 2-ベビー用品
結論… 2-菓子
となっています。これは、「ベビー用品を買った場合に、菓子を買うというルール」を表し
ています。(頭文字の "2" は、「商品名」が元のデータの 2 列目であることを意味します)
またそれぞれのルールには、次のような指標が対応しています。
信頼度
サポート
Lift (リフト)
これらの指標は、ルールの重要性を判定するために欠かせないものです。以下、順を追
って説明します。

59
もう一度、図 5-5 の 1 行目に注目します。
前提 … 2-ベビー用品
結論 … 2-菓子
信頼度 … 100.00
サポート … 0.220
信頼度とは、仮にルールの前提が起きたと仮定したときに、結論が起きる確率を表しま
す。例えばこのルールの場合、「ベビー用品を買った人が、100%の確率で菓子を購入する」
ということを意味しています。この数値が高ければ高いほど、ルールの前提と結論の結び
つきが高いということができます。すると、「ベビー用品を買った人は、必ず菓子を購入し
ているので、非常に重要な情報だ」と思われるかもしれませんが、実はそうではありませ
ん。
サポートを見てください。サポートとはルールの前提と結論が同時に起きる確率、つま
り「ルールそのものが起きる確率」を表します。「ベビー用品 → 菓子」というルールの場
合、サポートが 0.220%、つまり「ルールそのものが生じる確率」は 0.220% 程度しかな
く、このルールは約 500 回に 1 回しか起こらないことがわかります。ルールそのものがほ
とんど起きないため、このルールはあまり重要とはいえません。
以上からわかるように、信頼度が大きいからといって、ルールが重要だとは単純には言
えません。重要なルールは、サポートもそれなりに大きいことが求められます。
信頼度とサポートを考慮して、重要なルールだけを抽出してみましょう。既に貼り付け
てあるアソシエーション分析アイコンを右クリックして「実行」を選択してください。パ
ラメータを再設定するためのウインドウが開きます。
★ 実行と再実行
「実行」と「再実行」の違いに注意してください。すでに実行がされて、アイコンの名
前が赤くなっている場合、それぞれ動作は次のようになります。
実行
パラメータを設定するウインドウが開きます。パラメータは前回設定した値が既に
入力されています。OK を押すと、アイコンの計算が開始します。
再実行
前回設定したパラメータを用いて、計算を行います。

60
パラメータ設定画面で、次のように変更してください。
最低サポート … 1
最低信頼度 … 10
こうした場合、サポートが 1% 以上、信頼度が 10% 以上のルールだけを取り出すこと
になります。また、抽出するルールを制限することで、探索すべきルールが少なく済み、
計算時間が大幅に短縮される場合があります。
OK ボタンを押して、計算を行います。

61
結果は、次のようになります。
図 5-6 サポート、信頼度を制限したアソシエーション分析の結果

62
5.5. リフトの値を見る
信頼度とサポートを制限した分析結果を良く見ると、結論に「野菜」を含むルールが、
たくさん現れています。これらのルールは本当に重要なのでしょうか?
アソシエーション分析の結果をもう一度見てみましょう。一行目の結果をすべて書き出
すと以下のようになっています。
前提 … 2-パスタ パスタソース
結論 … 2-野菜
信頼度 … 82.353
サポート … 1.847
Lift … 1.534
Conviction … 2.624
ルール.数 … 42
前提.数 … 51
結論.数 … 1221
キー.数 … 2274
ここで最後の 4 項目を見てください。まずキー.数とは、データの中に現れたキーの数(こ
こではレシート ID の数)を表しています。このデータでは、のべ 2274 人が買物を行った
データであることがわかります。ルール.数とは、「パスタ パスタソース → 野菜」という
ルールがデータの中に現れた回数です。つまり、「パスタ パスタソース」と「野菜」を同
時に購入した客の数が 42 人いることを意味しています。
一方、前提.数、結論.数は、前提、結論が現れたキーの数を示しており、「パスタ パス
タソース」を購入したのは 51 人、「野菜」を購入したのが 1221 人いることがわかります。
ここで、「パスタ パスタソース」の人数に比べて、「野菜」の人数が非常に多くなってい
ることがわかります。「野菜」は、お客さんの大体半分近くが購入している商品であり、仮
に「パスタ パスタソース」と「野菜」の間の関連性が全くなかったとしても、信頼度は
50% 近くあることになります。つまり、「野菜」を結論に含むものは、仮に信頼度とサポ
ートが大きかったとしても、重要なルールであるとは、単純には言い切れません。
このような場合、リフト(Lift)14の値を用いると、前提と結論の間の結びつきが強いも
のを抽出することができます。リフトは、次の式で計算されます。
)(
)()(
BP
ABPBALift
14
リフトは興味値(Interest)、あるいは相関(Correlation)とも呼ばれます。
63
これは今取り上げている「パスタ パスタソース → 野菜」の場合、次のことを意味しま
す。
実際に値を入れると、
となり、リフトの値は 1.534 となります。
リフトは、前提が存在することで、結論がおこる確率がどれだけ大きくなるかの比を表
しており、リフトが 1 の場合は、全く前提の存在が効いていないことになります。リフト
が 1 より大きければ大きいほど、その効果は大きくなります。「パスタ パスタソース → 野
菜」の場合は、リフト 1.534 で「それなりに前提の存在が効いている」といえるでしょう。
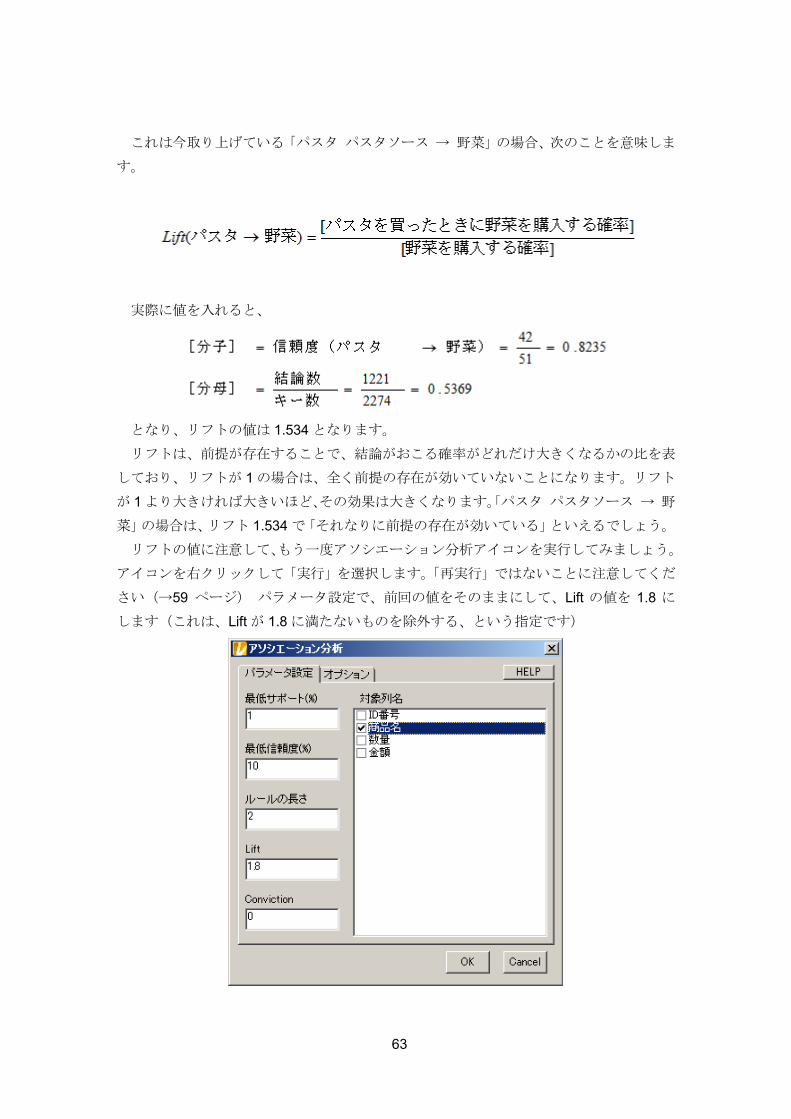
リフトの値に注意して、もう一度アソシエーション分析アイコンを実行してみましょう。
アイコンを右クリックして「実行」を選択します。「再実行」ではないことに注意してくだ
さい(→59 ページ) パラメータ設定で、前回の値をそのままにして、Lift の値を 1.8 に
します(これは、Lift が 1.8 に満たないものを除外する、という指定です)
64
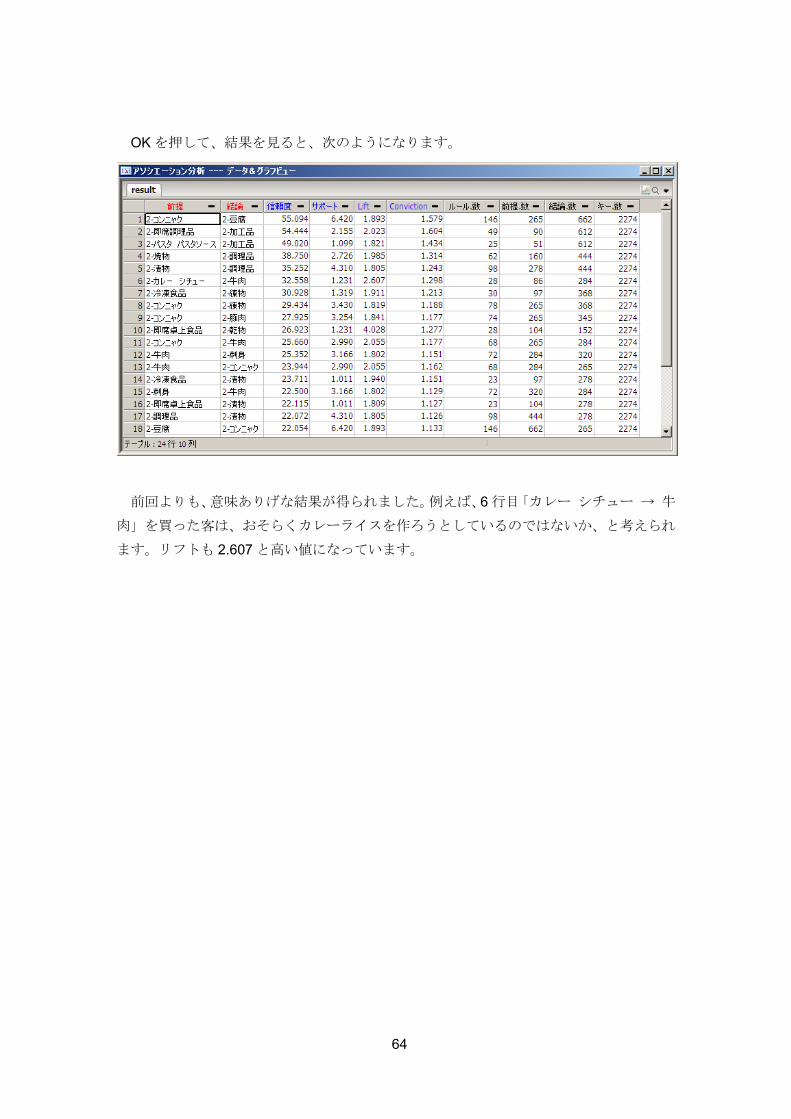
OK を押して、結果を見ると、次のようになります。
前回よりも、意味ありげな結果が得られました。例えば、6 行目「カレー シチュー → 牛
肉」を買った客は、おそらくカレーライスを作ろうとしているのではないか、と考えられ
ます。リフトも 2.607 と高い値になっています。

65
5.6. 長いルールを抽出する
前節までの分析で導出できたルールは、前提・結論でそれぞれ商品名が 1 つずつのもの
に限られていました。もっとたくさんの商品名がつながったルールを導出したい場合は、
パラメータ設定で、ルールの長さを増やします。ここでは、ルールの長さを 4 として、も
う一度アソシエーション分析アイコンを実行してみましょう。
結果は次のようになります。

66
結果は、A+B+C などのように、商品名の組み合わせで表されます。例えば 1 行目は
前提 : 2-牛乳+2-果実+2-豚肉
結論 : 2-野菜
信頼度 : 100
となっていますが、これは「牛乳と果実と豚肉を同時に買った場合、さらに野菜を買う
確率は 100%」となることを意味しています。前提は、それら 3 商品が同時に購入される
ことを意味することに注意してください。
ここでも、野菜が結論に多く現れています。Lift を再度設定して実行してもよいですが、
次のようにして有用なルールを見てみましょう。
データビューウインドウの列タイトル Lift の右にある「-」を 2 回クリックします。

67
1 回目のクリックで Lift が昇順に、2 回目のクリックで Lift が降順になるよう行を並び替
えてテーブルが表示されます15。Lift という文字の左には 1 という数字がついていますが、
これは複数列をキーにソートしたときに、どの列を優先してソートするかという順番を表
しています。
図 5-7 Lift 列をキーにしたソート
15
このソートを行っても、アソシエーション分析アイコンの処理結果は変化しません。こ
のソートでは表示される順番が変わるだけです。ソートアイコンは、ソートしたデータそ
のものを結果として持っています。この違いに注意してください。
68
5.7. この章のまとめ
この章では次のことを学びました。
アソシエーション分析アイコンの基本的な使い方
アソシエーションルールの指標となるパラメータ
重要なアソシエーションルールの抽出
★ 「market」を解析してみる
本章の説明では、アソシエーション分析アイコンを POS データに対して使ってきまし
た。しかし、アソシエーション分析アイコンは、必ずしも商品購入データの間の関連性を
導くためだけに用いられるわけではありません。
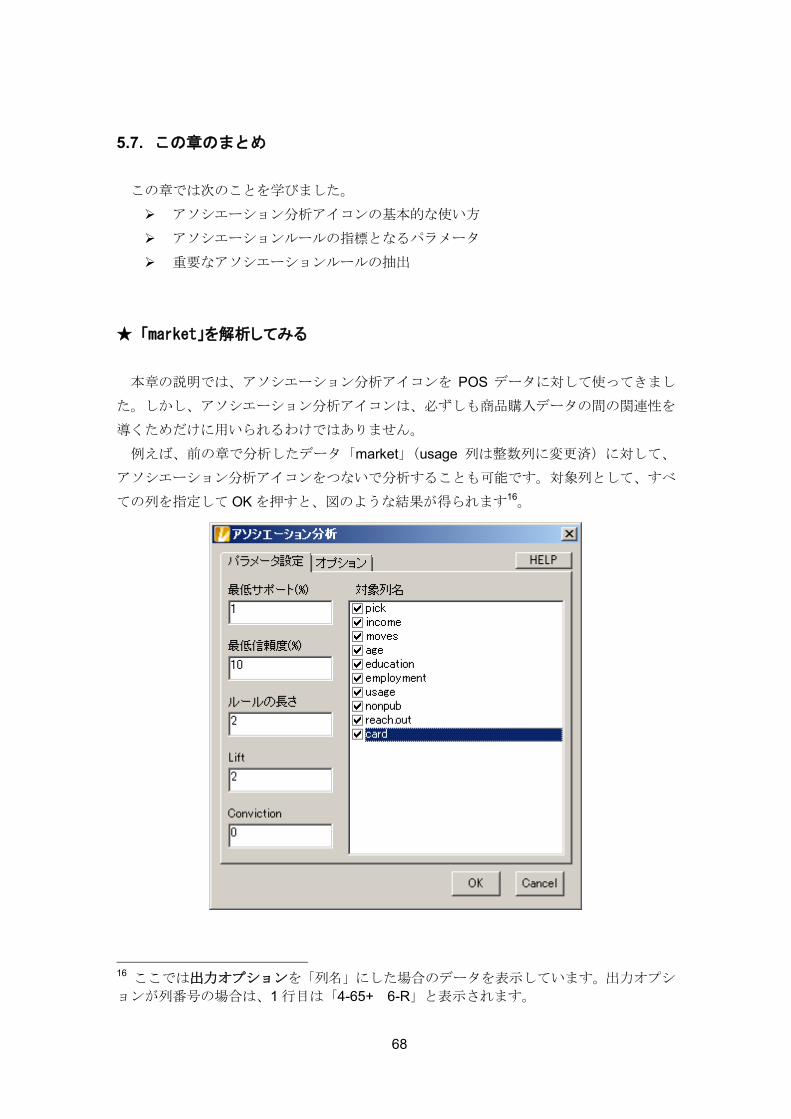
例えば、前の章で分析したデータ「market」(usage 列は整数列に変更済)に対して、
アソシエーション分析アイコンをつないで分析することも可能です。対象列として、すべ
ての列を指定して OK を押すと、図のような結果が得られます16。
16
ここでは出力オプションを「列名」にした場合のデータを表示しています。出力オプシ
ョンが列番号の場合は、1 行目は「4-65+ 6-R」と表示されます。

69
例えば、1 行目は「65 歳以上(age-65+)ならば、仕事をやめている(employment-R)
確率が 87.387% である」ということを意味しています。つまり顧客の属性間の関連性を
引き出していることになります。このように、複数の列にまたがった関連性の分析も可能
です。

70
索引
D
Decision Tree 38
アイコン 38
一段成長 41
強制分岐 41
全成長 43
対話作成画面 40
分岐変数 41
保存&閉じる 45
K
K-Means 法 21
アイコン 21
L
Lift 62, 63, 66
N
NA → 欠損値
あ
アソシエーション分析 54
アイコン 56
結論 58
出力オプション 68
前提 58
ルールの長さ 65
アソシエーションルール 54
か
過学習 46
く
クラス 26
クラスタ 19
クラスタ分析 21
グラフ表示
アイコン 17
クリーニング 14
アイコン 15, 35
け
欠損値 14, 35
検証 47
さ
再実行 59
サポート 59
し
集計
アイコン 11, 25, 48
信頼度 59
て
データ
データインポート 9, 30
データビュー 10

71
データファイル 7
取り込み 7
データビュー 13
データビューウインドウ内でのソート
66
に
入力マッチング変更 24
は
バスケット分析 55
ふ
フロー 12
プロジェクト 27
インポート 51
新規作成 53
名前をつけて保存 27
開く 28
分類分析 34
め
メッセージウインドウ 13
も
モデル 34
モデル作成アイコン 46
や
矢印線 11
よ
予測 34
アイコン 45, 46
り
リフト → Lift
る
ルートフォルダ 7, 51
れ
列属性変更
アイコン 31