xen benchmark sistemi paravirtualizzati
TRANSCRIPT

Università degli Studi del Sannio Facoltà di Ingegneria
Corso di laurea in Ingegneria Informatica
Analisi delle prestazione di sistemi cluster in ambienti paravirtualizzati
Relatore Ch.mo Prof. Umberto Villano
Candidato Flavio Pace 195001062
1

Sommario 2
¨ Overview Virtualizzazione • Definizione, Principi, Benefici • Tipi di virtualizzazione
¨ Architettura di Xen • Architettura • Ruolo dei domini • Profiling
¨ Ambiente di Test e Risultati ¨ Conclusioni ¨ Sviluppi futuri
Virtualizzazione
Definizione • La logica suddivisione delle risorse fisiche di un computer in multipli
ambienti di esecuzione
Principi • Lanciare multiple istanze di SO contemporaneamente • Garantire isolamento tra i vari SO • Gestione e controllo delle risorse condivise • Amministrazione centralizzata
Benefici • Consolidamento Server • Failover e Disaster Recovery • Ambienti personalizzati di Debugging e di Test • Alta scalabilità • Riduzione dei costi
3
Tipi di Virtualizzazione
¨ Full Virtualization ¨ Paravirtualization ¨ Hardware-Assisted
Virtualization ¨ Kernel-level Virtualization
4
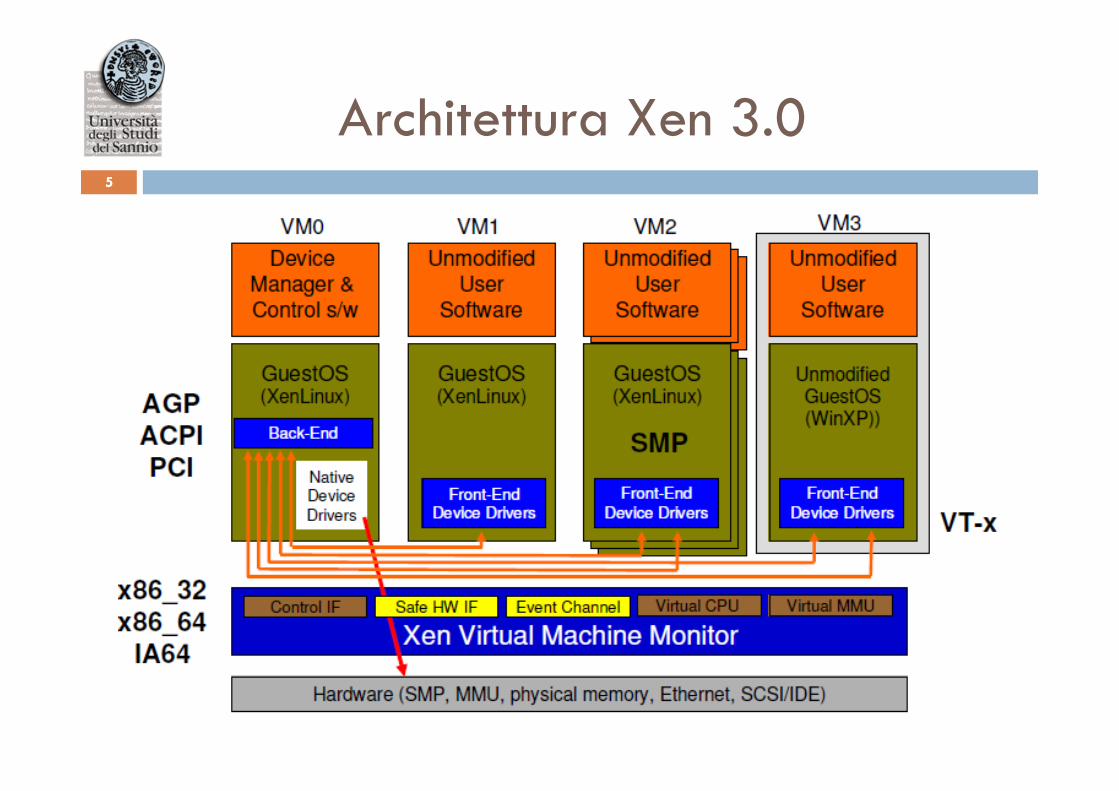
Architettura Xen 3.0 5
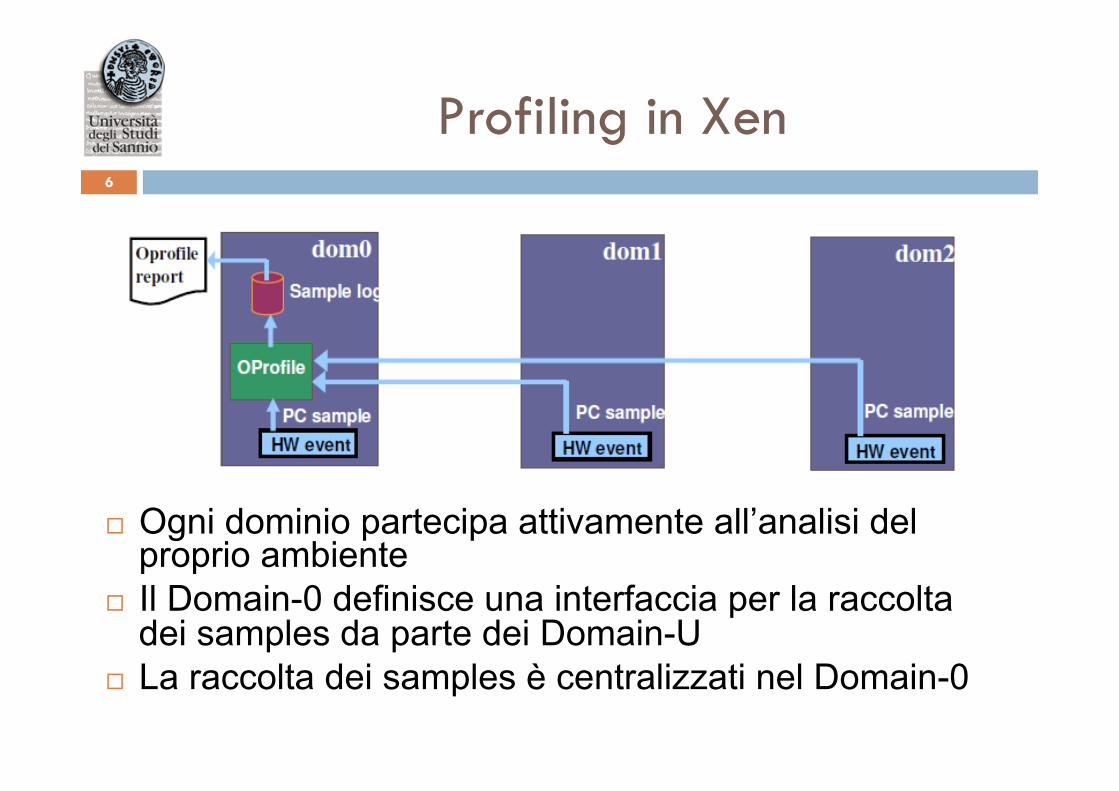
Profiling in Xen 6
¨ Ogni dominio partecipa attivamente all’analisi del proprio ambiente
¨ Il Domain-0 definisce una interfaccia per la raccolta dei samples da parte dei Domain-U
¨ La raccolta dei samples è centralizzati nel Domain-0
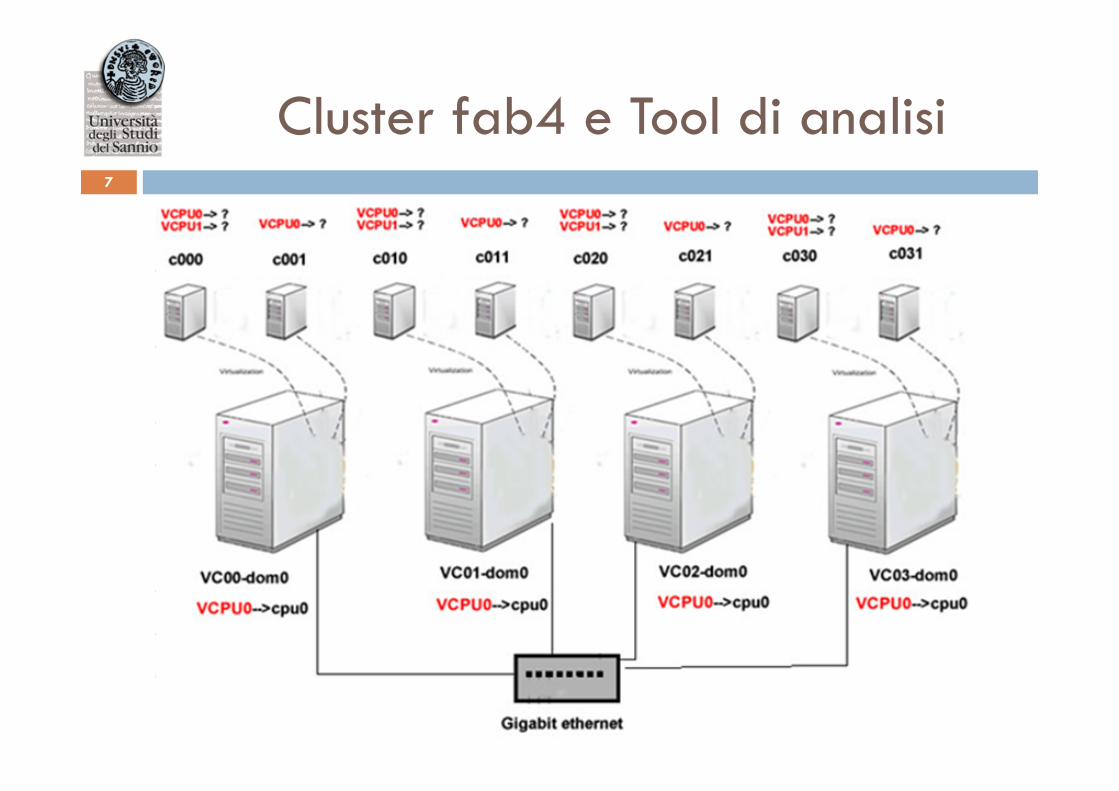
Cluster fab4 e Tool di analisi 7
Cluster fab4 • Il cluster è formato da un front-end e da 4 nodi
computazionali virtualizzati • I nodi sono interconnessi tra loro tramite uno switch
Gigabit Ethernet • Rocks 5.1 (CentOS 5) • La virtualizzazione dei nodi avviene tramite Xen 3.0
I tool di analisi usati sono: • Netperf • Pathload • Xenoprof
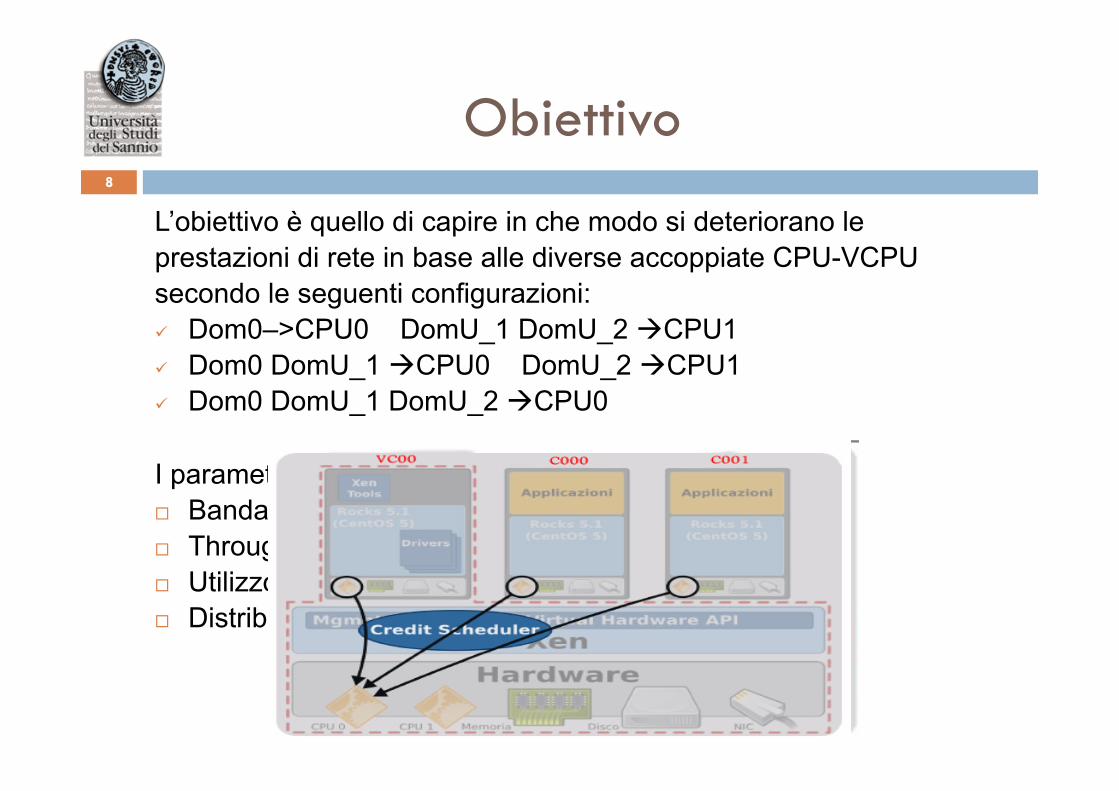
Obiettivo 8
L’obiettivo è quello di capire in che modo si deteriorano le prestazioni di rete in base alle diverse accoppiate CPU-VCPU secondo le seguenti configurazioni: ü Dom0–>CPU0 DomU_1 DomU_2 àCPU1 ü Dom0 DomU_1 àCPU0 DomU_2 àCPU1 ü Dom0 DomU_1 DomU_2 àCPU0 I parametri presi in considerazione sono stati: ¨ Banda disponibile ¨ Throughput di rete ¨ Utilizzo della CPU dei processi sender e receiver ¨ Distribuzione degli eventi hardware
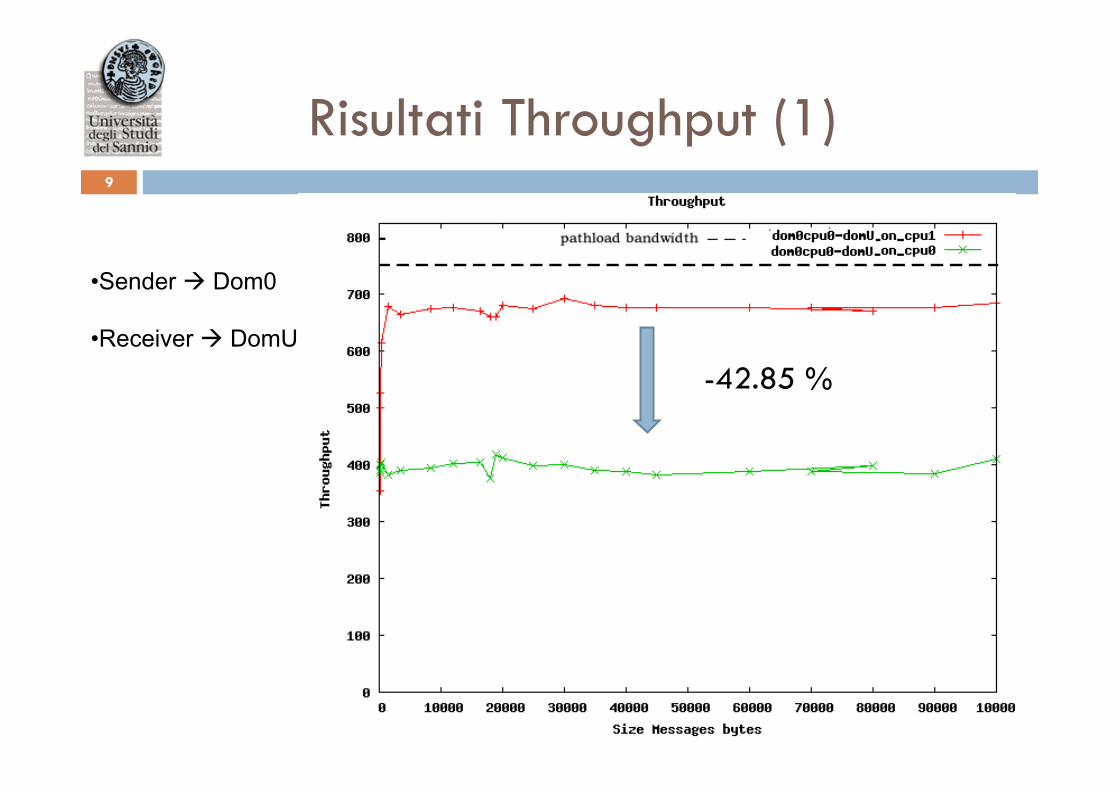
Risultati Throughput (1) 9
• Sender à Dom0 • Receiver à DomU
-42.85 %
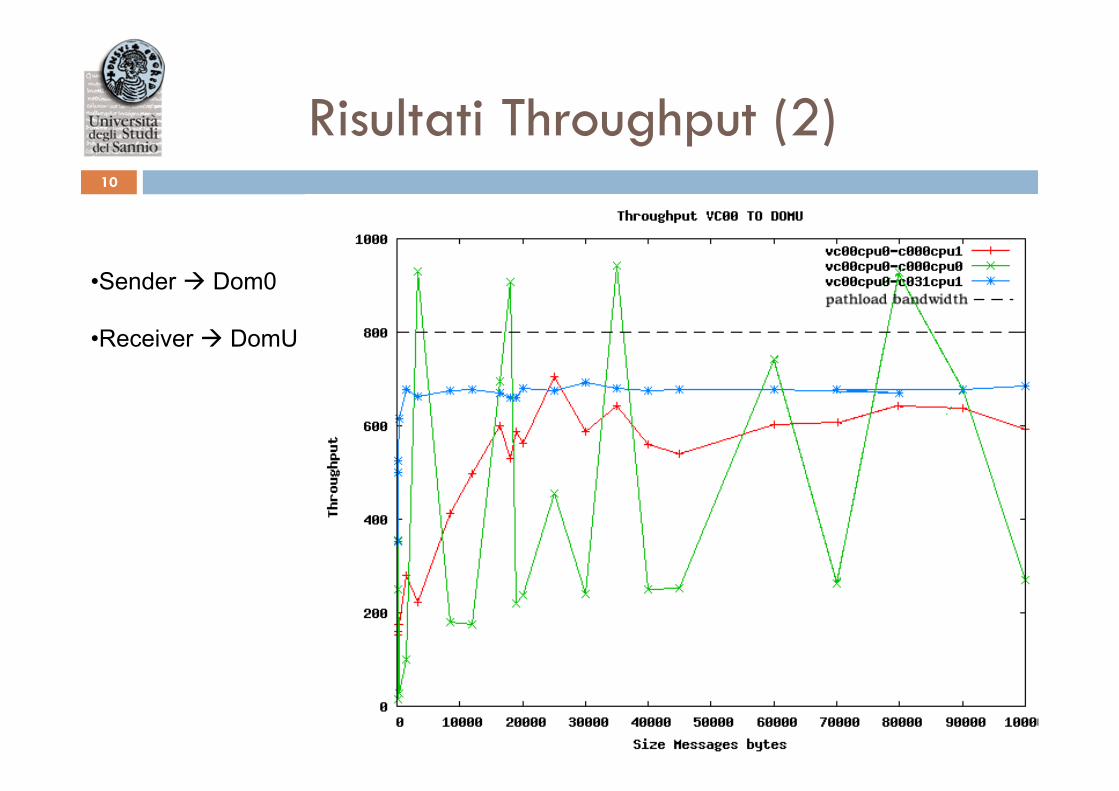
Risultati Throughput (2) 10
• Sender à Dom0 • Receiver à DomU
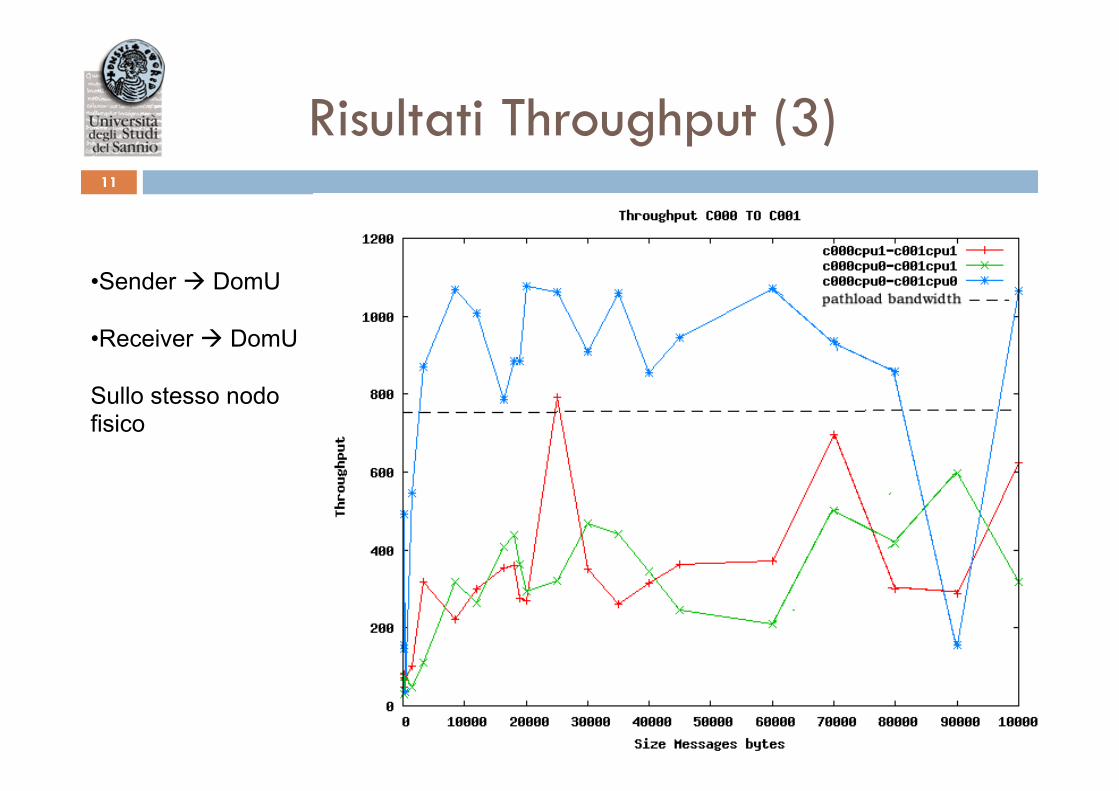
Risultati Throughput (3) 11
• Sender à DomU • Receiver à DomU
Sullo stesso nodo fisico
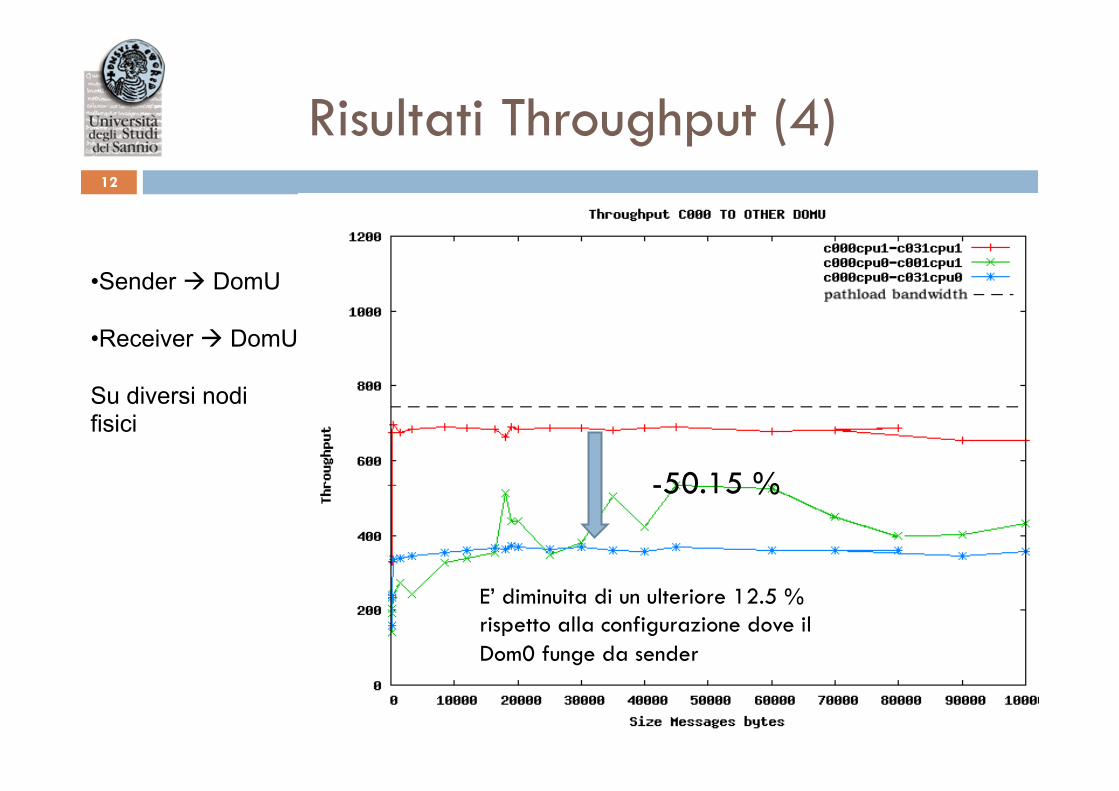
Risultati Throughput (4) 12
• Sender à DomU • Receiver à DomU
Su diversi nodi fisici
-50.15 %
E’ diminuita di un ulteriore 12.5 % rispetto alla configurazione dove il Dom0 funge da sender
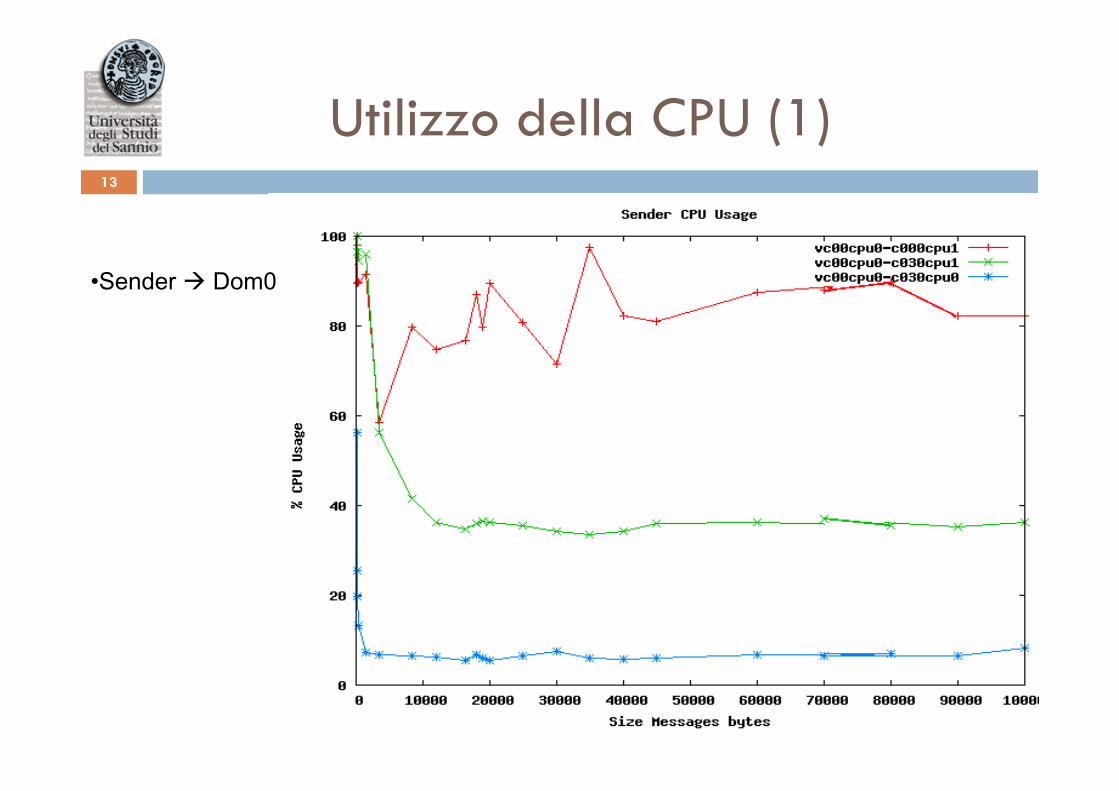
Utilizzo della CPU (1) 13
• Sender à Dom0
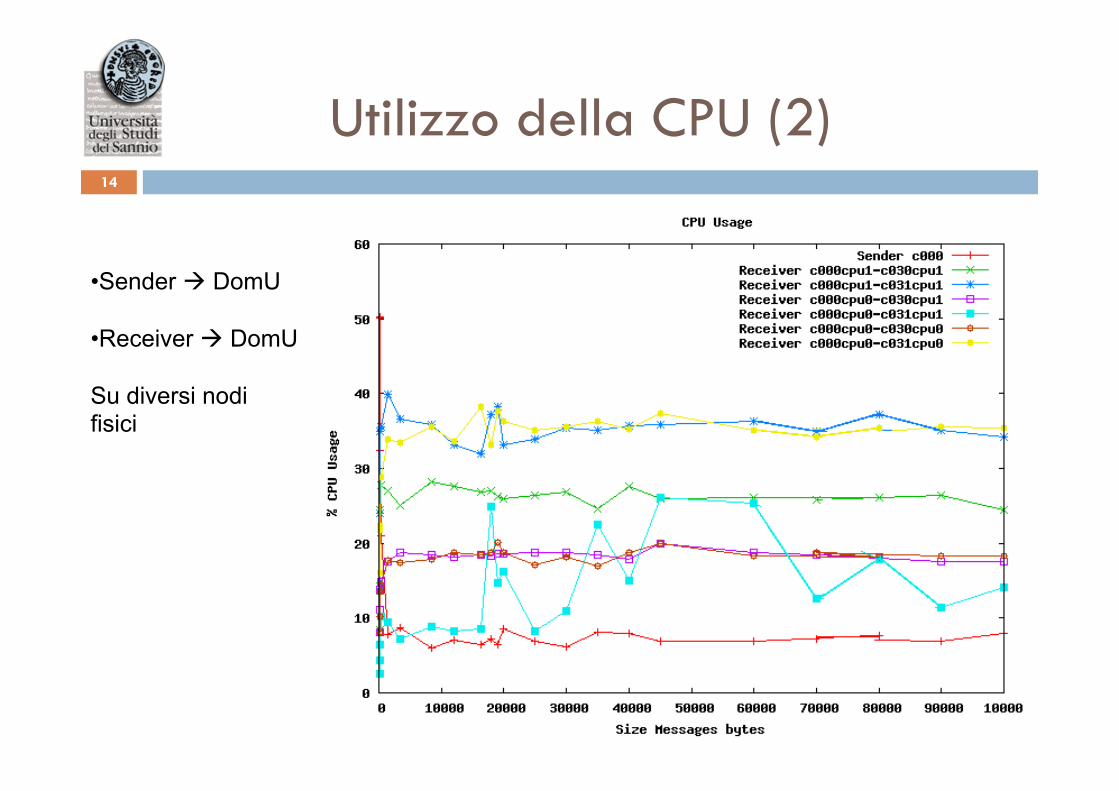
Utilizzo della CPU (2) 14
• Sender à DomU • Receiver à DomU
Su diversi nodi fisici
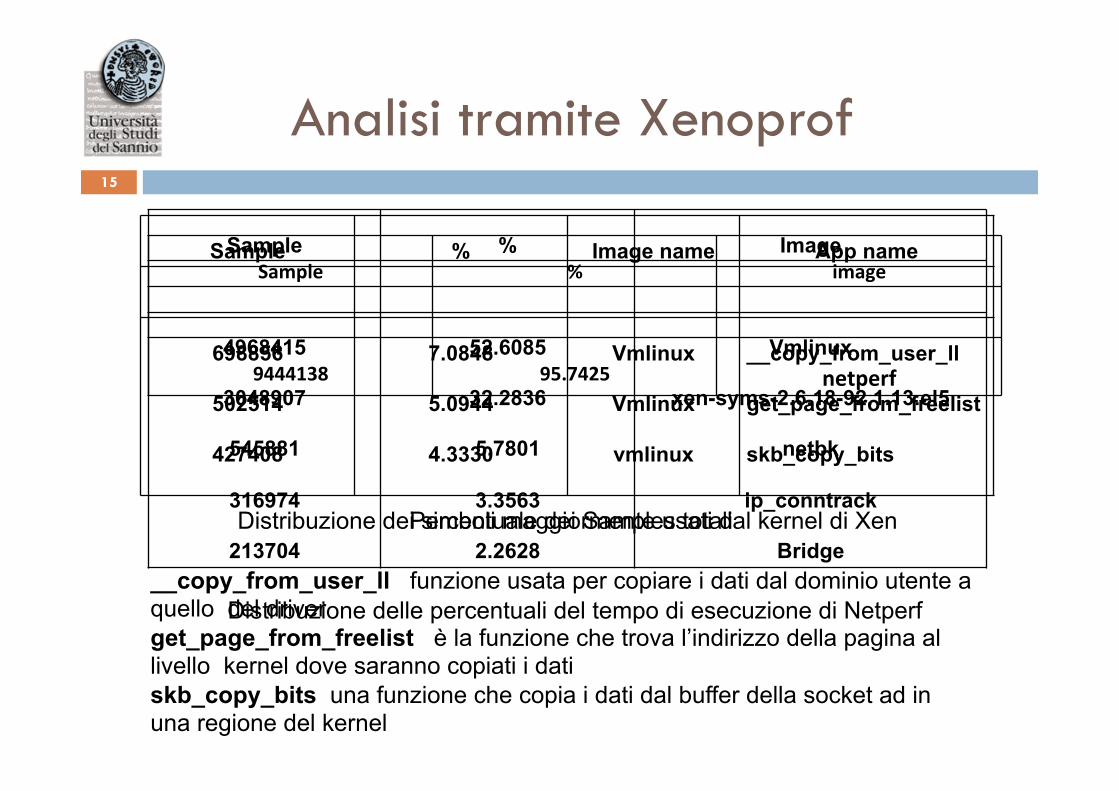
Sample % Image
4968415
3048907
545881
316974
213704
52.6085
32.2836
5.7801
3.3563
2.2628
Vmlinux
xen-syms-2.6.18-92.1.13.el5
netbk
ip_conntrack
Bridge
Analisi tramite Xenoprof 15
Sample % image
9444138 95.7425 netperf
Percentuale dei Samples totali
Sample % Image name App name
698856
502514
427408
7.0848
5.0944
4.3330
Vmlinux
Vmlinux
vmlinux
__copy_from_user_ll
get_page_from_freelist
skb_copy_bits
Distribuzione delle percentuali del tempo di esecuzione di Netperf
Distribuzione dei simboli maggiormente usati dal kernel di Xen
__copy_from_user_ll funzione usata per copiare i dati dal dominio utente a quello del driver get_page_from_freelist è la funzione che trova l’indirizzo della pagina al livello kernel dove saranno copiati i dati skb_copy_bits una funzione che copia i dati dal buffer della socket ad in una regione del kernel
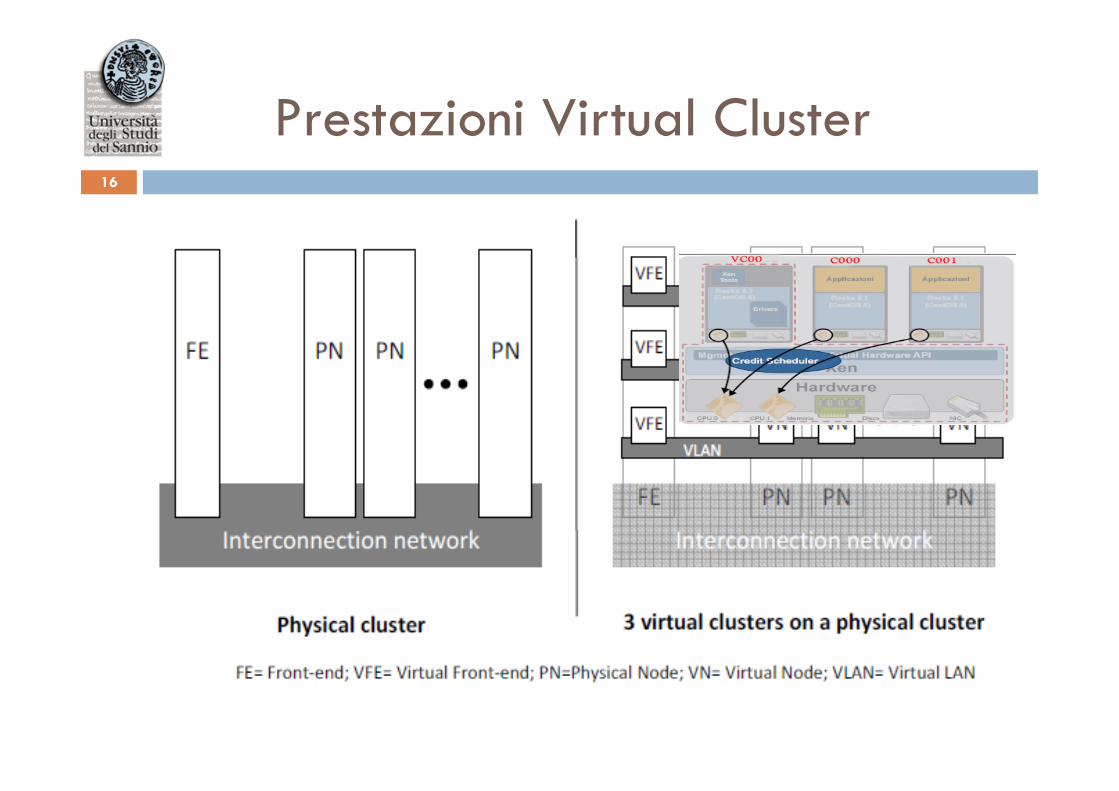
Prestazioni Virtual Cluster 16
¨ 3 nodi fisici, ogni nodo con due macchine virtuali oltre al Dom0
¨ 2 Virtual Cluster VC0 e VC1 • VC0 IMB-MPI1 (PingPong) • VC1 carico computazionale (NAS)
¨ Le VMs di VC0 girano sulla CPU0 assieme al Dom0 ¨ Le VMs di VC1 girano sulla CPU1
¨ Il Middleware utilizzato per i test è stato MPICH
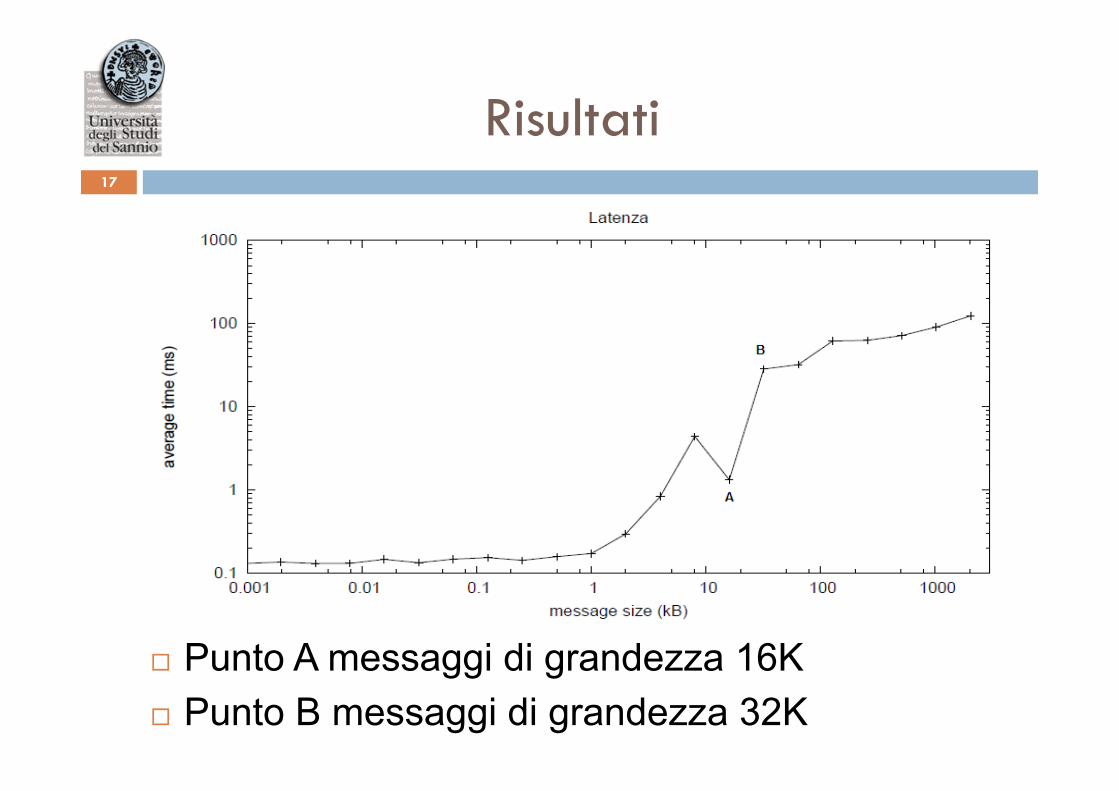
Risultati 17
¨ Punto A messaggi di grandezza 16K ¨ Punto B messaggi di grandezza 32K
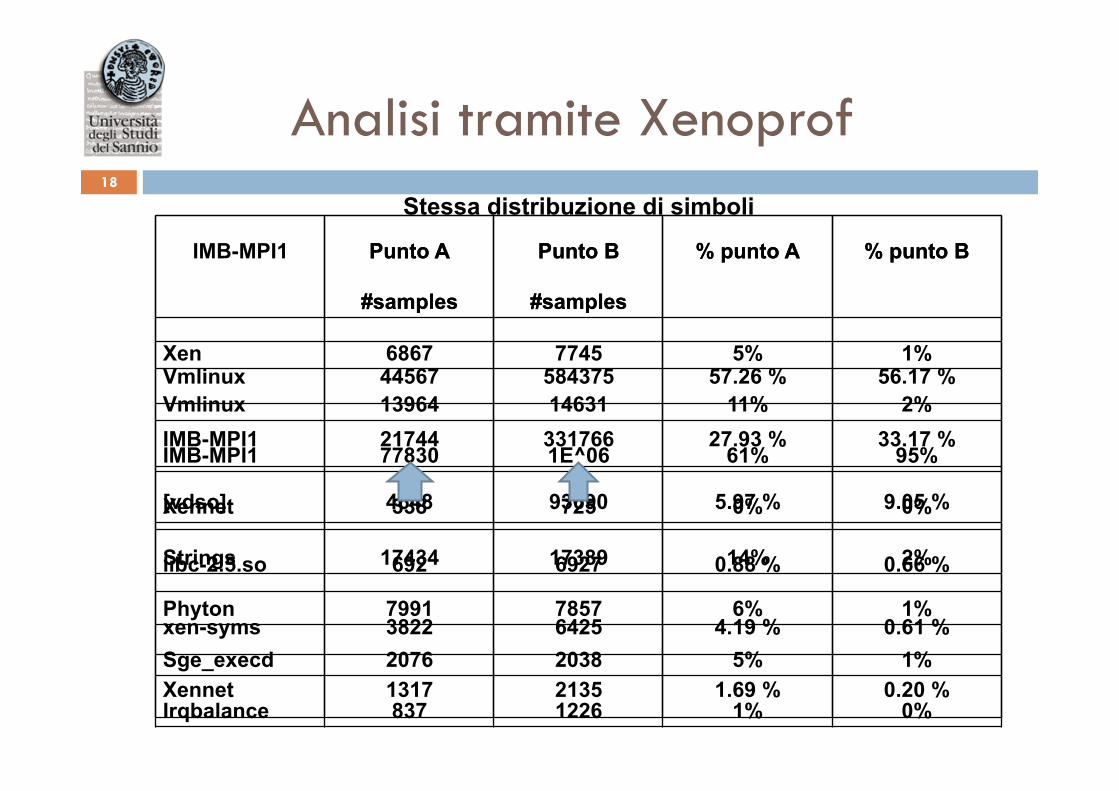
IMB-MPI1 Punto A
#samples
Punto B
#samples
% punto A % punto B
Vmlinux 44567 584375 57.26 % 56.17 %
IMB-MPI1 21744 331766 27.93 % 33.17 %
[vdso] 4648 93690 5.97 % 9.05 %
libc-2.5.so 692 6927 0.88 % 0.66 %
xen-syms 3822 6425 4.19 % 0.61 %
Xennet 1317 2135 1.69 % 0.20 %
Analisi tramite Xenoprof 18
Punto A
#samples
Punto B
#samples
% punto A % punto B
Xen 6867 7745 5% 1%
Vmlinux 13964 14631 11% 2%
IMB-MPI1 77830 1E^06 61% 95%
Xennet 338 725 0% 0%
Strings 17434 17389 14% 2%
Phyton 7991 7857 6% 1%
Sge_execd 2076 2038 5% 1%
Irqbalance 837 1226 1% 0%
Stessa distribuzione di simboli
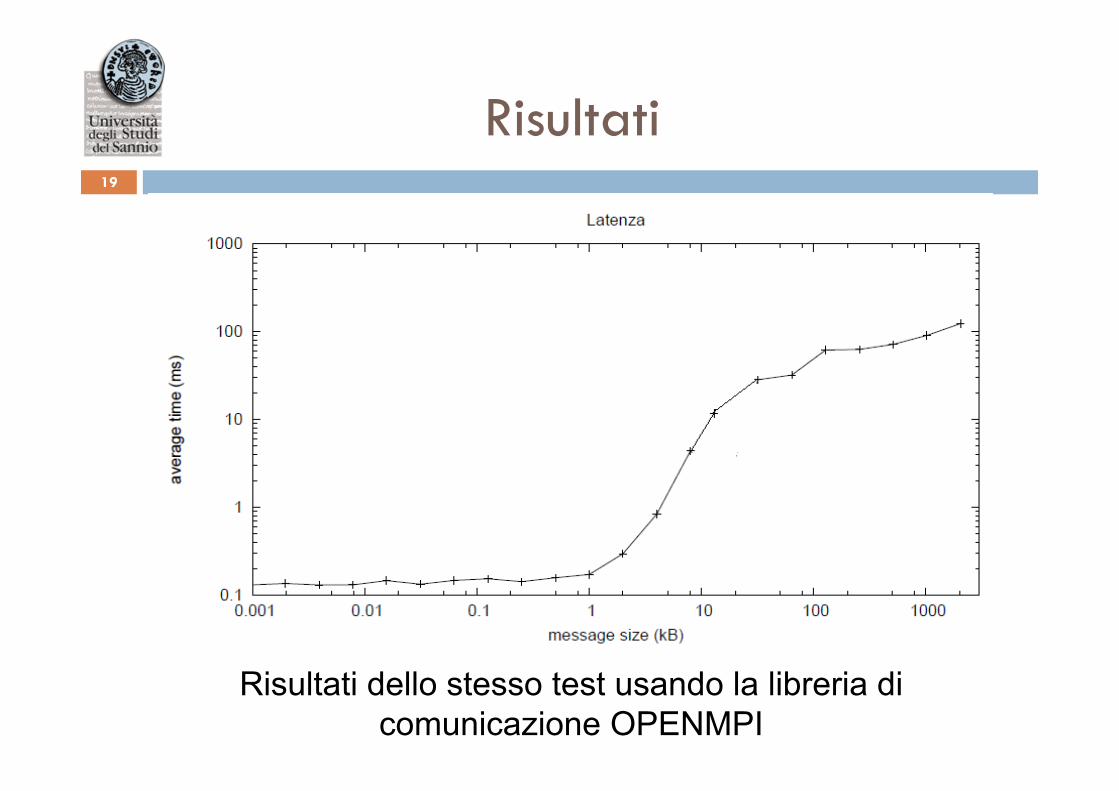
Risultati 19
Risultati dello stesso test usando la libreria di comunicazione OPENMPI

Conclusioni 20
¨ Abbiamo visto come cambia il throughput di rete in base alle diverse accoppiate CPU-VCPU
¨ L’utilizzo della CPU in base ai processi sender/receiver
¨ Attraverso il Profiling abbiamo appurato le funzioni maggiormente interessate dallo scambio intensivo di I/O di rete
¨ Il Profiling ci è venuto in aiuto nel definire l’area del problema riscontrato all’interno del tool sulle prestazione dei Virtual Cluster

Sviluppi futuri 21
¨ Analizzare le prestazioni di rete mettendole in relazioni con i risultati di un ambiente nativo
¨ Effettuare un’analisi più approfondita dei risultati di Xenoprof sulla libreria di comunicazione MPICH