読解支援@2015 07-17
TRANSCRIPT

語順の相関に基づく機械翻訳の自動評価法. 平尾努, 磯崎秀樹, 須藤克仁, Kevin Duh, 塚田元, 永田昌明.
自然言語処理 Vol.21, No.3, pp.421-‐444, 2014.
プレゼンテーション 関沢祐樹
2015/07/17 1

概要
• 機械翻訳の自動評価 – BLEU, ROUGE-‐L が主流 – 問題点
• ルールベース翻訳を低く評価(人間は高く評価) • AなのでB を BなのでA →スコアがあまり下がらない
• 提案手法 – 訳語の違いに寛大 – 大局的語順を考慮 – 従来の自動評価法よりも良い
2015/07/17 2

N-‐gram一致率に基づく自動評価
• BLEU – も良く使われる評価指標
• 人間による評価との相関が高いと言われているため • システム翻訳と参照翻訳間の一致するN-‐gramの数を
数えるだけのため、実装が簡単
– Nは一般的には4が使われる • 短い単語列のみに着目する • 文構造が大きく変わる場合、スコアが大きく下がる • スコアが高くても、文の意味を保持しない場合がある
2015/07/17 3

N-‐gram一致率に基づく自動評価
• 意味を保持できない例
原文:ボブはメアリーに指輪を買うためにジョンの店に行った。 参照翻訳:Bob went to John’s store to buy a ring for Mary.
主語は全てBob
SMT出力:Bob to buy rings, Mary went to John shop. ジョンの店にいったのはMary 2-‐gram,3-‐gramの一致率は、低くないので、スコアが低くない
2015/07/17 4

文全体の大局的語順を考慮した自動評価法
• ROUGE-‐L – 文全体の大局的語順を考慮
• システム翻訳と参照翻訳間の一致する 長共通部分単語列に基づいたスコア付け
– 日英間の翻訳などではN-‐gram一致より良い評価
• IMPACT – ROUGE-‐Lの改良版
• 長共通部分単語列を発見して、その部分を削除し、再度、 長共通部分単語列を探索する
2015/07/17 5

文全体の大局的語順を考慮した自動評価法
ROUGE-‐L の場合 原文:雨に濡れたので、彼は風邪をひいた。 参照翻訳:He caught a cold because he got soaked in the rain. SMT出力1:He caught a cold because he had got wet in the rain. 参照翻訳:He caught a cold because he got soaked in the rain. SMT出力2:He got soaked in the rain because he caught a cold. 2015/07/17 6

文全体の大局的語順を考慮した自動評価法
IMPACTの場合 ROUGE-‐L の結果から、さらに探索 原文:雨に濡れたので、彼は風邪をひいた。 参照翻訳:He caught a cold because he got soaked in the rain. SMT出力1:He caught a cold because he had got wet in the rain. 参照翻訳:He caught a cold because he got soaked in the rain. SMT出力2:He got soaked in the rain because he caught a cold.
2015/07/17 7

語順の相関に基づく自動評価法
• LRscore – 参照翻訳とシステム翻訳間で、短い翻訳に対す
るペナルティを乗じ、BLEUスコアとの線形補完で評価スコア決定
– BLEUのスコア付けに補間を加えたもの
2015/07/17 8

提案手法
• RIBES – 語順の相関に基づく自動評価法 – 文内の大局的な語の並びに注目
• システム翻訳と参照翻訳に一致して出現する単語の出現順の近さを利用
– 単語アライメントを作成する – 単語出現順の相関を計算 – 翻訳結果によってはペナルティを付ける
2015/07/17 9

単語アライメントと出現順ID
• r:参照翻訳 h1:SMT出力
• r:[1,2,3,4,5,6,9,10,11] • h1:[1,2,3,4,5,6, 9,10,11]
2015/07/17 10

順位相関
• Pearsonの積率相関係数 – 人間の評価と自動評価の線形関係の評価
• Spearmanの順位相関係数:ρ – 順位の小さな入れ替わりに寛容すぎる、
順位の大きな入れ替わりに厳しすぎる
• Kendallの順位相関係数:τ – 予備実験で、τの方が人間の評価との相関 高
2015/07/17 11

ペナルティ
• システム翻訳の単語数が少ないとき – 参照翻訳 :John went to a restaurant yesterday – システム翻訳: to a
• システム翻訳の単語一致、順位に誤りなし • 参照翻訳の意味は保持していない
文単位の長さに対して それぞれにペナルティを付ける
2015/07/17 12

実験設定
• 実験データ
• JE: 日英 • EJ: 英日
2015/07/17 13

実験設定
• 実験手順 – パラメータ調整 1. 文のIDをランダムで10個選択 2. これを用いて人間評価と、自動評価間の
Spearman順位相関係数 大のパラメータ決定 3. 1.の残りの文集合全体を用いて評価
– 実験結果の出力 • 1〜3を100回繰り返し、各相関係数の平均値を出力
2015/07/17 14
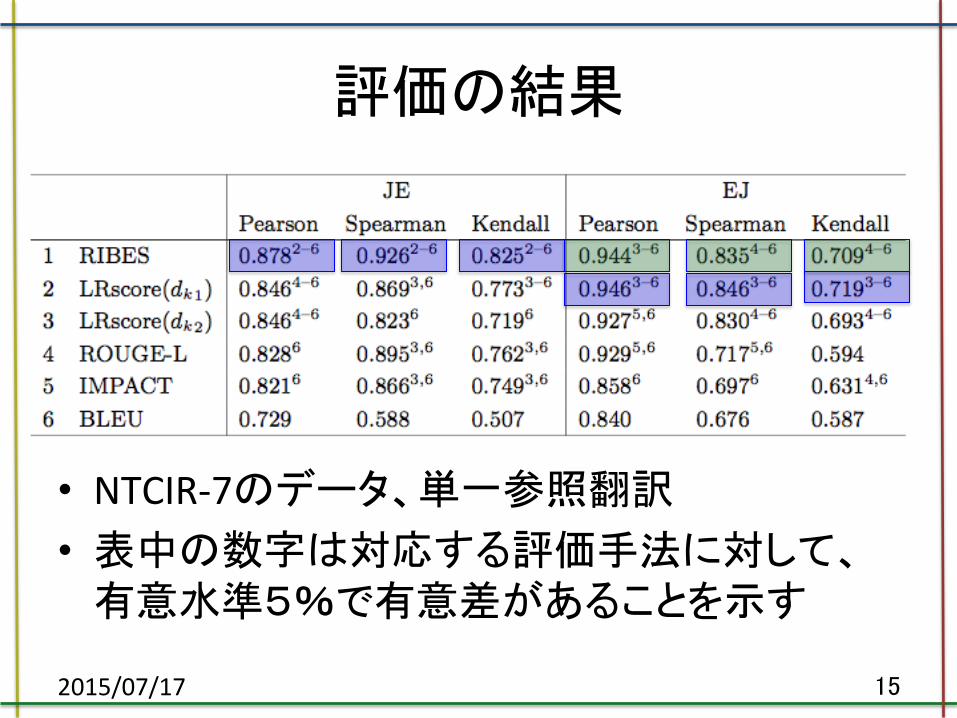
評価の結果
• NTCIR-‐7のデータ、単一参照翻訳 • 表中の数字は対応する評価手法に対して、
有意水準5%で有意差があることを示す
2015/07/17 15

評価の結果
• NTCIR-‐7のデータ、複数参照翻訳 • 表中の数字は対応する評価手法に対して、
有意水準5%で有意差があることを示す
2015/07/17 16

評価の結果
• NTCIR-‐9のデータ、単一参照翻訳 • 表中の数字は対抗する評価手法に対して、
有意水準5%で有意差があることを示す
2015/07/17 17

まとめ
• 従来の自動評価法 – 参照翻訳が少ない場合、相関が低い
• 提案手法:RIBES – 上記の弱点を克服 – 機能性にも優れる
– 日英、英日以外の言語対でも有効と考える
2015/07/17 18