Современные проблемы системного … · windows 3.1 1992 3 windows nt...
TRANSCRIPT

Современные проблемы системного программирования
Иванников Виктор ПетровичИванников Виктор ПетровичИнститут системного программирования РАН (ИСП РАН)
http://ispras.ru/
12 февраля 2013 года
ФУПМ МФТИ

Сложность современного ПО
Система Год Размер (106 LOC) Размер команды
Windows 3.1 1992 3
Windows NT 3.5 1994 10 300
Windows NT 4.0 1996 16 800
Windows 2000 1999 30 1400
2
Windows XP 2001 45 1800
Linux Kernel 2.6.0 2003 5,7
Open Solaris 2005 9,7
Mac OS X 10.4 2006 86
Windows Vista 2007 > 50
Вся авионика США (бортовая и наземная)
2007 ~1000
Дистрибутив Debian 5.0 2009 323
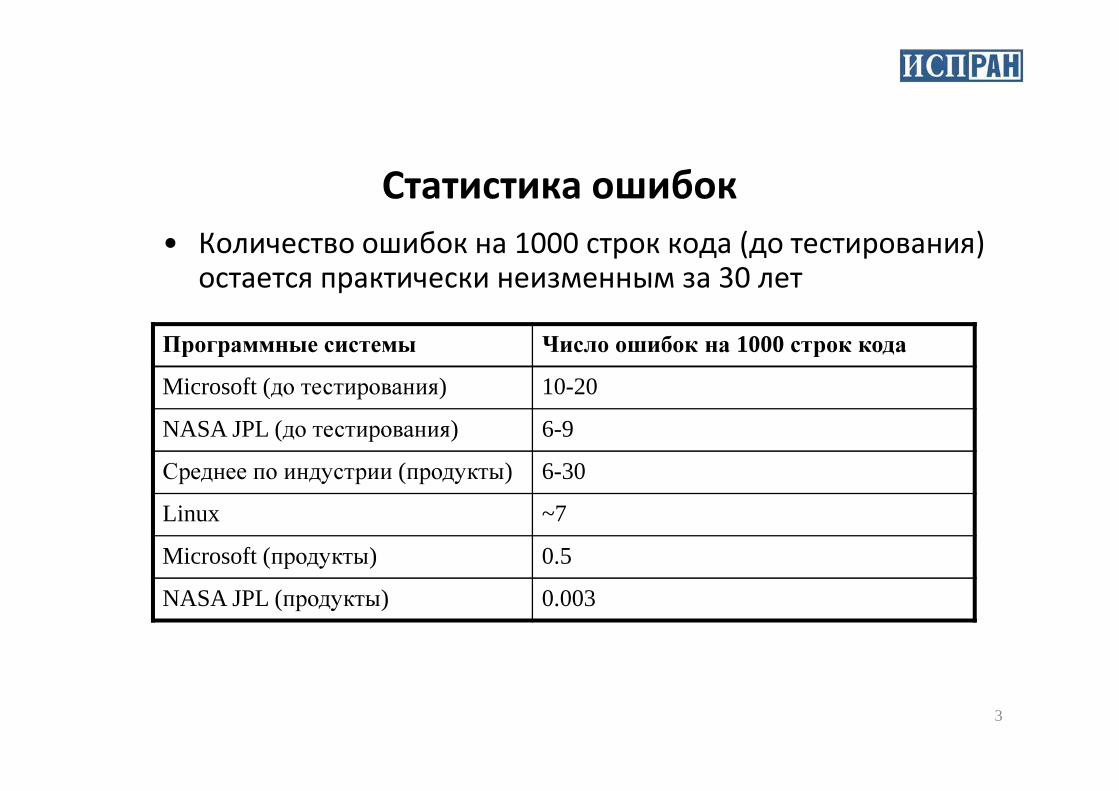
Статистика ошибок
• Количество ошибок на 1000 строк кода (до тестирования) остается практически неизменным за 30 лет
Программные системы Число ошибок на 1000 строк кода
Microsoft (до тестирования) 10-20
3
Microsoft (до тестирования) 10-20
NASA JPL (до тестирования) 6-9
Среднее по индустрии (продукты) 6-30
Linux ~7
Microsoft (продукты) 0.5
NASA JPL (продукты) 0.003

Верификация и информационная
безопасность программ
• Наличие ошибки в программе часто означает наличие уязвимости
• Технологии верификации одновременно являются средствами оценки и обеспечения информационной средствами оценки и обеспечения информационной безопасности программ
• Вывод: повышение информационной безопасности программ без развития технологий верификации невозможно
4

Сложность микропроцессоров
Микропроцессор
• > 109 транзисторов
• > 107 строк на Verilog
• ~4-10 ядер
Проектирование
• > 500 разработчиков 29 тыс (8086)
3.1 млн (Pentium)
800 нм
42 млн (Pentium 4)
180 нм 731 млн (Core i7)
45 нм
5 млрд (Xeon Phi)
22 нм
4,0
6,0
8,0
10,0
12,0
Число транзисторов на кристалле (log10
)
• > 500 разработчиков
• ~3-4 года работы
• > 100 млн долларов
Верификация – более 60% затрат на проектирование микропроцессора!
• > 10 000 ошибок проектирования (в спецификациях, Verilog-коде и т.д.)
• > 100 инженеров-верификаторов (модели, тесты, формальные методы)
• > 1000 компьютеров (круглосуточное моделирование и прогон тестов)
5
2,2 тыс (4004)
10 мкм
29 тыс (8086)
3 мкм
0,0
2,0
4,0
1965 1970 1975 1980 1985 1990 1995 2000 2005 2010 2015
Число транзисторов
удваивается каждые 2 года

Актуальные проблемы
• Автоматическая генерация функциональных тестов на
основе разного рода моделей
• Глубокий статический анализ Verilog-описаний цифровой
аппаратуры (потенциальные ошибки, мертвый код и т.п.)
• Автоматический поиск зависаний (deadlocks) в • Автоматический поиск зависаний (deadlocks) в
микроархитектурных моделях процессоров
• Формальная верификация протоколов обеспечения
когерентности памяти в многоядерных процессорах
• Распараллеливание верификации, обработка больших
графов (генерация тестов и проверка моделей)
6

Технологии верификации
• Экспертиза
• Тестирование (динамические испытания)
• Аналитическая верификация• Аналитическая верификация
• Статический и динамический анализы
исходного кода
• Комбинированные подходы
7

Экспертиза
• Поиск ошибок, оценка и анализ свойств ПО человеком (обычно группа 2-5 человек)
• Техники
– Списки важных ограничений и шаблонов ошибок
– Групповые обсуждения
• Производительность : 100-150 строк / час• Производительность : 100-150 строк / час
– Не более 2-3 часов в день
• Результаты : выявляется 50-90% ошибок (обнаруживаемых за
все время жизни ПО)
• Нужны настоящие эксперты, программисты с менее чем 10-летним стажем могут участвовать лишь как обучающиеся
8

Тестирование
• Оценка корректности системы по ее работе в выбранных ситуациях, с определенными данными
• Техники:
– Шаблоны сценариев, перебор и фильтрация
– Синтез тестов по структуре реализации или модели
• Производительность : сильно зависит от целей, техники, опыта • Производительность : сильно зависит от целей, техники, опыта и пр.
– Microsoft : производительность разработки тестов и тестирования примерно такая же, как у создателей кода, 10 строк/час
• Результаты : выявляется 30-80% ошибок
• Часто используется неопытный персонал, что отрицательно сказывается на качестве
9

Пример : проект DMS (ИСП РАН)
• Разработка тестов для ОС телефонного коммутатора Nortel Networks с использованием формальных методов
• Размер системы : 250 000 строк, 230 интерфейсных функций
• Трудоемкость : ~ 10 человеко-лет• Трудоемкость : ~ 10 человеко-лет
• Результаты:– Тестовый набор использовался для проверки всех новых версий ОС
– > 300 ошибок в системе с заявленной надежностью 99.9999%
– 12 ошибок, требующих холодного рестарта
– ~ 50% всех ошибок найдены в ходе экспертизы
– Остальные выявлены тестами, сгенерированными из формальных
спецификаций и нацеленными на их покрытие
10

Общая схема
Данные, оракул, покрытие
Пред-условия,итераторы
Тестовая системаТестовые
данные
Пост-условия
Отчеты
Тестовый сценарий
Ожидаемые
результаты,критерии
полноты
Тестируемая
система
11

Показатели качества тестирования
• Метрики тестового покрытия
– Функциональности программы и требований
– Структуры кода: строк, ветвлений, комбинаций условий в
ветвлениях
• Для адекватной оценки нужно сочетание нескольких • Для адекватной оценки нужно сочетание нескольких
метрик
• Примеры достигаемого тестового покрытия :
– Обычное коммерческое ПО : 15-20% ветвлений в коде
– Системное ПО : 60-80% ветвлений в коде
– Тесты на базе формальных моделей : 70-80% ветвлений в коде
– Аналитическая верификация : 100% ветвлений в коде
12

Аналитическая верификация
• Формальное описание семантики программы и требований и доказательство выполнения требований
• Техники:
– Метод Флойда (дедуктивный метод)
– Provers, solvers, интерактивные инструменты
• Инструменты:• Инструменты:
– Мировые лидеры: PVS, Isabelle/HOL, Frama-C
• Примеры приложений: микропроцессоры, ядро операционной системы seL4
• Опыт ИСП РАН: практикум по верификации с помощью Frama-C (~ 100 человеко-часов на программу размером порядка 100 строк)
13

Пример: верификация ядра ОС seL4
• Ядро встроенной ОС seL4
– 8700 строк на C, 600 строк на ассемблере
– Для реализации ~2.5 человеко-года
• Верификация
– 200 000 строк формальной модели
– Инструмент: Isabelle/HOL
– Трудоемкость – 20 человеко-лет (12 чел.)
Доказано ~10000 лемм
14

Статический
анализ
программпрограмм
15

f(char * p)
{ char s[6];
strcpy(s,p);
}
main1 ()
{ f(“hello”);
}
Стек после выполнения функции f, вызванной из main1
Стек после выполнения функции f, вызванной из main2
адрес
На место адреса main2 записали
Адрес main1
Простейший пример
}
main2 ()
{ f(“privet”);
}\0
o
l
l
e
h
t
\0
e
v
i
r
p
массив sВ случае main2 адрес возврата перезапишется и управление будет передано не на main2, а на другой участок кода
адрес возврата
записали лишний байт
main1
16

Рассматриваемые виды дефектов
� Переполнение буфера
� Format string: недостаточный контроль параметров при использовании функций семейства printf/scanf
� Tainted input: некорректное использование непроверяемых на корректность пользовательских непроверяемых на корректность пользовательских данных
� Разыменование нулевого указателя
� Утечки памяти
� Использование неинициализированных данных
17

Преимущества статического анализа
� Автоматический анализ многих путей исполнения одновременно
� Обнаружение дефектов, проявляющихся только на редких путях исполнения, или на необычных входных данных (которые могут быть установлены входных данных (которые могут быть установлены злоумышленником в процессе атаки)
� Возможность анализа на неполном наборе исходных файлов
� Отсутствие накладных расходов во время выполнения программы
18
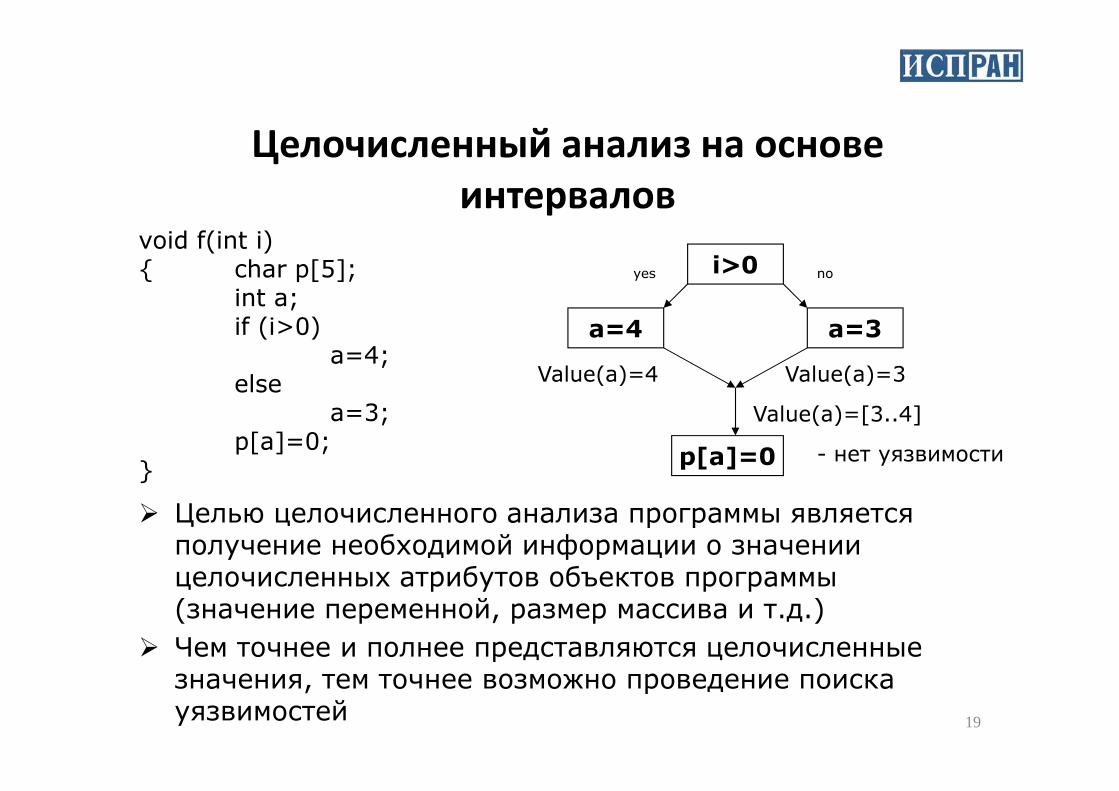
void f(int i){ char p[5];
int a;if (i>0)
a=4;else
i>0
a=4 a=3
yes no
Value(a)=3Value(a)=4
Целочисленный анализ на основе
интервалов
� Целью целочисленного анализа программы является получение необходимой информации о значении целочисленных атрибутов объектов программы (значение переменной, размер массива и т.д.)
� Чем точнее и полнее представляются целочисленные значения, тем точнее возможно проведение поиска уязвимостей
elsea=3;
p[a]=0;}
p[a]=0
Value(a)=[3..4]
- нет уязвимости
19

void f(int i){ char p[5];
int a,b,c;if (i>0)
a=0;else
a=1;
i>0
a=0 a=1
yes no
Value(a)=1Value(a)=0
Size(p)=5
Недостатки целочисленного
анализа интервалов
� Потеря точности в некоторых случаях.
� Отсутствие информации о связях между переменными: в случае анализа на основе интервалов в последней инструкции примера будет обнаружена ложная уязвимость.
a=1;b=a+4;c=b-a;p[c]=0
}
b=a+4
Value(a)=[0..1]
c=b-a
p[c]=0
Value(a)=[0..1]Value(b)=[4..5]Value(c)=[3..5]
Value(a)=[0..1]Value(b)=[4..5]
Value(a)=[0..1]Value(b)=a+4
Value(a)=[0..1]Value(b)=a+4Value(c)=4
Value(c)<Size(p)
Value(c) может быть равным Size(p) => ложная ошибка 20

Необходимость межпроцедурного анализа
f(char *p, char *s)
{ strcpy(p,s); // произойдет копирование 6 байт, включая //конец строки
}
main()main()
{ char *p;
p=malloc(5);
f(p,”hello”);
}
В приведенном примере указатель на объект размером 5 байт передается в функцию f, поэтому без межпроцедурного анализа эта информация никаким образом не попадет на вход вызову функции strcpy и ошибку не зафиксируется
21

Необходимость анализа указателей
…
char a[10];
char * p;
p=a;
p[10]=0;
……
Для данного примера в случае отсутствия анализа указателей невозможно сделать никаких предположений о размере массива, на который указывает p и, следовательно, невозможно определить наличие ошибки
22

Защита доверенных программ от
скомпрометированной ОС
• Злоумышленники могут атаковать:– Исполнимый код в файле на диске
– Оперативную память процесса из ядра ОС
– Образ памяти в файле подкачки
– Потоки данных ввода-вывода внутри ядра (драйверов)
– Ввод-вывод в обход механизмов защиты (файервол, антивирус)
• Ядро защиты: гипервизор (виртуализация)• Ядро защиты: гипервизор (виртуализация)– Приоритет выше ядра, перехват привилегированных операций и
переключений контекста
– Проверка целостности кода после загрузки
– Проверка целостности памяти процессов при переключении контекстов, загрузки из файла подкачки
– Перенаправление ввода-вывода приложений в обход ядра в доверенную сервисную виртуальную машину
– Блокировка доступа к сети для недоверенных процессов и ядра ОС
23

Современные компиляторные технологии
� Необходимы для решения важных IT-задач
� Производительность программ (статические
компиляторы GCC, LLVM)
� Размер кода (мобильные системы)
� Энергопотребление (мобильные системы и кластеры)
� Оптимизация сверхбольших программ � Оптимизация сверхбольших программ
(Firefox, программы Google)
� Динамическая оптимизация (JavaScript, Java, C#)
� Обеспечение портируемости и облегчение
развертывания программ
(одна версия программы для разных архитектур)
� Обеспечение безопасности программ
(поиск уязвимостей и критических дефектов)24

Исследования компиляторных технологий
� Анализ и оптимизация программ
� Машинно-независимые трансформации, учет
особенностей целевой архитектуры и профиля
пользователя (ускорение 20% до 3х и более)
Межмодульные оптимизации сверхбольших программ � Межмодульные оптимизации сверхбольших программ
ускорение на 5-10%, сокращение кода на 10-40%
� Динамическая оптимизация (JIT) “горячих” участков
(баланс между качеством кода и скоростью JIT)
ускорение JavaScript в Webkit ~300% (25% - 1250%)
� Переносимость программ на Си/Си++
25

Анализ бинарного кода
• Анализ кода отдельной программы недостаточен– Функциональность распределена по нескольким процессам, библиотекам,
использует недокументированные возможности ОС
– Неизвестная ОС, сильно модифицированная версия Linux/BSD/…
– Требуется выполнять анализ ПО в целом, включая прикладные и системные библиотеки, код ОС
• Код программ меняется во время работы– Динамически загружаемые библиотеки, JIT-компиляция,
самомодификация кодасамомодификация кода
– Требуется уметь представлять в статическом виде меняющийся код
• Программа распределена по нескольким компьютерам, часть кода недоступна– Из-за замедления работы отладчик неприменим
– Требуется трассировка без замедления работы
• Код программ содержит защиту от анализа– Антиотладочные приемы, контроль целостности кода
– Запутывание: «мусорный» код, усложненные потоки управления и данных, виртуальные машины
– Требуется сокрытие факта анализа (трассировки)и преодоление запутывания
26

Текущие результаты
• Среда анализа TrEx– Расширяемый список целевых архитектур: Intel64, ARM, …
– Восстановление событий уровня ОС: обработчиков прерываний, переключение процессов/тредов, загрузка/выгрузка модулей программ, …
– Восстановление по нескольким трассам статического представления.
– Автоматическое выделение алгоритма – Автоматическое выделение алгоритма (анализ потоков данных и управления, слайсинг трассы)
– Восстановление управляющих конструкций и форматов данных (как часть задачи восстановления сетевого протокола)
• Сбор трасс: программный эмулятор QEMU– Детерминированное воспроизведение работы виртуальной
машины (включая периферийные устройства)
– Высокая скорость (замедление ~5%), малый объем записываемых данных (~40КБ/сек),
– Возможность обратной отладки
27

Актуальные направления исследований
• Автоматический поиск «утечек» секретной информации– Анализ помеченных данных
– Разметка в коде необратимых преобразований (шифрования)
• Автоматический поиск уязвимостей– Обнаружение дефектов (переполнение буфера)
– Построение входных данных, на которых дефект позволит – Построение входных данных, на которых дефект позволит выполнять произвольный код
• Восстановление сетевых протоколов– Конечный автомат (описание состояний)
+ формат сообщений (описание условий перехода)
• Новые классы задач– Мобильные устройства: планшеты и смартфоны
– Программы, использующие криптографическую аппаратуру
– …
28

Обработка информации
• Большая часть всей информации находится в слабо формализованном виде (текст, фотографии, данные с датчиков и т.д.). Даже программная документация на 70-80% неформализована
• Проблемы анализа и обработки неструктурированной информацииинформации
– Как автоматически проверять объективность, достоверность, полноту и актуальность информации?
– Не существует достаточно удобного поиска по изображениям (попробуйте найти конкретную фотографию из любой социальной сети с помощью поискового запроса)
– Поиск текстовой информации тоже часто вызывает затруднения (на этом основан Кубок Яндекс)
29

Классические задачи обработки текстов
• Информационно-поисковые системы (Яндекс,
Google, Bing, …)
• Вопросно-ответные системы (Wolfram Alpha)
• Диалоговые системы (Apple Siri)
• Машинный перевод (Google translate, Promt)• Машинный перевод (Google translate, Promt)
Для полноценного решения любой из этих
задач необходимо научить компьютеры
понимать семантику (смысл) текстов.
30

Семантика и проблема понимания
• Представление знаний
– Открытая задача
– Существуют формальные методы описания знаний
(онтологии, семантические сети, тезаурусы)
• Извлечение знаний• Извлечение знаний
– Вручную
– Автоматически
– Автоматизировано
31

Проблемы извлечения знаний
• Множество неструктурированных источников
знаний (энциклопедии, учебники, патенты,
научные статьи)
• Как можно извлечь знания из этих источников?Как можно извлечь знания из этих источников?
• Как использовать эти знания для понимания
семантики обрабатываемых данных?
• Как при этом извлекать новые знания из
обрабатываемых данных?
32

Система Текстерра
• Автоматическое извлечение онтологии из Википедии (несколько языков)
• Методы подсчета семантической близости между извлеченными понятиями
• Набор методов для анализа текстовых данных и • Набор методов для анализа текстовых данных и извлечения знаний из них
• Приложения
– Семантический поиск по блогосфере (blognoon)
– Система рекомендаций
– Автоматическое реферирование
– И др.33

Анализ социальных сетей
� С позиций data mining – разреженный граф огромной
размерности. Пример -
� 1 млрд пользователей, 100 млрд связей
� 2,7 млрд новых оценок и комментариев ежедневно
� 250 млн новых фотографий ежедневно
� Пользователь в среднем имеет аккаунты в 3 разных сетях� Пользователь в среднем имеет аккаунты в 3 разных сетях
� Рост числа аккаунтов с 2011 года составил 28% (с 2,4 до 3,1 млрд)
� Прогноз на 2015 год: 3,9 млрд аккаунтов и 1,2 млрд
пользователей
� Глобально состоит из иерархии кластеров, отражающих
географическую близость пользователей и похожие интересы
� Уникальный источник данных о личной жизни и интересах
людей: переписка, дневники, фотоальбомы34

Направления работы
� Поиск сообществ пользователей
� Оценка информационного влияния
� Определение скрытых атрибутов пользователей
по текстам сообщений (пол, возраст)
� Определение эмоциональной окраски � Определение эмоциональной окраски
сообщений
� Рекомендация контента и пользователей
� Построение тематического профиля интересов
пользователя или сообщества
35

Ключевые проблемы
Большие данные
� 1 млрд пользователей, 100 млрд связей
� Данные постоянно обновляются, поступают в потоке
� Поиск компромиссов между качеством результатов,
производительностью и масштабируемостью
� Осваивание и развитие стремительно растущего стека технологий
Новые модели и алгоритмы
� Необходимость комбинации графовых алгоритмов с алгоритмами
обработки текстов, фото, видео, логов
� Изучение закономерностей общения и обмена информацией
� Потребность в новых математических моделях для тестирования
гипотез
� Потребность в новых сервисах для облегчения коммуникации
36

Спасибо за внимание!
Пожалуйста, вопросы.Пожалуйста, вопросы.
37