実験計画法入門 part 1
TRANSCRIPT

© Hajime Mizuyama
An Introduction to Design of Experiments (DOE)
青山学院大学 経営システム工学科
水山 元

© Hajime Mizuyama
Part 1
古典的な実験計画法の
基本概念と要因計画
Part 2
直交表と
一部実施要因計画
Part 3
応答曲面法と
最適計画
Part 4
直積実験と
ロバスト設計
© Hajime Mizuyama
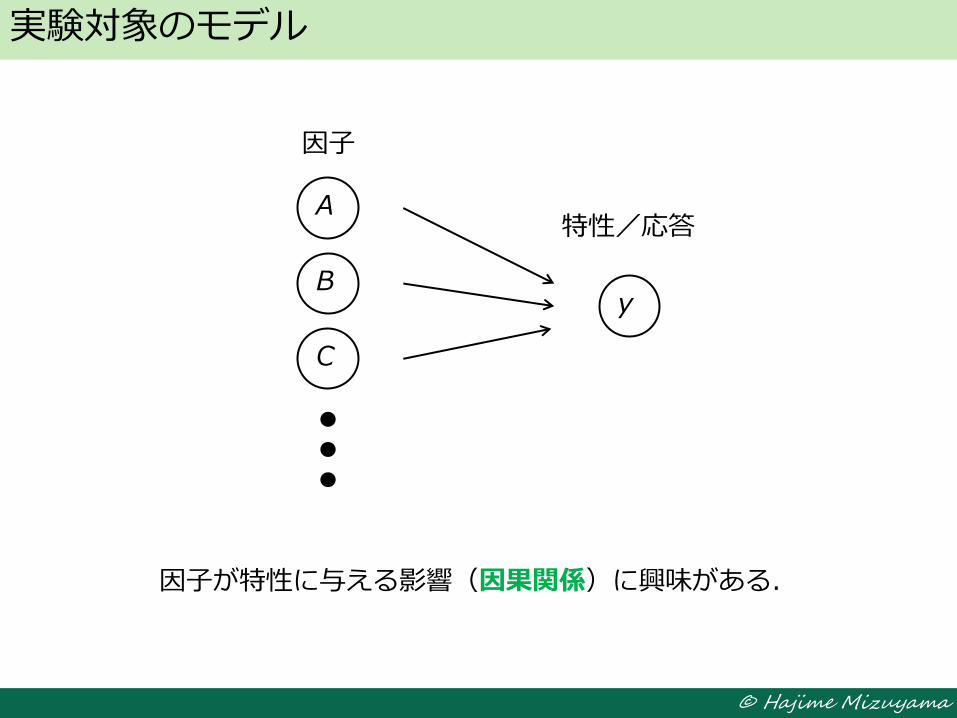
実験対象のモデル
A
y B
C
因子
特性/応答
因子が特性に与える影響(因果関係)に興味がある.

© Hajime Mizuyama
最適な水準を 見出したいもの
最適水準を決めることに 意味がないもの
母数因子 制御因子 標示因子
誤差因子
変量因子 ブロック因子
因子の分類

© Hajime Mizuyama
• 取り上げた因子が特性の値に影響を及ぼしているかどうか,を
判断したい.
• 影響を及ぼしていると判断された因子について,その値をどの
水準に設定すればよいか,を判断したい(主に特性値の最大化
や最小化の問題).
• 因子水準を操作することによる影響の大きさや,操作した後の
特性の値を推定したい.
実験の狙いと実験計画法の役割
これらを,統計的検定や推定の枠組みで実施できるようにする
ことが実験計画法の役割である.
これらを,統計的検定や推定の枠組みで実施できるようにする
ことが実験計画法の役割である.

© Hajime Mizuyama
因子の水準と処理
A
y B
C
因子
特性/応答 A1, A2, …
B1, B2, …
C1, C2, …
処理
A1, A2, …
B1, B2, …
C1, C2, …
水準
y1, y2, …
対象となる特性に影響を与える要因は無数に存在し得るため,
事前に網羅的に把握することは困難である.
また,例え把握できたとしても,実験の場でそれらを完全に
管理できるとは限らない.
対象となる特性に影響を与える要因は無数に存在し得るため,
事前に網羅的に把握することは困難である.
また,例え把握できたとしても,実験の場でそれらを完全に
管理できるとは限らない.
© Hajime Mizuyama
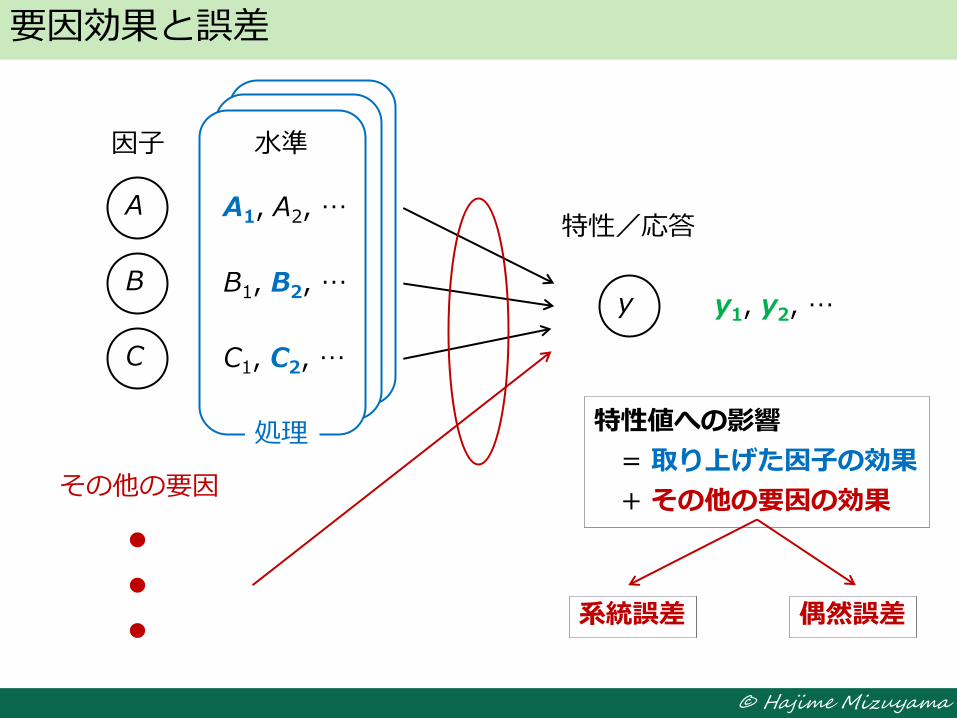
要因効果と誤差
A
y B
C
因子
特性/応答 A1, A2, …
B1, B2, …
C1, C2, …
処理
A1, A2, …
B1, B2, …
C1, C2, …
水準
y1, y2, …
その他の要因
特性値への影響
= 取り上げた因子の効果
+ その他の要因の効果
特性値への影響
= 取り上げた因子の効果
+ その他の要因の効果
系統誤差 系統誤差 偶然誤差 偶然誤差

© Hajime Mizuyama
実験計画法とは
構造モデル
(因子と特性の間の
因果関係を説明する
モデル)
iid 仮定
(誤差は独立に同一
の正規分布に従う)
構造モデル
(因子と特性の間の
因果関係を説明する
モデル)
iid 仮定
(誤差は独立に同一
の正規分布に従う)
主効果,交互作用
の検定・推定法
主に,分散分析や
線形回帰分析
実験の計画・実施
上のテクニック
基本は
Fisherの3原則

© Hajime Mizuyama
局所管理(Local control)
実験単位の集合を比較的均質な部分集合(ブロック)に分割し
て,ブロック内の偶然誤差を小さくするとともに,ブロック間
の系統誤差を取り除けるようにする.
無作為化(Randomization)
処理の実験単位への割付けをランダム化することで,残された
系統誤差を偶然誤差に転化する.
繰返し(Replication)
同じ処理を複数の実験単位に割り付けることで,偶然誤差のば
らつきの大きさを評価できるようにする.
Fisherの3原則

© Hajime Mizuyama
F分布 F分布
カイ2乗分布 カイ2乗分布
t分布 t分布
(標準)正規分布 (標準)正規分布
理解しておきたい確率分布(確率密度関数)
-3 -2 -1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
x
dn
orm
(x)
-3 -2 -1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
x
dt(
x, 4
)
0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
x
df(
x, 5
, 1
8)
0 2 4 6 8 10
0.0
00
.10
0.2
00
.30
x
dch
isq
(x, 3
)

© Hajime Mizuyama
標準正規分布とt分布
-4 -2 0
0.0
0.1
0.2
0.3
0.4
2 4
0.5
標準正規分布
サンプル数4の場合 (自由度6の t分布)
サンプル数2の場合 (自由度2の t分布)
© Hajime Mizuyama
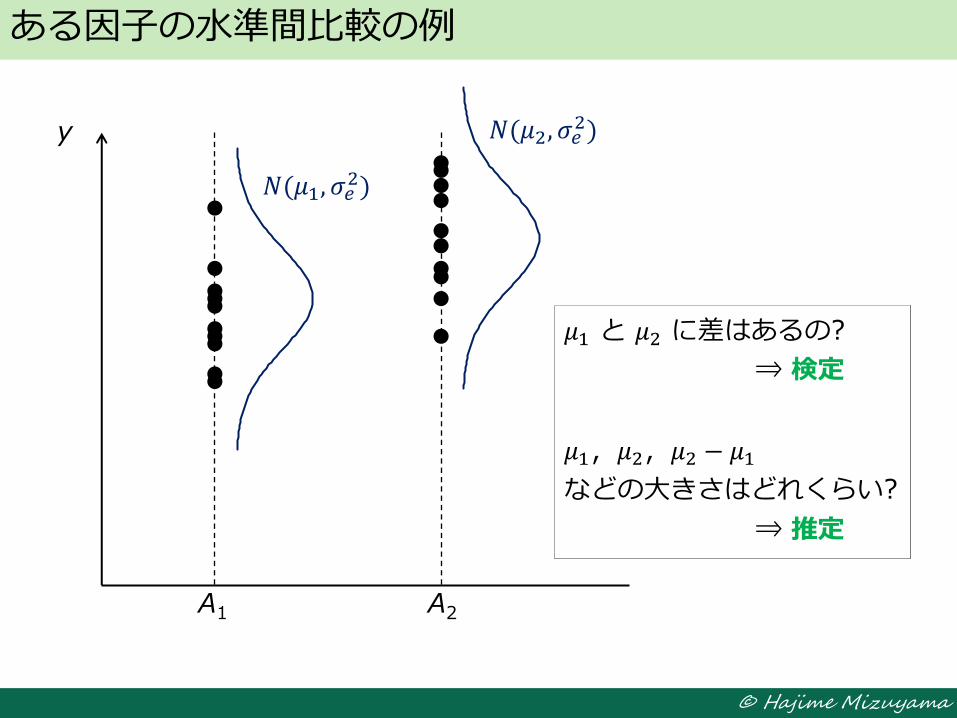
ある因子の水準間比較の例
A1 A2
y
𝑁(𝜇1, 𝜎𝑒2)
𝑁(𝜇2, 𝜎𝑒2)
𝜇1 と 𝜇2 に差はあるの?
⇒ 検定
𝜇1,𝜇2,𝜇2 − 𝜇1
などの大きさはどれくらい?
⇒ 推定
𝜇1 と 𝜇2 に差はあるの?
⇒ 検定
𝜇1,𝜇2,𝜇2 − 𝜇1
などの大きさはどれくらい?
⇒ 推定

© Hajime Mizuyama
サンプル数を 𝑛,水準Ai での標本平均を 𝑦 𝑖 とすると,
𝑦 𝑖 は 𝑁(𝜇𝑖 , 𝜎𝑒2 𝑛 ) に,𝑦 2 − 𝑦 1 は 𝑁(𝜇2 − 𝜇1, 2 𝜎𝑒
2 𝑛 ) に従うので,
母誤差分散𝝈𝒆𝟐 が既知の場合
(𝜇𝑖 − 𝑦 𝑖) 𝜎𝑒2/𝑛 や (𝑦 2 − 𝑦 1) 2𝜎𝑒
2/𝑛 は,標準正規分布に従う.
母誤差分散𝝈𝒆𝟐 が未知の場合
(𝜇𝑖 − 𝑦 𝑖) 𝑉𝑒/𝑛 や (𝑦 2 − 𝑦 1) 2𝑉𝑒/𝑛 は,自由度 𝟐𝒏 − 𝟐 の
t分布に従う.
ただし, 𝑉𝑒 = 𝑦𝑖𝑗 − 𝑦 𝑖2𝑛
𝑗=12𝑖=1 (2𝑛 − 2) は標本誤差分散である.
標本平均等の分布

© Hajime Mizuyama
帰無仮説
𝜇1 と 𝜇2 に差はない(因子A は効果を持たない)
検定統計量
(𝑦 2 − 𝑦 1) 2𝜎𝑒2/𝑛
帰無仮説が真の場合の検定統計量の分布(標準正規分布)
検定の考え方(母誤差分散𝜎𝑒2 が既知の場合)
-3 -2 -1 0 1 2 3
帰無仮説の下で 生じやすい値
⇒ 仮説を保持
帰無仮説の下では 生じにくい値
⇒ 仮説を棄却

© Hajime Mizuyama
帰無仮説
𝜇1 と 𝜇2 に差はない(因子A は効果を持たない)
検定統計量
(𝑦 2 − 𝑦 1) 2𝑉𝑒/𝑛
帰無仮説が真の場合の検定統計量の分布(t分布)
検定の考え方(母誤差分散𝜎𝑒2 が未知の場合)
-3 -2 -1 0 1 2 3
帰無仮説の下で 生じやすい値
⇒ 仮説を保持
帰無仮説の下では 生じにくい値
⇒ 仮説を棄却

© Hajime Mizuyama
推定したい母数
𝜇2 − 𝜇1
対応する統計量
Δ𝑦 = 𝑦 2 − 𝑦 1
母数と統計量の差の分布(正規分布)
推定の考え方(母誤差分散𝜎𝑒2 が既知の場合)
−3 2/𝑛𝜎𝑒 −2 2/𝑛𝜎𝑒 − 2/𝑛𝜎𝑒 + 2/𝑛𝜎𝑒 +2 2/𝑛𝜎𝑒 +3 2/𝑛𝜎𝑒
区間推定(95%)
0

© Hajime Mizuyama
推定したい母数
𝜇2 − 𝜇1
対応する統計量
Δ𝑦 = 𝑦 2 − 𝑦 1
母数と統計量の差の分布(横軸の縮尺を変えた t分布)
推定の考え方(母誤差分散𝜎𝑒2 が未知の場合)
−3 2𝑉𝑒/𝑛 −2 2𝑉𝑒/𝑛 − 2𝑉𝑒/𝑛
区間推定(95%)
+ 2𝑉𝑒/𝑛 +2 2𝑉𝑒/𝑛 +3 2𝑉𝑒/𝑛 0

© Hajime Mizuyama
• いくつかの因子を取り上げて,それらの因子の水準のすべての
組合せにおいて,それぞれ1回以上実験を実施する形式の計画を
要因計画と呼ぶ.
• 取り上げる因子が一つの場合を一元配置,二つの場合を二元配
置,三つ以上の場合を多元配置などと呼ぶこともある.
• 取り上げた因子の水準の組合せの(すべてではなく)一部にお
いてのみ実験を行う形式の計画を一部実施要因計画と呼ぶ.
• 直交表は,一部実施要因計画を作成するためのツールである.
要因計画と一部実施要因計画

© Hajime Mizuyama
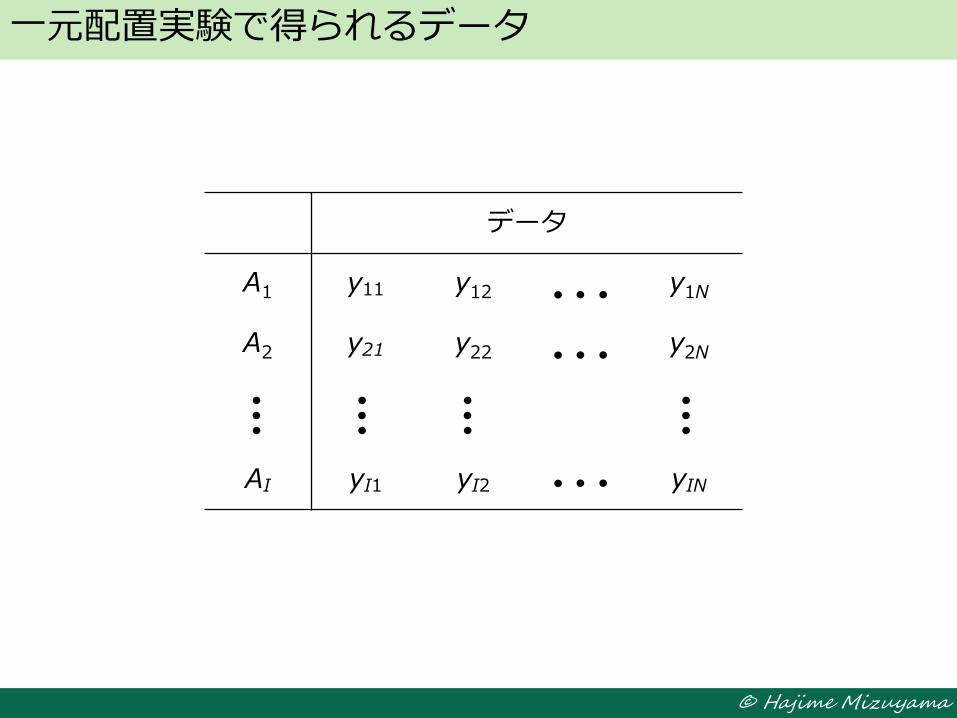
一元配置実験では,
特性に影響を及ぼし得る要因として,ある一つの因子A のみを
取り上げ,その因子について I 個の水準:
A1, A2, ..., AI
を選び,それぞれのもとで N 回ずつ,合計 I×N 回の実験を,
ランダムな順序で行う.
一元配置実験
© Hajime Mizuyama
一元配置実験で得られるデータ
データ
A1 y11 y12 y1N
A2 y21 y22 y2N
AI yI1 yI2 yIN

© Hajime Mizuyama
構造モデル
𝑦𝑖𝑛 = 𝜇 + 𝑎𝑖 + 𝑒𝑖𝑛
仮定
– 主効果の総和はゼロである(𝑎1 + 𝑎2 + ⋯+ 𝑎𝐼 = 0).
– 誤差項は互いに独立かつ等分散である.
– 誤差項は期待値ゼロの正規分布に従う.
一元配置の構造モデル
一般平均 因子A の主効果 誤差項
𝒆~𝑁(𝟎, 𝜎𝑒2 ∙ 𝑰)

© Hajime Mizuyama
因子水準ごとの平均
データ 平均
A1 y11 y12 y1N
A2 y21 y22 y2N
AI yI1 yI2 yIN
𝑦 1 = 𝜇 + 𝑎1 +1
𝑁 𝑒1𝑛
𝑁
𝑛=1
𝑦 2 = 𝜇 + 𝑎2 +1
𝑁 𝑒2𝑛
𝑁
𝑛=1
𝑦 𝐼 = 𝜇 + 𝑎𝐼 +1
𝑁 𝑒𝐼𝑛
𝑁
𝑛=1
𝑦 = 𝜇 +1
𝐼𝑁 𝑒𝑖𝑛
𝑁
𝑛=1
𝐼
𝑖=1 𝑦𝑖𝑛 = 𝜇 + 𝑎𝑖 + 𝑒𝑖𝑛

© Hajime Mizuyama
データの総偏差平方和
平方和とその分解
残差平方和 Se
A間平方和 SA
= 0
𝑆𝑇 = 𝑦𝑖𝑛 − 𝑦 2
𝑁
𝑛=1
=
𝐼
𝑖=1
𝑦𝑖𝑛 − 𝑦 𝑖 + 𝑦 𝑖 − 𝑦 2
𝑁
𝑛=1
𝐼
𝑖=1
= 𝑦𝑖𝑛 − 𝑦 𝑖2
𝑁
𝑛=1
+
𝐼
𝑖=1
2 (𝑦𝑖𝑛 − 𝑦 𝑖)(𝑦 𝑖 − 𝑦 )
𝑁
𝑛=1
𝐼
𝑖=1
+ 𝑁 𝑦 𝑖 − 𝑦 2
𝐼
𝑖=1
Se の期待値
𝐸 𝑆𝑒 = 𝐼 𝑁 − 1 𝜎𝑒
2
SA の期待値
𝐸 𝑆𝐴 = 𝑁 𝑎𝑖2
𝐼
𝑖=1
+ 𝐼 − 1 𝜎𝑒2

© Hajime Mizuyama
データの平方和の分解(射影としての理解)
INy
y
y
12
11
y
yy
yy
yy
IN
12
11
y
y
y
yy
yy
yy
I
1
1
IIN yy
yy
yy
112
111
データベクトル
(IN次元)
平方和は,各ベクトルの
ノルムの2乗
平方和は,各ベクトルの
ノルムの2乗 v方向への射影
(1次元)
その直交補空間 への射影
(IN-1次元)
その直交補空間 への射影
(I(N-1)次元)
v1, v2, …, vIで張られ vと直交な部分空間
への射影
(I-1次元)
T
INININ
1,,1,1 v
T
iNN
0,,0,1,,1,0,,0 v
i番目のN個

© Hajime Mizuyama
残差平方和の期待値
2
22
1
1
11
2
1
2
1
1 1
2
)1(
11
e
ee
I
i
T
ii
I
i
T
ii
T
I
i
T
ii
TI
i
T
ii
T
I
i
T
ii
I
i
T
ii
I
i
N
n
iine
NI
NINtr
E
E
EE
yyESE
vvI
evvIe
evvIvvIe
evvIyvvI

© Hajime Mizuyama
A間平方和の期待値
2
1
2
2
1
2
2
11
2
111
2
2
11
2
2
11
2
)1(
11
e
I
i
i
e
I
i
i
e
TI
i
T
ii
I
i
i
TI
i
T
ii
T
TI
i
T
ii
TI
i
i
TI
i
T
ii
I
i
i
TI
i
T
ii
I
i
iA
IaN
INNINaN
traN
EaN
EaN
EyyNESE
vvvv
evvvvvvvve
evvvv
yvvvv

© Hajime Mizuyama
データの平方和の分解(射影としての理解)
INe
e
e
12
11
y
ee
ee
ee
IN
12
11
e
e
e
ee
ee
ee
I
1
1
IIN ee
ee
ee
112
111
データベクトル
(IN次元)
帰無仮説:因子A は主効果
を持たない,が真ならば?
帰無仮説:因子A は主効果
を持たない,が真ならば? v方向への射影
(1次元)
その直交補空間 への射影
(IN-1次元)
その直交補空間 への射影
(I(N-1)次元)
v1, v2, …, vIで張られ vと直交な部分空間
への射影
(I-1次元)
T
INININ
1,,1,1 v
T
iNN
0,,0,1,,1,0,,0 v
i番目のN個

© Hajime Mizuyama
誤差の平方和の分解(射影としての理解)
ee
ee
ee
IN
12
11
ee
ee
ee
I
1
1
IIN ee
ee
ee
112
111
誤差ベクトル
(IN次元)
誤差ベクトルのノルムの2乗を𝜎𝑒2
で割った値はカイ2乗分布に従う.
誤差ベクトルのノルムの2乗を𝜎𝑒2
で割った値はカイ2乗分布に従う. v方向への射影
(1次元)
その直交補空間 への射影
(IN-1次元)
その直交補空間 への射影
(I(N-1)次元)
v1, v2, …, vIで張られ vと直交な部分空間
への射影
(I-1次元)
e
e
e
INe
e
e
12
11
e
T
INININ
1,,1,1 v
T
iNN
0,,0,1,,1,0,,0 v
i番目のN個

© Hajime Mizuyama
分散分析表
要因 平方和 自由度 平均平方 F値
A SA fA = I-1 VA = SA /(I-1) FA = VA /Ve
残差 Se fe = I(N-1) Ve = Se /I(N-1) ―
計 ST IN-1 ― ―
帰無仮説:因子A は主効果を持たない.
0 1 2 3 4 5
帰無仮説が 真の場合の FA の分布
自由度 fA, fe のF分布
帰無仮説の下で 生じやすい値
⇒ 仮説を保持
帰無仮説の下では 生じにくい値
⇒ 仮説を棄却

© Hajime Mizuyama
母平均に関する推定
A1 A2 Ai 因子水準
特性値
母平均 (𝜇 + 𝑎𝑖)の区間推定
二つの母平均の差の区間推定
1y
2y
母平均の点推定 𝑦 𝑖 − 𝑦 j ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
2𝑉𝑒𝑁
𝑦 𝑖 ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
𝑉𝑒𝑁
© Hajime Mizuyama
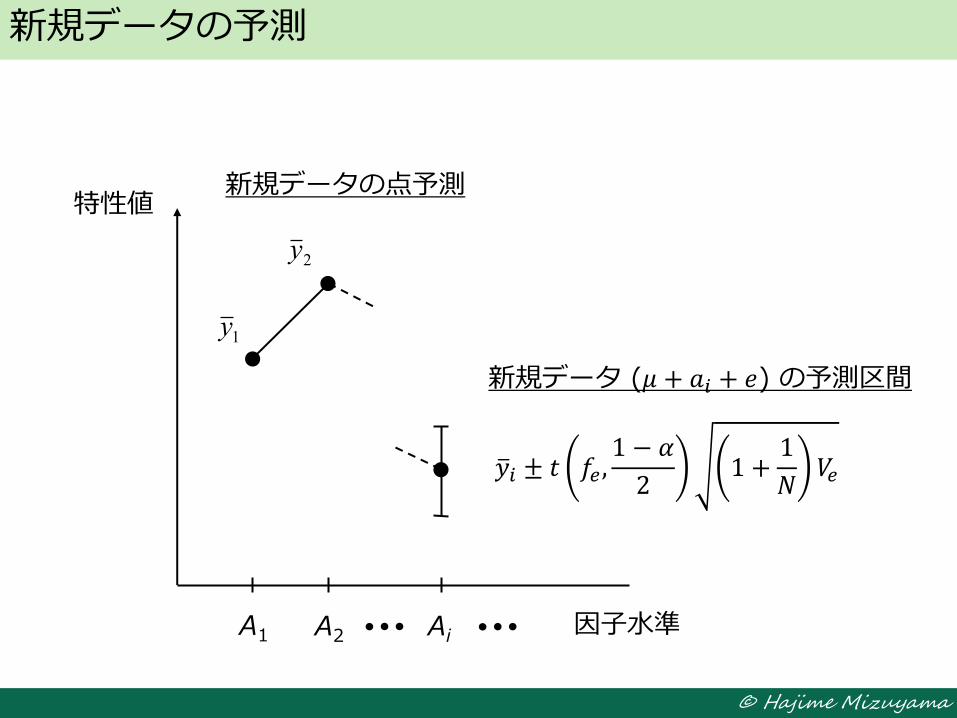
新規データの予測
A1 A2 Ai 因子水準
特性値
新規データ (𝜇 + 𝑎𝑖 + 𝑒) の予測区間
新規データの点予測
1y
2y
𝑦 𝑖 ± 𝑡 𝑓𝑒 ,1 − 𝛼
21 +
1
𝑁𝑉𝑒

© Hajime Mizuyama
繰返しのある二元配置実験では,
特性に影響を及ぼし得る要因として,ある二つの因子A と B を
取り上げ,それらの因子について I 個と J 個の水準:
A1, A2, ..., AI / B1, B2, ..., BJ
を選び,すべての水準の組合せのもとで N 回ずつ,合計
I×J×N 回の実験を,ランダムな順序で行う.
繰返しのある二元配置実験

© Hajime Mizuyama
繰返しのある二元配置実験で得られるデータ
B1 B2 BJ
A1 y111, …, y11N y121, …, y12N y1J1, …, y1JN
A2 y211, …, y21N y221, …, y22N y2J1, …, y2JN
AI yI11, …, yI1N yI21, …, yI2N yIJ1, …, yIJN

© Hajime Mizuyama
構造モデル
𝑦𝑖𝑗𝑛 = 𝜇 + 𝑎𝑖 + 𝑏𝑗 + 𝑎𝑏 𝑖𝑗 + 𝑒𝑖𝑗𝑛
仮定
– 主効果,交互作用はそれぞれ総和がゼロになる:
– 誤差項は独立,等分散で期待値ゼロの正規分布に従う:
繰返しのある二元配置の構造モデル
一般平均 因子A 因子B A×B 誤差項 主効果 主効果 交互作用
𝒆~𝑁(𝟎, 𝜎𝑒2 ∙ 𝑰)
𝑎𝑖
𝐼
𝑖=1
= 𝑏𝑗
𝐽
𝑗=1
= (𝑎𝑏)𝑖𝑗
𝐼
𝑖=1
= (𝑎𝑏)𝑖𝑗
𝐽
𝑗=1
= 0

© Hajime Mizuyama
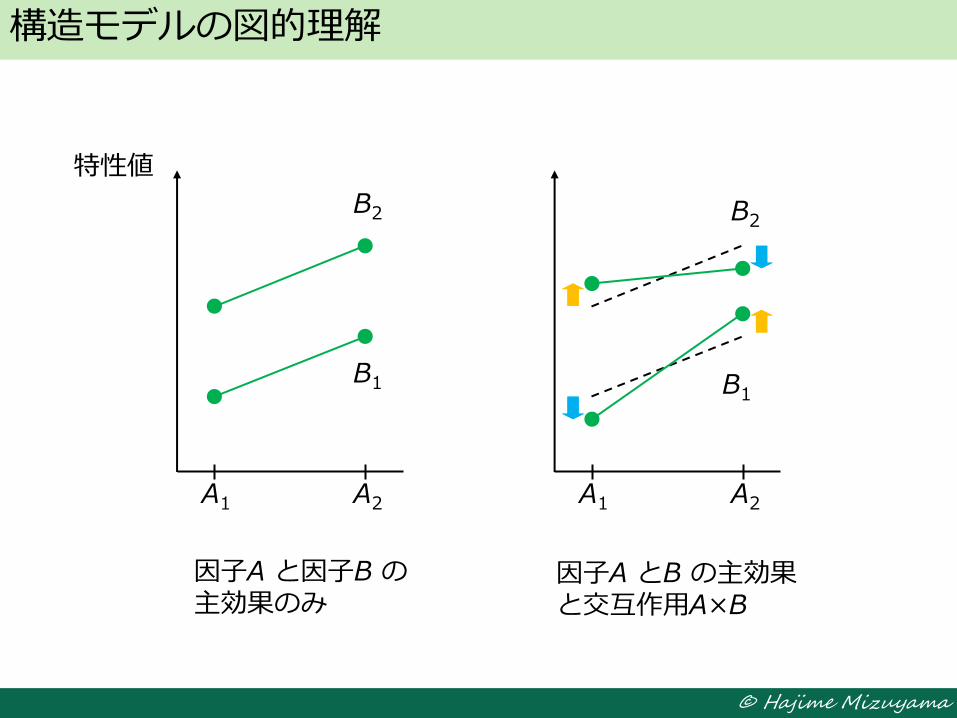
構造モデルの図的理解
A1 A2
特性値
因子A の主効果
A1 A2
因子B の主効果
B2
B1
© Hajime Mizuyama
構造モデルの図的理解
特性値
A1 A2
B2
因子A と因子B の 主効果のみ
B1
A1 A2
B2
因子A とB の主効果 と交互作用A×B
B1

© Hajime Mizuyama
データの平均と誤差項の分散
B1 Bj BJ
A1 y111, …, y11N y1j1, …, y1jN y1J1, …, y1JN
Ai yi11, …, yi1N yij1, …, yijN yiJ1, …, yiJN
AI yI11, …, yI1N yIj1, …, yIjN yIJ1, …, yIJN
(誤差項の分散は 𝜎𝑒2/𝑁) 𝑦 𝑖𝑗 = 𝜇 + 𝑎𝑖 + 𝑏𝑗 + 𝑎𝑏 𝑖𝑗 +
1
𝑁 𝑒𝑖𝑗𝑛
𝑁
𝑛=1

© Hajime Mizuyama
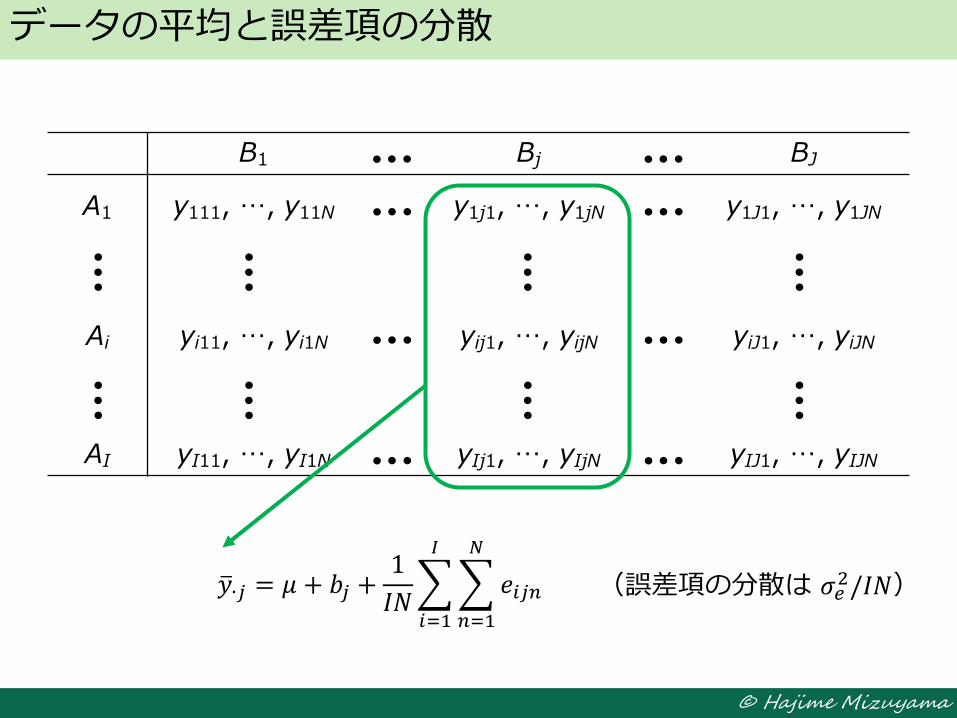
データの平均と誤差項の分散
B1 Bj BJ
A1 y111, …, y11N y1j1, …, y1jN y1J1, …, y1JN
Ai yi11, …, yi1N yij1, …, yijN yiJ1, …, yiJN
AI yI11, …, yI1N yIj1, …, yIjN yIJ1, …, yIJN
(誤差項の分散は 𝜎𝑒2/𝐽𝑁) 𝑦 𝑖∙ = 𝜇 + 𝑎𝑖 +
1
𝐽𝑁 𝑒𝑖𝑗𝑛
𝑁
𝑛=1
𝐽
𝑗=1
© Hajime Mizuyama
データの平均と誤差項の分散
B1 Bj BJ
A1 y111, …, y11N y1j1, …, y1jN y1J1, …, y1JN
Ai yi11, …, yi1N yij1, …, yijN yiJ1, …, yiJN
AI yI11, …, yI1N yIj1, …, yIjN yIJ1, …, yIJN
(誤差項の分散は 𝜎𝑒2/𝐼𝑁) 𝑦 ∙𝑗 = 𝜇 + 𝑏𝑗 +
1
𝐼𝑁 𝑒𝑖𝑗𝑛
𝑁
𝑛=1
𝐼
𝑖=1

© Hajime Mizuyama
データの平均と誤差項の分散
B1 Bj BJ
A1 y111, …, y11N y1j1, …, y1jN y1J1, …, y1JN
Ai yi11, …, yi1N yij1, …, yijN yiJ1, …, yiJN
AI yI11, …, yI1N yIj1, …, yIjN yIJ1, …, yIJN
(誤差項の分散は 𝜎𝑒2/𝐼𝐽𝑁) 𝑦 = 𝜇 +
1
𝐼𝐽𝑁 𝑒𝑖𝑗𝑛
𝑁
𝑛=1
𝐽
𝑗=1
𝐼
𝑖=1

© Hajime Mizuyama
データの総偏差平方和
平方和の分解
残差平方和:Se AB間平方和:SAB
𝑆𝑇 = 𝑦𝑖𝑗𝑛 − 𝑦 𝑖𝑗2
𝑁
𝑛=1
𝐽
𝑗=1
+
𝐼
𝑖=1
𝑁 𝑦 𝑖𝑗 − 𝑦 2
𝐽
𝑗=1
𝐼
𝑖=1
A間平方和:SA B間平方和:SB A×B間平方和:SA×B
𝑆𝐴𝐵 = 𝐽𝑁 𝑦 𝑖∙ − 𝑦 2
𝐼
𝑖=1
+ 𝐼𝑁 𝑦 ∙𝑗 − 𝑦 2+ 𝑁 𝑦 𝑖𝑗 − 𝑦 𝑖∙ − 𝑦 ∙𝑗 + 𝑦
2𝐽
𝑗=1
𝐼
𝑖=1
𝐽
𝑗=1
𝐸 𝑆𝐴 = 𝐽𝑁 𝑎𝑖2
𝐼
𝑖=1
+ 𝐼 − 1 𝜎𝑒2
𝐸 𝑆𝐵 = 𝐼𝑁 𝑏𝑗2
𝐽
𝑗=1
+ 𝐽 − 1 𝜎𝑒2
𝐸 𝑆𝐴×𝐵 = 𝑁 𝑎𝑏 𝑖𝑗2
𝐽
𝑗=1
𝐼
𝑖=1
+ (𝐼 − 1) 𝐽 − 1 𝜎𝑒2

© Hajime Mizuyama
分散分析による要因効果の検定
要因 平方和 自由度 平均平方 F値
A SA fA = I-1 VA = SA /fA FA = VA /Ve
B SB fB = J-1 VB = SB /fB FB = VB /Ve
A×B SA×B
fA×B =
(I-1)(J-1) VA×B = SA×B /fA×B FA×B = VA×B /Ve
残差 Se fe = IJ(N-1) Ve = Se /fe ―
計 ST IJN-1 ― ―

© Hajime Mizuyama
どちらか一方の因子(仮に A)の主効果のみ有意の場合
どちらの因子の主効果も有意だが交互作用は有意でない場合
交互作用が有意な場合
母平均の区間推定
𝑦 𝑖∙ ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
𝑉𝑒𝐽𝑁
𝑦 𝑖𝑗 ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
𝑉𝑒𝑁
𝑦 𝑖∙ + 𝑦 ∙𝑗 − 𝑦 ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
(𝐼 + 𝐽 − 1)𝑉𝑒𝐼𝐽𝑁

© Hajime Mizuyama
双方の主効果のみ有意な場合
B1 Bj BJ
A1 y111, …, y11N y1j1, …, y1jN y1J1, …, y1JN
Ai yi11, …, yi1N yij1, …, yijN yiJ1, …, yiJN
AI yI11, …, yI1N yIj1, …, yIjN yIJ1, …, yIJN
+ -

© Hajime Mizuyama
双方の主効果のみ有意な場合
B1 Bj BJ
A1 -1 / IJN (J-1) / IJN -1 / IJN
Ai (I-1) / IJN (I+J-1) / IJN (I-1) / IJN
AI -1 / IJN (J-1) / IJN -1 / IJN
1/𝑛𝑒 = 𝐼𝐽𝑁 − 𝐼𝑁 − 𝐽𝑁 + 𝑁−1
𝐼𝐽𝑁
2
+ 𝐼𝑁 − 𝑁𝐽 − 1
𝐼𝐽𝑁
2
+ 𝐽𝑁 − 𝑁𝐼 − 1
𝐼𝐽𝑁
2
+ 𝑁𝐼 + 𝐽 − 1
𝐼𝐽𝑁
2
=𝐼 + 𝐽 − 1
𝐼𝐽𝑁
+ -
の誤差分散を
𝜎𝑒2/𝑛𝑒
とおくと

© Hajime Mizuyama
有効反復数
– 母平均の区間推定の際に用いる 𝑛𝑒 の値
有効反復数の算出ルール
– 田口のルール:
– 伊奈のルール:
母平均の区間推定における有効反復数
1
𝑛𝑒=
1 + (推定に用いた要因の自由度の和)
全データ数=
1 + (𝐼 − 1) + (𝐽 − 1)
𝐼𝐽𝑁
1
𝑛𝑒= 点推定に用いられている平均の係数の和 =
1
𝐽𝑁+
1
𝐼𝑁−
1
𝐼𝐽𝑁

© Hajime Mizuyama
繰返しのない二元配置実験では,
特性に影響を及ぼし得る要因として,ある二つの因子A と B を
取り上げ,それらの因子について I 個と J 個の水準:
A1, A2, ..., AI / B1, B2, ..., BJ
を選び,すべての水準の組合せのもとで1回ずつ,合計 I×J 回
の実験を,ランダムな順序で行う.
繰返しのない二元配置実験

© Hajime Mizuyama
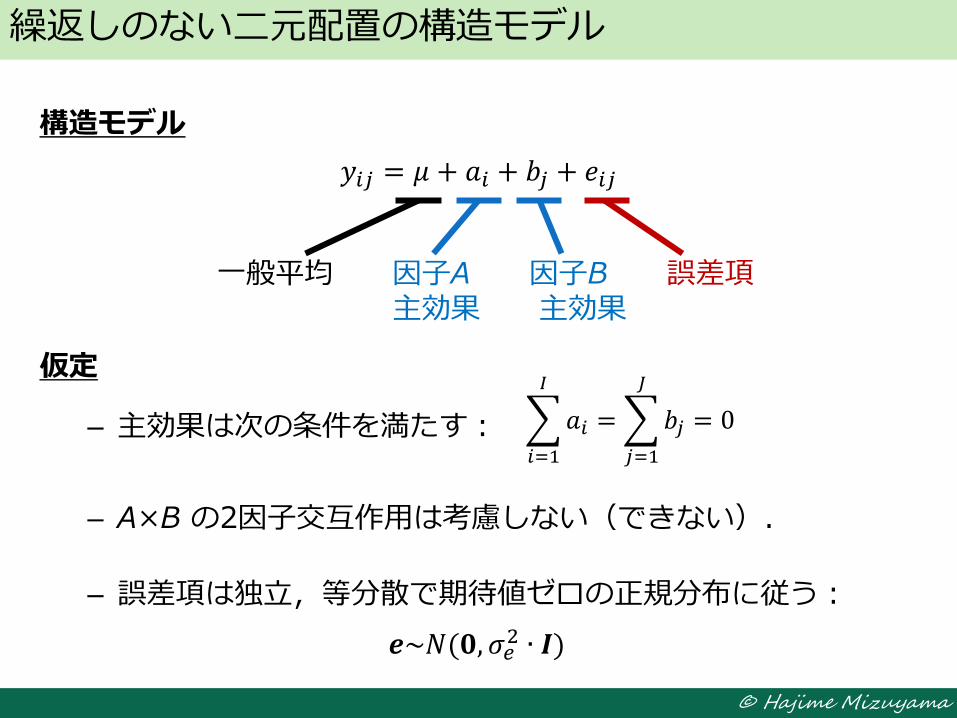
繰返しのない二元配置実験のデータ
B1 B2 BJ
A1 y11 y12 y1J
A2 y21 y22 y2J
AI yI1 yI2 yIJ
© Hajime Mizuyama
構造モデル
𝑦𝑖𝑗 = 𝜇 + 𝑎𝑖 + 𝑏𝑗 + 𝑒𝑖𝑗
仮定
– 主効果は次の条件を満たす:
– A×B の2因子交互作用は考慮しない(できない).
– 誤差項は独立,等分散で期待値ゼロの正規分布に従う:
繰返しのない二元配置の構造モデル
一般平均 因子A 因子B 誤差項 主効果 主効果
𝒆~𝑁(𝟎, 𝜎𝑒2 ∙ 𝑰)
𝑎𝑖
𝐼
𝑖=1
= 𝑏𝑗
𝐽
𝑗=1
= 0

© Hajime Mizuyama
データの総偏差平方和
平方和の分解
A間平方和:SA B間平方和:SB 残差平方和:Se
𝑆𝑇 = 𝑆𝐴𝐵 = 𝐽 𝑦 𝑖∙ − 𝑦 2
𝐼
𝑖=1
+ 𝐼 𝑦 ∙𝑗 − 𝑦 2+ 𝑦𝑖𝑗 − 𝑦 𝑖∙ − 𝑦 ∙𝑗 + 𝑦
2𝐽
𝑗=1
𝐼
𝑖=1
𝐽
𝑗=1
𝐸 𝑆𝐴 = 𝐽 𝑎𝑖2
𝐼
𝑖=1
+ 𝐼 − 1 𝜎𝑒2 𝐸 𝑆𝐵 = 𝐼 𝑏𝑗
2
𝐽
𝑗=1
+ 𝐽 − 1 𝜎𝑒2
𝐸 𝑆𝑒 = (𝐼 − 1) 𝐽 − 1 𝜎𝑒2

© Hajime Mizuyama
繰返しのない二元配置の分散分析
要因 平方和 自由度 平均平方 F値
A SA fA = I-1 VA = SA /fA FA = VA /Ve
B SB fB = J-1 VB = SB /fB FB = VB /Ve
残差 Se
fe =
(I-1)(J-1) Ve = Se /fe ―
計 ST IJ-1 ― ―
交互作用A×B が存在しないことが技術的に分かっている
場合に用いることがある.

© Hajime Mizuyama
どちらか一方の因子(仮に A)の主効果のみ有意の場合
どちらの因子の主効果も有意だが交互作用は有意でない場合
母平均の区間推定
𝑦 𝑖∙ ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
𝑉𝑒𝐽
𝑦 𝑖∙ + 𝑦 ∙𝑗 − 𝑦 ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
(𝐼 + 𝐽 − 1)𝑉𝑒𝐼𝐽

© Hajime Mizuyama
三元配置実験では,
特性に影響を及ぼし得る要因として,ある三つの因子A,B,C
を取り上げ,それらの因子について I,J,K 個の水準:
A1, A2, ..., AI / B1, B2, ..., BJ / C1, C2, ..., CK
を選び,すべての水準の組合せのもとで N 回ずつ,合計
I×J×K×N 回の実験を,ランダムな順序で行う(繰返しなしの
場合は N=1) .
多元配置実験(三元配置の例)

© Hajime Mizuyama
構造モデル
𝑦𝑖𝑗𝑘𝑛 = 𝜇 + 𝑎𝑖 + 𝑏𝑗 + 𝑐𝑘 + 𝑎𝑏 𝑖𝑗 + 𝑏𝑐 𝑗𝑘 + 𝑐𝑎 𝑘𝑖 + 𝑒𝑖𝑗𝑘𝑛
仮定
– 3因子以上の交互作用は考慮しない(誤差に含める)ことが
多い.
– 主効果,交互作用はそれぞれ総和がゼロになる.
– 誤差項は独立,等分散で期待値ゼロの正規分布に従う.
多元配置の構造モデル(三元配置の例)
一般平均 主効果 交互作用 誤差項

© Hajime Mizuyama
乱塊法とは
局所管理のために実験単位の集合を,ブロックと呼ばれるいく
つかの部分集合に分割して行う実験方法
ブロック因子
ブロックの区別を示す因子で,変量因子として扱う.ブロック
因子と他の因子の間の交互作用は考えない(誤差に含める).
1因子の場合の例(日がブロック因子)
乱塊法
1日目 2日目 3日目
完全無作為化 A2, A3, A3 A1, A1, A2 A1, A3, A2
乱 塊 法 A3, A1, A2 A1, A3, A2 A1, A2, A3
© Hajime Mizuyama
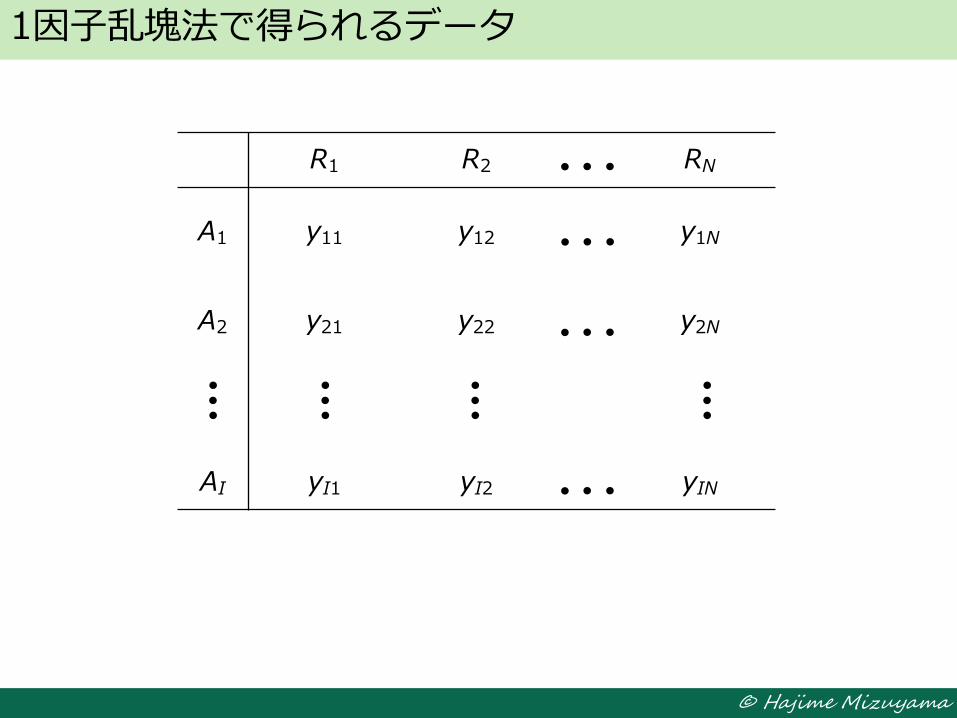
1因子乱塊法で得られるデータ
R1 R2 RN
A1 y11 y12 y1N
A2 y21 y22 y2N
AI yI1 yI2 yIN

© Hajime Mizuyama
構造モデル
𝑦𝑖𝑛 = 𝜇 + 𝑎𝑖 + 𝑟𝑛 + 𝑒𝑖𝑛
仮定
– 主効果は次の条件を満たす: ,
– ブロック因子と他の因子の間の交互作用は考慮しない.
– 誤差項は独立,等分散で期待値ゼロの正規分布に従う:
1因子乱塊法の構造モデル
一般平均 因子A ブロック因子R 誤差項 主効果 主効果
𝒆~𝑁(𝟎, 𝜎𝑒2 ∙ 𝑰)
𝒓~𝑁(𝟎, 𝜎𝑅2 ∙ 𝑰) 𝑎𝑖
𝐼
𝑖=1
= 0

© Hajime Mizuyama
データの総偏差平方和
平方和の分解
A間平方和:SA R間平方和:SR 残差平方和:Se
𝑆𝑇 = 𝑆𝐴𝑅 = 𝑁 𝑦 𝑖∙ − 𝑦 2
𝐼
𝑖=1
+ 𝐼 𝑦 ∙𝑛 − 𝑦 2 + 𝑦𝑖𝑛 − 𝑦 𝑖∙ − 𝑦 ∙𝑛 + 𝑦 2
𝑁
𝑛=1
𝐼
𝑖=1
𝑁
𝑛=1
𝐸 𝑆𝐴 = 𝑁 𝑎𝑖2
𝐼
𝑖=1
+ 𝐼 − 1 𝜎𝑒2 𝐸 𝑆𝑅 = 𝐼 𝑁 − 1 𝜎𝑅
2 + 𝑁 − 1 𝜎𝑒2
𝐸 𝑆𝑒 = (𝐼 − 1) 𝐽 − 1 𝜎𝑒2

© Hajime Mizuyama
1因子乱塊法の分散分析
要因 平方和 自由度 平均平方 F値
A SA fA = I-1 VA = SA /fA FA = VA /Ve
R SR fR = N-1 VR = SR /fR FR = VR /Ve
残差 Se
fe =
(I-1)(N-1) Ve = Se /fe ―
計 ST IN-1 ― ―
1因子乱塊法の分散分析表の構造は,繰返しのない二元配置と 同じになる.

© Hajime Mizuyama
ブロック因子の効果が無視できる場合
ブロックを単なる繰返しとみて,一元配置として扱えばよい.
ブロック因子の効果が無視できない場合
ブロック因子は変量因子であるため,その影響を,誤差変動に
加えて考える.
誤差項の影響:
ブロック因子の影響:
1因子乱塊法の分散分析後の手続き
𝜎𝑒2 ← 𝜎 𝑒
2 = 𝑉𝑒
𝜎𝑅2 ← 𝜎 𝑅
2 =𝑉𝑅 − 𝑉𝑒
𝐼
© Hajime Mizuyama
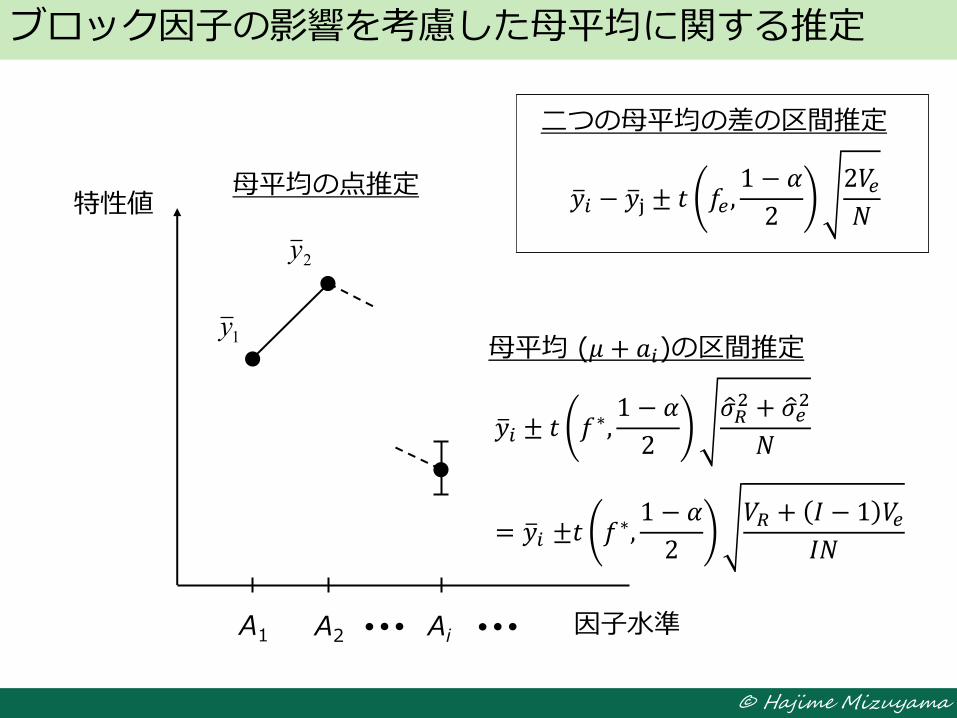
ブロック因子の影響を考慮した母平均に関する推定
A1 A2 Ai 因子水準
特性値
1y
2y
二つの母平均の差の区間推定
母平均の点推定
母平均 (𝜇 + 𝑎𝑖)の区間推定
𝑦 𝑖 − 𝑦 j ± 𝑡 𝑓𝑒 ,1 − 𝛼
2
2𝑉𝑒𝑁
𝑦 𝑖 ± 𝑡 𝑓∗,1 − 𝛼
2
𝜎 𝑅2 + 𝜎 𝑒
2
𝑁
= 𝑦 𝑖 ±𝑡 𝑓∗,1 − 𝛼
2
𝑉𝑅 + 𝐼 − 1 𝑉𝑒𝐼𝑁

© Hajime Mizuyama
ブロック因子の影響を考慮した新規データの予測
A1 A2 Ai 因子水準
特性値
1y
2y
新規データ (𝜇 + 𝑎𝑖 + 𝑒) の予測区間
新規データの点予測
𝑦 𝑖 ± 𝑡 𝑓∗,1 − 𝛼
21 +
1
𝑁𝜎 𝑅
2 + 𝜎 𝑒2
= 𝑦 𝑖 ±𝑡 𝑓∗,1 − 𝛼
2
(𝑁 + 1) 𝑉𝑅 + 𝐼 − 1 𝑉𝑒𝐼𝑁

© Hajime Mizuyama
Satterthwaiteの方法
– 互いに独立な標本分散: V1, V2, …
– それらの自由度: f1, f2, …
– 定数: c1, c2, …
とするとき,V * = c1V1 + c2V2 + … の等価自由度 f *を次式で
定める方法:
自由度の決め方
2
2
22
1
2
11
2
2211*
f
Vc
f
Vc
VcVcf

© Hajime Mizuyama
因子の階層構造(2次までの場合)
• 1次因子:水準変更が困難な因子,水準設定を先に行う因子
• 2次因子:水準変更が容易な因子,水準設定を後に行う因子
分割法とは
因子間に階層構造があり,低次の因子に関する処理を施した各
実験単位が,高次の因子を割り付ける際に複数の実験単位とし
て利用できる場合の実験方法
1次因子に関する処理で生じる1次誤差と,2次因子に関する処
理で生じる2次誤差を区別するのがポイントとなる.
分割法
© Hajime Mizuyama
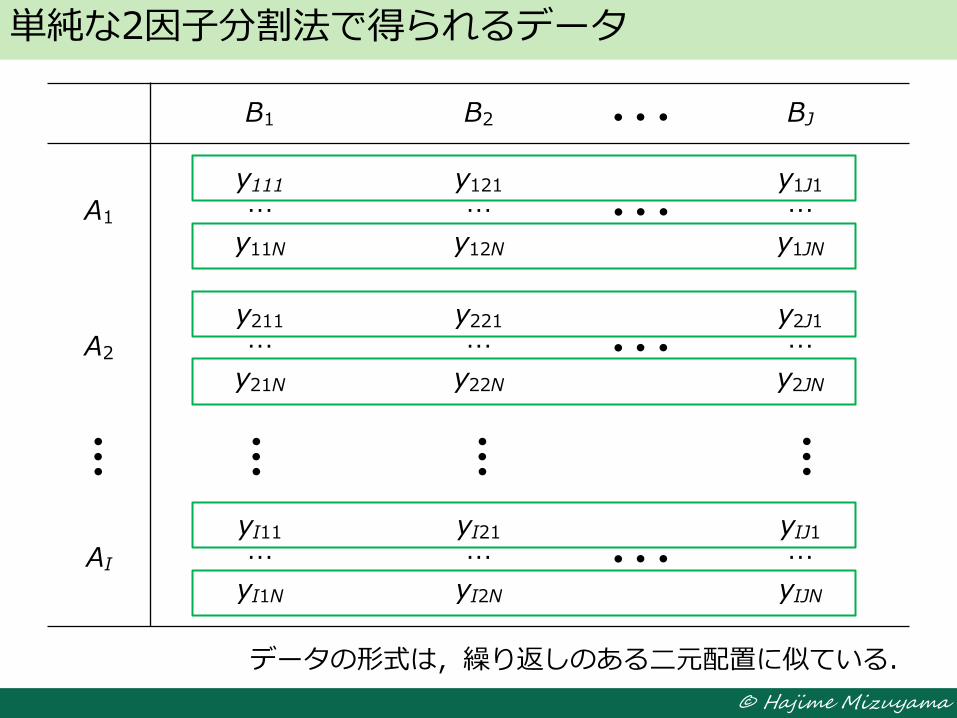
単純な2因子分割法で得られるデータ
B1 B2 BJ
A1
y111
… y11N
y121 …
y12N
y1J1 …
y1JN
A2
y211 …
y21N
y221 …
y22N
y2J1 …
y2JN
AI
yI11 …
yI1N
yI21 …
yI2N
yIJ1 … yIJN
データの形式は,繰り返しのある二元配置に似ている.
© Hajime Mizuyama
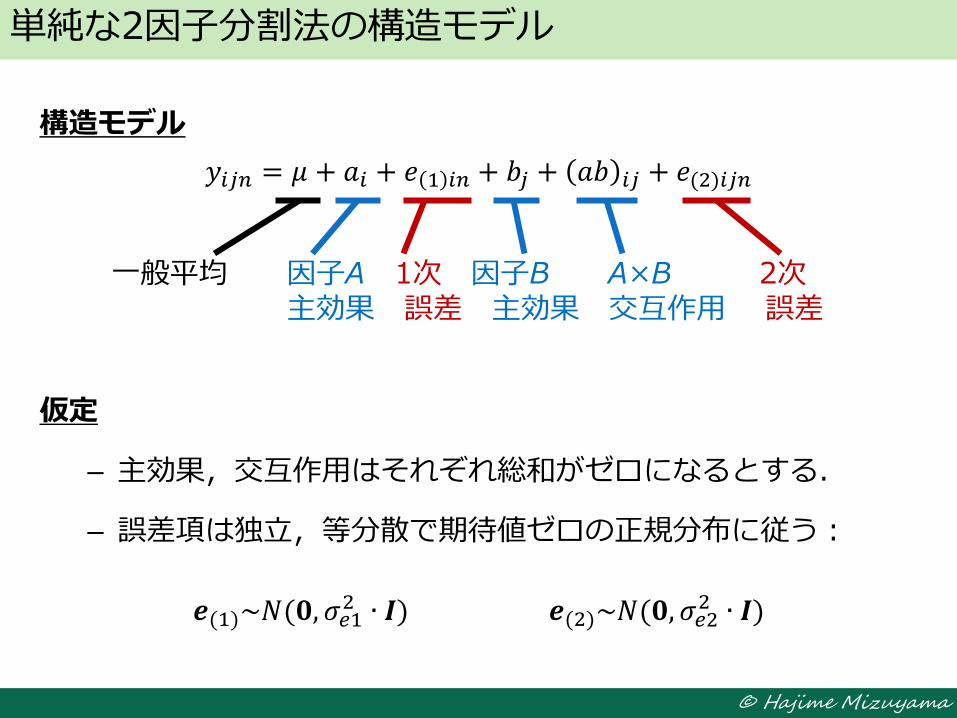
構造モデル
𝑦𝑖𝑗𝑛 = 𝜇 + 𝑎𝑖 + 𝑒 1 𝑖𝑛 + 𝑏𝑗 + 𝑎𝑏 𝑖𝑗 + 𝑒(2)𝑖𝑗𝑛
仮定
– 主効果,交互作用はそれぞれ総和がゼロになるとする.
– 誤差項は独立,等分散で期待値ゼロの正規分布に従う:
単純な2因子分割法の構造モデル
一般平均 因子A 1次 因子B A×B 2次 主効果 誤差 主効果 交互作用 誤差
𝒆(1)~𝑁(𝟎, 𝜎𝑒12 ∙ 𝑰)
𝒆(2)~𝑁(𝟎, 𝜎𝑒22 ∙ 𝑰)

© Hajime Mizuyama
分散分析による要因効果の検定
要因 平方和 自由度 平均平方 F値
A SA fA = I-1 VA = SA /fA FA = VA /Ve1
1次誤差 Se1 = SAR-SA
fe1 = I(N-1) Ve1 = Se1 /fe1 Fe1 = Ve1 /Ve2
B SB fB = J-1 VB = SB /fB FB = VB /Ve2
A×B SA×B
fA×B =
(I-1)(J-1) VA×B = SA×B /fA×B FA×B = VA×B /Ve2
2次残差 Se2 = Se-Se1
fe2 = IJ(N-1)-fe1
Ve2 = Se1 /fe1 ―
計 ST IJN-1 ― ―
