読書会 「トピックモデルによる統計的潜在意味解析」 第6回 4.3節...
TRANSCRIPT

1
読書会 「トピックモデルによる統計的潜在意味解析」第6回4.3節 潜在意味空間における分類問題
日時: 2015/09/17 19:30~
場所: 株式会社 ALBERT
発表者: @aoki_kenji

目次
2
• 4.3.1節 LDA+ロジスティック回帰モデル
• 4.3.2節 LDA+多クラスロジスティック回帰モデル
• 4.3.3節 LDA+SVM
• 4.3.4節 LDA+SVMの学習アルゴリズム
目次
3
• 4.3.1節 LDA+ロジスティック回帰モデル
• 4.3.2節 LDA+多クラスロジスティック回帰モデル
→時間の都合上まとめて定式化
• 4.3.3節 LDA+SVM
• 4.3.4節 LDA+SVMの学習アルゴリズム

(多クラス)ロジスティック回帰モデル
4
• ラベルを推定するためのモデル
• ラベルの種類が二つの場合はロジスティック回帰モデル、三つ以上の場合は多クラスロジスティック回帰モデルと呼ばれる
• LDAの文脈では、例えば商品レビューが肯定的か否定的かをそのレビューに含まれる単語から推定する問題がこれに該当する
ロジスティック回帰モデルの適用例 (出力:試験の合否 入力:勉強時間)
(引用元) Wikipedia: https://en.wikipedia.org/wiki/Logistic_regression

(多クラス)ロジスティック回帰モデルの定式化
5
• 出力を𝑦、入力を𝒙とすると 𝐶 + 1 クラスロジスティック回帰モデルは以下の式で表わされる ※𝜼1:𝐶 = 𝜼1, ⋯ , 𝜼𝐶 はパラメータ
𝑝 𝑦 𝒙, 𝜼1:𝐶 =exp 𝜼𝑦
𝑇𝒙
1 + 𝑐=1𝐶 exp 𝜼𝑐
𝑇𝒙4.40 , 4.53
• 一般化線形モデルの式で書くと
𝑝 𝑦 𝒙, 𝜼1:𝐶 = exp 𝜼𝑦𝑇𝒙 − log 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇𝒙 (4.41)

LDA+(多クラス)ロジスティック回帰モデルの定式化
6
• モデル全体は以下の式となる𝑝 𝒚,𝒘, 𝒛, 𝝓, 𝜽 𝜶,𝜷, 𝜼1:𝐶 = 𝑝 𝒚 𝒛, 𝜼1:𝐶 𝑝 𝒘 𝒛,𝝓 𝑝 𝒛 𝜽 𝑝 𝝓 𝜷 𝑝 𝜽 𝜶
• ロジスティック回帰モデルの部分は4.2節と同様に入力を 𝒛𝑑とする
𝑝 𝒚 𝒛, 𝜼1:𝐶 =
𝑑=1
𝑀
𝑝 𝑦𝑑 𝒛𝑑 , 𝜼1:𝐶
𝑝 𝑦𝑑 𝒛𝑑 , 𝜼1:𝐶 = exp 𝜼𝑦𝑇 𝒛𝑑 − log 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 4.42
新たに追加された部分

LDA+(多クラス)ロジスティック回帰モデルの学習その1
7
• 4.2節と同様に変分ベイズ法によって学習する
• 𝐹LDAをLDAの変分下限とするとLDA+(多クラス)ロジスティック回帰モデルの変分下限は以下の式で表わされるlog 𝑝 𝒚,𝒘 𝜶,𝜷, 𝜼1:𝐶
≥
𝒛
𝑞 𝒛, 𝜽,𝝓 log𝑝 𝒚,𝒘, 𝒛, 𝝓, 𝜽 𝜶, 𝜷, 𝜼1:𝐶
𝑞 𝒛, 𝜽, 𝝓𝑑𝜽𝑑𝝓
=
𝒛
𝑞 𝒛, 𝜽,𝝓 log𝑝 𝒚 𝒛, 𝜼1:𝐶 𝑝 𝒘 𝒛,𝝓 𝑝 𝒛 𝜽 𝑝 𝝓 𝜷 𝑝 𝜽 𝜶
𝑞 𝒛, 𝜽,𝝓𝑑𝜽𝑑𝝓
= 𝐹LDA +
𝒛
𝑞 𝒛, 𝜽,𝝓 log 𝑝 𝒚 𝒛, 𝜼1:𝐶
= 𝐹LDA + 𝐸𝑞 𝒛 log 𝑝 𝒚 𝒛, 𝜼1:𝐶 4.43
• したがって𝑞 𝜽 , 𝑞 𝝓 の更新式はLDAと同じ
• 次ページ以降で𝑞 𝒛 , 𝜼1:𝐶の更新式を導出する
新たに追加された部分

LDA+(多クラス)ロジスティック回帰モデルの学習その2
8
𝐸𝑞 𝒛𝑑 log 𝑝 𝑦𝑑 𝒛𝑑 , 𝜼1:𝐶
= 𝜼𝑦𝑑𝑇 𝐸𝑞 𝒛𝑑 𝒛𝑑 − 𝐸𝑞 𝒛𝑑 log 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 4.45 , 4.54
• 上記第2項は解析的に計算できないため
log 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 ≤
1 + 𝑐=1𝐶 exp 𝜼𝑐
𝑇 𝒛𝑑𝜉𝑑
+ log 𝜉𝑑 − 1 (4.44)
を利用して目的関数の下限を最大化する(変分下限の下限を最大化する)
• (4.43)と(4.44)から
𝐹LDA +
𝑑=1
𝑀
𝜼𝑦𝑑𝑇 𝐸𝑞 𝒛𝑑 𝒛𝑑 −
1
𝜉𝑑𝐸𝑞 𝒛𝑑 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 − log 𝜉𝑑 + 1
= 𝐹LDA + 𝐿m−logistic
が新たな目的関数となる(ちなみに右辺第2項は 4.33 式から計算可能)

LDA+(多クラス)ロジスティック回帰モデルのパラメータ推定その1
9
◎𝜼𝑐の推定𝜕𝐿m−logistic
𝜕𝜼𝑐
=
𝑑 𝑦𝑑 = 𝑐
𝐸𝑞 𝒛𝑑 𝒛𝑑 −1
𝜉𝑑
𝜕
𝜕𝜼𝑐𝐸𝑞 𝒛𝑑 1 + exp 𝜼𝑐
𝑇 𝒛𝑑 4.57
から𝜕𝐿m−logistic
𝜕𝜼𝑐= 0を求めたいが解析的に解けないため共役勾配法(付録A.4)を
用いて求める(ちなみに右辺第2項は 4.35 式から計算可能)

LDA+(多クラス)ロジスティック回帰モデルのパラメータ推定その2
10
◎𝝃𝑑の推定
𝜕𝐿m−logistic
𝜕𝝃𝑑=1
𝜉𝑑2 𝐸𝑞 𝒛𝑑 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 −
1
𝜉𝑑= 0 4.58
から
𝜉𝑑 = 𝐸𝑞 𝒛𝑑 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 4.59

LDA+(多クラス)ロジスティック回帰モデルのパラメータ推定その3
11
◎𝑞 𝑧𝑑,𝑖 = 𝑘 の推定
𝜕𝐿m−logistic
𝜕𝑞 𝑧𝑑,𝑖 = 𝑘=𝜂𝑦𝑑,𝑘
𝑛𝑑−1
𝜉𝑑
𝜕
𝜕𝑞 𝑧𝑑,𝑖 = 𝑘𝐸𝑞 𝒛𝑑 1 +
𝑐=1
𝐶
exp 𝜼𝑐𝑇 𝒛𝑑 4.61
で、右辺第2項は 4.60 から計算可能
したがって 3.98 と合わせると
𝑞 𝑧𝑑,𝑖 = 𝑘
∝ exp 𝐸𝑞 𝝓𝑘 log 𝜙𝑘,𝑤𝑑,𝑖 exp 𝐸𝑞 𝜽𝑑 log 𝜃𝑑,𝑘 exp𝜕𝐿m−logistic
𝜕𝑞 𝑧𝑑,𝑖 = 𝑘
4.62

目次
12
• 4.3.1節 LDA+ロジスティック回帰モデル
• 4.3.2節 LDA+多クラスロジスティック回帰モデル
• 4.3.3節 LDA+SVM
• 4.3.4節 LDA+SVMの学習アルゴリズム
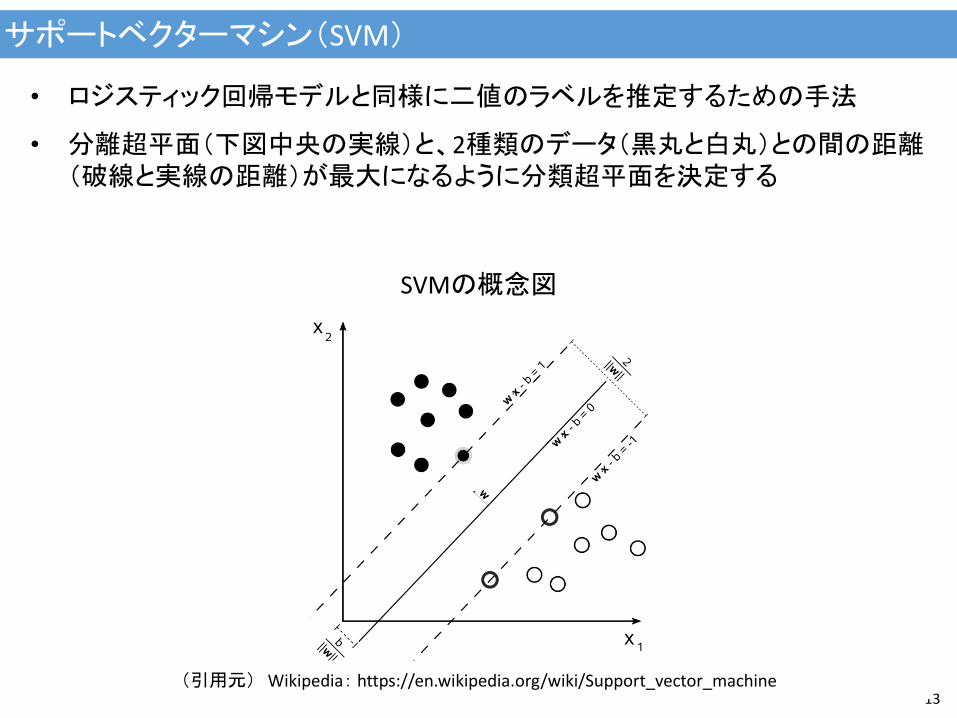
サポートベクターマシン(SVM)
13
• ロジスティック回帰モデルと同様に二値のラベルを推定するための手法
• 分離超平面(下図中央の実線)と、2種類のデータ(黒丸と白丸)との間の距離(破線と実線の距離)が最大になるように分類超平面を決定する
SVMの概念図
(引用元) Wikipedia: https://en.wikipedia.org/wiki/Support_vector_machine

ソフトマージンのサポートベクターマシン(SVM)の定式化
14
• 𝒙𝑖を前ページ図中の黒丸および白丸の座標、 𝑦𝑖を黒か白かを表わすラベル、𝜼を分離超平面の傾きおよび切片とするとソフトマージンのSVMの最適化問題は以下で定式化される
min𝜼,𝝃
1
2𝜼𝑇𝜼 + 𝐶
𝑖=1
𝑛
𝜉𝑖 ,
s.t. ∀𝑖 1 − 𝑦𝑖𝜼𝑇𝒙𝑖 − 𝜉𝑖 ≤ 0, 𝜉𝑖 ≥ 0 4.63
• 𝜉𝑖があるため、必ずしも1 − 𝑦𝑖𝜼𝑇𝒙𝑖 ≤ 0が満たされなくてもよい
• ただし𝜉𝑖は目的関数に含まれるため、𝜼と同時に小さくすることが望まれる
• SVMはロジスティック回帰とは異なり確率モデルによる定式化ではないため、LDAと組み合わせるには異なる枠組みが必要

制約付きベイズ学習による枠組みその1
15
• 事後分布導出を以下の最適化問題によって定式化する
min𝑞 𝜽𝐾𝐿 𝑞 𝜽 𝑝 𝜽 − 𝑞 𝜽 log 𝑝 𝑥1:𝑛 𝜽 𝑑𝜽 ,
s.t. 𝑞 𝜽 ∈ 𝑃 4.65
ここで制約条件は
𝑞 𝜽 𝑑𝜽 = 1
を表わす
• 上記の解は変分法によって𝑞 𝜽 = 𝑝 𝜽 𝑥1:𝑛
と求まる

制約付きベイズ学習による枠組みその2
16
• 前ページをもう少し一般化すると
min𝑞 𝜽𝐾𝐿 𝑞 𝜽 𝑝 𝜽 − 𝑞 𝜽 log 𝑝 𝑥1:𝑛 𝜽 𝑑𝜽 + 𝑈 𝝃 ,
s.t. 𝑞 𝜽 ∈ 𝑃𝑐 𝝃 4.66
𝝃はここで制約緩和のためのスラック変数、𝑈 𝝃 は制約を破ったときの罰則金を意味する

制約付きベイズ学習による枠組みその3
17
• LDAの変分下限は
−𝐹𝐿𝐷𝐴 = −
𝒛
𝑞 𝒛, 𝜽, 𝝓 log𝑝 𝒘, 𝒛, 𝝓, 𝜽 𝜶, 𝜷
𝑞 𝒛, 𝜽, 𝝓𝑑𝜽𝑑𝝓
= −
𝒛
𝑞 𝒛, 𝜽, 𝝓 log𝑝 𝒛, 𝝓, 𝜽 𝜶, 𝜷 𝑝 𝒘 𝒛, 𝝓, 𝜽
𝑞 𝒛, 𝜽, 𝝓𝑑𝜽𝑑𝝓
= 𝐾𝐿 𝑞 𝒛, 𝜽, 𝝓 𝑝 𝒛,𝝓, 𝜽 𝜶, 𝜷 − 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒘 𝒛, 𝝓, 𝜽 𝑑𝜽𝑑𝝓
なので、制約付きベイズ学習の枠組みで最適化問題として定式化するとmin𝑞 𝒛,𝝓,𝜽−𝐹𝐿𝐷𝐴 ,
s.t. 𝑞 𝒛, 𝝓, 𝜽 ∈ 𝑄 4.69
𝑄は因子化仮定を表わす

制約付きベイズ学習による枠組みその4
18
• 一方で、SVMの定式化 4.63 を以下のように解釈する
min𝜼,𝝃− log 𝑝 𝜼 + 𝐶
𝑖=1
𝑛
𝜉𝑖 ,
s.t. ∀𝑖 1 − 𝑦𝑖𝜼𝑇𝒙𝑖 − 𝜉𝑖 ≤ 0, 𝜉𝑖 ≥ 0 4.67
ここで、
𝑝 𝜼 =1
2𝜋𝐷 exp −
1
2𝜼𝑇𝜼
を𝜼の事前分布と仮定し、𝜼を点推定することを考える

制約付きベイズ学習による枠組みその4
19
• したがって、 4.69 と 4.67 を組み合わせて、LDA+SVMを以下の式で定式化する
min𝑞 𝒛,𝝓,𝜽 ,𝜼,𝝃
−𝐹𝐿𝐷𝐴 − log 𝑝 𝜼 + 𝐶
𝑑=1
𝑀
𝜉𝑑 ,
s.t. 𝑞 𝒛, 𝝓, 𝜽 ∈ 𝑄, ∀𝑑 1 − 𝑦𝑑𝜼𝑇𝐸𝑞 𝒛𝑑 𝒛𝑑 − 𝜉𝑑 ≤ 0, 𝜉𝑑 ≥ 0 4.70
新たに追加された部分

目次
20
• 4.3.1節 LDA+ロジスティック回帰モデル
• 4.3.2節 LDA+多クラスロジスティック回帰モデル
• 4.3.3節 LDA+SVM
• 4.3.4節 LDA+SVMの学習アルゴリズム

LDA+SVMの学習その1
21
• 制約付き最適化問題 4.70 のラグランジュ関数は、𝜆𝑑 , 𝛾𝑑をラグランジュ乗数とすると、以下の式で表わされる𝐿 𝑞 𝒛 , 𝑞 𝜽 , 𝑞 𝝓 , 𝜼, 𝝀, 𝜸
= −𝐹𝐿𝐷𝐴 +1
2𝜼𝑇𝜼 + 𝐶
𝑑=1
𝑀
𝜉𝑑 +
𝑑=1
𝑀
𝜆𝑑 1 − 𝑦𝑑𝜼𝑇𝐸𝑞 𝒛𝑑 𝒛𝑑 − 𝜉𝑑 +
𝑑=1
𝑀
𝛾𝑑𝜉𝑑 4.71
• したがって𝑞 𝜽 , 𝑞 𝝓 の更新式はLDAと同じ
• 𝜼, 𝝀, 𝜸の更新は𝐸𝑞 𝒛𝑑 𝒛𝑑 が与えられたもとでSVMの学習アルゴリズムをその
まま適用することができる
• 次ページ以降で𝑞 𝒛 の更新式を導出する

LDA+SVMのパラメータ推定その1
22
◎𝑞 𝑧𝑑,𝑖 = 𝑘 の推定𝜕
𝜕𝑞 𝑧𝑑,𝑖 = 𝑘𝜼𝑇𝐸𝑞 𝒛𝑑 𝒛𝑑 =
𝜂𝑘𝑛𝑑
4.73 , 4.74
より、 3.98 と合わせると
𝑞 𝑧𝑑,𝑖 = 𝑘
∝ exp 𝐸𝑞 𝝓𝑘 log 𝜙𝑘,𝑤𝑑,𝑖 exp 𝐸𝑞 𝜽𝑑 log 𝜃𝑑,𝑘 exp𝜆𝑑𝑦𝑑𝜂𝑘𝑛𝑑
4.75
したがって、大きい𝜆𝑑に対応する文書(サポートベクター)ほど、SVMの学習結果𝜼の影響を強く受ける

LDA+SVMのパラメータ推定その2
23
• 次に𝜼の点推定でなく事後分布を求める場合を考える(𝜼に関しても変分近似を仮定する)
• 4.70 は以下のように書き換えられる
min𝑞 𝒛,𝝓,𝜽,𝜼 ,𝝃
−𝐹𝐿𝐷𝐴 + 𝐾𝐿 𝑞 𝜼 𝑝 𝜼 + 𝐶
𝑑=1
𝑀
𝜉𝑑 ,
s.t. 𝑞 𝒛, 𝝓, 𝜽, 𝜼 ∈ 𝑄, ∀𝑑 1 − 𝑦𝑑𝐸𝑞 𝒛𝑑,𝜼 𝜼𝑇 𝒛𝑑 − 𝜉𝑑 ≤ 0, 𝜉𝑑 ≥ 0 4.76
• 実は𝑞 𝜼 として𝑁 𝝁, 𝑰 を仮定しても同じ最適化問題となる(証明は162ページを参照)ので上記の最適化問題は以下のように書き換えられる
min𝑞 𝒛,𝝓,𝜽 ,𝝁,𝝃
−𝐹𝐿𝐷𝐴 +1
2𝝁𝑇𝝁 + 𝐾 + 𝐶
𝑑=1
𝑀
𝜉𝑑 ,
s.t. 𝑞 𝒛, 𝝓, 𝜽 ∈ 𝑄, ∀𝑑 1 − 𝑦𝑑𝝁𝑇𝐸𝑞 𝒛𝑑 𝒛𝑑 − 𝜉𝑑 ≤ 0, 𝜉𝑑 ≥ 0 4.76
変更があった部分

LDA+SVMのパラメータ推定その3
24
• 制約付き最適化問題 4.76 のラグランジュ関数は、𝜆𝑑 , 𝛾𝑑をラグランジュ乗数とすると、以下の式で表わされる𝐿 𝑞 𝒛 , 𝑞 𝜽 , 𝑞 𝝓 , 𝑞 𝜼 , 𝝀, 𝜸
= −𝐹𝐿𝐷𝐴 +1
2𝝁𝑇𝝁 + 𝐾 + 𝐶
𝑑=1
𝑀
𝜉𝑑 +
𝑑=1
𝑀
𝜆𝑑 1 − 𝑦𝑑𝝁𝑇𝐸𝑞 𝒛𝑑 𝒛𝑑 − 𝜉𝑑
+
𝑑=1
𝑀
𝛾𝑑𝜉𝑑 4.83
• したがって𝑞 𝜽 , 𝑞 𝝓 の更新式はLDAと同じ
• 𝝁, 𝝀, 𝜸の更新は𝐸𝑞 𝒛𝑑 𝒛𝑑 が与えられたもとでSVMの学習アルゴリズムをその
まま適用することができる
• 𝑞 𝒛 の更新式 4.75 も𝜼が𝝁に変わっただけ