20140120 presto meetup
TRANSCRIPT

Prestoの利用事例と性能測定結果
Hironori OgibayashiShin Matsuura

自己紹介
● 荻林 裕憲(@angostura11) ● 松浦 晋
○ 通信会社の社内システム基盤部門勤務○ ミドルウェアを中心に、検証、設計、構築等
をやってます

今日話すこと
● Prestoの利用事例○ システム構成○ 用途○ 困ったこと/トラブル事例○ 今後の課題
● Hive+Tez/Prestoの性能比較

Prestoの利用事例
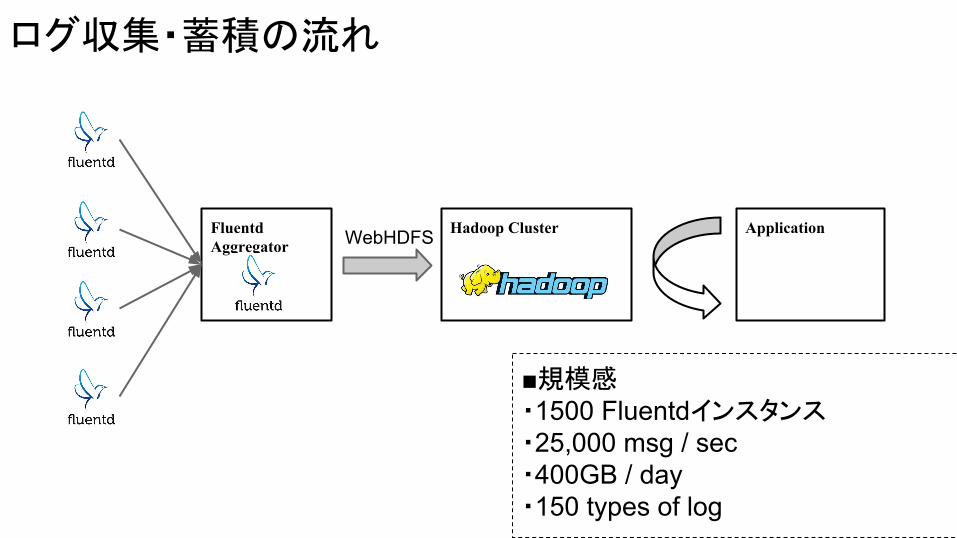
ログ収集・蓄積の流れ
FluentdAggregator
Hadoop Cluster ApplicationWebHDFS
■規模感・1500 Fluentdインスタンス・25,000 msg / sec・400GB / day・150 types of log

ログの用途
● 基盤部門が自分たちのために○ サーバ利用状況の確認○ Oracle DB性能分析ツール
● システム開発部門による分析○ システム・業務改善のため
ログの利用例

Why Presto?
● インタラクティブ/ad-hocな使い方が多い● 当然、速い方が嬉しい
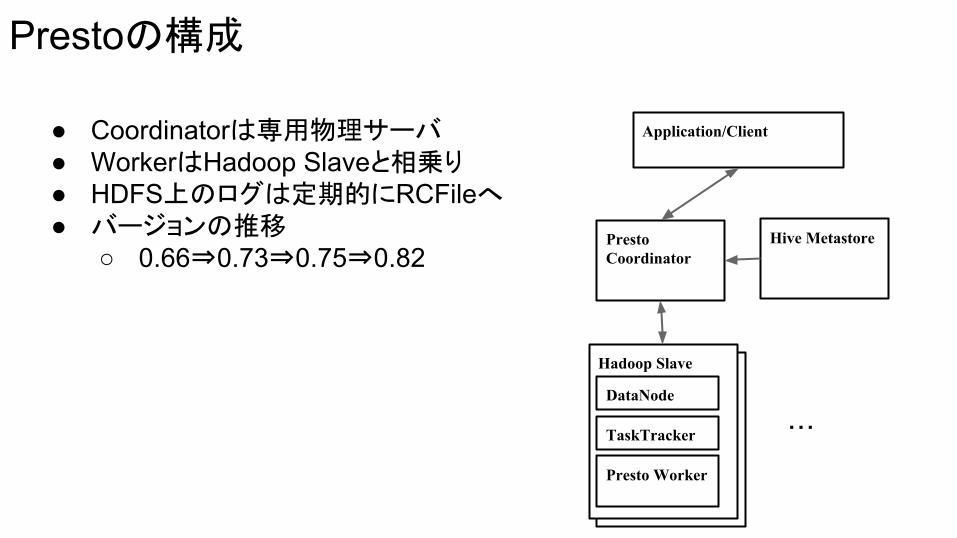
Hadoop Slave
Prestoの構成
Hadoop Slave
DataNode
TaskTracker
Presto Worker
Presto Coordinator
Hive Metastore
Application/Client
・・・
● Coordinatorは専用物理サーバ● WorkerはHadoop Slaveと相乗り● HDFS上のログは定期的にRCFileへ● バージョンの推移
○ 0.66⇒0.73⇒0.75⇒0.82
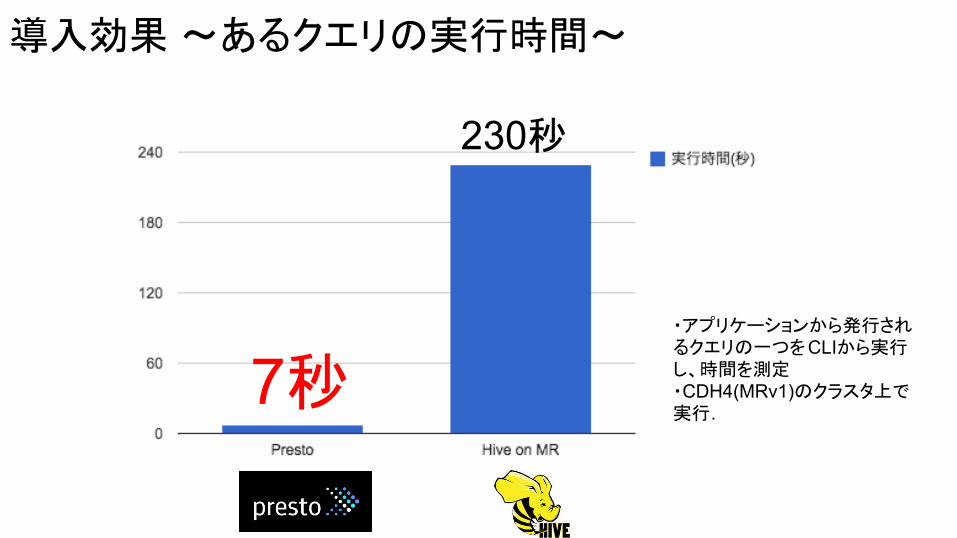
導入効果 〜あるクエリの実行時間〜
230秒
7秒・アプリケーションから発行されるクエリの一つをCLIから実行し、時間を測定・CDH4(MRv1)のクラスタ上で実行.

構築・運用
● 構築○ RPM化してAnsibleで展開○ 配置+設定ファイル書き換えだけなので簡単
● 運用で使っているもの○ クエリ実行履歴
■ コーディネータのWeb UI○ ログ
■ /var/presto/data/logs/{server.log,launcher.log}○ メトリック
■ presto-metrics(https://github.com/xerial/presto-metrics)⇒Fluentd⇒Elasticsearch + Kibana
○ sysスキーマ

困ったこと・トラブル事例
● Workerが落ちる、固まる○ OutOfMemory. 固まった時は、kill -9 しかない○ task.shard.max-threads×task.max-memoryが-Xmx
以下となるように調整
● node-scheduler.include-coordinator=trueにしてた頃は、CoordinatorがWorkerと一緒に落ちてた
● HiveQLとの違い○ アプリケーション側でHiveQL/Presto(ANSI SQL)両パターンのク
エリを用意

今後の課題
● Coordinator SPOFの対応● セキュリティ
○ 全てPresto実行ユーザの権限になってしまう● Hadoop Clusterとの間のリソース制御

Presto VS Hive+Tez

やったこと
クエリパフォーマンス観点での、
Presto VS Hive+Tez

結論
Presto VS Hive+TezWin Lose

どれくらい?
Presto VS Hive+Tez2.0~136倍

詳しく
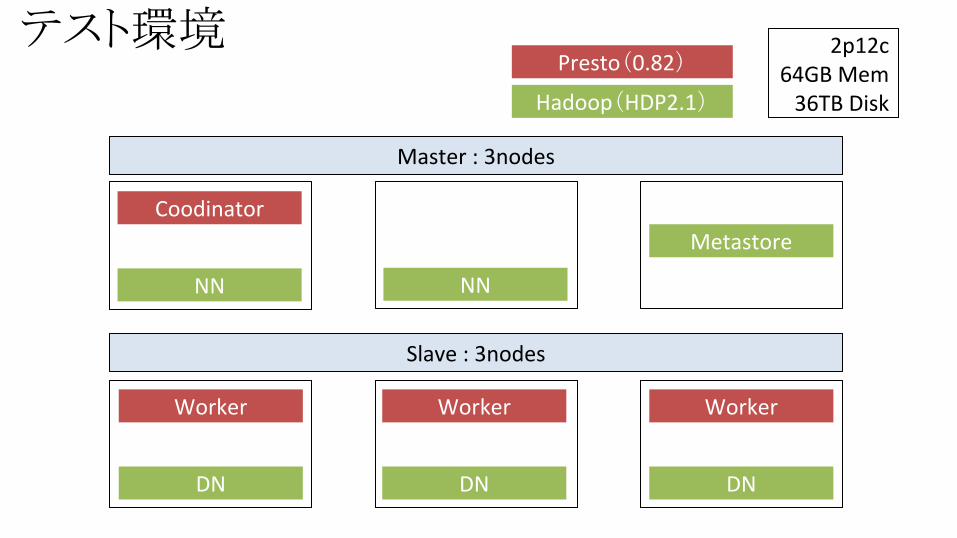
テスト環境 2p12c64GB Mem
36TB Disk
NN
DN DN DN
Hadoop(HDP2.1)
Presto(0.82)
Coodinator
Worker Worker Worker
Master : 3nodes
Slave : 3nodes
NN
Metastore
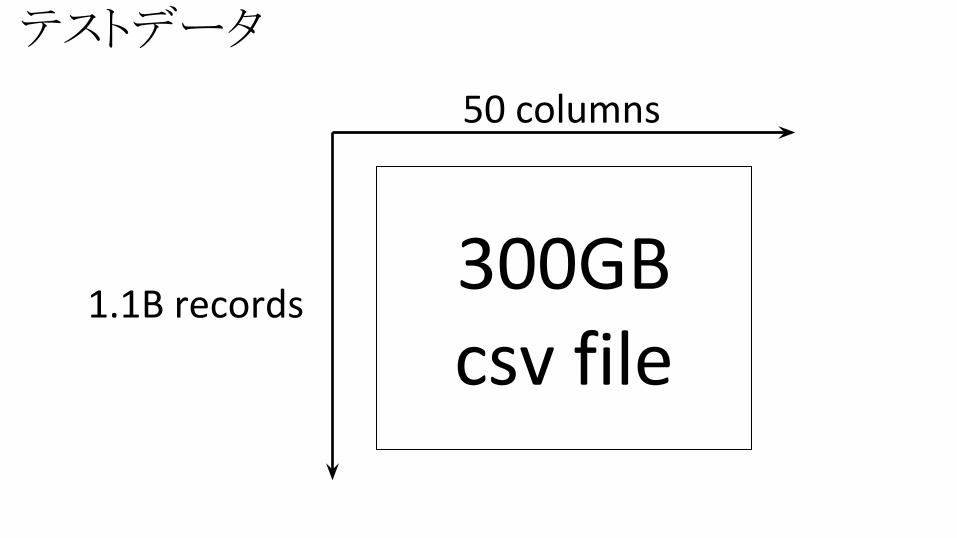
テストデータ
300GBcsv file
50 columns
1.1B records

パフォーマンス測定の軸
• クエリの種類• データの格納形式• 繰り返し

クエリの種類

測定したクエリ
Query1: select count(*) from TestTBL
Query2: select * from TestTBL where col1 = ‘XXX’
Query3: select * from TestTBL where col1 = ‘XXX’ and col2 = ‘YYY’
Query4: select col1, count(*) from TestTBL group by col1
Query5: select col1, count(*) from TestTBL where col2 = ‘YYY’ group by col1
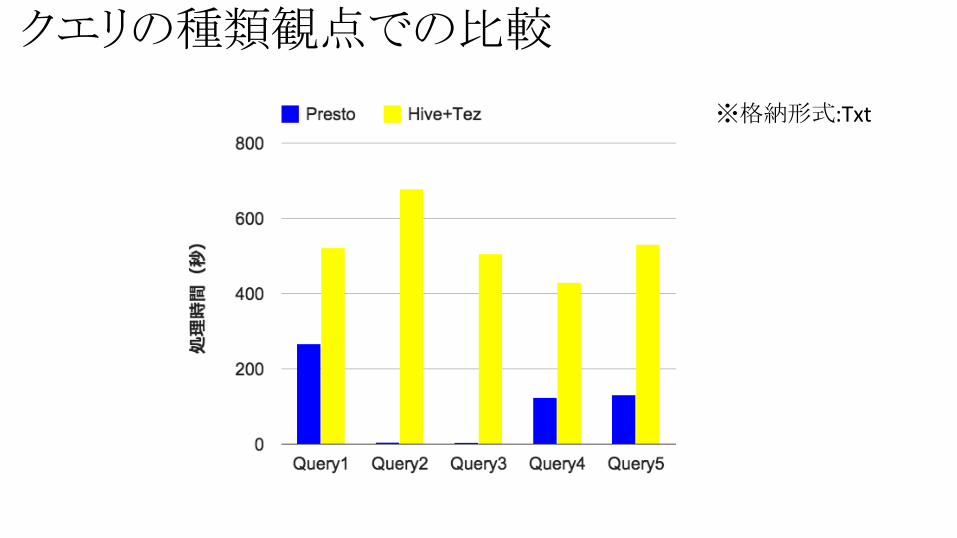
※格納形式:Txt
クエリの種類観点での比較
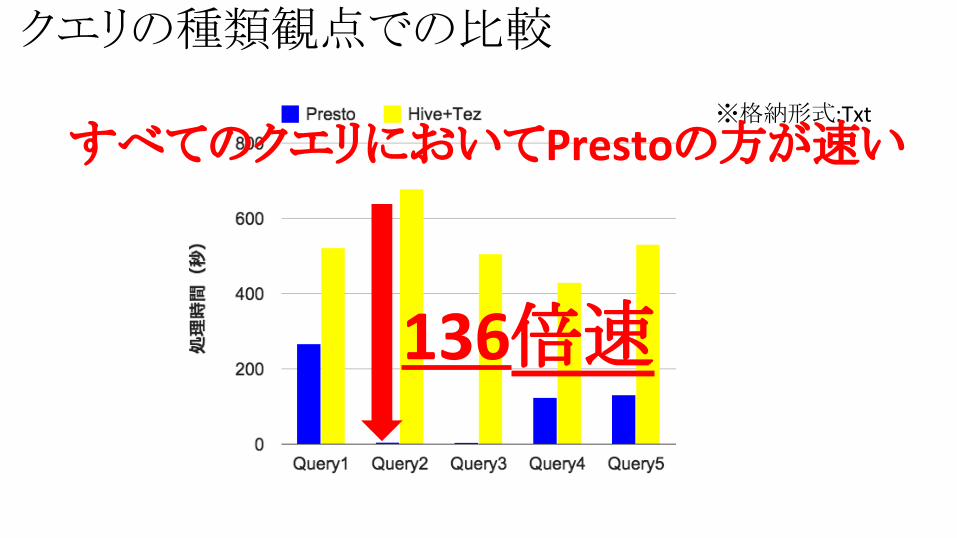
※格納形式:Txt
クエリの種類観点での比較
すべてのクエリにおいてPrestoの方が速い
136倍速

データ格納形式

測定した格納形式
• Text File (Textfile)• Record Columnar File (RCfile)• Optimized Row Columnar File (ORCfile)
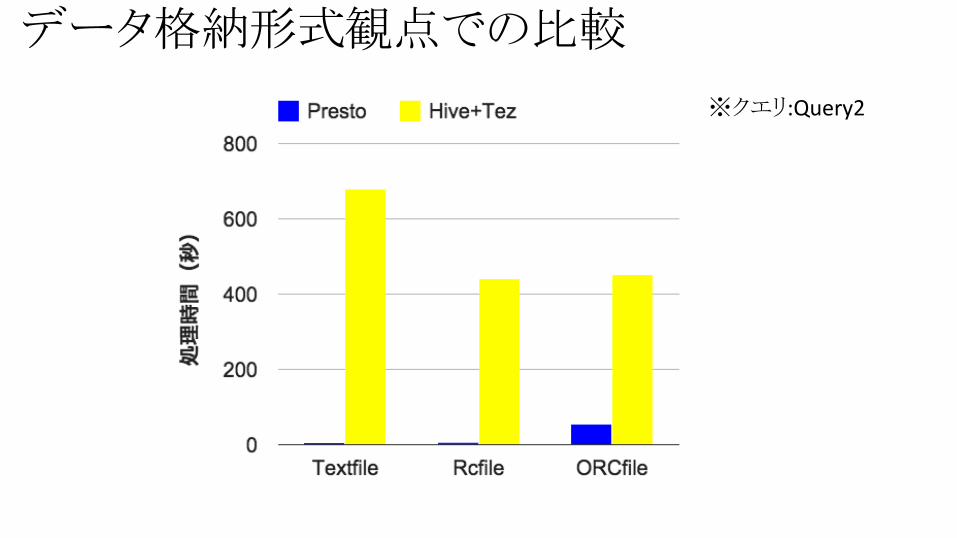
データ格納形式観点での比較
※クエリ:Query2
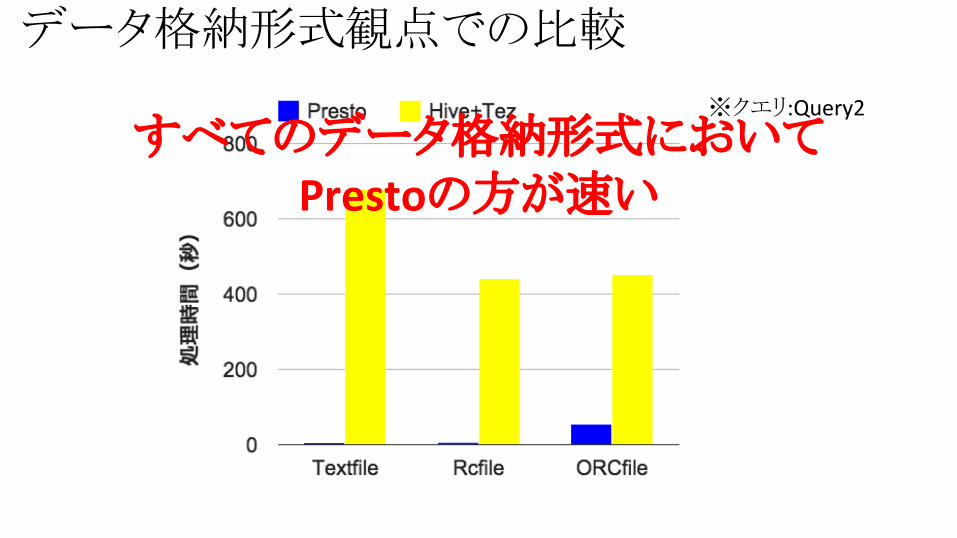
データ格納形式観点での比較
※クエリ:Query2
すべてのデータ格納形式においてPrestoの方が速い

繰り返し
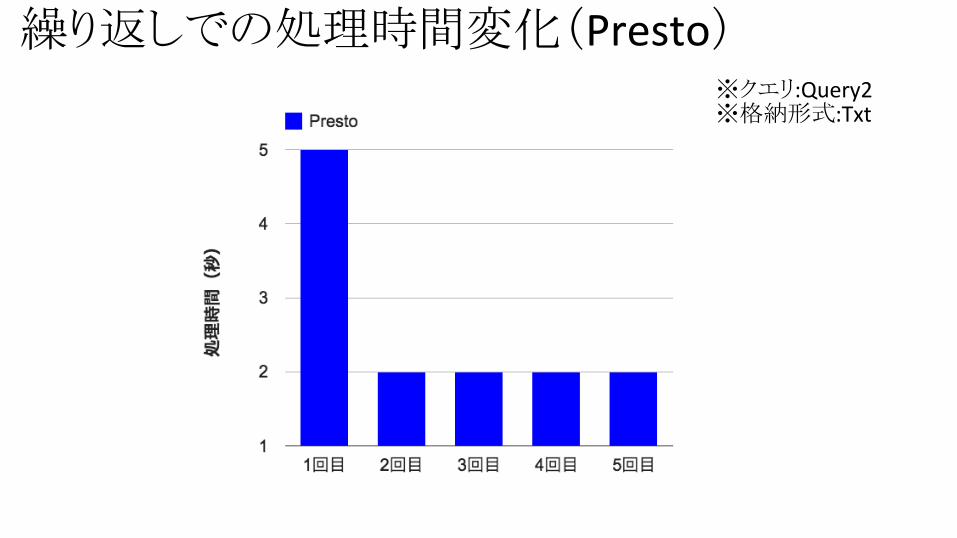
繰り返しでの処理時間変化(Presto)※クエリ:Query2※格納形式:Txt
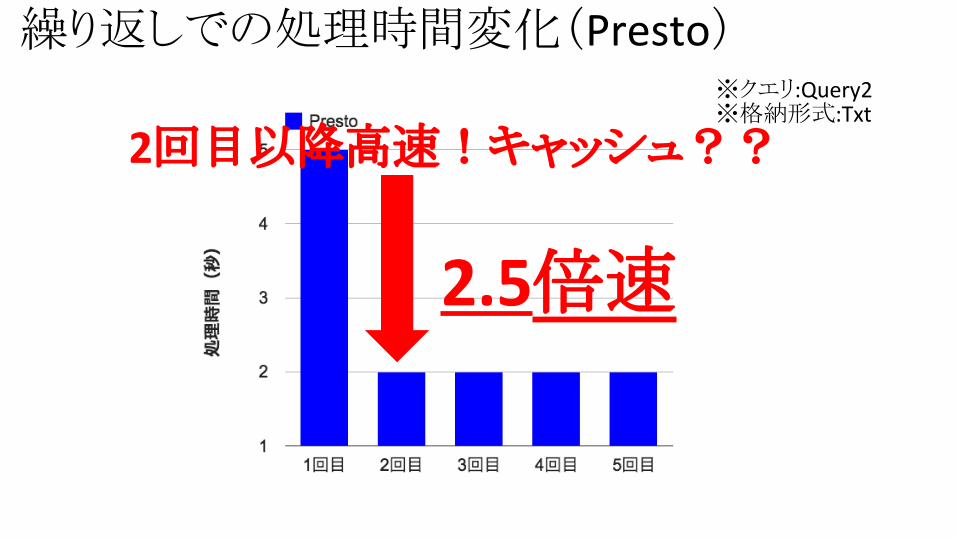
繰り返しでの処理時間変化(Presto)※クエリ:Query2※格納形式:Txt
2回目以降高速!キャッシュ??
2.5倍速
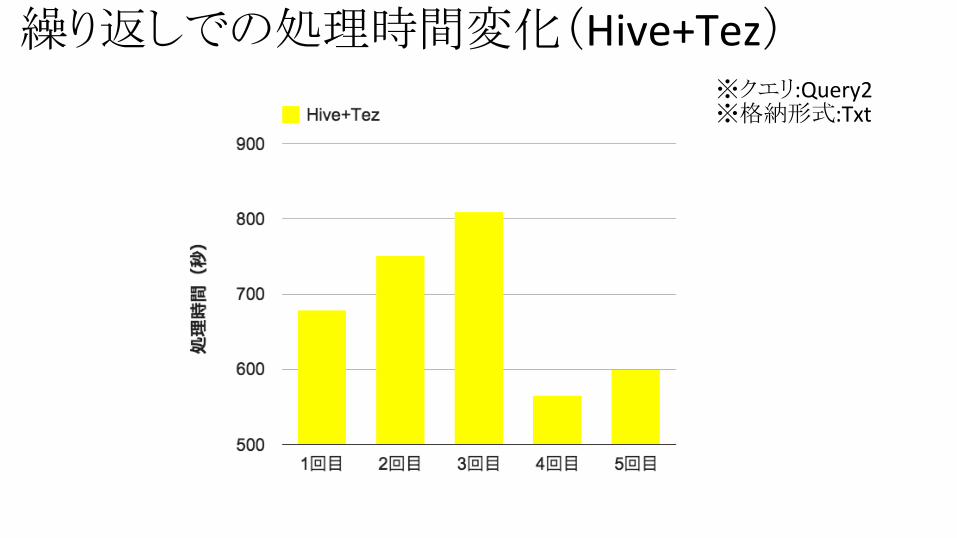
繰り返しでの処理時間変化(Hive+Tez)※クエリ:Query2※格納形式:Txt
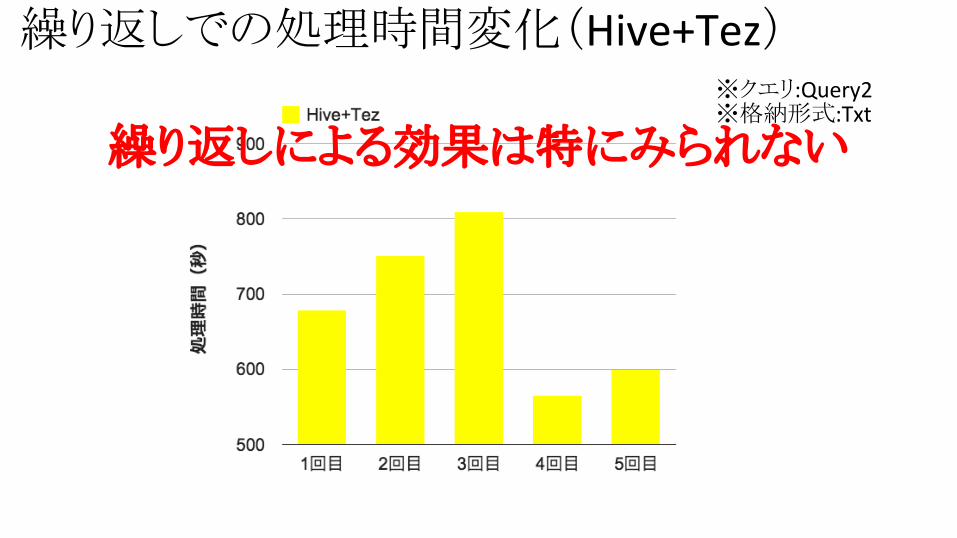
繰り返しでの処理時間変化(Hive+Tez)※クエリ:Query2※格納形式:Txt
繰り返しによる効果は特にみられない
+α
Engine:Presto
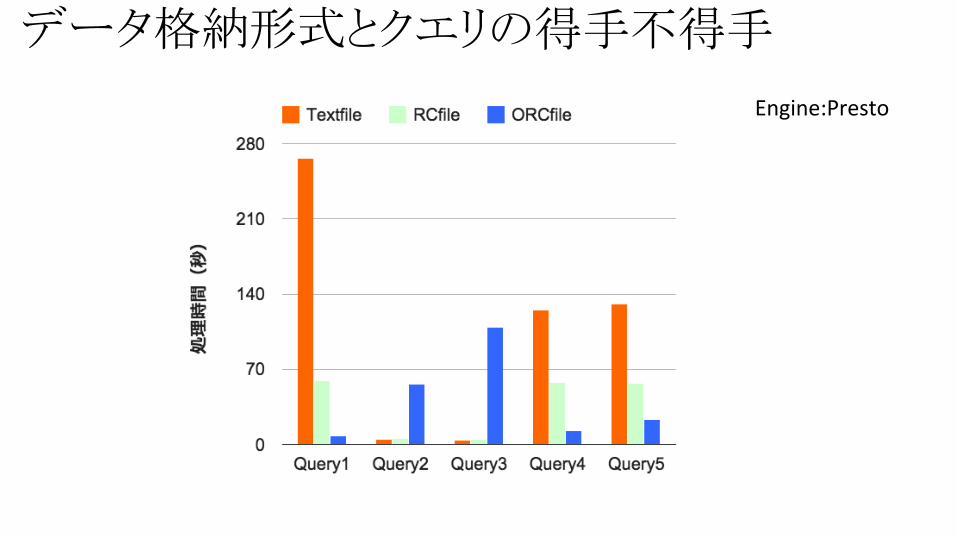
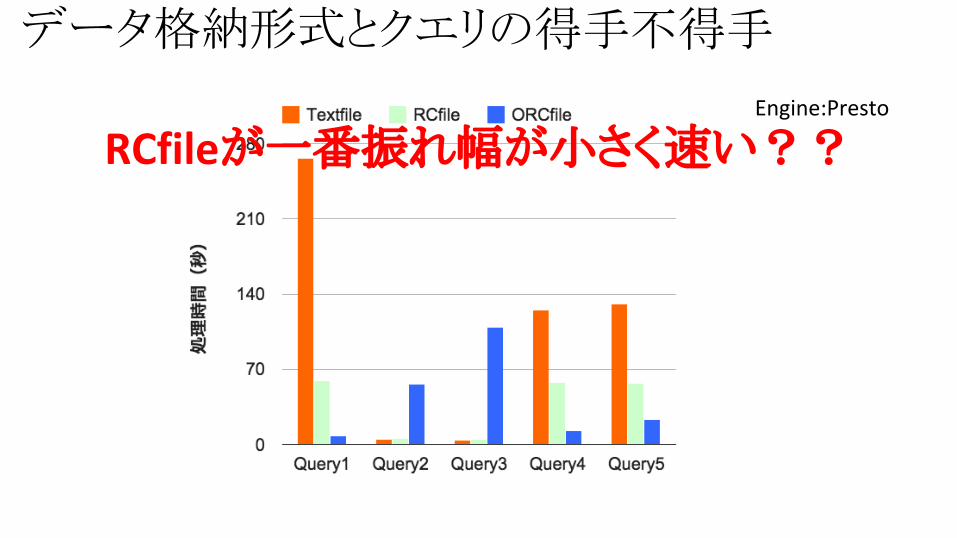
データ格納形式とクエリの得手不得手
Engine:Presto
データ格納形式とクエリの得手不得手
RCfileが一番振れ幅が小さく速い??

まとめ
結果● クエリの種類を問わず、Prestoの方が高速● データの格納形式を問わず、Prestoの方が高速● Prestoは繰り返し処理を行うと高速化する● PrestoはRCファイルを用いた場合に、最も安定的に高速処
理ができる
今後やりたいこと● ノードスケール、データ量観点での測定● ORCファイルの圧縮機能を使用しての測定● HDP2.2で同様のテスト


Appendix
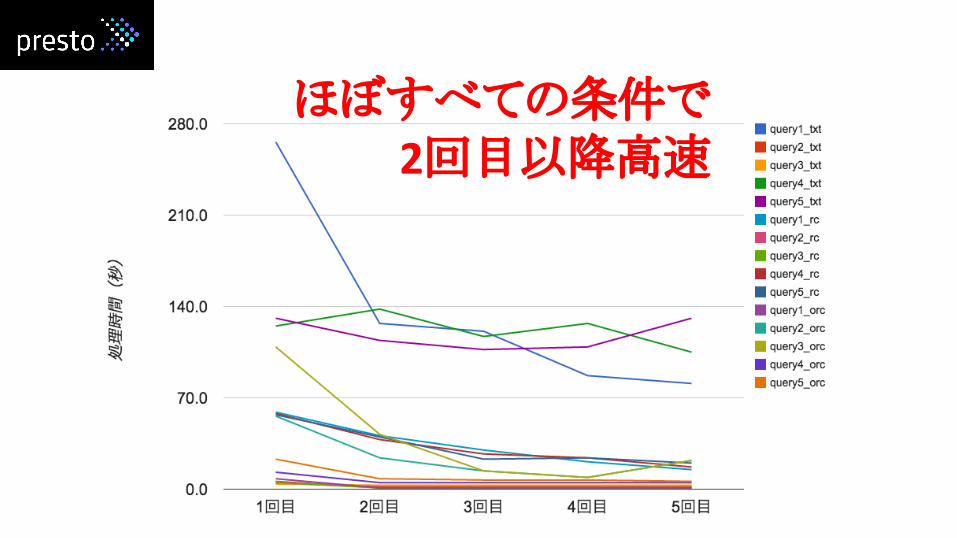
ほぼすべての条件で2回目以降高速