先端論文紹介ゼミ role-based context-specific multiagent q-learning
DESCRIPTION
先端論文紹介ゼミ Role-based Context-specific Multiagent Q-learning. M1 倉野 直. 目次. Abstract Introduction Collaborative multiagent MDPs and einforcement learning Role-based context-specific Q-learning Experiments Conclusion. Abstract. マルチエージェント強化学習における主な問題はエージェント数に従い行動状態空間サイズが指数関数的に増大すること。 - PowerPoint PPT PresentationTRANSCRIPT

M1 倉野 直
先端論文紹介ゼミRole-based Context-specific Multiagent Q-learning

目次AbstractIntroductionCollaborative multiagent MDPs and
einforcement learningRole-based context-specific Q-learningExperimentsConclusion
2011/1/21 2先端論文紹介ゼミ

Abstractマルチエージェント強化学習における主な問題は
エージェント数に従い行動状態空間サイズが指数関数的に増大すること。
本稿では行動空間の増加を軽減するために「 roles and context - specific coordination graphs 」を利用する。
全体結合 Q 関数を部分的 Q 関数に分解する。部分的 Q 関数は小グループのエージェントで構成さ
れ価値ルールの組で構成される。自動的に各価値ルールの重みを学習するマルチエー
ジェント Q 学習アルゴリズムを提案する。
2011/1/21 3先端論文紹介ゼミ

Introductionマルチエージェントシステムとは複数のエージェン
トとの相互作用で共存するエージェント群。マルチエージェントシステムの研究ではエージェン
トの行動管理の問題に焦点を当てている。本稿では全てのエージェントが共通の目標をもつ完
全集中型マルチエージェントシステムに焦点を当てる。
エージェントの個々の行動を確認するプロセスはグループ全体の最適政策を学習する。
2011/1/21 4先端論文紹介ゼミ

Introduction マルチエージェントシステムを単一の「大きな」
エージェントとして扱い、最適政策を学習させる方法。
行動空間が指数関数的に増加するため詳細な設計が難しい
各エージェントが独立した自身の政策を学習する方法。各エージェントが他のエージェントの情報なしに学習を行
う。
収束が学習エージェントの政策に依存するため、安定しない。
2011/1/21 5先端論文紹介ゼミ

Introduction行動空間のサイズを軽減するために最近の研究
は“ context-specific coordination graph (CG)” を使用する。
CG の考え方: エージェントが個々に行動できる中で少数のエージェントの行動の調整を行う。
例)ロボットサッカーにおいて他のロボットが自己の独立した行動をするなかで、ボールの保持者やその周りのプレイヤーの行動を調整する必要がある。
2011/1/21 6先端論文紹介ゼミ

Introduction本論文では CG に基づいたマルチエージェント Q 学
習を提案する。オフライン設計段階では役割に対する価値ルールを
定義する。オンライン割り当て段階では、役割割当アルゴリズ
ムを用いて、エージェントに役割を割当て、エージェントが役割に対応した価値ルールを得る。
提案手法では CG の重みを学習する。CG の重みは Q 学習から派生した更新式を利用する。
2011/1/21 7先端論文紹介ゼミ

Collaborative multiagent MDPs (CMMDP)and reinforcement learningマルコフ決定過程を拡張した CMMDP 構造を使用す
る。CMMDP は 5 つの要素< n,S,A,R,T> より成り立つ。
( n: エージェント数、 S: 有限状態空間、 A :行動空間、 R :報酬、 T :状態 s のエージェントが行動 a を選択し状態 s’ に遷移した場合に取る行動の確率)
Q 学習は以下の式を用いて更新される。
γ は報酬割引率、 α は学習率とする。
)1(),()','(max),(),(),('
asQasQasRasQasQa
2011/1/21 8先端論文紹介ゼミ

Collaborative multiagent MDPs (CMMDP)and reinforcement learningJoint action learners ( JAL)
この手法はマルチエージェントシステム( MAS の)を単一の「大きな」エージェントとして扱う。 エージェントの状態 - 行動の組は結合状態空間と元の MAS の結合行動空間である。
「大きな」エージェントの学習には Q 学習を用いる。
欠点: 学習エージェントの状態と行動の組がエージェント数に従い
指数関数的に増加する。
2011/1/21 9先端論文紹介ゼミ

Collaborative multiagent MDPs (CMMDP)and reinforcement learning Independent learners ( IL)
この手法はエージェントが他のエージェントの情報なしに独立した学習を行う。
指数関数的な結合行動空間を考慮する必要はない。
欠点: 他のエージェントの政策に依存するため、学習の収束が安定
しない。
2011/1/21 10先端論文紹介ゼミ

Role-based context-specific Q-learning
Context-specific coordination graphs and roles
協調の依存関係は CG を用いて表すことができる。 価値ルールはエージェントが協調行動を実行する文
脈を定義する。 協調の依存関係を G=(V,E) で定義する。 全体結合 Q 関数を部分的 Q 関数の和で近似される。
2011/1/21 11先端論文紹介ゼミ

Role-based context-specific Q-learning
Context-specific coordination graphs and roles
定義 2 : 価値ルール は現在の状態
が s であり、統一行動 a を行った時、 となる。それ以外は0とする。
定義 3 :
ここで
vas :vas ),(
)2(]}[|{][ iiii QDomAAAQAgent
)3(),(),(1
n
jji asasQ
0][][ ij QAgentAgent
2011/1/21 12先端論文紹介ゼミ
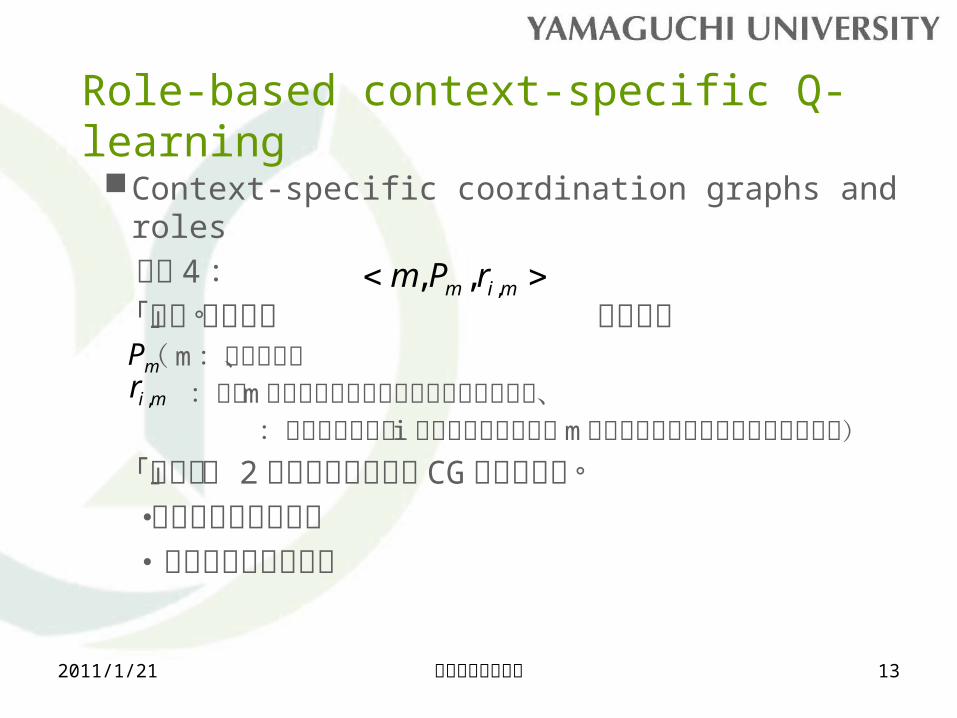
Role-based context-specific Q-learning
Context-specific coordination graphs and roles
定義 4 : 「役割」の要素は とする。 ( m :役割の数、 :役割 m に関連付けられておる価値ルールの組、 :はエージェント i が現在の状態で役割 m が適当であるか
のポテンシャル関数)
「役割」を 2 つの段階を用いて CG に内蔵する。・オフライン設計段階・オンライン割当段階
mim rPm ,,,
mPmir ,
2011/1/21 13先端論文紹介ゼミ

Role-based context-specific Q-learning
Context-specific coordination graphs and roles
オフライン設計段階 エージェントに対する価値ルールの定義の代わりに役割に対
する価値ルールを定義する。
オフライン設計段階 エージェントに役割を割り当てる役割割当アルゴリズムを使
用する。 エージェントは割り当てられた役割から価値ルールを得る。
2011/1/21 14先端論文紹介ゼミ

Role-based context-specific Q-learning
Context-specific coordination graphs and roles
役割割当アルゴリズム |M|>n のとき配列M を定義する。( M :役割の数、 n :エー
ジェント数) 役割の重要度により順序付けされる。 同じ役割は複数のエージェントに割り当てることができる。 エージェントが複数の役割をもつことはできない。 エージェント i と役割 m からポテンシャル を算出する。
mir ,
2011/1/21 15先端論文紹介ゼミ

Role-based context-specific Q-learning
Q-learning in context-specific coordination graphs
定義 5 : はエージェント i に対する部分的Q 値
はエージェント i を含む価値ルール。 nj はエージェント i を含むそのルールに関係するエージェント
の数。
)4(),(
),( j
j
iji
n
asasQ
),( asQ i
),( asij
2011/1/21 16先端論文紹介ゼミ

Role-based context-specific Q-learning
Q-learning in context-specific coordination graphs
定理1:価値ルール は以下の式で更新する。
nj は ρj に関するエージェントの数。 ni は状態sで統一行動 a が一致しているインスタンスの価
値ルールのエージェント i の出現回数。
),( asj
)10(),(
),(),(1
jn
i i
i
jj n
asQasas
2011/1/21 17先端論文紹介ゼミ

Role-based context-specific Q-learning
Q-learning in context-specific coordination graphs
学習アルゴリズム
2011/1/21 18先端論文紹介ゼミ

Experiments提案手法 RQ を JAL 、 IL と比較する。問題設定は追跡問題を適用する。10*10 のグリッド平面に2体のハンターと1体の獲物を配置
ハンターと獲物の行動は上下左右静止の5行動。獲物はランダム行動を行う。捕獲条件は獲物と同セルおよび隣接セルに両ハンターが移動。
2011/1/21 19先端論文紹介ゼミ

ExperimentsRQ アルゴリズムにおいて役割を二つ用意する。
capture :獲物を捕獲するように行動する。 Supporter:捕獲者のサポートをする行動を取る。役割割当の配列 は となる。
capture の役割のポテンシャルはハンターと獲物のマンハッタン距離に基づく。
Where is the distance between predator i and the prey
}sup,{ portercaptureM
)15(),1max(
1
,,
picapturei dr
pid ,
2011/1/21 20先端論文紹介ゼミ

Experiments各ハンターが得る報酬は以下に示す。
) (
それ以外へ移動する場合が支援なしに獲物の方 エージェント
した場合 他のハンターと衝突を受けて捕獲した場合が他のハンターの支援 エージェント
16
0.1
0.10
0.50
0.50
),(
i
i
asRi
2011/1/21 21先端論文紹介ゼミ

Experiments実行結果
手法 平均捕獲ステップ
RQ 12.92
JAL 12.78
IL 17.02
2011/1/21 22先端論文紹介ゼミ

Conclusion role-based context-specific multiagent Q-learning 手法
を提案。Role and context-specific coordinarion graphs を使用。自動的に各価値ルールの重みを学習する Q 学習アル
ゴリズムを提案。実験は従来のマルチエージェント強化学習より大幅
に速い学習速度で同じ政策に収束することを示した。
2011/1/21 23先端論文紹介ゼミ

ご清聴ありがとうございました。
2011/1/21 24先端論文紹介ゼミ

Role-based context-specific Q-learning
補足 1
例)状態sと状態 s0 が以下の規則をもつ。
エージェントは状態sに協調行動 a= {a1,a2,a3} を行い、状態は s’ に遷移する。状態 s’ での最適行動は である。
従って状態 s においてルール ρ1 、 ρ2 、 ρ4 が表れ、状態s’ においてルール ρ5 と ρ7 が表れる。
83284324
73273323
62162212
515111
:';:;
:';:;
:';:;
:';:;
vaasvaas
vaasvaas
vaasvaas
vasvas
},,{ 321* aaaa
2011/1/21 25先端論文紹介ゼミ

Role-based context-specific Q-learning
補足 1
次のように ρ1 、 ρ2 、 ρ4 を更新する。
1
),(
2
),(),(
2
),(
2
),(),(
2
),(),(
22),(),(
222),(),(
211),(),(
32
33
21
22
1
11
473
3
4272
2
2151
1
asQasQvas
asQasQvas
asQvas
vvasRasQ
vvvasRasQ
vvvasRasQ
2011/1/21 26先端論文紹介ゼミ

Experiments
補足 2: 生成される価値ルールの一例
価値ルール ρ1 は捕獲者の役割が他の支援者となるハンターの支援がなくても獲物をほかうしようとするべきと示す。
ルール ρ2 は捕獲者が獲物の位置に動き、支援者が現在の位置で静止する連携文脈である。
100:)(
()
)(
)(sup;
100:)(;
2
1
centermoveToa
moveTopreya
jpreytoadjacentis
jporterrolehas
dirmoveToa
j
i
captuer
icaptuer
2011/1/21 27先端論文紹介ゼミ