2. introducción y conceptos básicos
TRANSCRIPT

Bases de datos distribuidasIntroducción y conceptos básicos

Complicaciones introducidas por la distribuciónReplicación en un ambiente distribuido
◦Escoger una de las copias en caso de recuperación.
◦Asegurarse que la actualización se refleje en cada una de las copias.
Si algún sitio o enlace de comunicación falla mientras se ejecuta una actualización, el sistema debe asegurarse que los efectos se reflejen en los datos.
La sincronización de transacciones en múltiples sitios es más difícil que en los sistemas centralizados.

CUESTIONES (PROBLEMAS) DE DISEÑO

Diseño de bases de datos distribuida¿Dónde se deben establecer
(sitios) las bases de datos y las aplicaciones que corren sobre ella?
Existen dos alternativas para establecer o posicionar los datos en un diseño distribuido.

Diseño de bases de datos distribuidasParticionada (no replicada): La base de
datos se divide en un número de particiones disjuntas las cuales se posicionan en diferentes sitios.
Replicada◦Completamente replicada (completamente
duplicada): donde la base de datos entera se almacena en cada sitio.
◦Parcialmente replicada (parcialmente duplicada): donde cada partición se almacena en más de un sitio, pero no en todos.

Diseño de bases de datos distribuidasLos problemas fundamentales de
diseño son:◦Fragmentación: separación de una
base de datos en particiones llamadas fragmentos.
◦Distribución: La distribución óptima de los fragmentos.

Administración del directorio distribuidoMetadatos.Los problemas relacionados con
el directorio distribuido son muy similares a los presentados con los DDBS’s.

Procesamiento de consultas distribuidasAlgoritmos que analizan
consultas y las convierten en una serie de operaciones de manipulación de datos.
Elegir estrategias para ejecutar consultas sobre la red con el mejor costo-eficiencia.
Factores: distribución de los datos, costo de la comunicación, carencia de suficiente información disponible localmente.

Control de concurrencia distribuidoSincronización de accesos a la base de
datos distribuida.Además de preocuparse por la integridad
de los datos, debe preocuparse de la “consistencia mutua”.
Las clases de soluciones son:◦Pesimista: Sincronizar la ejecución de las
peticiones de los usuarios antes de que comiencen a ejecutarse.
◦Optimista: Ejecutar las peticiones y después checar si la ejecución ha comprometido la consistencia de la base de datos.

Control de concurrencia distribuidoLos principios fundamentales que
pueden utilizarse en las clases de soluciones son:◦Bloqueo (locking): Basado en la
exclusión mutua de accesos a objetos de datos.
◦Sello de tiempo (timestamping): La ejecución de las transacciones se ordenan con sellos de tiempo.

Administración de puntos muertos (deadlocks) distribuidosLos usuarios compiten por un
conjunto de recursos (datos en este caso), lo cual puede resultar en un deadlock (punto muerto) si el mecanismo de sincronización está basado en bloqueo.

Confiabilidad de los DDBS’sfalla varios sitios inoperables o
inaccesibles las bases de datos en los sitios operables consistentes y actualizadas
Sistema se recupera DDBS se recupera DDBS actualiza los sitios caídos

ReplicaciónRéplica: copia de objeto de datos.Implementar protocolos que aseguren
la consistencia de las réplicas.◦Protocolo “entusiasta”: Fuerzan las
actualizaciones a todas las réplicas antes que la transacción se complete.
◦Protocolo “lento”: La transacción actualiza una copia (maestro) desde donde las actualizaciones se propagan hacia las demás copias una vez que se completa la transacción.

Relación entre los problemas

ARQUITECTURA

Arquitectura de los DDBS’sComponentes identificadosFunciones de los componentes
identificadasRelaciones e interacciones entre
componentes definidas

ANSI / SPARC
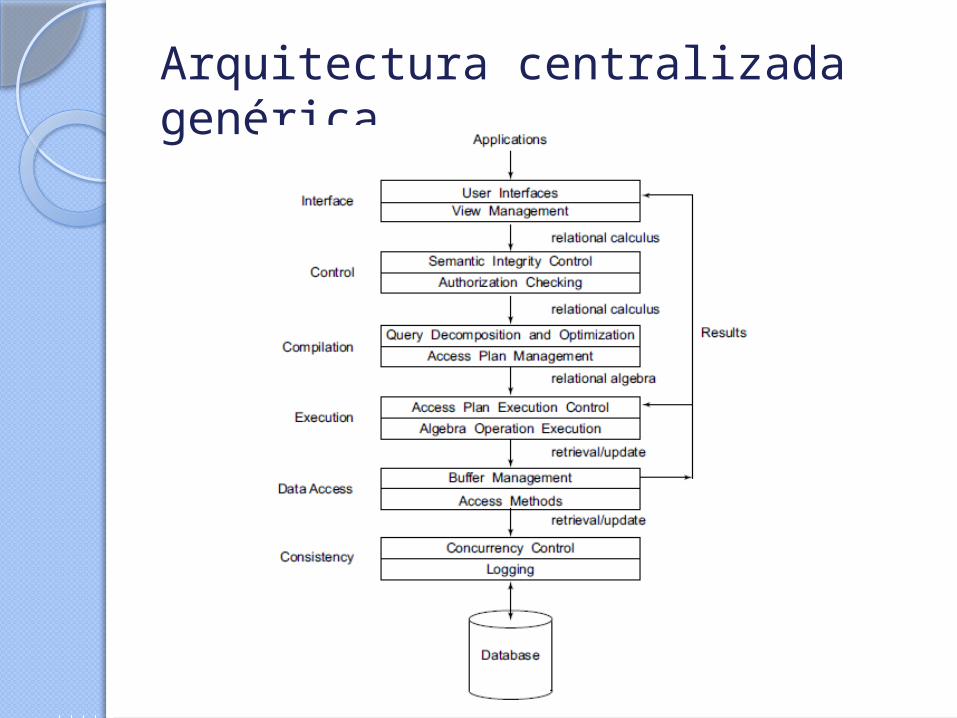
Arquitectura centralizada genérica

MODELOS DE ARQUITECTURA DE DDBS’S
Los DDBS’s se clasifican sobre 3 características

Modelos de arquitectura de DDBS’s

AutonomíaSe refiere a la distribución del control
(no de los datos).◦Las operaciones locales no son afectadas
por su participación en el sistema distribuido.
◦La manera en que procesa y optimiza consultas no son afectadas por la ejecución de consultas globales que acceden a múltiples bases de datos.
◦La consistencia de las operaciones o del sistema no se comprometen cuando se deja o se une al sistema distribuido.

AutonomíaLas dimensiones de autonomía son
las siguientes:◦Autonomía de diseño: Utilizan modelos de
datos y administración de transacciones que prefieran.
◦Autonomía de comunicación: Libre de decidir que tipo de información desea compartir con otros DBMS’s o con el software que controla su ejecución.
◦Autonomía de ejecución: Puede ejecutar las transacciones de la manera que desee.

AutonomíaClasificación de autonomía
◦ Integración estrecha (tight integration): Existe una única imagen de toda la base de datos que puede ser compartida y encontrarse en múltiples bases de datos, y un administrador de datos tomará el control de las peticiones de todos los usuarios.
◦Semiautónomo: deciden participar en una federación para compartir sus datos locales.
◦Aislamiento total: no conocen la existencia de otros DBMS’s ni la manera de comunicarse con ellos.

Distribución (datos)Cliente / servidor.Punto a punto.Sistemas de Bases de datos
múltiples.

HeterogeneidadLa heterogeneidad puede ocurrir de
varias maneras en sistemas distribuidos, desde la heterogeneidad del hardware y las diferencias en los protocolos de redes hasta las variaciones en las administraciones de datos.Modelos de datosLenguajes de búsquedaProtocolos de administración de
transacciones.