第四章 多元线性回归模型
DESCRIPTION
第四章 多元线性回归模型. 第一节 多元线性回归模型的概念 在许多实际问题中,我们所研究的因变量的变动可能不仅与一个解释变量有关。因此,有必要考虑线性模型的更一般形式,即多元线性回归模型: t=1,2,…,n 在这个模型中, Y 由 X 1 、 X 2 、 X 3 、 … X K 所解释,有 K+1 个未知参数 β 0 、 β 1 、 β 2 、 … β K 。 这里, “ 斜率 ” β j 的含义是 其它变量不变的情况下 , X j 改变一个单位对因变量所产生的影响。. 例 1 : 其中, Y= 在食品上的总支出 X= 个人可支配收入 P= 食品价格指数 - PowerPoint PPT PresentationTRANSCRIPT

1
第四章 多元线性回归模型第四章 多元线性回归模型

2
第一节 多元线性回归模型的概念 在许多实际问题中,我们所研究的因变量的变动可能不仅与一个解释变量有关。因此,有必要考虑线性模型的更一般形式,即多元线性回归模型: t=1,2,…,n
在这个模型中, Y 由 X1 、 X2 、 X3 、… XK 所解释,有 K+1 个未知参数 β0 、 β1 、 β2 、… βK 。
这里,“斜率” βj 的含义是其它变量不变的情况下, Xj 改变一个单位对因变量所产生的影响。
tktkttt XXXY uβ...βββ 22110

3
例 1 : 其中, Y= 在食品上的总支出 X= 个人可支配收入 P= 食品价格指数
用美国 1959-1983 年的数据,得到如下回归结果(括号中数字为标准误差):
uβββ 210 PXY
)114.0()003.0()6.9(
99.0739.0112.07.116ˆ 2 RPXY
),(数总消费支出价格平减指
食品价格平减指数1001972100 P
Y 和 X 的计量单位为 10 亿美元 ( 按 1972 不变价格计算 ).

4
多元线性回归模型中斜率系数的含义
上例中斜率系数的含义说明如下: 价格不变的情况下,个人可支配收入每上升 10亿美元( 1 个 billion ),食品消费支出增加 1.12亿元( 0.112 个 billion )。
收入不变的情况下,价格指数每上升一个点, 食品消费支出减少 7.39 亿元( 0.739 个 billion )

5
例 2 :
其中, Ct= 消费, Dt= 居民可支配收入 Lt= 居民拥有的流动资产水平 β2 的含义是,在流动资产不变的情况下,可支配收入变动一个单位对消费额的影响。这是收入对消费额的直接影响。
收入变动对消费额的总影响 = 直接影响 + 间接影响。 (间接影响:收入影响流动资产拥有量影响消费额)
但在模型中这种间接影响应归因于流动资产,而不是收入,因而, β2 只包括收入的直接影响。 在下面的模型中:
这里, β 是可支配收入对消费额的总影响,显然 β 和 β2
的 含义是不同的。
tttt uLDC 321 βββ
ntuDC ttt ,...,2,1,

6
回到一般模型 t=1,2,… , n
即对于 n 组观测值,有
tktkttt XXXY uβ...βββ 22110
nKnKnnnn
KK
KK
uXXXXY
uXXXXY
uXXXXY
β...ββββ
......
β...ββββ
β...ββββ
3322110
2232322212102
1131321211101

7
其矩阵形式为:
其中
nY
Y
Y
Y...
2
1
Knn
K
K
XX
XX
XX
X
...1
............
...1
...1
1
212
111
uXY
nK
u
u
u
u...
,
...
2
1
2
1
0

8
第二节 多元线性回归模型的估计
多元线性回归模型的估计与双变量线性模型类似,仍采用OLS 法。当然,计算要复杂得多,通常要借助计算机。理论推导需借助矩阵代数。下面给出普通最小二乘法应用于多元线性回归模型的假设条件、估计结果及所得到的估计量的性质。
一.假设条件( 1 ) E(ut)=0, t=1,2,…,n
( 2 ) E(ui uj)=0, i≠j ( 3 ) E(ut
2)=σ2, t=1,2,…,n ( 4 ) Xjt 是非随机量, j=1,2, … k t=1,2, … n

9
除上面 4 条外,在多个解释变量的情况下,还有两个条件需要满足:
( 5 )( K+1 ) < n; 即观测值的数目要大于待估计的参数的个数 (要有足够数量的数据来拟合回归线)。
( 6 )各解释变量之间不存在严格的线性关系。
上述假设条件可用矩阵表示为以下四个条件:

10
A1. E(u)=0 A2.
由于
显然, 仅当 E(ui uj)=0 , i≠j
E(ut2) = σ2, t=1,2,…,n
这两个条件成立时才成立,因此, 此条件相当前面条件(2), (3) 两条,即各期扰动项互不相关,并具有常数方差。
221
22212
12121
212
1
......
.................................
......
......
......
nnn
n
n
n
n uuuuu
uuuuu
uuuuu
uuu
u
u
u
uu
nIuuE 2)(
nIuuE 2)(

11
A3. X 是一个非随机元素矩阵。
A4. Rank(X) = (K+1) < n. ------ 相当于前面 (5) 、 (6) 两 条
即矩阵 X 的秩 = ( K+1)< n
当然,为了后面区间估计和假设检验的需要,还要加上一条:
A5. ~ , t=1,2,…n),0( 2Ntu
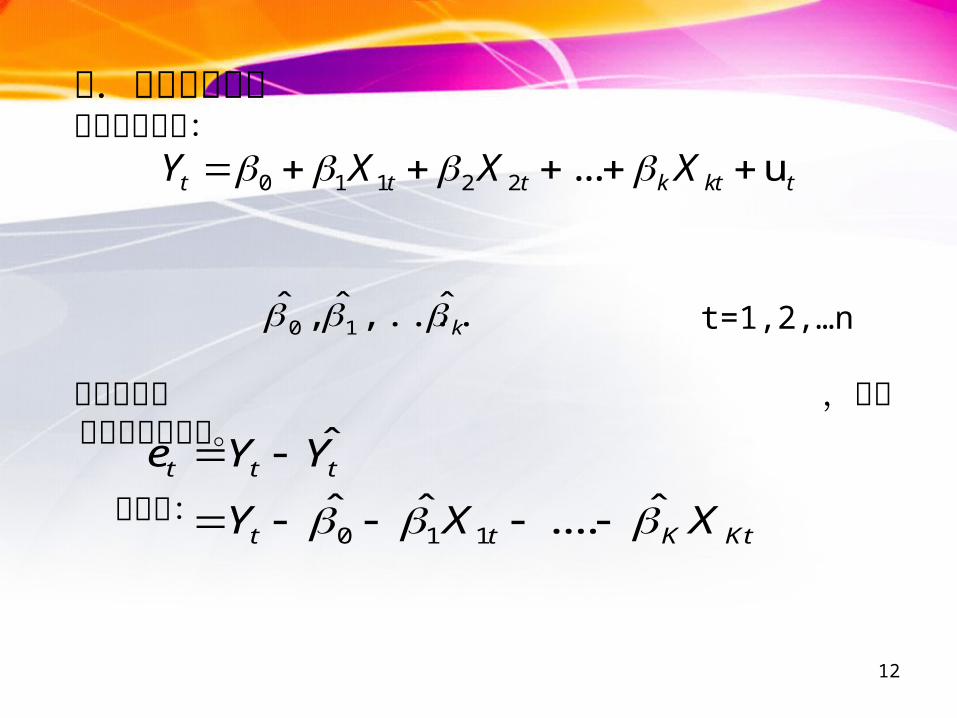
12
二.最小二乘估计我们的模型是:
t=1,2,…n
问题是选择 ,使得残差平方和最小。 残差为:
k ˆ,....,ˆ,ˆ10
0 1 1
ˆ
ˆ ˆ ˆ....
t t t
t t K Kt
e Y Y
Y X X
0 1 1 2 2 ... ut t t k kt tY X X X

13
要使残差平方和
为最小,则应有:
我们得到如下 K+1 个方程(即正规方程):
220 1 1
ˆ ˆ ˆ...t t t K KtS e Y X X
0ˆ
...,,0ˆ
,0ˆ
10
K
SSS

14
按矩阵形式,上述方程组可表示为:
tktKtKtktkt
ttKttKttt
ttKttKtt
tKtKt
YXXXXX
YXXXXXX
YXXXXX
YXXn
2
110
2212120
112
1110
110
β......ββ
........................
β......ββ
β......ββ
β......ββ

15
=
)'( XX
β 'X Y
即 YXXX 'β)'(
21
1
2
11
1
...
............
...
...
KttKtKt
Ktttt
Ktt
XXXX
XXXX
XXn
Kβ
...
β
β
1
0
nKnKK
n
Y
Y
Y
XXX
XXX
...
...
............
...
1...11
2
1
21
11211
YXXX
1)(β

16
YXXX
1)(β
三 . 最小二乘估计量 的性质 我们的模型为
估计式为 1 . 的均值
β
β
βˆ XY
uXY
)uβ()( 1 XXXX
u)(β)( 11 XXXXXXX
u)(β 1 XXX

17
(由假设 3 ) ( 由假设 1)
即
这表明, OLS 估计量 是无偏估计量。
β
KKK E
E
E
E
β
...
β
β
)β(
......
)β(
)β(
β
...
β
β
1
0
1
0
1
0
β
)u()(β)β( 1
EXXXE

18
2 . 的方差
为求 Var( ) ,我们考虑
β
β
ββββE
00
110 10 1
β β
β β β β β β ... β β...
β β
KK
KK
E

19
)β(...)β,β()β,β(
............
)β,β(...)β()β,β(
)β,β(...)β,β()β(
10
1101
0100
KKK
K
K
VarCovCov
CovVarCov
CovCovVar
不难看出,这是 的方差 -协方差矩阵,它是一个 (K+1)×(K+1) 矩阵,其主对角线上元素为各系数估计量的方差,非主对角线上元素为各系数估计量的协方差。
β

20
由上一段的 (4.5) 式,我们有因此
uXXX
1)(ββ
11 uu XXXEXXX
1 1E X X X uu X X X
uuββββ 11 XXXXXXEE
121 XXXIXXX n
211 XXXXXX
21 XX

21
请注意,我们得到的实际上不仅是 的方差,而且是一个方差 -协方差矩阵,为了反映这一事实,我们用下面的符号表示之:
21)()β( XXCovVar
β
为方便起见,我们也常用 Var( ) 表示的方差 -协方差矩阵,因此上式亦可写作:
需要注意的是,这里 不表示方差向量,而是方差 -协方差矩阵。
β
1 2( ) ( )Var β X X
( )Var β

22
3 . 2 的估计 与双变量线性模型相似, 2 的无偏估计量是
分母是 的自由度,这是因为我们在估计 的过程中,失去了( K+1 )个自由度。
4 . 高斯 -马尔科夫定理
对于 以及标准假设条件 A1- A4 ,
普通最小二乘估计量是最佳线性无偏估计量( BLUE )
)1(ˆ
2
2
Kn
et
kβ,...β,β 10
uβ XY
2te

23
我们已在上一段中证明了无偏性,下面证明线性和最小方差性。证明的路子与双变量模型中类似,只不过这里我们采用矩阵和向量的形式。 由 OLS 估计量 的公式
可知 , 可表示为一个矩阵和因变量观测值向量 的乘积:
其中 是一个 (K+1)*n 非随机元素矩阵。
因而 是线性估计量。
YXXX
1)(β
Y
Yk
XXXk 1)(

24
现设 为 的任意一个线性无偏估计量,即
其中 是一个 (K+1)*n 非随机元素矩阵。则
显然,若要 为无偏估计量,即 ,只有
, 为( K+1 )阶单位矩阵。
* Yc*
c
ucXcuXcYc )(*
Xc
uEcXc
ucXcEE
)(
)()( *
*)(E*
IXc I

25
的方差为:
我们可将 写成
从而将 的任意线性无偏估计量 与 OLS 估计量 联系起来。
*
cc
cuVarc
ucVar
ucXcVarVar
2
*
)(
)(
)()(
DXXXc 1)(
c
*

26
由 可推出:
即 因而有
由 从而 ,因此上式中间两项为 0 ,我们有
IXDXXXX 1)(
IXDI
0XD
DDXXXDDXXXXXXXXX
DXXXDXXX
DXXXDXXXcc
1111
11
11
)()()()(
)()(
)()(
0XD 0DX
DDXXcc 1)(
IXc

27
因此
最后的不等号成立是因为 为半正定矩阵。这就证明了 OLS估计量 是 的所有线性无偏估计量中方差最小的。至此,
我们证明了高斯 -马尔科夫定理。
)ˆ(
)ˆ(
)(
)(
*)(
2
212
12
2
Var
DDVar
DDXX
DDXX
ccVar
DD

28
第三节 拟合优度
一.决定系数 R2
对于双变量线性模型
Y=α+βX + u我们有
其中, = 残差平方和
2
22 1
YY
eR
2e

29
对于多元线性模型
我们可用同样的方法定义决定系数:
为方便计算,我们也可以用矩阵形式表示 R2
uXXY KK ...110
TSS
RSS
TSS
ESSR
YY
eR
1
1
2
2
22
或
总变差解释变差

30
我们有:残差 其中,
残差平方和:
Y Ye
βXY
)()(
2
YYYY
eeet
)β()β(
XYXY
)β)(β(
XYXY
ββββ XXXYYXYY
YXXXXXXYYXYY
1)(βββ
βXYYY
YXXYYXYY
βββ

31
而 将上述结果代入 R2 的公式,得到:
2222YnYYYnYYY
这就是决定系数
R2 的矩阵形式。
2
22 1
YY
eR
2
22
YY
eYY
2
2 )ˆ(
YnYY
XYYYYnYY
2
2ˆ
YnYY
YnXY

32
二.修正决定系数:
残差平方和的一个特点是,每当模型增加一个解释变量,并用改变后的模型重新进行估计,残差平方和的值会减小。 由此可以推论,决定系数是一个与解释变量的个数有关的量: 解释变量个数增加 减小 R2 增大
也就是说,人们总是可以通过增加模型中解释变量的方法来增大 R2 的值。因此,用 R2 来作为拟合优度的测度,不是十分令人满意的。
为此,我们定义修正决定系数 ( Adjusted )如下:
2R
2e
2R 2R

33
)1(
)1(1
2
22
nYY
KneR
2
2
)1(
)1(1
YYKn
en
1
)1)(1(1
2
Kn
Rn
34
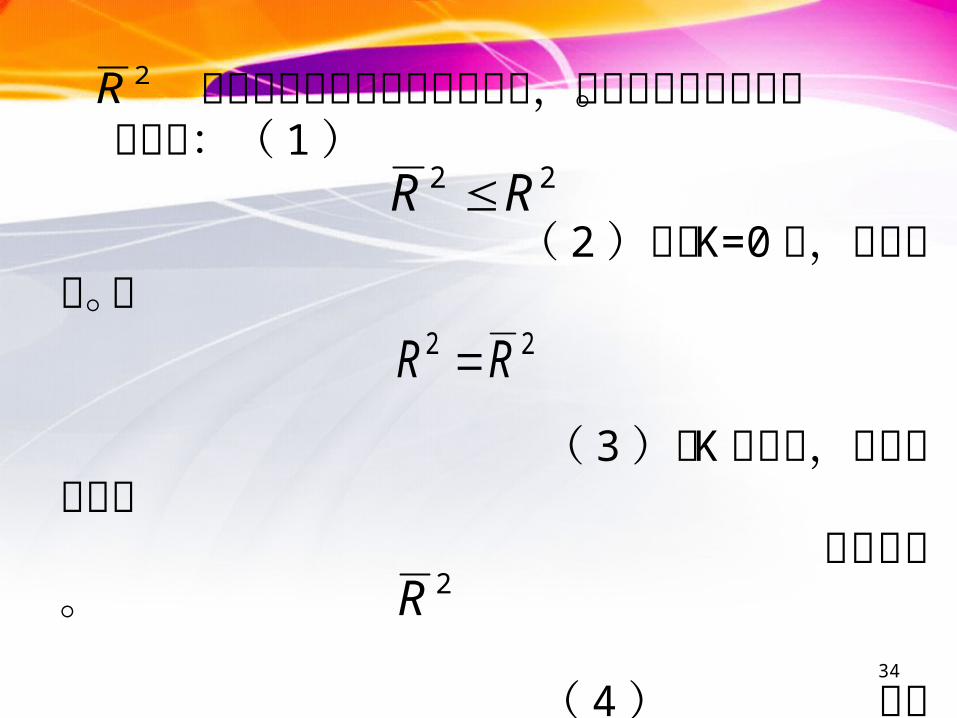
是经过自由度调整的决定系数,称为修正决定系数。
我们有:( 1 )
( 2 )仅当 K=0 时,等号成立。即
( 3 )当 K 增大时,二者的差异也 随之增大。 ( 4 ) 可能出现负值。
2R
22 RR
22 RR
2R

35
三.例子 下面我们给出两个简单的数值例子,以帮助理解这两节的内容 .
例 1 Yt = 1 + 2X2 t + 3X3 t + u t
设观测数据为: Y : 3 1 8 3 5 X2 : 3 1 5 2 4 X3 : 5 4 6 4 6 试求各参数的 OLS 估计值,以及 。
解:我们有
22 RR 和

36
641
421
651
411
531
5
3
8
1
3
XY
1298125
815515
25155
641
421
651
411
531
64645
42513
11111
XX

37
109
76
20
5
3
8
1
3
64645
42513
11111
YX
5.1
5.2
4
109
76
20
4/102/38
2/3110/45
810/4510/267
109
76
20
1298125
815515
25155
)(ˆ
1
1 YXXX

38
故回归方程为:
32 5.15.24ˆ XXY
2
22
ˆ
YnYY
YnXYR
5.106
5.1
5.2
4
1097620ˆ
XY
108
5
3
8
1
3
53813
YY

39
805
538135
22
Yn
9464.028
5.26
80108
805.1062
R
8928.0)35(
)9464.01(41
)1(
)1)(1(1
22
kn
RnR

40
例 2. 设 n = 20, k = 3, R2 = 0.70 , 求 。 解:
下面改变 n 的值,看一看 的值如何变化。我们有
若 n = 10 ,则 = 0.55
若 n = 5 , 则 = - 0.20 由本例可看出, 有可能为负值。 这与 R2 不同 ( )。
2R
644.0)420(
)70.01(191
)1(
)1)(1(1
22
kn
RnR
2R
2R
10 2 R
2R
2R

41
第四节 非线性关系的处理
迄今为止,我们已解决了线性模型的估计问题。但在实际问题中,变量间的关系并非总是线性关系,经济变量间的非线性关系比比皆是。如大家所熟悉的柯布 -道格拉斯生产函数 :
就是一例。
在这样一些非线性关系中,有些可以通过代数变换变为线性关系处理,另一些则不能。下面我们通过一些例子来讨论这个问题。
LAKQ

42
一 . 线性模型的含义 线性模型的基本形式是 :
其特点是可以写成每一个解释变量和一个系数相乘的形式。 线性模型的线性包含两重含义: ( 1 )变量的线性 变量以其原型出现在模型之中,而不是以X2或 Xβ 之类的函数形式出现在模型中。 ( 2 )参数的线性 因变量 Y 是各参数的线性函数。
......22110 XXY

43
二.线性化方法 对于线性回归分析,只有第二种类型的线性才是重要的,因为变量的非线性可通过适当的重新定义来解决。例如,对于
此方程的变量和参数都是线性的。
2 31 1 2 2 3
4
2 31 1 2 2 3
4
1 1 2 2 3 3
...
, , ...
...
XY X X
X
XZ X Z X Z
X
Y Z Z Z
只需定义
该关系即可以重写为:

44
参数的非线性是一个严重得多的问题,因为它不能仅凭重定义来处理。可是,如果模型的右端由一系列的 Xβ或 eβX 项相乘,并且扰动项也是乘积形式的,则该模型可通过两边取对数线性化。例如,需求函数
其中, Y= 对某商品的需求 X= 收入 P= 相对价格指数 ν= 扰动项可转换为:
Y X P v
log log log log logY X P v

45
用 X,Y,P 的数据,我们可得到 logY,logX 和 logP,从而可以用 OLS 法估计上式。 logX 的系数是 β 的估计值,经济含义是需求的收入弹性, logP 的系数将是 γ 的估计值,即需求的价格弹性。
弹性( elasticity )是一变量变动 1% 所引起的另一变量变动的百分比。其定义为
本例中, 需求的收入弹性是收入变化 1% ,价格不变时所引起的商品需求量变动的百分比。 需求的价格弹性是价格变化 1% ,收入不变时所引起的商品需求量变动的百分比。
Y
X
X
Y

46
三.例子
例 1 需求函数 本章 §1 中,我们曾给出一个食品支出为因变量,个人可支配收入和食品价格指数为解释变量的线性回归模型例子(例 4.1 )。现用这三个变量的对数重新估计(采用同样的数据),得到如下结果(括号内数字为标准误差):
回归结果表明,需求的收入弹性是 0.64, 需求的价格弹性是 -0.48 ,这两个系数都显著异于 0 。
)12.0()03.0()42.0(
99.0log48.0log64.082.2log 2 RPXY

47
例 2 .柯布 -道格拉斯生产函数
用柯布和道格拉斯最初使用的数据(美国1899-1922 年制造业数据)估计经过线性化变换的模型
得到如下结果(括号内数字为标准误差) :
从上 述 结 果 可 以 看 出 , 产 出 的 资本弹性 是0.23 ,产出的劳动弹性为 0.81 。
LAKQ
logloglogloglog LKAY
2ˆlog 0.18 0.23log 0.81log 0.96
(0.43) (0.06) (0.15)
Y K L R

48
例 3 .货币需求量与利率之间的关系 M
r=2 r
M=a(r-2)b
(a>0,b<0)
M = a(r - 2)b
这里,变量非线性和参数非线性并存。对此方程采用对数变换 logM=loga+blog(r-2)
令Y=logM, X=log(r-2), β1= loga, β2=b 则变换后的模型为:
Yt=β1+β2Xt + ut

49
将 OLS 法应用于此模型,可求得 β1 和 β2 的估计值 ,从而可通过下列两式求出 a 和 b 估计值:
应当指出,在这种情况下,线性模型估计量的性质(如 BLUE, 正态性等)只适用于变换后的参数估计量 ,而不一定适用于原模型参数的估计量 和 。
21ˆ,ˆ
11
2
ˆˆ ˆlog( ) ( e )
ˆ ˆ
a a
b
21ˆˆ 和
a b

50
例 4 .上例在确定货币需求量的关系式时,我们实际上给模型加进了一个结束条件。根据理论假设,在某一利率水平上,货币需求量在理论上是无穷大。我们假定这个利率水平为 2% 。假如不给这一约束条件,而是从给定的数据中估计该利率水平的值,则模型变为:
M = a(r - c)b
式中 a,b,c 均为参数。仍采用对数变换,得到
log(Mt) = loga + blog(rt - c) + ut t=1,2,…,n 我们无法将 log(rt-c)定义为一个可观测的变量 X, 因为这里有一个未知量 c 。也就是说,此模型无法线性化。在这种情况下,只能用估计非线性模型参数值的方法。

51
四.非线性回归
模型 Y = a(X - c)b
是一个非线性模型, a 、 b 和 c 是要估计的参数。此模型无法用取对数的方法线性化,只能用非线性回 归技术进行估 计 , 如 非 线 性 最 小 二 乘 法( NLS )。该方法的原则仍然是残差平方和最小。计量经济软件包通常提供这类方法,这里给出有关非线性回归方法的大致步骤如下:

52
非线性回归方法的步骤
1 . 首先给出各参数的初始估计值(合理猜测值) ;2 . 用这些参数值和 X 观测值数据计算 Y 的各期预测 值(拟合 值) ;
3 .计算各期残差,然后计算残差平方和∑ e2; 4 .对一个或多个参数的估计值作微小变动; 5 .计算新的 Y预测值 、残差平方和∑ e2; 6 .若新的∑ e2 小于老的∑ e2 ,说明新参数估计值 优于老估计值,则以它们作为新起点; 7 .重复步骤 4 , 5 , 6 ,直至无法减小∑ e2 为止。 8 .最后的参数估计值即为最小二乘估计值。
Y
Y

53
第五节 假设检验
一.系数的显著性检验1 . 单个系数显著性检验
目的是检验某个解释变量的系数 βj 是否为 0 ,即该解释变量是否对因变量有影响。
原假设 H0 : βj=0 备择假设 H1 : βj≠0

54
单个系数显著性检验的检验统计量是自由度为 n-k-1 的 t 统计量:
~ t(n-k-1)
其中, 为矩阵 主对角
线上第 j+1 个元素。而
)ˆ(
ˆ
)ˆ(
ˆ
j
j
j
j
VarSet
)ˆ( jVar 21 ˆ)( XX
1
ˆ
1ˆ
2
2
kn
XYYY
kn
et

55
例:柯布 -道格拉斯生产函数
用柯布和道格拉斯最初使用的数据(美国 1899-1922 年制造业数据)估计经过线性变换的模型
得到如下结果(括号内数字为标准误差) :
)15.0()06.0()43.0(
96.0log81.0log23.018.0ˆlog 2 RLKY
请检验“斜率”系数和的显著性。
log log log log logY A K L v

56
解: (1) 检验的显著性
原假设 H0 : = 0
备择假设 H1 : ≠ 0
由回归结果,我们有: t= 0.23/0.06=3.83
用 =24- 3= 21查 t 表, 5% 显著性水平下, tc
= 2.08.
∵t= 3.83 tc = 2.08 , 故拒绝原假设 H0 。
结论:显著异于 0 。

57
(2) 检验 的显著性
原假设 H0 : = 0
备择假设 H1 : ≠ 0
由回归结果,我们有: t= 0.81/0.15=5.4
∵t= 5.4 tc = 2.08 , 故拒绝原假设 H0 。
结论:显著异于 0 。

58
2 .若干个系数的显著性检验(联合假设检验)
有时需要同时检验若干个系数是否为 0 ,这可以通过建立单一的原假设来进行。
设要检验 g 个系数是否为 0 ,即与之相对应的 g 个解释变量对因变量是否有影响。不失一般性,可设原假设和备择假设为:
H0: β1 =β2 = … =βg =0 H1: H0 不成立 ( 即 X1, …Xg 中某些变量对 Y 有 影响 )

59
分析: 这实际上相当于检验 g 个约束条件 β1= 0 , β2 = 0 ,… , βg = 0 是否同时成立。
若 H0 为真,则正确的模型是:
据此进行回归(有约束回归),得到残差平方和
SR 是 H0 为真时的残差平方和。
tKtKtggt XXY uβ...ββ 110
2110 β...ββ KtRktg
Rg
RtR XXYS
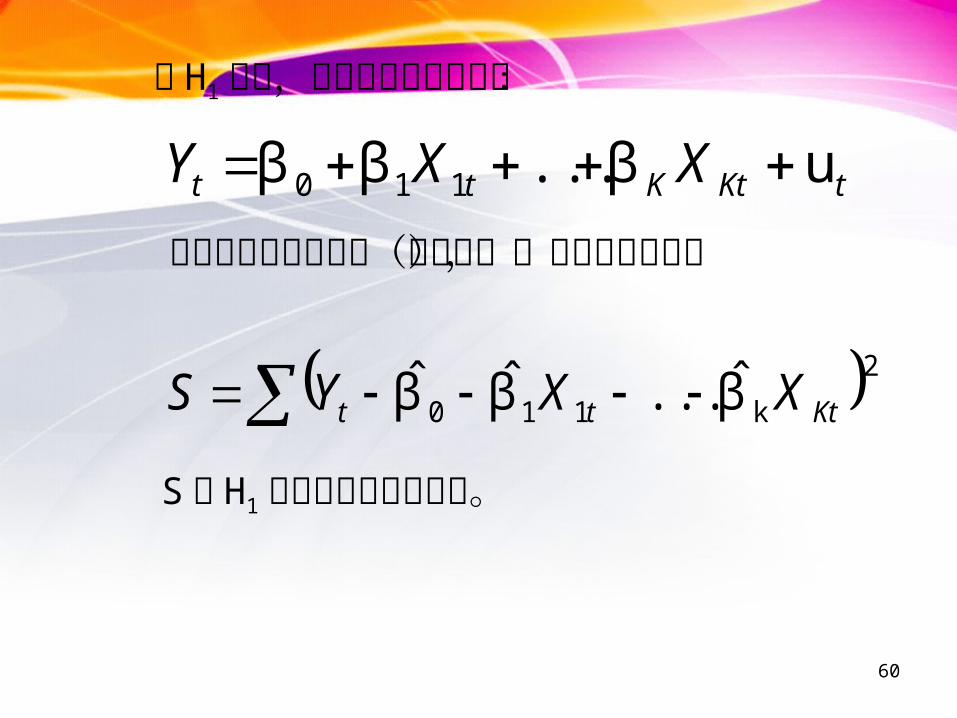
60
若 H1 为真,正确的模型即原模型:
tKtKtt XXY uβ...ββ 110 据此进行无约束回归(全回归),得到残差平方和
S 是 H1 为真时的残差平方和。
2k110 β...ββ Kttt XXYS

61
如果 H0 为真,则不管 X1, …Xg 这 g 个变量是否包括在模型中,所得到的结果不会有显著差别,因此应该有: S ≈ SR
如果 H1 为真,则由上一节中所讨论的残差平方和∑ e2 的特点,无约束回归增加了变量的个数,应有
S < SR
通过检验二者差异是否显著地大,就能检验原假设是否成立。

62
所使用的检验统计量是: ~ F(g, n-k-1)
其中, g 为分子自由度, n-k-1 为分母自由度。
使用 的作用是消除具体问题中度量单位
的影响, 使计算出的 F 值是一个与度量单位无关的量。
)1(
KnS
gSSF R
S
SSR

63
例:给定 20 组 Y, X1, X2, X3 的观测值,试检验模型 中 X1 和 X3 对 Y 是否有影响?
解:( 1 )全回归
估计
得到: S =∑e2 = 25
( 2 )有约束回归 估计
得到: SR =∑e2 = 30
ttttt XXXY uββββ 3322110
ttt XY uββ 220

64
原假设 H0: β1 = β3 = 0 备择假设 H1: H0 不成立
我们有: n=20, g=2, k=3
6.1
1625
22530
)1(
KnS
gSSF R
用自由度( 2 , 16 )查 F分布表, 5% 显著性水平下, ∵F=1.6< FC =3.63, 故接受 H0 。
结论: X1 和 X3 对 Y 无显著影响
3.63cF

65
3 .全部斜率系数为 0 的检验 上一段结果的一个特例是所有斜率系数均为 0 的检验,即回归方程的显著性检验:
H0 : β1 =β2 = … = βK = 0
也就是说,所有解释变量对 Y 均无影响。
注意到 g=K , 则该检验的检验统计量为:
2)( YYSR
)1(
)(
)1(
)(2
22
Kne
KeYY
KnS
KSSF R

66
分子分母均除以 ,有 2)( YY
1)(
)(1
2
2
2
2
KnYY
e
KYY
e
F)1()1( 2
2
KnR
KR
从上式不难看出,全部斜率为 0 的检验实际是检验R2 的值是否显著异于 0 ,如果接受原假设,则表明因变量的行为完全归因于随机变化。若拒绝原假设,则表明所选择模型对因变量的行为能够提供某种程度的解释。

67
二.检验其他形式的系数约束条件
上面所介绍的检验若干个系数显著性的方法,也可以应用于检验施加于系数的其他形式的约束条件,如
检验的方法仍是分别进行有约束回归和无约束回归,求出各自的残差平方和 SR 和 S ,然后用 F 统计量进行检验。 当然,单个系数的假设检验,如 H0 : 3=1.0 ,亦可用 t 检验统计量进行检验。
1,1
1,
5.2,0.1
3
243
42

68
例: Cobb-Douglas 生产函数
Y=AKαLβν 试根据美国制造业 1899-1922 年数据检验规模效益不变的约束: α+β=1
解:( 1 )全回归
2
2
ˆlog 0.18 0.23log 0.81log 0.96
: (0.43) (0.06) (0.15) 252
0.0710
Y K L R
Se F
e

69
( 2 )有约束回归: 将约束条件代入,要回归的模型变为: Y=AKαL1-αν 为避免回归系数的不一致问题, 两边除以 L ,模型变换为: Y/L=A(K/L)αν
回归,得:
2 2
log( / ) 0.02 0.25log( / )
: (0.02) (0.04)
0.63 38.0 0.0716
Y L K L
Se
R F e

70
由回归结果得到的约束回归和全回归的残差平方和分别为 SR=0.0716 S=0.0710 ( 3 )检验 原假设 H0:α+β= 1 备择假设 H1:α+β≠1 本例中, g=1, K=2, n=24
18.0
210710.0
10710.00716.0
)1(
KnS
gSSF R

71
用自由度( 1 , 21 )查 F 表, 5% 显著性水平下, Fc=4.32
∵F=0.18< Fc=4.32 故接受原假设 H0:α+β= 1
( 4 )结论 我们的数据支持规模收益不变的假设。

72
第六节 预测
我们用 OLS 法对多元回归模型的参数进行了估计之后,如果结果理想,则可用估计好的模型进行预测。与双变量模型的作法类似,预测指的是对诸自变量的某一组具体值
来预测与之相对应的因变量值 。当然,要进行预测,有一个假设前提应当满足,即拟合的模型在预测期也成立。
)...1( 02010 kXXXC
0Y

73
点预测值由与给定的诸 X 值对应的回归值给出,即
而预测期的实际 Y 值由下式给出:
其中 u0 是从预测期的扰动项分布中所取的值。
ˆˆ...ˆˆˆˆ020210100
CXXXY kk
00020210100 ... uCuXXXY kk

74
预测误差可定义为:
000 YYe
)ˆ(0 Cu
0
)ˆ()()( 00
ECuEeE
0CY
两边取期望值,得
因 此 , OLS 预测量
是一个无偏预测量。

75
预测误差的方差为:
))(1(
)(
)ˆ()()(
12
212
00
CXXC
CXXC
CVarCuVareVar
)(
)(
0
00
eSe
eEe )1,0(~)(1 1
0 NCXXC
e
从 e0 的定义可看出, e0 为正态变量的线性函数,因此,它本身也服从正态分布。故

76
由于 为未知,我们用其估计值代替它,有
则 的 95%置信区间为:
即
)1(ˆ 2 knet
)1(~)(1ˆ
ˆ
1
00
kntCXXC
YY
10 0.025ˆ ˆ 1 ( )Y t C X X C
0Y
CXXCtC 1025.0 )(1ˆˆ

77
例 用书上 P85 例 4.3 的数据,预测 X2=10 , X3=10 的 Y值。
解:
由例 4.3 我们已得到:
14)10(5.1)10(5.240 Y
7.6
10
10
1
4/102/38
2/3110/45
810/4510/267
)10101()( 1
CXXC
5.106ˆ XY 108YY

78
因此
的 95%置信区间为:
或 3.66至 24.34 之间 .
75.0125
5.106108
1
ˆ
1ˆ
2
2
kn
XYYY
kn
et
0Y
7.6175.0303.414

79
第七节 虚拟变量( Dummy variables )一.虚拟变量的概念
在回归分析中,常常碰到这样一种情况,即因变量的波动不仅依赖于那种能够很容易按某种尺度定量化的变量(如收入、产出、价格、身高、体重等),而且依赖于某些定性的变量(如性别、地区、季节等)。
在经济系统中,许多变动是不能定量的。如政府的更迭(工党 -保守党)、经济体制的改革、固定汇率变为浮动汇率、从战时经济转为和平时期经济等。

80
这样一些变动都可以用 0-1 变量来表示,用 1 表示具有某一“品质”或属性,用 0 表示不具有该“品质”或属性。这种变量在计量经济学中称为“虚拟变量”。虚拟变量使得我们可以将那些无法定量化的变量引入回归模型中。
下面给出几个可以引入虚拟变量的例子。
例 1 :你在研究学历和收入之间的关系,在你的样本中,既有女性又有男性,你打算研究在此关系中,性别是否会导致差别。

81
例 2 :你在研究某省家庭收入和支出的关系,采集的样本中既包括农村家庭,又包括城镇家庭,你打算研究二者的差别。
例 3 :你在研究通货膨胀的决定因素,在你的观测期中,有些年份政府实行了一项收入政策。你想检验该政策是 否对通货膨胀产生影响。
上述各例都可以用两种方法来解决,一种解决方法是分别进行两类情况的回归,然后检验参数是否不同。另一种方法是用全部观测值作单一回归,将定性因素的影响用虚拟变量引入模型。
82
二.虚拟变量的使用方法
1 . 截距变动 设 Y 表示消费, X 表示收入,我们有: } 假定 β 不变。
对于 5 年战争和 5 年和平时期的数据,我们可分别估计上述两个模型,一般将给出 的不同值。 现引入虚拟变量 D, 将两式并为一式: 其中,
XY
uXY
2
1
和平时期:战时:
β
uDXY 210 0 战时D=
1 平时

83
此式等价于下列两式: }截距变动,斜率不变
在 包 含 虚 拟 变 量 的 模 型 中 , D 的 数 据 为0 , 0 , 0 , 0 , 0 , 1 , 1 , 1 , 1 , 1 。
估计结果如下图所示:
应用 t 检验, β2 是否显著 可以表明截距项在两个时 期是否有变化。
uXY
uXY
120
10
平时:战时:
Y 平时
战时
α 2-α 1=β 2
α 1=β 0
X

84
2 . 斜率变动 如果我们认为战时和平时的消费函数中,截距项不变,而斜率不同,即 β 变动,则可用下面的模型来研究两个时期边际消费倾向的差异:
其中, D={ 不难看出,上式相当于下列两式:
同样,包括虚拟变量的模型中, β2 是否显著可以表明斜率在两个时期是否变化。
uDXXY
uXDY
)(
)(
21
21
即:
平时战时
1
0
uXY
uXY
)( 21
1
Y 战时 平时
α
X

85
3 .斜率和截距都变动在这种情况下,模型可设为:
其中, D={ 此式等价于下列两个单独的回归式:
uDXXDY
uXDDY
)(
)()(
4321
4321
即:
平时战时
1
0
uXY
uXY
)(平时:战时:
4321
31
)(
引进了虚拟变量的回归模型对于检验两个时期中是否 发生结构性变化很方便。 如上例中,相当于检验 H0: β2=β4=0

86
4 .季节虚拟变量的使用
许多变量展示出季节性的变异 ( 如商品零售额、电和天然气的消费等 ) ,我们在建立模型时应考虑这一点,这有两种方法:
( 1 ) 在估计前对数据进行季节调整; ( 2 ) 采用虚拟变量将季节性差异反映在模型 中。

87
例:设 Y=购买汽车的实际支出额 X= 实际总消费支出 用美国 1973(1) - 1980(2) 的季度数据(按 1975年价格计算),得回归结果如下:
)5.0()6.1(:)(
0281.00133.00.765ˆ 2
t
RXY
这一结果很不理想,低 R2 值,低 t 值, X 的符号也不对。考虑到可能是季节性变异的问题,我们建立下面的模型:

88
其中, uXQQQY 43322110
1
1 1
0Q
季度其它季度
2
1 2
0Q
季度其它季度
3
1 3
0Q
季度其它季度
各季度的截距分别为:1季度: 0 + 1
2季度: 0 + 2
3季度: 0 + 3
4季度: 0
请注意我们仅用了 3 个虚拟变量就可表示 4个季度的情况。

89
估计结果如下:
结果仍不理想,但好多了。四个季度的截距项分别为: -1039.2 , -1122.7 , -1161.4 , -1455.8 。
所得到的实际总支出的参数估计值( 0.1044 )是一个不受季节变动影响的估计值。
65.0
1044.034.29421.3336.41681.1455
2
)5.4()9.5()4.6(1
)2.7()5.3(:)(
R
XQQQYt

90
5. 虚拟变量陷阱 我们在上一段中用三个虚拟变量表示四个季度
的情况。能不能用四个虚拟变量来区分四个季度呢?答案是绝对不行。因为这将在 X 矩阵中增加一列(虚拟变量 Q4 的观测值列),四季度为 1 ,其它季度为 0 。不难看出,在这种情况下,四个虚拟变量在 X 矩阵中的观测值列相加,就得到一个所有元素都为 1 的列向量,与 X 矩阵中第一列(截距项列)完全相同,表明 X 矩阵各列线性相关,矩阵的秩小于 k+ 1 ,不满足假设条件( 4 ), OLS 估计无法进行。 这就是 所谓的 “虚拟 变 量陷阱( Dummy variable trap )”因此,若定性变量有 m 个类别,则仅需引入(
m- 1 )个虚拟变量。如果引入 m 个虚拟变量,则会画蛇添足,陷入虚拟变量陷阱。

91
* 第八节 极大似然法 与普通最小二乘法相比,一个具有更强的理论性质的点估计方法是极大似然法( Maximum Likelihood method , ML )。 极大似然法的一般概念是,设 是随机变量 X的密度函数,若有一随机样本 X1 , X2 ,… XN ,则 的极大似然估计值是具有产生该观测样本的最高概率的那个值,或者换句话说, 的极大似然估计值是使密度函数达到最大的值。下面让我们通过一个例子来进一步说明极大似然法的概念。
( , )f x

92
一、似然的概念 一个样本发生的概率称为该样本的似然。例如,抛一枚不均衡的硬币 10次,得到 4次正面。根据二项分布,我们有
其中 X = 出现正面的次数 p = 一次抛掷中出现正面的概率,即 P( 正面) 根据似然的定义, P(X=4) 是当 P( 正面 )=p 时,X=4 的似然。我们有 :
4 4 610( 4) (1 )P X C p p
0.1
0.3
0.4
0.5
0.8
p
p
p
p
p
( 4) 0.011
( 4) 0.200
( 4) 0.251
( 4) 0.205
( 4) 0.006
P X
P X
P X
P X
P X

93
由于 p 是未知的,我们可以通过选择一个值 来估计它,这个 使似然最大,或者说,这个值 给出该样本结果的可能性最大。 我们可以通过下面两种方法求得 。 ( 1 )迭代法 试不同的值,找出使似然最大的值。在本例中,由于 p=0.4 时 P(X=4)=0.251 为最大,即这个值最有可能给出 10次抛掷中出现 4次正面的结果,因此 =0.4 。 ( 2 )计算法 设 ,令 ,求得使 L达到
最大的 p 值。计算结果, =0.4 。
p~
p~p~
p~
p~
4 4 610 (1 )L C p p 0
dL
dp
p~

94
二、正态分布参数的极大似然估计 给定一个取自正态分布的随机样本 X1 , X2,…Xn ,我们希望估计总体均值 μ 和总体方差。我们有
该样本的似然 L= P(样本值为 X1,X2,…Xn)
2
2
( )
21( )
2
ix
iP x e
2 2 21 2
2 2 2
1 2
( ) ( ) ( )
2 2 2
2
2
( ) ( )... ( )
1 1 1( )( )......( )
2 2 2
( )1( ) exp
22
n
n
X X X
in
P X P X P X
e e
X
e

95
令 我们可求得:
我们有
而
2
ln0
ln0
L
L
u
22 ( )
i
i
XX
n
X X
n
2 22 2
( )
( 1)( )
E
nE
n n
2 2是 的无偏估计量,而 是 的有偏估计量。
这表明:

96
三、双变量线性回归模型的极大似然估计
模型:
假设(与最小二乘法相同):
t t tY X u
2 2( ) 0, ( ) , ( ) 0,t t i j
t t
E u E u E u u i j
X u
为非随机的, 服从正态分布。
由假设我们有
因而
2( , )tN X tY~
2
2( )
21( )
2
t tY X
tP Y e

97
故对于 Y1,Y2,…Yn ,有
1 2( ) ( )... ( )nL P Y P Y P Y2
2
( )
21( )
2
t tY X
n e
当 L被看作是参数 的函数时,称为似然函数,表示为 ,极大似然法要求我们选择使似然函数达到最大的参数估计值。在很多情况下,极大化似然函数的对数要比极大化似然函数本身方便一些,并且结果相同,因为二者在相同的点获得最大值,因此我们写出 的对数:
2 ( , , )2L ( , , )
2L ( , , )

98
22
2
( )ln ln(2 ) ln( )
2 2 2t tY Xn n
L
令2
ln ln ln0, 0, 0
( )
L L L
得:
2
22 ( )
t t
t t t t
t t
Y n X
X Y X X
Y X
n
不难看出,前两式与用普通最小二乘法得出的正规方程相同,故 。但最后一式表明, 的极大似然估计量与最小二乘估计量不同。
ˆ~,ˆ~
2

99
最小二乘估计量
是一个无偏估计量。而
这表明 是一个有偏估计量。
不难看出,当样本容量趋向无穷时,
即 是一个渐近无偏估计量。
2 22
ˆˆ( )ˆ
2 2t t te Y X
n n
2 2 22 2( 2) 2
( ) ( )te nE E
n n n
22 ( )t tY X
n
22 22
n
2

100
四、极大似然估计量的性质1. 从上面的分析可看出,在小样本情况下, ML 估计量不一定是无偏的(如 ),但在大样本情况下,具有渐近无偏性。2. 可以证明, ML 估计量是一致估计量。3. 可以证明,在大样本情况下, ML 估计量服从正态分布,且为最有效的估计量,即对于任何无偏估计量 ,有
2
var( )lim( 1
var( )n
由此可得出如下结论:在大样本的情况下, ML 估计量比 OLS 估计量更有效。

101
五、似然比 (LR) 检验、沃尔德 (W) 检验与拉格朗日乘数 (LM) 检验
似然比检验( Likelihood Ratio Test, LR )、瓦尔德检 验 ( Wald Test, W ) 和拉格朗日乘 数 检 验( Lagrange Multiplier Test, LM )是三种基于极大似然法的大样本检验方法。
我们在第五节中介绍的 F 检验适用于检验 CLR 模型的线性约束条件。如果施加于模型的约束是非线性的,模型存在参数非线性,或者扰动项的分布不是正态的,在这些情况下, F 检验就不再适用,通常需要采用 LR 、 W 和 LM 这三个检验方法中的一个来检验约束条件是否成立。
这三个检验统计量基于三个不同的原理,我们用图 4- 4 来解释之。

102
W
A
B
C
g()
LM
l nL
O
LR
l nL, g()
l nLmax
图 4- 4 LR 、 W 、 LM统计量的直观解释

103
设 θ 表示模型中的参数集(如双变量线性模型中, θ 由三个参数 组成), L(θ) 为似然函数, 表示无约束极大似然估计值( unrestricted MSE ), 表示有约束极大似然估计值( restricted MSE )。 W 检验仅用 , LM 检验仅用 , LR检验二者都要用。也就是说 , LR 检验既需要对无约束方程又需要对有约束方程进行极大似然估计 ,W 检验仅需对无约束方程进行极大似然估计 , LM 检验仅需对有约束方程进行极大似然估计。在很多情况下,计算有约束极大似然估计值较容易,因为方程相对简单。这也是 LM 检验法非常流行的原因。
2、 和

104
1 . LM 检验和 W 检验令
我们有:
E[S(θ)] = 0, var[S(θ)] = I(θ),
并且,若 是极大似然估计值( MLE ),则
2
2
ln ln( ) , ( )
L LS I E
ˆ( ) 0S

105
LM 检验的逻辑是,如果原假设是关于 θ 的某些约束条件成立,则对于有约束极大似然估计值 ,应该有
因此 LM 检验统计量为( ) 0 ( ) ( )S I I 。同时还有 。
1 2: ( ) [ ( )] ( )s kT S I S
其中 k 为约束的数目。 LM 检验有几种形式,取决于 如何被估计。如果 显著不同于 ,或者原假设不成立, 将显著异于 0 。
W 检验则使用无约束极大似然估计值 的协方差矩阵 来构造原假设的检验。
sT
sT( )I
1ˆ[ ( )]I

106
2 . LR 检验LR 检验法的思路与本节前面讨论的联合假设检
验一样,分别进行无约束回归和有约束回归,算出无约束和有约束情况下的 L(θ) 最大值,然后计算比率
由于约束条件下的 L(θ) 最大值小于无约束条件下的 L(θ) 最大值,因而 λ 必然小于 1 。如果约束条件(原假设)不成立, λ将显著小于 1;如果约束条件(原假设)成立,则 λ将接近于 1 。
LR 检验使用的检验统计量为- 2Lnλ ,该检验统计量服从自由度为 k 的 分布, k 为约束的数目。
( )
( )
L
L
约束条件下的 最大值=无约束条件下的 最大值
2

107
3 .用于检验线性约束的 LR 、 W 和 LM 检验统计量
对于线性约束的检验,似然比检验统计量为
lnRRSS
LR nURSS
其中 RRSS=有约束残差平方和 URSS=无约束残差平方和 n=观测值个数 LR服从自由度为 k 的 分布, k 为约
束的数目。
2

108
这三个大样本检验方法用于双变量线性模型中检验原假设 的检验统计量为0
2
2
2
2
1ln
1
1
LR nR
nRW
R
LM nR
这三者都服从自由度为 1 的 分布。2

109
实践中三种检验法的选择问题
当面临具有相同渐近性质的几种统计量时,计量经济学家通常根据它们的小样本性质来进行选择。然而实践中在 LR 、 W 和 LM 的选择上,计算成本往往起着关键作用。
计算 LR统计量, 的约束和无约束估计值都要计算,如果二者都不难计算,则 LR 检验是三种检验中最具吸引力的。

110
计算 W统计量仅需要无约束估计值。如果约束估计值的计算比较困难,而无约束估计值计算不困难,如约束条件是非线性的情况,则 W统计量应成为首选。
计算 LM 统计量仅需约束估计值。如果约束估计值的计算比较容易,而无约束估计值的计算困难,例如施加约束后使非线性模型转换成线性模型的情况,则 LM统计量应成为首选。
在计算方面的考虑不是问题的情况下,应选择LR 检验。