パイプライン 構造(内容 1 ) pipeline structure ( contents 1 )
DESCRIPTION
パイプライン 構造(内容 1 ) Pipeline structure ( Contents 1 ). パイプラインの考え方 Background idea of a Pipeline DLX (仮想 RISC )命令セット DLX ( virtual machine by H & P ) ( RISC )命令セットパイプライン構造 Pipe line stages for (RISC) Instruction set CPI&MIPS ( Million Instruction Per Sec. ). - PowerPoint PPT PresentationTRANSCRIPT

福永 力 ; Chikara Fukunaga 1
パイプライン構造(内容 1 )Pipeline structure ( Contents 1 )
• パイプラインの考え方Background idea of a Pipeline
• DLX (仮想 RISC )命令セットDLX ( virtual machine by H & P )
• ( RISC )命令セットパイプライン構造Pipe line stages for (RISC) Instruction set
• CPI&MIPS ( Million Instruction Per Sec. )

パイプライン構造(内容 2 )Pipeline structure ( Contents
2 )• ハザード・コンフリクト
Hazards/Conflictsスムーズなパイプライン処理を阻む要因Factors for blocking of smooth pipeline processes• 構造的( Structural ) Hazard• Data Hazard• 制御( Control ) Hazard
• ソフトウェアパイプラインSoftware Pipeline
福永 力 ; Chikara Fukunaga 2

福永 力 ; Chikara Fukunaga 3
パイプラインの考え方Ideas of a Pipeline
• 1 命令の実行をいくつか( n )の工程に分解し異なる工程を並列に動作させる.The Processing of one instruction can be divided into several independent stages. Each stage can be processed in parallel for different instructions.
• 結果的に数個の命令が並列動作しているようにみせかけ 1 命令あたりの消費クロック数を少なくみせるしかけ.It is looked like several instructions processed in one clock period, the number of clocks/instr. can be said to be less than sequential processing

DLX (Virtual RISC machine) 命令セット Instruction set
福永 力 ; Chikara Fukunaga 4

福永 力 ; Chikara Fukunaga 5
( RISC )命令セットパイプライン構造Pipeline structure of (RISC) Instruction set
• IF: Instruction Fetch• ID&RF: Instruction Decode & Registers fetch• EX: Execution• MEM: Memory Access & Branch completion• WB: Write Back

福永 力 ; Chikara Fukunaga 6
• IF: IR ← Mem[PC], PC←PC+4• ID&RF: A←Rs0 ( IR6-10), B←Rs1(IR11-15), IMM←Sgn^IR16-31• EX:
• Memory: ALUout ← A + IMM• ALU op.: ALUout ← (A op B) or (A op IMM)• Branch: ALUout ←PC+IMM, cond←A op 0
• MEM:• MDR←M[ALUout] (Load) or M[ALUout] ← B (Store)• if(cond) PC ← ALUout• ALUout1 ← ALUout
• WB:Rd ← MR(Load)• Register-Register ALU op. : Rd ( IR16-20) ← ALUout1• Regsiter-Imm. ALU op. : Rd(IR11-15) ← ALUout1• Load: Rd(IR11-15) ← MDR
Registers:GPR0-31:GeneralPC: Program CounterIR: Instruction RegisterA,B,IMMALUout,ALUout1MDR

福永 力 ; Chikara Fukunaga 7
パイプライン制御Pipeline control
• パイプラインによる制御がない場合,3命令で 15 サイクル3 instructions with 15 cycles if no pipeline mechanism
• (理想的)パイプラインによる制御Idealized control of pipeline
• 5 instructions/9 clock cycles• CPI ( Clocks per Instruction ) =9/5=1.8
福永 力 ; Chikara Fukunaga 8
MIPS 値• MIPS ( Million Instructions per Second )
定義( Definition ) : MIPS=Clock Frequency ( MHz ) ÷CPI( Dhrystone MIPS とは別の定義)(Dhrystone MIPS is a different definition for CPU performance)
• If clock cycle is 100MHz, then• And if CPI=1.8 、 MIPS=100/1.8=55.55
ここで IF,ID,EX,MEM,WB を 1clock でこなすと仮定( We assume each stage with 1 clock)
• Pentium (初期)は CPI 平均 0.7 (といわれている),クロック 100MHz で MIPS 〜 143Average CPI of Pentium (oldest version) is (told as) 0.7, and MIPS is estimated as ~143 if 100MHz clock

福永 力 ; Chikara Fukunaga 9
スムーズなパイプライン処理の乱れVarious factors of Pipeline stalls
• さまざまな制約によりパイプライン処理は理想的に動かない→これをハザード( hazard )あるいはコンフリクト( conflict )と呼んだりするStalls of a pipeline, which will be occurred with various reasons are called hazards or conflicts.
• 今まで工夫をこらしてさまざまな(後述の)ハザード対策を行ってきた.しかしその対策が新たなハザードを生むと行った具合で大変むずかしい問題が存在する.Various measures against hazards has been taken (will be introduced later). There may be several inherent problems to eliminate hazards since the measures produce another kind of hazards.
• パイプライン処理技術の発展とは H/W , S/W ともにこのハザード対策といってよいDevelopment of pipeline technique embedded in modern processors is just to measure/kill the hazards for both h/w and s/w

福永 力 ; Chikara Fukunaga 10
ハザードの原因別分類( 1 )Classification of Hazards with factors ( 1 )1. 構造的ハザード(ユニットコンフリクト)
Structural hazards(Unit conflict)• Cache の各ステージでの取り合い ⇒ I-cache と D-cache を分
けるCache sharing in several stages
• ALU の取り合い⇒ALU sharing in several stages ⇒
• メモリアドレス計算ユニットと算術演算ユニットの分離Two ALUs for immediate value (memory address) calcul and ALU operation
• 即値アドレス計算を ALU 演算命令には使わない( DLXの考え方)Instructions with ALU are never implemented the address modifier logic
• 算術演算(整数と浮動小数点で異なるユニット利用)Different ALUs for floating points and integers

福永 力 ; Chikara Fukunaga 11
ハザードの原因別分類( 2 )Classification of Hazards with factors ( 2 )
2. データハザード( Data Hazard )• とりあえず RAW ( Read After Write )なる状況を考える.
Only RAW situation must be considered seriously• WAR ( Write after read ), WAW ( Write after Write )は
通常起きないと考えられる.Neither WAR nor WAW can be out of scope for the moment
3. コントロール(制御)ハザード /Control hazards• 分岐命令後次の実行アドレス決定までのもたつき.
Dead time introduced in decision of Target Address for a Branch instruction
• パイプラインのステージ進行がハザードでもたつくことを「 stall 」あるいは「 interlock 」と呼ぶTime taking (idling) for moving of stage by stage due to hazards is generally called “stall” or “interlock”

DLX アセンブリプログラム例An example program of DLX assembly
福永 力 ; Chikara Fukunaga 12
• コラーツ数列( Collatz sequence )• 初項の値を n とする(プログラムでは値 123 を r1 に入れている)
Initial value is set to n (The example sets 123 to r1 as the init. Value)• 次項はもし n が奇数なら 3*n+1 ,偶数なら n/2 で与える
The next term will be 3*n+1 if n is odd, else n/2タグ (Tag)
(アドレスに名前付けNaming to an address )
命令( Instructions )
operand
Comment

データ( RAW )ハザード例Data(RAW) Hazard
• for(i=0;i<100;i++) a[i]=a[i]+b[i]+c[i+1]; • Example of RAW stalls in a primitive pipeline processing
29 cycles
福永 力 ; Chikara Fukunaga 13

データハザード回避策 (1)Avoidance of Data Hazard(1)
• Pipeline forwarding (19 cycles)
福永 力 ; Chikara Fukunaga 14

• 命令を発行順ではなく自由に並びかえパイプラインの効率を高めるコンパイラの導入( 15 cycles )To have a good compiler in order to execute instructions in out of order for the pipeline (15cycles)
• オレンジ部は命令の実行順序を元のそれから変えた.結果に影響はないが stall は減っている.Instructions in the orange parts are changed their execution order from the original coding. Stalls can be eliminated drastically.
福永 力 ; Chikara Fukunaga 15
データハザード回避策 (2)Avoidance of Data Hazard(2)

コントロールハザードControl Hazard
• 分岐命令によりひき起されるハザードHazards triggered by branch instructions
• 条件分岐( beqz, bnez )は条件成立( taken )で分岐アドレス以降の命令、不成立( not taken )で直後の命令に移行An instruction at the target address will be executed next if the branch condition is met (taken), else one after the branch will be done (not taken).
福永 力 ; Chikara Fukunaga 16

分岐命令によるストール例Example of a stall caused by a branch instruction
• ブランチ命令に cond の真偽は MEM ステージで確定する.そこまで次のアドレスは決められない.True/False in branch condition is determined in MEM stage. Target address can not be determined until this stage
福永 力 ; Chikara Fukunaga 17
Not taken (3 stalls)
Taken (3 stalls)

• 遅延分岐 Delay Branch• 分岐先判明までの時間を有効に使うためその次に
数スロット命令を追加する.分岐先判明後に分岐先命令実行Several instructions which are not critical for the branch operation will be installed until the branch address is fixed.
• もし命令数が分岐先判明までのスロット数と同じであればストールはない.If you can insert number of instructions as same as one for the decision needed, no stall will be observed
福永 力 ; Chikara Fukunaga 18
分岐命令のストール対策( 1 )Elimination of stalls of Branch instructions (1)

遅延分岐例An example of delayed branch
• addi r4,r4,#4 は taken/not taken に関わらず実行されるaddi r4,r4,#4 will be done always regardless of the branch condition
• この命令を branch 命令後に実行させることによりストールを減らせるNumber of stalls can be reduced if this instruction is put after the branch
福永 力 ; Chikara Fukunaga 19

分岐命令のストール対策( 2 )Elimination of stalls of Branch instructions (2) • Taken/Not taken をできるだけ前のステージで決める
Taken /Not taken should be determined in as forward stage as possible• 分岐先アドレスもできるだけ前のステージで決める
Branch Target Address should be also determined in as forward stage as possible
• 分岐命令は以下のように ID&RF で条件成立ととび先の確定を行うConditon and target address decision is done in ID&RF stage
• 分岐命令は以下のようになる.命令のデコード途中なので赤い部分はすべての命令で実行されるようにするID&RF stage of Branch instruction is done in the following way; all theinstruction should perform steps indicated in red because branch is not decoded;
福永 力 ; Chikara Fukunaga 20
• IF: IR ← Mem[PC], PC ← PC+4• ID&RF: A←Rs0 ( IR6-10), B←Rs1(IR11-15),
BTA ← Sgn^IR16-31, if (Rs0 op 0) PC ← BTA• EX:• MEM:• WB:

分岐命令のストール対策( 2 )Elimination of stalls in Branch ( 2 )
• もし ID ステージで前スライドのような前倒しが可能ならif the determination of the branch (T/NT) and BTA can be done in the forward stage,
• Not taken でのストールはなくなるが Taken では 1 ストール発生No Stall in the case of Not taken, but still 1 stalls in Taken
• この手続きでは Not taken優勢として次の命令の IF ステージを進めているIn this algorithm, the instruction in not taken is assumed to be done next
福永 力 ; Chikara Fukunaga 21

福永 力 ; Chikara Fukunaga 22
静的分岐予測( 1 )Static Prediction of Branch (1)
• 静的予測(予測違いによる被害が小さいように):Static Branch prediction (in order not to make serious hazards)
• プログラムの特質を考慮した分岐の予測を行うBranch prediction with program characteristics
• 一般にプログラムは 11-17% の条件分岐, 2-8% の無条件分岐を含んでいるNormally a program contains 11-17% of conditional branch, and 2-8% of unconditional branch
• 条件分岐の taken 確率〜 50%probability of taken in a conditional branch ~50%
• loop 構成の条件分岐の taken 確率 >90%probability of taken in a conditional branch used in a loop >90%
• bit test の条件分岐のほとんどは not-takenresults of conditional branch with bit test is almost not taken

• 静的分岐予測(続き)Static Branch prediction (cont’d)
• あらかじめ条件分岐がループの場合(分岐先が現在番地より手前)は 9割 taken , 1割 not-taken としてしまうBranch condition in a loop (target address is in front of the current address) is set to taken 90%, not taken 10%
• If (条件) then A… else B… の場合, A… のほうがメジャーなのではとの設定In the case of If (condition) A… else B…, fixed as A… is prior than B…
福永 力 ; Chikara Fukunaga 23
静的分岐予測( 2 )Static Prediction of Branch (2)

福永 力 ; Chikara Fukunaga 24
動的分岐予測 1 ( BPB )Dynamical Branch Prediction (1)
• 分岐予測バッファ(キャッシュ)Branch Prediction Buffer; BPB (Cache)
• コンパイル時にブランチ命令のアドレスを BPB に登録しておく.予測のため2ビット分用意するThe addresses of branch instructions areregistered in BPB at compilation, T/N is predicted with twice occurrence of the branch. 2bits for prediction are prepared.
• ID ステージで分岐命令と判明したら, BPB を参照して次回予測Taken/Not taken を得る,If a branch instruction at ID stage is confirmed, the processor predicts its Taken/Not taken by referring the BPB.
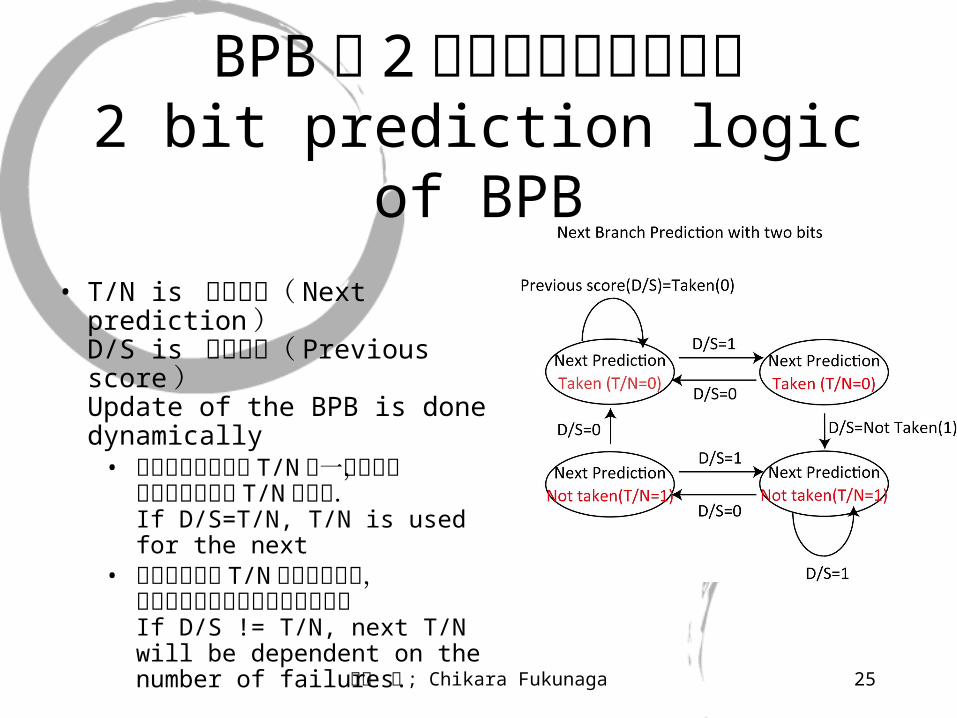
BPB の 2ビット分岐予測論理2 bit prediction logic of BPB
• T/N is 次回予測( Next prediction )D/S is 前回実績( Previous score ) Update of the BPB is done dynamically
• もし前回の結果が T/N と一致なら,次回予測もその T/N とする.If D/S=T/N, T/N is used for the next
• 今回の結果が T/N の反対の場合,次回予測ははずれの回数による.If D/S != T/N, next T/N will be dependent on the number of failures.
福永 力 ; Chikara Fukunaga 25

福永 力 ; Chikara Fukunaga 26
動的分岐予測 2 ( BTB )Dynamic Branch Prediction 2
• 分岐標的バッファ( Branch Target Buffer; BTB )• 分岐の taken/not-taken のみならず,分岐先予測も行う.
BTB に分岐履歴を保持しておく.Branch address prediction will be don as well as T/N prediction.
• IF- ステージで命令アドレスを常に(どの命令でも) BTB で検索しSearch of the instruction address in the BTB at IF-stage for every instruction, and
• 一致があればそれは分岐命令であり, predicted address field に登録されているアドレスにすみやかに移動.そのアドレスでの IF- ステージ実行(ストールなし)If a matching is found, the instruction is regarded as a branch, then IF-stage for the instruction of the destination address registered in the table is stared immediately
• 一致なければ通常パイプラインフローNo matching, normal pipeline flow

スーパーパイプラインSuper-pipeline
1. 命令実行を加速させるひとつの方法Another way to boost instruction execution
2. ステージ数を増加させる( 6 から 20 ステージ、 Core 2 は 14 ステージ). Increased number of stages(6 〜 20 stages, Core 2 has 14 stages).
3. 各ステージの動作の単純化simplify the functionality of each stage
4. 3 と 4 で high clock freq. を達成させる.With items 3 and 4, Clock freq. can be increased
5. しかし data hazard 対策と高度な分岐予測が必要But careful treatment for data hazard and super technique of branch prediction are indispensable
福永 力 ; Chikara Fukunaga 27

Super-pipeline 例( Example )• もし各ステージ 1 クロックで動作させると
If we operate pipeline with 1 stage/clock,CPI (Clock per Instruction) for 5 stage pl = 8/4, but one for 10 stage = 13/4=3.25
• 5 stage
• 10 stage
• しかしもし Freq. を ×1.666 up させると 3.25×0.6=1.95 、If Freq. is increased 60%, 3.25×0.6=1.95同程度以上の性能が得られる.Comparable performance can be gotten.
福永 力 ; Chikara Fukunaga 28

福永 力 ; Chikara Fukunaga 29
SAXPY 計算SAXYPY calculation
• Z[i]=a*X[i]+Y[i] :SAXPY単精度 axi+yi という計算Z[i]=a*X[i]+Y[i]:SAXPY;Single precision AX Plus Y calculation
• 単純なパイプラインではデータハザード( RAW )によるストールが多発Many stalls due to Data (RAW) hazards with the simple pipeline
• 繰返し 1 回で 24 cycles24 cycles required for a turn in the loop

福永 力 ; Chikara Fukunaga 30
ループ展開( Loop Unrolling )• RISC スタイルの CPU では数多くの汎用レジスタがあるのでループ内
をレジスタを豊富に使い書き直すUse general purpose registers as much as possible for instructions in a loop
• 3 回分の繰り返しを 1 回のループに展開( unroll )する.3 original loops into one big loop with loop unrolling technique

福永 力 ; Chikara Fukunaga 31
SAXPY Software Pipeline• 1つのループをいくつかのステージに分ける.
Instructions in the loop can be divided into several stages• 1つのループ内でステージごとに異なるデータ領域への操作を行う
Each stage handles different region of data arrays
Storing of r8 to Z[i]
Modification of r8 (Y[i+1]) with r8+r10Preparation of r10(a×X[i+2])

福永 力 ; Chikara Fukunaga 32
Software pipeline - 考え方( 1 ) -background idea(1)
• SAXPY のような処理ループで同じレジスタの取り合いが RAW データハザードSharing of a few registers makes the RAW data hazards in the SAXPY loop
• 処理をパイプライン的に捉え直すProcess in the loop can be reconstructed with the idea of a pipelin
• 各ステージでは処理用レジスタを異なるものにする.結果的にハザードを減らせるUse different register sets for different stage in the loop will reduce the hazardous situations.

福永 力 ; Chikara Fukunaga 33
Software pipeline - 考え方( 2 ) -background idea(2)
• 先の SAXPY のソフトウェアパイプラインプログラムを C で書いてみよう:C like program expression for SAXPY with Software pipeline
• 機械語プログラムでは主ループの前(プロローグ)と後(エピローグ)の記述を抜かしてあった.The programs expressed in DLX assembly ignored both the prolog and epilog parts