分類分析 (taxometric analysis)
TRANSCRIPT
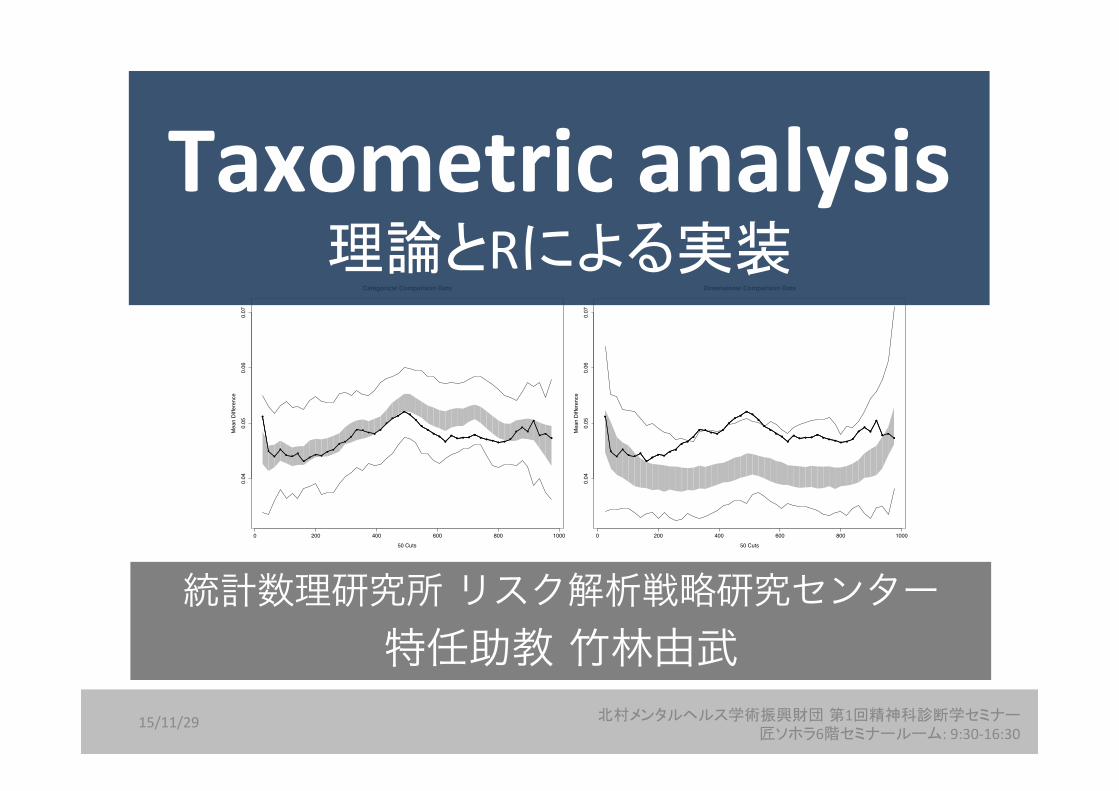
0 200 400 600 800 1000
0.04
0.05
0.06
0.07
Categorical Comparison Data
50 Cuts
Mea
n D
iffer
ence
0 200 400 600 800 1000
0.04
0.05
0.06
0.07
Dimensional Comparison Data
50 Cuts
Mea
n D
iffer
ence
Taxometric analysis 理論とRによる実装
統計数理研究所 リスク解析戦略研究センター 特任助教 竹林由武
15/11/29 北村メンタルヘルス学術振興財団 第1回精神科診断学セミナー 匠ソホラ6階セミナールーム: 9:30-‐16:30

発表の構成 2
理 論
書き方
実 装
各分析手法の理論解説
研究を始める前に知っておきたい 論文執筆上のチェックポイント
Rによるtaxometric分析の実施 出力結果の解釈

発表の構成 3
理 論
書き方
実 装
各分析手法の理論解説
研究を始める前に知っておきたい 論文執筆上のチェックポイント
Rによるtaxometric分析の実施 出力結果の解釈

はじめに
• 本発表の内容は、引用文献の記載がない箇所の内容は、以下の書籍・論文を参照
4
Ruscio, J., Haslam, N., & Ruscio, A. M. (2006). Chapter9: Taxometric checklist, Introduction to the taxometric method: A practical guide. Routledge.
Taxometric分析の解説書 実施する理由, 他のモデルとの比較, 分析手続きの詳細, 実施・報告上のポイント を簡潔かつ網羅的に解説。
Taxometric分析の概説論文 上記の本の9章のチェックポイントを、 最新の知見を踏まえてアップデート

連続的
はじめに • Taxometric分析 提唱者: Paul Meehl, Ph.D 分析の目的:
5
非連続的
Waller, N. G., & Meehl, P. E. (1998). Multivariate taxometric procedures: Distinguishing types from continua. Sage Publications, Inc.
測定概念の分布の性質を検討

構成概念の測定
• Correlated item
6
症状 A
症状 D
症状 B
症状 C
症状 E
相関のある観測変数群

構成概念の測定
• Common cause model
7
症状 A
症状 D
症状 B
症状 C
症状 E
構成 概念
e1 e2 e3 e4 e5
観測変数間の相関を、 共通する潜在変数で 表現
観測変数 = indicator

構成概念の得点の分布
• 潜在変数の推定→因子得点の分布
8
!
A D!!
B C E!
!
e1 e2 e3 e4 e5

用語 • Taxon: 分類,
9
非連続的, カテゴリカル, 質的な違い
Waller, N. G., & Meehl, P. E. (1998). Multivariate taxometric procedures: Distinguishing types from continua. Sage Publications, Inc.
連続的, 次元的 程度の違い
Dimensional ConAnuous QuanAtaAve
Taxonic Categorical QualitaAave
taxon
complement

taxometric分析の研究例
• 事例 : 概要 目的:青年の自殺念慮の分布は連続的か検討 患者: 大うつ病の青年 (12歳-18歳)334名 研究デザイン:横断研究 測定指標:Suicidal Ideation Questionnaire 結果:青年うつ病患者の自殺念慮は連続的
10
Liu, R. T., Jones, R. N., & Spirito, A. (2015). Is adolescent suicidal ideaAon conAnuous or categorical? A taxometric analysis. Journal of abnormal child psychology, 1-‐8.

taxometric分析の研究例
• 事例 : 概要 目的:サイコパシー傾向の分布は連続的か検討 患者: 犯罪者4865名 研究デザイン:横断研究 測定指標:Psychopathy Checklist̶Revised 結果:サイコパシー傾向は連続的
11
Liu, R. T., Jones, R. N., & Spirito, A. (2015). Is adolescent suicidal ideaAon conAnuous or categorical? A taxometric analysis. Journal of abnormal child psychology, 1-‐8.

Taxometric分析
• 事例 : 概要 目的:問題賭博の分布は連続的か質的か検討 患者: 犯罪者4865名 研究デザイン:横断研究 測定指標:the Problem Gambling Severity Index (PGSI) 病的賭博の診断基準
結果:問題賭博の分布は非連続的
12
Liu, R. T., Jones, R. N., & Spirito, A. (2015). Is adolescent suicidal ideaAon conAnuous or categorical? A taxometric analysis. Journal of abnormal child psychology, 1-‐8.
研究の問いと結果 構成概念が連続的か否かのみなので、極めてクリア

Taxometric分析のインパクト
・理論への示唆 質的 ‒ 単一 (少数)のリスクファクター 連続 ‒ 複合的なリスクファクター
・研究法への示唆 連続的 ‒ 連続得点で評価 質的 ‒ 群間比較デザインが適切
13
当該概念の捉え方そのものに影響を与える重大な知見
結果はシンプル、しかしインパクトはでかい

分析手法 • 代表的な方法 Mean Above Minus Below A Cut (MAMBAC) MAXimum EIGenvalue (MAXCOV) Latent Mode (L-MODE)
• その他の方法 MAXimum COVariance (MAXCOV) MAXimum SLOPE (MAXSLOPE)
14
代表的な方法を中心に解説します

MAMBAC
群間差のプロットに基づく:
15
非連続的 連続的
凸型 明確なピークが存在
U型 (お椀型) 明確なピークなし

MAMBAC
プロットの作成手順: i) 2つのindicatorを用意
ii) 一方の変数 (変数A)を任意の間隔で区切る
iii) 各区分点で、区分点以上以下で2群に分ける
iv) 各群でもう一方の変数 (変数B)の, 平均値・群間差を算出
v) 各区分点をx軸、群間差をy軸にプロット
16

MAMBACプロットへの道 17
output indicator
input indicator
二つのindicatorを用意
非連続的データの場合

MAMBACプロットへの道 18
input indicatorのカットポイントを設定
5点区切りのカットポイントを設定
※ カットポイントの設定点は任意
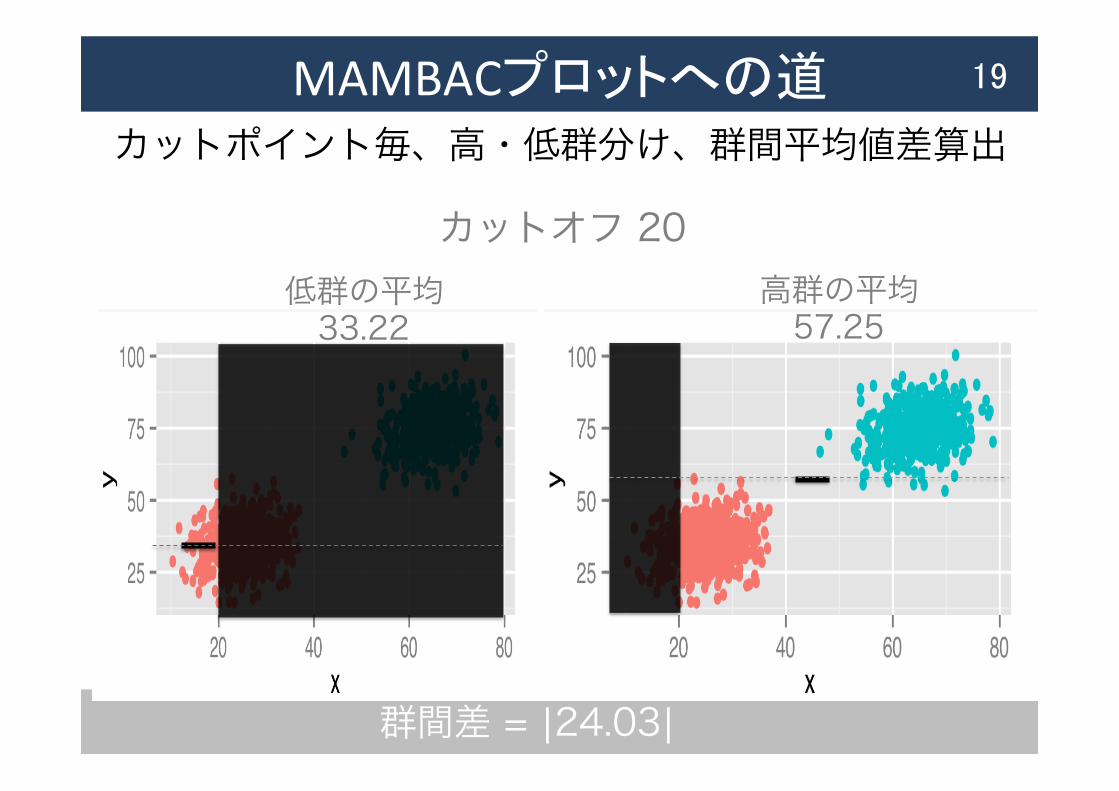
MAMBACプロットへの道 19
低群の平均 33.22
高群の平均 57.25
カットポイント毎、高・低群分け、群間平均値差算出
カットオフ 20
群間差 = |24.03|

MAMBACプロットへの道 20
低群の平均 35.02
高群の平均 75.01
群間差 = |40.01|
2群が明確に分かれるポイントで群間差最大 カットオフ 40

MAMBACプロットへの道 21
低群の平均 53.32
高群の平均 76.85
群間差 = |23.53|
indicatorの両極では群間差が低め カットオフ 40
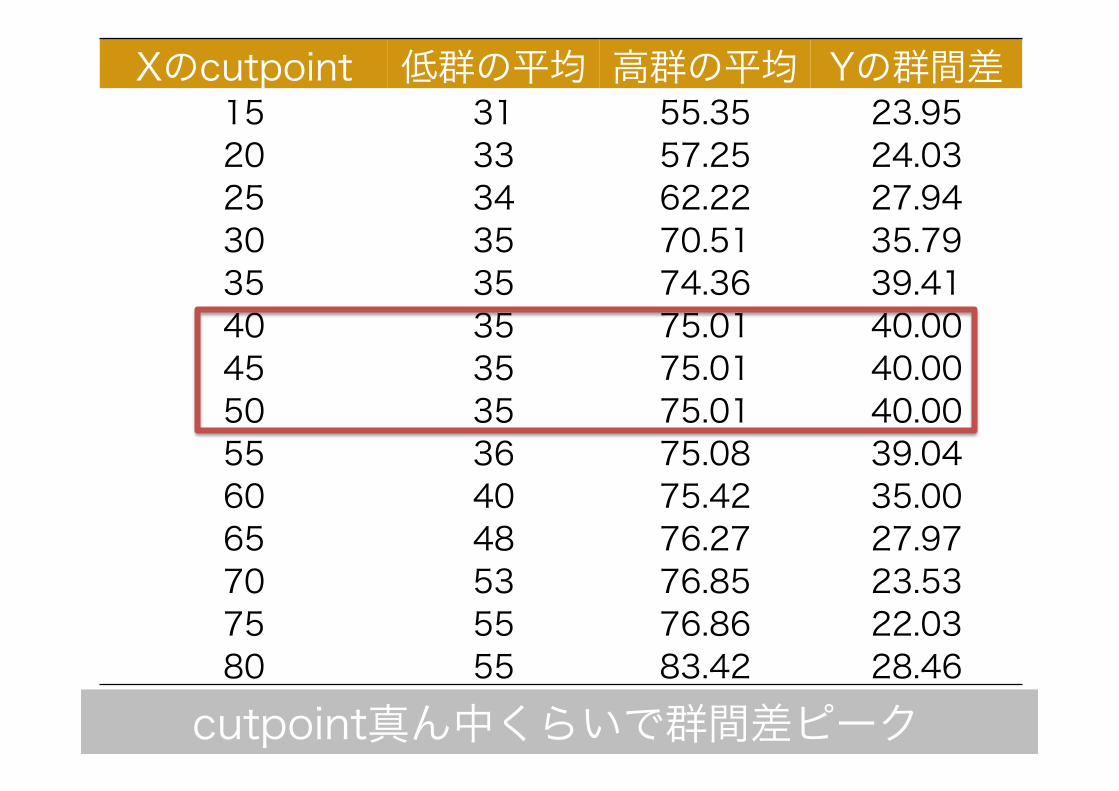
22 Xのcutpoint 低群の平均 高群の平均 Yの群間差 15 31 55.35 23.95 20 33 57.25 24.03 25 34 62.22 27.94 30 35 70.51 35.79 35 35 74.36 39.41 40 35 75.01 40.00 45 35 75.01 40.00 50 35 75.01 40.00 55 36 75.08 39.04 60 40 75.42 35.00 65 48 76.27 27.97 70 53 76.85 23.53 75 55 76.86 22.03 80 55 83.42 28.46 cutpoint真ん中くらいで群間差ピーク

23
群間差のプロットにピークが認められる = 質的
25
30
35
40
20 40 60 80X1
X2
MAMBACプロット完成 23
input indicatorのcut point
output indicatorの群間差
output indicatorのピーク値で分割したtaxon群の割合 = taxon base rate rate

MAMBACプロットへの道 24
二つのindicatorを用意
連続的データの場合 output indicator
input indicator

MAMBACプロットへの道 25
低群の平均 28.61
高群の平均 45.36
カットポイント毎、高・低群分け、群間平均値差算出 カットオフ 19
群間差 = |16.75|
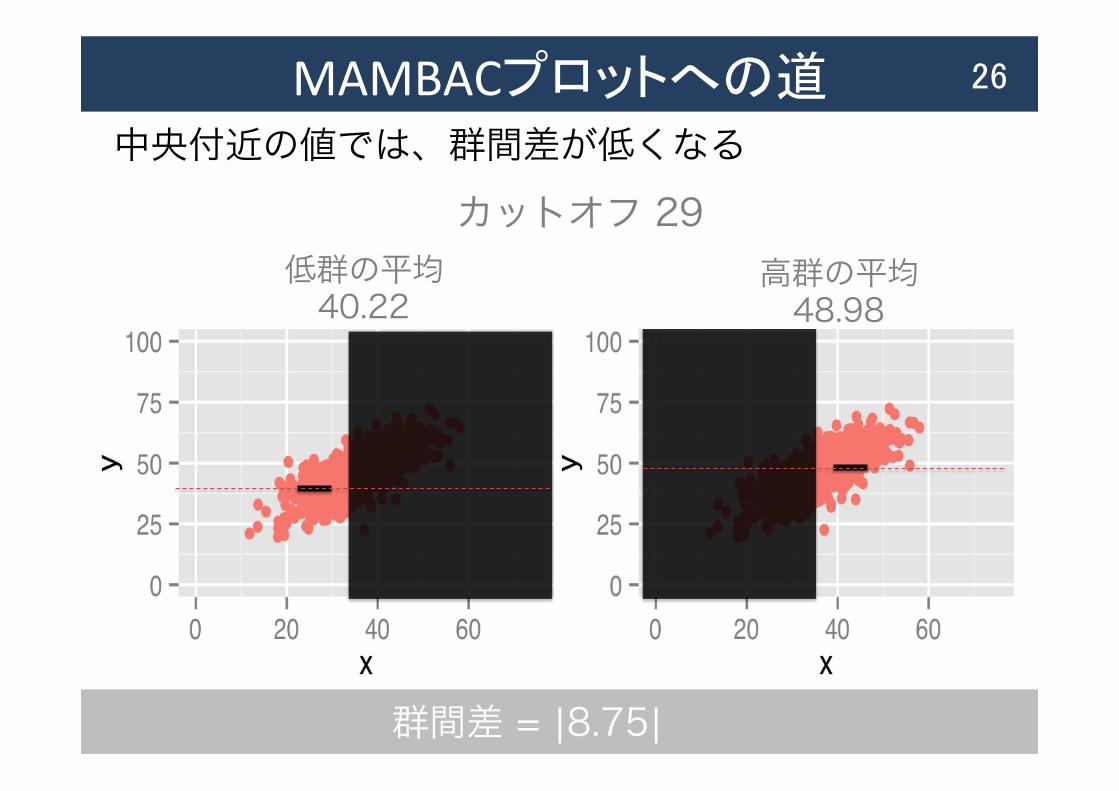
MAMBACプロットへの道 26
低群の平均 40.22
高群の平均 48.98
中央付近の値では、群間差が低くなる カットオフ 29
群間差 = |8.75|

MAMBACプロットへの道 27
低群の平均 45.14
高群の平均 66.82
極値付近で、群間差が最大になる カットオフ 29
群間差 = |21.68|

28 Xのcutpoint 低群の平均 高群の平均 Yの群間差 19 28.61 45.36 16.75
24 33.61 45.99 12.38
29 36.87 47.17 10.30
34 40.22 48.98 8.75
39 42.69 51.71 9.01
44 44.11 54.54 10.43
49 44.95 60.46 15.51
54 45.14 66.82 21.68
極値で群間差が大きくなる

29
群間差にピークなくお椀型 = 連続的
MAMBACプロット完成 29
input indicatorのcut point
output indicatorの群間差
cut pointの両極値で群間差ピーク

MAXCOV
2変数間の共分散に基づく:
30
非連続的 連続的
凸型 ピークが存在
平行型 明確なピークなし

MAXCOV
プロットの作成手順: i) 3つのindicatorを用意
ii) 1つの変数の任意の間隔で集団を分割
iii) 下位集団ごとに、残りの2変数間の共分散を求める
v) 分割区間をx軸、共分散をy軸にプロット
31
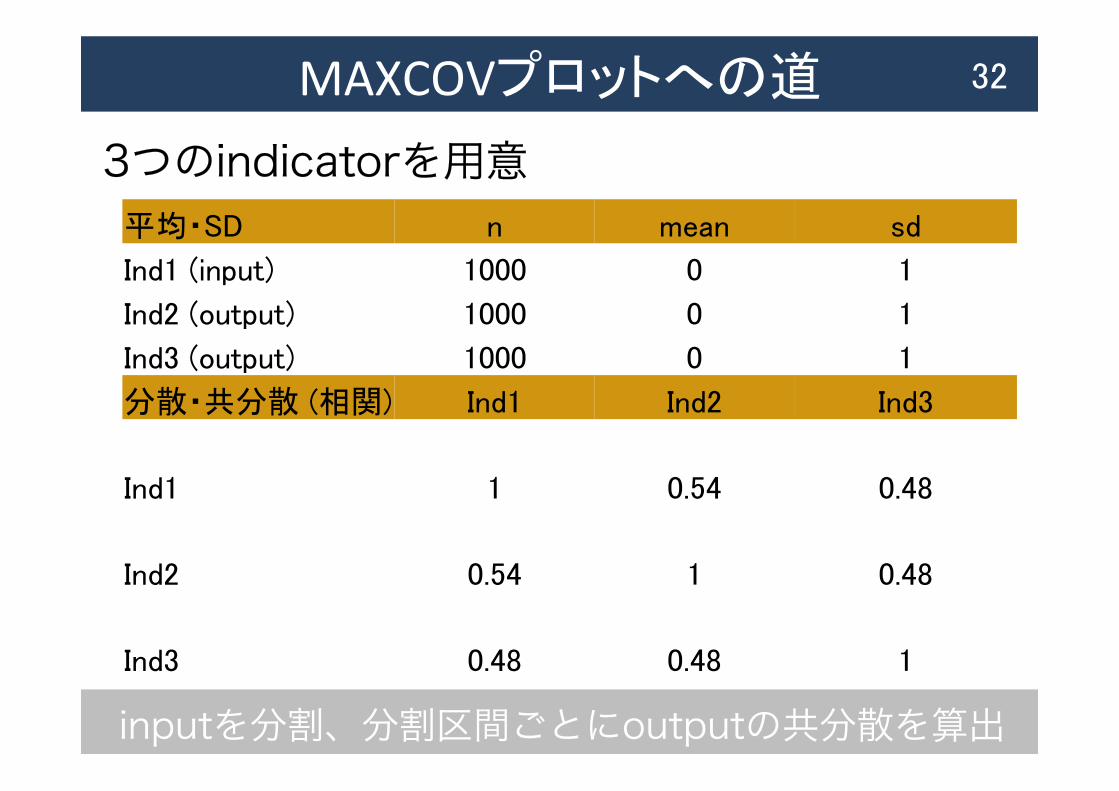
MAXCOVプロットへの道
3つのindicatorを用意
32
平均・SD n mean sd
Ind1 (input) 1000 0 1
Ind2 (output) 1000 0 1
Ind3 (output) 1000 0 1
分散・共分散 (相関) Ind1 Ind2 Ind3
Ind1 1 0.54 0.48
Ind2 0.54 1 0.48
Ind3 0.48 0.48 1
inputを分割、分割区間ごとにoutputの共分散を算出

MAXCOV 33
0 -‐1 -‐2 +1 +2
OUTPUT indicator 間の共分散が、0付近で区間で最も大きくなる
-‐2.75 -‐1.75 -‐0.75 0.25 1.25 2.25
input indicatorを5分割、各区間の下位集団の共分散
非連続的データの場合

MAXCOVプロットへの道 34
inputの区間 outputの共分散
-2 0
-1 0.09
0 0.33
1 0.20
2 0

35
群間差のプロットにピークが認められる = 質的
MAXCOVプロット完成 35
input indicatorの分割集団
output indicatorの共分散
共分散ピークのindicatorの値 = hitmax value Hitmaxで分割したtaxon群の割合 = taxon base rate rate
Hitmax この値で標本を分割すると、最も精度よくtaxon とcomplementを分けられる
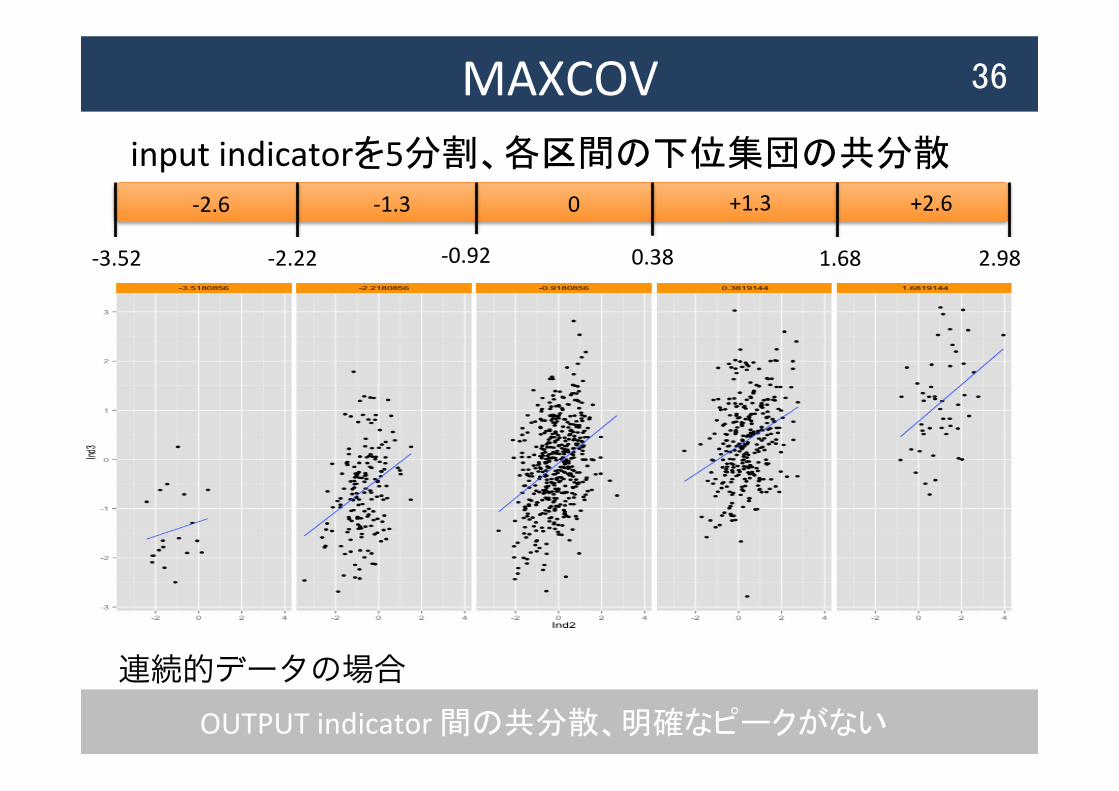
MAXCOV 36
0 -‐1.3 -‐2.6 +1.3 +2.6
OUTPUT indicator 間の共分散、明確なピークがない
-‐3.52 -‐2.22 -‐0.92 0.38 1.68 2.98
input indicatorを5分割、各区間の下位集団の共分散
連続的データの場合

MAXCOVプロットへの道 37
inputの区間 outputの共分散
-2 0.10
-1 0.22
0 0.27
1 0.24
2 0.36
OUTPUT indicator 間の共分散、明確なピークがない

38
共分散のプロットに明確なピークなし = 連続的
MAXCOVプロット完成 38
input indicatorの分割集団
output indicatorの共分散
明確なピークなし
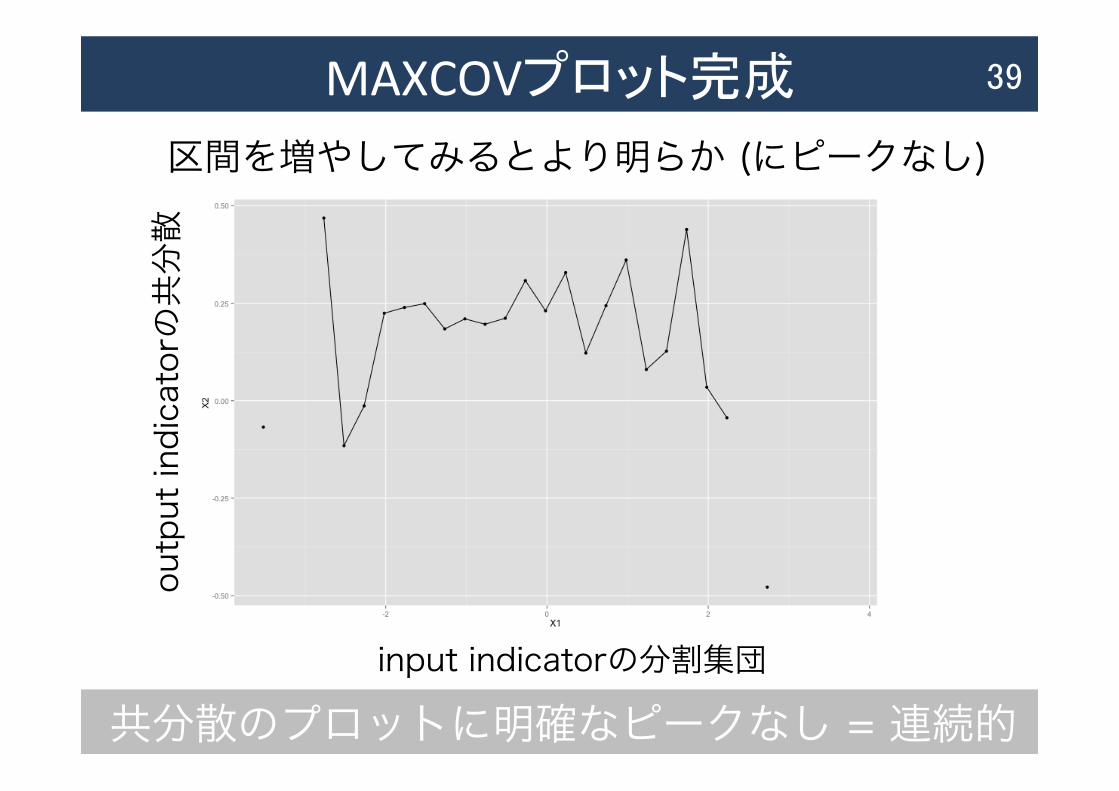
39
共分散のプロットに明確なピークなし = 連続的
MAXCOVプロット完成 39
input indicatorの分割集団
output indicatorの共分散
区間を増やしてみるとより明らか (にピークなし)

MAXEIG
複数の変数の(条件付き)固有値のプロットに基づく:
40
非連続的 連続的
凸型 明確なピークが存在
平行型 明確なピークなし

MAXEIG
プロットの作成手順: i) 3つ以上のindicatorを用意
ii) 1つの変数の任意の間隔で集団を分割
iii) 下位集団ごとに、残りの変数間の固有値を求める
v) 分割区間をx軸、固有値をy軸にプロット
41
共分散 = 2変数間の共変関係を表す 固有値 = 3変数以上の変数間の共変関係を表す
共分散が固有値に置き換わっただけで原理は一緒

L-‐MODE 因子得点の分布に基づく:
42
非連続的 連続的
因子得点の分布 ピークが二つ以上
因子得点の分布 ピークが一つ

L-‐MODE
プロットの作成手順: i) 3つ以上のindicatorを用意 ii) Indicatorを観測変数とした因子分析を実施
iii) 因子得点を算出 (Bartlett法)
iv) 因子得点の分布をプロット
43
!
e1 e2 e3 e4
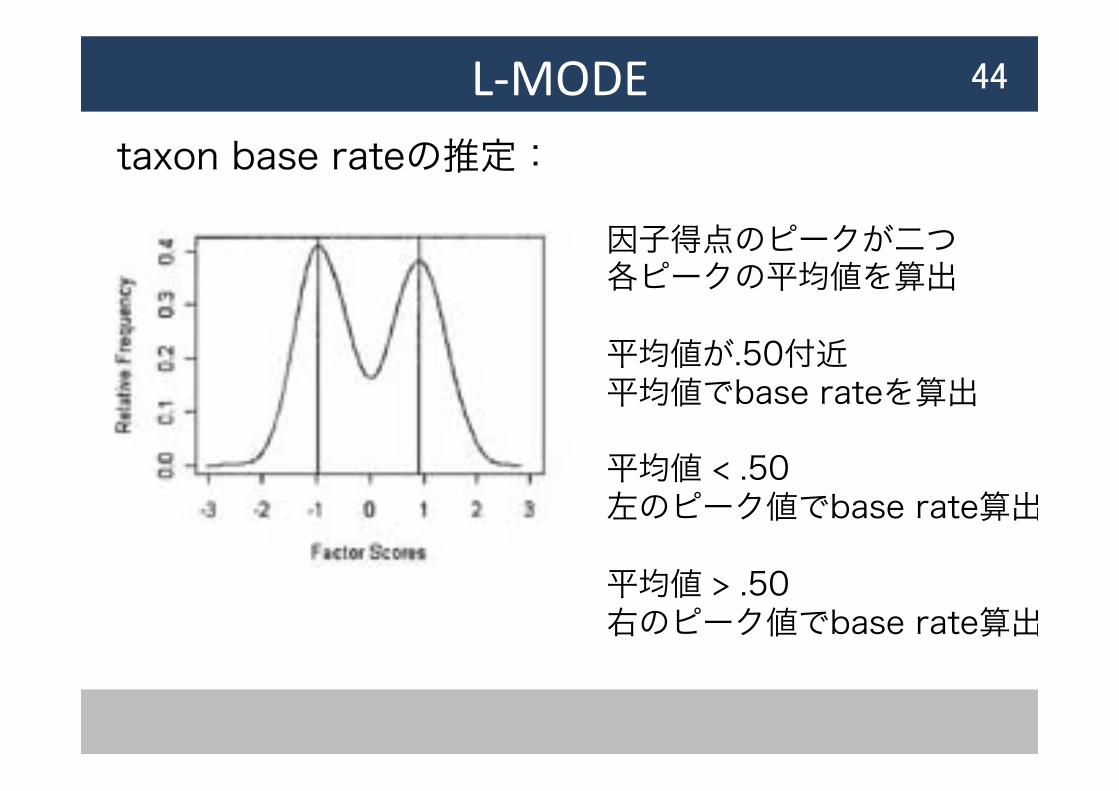
L-‐MODE taxon base rateの推定:
44
因子得点のピークが二つ 各ピークの平均値を算出 平均値が.50付近 平均値でbase rateを算出 平均値 < .50 左のピーク値でbase rate算出 平均値 > .50 右のピーク値でbase rate算出
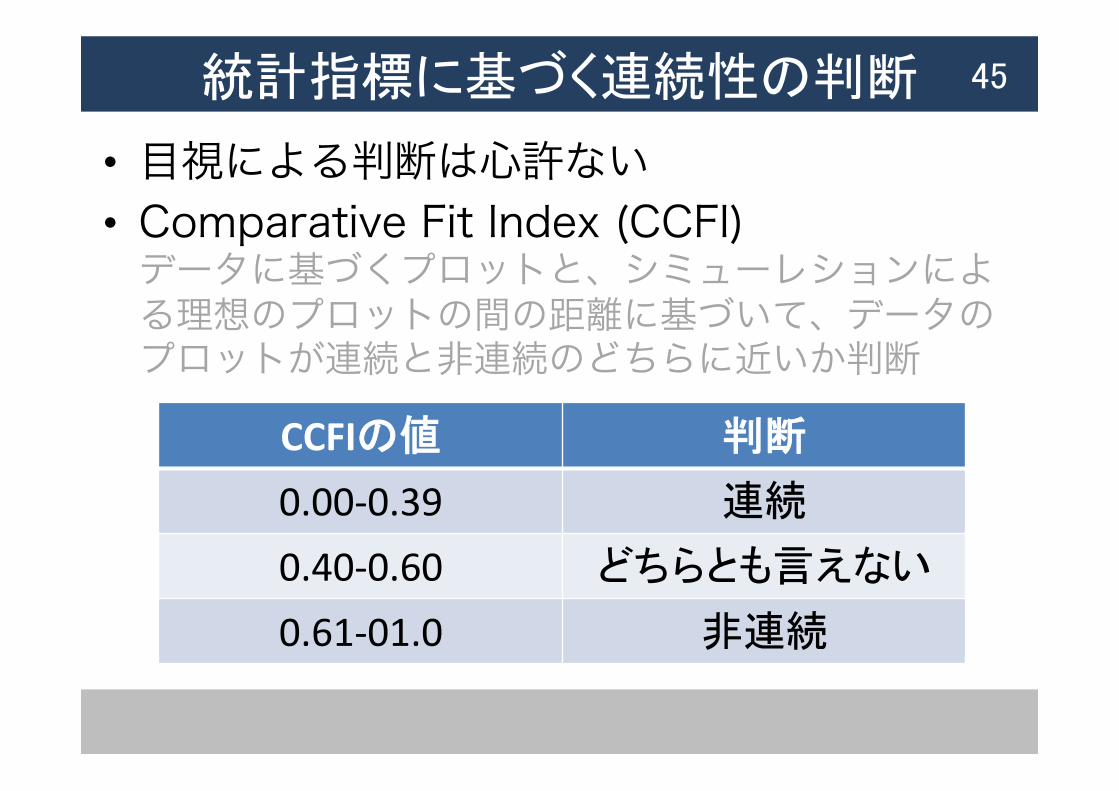
統計指標に基づく連続性の判断
• 目視による判断は心許ない • Comparative Fit Index (CCFI) データに基づくプロットと、シミューレションによる理想のプロットの間の距離に基づいて、データのプロットが連続と非連続のどちらに近いか判断
45
CCFIの値 判断
0.00-‐0.39 連続
0.40-‐0.60 どちらとも言えない
0.61-‐01.0 非連続

ComparaAve Curve Fit Index 46
データからのプロット (実線)
連続な場合の理想的プロット
非連続な場合の理想的プロット
データからのプロット (実線)
CCFIは理想(シミュレーション)と現実(データ)間の距離に基づき算出
非連続型に近いのか、連続型に近いのか、指標で判断できる
MAXIEIGのプロット: CCFI = 0.94
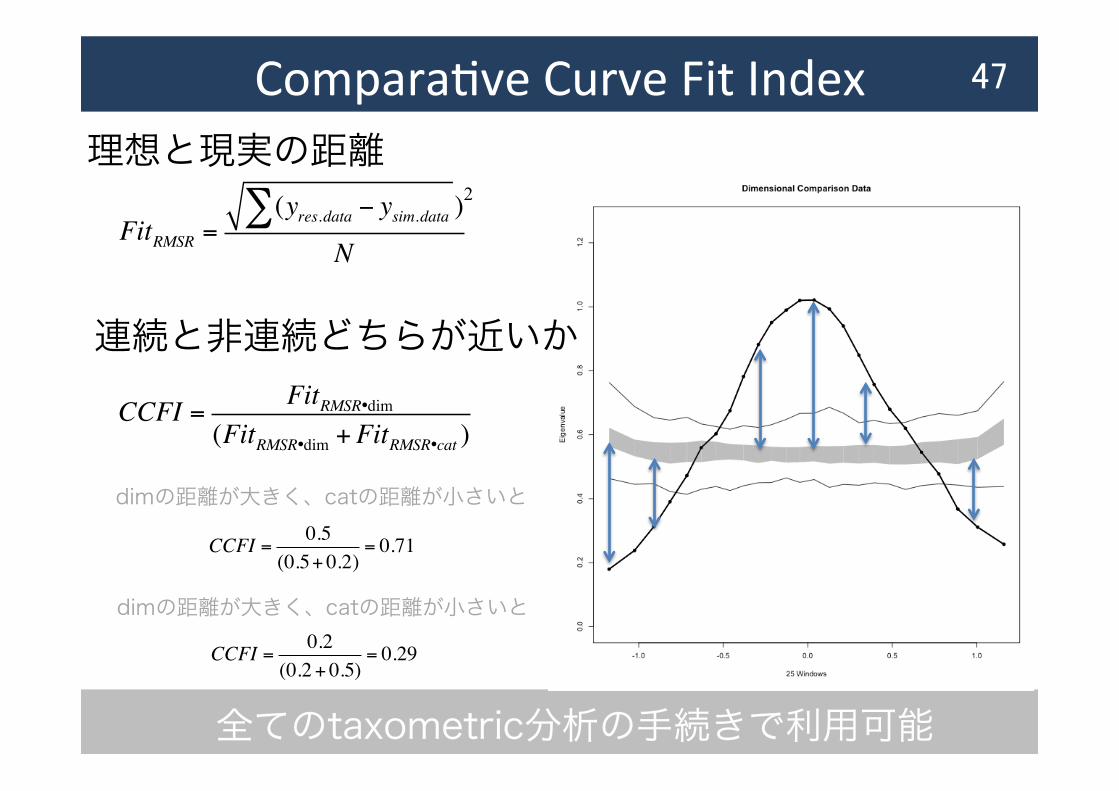
ComparaAve Curve Fit Index 47
理想と現実の距離
FitRMSR =(yres.data − ysim.data∑ )
N
2
CCFI = FitRMSR•dim(FitRMSR•dim +FitRMSR•cat )
CCFI = 0.5(0.5+ 0.2)
= 0.71
dimの距離が大きく、catの距離が小さいと
CCFI = 0.2(0.2+ 0.5)
= 0.29
dimの距離が大きく、catの距離が小さいと
連続と非連続どちらが近いか
全てのtaxometric分析の手続きで利用可能

発表の構成 48
理 論
書き方
実 装
各分析手法の理論解説
研究を始める前に知っておきたい 論文執筆上のチェックポイント
Rによるtaxometric分析の実施 出力結果の解釈

Taxometric分の実施・報告ガイドライン 49
最新の実証研究の知見を踏まえ、
アップデート
Ruscio, J., Haslam, N., & Ruscio, A. M. (2006). Chapter9: Taxometric checklist, Introduction to the taxometric method: A practical guide. Routledge.

論文化チェックリスト
✅ 分析を実施する科学的な合理性があるか? ✅ データが分析に適切か? ✅ 多様な分析手続きが適切に用いられているか?
✅ 結果が適切に提示され、解釈されているか? ✅ 結果のimplicationが明確に述べられているか?
Ruscio, J., Haslam, N., & Ruscio, A. M. (2006). Introduction to the taxometric method: A practical guide. Routledge.
50
5つの項目をチェック John Ruscio
http://www.tcnj.edu/~ruscio/

論文化チェックリスト
✅ 分析を実施する科学的な合理性があるか? ✅ データが分析に適切か? ✅ 多様な分析手続きが適切に用いられているか?
✅ 結果が適切に提示され、解釈されているか? ✅ 結果のimplicationが明確に述べられているか? Ruscio, J., Haslam, N., & Ruscio, A. M. (2006). Introduction to the taxometric method: A practical guide. Routledge.
51
5つの項目をチェック John Ruscio
http://www.tcnj.edu/~ruscio/
taxometric分析を適切に実施するためのポイントを紹介します

✅ データの適切性
A. 標本サイズ B. taxonのサイズ C. indicator数 D. 順序カテゴリデータの場合のカテゴリ数 E. indicatorの妥当性 F. 群内相関
52

✅ データの適切性
A. 標本サイズ ・Meehl (1995)の基準
300人以上 (Meehl, 1995) ・Ruscio et al. (2010)のシミュレーション
連続的:300人以上 非連続的:100人以下でも検出可能
53
少なくとも300人以上が必要
Ruscio, J., Walters, G. D., Marcus, D. K., & Kaczetow, W. (2010). Comparing the relaAve fit of categorical and dimensional latent variable models using consistency tests. Psychological Assessment, 22(1), 5.

✅ データの適切性
B. Taxonのサイズ ・Meehl (1995)の基準 標本の10%以上 ・Ruscio et al. (2010)のシミュレーション 標本の5%以上10%未満でも、誤分類は稀 ・Ruscio et al. (2004, 2010)の推奨
54
標本の5%以上かつ50人以上 疾患群、非疾患群の分類を対象とするなら、有病率に基づいて見積もると良い
Ruscio, J., Walters, G. D., Marcus, D. K., & Kaczetow, W. (2010). Comparing the relaAve fit of categorical and dimensional latent variable models using consistency tests. Psychological Assessment, 22(1), 5.

✅ データの適切性
記載例) 結果の節
55
Liu, R. T., Jones, R. N., & Spirito, A. (2015). Is adolescent suicidal ideaAon conAnuous or categorical? A taxometric analysis. Journal of abnormal child psychology, 1-‐8.
標本の適切性 The first recommends the base rate, or the proportion of cases in the whole sample assigned to the putative taxon should be ≥10% [47] or 5% [13]. The PGSI base rate (0.086) is sufficient, but the DSM-IV rate (0.046) is smaller than the recommended heuristic.

✅ データの適切性
C. indicatorの数 ・MAMBAC/MAXSLOPE = 2, MAXIEIG/L-MODE ≧ 3 Ruscio et al. (2010)のシミュレーション
indicator数=3でも妥当な推定結果 indicator数が多いほど結果が明瞭 indicator数=2の場合: 標本サイズ600以上10件法以上で安定
56
Ruscio, J., Walters, G. D., Marcus, D. K., & Kaczetow, W. (2010). Comparing the relaAve fit of categorical and dimensional latent variable models using consistency tests. Psychological Assessment, 22(1), 5.

✅ データの適切性
D. 順序カテゴリカルindicator ・4件法以下の尺度 indicator数 < 5で結果が不安定
・カテゴリ数 < 4 で不正確になる
57
Ruscio, J., Walters, G. D., Marcus, D. K., & Kaczetow, W. (2010). Comparing the relaAve fit of categorical and dimensional latent variable models using consistency tests. Psychological Assessment, 22(1), 5.

✅ データの適切性
E. indicatorの妥当性 - 群間の標準平均値差 - 群内の共分散 (相関) - indicatorの歪度 (skew) - 十分な信頼性・因子負荷
58

✅ データの適切性
群間の標準平均値差 - taxon群とcomplement群間の標準化平均値差 ・事前の検討:尺度のカットオフ値等で群分け ・事後の検討:推定されたtaxon base rate に基づく群分け
59
標準化平均値差、d = 1.25以上

✅ データの適切性
群内相関 - taxon群とcomplement群の各群内での indicatorの相関 - taxonが存在するなら、局所独立なので、 群内相関は理想的には0
60
群内相関、r = 0.25以下

✅ データの適切性
歪度・因子負荷 - indicatorの歪度が高いと、分析結果が不正確 - 信頼性低、因子負荷低のindicatorは、 当該の構成概念を適切に反映していない。
61
先行研究で十分に信頼性と妥当性が
確認されている尺度を用いる
indicator選定のために、taxometric分析実施前に行うのもあり

✅ データの適切性
記載例) 結果の節
62
Liu, R. T., Jones, R. N., & Spirito, A. (2015). Is adolescent suicidal ideaAon conAnuous or categorical? A taxometric analysis. Journal of abnormal child psychology, 1-‐8.
群間差 The second requirement is for a large between-groups effect size between the putative taxon and non-taxon members of Cohen’s d > 1.25 [13,47]. All the items meet this assumption (Table 2).
群内分散 (相関) The third assumption is that there is little nuisance covariance, which refers to the correlations between indicator variables within the taxon and non-taxon groups. A correlation of r < 0.3 has been recommended previously, and that the correlation between items across the whole sample is greater than the correlation between items in the taxon [13]. Neither of the measures met this assumption,
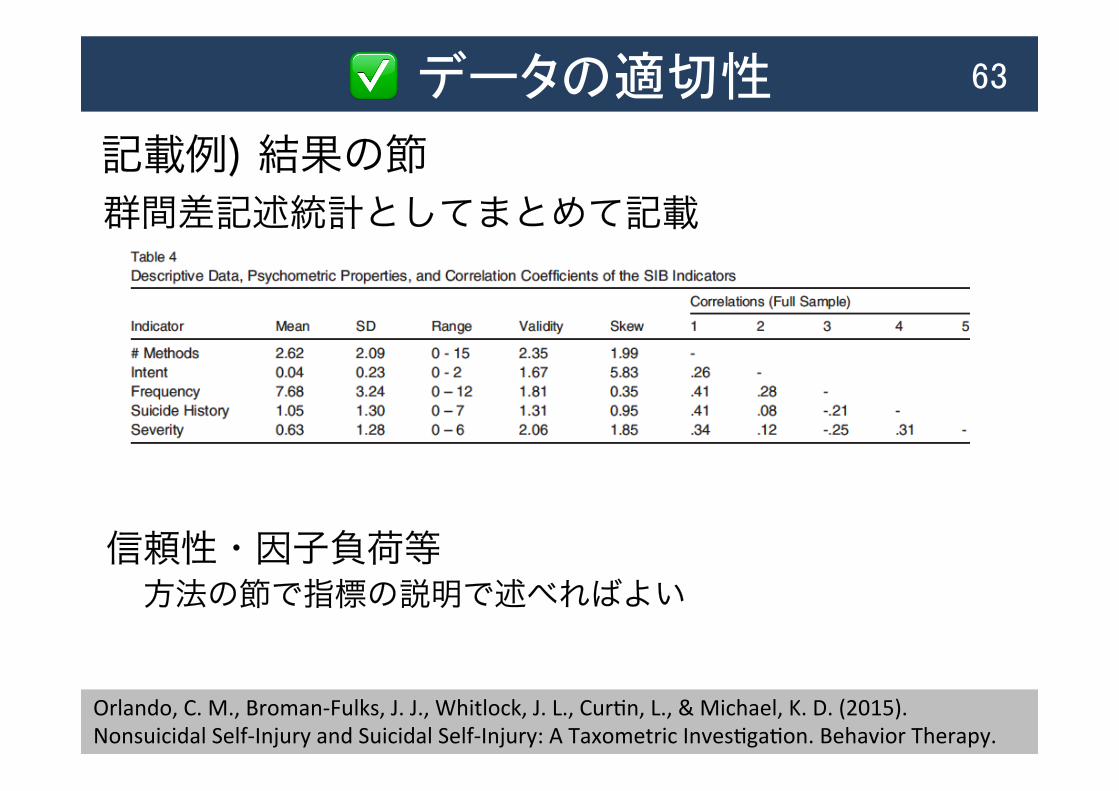
記載例) 結果の節
✅ データの適切性 63
群間差記述統計としてまとめて記載
Orlando, C. M., Broman-‐Fulks, J. J., Whitlock, J. L., CurAn, L., & Michael, K. D. (2015). Nonsuicidal Self-‐Injury and Suicidal Self-‐Injury: A Taxometric InvesAgaAon. Behavior Therapy.
信頼性・因子負荷等 方法の節で指標の説明で述べればよい

記載例) 結果の節
✅ データの適切性 64
因子分析によるindicatorの選択
Liu, R. T., Jones, R. N., & Spirito, A. (2015). Is adolescent suicidal ideaAon conAnuous or categorical? A taxometric analysis. Journal of abnormal child psychology, 1-‐8.

✅ データの適切性
その他. 以下のような標本の操作は原則禁止
i) 標本の追加・混合
ii) サブグループ化
iii) complement memberをトリミング
65
taxonが得られる恣意的に標本操作をするのはNG

✅ 多様な分析手続き
・一貫性テスト(consistency test)を必ず実施 多様な分析手続き間で、連続・非連続の 結果が一貫しているか検討 主な方法: 異なる分析手法間での一貫性 異なるindicator間での一貫性
66

✅ 多様な分析手続き
・一貫性テスト 複数の方法から得られたCCFIを平均 判断の基準は一つずつの場合と一緒
67
CCFIの値 判断
0.00-‐0.39 連続
0.40-‐0.60 どちらとも言えない
0.61-‐01.0 非連続
他にも一貫性の検討手法が存在するが、CCFIに基づくのが最も良い

発表の構成 68
理 論
書き方
実 装
各分析手法の理論解説
研究を始める前に知っておきたい 論文執筆上のチェックポイント
Rによるtaxometric分析の実施 出力結果の解釈

Ruscioのページ
クリックして、「Manual 2014-‐07-‐29.rdata」をダウンロード. 任意のフォルダに保存
69

Manual 2014-‐07-‐29.rdata
RまたはRStudioで開く
これだけで準備完了!!
70

Taxometric分析に必要なコード 71
サンプルデータ (読み込んだ.rdataに入ってる) カテゴリカル:TS1〜TS4 連続:DS1〜DS4
# 先頭6行のみ表示
データセットの中身

Taxometric分析に必要なコード
> MAMBAC(TS2)
> MAXEIG(TS2)
> LMode(TS2)
これだけで、taxometric分析に必要な全ての結果が出力される!!
indicator3つでMAXCOV, 4つ以上でMAXEIG
72

出力の見方 73
プロットが自動で出力される
0 200 400 600 800 1000
0.07
0.08
0.09
0.10
0.11
0.12
Categorical Comparison Data
50 Cuts
Mea
n D
iffer
ence
0 200 400 600 800 1000
0.07
0.08
0.09
0.10
0.11
0.12
Dimensional Comparison Data
50 Cuts
Mea
n D
iffer
ence
この出力がそのまま論文に掲載できる
非連続の場合の理想と比較 連続の場合の理想と比較
(MAMBAC)
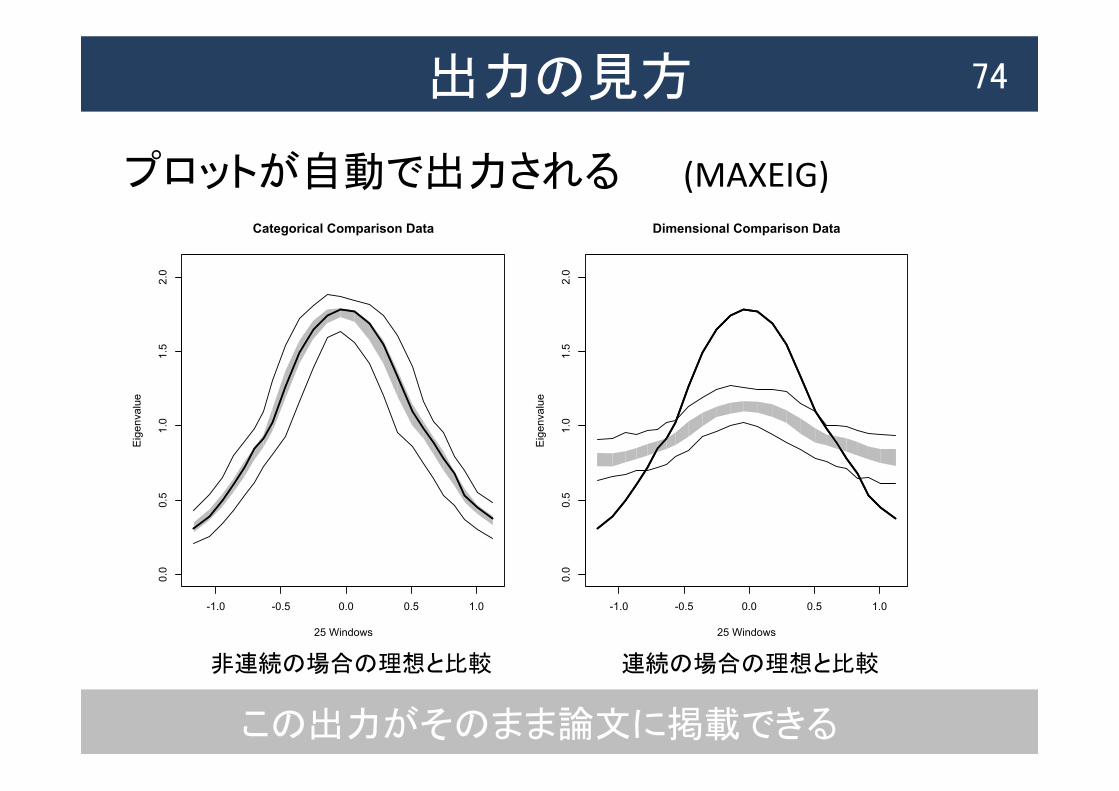
出力の見方 74
プロットが自動で出力される
この出力がそのまま論文に掲載できる
非連続の場合の理想と比較 連続の場合の理想と比較
(MAXEIG)
-1.0 -0.5 0.0 0.5 1.0
0.0
0.5
1.0
1.5
2.0
Categorical Comparison Data
25 Windows
Eigenvalue
-1.0 -0.5 0.0 0.5 1.0
0.0
0.5
1.0
1.5
2.0
Dimensional Comparison Data
25 Windows
Eigenvalue

出力の見方 75
プロットが自動で出力される
この出力がそのまま論文に掲載できる
非連続の場合の理想と比較 連続の場合の理想と比較
(LMODE)
-2 -1 0 1 2
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Categorical Comparison Data
Factor Scores
Density
-2 -1 0 1 2
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Dimensional Comparison Data
Factor Scores
Density

出力の見方 76
サンプルサイズ、indicatorの数、cutpointの値など、基礎情報

出力見方 77
Taxon base rate (MAMBAC)
指標の全組み合わせでMAMBAC 1. 全体の平均 2. indicatorごとの平均 3. indicatorごとの平均の平均
論文では、赤線で囲った値を報告すればよい
出力の見方 78
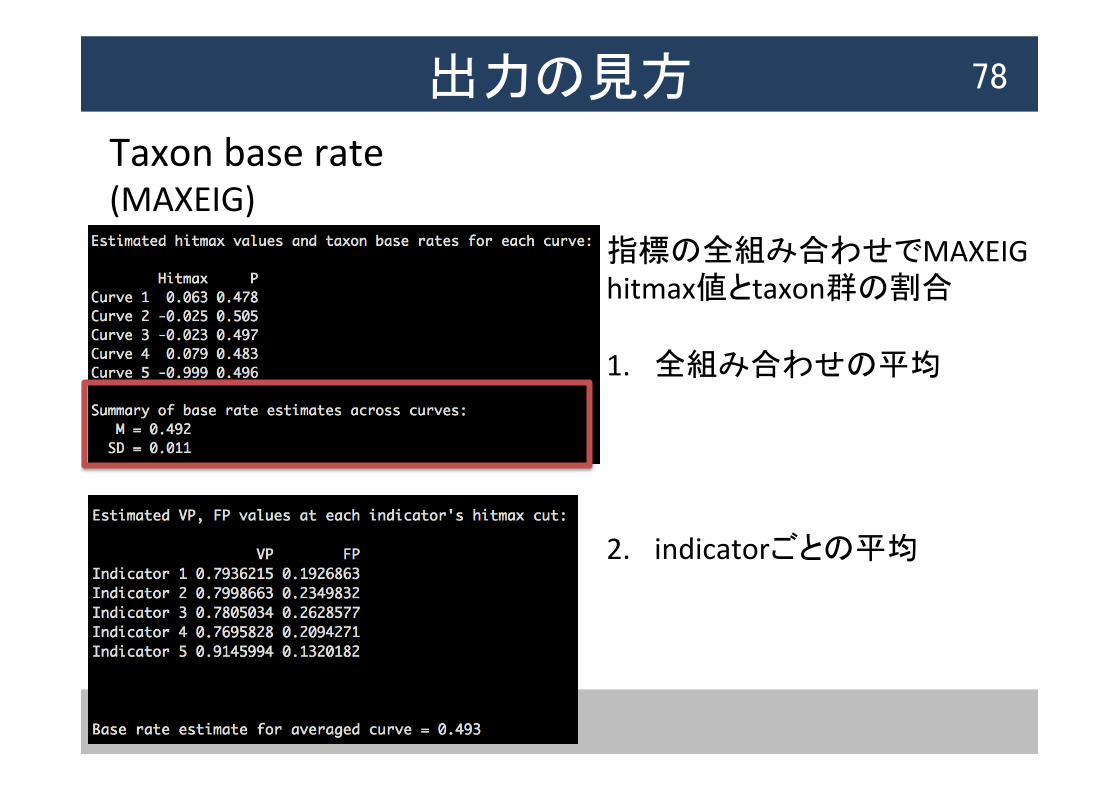
Taxon base rate (MAXEIG)
指標の全組み合わせでMAXEIG hitmax値とtaxon群の割合
1. 全組み合わせの平均
2. indicatorごとの平均

出力の見方 79
Taxon base rate (LMODE)
2峰の因子得点のピーク値の平均に基づいて、taxon base rate算出
各群のindicatorごとの因子得点の平均値を算出

出力の見方 80
indicatorの記述統計量 (平均、SD、歪度、尖度) 標本全体
taxon群 complement群
非連続の場合には、各群の値と人数の報告、連続であれば全体のみ
歪度(skew)の値をチェック 3〜2以下が目安

出力の見方 81
indicatorの妥当性
dが1.25以上がチェック
論文で必ず報告

出力の見方 82
indicator間の相関 (全サンプル)
記述統計として、平均・SDとともに報告した方が良い

出力の見方 83
indicator間の相関
各相関の平均は、論文に必ず報告
群内で、indicator間に 大きな相関がないか チェック
各相関の平均
出力の見方 84
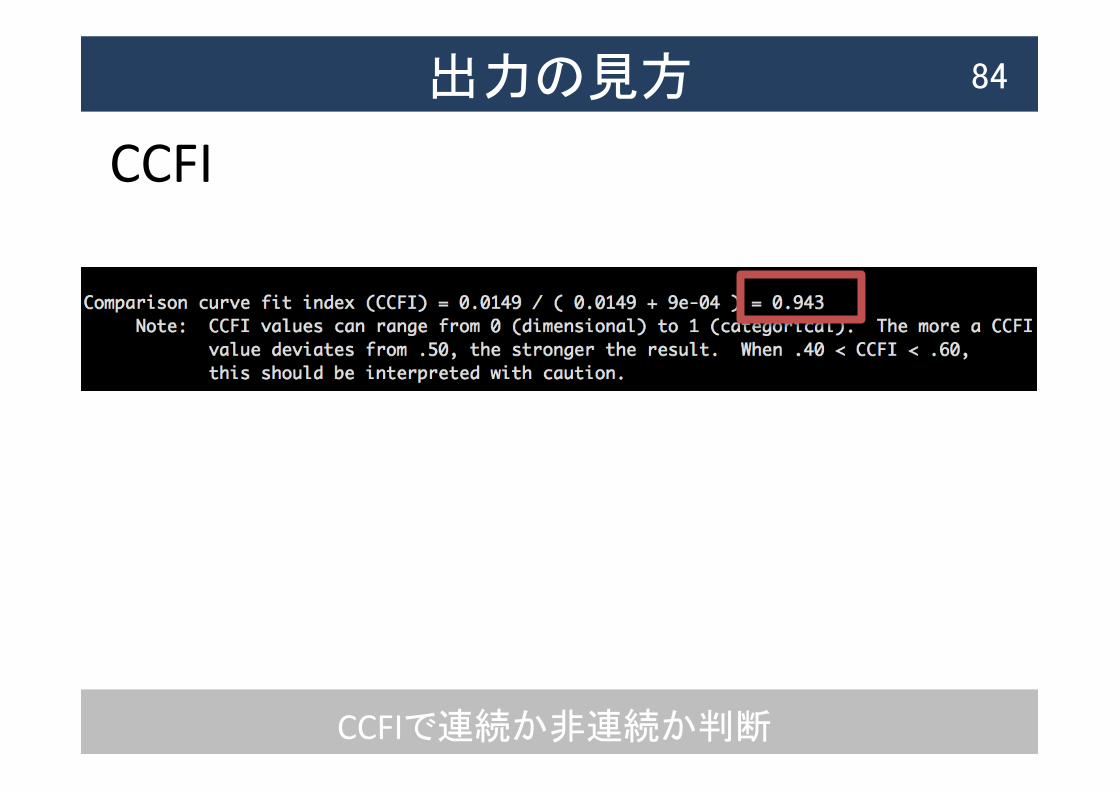
CCFI
CCFIで連続か非連続か判断

他の分析手法との比較 85
taxometric LCA / LPA
前提 indicatorの妥当性 群内分散低
多変量正規性 局所独立性
結果 連続か非連続の2値判断 taxon base rateに基づく、 群の構成割合
所属確率に基づく、 群の構成割合、 各群への所属確率
強み 連続モデルかどうかの判断に強い indicatorの分布に関する強い制約はない
クラス分けに強い クラスの特徴を詳細に検討できる。
使い分けの私見 連続か質的かの知見がないまたは乏しい → taxometricを実施 質的である可能性が高い → LCAで質の特徴を検討

最近のトレンド:Factor mixture model 86
症状 A
症状 D
症状 B
症状 C
症状 E
factor
e1 e2 e3 e4 e5
factorは 連続潜在変数
classは カテゴリ潜在変数
因子モデル + 潜在クラス分析
class
※イメージ:LModeをSEMの枠組みで検討

FFM 87
Class 1 Class 2
!A
D!
!B
C
E!
factor
e1 e2 e3 e4 e5
!A
D!
!B
C
E!
factor
e1 e2 e3 e4 e5
因子得点の平均や因子負荷が異なるクラスが抽出される
※イメージ:多母集団同時分析の母集団が未知なモデル

TaxometricとFMMを併用
• FMMでは因子モデルの潜在変数の分布を検討するので、Taxometricと目的が一致
• 感度解析的に両者を使用
• Taxometricで質的・連続を判断し、質的ならFMMで詳細な検討がベスト (私見)
88
Bernstein, A., SAckle, T. R., Zvolensky, M. J., Taylor, S., Abramowitz, J., & Stewart, S. (2010). Dimensional, categorical, or dimensional-‐categories: tesAng the latent structure of anxiety sensiAvity among adults using factor-‐mixture modeling. Behavior Therapy, 41(4), 515-‐529.
参考

おまけ:FFMのMplusコード 89
ANALYSISやVARIABLEコマンドは 潜在クラス分析と一緒 MODELコマンドに因子分析モデルを指定 MODEL: %OVERALL% f on item1 – item6;

TAKE HOME MESSAGE 90
• Taxometric, 潜在変数の分布の連続性を、観測変数間の関連指標のプロットで判断
• indicatorの妥当性を群間差等で必ずチェック
• 連続性の判断はCCFIの値を参照
• 複数の分析法とindicator構成で一貫性テスト