Григорий Демченко, “Асинхронность и сопрограммы:...
TRANSCRIPT

1

2
Асинхронность и
сопрограммы:
обработка данных
Григорий Демченко
cтарший разработчик

3
План
Обзор технологий
Предлагаемый поход
Вопросы
Обсуждение
Дальнейшие улучшения
Выводы

4
Обзор технологий
5
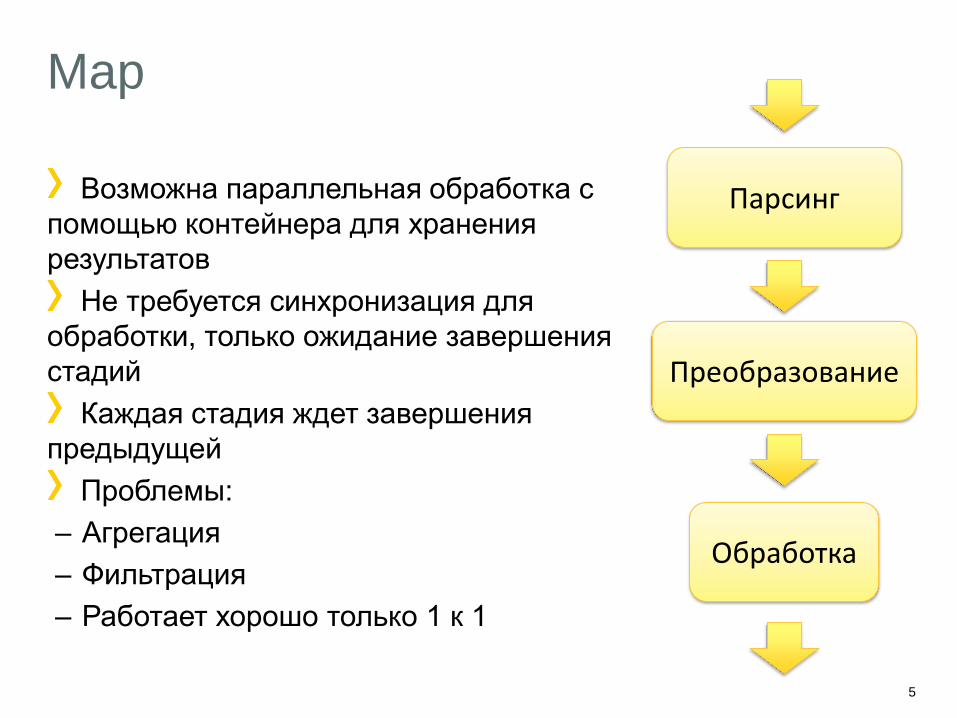
Map
Возможна параллельная обработка с
помощью контейнера для хранения
результатов
Не требуется синхронизация для
обработки, только ожидание завершения
стадий
Каждая стадия ждет завершения
предыдущей
Проблемы:
– Агрегация
– Фильтрация
– Работает хорошо только 1 к 1
Парсинг
Преобразование
Обработка
6
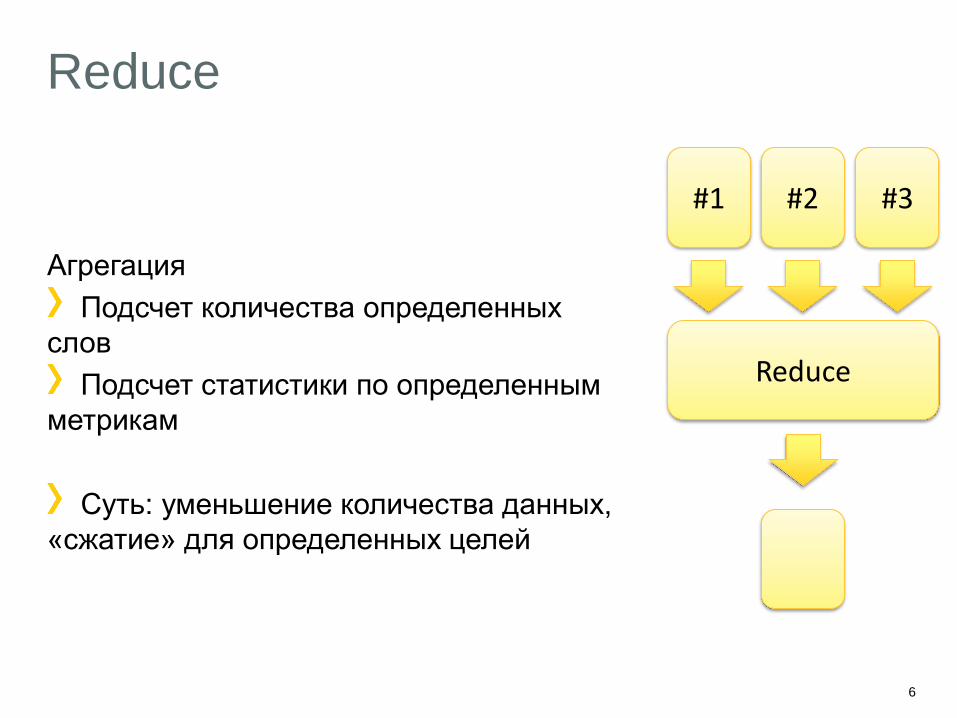
Reduce
Агрегация
Подсчет количества определенных
слов
Подсчет статистики по определенным
метрикам
Суть: уменьшение количества данных,
«сжатие» для определенных целей
#1
Reduce
#2 #3

7
Проблемы традиционных подходов
Требуется синхронизация
Сложный контроль потребления памяти
Последовательное выполнение стадий
Нагрузка на планировщик
Внешние взаимодействия:
– сетевые запросы
– обращение к базе данных
– обращение к диску

8
Предлагаемый подход

9
Что хочется?
Эффективно использовать сеть: получение и посылка
данных
Эффективно использовать процессор: запускать задачи, не
дожидаясь завершения стадий
Эффективно использовать память: выделять память под
конкретные нужды
Разгрузка планировщика: планировать более крупные
задачи
Нацеленность на результат: получение первых конечных
данных как можно быстрее
По возможности не использовать синхронизацию явно
Максимизация параллельности операций
Обработка сложных сценариев (например, петли)

10
Задача
Выдать 20 наиболее используемых слов сайта

11
Обработка данных
Преобразование одних данных в
другие
Data Oriented Design – всё есть
преобразование данных
Преобразование
Исходные данные
Результат
12
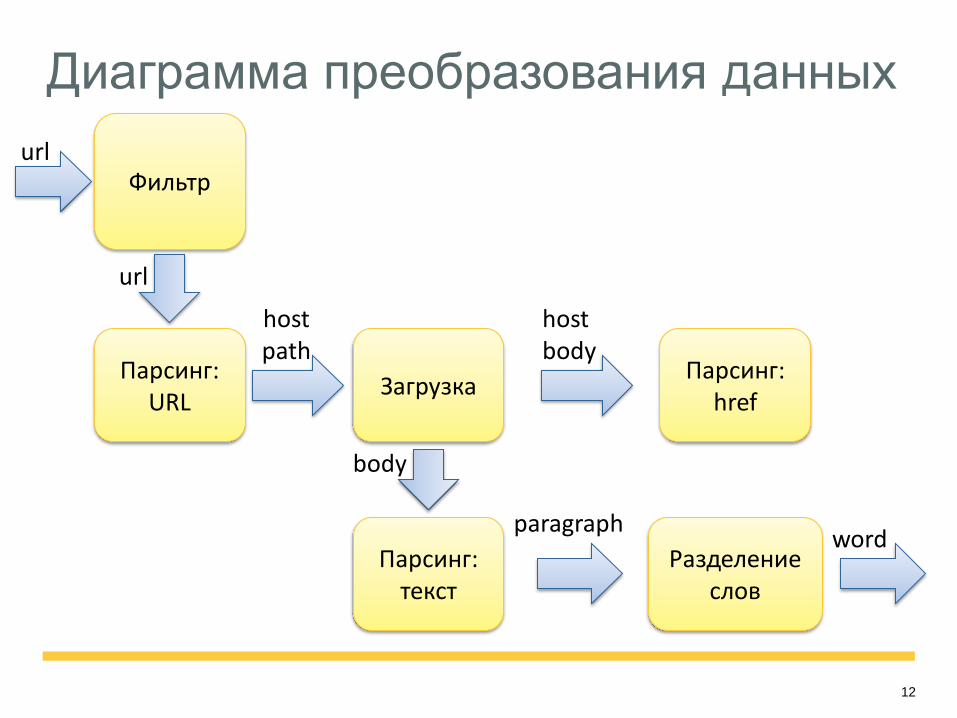
Диаграмма преобразования данных
Фильтр
Парсинг: URL
Загрузка
Парсинг: текст
Парсинг: href
Разделение слов
host path
host body
url
body
paragraph word
url
13
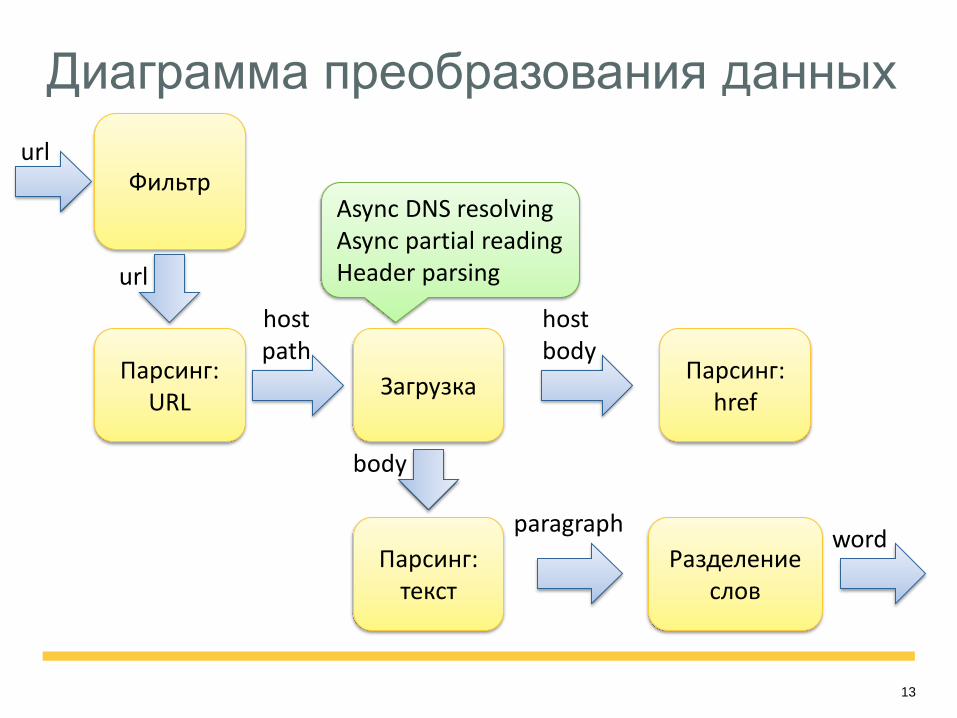
Диаграмма преобразования данных
Фильтр
Парсинг: URL
Загрузка
Парсинг: текст
Парсинг: href
Разделение слов
host path
host body
url
body
paragraph
Async DNS resolving Async partial reading Header parsing
word
url

14
Диаграмма преобразования данных
Фильтр
Парсинг: URL
Загрузка
Парсинг: текст
Парсинг: href
Разделение слов
host path
host body
url
body
paragraph
Async DNS resolving Async partial reading Header parsing
word
url
url

15
Как реализовать?
Обратные связи – традиционные способы не подходят
Асинхронность в обработчиках

16
Канал
Парсинг: текст
Разделение слов
paragraph
Канал: Channel<std::string>

17
Канал: параллельность
Парсинг: текст
Разделение слов
paragraph
Канал: Channel<std::string>
Парсинг: текст Парсинг:
текст Разделение
слов

18
Канал: интерфейс
put – посылка значения
get – извлечение значения
Потокобезопасный
Можно: for (auto&& w: wordsChan) { ... }
template<typename T>
struct Channel
{
bool empty() const;
void put(T val);
bool get(T& val);
T get();
void open();
void close();
};

19
Канал: параллельность
Парсинг: текст
Разделение слов
paragraph
Канал: Channel<std::string>
Парсинг: текст Парсинг:
текст Разделение
слов
Channel::put Channel::get

20
Канал: параллельность
Парсинг: текст
Разделение слов
paragraph
Канал: Channel<std::string>
Парсинг: текст Парсинг:
текст Разделение
слов
Channel::put Channel::get
Channel::close
returns: false

21
Сложности
Канал может быть пустым, что делать потребителю?
Как обрабатывать асинхронные взаимодействия?
Сколько использовать обработчиков для параллельной
работы?

22
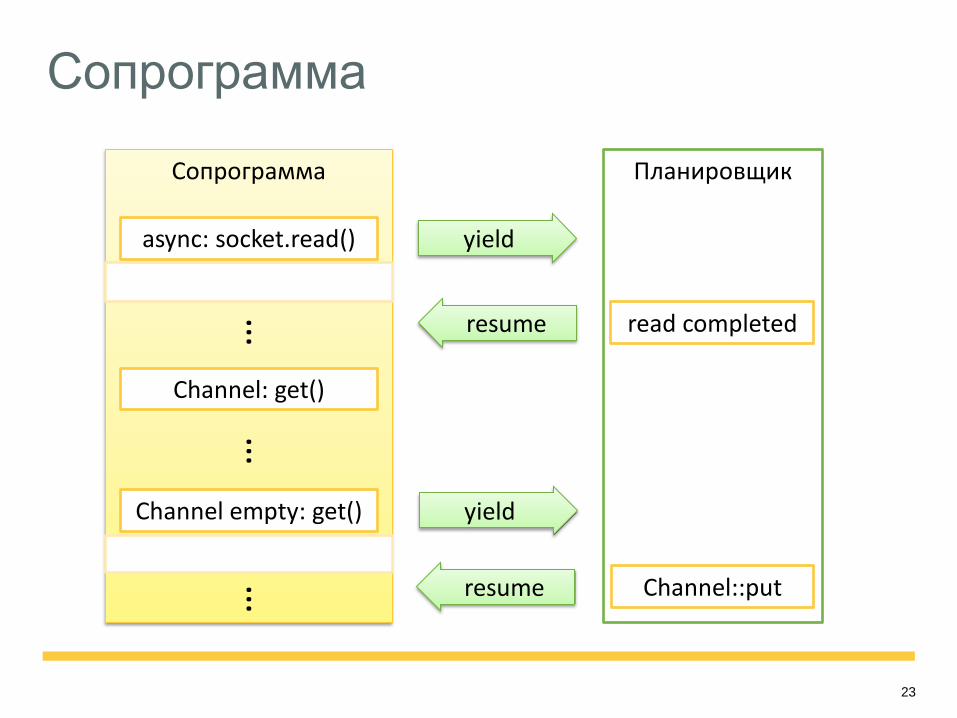
Решение: сопрограммы!
Подпрограмма: выполняются все действия перед возвратом
управления
Сопрограмма: частичное выполнение действий перед
возвратом управления
Сопрограмма обобщает понятие подпрограммы, т.е.
подпрограмма - это частный случай сопрограммы.
Для эффективной реализации на С++ будем использовать
boost.context.
23
Сопрограмма
Сопрограмма Планировщик
async: socket.read() yield
read completed
Channel: get()
…
Channel empty: get()
…
Channel::put …
resume
yield
resume

24
Обработчики
Связь двух каналов
template<typename T_src, typename T_dst, typename F_pipe>
void piping(T_src& s, T_dst& d, F_pipe f, int n = 1)
{
goN(n, [&s, &d, f] {
auto c = closer(d);
f(s, d);
});
}
piping(c1, c2, [](Channel<int>& src, Channel<int>& dst) {
for (int v: src)
dst.put(v + 1);
});
closer: автоматически закрывает канал
goN: асинхронно запускает n сопрограмм

25
Обработчики
Связь двух каналов 1 к 1 (map)
template<typename T_src, typename T_dst, typename F_pipe>
void piping1to1(T_src& s, T_dst& d, F_pipe f, int n = 1)
{
piping(s, d, [f] (T_src& s, T_dst& d) {
for (auto&& v: s)
d.put(std::move(f(v)));
}, n);
}
piping1to1(c1, c2, [](int v) {
return v + 1;
}, 10);
будет запущено 10 обработчиков

26
Разделение каналов
go([&] {
auto c1 = closer(contentHref);
auto c2 = closer(contentText);
for (auto&& c: content)
{
contentHref.put(c);
contentText.put(c.second);
}
});
Split
Парсинг: текст
Парсинг: href
host + body
body
host + body
body
27
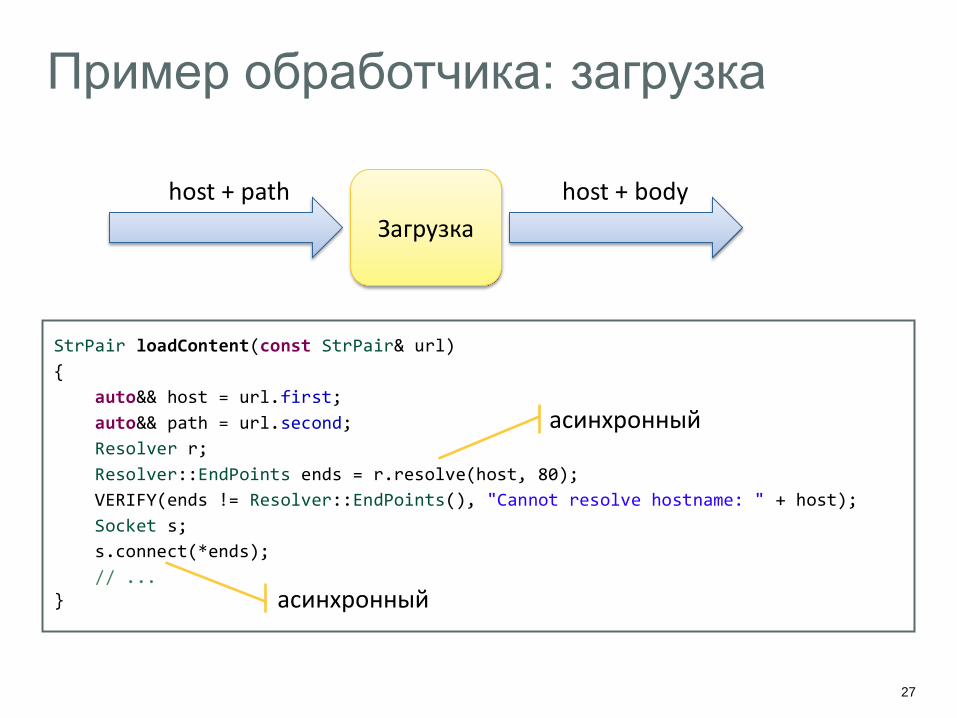
Пример обработчика: загрузка
StrPair loadContent(const StrPair& url)
{
auto&& host = url.first;
auto&& path = url.second;
Resolver r;
Resolver::EndPoints ends = r.resolve(host, 80);
VERIFY(ends != Resolver::EndPoints(), "Cannot resolve hostname: " + host);
Socket s;
s.connect(*ends);
// ... }
Загрузка
host + body host + path
асинхронный
асинхронный

28
Пример обработчика: ссылки
Преобразование ссылки из строки в host+path
StrPair parseUrl(const Str& url)
{
static const regex e("http://([\\w\\d\\._-]*[\\w\\d_-]+)(.*)", regex::icase);
smatch what;
bool result = regex_search(url, what, e);
if (!result)
return {};
Str host = what[1];
Str path = what[2];
if (path.empty())
path = "/";
return {host, path};
}
piping1to01(filteredUrl, parsedUrl, parseUrl);
piping1to01: игнорирует пустые элементы

29
Пример обработчика: слова
Разделение текста на отдельные слова
void splitWords(const Str& text, Channel<Str>& words)
{
static const regex e("([a-zA-Z]+)");
sregex_token_iterator i = make_regex_token_iterator(text, e, 1);
sregex_token_iterator ie;
while (i != ie)
words.put(*i++);
}
piping1toMany(text, words, splitWords);
piping1toMany: один ко многим

30
Петля
Помещаем url после разбора снова в фильтр:
piping1toMany(contentHref, url, parseHref);
Как оборвать петлю?
Фильтр
Парсинг: URL
Загрузка Парсинг:
href
host path
host body
url url

31
Обработка петель
Решение: использовать closeAndWait
int threads = std::thread::hardware_concurrency();
ThreadPool tp(threads, "tp");
Channel<Str> url;
url.put("http://www.boost.org");
closeAndWait(tp, url);
template<typename T_channel>
void closeAndWait(ThreadPool& tp, T_channel& c)
{
tp.wait();
c.close();
tp.wait();
}
засыпание обработчиков на Channel::get
закрываем самый первый канал
выход из всех обработчиков
32
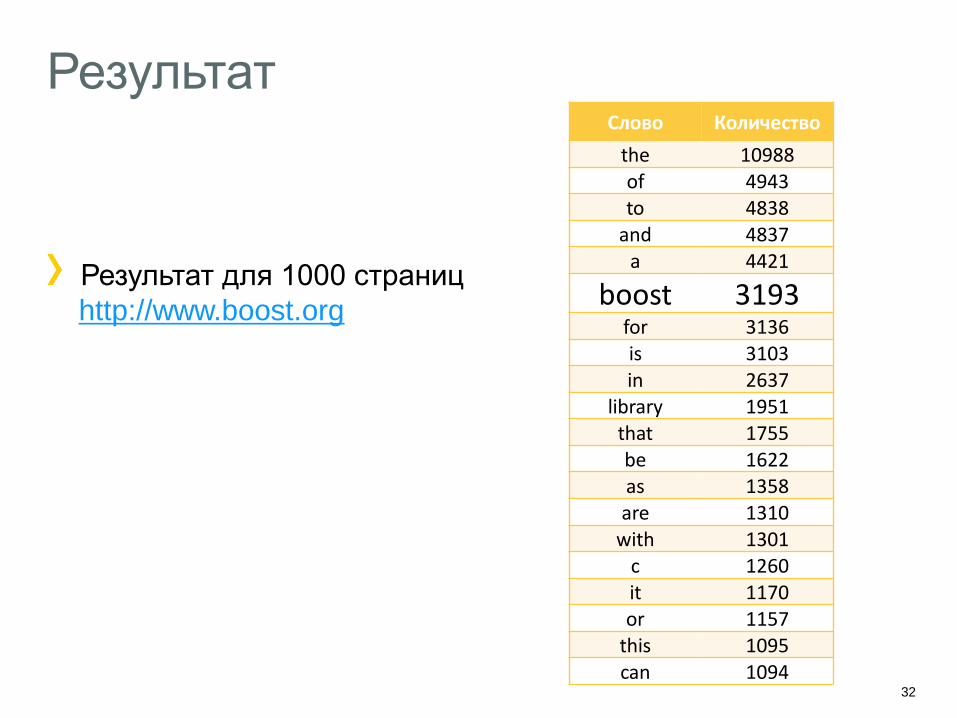
Результат
Результат для 1000 страниц
http://www.boost.org
Слово Количество
the 10988 of 4943 to 4838
and 4837 a 4421
boost 3193 for 3136 is 3103 in 2637
library 1951 that 1755 be 1622 as 1358 are 1310
with 1301 c 1260 it 1170 or 1157
this 1095 can 1094

33
Вопросы

34
Количество обработчиков
Какое число обработчиков необходимо в случае:
– Лёгких задач?
– Тяжелых задач?
– Сетевых операций?

35
Количество обработчиков
Какое число обработчиков необходимо в случае:
– Лёгких задач ~1-2
– Тяжелых задач = числу ядер
– Сетевых операций >> числа ядер

36
Обработка блокирующих вызовов
Каким образом обрабатывать блокирующие вызовы в
случае:
– Обращения к диску?
– Синхронные запросы к удаленной БД?

37
Обработка блокирующих вызовов
Каким образом обрабатывать блокирующие вызовы в
случае:
– Обращения к диску
– Синхронные запросы к удаленной БД
Ответ: запускать в отдельном пуле потоков,
число потоков >> числа ядер

38
Кеширование DNS запросов
Загрузка
host + body host + path

39
Кеширование DNS запросов
struct DNSCache
{
void add(const Str& host);
Resolver::Endpoints get(const Str& host) const;
private:
static Resolver::Endpoints resolve(const Str& host);
mutable std::mutex mutex;
std::unordered_map<Str, Resolver::Endpoints> cache; };
Загрузка
host + body host + path
40
Кеширование DNS запросов
struct DNSCache
{
void add(const Str& host);
Resolver::Endpoints get(const Str& host) const;
private:
static Resolver::Endpoints resolve(const Str& host);
mutable std::mutex mutex;
std::unordered_map<Str, Resolver::Endpoints> cache; };
Загрузка
host + body host + path
41
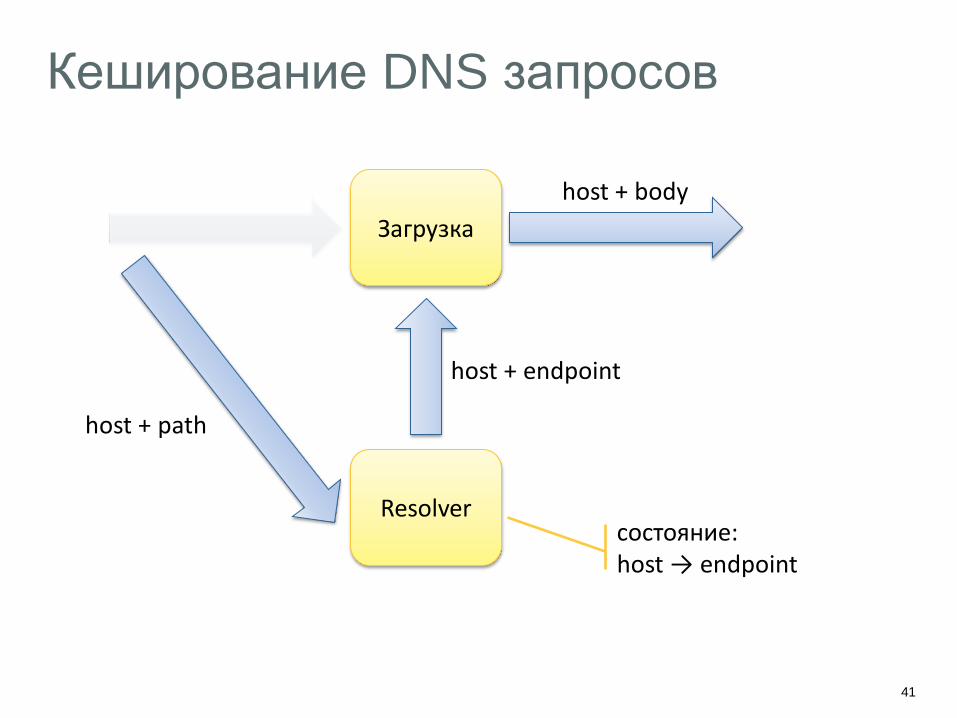
Кеширование DNS запросов
Загрузка
host + body
host + path
Resolver
host + endpoint
состояние: host → endpoint

42
Нагрузка на планировщик
Какова нагрузка на планировщик в случае частого обмена
сообщениями через каналы?
bool get(T& val) {
Lock lock(mutex);
if (!queue.empty()) {
val = std::move(queue.front());
queue.pop();
return true;
}
if (closed)
return false;
Waiter w(val);
waiters.push(w);
lock.release();
deferProceed([this, &w](Handler proceed) {
w.setProceed(std::move(proceed));
mutex.unlock();
});
return w.hasValue();
}
значение в очереди => сразу возвращаем
создаем ожидающего и добавляем его в список
устанавливаем обработчик для возобновления выполнения
после продолжения значение записывается в переменную val (при наличии)

43
Нагрузка на планировщик
Планировщик используется только при вызове proceed()!
Combining – техника; нет нагрузки в случае простаивания
void put(T val)
{
Lock lock(mutex);
Waiter* w = waiters.pop();
if (w)
{
lock.unlock();
w->proceed(std::move(val));
}
else
{
queue.emplace(std::move(val));
}
}
если есть ожидающий => передаем значение непосредственно ему и возобновляем выполнение
добавляем значение в очередь
аналогично реализуются: • неблокирующие мьютексы • неблокирующие condition variables

44
Обсуждение

45
Петли
Легко реализуются
Нет проблем с завершением

46
Каналы: ограничение по размеру
Реализация: 2 очереди для ожидания вместо одной
Ограничивает потребление памяти
Сетевое использование: TCP flow control
Контролирует latency

47
Обработчики и состояние
Отдавайте предпочтение обработчикам без состояний, т.к.
они позволяют параллельное выполнение стадии
Reduce-стадии как правило имеют состояние
Часто можно разбить reduce-стадии на несколько
независимых, результат объединить на следующей стадии

48
Дальнейшие улучшения

49
Буферизированные каналы
Позволяют снизить lock contention на каналы
Увеличивают throughput
Увеличивают latency

50
Планировщик «в глубину»
Обычно используют планировщик «в ширину», т.е. очередь
задач.
Вместо очереди задач можно использовать стек задач.
Получаем планировщик «в глубину» с другими свойствами.

51
Планировщик «в глубину»
Преимущества:
Более быстрое получение первых результатов
Снижение нагрузки на обработчики за счет более
равномерного распределения данных между стадиями
Уменьшение потребления памяти
«Прогретые» процессорные кеши
Отлично работает в связке с bounded каналами, заставляя
данные более активно перемещаться к результату
Недостатки:
Отсутствие fairness
Потеря контроля над latency

52
Планы на будущее
Распределенность
Отказоустойчивость
Оптимизация планировщика

53
Выводы

54
Предлагаемый подход позволяет
Реализовать простые сценарии (фильтрация, кеширование,
парсинг, преобразование и т.д.)
Реализовать сложные сценарии (петли, split, merge)
Использовать асинхронное сетевое взаимодействие
Забыть про синхронизацию
Простая параллелизация:
– Стадии выполняются параллельно, в отличие от MR
– Несколько обработчиков одной стадии также выполняются
параллельно

55
Спасибо за
внимание!

56
http://habrahabr.ru/users/gridem
https://github.com/gridem/Synca
https://bitbucket.org/gridem/synca