読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節...
TRANSCRIPT

1
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
日時: 2015/06/18 19:30~
場所: 株式会社 ALBERT
発表者: @aoki_kenji

目次
2
• 前回の復習(条件付き独立性)
• ギブスサンプリングとは?
• 3.2.1節 ギブスサンプリング
• 3.2.2節 周辺化ギブスサンプリング
• 3.2.3節 LDAのギブスサンプリング
• 3.2.4節 LDAの周辺化ギブスサンプリング
今回は時間の都合上省略

目次
3
• 前回の復習(条件付き独立性)
• ギブスサンプリングとは?
• 3.2.1節 ギブスサンプリング
• 3.2.2節 周辺化ギブスサンプリング
• 3.2.3節 LDAのギブスサンプリング
• 3.2.4節 LDAの周辺化ギブスサンプリング

グラフィカルモデル? or 数式?
4
前回の@ksmznさんの資料から引用
• 前回はグラフィカルモデルを参照して条件付き分布を導出した
• 今回は数式から直接条件付き分布を導出してみる

数式からの条件付き独立性の導出(p.22の図1.7)
5
𝑏
𝑎
𝑐
𝑎
𝑏
𝑐
𝑎
𝑏
𝑐
tail-to-tail head-to-tail head-to-head
𝑝 𝑎, 𝑏, 𝑐 = 𝑝 𝑎|𝑐 𝑝 𝑏|𝑐 𝑝 𝑐
𝑝 𝑎, 𝑏|𝑐 ∝ 𝑝 𝑎 𝑐 𝑝 𝑏 𝑐 ⇒ 𝑎 ⊥ 𝑏|𝑐
𝑝 𝑎, 𝑏, 𝑐 = 𝑝 𝑏|𝑐 𝑝 𝑐|𝑎 𝑝 𝑎
𝑝 𝑎, 𝑏|𝑐 ∝ 𝑝 𝑏|𝑐 𝑝 𝑐|𝑎 𝑝 𝑎 ⇒ 𝑎 ⊥ 𝑏|𝑐
𝑝 𝑎, 𝑏, 𝑐 = 𝑝 𝑐|𝑎, 𝑏 𝑝 𝑎 𝑝 𝑏
𝑝 𝑎, 𝑏|𝑐 ∝ 𝑝 𝑐|𝑎, 𝑏 𝑝 𝑎 𝑝 𝑏 ⇒ 𝑎 ⊥ 𝑏|𝑐
グラフィカルモデル
数式
条件付き 独立性

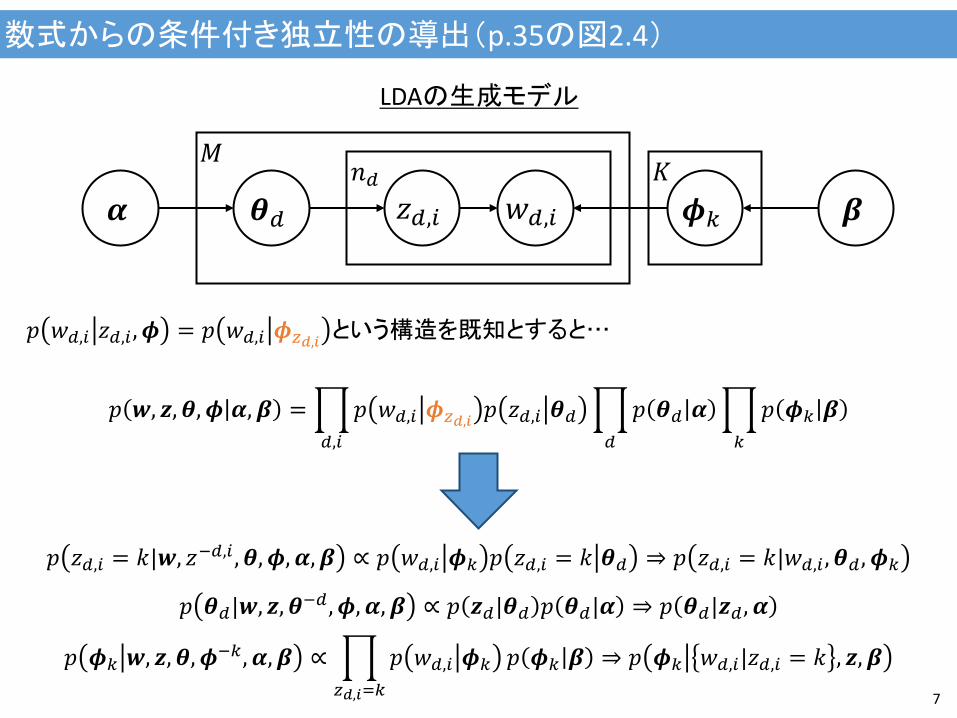
数式からの条件付き独立性の導出(p.35の図2.4)
6
𝜷 𝜶
LDAの生成モデル
𝑝 𝑧𝑑,𝑖|𝒘, 𝒛−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 , 𝝓 𝑝 𝑧𝑑,𝑖 𝜽𝑑 ⇒ 𝑝 𝑧𝑑,𝑖|𝑤𝑑,𝑖 , 𝜽𝑑, 𝝓
𝑝 𝜽𝑑|𝒘, 𝒛, 𝜽−𝑑, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝒛𝑑|𝜽𝑑 𝑝 𝜽𝑑|𝜶 ⇒ 𝑝 𝜽𝑑|𝒛𝑑 , 𝜶
𝑝 𝝓𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘 , 𝜶, 𝜷 ∝ 𝑝 𝒘 𝒛,𝝓 𝑝 𝝓𝑘 𝜷 ⇒ 𝑝 𝝓𝑘 𝒘, 𝒛, 𝝓
−𝑘, 𝜷
𝝓𝑘 𝜽𝑑 𝑧𝑑,𝑖 𝑤𝑑,𝑖 𝐾 𝑛𝑑
𝑀
𝑝 𝒘, 𝒛, 𝜽, 𝝓 𝜶, 𝜷 = 𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 , 𝝓 𝑝 𝑧𝑑,𝑖 𝜽𝑑𝑑,𝑖
𝑝 𝜽𝑑 𝜶
𝑑
𝑝 𝝓𝑘 𝜷
𝑘
各確率変数の条件付き分布を数式から導出してみる
1段目と3段目の式に関しては実際よりも冗長
数式からの条件付き独立性の導出(p.35の図2.4)
7
𝜷 𝜶
LDAの生成モデル
𝑝 𝑧𝑑,𝑖 = 𝑘|𝒘, 𝑧−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝑤𝑑,𝑖 𝝓𝑘 𝑝 𝑧𝑑,𝑖 = 𝑘 𝜽𝑑 ⇒ 𝑝 𝑧𝑑,𝑖 = 𝑘|𝑤𝑑,𝑖 , 𝜽𝑑, 𝝓𝑘
𝑝 𝜽𝑑|𝒘, 𝒛, 𝜽−𝑑, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝒛𝑑|𝜽𝑑 𝑝 𝜽𝑑|𝜶 ⇒ 𝑝 𝜽𝑑|𝒛𝑑, 𝜶
𝑝 𝝓𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘, 𝜶, 𝜷 ∝ 𝑝 𝑤𝑑,𝑖 𝝓𝑘
𝑧𝑑,𝑖=𝑘
𝑝 𝝓𝑘 𝜷 ⇒ 𝑝 𝝓𝑘 𝑤𝑑,𝑖|𝑧𝑑,𝑖 = 𝑘 , 𝒛, 𝜷
𝝓𝑘 𝜽𝑑 𝑧𝑑,𝑖 𝑤𝑑,𝑖 𝐾 𝑛𝑑
𝑀
𝑝 𝒘, 𝒛, 𝜽, 𝝓 𝜶, 𝜷 = 𝑝 𝑤𝑑,𝑖 𝝓𝑧𝑑,𝑖 𝑝 𝑧𝑑,𝑖 𝜽𝑑𝑑,𝑖
𝑝 𝜽𝑑 𝜶
𝑑
𝑝 𝝓𝑘 𝜷
𝑘
𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 , 𝝓 = 𝑝 𝑤𝑑,𝑖 𝝓𝑧𝑑,𝑖 という構造を既知とすると…

目次
8
• 前回の復習(条件付き独立性)
• ギブスサンプリングとは?
• 3.2.1節 ギブスサンプリング
• 3.2.2節 周辺化ギブスサンプリング
• 3.2.3節 LDAのギブスサンプリング
• 3.2.4節 LDAの周辺化ギブスサンプリング

ギブスサンプリングのアルゴリズム概要
9
例えば 𝑝 𝑎, 𝑏, 𝑐|𝜃
から直接乱数を生成できないようなときでも、以下の手順(ギブスサンプリング)によって上記分布からの乱数を生成することができる
Step1: 𝑏, 𝑐の初期値𝑏 0 , 𝑐 0 と正数𝑆を与える
Step2: 𝑠 = 1,⋯ , 𝑆に対して以下を繰り返す
𝑝 𝑎 𝑠 |𝑏 𝑠−1 , 𝑐 𝑠−1 , 𝜃 から𝑎 𝑠 をサンプリング
𝑝 𝑏 𝑠 |𝑎 𝑠 , 𝑐 𝑠−1 , 𝜃 から𝑏 𝑠 をサンプリング
𝑝 𝑐 𝑠 |𝑎 𝑠 , 𝑏 𝑠 , 𝜃 から𝑐 𝑠 をサンプリング
上記の手順によって生成された乱数が𝑝 𝑎, 𝑏, 𝑐|𝜃 に従う理論的説明は、例えば
• 伊庭他(2005)、『計算統計Ⅱマルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア12)』、岩波書店
を参照

ギブスサンプリングのアルゴリズム概要
10
• もちろん上記の手順を実行するためには各確率変数の条件付き分布からのサンプリングが可能でなければならない (LDAの場合は条件付き分布が解析的に導出可能である)
• 𝑎, 𝑏, 𝑐はそれぞれベクトル(多次元)であっても構わない(その場合はブロック化ギブスサンプリングと呼ばれる)
• 𝑎 𝑠 , 𝑏 𝑠 , 𝑐 𝑠s=1
Sを利用して、例えば𝑝 𝑎, 𝑏, 𝑐|𝜃 に関する任意の関数
𝑓 𝑎, 𝑏, 𝑐 の期待値を近似することができる
𝑝 𝑎, 𝑏, 𝑐|𝜃 𝑓 𝑎, 𝑏, 𝑐 𝑑𝑎𝑑𝑏𝑑𝑐 ≈1
𝑆 𝑓 𝑎 𝑠 , 𝑏 𝑠 , 𝑐 𝑠𝑆
𝑠=1
• 実際は、上記のように𝑠 = 1から𝑆までの全てのサンプルを使わずに、初期値に依存した最初の方のサンプルを捨てることがある このサンプルを捨てる期間を破棄する期間(burn-in period)と呼ぶ

目次
11
• 前回の復習(条件付き独立性)
• ギブスサンプリングとは?
• 3.2.1節 ギブスサンプリング
• 3.2.2節 周辺化ギブスサンプリング
• 3.2.3節 LDAのギブスサンプリング
• 3.2.4節 LDAの周辺化ギブスサンプリング

ギブスサンプリングの動機
12
• LDAのベイズ推定では予測分布以前に事後分布のサンプル生成すら難しい
◎予測分布(積分計算が難しい)
𝑝 𝑤𝑑∗ 𝒘,𝜶, 𝜷 = 𝑝 𝑤𝑑
∗ , 𝑧𝑑∗ , 𝒛, 𝜽, 𝝓 𝒘, 𝜶, 𝜷
𝒛𝑧𝑑∗
𝑑𝜽𝑑𝝓
= 𝑝 𝑤𝑑∗ 𝝓𝑧𝑑
∗ 𝑝 𝑧𝑑∗ 𝜽𝑑 𝑝 𝒛, 𝜽, 𝝓 𝒘, 𝜶, 𝜷
𝒛𝑧𝑑∗
𝑑𝜽𝑑𝝓
◎事後分布からのサンプリングによる近似 (事後分布の導出が困難&サンプル生成が難しい)
𝑝 𝑤𝑑∗ 𝒘,𝜶, 𝜷 ≈
1
𝑆 𝑝 𝑤𝑑
∗ 𝝓𝑧𝑑∗𝑠𝑝 𝑧𝑑∗ 𝜽𝑑𝑠
𝑧𝑑∗
𝑆
𝑠=1
• LDAの場合、 𝒛 𝑠 , 𝜽 𝑠 , 𝝓 𝑠 を一度にサンプリングするのは難しいが、
𝒛 𝑠 , 𝜽 𝑠 , 𝝓 𝑠 をそれぞれ個別にサンプリングすることは容易である(条件付き分布が解析的に導出可能である)
ギブスサンプリングによる近似が可能

条件付き分布の導出その1
13
◎𝑧𝑑,𝑖について(𝑤𝑑,𝑖 = 𝑣とする)
𝑝 𝑧𝑑,𝑖 = 𝑘 𝑤𝑑,𝑖 = 𝑣,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝑤𝑑,𝑖 = 𝑣 𝝓𝑘 𝑝 𝑧𝑑,𝑖 = 𝑘 𝜽𝑑
= 𝜙𝑘,𝑣𝜃𝑑,𝑘
𝑝 𝑧𝑑,𝑖 = 𝑘 𝑤𝑑,𝑖 = 𝑣,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 = 1𝐾
𝑘=1 となるように正規化すると
𝑝 𝑧𝑑,𝑖 = 𝑘 𝑤𝑑,𝑖 = 𝑣,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 =
𝜙𝑘,𝑣𝜃𝑑,𝑘
𝜙𝑘′,𝑣𝜃𝑑,𝑘′𝐾𝑘′=1

条件付き分布の導出その2
14
◎𝜽𝑑について 𝑝 𝜽𝑑 𝒘, 𝒛, 𝜽
−𝑑 , 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝒛𝑑 𝜽𝑑 𝑝 𝜽𝑑 𝜶
∝ 𝜃𝑘𝛼𝑘+𝑛𝑑,𝑘−1
𝐾
𝑘=1
ここで𝑛𝑑,𝑘は文書𝑑の中でトピック𝑘に属する単語の数とする
すなわち𝑛𝑑,𝑘 = 𝛿 𝑧𝑑,𝑖 = 𝑘𝑛𝑑𝑖=1
上の式から𝑝 𝜽𝑑 𝒘, 𝒛, 𝜽−𝑑 , 𝝓, 𝜶, 𝜷 はディリクレ分布の形をしているので
𝑝 𝜽𝑑 𝒘, 𝒛, 𝜽−𝑑 , 𝝓, 𝜶, 𝜷 = 𝐷𝑖𝑟 𝜽𝑑|𝜶 + 𝒏𝑑 , 𝒏𝑑 = 𝑛𝑑,1, ⋯ , 𝑛𝑑,𝐾

条件付き分布の導出その3
15
◎𝝓𝑘について
𝑝 𝝓𝑘 𝒘, 𝒛, 𝜽,𝝓−𝑘, 𝜶, 𝜷 ∝ 𝑝 𝑤𝑑,𝑖 = 𝑣 𝝓𝑘
𝑧𝑑,𝑖=𝑘
𝑝 𝝓𝑘 𝜷
∝ 𝜙𝑣𝛽𝑣+𝑛𝑘,𝑣−1
𝑉
𝑣=1
ここで𝑛𝑘,𝑣は全文書の中でトピック𝑘に属する単語𝑣の数とする
すなわち𝑛𝑘,𝑣 = 𝛿 𝑧𝑑,𝑖 = 𝑘,𝑤𝑑,𝑖 = 𝑣𝑛𝑑𝑖=1
𝑀𝑑=1
上の式から𝑝 𝝓𝑘 𝒘, 𝒛, 𝜽,𝝓−𝑘, 𝜶, 𝜷 はディリクレ分布の形をしているので
𝑝 𝝓𝑘 𝒘, 𝒛, 𝜽,𝝓−𝑘, 𝜶, 𝜷 = 𝐷𝑖𝑟 𝝓𝑘|𝜷 + 𝒏𝑘 , 𝒏𝑘 = 𝑛𝑘,1, ⋯ , 𝑛𝑘,𝑉

条件付き分布の導出まとめ
16
• どの確率変数𝑧𝑑,𝑖 , 𝜽𝑑 , 𝝓𝑘に関しても
事後分布 ↓ 結合分布(生成モデル) ↓ 定数項を除外
のステップを踏むことにより条件付き事後分布を導出することができた

LDAのギブスサンプリングの擬似コード
17
• 以下に、LDAのギブスサンプリングの擬似コードを示す
• 𝜶,𝜷の更新に関しては3.6節で取り扱う
Step1: 𝜶,𝜷, 𝜽,𝝓の初期値𝜶 0 , 𝜷 0 , 𝜽 0 , 𝝓 0 と正数𝑆を与える
Step2: 𝑠 = 1,⋯ , 𝑆に対して以下を繰り返す
全ての𝑧𝑑,𝑖に対して𝑝 𝑧𝑑,𝑖|𝑤𝑑,𝑖 , 𝜽𝑑𝑠−1, 𝝓𝑘𝑠−1
から𝑧𝑑,𝑖𝑠をサンプリング
全ての𝜽𝑑に対して𝑝 𝜽𝑑|𝒛𝑑𝑠, 𝜶 から𝜽𝑑
𝑠をサンプリング
全ての𝝓𝑘に対して𝑝 𝝓𝑘 𝑤𝑑,𝑖|𝑧𝑑,𝑖𝑠= 𝑘 , 𝒛 𝑠 , 𝜷 から𝝓𝑘
𝑠をサンプリング
𝜶, 𝜷を更新する:𝜶 𝑠−1 , 𝜷 𝑠−1 → 𝜶 𝑠 , 𝜷 𝑠

目次
18
• 前回の復習(条件付き独立性)
• ギブスサンプリングとは?
• 3.2.1節 ギブスサンプリング
• 3.2.2節 周辺化ギブスサンプリング
• 3.2.3節 LDAのギブスサンプリング
• 3.2.4節 LDAの周辺化ギブスサンプリング

周辺化ギブスサンプリングの動機
19
• LDAのギブスサンプリングでは予測分布𝑝 𝑤𝑑∗ 𝒘,𝜶,𝜷 を計算するために事後
分布から 𝒛 𝑠 , 𝜽 𝑠 , 𝝓 𝑠𝑠=1
𝑆をサンプリングした
• より効率的なサンプリング方法として、𝜽,𝝓を積分消去(周辺化)して𝒛のみをサンプリングする方法がある(逆は不可)
• この方法は周辺化ギブスサンプリングと呼ばれる
• 周辺化ギブスサンプリングでは以下のように予測分布を近似することになる
𝑝 𝑤𝑑∗ 𝒘,𝜶, 𝜷 = 𝑝 𝑤𝑑
∗ , 𝑧𝑑∗ , 𝒛 𝒘, 𝜶, 𝜷
𝒛𝑧𝑑∗
= 𝑝 𝑤𝑑∗ , 𝑧𝑑∗ 𝒘, 𝒛, 𝜶, 𝜷 𝑝 𝒛 𝒘, 𝜶, 𝜷
𝒛𝑧𝑑∗
≈1
𝑆 𝑝 𝑤𝑑
∗, 𝑧𝑑∗ 𝒘, 𝒛 𝑠 , 𝜶, 𝜷
𝑧𝑑∗
𝑆
𝑠=1
• 𝑝 𝑤𝑑∗ , 𝑧𝑑∗ 𝒘, 𝒛, 𝜶, 𝜷 の具体的な形については次ページ以降で導出する

条件付き分布の導出その1
20
◎𝑧𝑑,𝑖の条件付き分布のみを導出すればよい(𝑤𝑑,𝑖 = 𝑣とする)
𝑝 𝑧𝑑,𝑖 = 𝑘 𝑤𝑑,𝑖 , 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
∝ 𝑝 𝑧𝑑,𝑖 = 𝑘,𝑤𝑑,𝑖 , 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 𝜶, 𝜷
= 𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 = 𝑘,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 𝑝 𝑧𝑑,𝑖 = 𝑘 𝒘
−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 𝑝 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
∝ 𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 = 𝑘,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 𝑝 𝑧𝑑,𝑖 = 𝑘 𝒘
−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
= 𝑝 𝑤𝑑,𝑖 = 𝑣 𝝓𝑘 𝐷𝑖𝑟 𝝓𝑘|𝜷 + 𝒏𝑘−𝑑,𝑖 𝑑𝝓𝑘 𝑝 𝑧𝑑,𝑖 = 𝑘 𝜽𝑑 𝐷𝑖𝑟 𝜽𝑑|𝜶 + 𝒏𝑑
−𝑑,𝑖 𝑑𝜽𝑑
= 𝜙𝑘,𝑣𝐷𝑖𝑟 𝝓𝑘|𝜷 + 𝒏𝑘−𝑑,𝑖 𝑑𝝓𝑘 𝜃𝑑,𝑘𝐷𝑖𝑟 𝜽𝑑|𝜶 + 𝒏𝑑
−𝑑,𝑖 𝑑𝜽𝑑
=𝑛𝑘,𝑣−𝑑,𝑖 + 𝛽𝑣
𝑛𝑘,𝑣′−𝑑,𝑖 + 𝛽𝑣′
𝑉𝑣′=1
𝑛𝑑,𝑘−𝑑,𝑖 + 𝛼𝑘
𝑛𝑑,𝑘′−𝑑,𝑖 + 𝛼𝑘′
𝐾𝑘′=1
𝑛𝑘,𝑣−𝑑,𝑖 , 𝑛𝑑,𝑘
−𝑑,𝑖は𝑛𝑘,𝑣, 𝑛𝑑,𝑘の計算から𝑧𝑑,𝑖を
抜いたもの
ここの導出は次ページに記載

条件付き分布の導出その2
21
◎𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 = 𝑘,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 の計算に関して
𝑝 𝑤𝑑,𝑖 , 𝑧𝑑,𝑖 = 𝑘,𝒘
−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
= 𝑝 𝑤𝑑,𝑖 = 𝑣 𝝓𝑘 𝑝 𝑤𝑑′,𝑖′ 𝝓𝑘𝑧𝑑,𝑖=𝑘
𝑑′,𝑖′≠𝑑,𝑖
𝑝 𝝓𝑘 𝜷 𝑑𝝓𝑘 × 𝐹 𝑤𝑑,𝑖 𝑧𝑑,𝑖 ≠ 𝑘 , 𝒛
𝑝 𝑧𝑑,𝑖 = 𝑘,𝒘
−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
= 𝑝 𝑤𝑑′,𝑖′ 𝝓𝑘𝑧𝑑,𝑖=𝑘
𝑑′,𝑖′≠𝑑,𝑖
𝑝 𝝓𝑘 𝜷 𝑑𝝓𝑘 × 𝐹 𝑤𝑑,𝑖 𝑧𝑑,𝑖 ≠ 𝑘 , 𝒛
したがって
𝑝 𝑤𝑑,𝑖 𝑧𝑑,𝑖 = 𝑘,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑤𝑑,𝑖 = 𝑣 𝝓𝑘 𝐷𝑖𝑟 𝝓𝑘|𝜷 + 𝒏𝑘
−𝑑,𝑖 𝑑𝝓𝑘

条件付き分布の導出その3
22
◎𝑝 𝑧𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 の計算に関して
𝑝 𝑧𝑑,𝑖 = 𝑘,𝒘
−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
= 𝑝 𝑧𝑑,𝑖 = 𝑘 𝜽𝑑 𝑝 𝑧𝑑,𝑖′ 𝜽𝑑𝑖′=𝑖
𝑝 𝜽𝑑 𝜶 𝑑𝜽𝑑 × 𝐹 𝑤−𝑑,𝑖 , 𝒛−𝑑
𝑝 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
= 𝑝 𝑧𝑑,𝑖′ 𝜽𝑑𝑖′=𝑖
𝑝 𝜽𝑑 𝜶 𝑑𝜽𝑑 × 𝐹 𝑤−𝑑,𝑖 , 𝒛−𝑑
したがって
𝑝 𝑧𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑧𝑑,𝑖 = 𝑘 𝜽𝑑 𝐷𝑖𝑟 𝜽𝑑|𝜷 + 𝒏𝑑
−𝑑,𝑖 𝑑𝜽𝑑

予測分布の具体的な形
23
◎積み残しにしていた𝑝 𝑤𝑑∗ , 𝑧𝑑∗ 𝒘, 𝒛, 𝜶, 𝜷 の具体的な形に関して
前ページまでの結果から
𝑝 𝑤𝑑,𝑖 = 𝑣, 𝑧𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
= 𝑝 𝑤𝑑,𝑖 = 𝑣 𝑧𝑑,𝑖 = 𝑘,𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 𝑝 𝑧𝑑,𝑖 = 𝑘 𝒘
−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷
=𝑛𝑘,𝑣−𝑑,𝑖 + 𝛽𝑣
𝑛𝑘,𝑣′−𝑑,𝑖 + 𝛽𝑣′
𝑉𝑣′=1
𝑛𝑑,𝑘−𝑑,𝑖 + 𝛼𝑘
𝑛𝑑,𝑘′−𝑑,𝑖 + 𝛼𝑘′
𝐾𝑘′=1
したがって
𝑝 𝑤𝑑∗ = 𝑣, 𝑧𝑑
∗ = 𝑘 𝒘, 𝒛, 𝜶, 𝜷 =𝑛𝑘,𝑣 + 𝛽𝑣
𝑛𝑘,𝑣′ + 𝛽𝑣′𝑉𝑣′=1
𝑛𝑑,𝑘 + 𝛼𝑘
𝑛𝑑,𝑘′ + 𝛼𝑘′𝐾𝑘′=1

LDAの周辺化ギブスサンプリングの擬似コード
24
• 以下に、LDAの周辺化ギブスサンプリングの擬似コードを示す
• 𝜶,𝜷の更新に関しては3.6節で取り扱う
Step1: 𝜶,𝜷, 𝒛の初期値𝜶 0 , 𝜷 0 , 𝒛 0 (=𝑛𝑘,𝑣, 𝑛𝑑,𝑘)と正数𝑆を与える
Step2: 𝑠 = 1,⋯ , 𝑆に対して以下を繰り返す 全ての𝑑, 𝑖 に対して以下を繰り返す
𝑛𝑘,𝑣−𝑑,𝑖 , 𝑛𝑑,𝑘
−𝑑,𝑖 𝑘 = 1,⋯ , 𝐾 を計算する
𝑛𝑘,𝑣−𝑑,𝑖+𝛽𝑣
𝑛𝑘,𝑣′−𝑑,𝑖+𝛽𝑣′
𝑉𝑣′=1
𝑛𝑑,𝑘−𝑑,𝑖+𝛼𝑘
𝑛𝑑,𝑘′−𝑑,𝑖+𝛼𝑘′
𝐾𝑘′=1
から𝑧𝑑,𝑖𝑠をサンプリング
𝑛𝑘,𝑣, 𝑛𝑑,𝑘を更新する
𝜶, 𝜷を更新する:𝜶 𝑠−1 , 𝜷 𝑠−1 → 𝜶 𝑠 , 𝜷 𝑠