หัดเขียน a.i. แบบ alphago กันชิวๆ
TRANSCRIPT

หัดเขียน A.I. แบบ AlphaGo กันชิวๆKan Ouivirach
http://www.tgdaily.com/web/134986-machine-learning-ai-and-digital-intelligences-effect-on-business

Kan OuivirachResearch & Development
Engineer

http://www.bigdata-madesimple.com/
Machine Learning
“Given example pairs, induce such that for given pairs and generalizes well for unseen ”
–Peter Norvig (2014)
(x, y) fy = f(x)
x

Dog
Cat
Generalization

Main Types of Learning
• Supervised Learning
• Unsupervised Learning
• Reinforcement Learning

“ไขความลับ อัลฟ่าโกะ การเรียนรู้แบบเชิงลึก และอนาคตของปัญญาประดิษฐ์”
ดร. สรรพฤทธิ์ มฤคทัต22 มี.ค. 2559


Google DeepMind: Ground-breaking AlphaGo masters the game of Go
https://www.youtube.com/watch?v=SUbqykXVx0A


We’ll do this today!

Minimax Decisions
Reinforcement Learning
and
http://www.123rf.com/photo_8104943_hand-drawn-tic-tac-toe-game-format.html

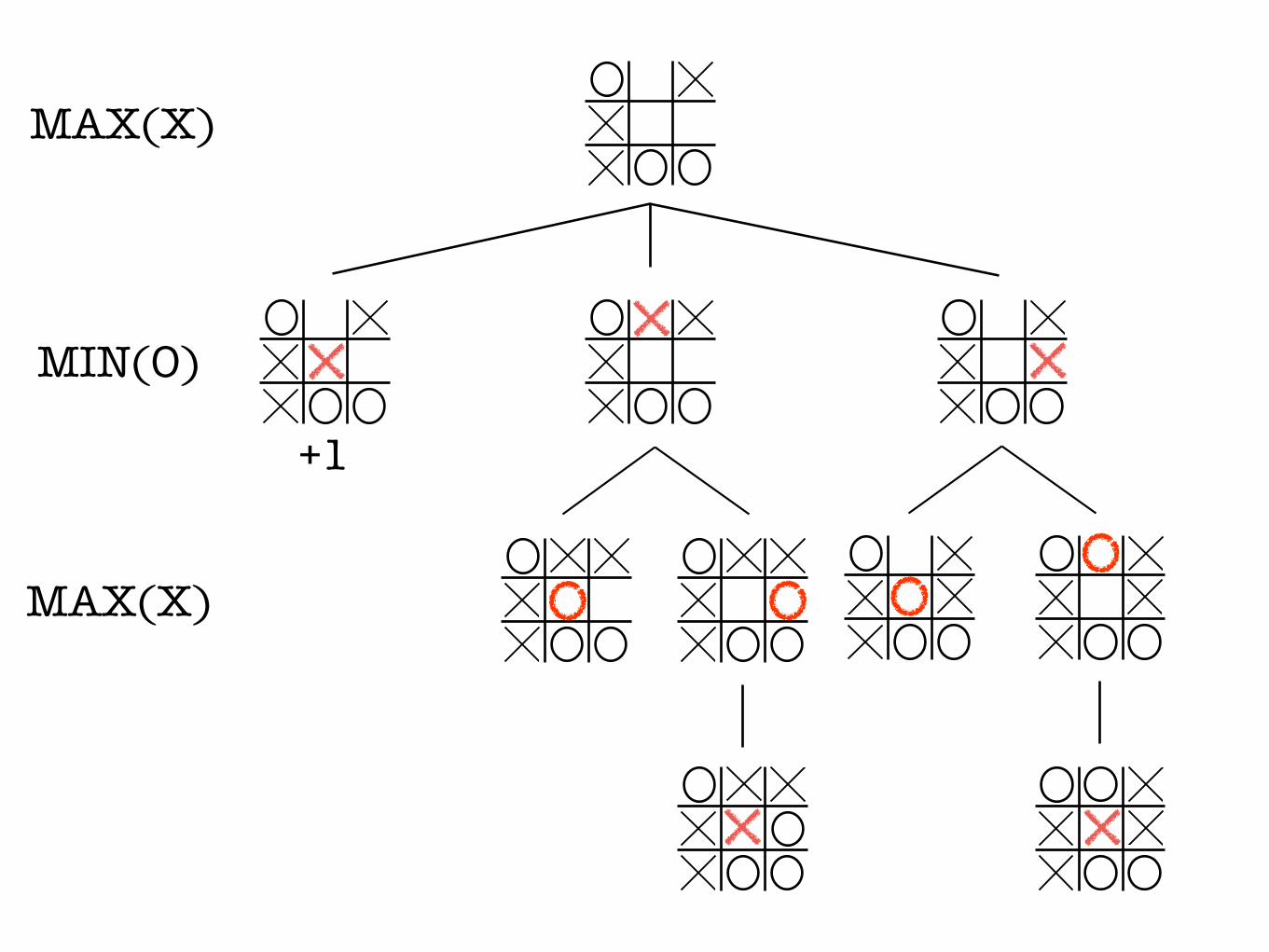
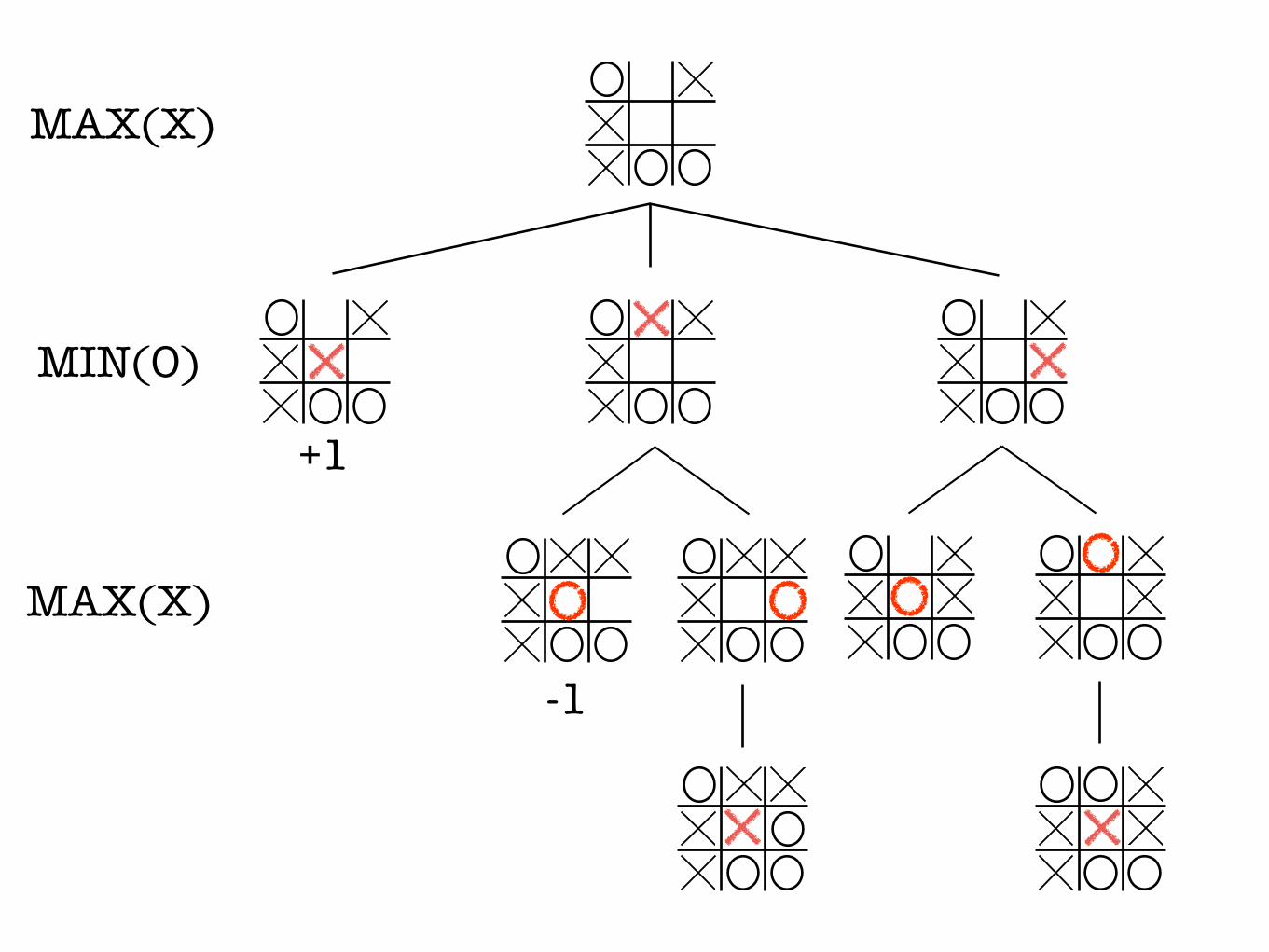
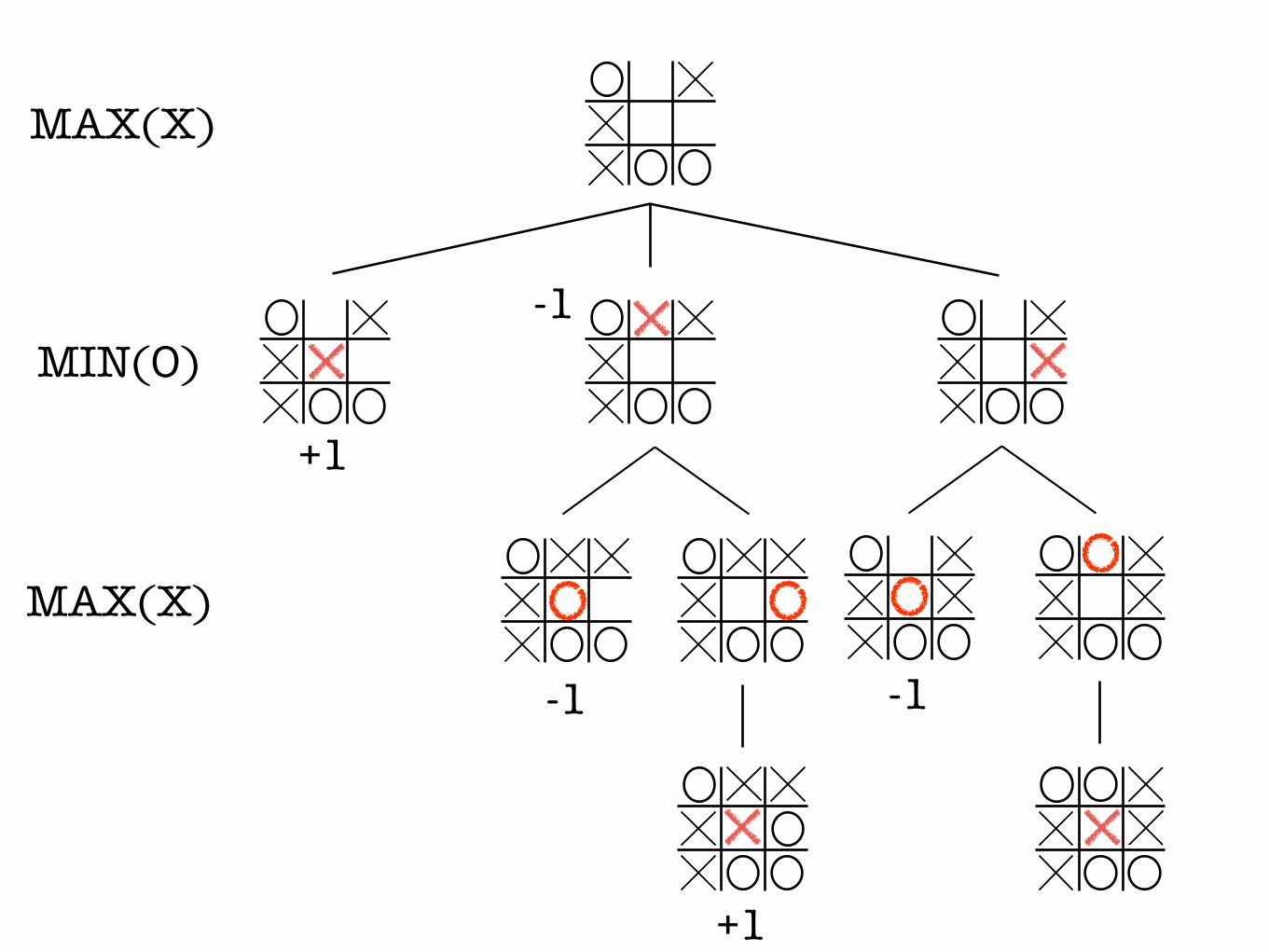
Minimax Decisions

MAX(X)
MIN(O)
MAX(X)
• 1 if wins • -1 if loses
MAX(X)
MIN(O)
MAX(X)
+1
MAX(X)
MIN(O)
MAX(X)
+1
-1

MAX(X)
MIN(O)
MAX(X)
+1
-1
+1

MAX(X)
MIN(O)
MAX(X)
+1
-1
+1
-1
MAX(X)
MIN(O)
MAX(X)
+1
-1
+1
-1
-1

MAX(X)
MIN(O)
MAX(X)
+1
-1
+1
-1
+1
-1

MAX(X)
MIN(O)
MAX(X)
+1
-1
+1
-1
-1
+1
-1

argmaxa 2 ACTIONS(s)MIN-VALUE(RESULT(state, a))
MINIMAX-DECISION(state)function returns an action
return
MAX-VALUE(state)
TERMINAL-TEST(state) UTILITY(state)v �1
ACTIONS(state)
v MAX(v,MIN-VALUE(RESULT(s, a)))
v
function
return
returns
then return
a utility value
afor each
in do
if
TERMINAL-TEST(state) UTILITY(state)
ACTIONS(state)
v
function
return
returns
then return
a utility value
afor each
in do
if
MIN-VALUE(state)
v 1
v MIN(v,MAX-VALUE(RESULT(s, a)))

https://github.com/zkan/tictactoe/blob/master/tictactoe_minimax.py

Alpha-Beta Pruning

[�1,+1]
↵ �max
min

3
max
min
[�1,+1]
[�1,+1]
↵ �

[�1, 3]
3
[�1,+1]
↵ �max
min

3 12
[�1, 3]
[�1,+1]
↵ �max
min

3 12 8
[3,+1]
[�1, 3]
↵ �max
min

3 12 8 2
[3, 2]
[3,+1]
[�1, 3]
↵ �max
min

3 12 8 2
Prune!
[3, 2]
[3,+1]
[�1, 3]
↵ �max
min

http://researchers.lille.inria.fr/~munos/
Reinforcement Learning

Reinforcement Learning (RL)
y = f(x)
z
Given x and z, find a function f that generates y.

Agent-Environment Interaction in RL
Agent
Environment
Rt+1
St+1
St Rt At
State Reward Action

Policy
• The learning agent's way of behaving at a given time
• A mapping from perceived states of the environment to actions to be taken when in those states
• A simple lookup table

Agent
Environment
Rt+1
St+1
St Rt At
State Reward Action
I’m gonna find my optimal policy!

y = f(x)
z
Given x and z, find a function f that generates y.
Action
State
Reward
Policy


Google DeepMind's Deep Q-learning playing Atari Breakout
https://www.youtube.com/watch?v=V1eYniJ0Rnk
Flappy Bird Hack using Reinforcement Learning
http://sarvagyavaish.github.io/FlappyBirdRL/

http://quotes.lifehack.org/quote/albert-einstein/learning-is-experience-everything-else-is-just/


Exploration & Exploitation
http://mariashriver.com/blog/2012/10/balancing-happiness-and-heartache-in-alzheimers-kerry-lonergan-luksic/

Q-Learning
Q(s, a) Q(s, a) + ↵(R(s) + � maxa0Q(s0, a0)�Q(s, a))
↵ learning rate� discount factor
Q table of action values indexed by state and action
s
a
previous stateprevious action
a0 s0
R(s) reward in state s
action taken in state

Q-Learning through Simple Example
1 2
3 4
5
Goal!

1 2
3 4
5
Goal!
1 2
3 4
5 Goal!

1 2
3 4
5 Goal!
0
0
000
0
0
0
00
R =
0
BBBBBB@
1 2 3 4 5
1 �1 �1 0 �1 �1
2 0 �1 �1 0 100
3 0 �1 �1 0 �1
4 �1 0 0 �1 �1
5 �1 0 �1 �1 100
1
CCCCCCA
Define a reward function.

Q(s, a) Q(s, a) + ↵(R(s) + � maxa0Q(s0, a0)�Q(s, a))
Suppose:
� = 0.8↵ = 1
1 2
3 4
5 Goal!
00
000
0
0
0
00
Q =
0
BBBBBB@
1 2 3 4 5
1 0 0 0 0 0
2 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
1
CCCCCCA
Let’s start here.
R =
0
BBBBBB@
1 2 3 4 5
1 �1 �1 0 �1 �1
2 0 �1 �1 0 100
3 0 �1 �1 0 �1
4 �1 0 0 �1 �1
5 �1 0 �1 �1 100
1
CCCCCCA
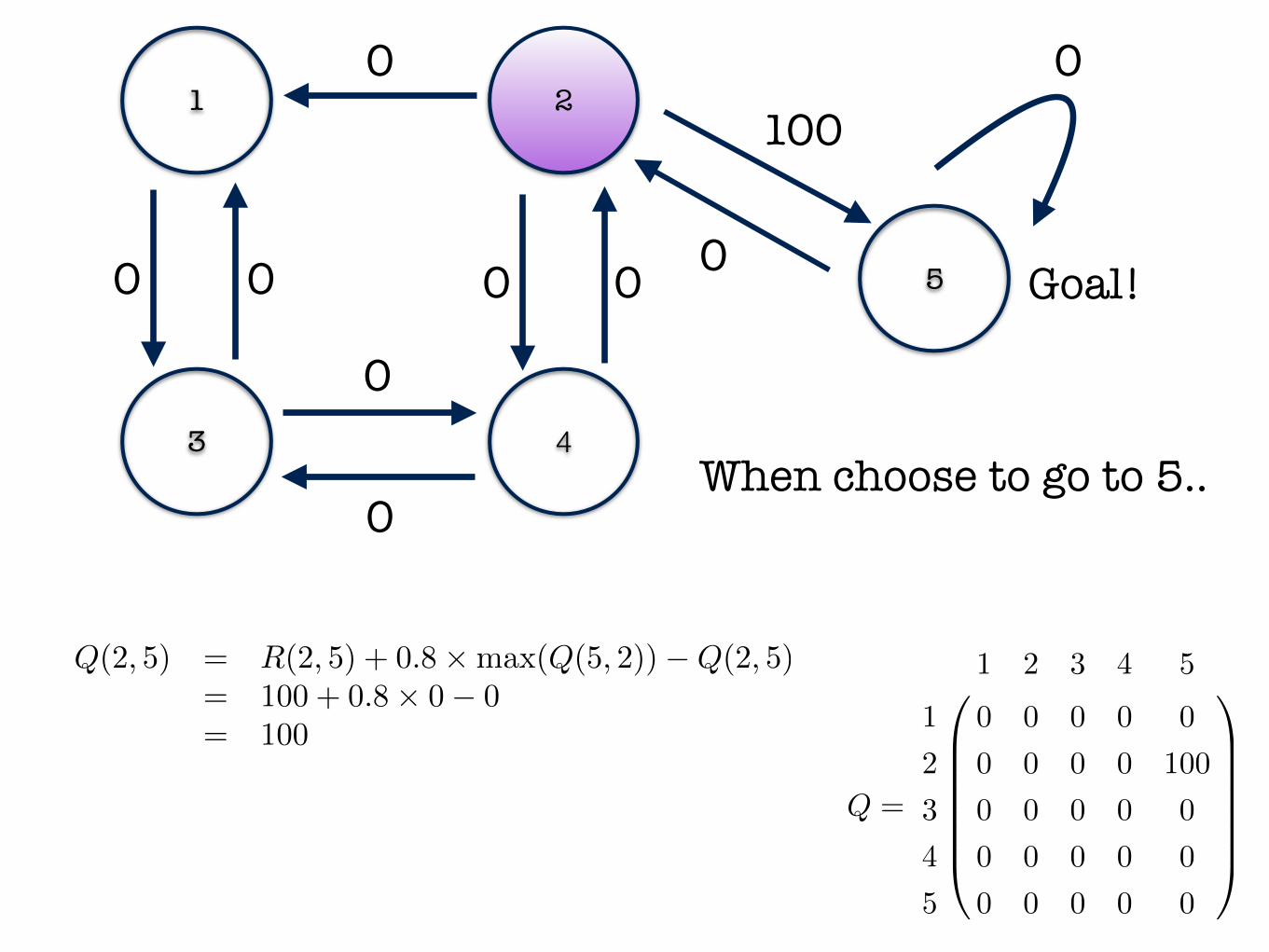
1 2
3 4
5 Goal!
1000
000
0
0
0
00
Q(2, 5) = R(2, 5) + 0.8⇥max(Q(5, 2))�Q(2, 5)= 100 + 0.8⇥ 0� 0
= 100
Q =
0
BBBBBB@
1 2 3 4 5
1 0 0 0 0 0
2 0 0 0 0 100
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
1
CCCCCCA
When choose to go to 5..
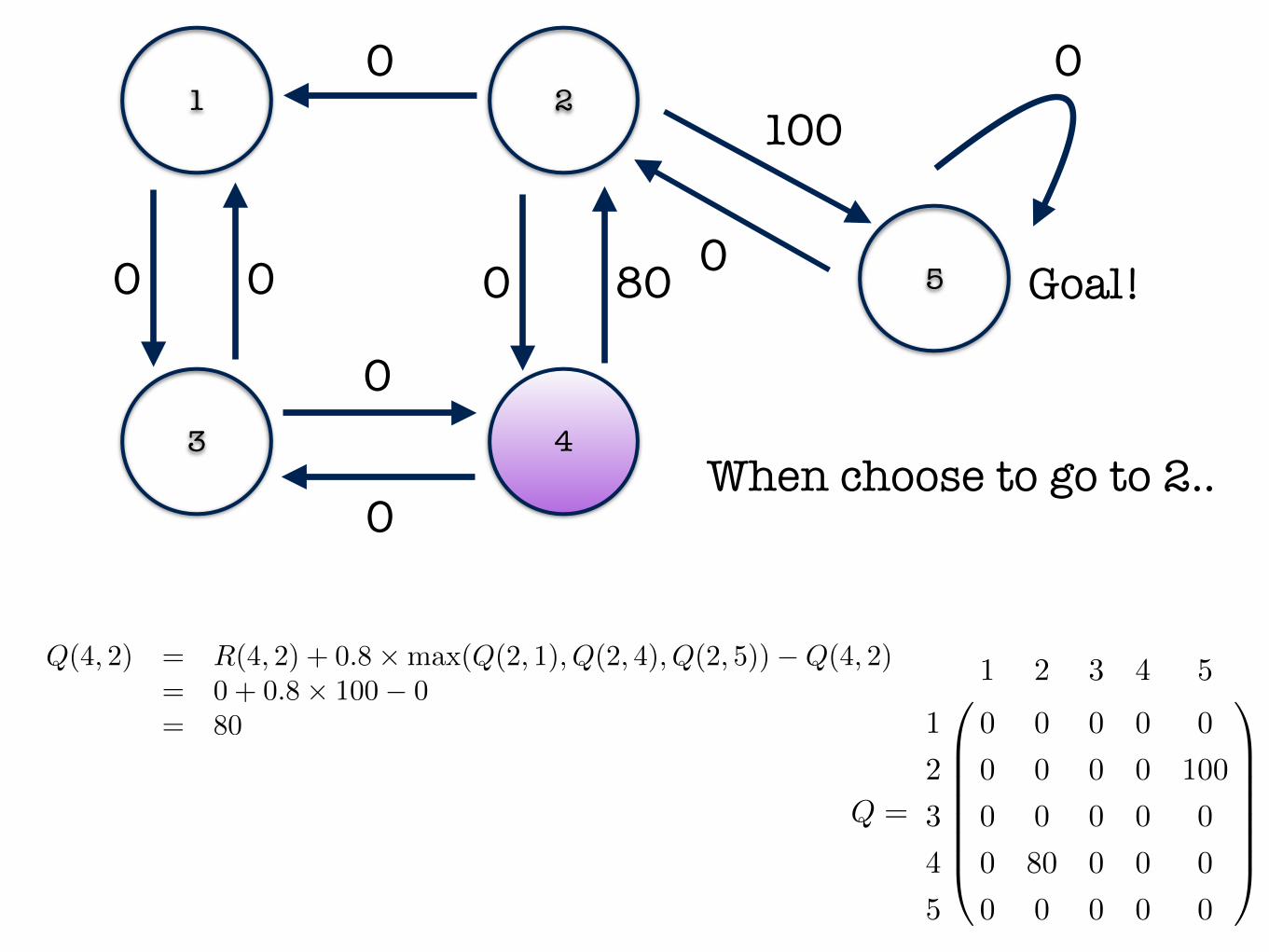
1 2
3 4
5 Goal!
1000
0800
0
0
0
00
Q(4, 2) = R(4, 2) + 0.8⇥max(Q(2, 1), Q(2, 4), Q(2, 5))�Q(4, 2)= 0 + 0.8⇥ 100� 0
= 80
Q =
0
BBBBBB@
1 2 3 4 5
1 0 0 0 0 0
2 0 0 0 0 100
3 0 0 0 0 0
4 0 80 0 0 0
5 0 0 0 0 0
1
CCCCCCA
When choose to go to 2..

1 2
3 4
5 Goal!
1000
0800
64
0
0
00
Q(3, 4) = R(3, 4) + 0.8⇥max(Q(4, 2), Q(4, 3))�Q(3, 4)= 0 + 0.8⇥ 80� 0
= 64
Q =
0
BBBBBB@
1 2 3 4 5
1 0 0 0 0 0
2 0 0 0 0 100
3 0 0 0 64 0
4 0 80 0 0 0
5 0 0 0 0 0
1
CCCCCCA
When choose to go to 4..

http://www.123rf.com/photo_8104943_hand-drawn-tic-tac-toe-game-format.html
State Space
• Board
Actions
• Move
Rewards
• +1 if A.I. wins
• -1 if A.I. loses
• 0.5 if the game’s a draw
Back to our Tic Tac Toe!

https://github.com/zkan/tictactoe/blob/master/tictactoe_rl.py

Supervised learning and unsupervised
learning?
